D-Lib Magazine
|
|
|
David A. Smith |
![]()
|
Among many observations in the widely bruited UN Arab Human Development Report of 2002, one in particular struck home: fewer books had been translated into Arabic in the millennium since the caliph al-Mutawakkil than were translated into Spanish in a year. The sting of this comparison invoked the caliphs as the intellectual culture heroes, who had supported scholars translating Greek, Syriac, and Indian works to fill the libraries of Baghdad and Samarra. The report's authors might also have thought of the later cultural interface in Spain where multiconfessional translators turned Arabic into Latin and Spanish before "the tragedy of al-Andalus". Recalling the zenith of the Abbasids, the UN scholars provide a pedigree for translation not as passive reception of occidental fashion but as the expression of a rising and confident culture. Just as translation builds libraries, libraries nurture translation. Machine translation, even in embryo, provides some hope that ever expanding digital collections can also greatly expand their audience. That hope derives, in part, from the ways that massive digital libraries can enrich and change research on machine translation. Works in digital (and print) collections are translated at unequal rates. A small number of works—in religious and literary canons—are translated again and again. A moderate number are translated once or a few times, and the great mass are never translated at all. This Zipfian distribution (with its "long tail") provides a mutual opportunity for MT and digital libraries: at the peak, MT can benefit from massively parallel translations; in the middle, MT can help DLs find and align existing translations; in the tails, MT can provide readers with finding and browsing aids for multilingual texts (Figure 1). I will first ground these predictions in the origins and development of data-driven, or empirical, machine translation (MT). I then describe some major subproblems in MT research and note how they might adapt to benefit, or benefit from, emerging comprehensive digital libraries. Finally, we see how MT and digital libraries could enter a virtuous cycle of collection, augmentation, and access. Breaking the CodeThe generation of Second World War code breakers Turing, von Neumann, Shannon, and Wiener invented computing machinery and, almost simultaneously, the idea of translation as mechanized "decoding". Hopes for easily ingesting Russian technical literature receded into the future until the Automatic Language Processing Advisory Committee (ALPAC) report of 1966 recommended that the U.S. government stop funding machine translation. One recommendation was for more basic linguistics research (and indeed by 1968, the MIT linguist Paul Kiparsky, for example, could publish papers on Swiss-German phonology and the Indo-European injunctive mood that were funded by the Air Force).
Despite the ALPAC report and its identification of a "glut" of human translators, companies such as SYSTRAN continued to amass translation lexicons. Human linguists wrote rules to transform one languages syntax into another's, especially for limited domains such as equipment manuals. Riding a wider empirical wave in artificial intelligence and natural language processing in the late 1980s and early 1990s, MT researchers at IBM and AT&T realized that a growing amount of on-line bilingual data could be used to train translation systems. Much of this early statistical work used the English-French Canadian Parliamentary Hansards. Similar parallel texts – European Parliament transcripts, UN documents, and Hong Kong Hansards – provided training data for other language pairs. Empirical translation research has made strides from IBM's Candide system to the latest Google translation services. The research program of statistical machine translation has remained
These goals may not always be completely congruent: we might want to model, and to find in a library, free or erroneous human translations; but we don't necessarily want to reproduce those features in automatic translations. Even more helpful than source text with a single translation is source text with multiple translations. Multiple translations can give us much more information about the variation of translations: to what extent is the same source text subject to varying or consistent translation in exactly the same context? Single translations provide information about how the same source word or phrase might be translated differently in different contexts, but this information has a higher variance. In any case, very little parallel text in the appropriate domain or language pair may be available. To overcome this, researchers have turned to comparable corpora such as news stories from the same week or technical articles on similar topics. Words with similar distributions in comparable documents tend to be translations. The majority of scientific and technical literature, and specialized scholarly productions, is not translated. Subject metadata and overlapping technical terms can help us identify comparable articles in different languages. We can then bootstrap more terms into our translation dictionaries and repeat the process. While online translation services such as Babel Fish (as described in Yang & Lange 1998) and Google Translations (see Figure 2 below) have been limited to pairs of only a handful of widely used languages – English, several Western European languages, Russian, Japanese, Chinese and Korean – a number of researchers are also applying MT methods to underrepresented languages such as Serbo-Croatian and Haitian Creole (Frederking et al. 2000) and Mapudungun (Probst et al. 2003). Aside from web-based translation, MT has also been used productively in translating TV closed captions (Turcato et al. 2000) and chat room conversations (Flournoy and Callison-Burch 2000), and is also widely used as a tool to help human translators (Isabelle and Church 1998).
