大規模分散処理フレームワークの設計、実装が進行中
楽天版MapReduce・HadoopはRubyを活用
2008/12/01
楽天は11月29日、東京・品川の本社で開催した技術系イベント「楽天テクノロジーカンファレンス2008」において、近い将来に同社のEコマースサービス「楽天市場」を支える計画があるRubyベースの大規模分散処理技術「ROMA」(ローマ)と「fairy」(フェアリー)について、その概要を明らかにした。

レコメンデーションの処理自体はシンプル
楽天市場では現在、2600万点の商品を取り扱い、4200万人の会員に対してサービスを提供している。この規模の会員数・商品点数でレコメンデーション(商品の推薦)を行うのは容易ではない。
※記事初出時に楽天市場の会員数を4800万人としてありましたが、これは楽天グループのサービス利用者全体の数字でした。楽天市場の会員数は正しくは4200万人とのことです。お詫びして訂正いたします。
レコメンデーションの仕組みとして同社は、一般的でシンプルなアプローチを使っているという。1つは“協調フィルタリング”と呼ばれるもので、購買履歴や商品アイテムの評価が似たユーザーを探しだし、未購入の商品を勧めるというものだ。この方法では自分と嗜好(しこう)が似た人が買ったものが推薦されるのでジャンルに関係なく、意外性のある商品が推薦できる。もう1つの方法は、商品名や商品説明が類似しているもの、言い換えれば同ジャンルのものを推薦する方法だ。
楽天ではこれらの方法に加えて、在庫情報を照会して在庫の多いものを推薦する(在庫がないものは推薦しない)など独自の処理も加えているというが、基本的なアプローチはシンプルだという。
楽天も情報爆発しています
計算モデルがシンプルでも規模が巨大になるとまったく別の問題が生まれてくる。処理すべき情報量が爆発的に増加しているからだ。
例えば協調フィルタリングではユーザーを縦軸に、商品アイテムを横軸にした購買履歴マトリックスについて計算処理を行う必要があるが、あまりに量が多く、素直に実装すると「2日待っても計算が終わらないということになる」(同社)。同社では過去1年だけでも、処理すべきデータ量は3.7倍に膨らんだという。
このため同社ではアルゴリズムの工夫と大規模分散処理という2つの面で取り組んでいるという。
アルゴリズム面では、例えば嗜好の似たユーザーかどうかを判定するのに、「ローカリティ・センシティブ・ハッシング」(LSH:Locality Sensitive Hashing)というテクニックを使っているという。LSHを使うと、ユーザーの購買や評価の履歴が作る個別ベクトルの距離が小さい場合、高い確率でハッシュ値が一致するため、ベクトル間の距離をすべて計算せずに済むという。また、商品情報から辞書とマッチする言葉を抽出する際には検索関連で知られた技術「ダブル・アレイ・ツリー」(Double Array Trie)を使うことで高速化しているという。
こうしたアルゴリズムの工夫に加えて取り組んでいるのが大規模分散処理だ。現在はオープンソースのJava向け分散処理フレームワーク「Hadoop」を使っているが、同社は今後、Rubyベースで開発中の「ROMA」や「fairy」に代替していく計画という。
 楽天研究所ではRubyを使って「ROMA」と「fairy」を開発中
楽天研究所ではRubyを使って「ROMA」と「fairy」を開発中MapReduce、Hadoopの楽天版「fairy」
妖精を意味する「fairy」はRubyで実装した大規模分散処理フレームワークだ。「Framework Ambient Integration On Ruby」の略称ということになっているが「響きがいいだけで、特に意味はない」(楽天技術研究所 シニアテクノロジスト 増田創氏)という。競合する技術はグーグルのGFS/MapReduceや、ヤフーが中心となって開発を進めるオープンソースのHadoopだ。
fairyの開発を担当する楽天技術研究所 客員研究員の鳥居順次氏は「説明のためにMapReduceのようなものと言うが、実際には処理モデルが異なる」と説明する。MapReduceは処理対象を小さな単位に分けて分散処理し、それを集約して最終結果を得るという大きく2つの処理からなるが、fairyでは任意の数のフィルタを適用できるという違いがある。入出力をストリームで扱い、このストリームに各フィルタを順次適用していくことで処理を行う。
fariryのフレームワークでは処理を依頼する“クライアント”、それを受け取る“マスター”、マスターから細切れのデータと処理依頼を受け取る“ノード”の3要素からなる。各ノード上では、処理を受け取るサーバを事前に起動しておく。やろうと思えば1台で3役もこなせるが、fairlyは大規模でスケーラブルなシステムを想定しているという。