Building SystemsData-driven MT systems are built in three general stages:
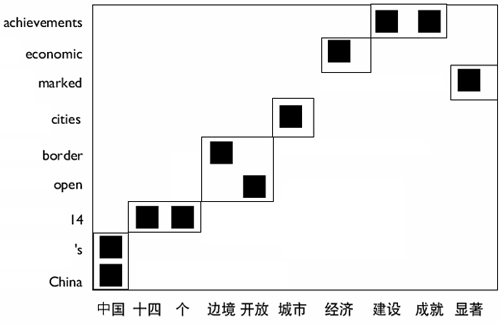
The latter two modeling stages are often said to concern the adequacy of a translation at conveying meaning and its fluency. We consider all three stages and their niche in the digital library environment. Since the bilingual data used to train current MT systems usually comes from newswire services or government agencies, metadata is often available to align these texts – at least to the level of an article or document section of some tens of sentences. Within these articles, sentence and word alignments can proceed fairly rapidly, even while allowing for the translator's dropped clauses or breaking up or combining sentences from the source. Such dense metadata are not usually available in large digital libraries. Some catalogue records contain uniform titles that could match texts with their translations but this information is not universal or fine-grained enough. A book containing translations of three works of Aristotle might not be formally linked to each of the original works. In theory, an exhaustive search in a library of n items would require n2/2 book-to-book comparisons – even more if we allowed arbitrary collections of works to be bound together. Even without richer metadata such as publication or uniform author information, we can make this search much more tractable in practice. If, for example, we were interested in translations into English, we would need to compare English books only against works in other languages. Automatic methods can identify languages very quickly by looking at only a few hundred words of text (or even 30 seconds of speech). In any case, even if we know that a volume is an English version of the Nicomachean Ethics or Madame Bovary, metadata on chapter breaks and smaller subdivisions is usually non-existent. Sentence, or more generally, chunk alignment can progress simply by looking at the relative length distributions of successive sections; these algorithms, of course, improve when a translation lexicon is available. Also, even rough chapter segmentation information can greatly speed up alignment. Similarly, researchers trying to align web pages from the Internet Archive got substantial gains by paying attention to parallel HTML structures (Resnik & Smith, 2003). Note also that the basic tokens of information may vary from one language to another. Chinese and Japanese texts are conventionally written without inter-word spaces and we may need to simultaneously decide on the best word segmentation and alignment. Current MT researchers are mostly interested in high precision in chunk and word alignments. They will throw out quite a bit of promising data to ensure that their translation models have the highest accuracy. A digital library application might be more interested in recall. If a translation of some text is already in the library, it is better to spend a little effort finding it than to use the most advanced MT system. Ideally, automatic translation-finding techniques can act as a filter for richer metadata creation. Once parallel text has been aligned down the level of words and phrases (Figure 3), we produce a translation model for how structures in one language relate to those in another. The simplest models are lexical: German das becomes the with some probability and translates as that with another probability. Lexical models may also involve the deletion of individual words: French ne goes to the empty string and pas goes to not. Since words are affected by the company they keep, more refined models often define their probability distributions over contiguous phrases (Och & Ney, 2004). The German zu Hause aligns to at home much more often than at the house. Besides word-aligned texts, we may mine these correspondences directly from bilingual dictionaries. One pitfall with dictionaries, however, is estimating the relative frequency of various translation options; a dictionary may give us an inflated idea of the importance of relatively rare constructions. The quality (or lack thereof) of translation models learned purely from parallel text grows approximately logarithmically with the amount of training data. At the low end, a little bit more training data helps a lot. Here are two versions of the first sentence of the Spiegel article shown above in Figure 2. With only 1000 sentence pairs of training data, only function words, and the translation of "USA" as "United States", have been seen: the new york 'times' berichtet Über the weitergabe a militärischen skizze in the vorfeld of irak - kriegs through the bnd in the united states. With 100,000 sentence pairs, the translation is much cleaner, even though some German words have not been seen in training: the new york 'times' reports on analysis of the militärischen skizze in advance of iraq - kriegs by the bnd in the united states.
Besides individual words and contiguous strings or "phrases", aligning higher-level syntactic or semantic structures seems to be an attractive approach. We could generalize beyond the concrete usages found in our training data and more easily deal with insertions and deletions of non-obligatory (adjunct) phrases and clauses. We could cover a lot more data by saying that Arabic, for example, is generally a verb-subject-object language than by observing many sentences beginning with specific verbs. There are pitfalls with a naive application of this idea. Free or erroneous translations foil any idea of one-to-one grammatical mappings (Figure 4). More subtly, models of syntax in the source or the target language are often built from monolingual trees created to suit certain linguistic theories. A German parser, for instance, may be trained on the Negra corpus, which treats relative pronouns as children of the relative clause verb and prepositions as "case marking" children of their object nouns. English parsers are often trained on the Penn Wall Street Journal Treebank, where these relations are reversed. The most successful syntactic translation approaches have thus induced grammars directly from the data, rather than relying on a priori categories (Chiang, 2005; Wu, 1996).
Digital library collections provide several opportunities for translation modeling. Most obviously, the presence of multiple translations will allow more direct models of what is obligatory and what is optional in translation. Multiple translations can also be helpful for training summarization, paraphrase detection, and information retrieval systems. The much broader range of genres and topics in digital libraries open up the possibility of more targeted models of sublanguages. This approach can already be seen in separate natural language processing systems tuned for biomedical text. In contrast to the work necessary to align and model bilingual text, building monolingual language models is straightforward. As noted above, automatic language identification is reliable even on fairly small samples. We can then easily collect text in any desired language and construct models that assign probability to a sequences of words in the language. The most common form for language models is factored: predict every word given the previous three or four words, then multiply all the word probabilities to get the probability of a given passage. Alternately, we can predict words given preceding syntactic structures. In computational humanities, language modeling is most closely associated with authorship studies. In MT, statistical language models are used to choose the candidate translation with the closest resemblance to fluent target language text. Statisticians have used language models to impute missing words in government-censored texts; similarly, language models could suggest completions for lacunae in manuscripts and inscriptions. Plagiarism detection, in a less adversarial form, could be applied to quotation finding. More subtly, syntactic language models could be used, for example, to find "Ciceronian" passages in the neo-Latin productions of the Renaissance. The Virtuous CycleDevelopment in language technologies has been driven by new algorithms, new problems, and new data. Million-book libraries provide not only testbeds for existing ideas, but also several problems in need of immediate solution. As data acquisition becomes more automated, cataloguing needs more automated help. Automatic language identification – and translation finding and alignment – provide fine-grained metadata, perhaps to the level of individual words. The Zipfian, power-law distribution of data in digital libraries predicts that we will have some intensively curated materials for training our models. At the same time, there will always be the "long tail" of holdings never translated. Providing universal access to the library requires first of all that the language of its texts is readable to the user. The first priority must be to detect and align existing translations within the library. Secondly, we can provide machine translation services that, however flawed, can help readers make some sense of multilingual content. Finally, we can close the loop: human translators working in the digital library can edit machine translations or have translations suggested to them as they type (Foster et al., 2002). These new translations can be automatically aligned, as they are created, to the source text and provide detailed training data for future systems. BibliographyD. Chiang. 2005. "A Hierarchical Phrase-Based Model for Statistical Machine Translation," Proceedings of the Association for Computational Linguistics. <http://www.aclweb.org/anthology/P/P05/P05-1033>. K. W. Church and E. H. Hovy. 1993. "Good Applications for Crummy Machine Translation," Machine Translation 8(4). R. S. Flournoy and C. Callison-Burch. 2000. "Reconciling User Expectations and Translation Technology to Create a Useful Real-World Application," Translating and the Computer 22: Proceedings of the 22nd International Conference on Translating and the Computer. G. Foster, P. Langlais, and G. Lapalme. 2002. "User-Friendly Text Prediction for Translators," Empirical Methods in Natural Language Processing. <http://www.aclweb.org/anthology/W/W02/W02-1020>. R. Frederking, A. Rudnicky, C. Hogan, and K. Lenzo. 2000. "Interactive Speech Translation in the DIPLOMAT Project," Machine Translation 15(1-2). P. Isabelle and K. W. Church (eds.). 1998. "New Tools for Human Translators," Machine Translation 13(1-2). F. J. Och and H. Ney. 2004. "The Alignment Template Approach to Statistical Machine Translation," Computational Linguistics 30(4). <http://www.aclweb.org/anthology/J04-4002>. K. Probst, L. Levin, E. Peterson, A. Lavie, and J. Carbonell. 2003. "MT for Minority Languages Using Elicitation-Based Learning of Syntactic Transfer Rules," Machine Translation 17(4). P. Resnik and N. A. Smith. 2003. "The Web as a Parallel Corpus," Computational Linguistics 29(3). <http://www.aclweb.org/anthology/J03-3002>. D. Turcato, F. Popowich, P. McFetridge, D. Nicholson, and J. Toole. 2000. "Pre-Processing Closed Captions for Machine Translation," Proceedings of the ANLP/NAACL Workshop on Embedded Machine Translations Systems. D. Wu. 1996. "A Polynomial-Time Algorithm for Statistical Machine Translation," Proceedings of the Association for Computational Linguistics. <http://www.aclweb.org/anthology/P/P96/P96-1021>. J. Yang and E. D. Lange. 1998. "Systran on AltaVista: A User Study on Real-Time Machine Translation on the Internet," In D. Farwell et al. (eds.), Proc. AMTA. Copyright © 2006 David A. Smith |
|
| |
|
|
Top | Contents | |
| | |
|
D-Lib Magazine Access Terms and Conditions doi:10.1045/march2006-smith
|



{kind=link}
{kind=link}