入力データとしてオープンしたファイルは分散ノード上で断片化するが、仮想分散ファイル(VFile)として扱われるため、プログラマはそれを意識する必要がない。また、入力データは現在のところテキストデータのみの対応だが、今後はバイナリも検討するという。
代表的なフィルタとして、入力データを要素として扱い、後ろのフィルタに出力する「map」系のものや、入力データをグルーピングして後ろのフィルタに出力する「group_by」が使えるという。MapReduceやHadoopの“Hello World”に相当するワード・カウント(単語ごとの出現回数を数える)の処理では「単語に分割」(smap)、「単語ごとにグルーピング」(group_by)、「グルーピングされた単語数を数える」(smap)という3段階で実現できる。楽天では何千万件にもなるユーザーごとの購買履歴から、商品アイテムごとにグルーピングされた併売数集計にまとめるような処理でfairyを使う計画という。
これらのフィルタ処理は、Rubyプログラマにはなじみの深い文法/処理構造であるコードブロックを使って定義できる。「Rubyの生産性の高さを損なわないで、自然で簡潔に分散処理できるように設計した」(増田氏)という。ROMA/fairyの設計・開発にあたってはRuby設計者のまつもとゆきひろ氏のアドバイスも受けており、「特にノーテーション(記法)についてはまつもと氏の強いこだわりが反映されている」(同氏)という。

 ワードカウントの実際のコード例。コードブロック中のiとoが、それぞれ入出力ストリームに相当する。読み込んだ各行(ln)を単語に切り分けて出力ストリーム(o)にpushする、という10行目などはRubyプログラマにはごく自然
ワードカウントの実際のコード例。コードブロック中のiとoが、それぞれ入出力ストリームに相当する。読み込んだ各行(ln)を単語に切り分けて出力ストリーム(o)にpushする、という10行目などはRubyプログラマにはごく自然


十分なパフォーマンスを出すこともfairyの大きな設計目標という。「Rubyはもともと速いと言われていないが、なるべくデータをメモリ上に置くとか、ネットワーク越しの転送を抑えるなどして実用に耐えるパフォーマンスを目指している」(同氏)。また今後はJava VM上で動くRuby処理系のJRubyへの対応も検討する。Cで書かれたオリジナルのRubyでは移植性を重視したためスレッド処理はネイティブスレッドに対応しない。このためマルチコアの恩恵を受けづらい。JRubyであれば処理の並列化が容易ではないかという。
現在fairyは基本的なフィルタ処理は実装済みで動作しているが、パフォーマンスについては未知数だ。増田氏は「今後は実際の課題で適用可能性を実証していくが、遅くて使えないよという話になると思うので、どんどんチューニングしていきたい」と話す。「いろいろ課題はあると思うが、“Yes, we can”という精神でやっていく」(同氏)と意気込みを語る。
 併売データとは、ある商品アイテムに注目したとき、その商品とともに買われている商品を、商品ごとに点数で表したデータ
併売データとは、ある商品アイテムに注目したとき、その商品とともに買われている商品を、商品ごとに点数で表したデータ 元データにはユーザーIDごとに購入した商品データがIDで並んでいる。ここから併売データを生成する
元データにはユーザーIDごとに購入した商品データがIDで並んでいる。ここから併売データを生成する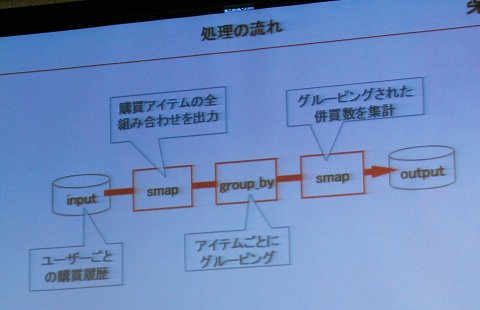 fairyを使った併売データ作成処理の流れ
fairyを使った併売データ作成処理の流れ

memcached、Coherence、Dynamoに相当する「ROMA」
楽天の大規模分散処理フレームワークのもう1つのプロジェクトは「ROMA」(Rakuten On-Memory Architecture)と名付けられた分散オンメモリストレージだ。任意の台数のサーバに搭載されたメモリを仮想的に1つにまとめ、1つの大きなハッシュテーブルのストレージとして扱うことができるという。「キー・値」(key-value)というオブジェクトデータを保存したり(PUT)、読み出したり(GET)できる。ROMAのクライアントにはRubyとJavaが使える。
 楽天技術研究所 アソシエイト 西澤無我氏
楽天技術研究所 アソシエイト 西澤無我氏ROMAは、アマゾンが「Dynamo」と名付けたシステムで取り組む分散ハッシュテーブルの実装や、オラクルがデータベースのI/Oボトルネックを解消する目的で提供する分散型インメモリ・データグリッド「Oracle Coherence」に相当する仕組みだという。負荷集中の緩和やディスクI/Oのボトルネック解消を目的としている点では、分散メモリオブジェクトキャッシュシステムの「memcached」とも重なる。
Dynamo、Coherence、ROMA、memcachedは技術的に似ているが、楽天技術研究所の西澤無我氏によれば、これらにはデータの一貫性に対する考え方の違いがあるという。「パフォーマンスとデータの一貫性はトレードオフ」(西澤氏)で、例えばmemcachedはパフォーマンスは高いが、データの一貫性の保証はクライアントが行う必要がある。逆にROMAはデータの一貫性を重視しており、ユーザー(開発者)は実際のデータがどのノードにあるか、そのデータが有効なものかどうかなどを気にする必要がない。Dynamoではデータの一貫性をある程度犠牲にすることでパフォーマンスを稼いでいると言われている。

環状のP2P構成で耐障害性を実現
ROMAの設計目標の1つは、高負荷な状況下や障害時にも正常動作し続ける、というものだ。耐障害性という点ではデータベースのHA構成でも良いが、ディスクI/Oのボトルネックが残る。また単純にメモリ上にデータを置くと、コストがかさむ上に障害時にデータ喪失が起こるという問題がある。
このため、ROMAではP2Pの環状モデルを採用しており、特定ノードが保持するデータは隣接する2つのノードにもコピーするという3重の冗長度を持つ設計になっているという。ただし、同一データは3個所にあるが、PUT/GETは必ずプライマリノードが担当する。パフォーマンスを上げるためには、隣接するセカンダリノードに対してPUT/GETする方法もあるが、データの一貫性を保ちやすいことや、現在はまだモデルの検証段階であることなどから、ROMAではこうした設計になっているという。プライマリノードが高負荷になりボトルネックとなる場合には、その付近に新規ノードを追加することで対処できるのではないかという。ROMAでは環状に並んだノードの任意の場所に動的にノードを追加できるため、次々とサーバ(メモリ)を追加していくことでスケールアウトできる。
パフォーマンス向上のため、ROMAではデータの探索はクライアントが行う。クライアントは、ROMAに初めてアクセスしたときに各ノードのID、ポート番号、ハッシュ値などを取得する。各ノードは飛び飛びのハッシュ値が昇順に隣接して並んでおり、あるキーのハッシュ値を求めれば担当ノードが分かる。こうすることでデータ探索のためのノード間ホップを不要とし、高いレスポンス速度を実現するという。「たかだか数百台、多くても1000台程度を上限と考えているので、こういうやり方ができる」(西澤氏)。






独自のオブジェクトハンドリングで速度向上
“たかだか”という言葉を使ってはいるが、楽天がROMAの利用で想定している規模は大きい。「われわれは数百万オブジェクトをROMAに載せるつもりだ」(鳥居氏)。例えば5台のノードで構成した場合、100万オブジェクトでも各ノードが保持するオブジェクト数は60万(100万/5台×冗長度3)にもなる。こうなってくると、Ruby処理系のガーベージコレクタのオーバーヘッドが大きくなり、レスポンスが悪くなる。あまりレスポンスが遅くなると、そのノードを不活性と判定した別ノード上で耐障害用のメソッドが走り出すなど別の問題も出てくるという。このため、独自に実装した拡張ライブラリを使ってRuby処理系が提供するヒープ領域とは別にオブジェクトを保存し、明示的にメモリを開放するというチューニングを行っているという。実装や処理モデルは複雑になるが、Ruby処理系と同様にユーザー(開発者)にとってシンプルに見えることを重視しているという。

現在、ROMAは5台構成でGET処理を行うと1秒間に8000クエリ程度の処理能力が出ているという。これは同様の構成で1〜2万クエリ/秒をたたき出すmemcachedには及ばないが、十分に速い。また西澤氏は、「アプリケーションによっては(一貫性を多少犠牲にしても)速度がほしいこともあるので、そういうモデルに適したものも提供していきたい」と話す。
今後ROMAでは、連続する3ノードが同時に失われた場合でもディスクからデータを復旧できる永続化機能の実装を計画している。また、ROMA、fairyとも2009年にはオープンソース化も視野に入れており、楽天では「大規模処理や高速化の知見をRubyコミュニティに還元していきたい」(西澤氏)としている。
楽天でROMA、fairyに取り組むプロジェクトメンバは社内外を含めて5人。Rubyの開発で知られるまつもと氏や石塚圭樹氏、並列・分散プログラミングで知られる楽天技術顧問で東大准教授の増原英彦氏など「豪華なメンバーでやっている」(増田氏)という。
関連リンク
関連記事
情報をお寄せください:
- プログラムの実行はどのようにして行われるのか、Linuxカーネルのコードから探る (2017/7/20)
C言語の「Hello World!」プログラムで使われる、「printf()」「main()」関数の中身を、デバッガによる解析と逆アセンブル、ソースコード読解などのさまざまな側面から探る連載。最終回は、Linuxカーネルの中では、プログラムの起動時にはどのような処理が行われているのかを探る - エンジニアならC言語プログラムの終わりに呼び出されるexit()の中身分かってますよね? (2017/7/13)
C言語の「Hello World!」プログラムで使われる、「printf()」「main()」関数の中身を、デバッガによる解析と逆アセンブル、ソースコード読解などのさまざまな側面から探る連載。今回は、プログラムの終わりに呼び出されるexit()の中身を探る - VBAにおけるFileDialog操作の基本&ドライブの空き容量、ファイルのサイズやタイムスタンプの取得方法 (2017/7/10)
指定したドライブの空き容量、ファイルのタイムスタンプや属性を取得する方法、FileDialog/エクスプローラー操作の基本を紹介します - さらば残業! 面倒くさいエクセル業務を楽にする「Excel VBA」とは (2017/7/6)
日頃発生する“面倒くさい業務”。簡単なプログラミングで効率化できる可能性がある。本稿では、業務で使うことが多い「Microsoft Excel」で使えるVBAを紹介する。※ショートカットキー、アクセスキーの解説あり
|
|
キャリアアップ
- - PR -
注目のテーマ




転職/派遣情報を探す


「ITmedia マーケティング」新着記事
SNS経由の商談アポ依頼はアリ? 経営者・企業幹部に調査
SNSを活用したビジネスアポイントの獲得が拡大している。見知らぬ相手からのアプローチに...
Xの利用者数は過去最高? 減少中? X自身のデータで検証してみると……
Xは、2024年の利用者数が過去最高を記録したとアピールしている。これは本当だろうか。も...
自己肯定感? 将来への投資? 「サステナブルカスタマー」は今、どのくらいいるのか?
電通が第3回「サステナブルカスタマー調査」を実施。調査結果から、サーキュラーエコノミ...