M${^2}$Depth: Self-supervised Two-Frame Multi-camera Metric Depth Estimation

0
📉
Sign in to get full access
Overview
- This paper presents a novel depth estimation network called M²Depth that uses two-frame images from multiple cameras to predict reliable scale-aware surrounding depth in autonomous driving scenarios.
- Unlike previous methods, M²Depth combines spatial and temporal information to produce high-quality depth maps, and it also leverages neural priors to improve depth edge detection.
- Experiments on the nuScenes and DDAD datasets show that M²Depth achieves state-of-the-art performance in depth estimation for autonomous driving.
Plain English Explanation
M²Depth is a new depth estimation system that uses images from multiple cameras taken at slightly different time points to create accurate 3D depth information around a self-driving car. Previous methods either used images from a single camera at one time point or images from multiple cameras at the same time, but M²Depth combines both spatial and temporal information to get the best of both worlds.
The key innovation is the way M²Depth processes the input images. First, it creates cost volumes that capture the spatial and temporal relationships between the images. Then, it fuses these spatial and temporal cost volumes together to get a robust 3D representation. Finally, it combines this with neural priors, which are general patterns the model has learned, to refine the depth edges and distinguish the foreground from the background.
This produces depth maps that are highly accurate and can give the self-driving car a clear understanding of its 3D surroundings, which is crucial for safe navigation. The researchers showed that M²Depth outperforms previous state-of-the-art methods on standard autonomous driving benchmarks.
Technical Explanation
M²Depth is designed to leverage two-frame images from multiple cameras to estimate accurate, scale-aware depth in autonomous driving scenarios. Unlike prior work that used either single-view images at one time point or multi-view images at the same time point, M²Depth combines spatial and temporal information to produce high-quality depth maps.
The core of the M²Depth architecture is a spatial-temporal fusion module that integrates cost volumes constructed in the spatial and temporal domains. The spatial cost volume captures the geometric relationships between the multi-view images, while the temporal cost volume encodes the motion dynamics between the two time frames. Fusing these two cost volumes enables M²Depth to effectively leverage both spatial and temporal cues.
Additionally, M²Depth combines the neural prior from SAM features with its internal features to reduce ambiguity between the foreground and background, and to strengthen the depth edges. This helps M²Depth produce sharper, more reliable depth predictions.
Extensive experiments on the nuScenes and DDAD benchmarks demonstrate that M²Depth achieves state-of-the-art performance in depth estimation for autonomous driving, surpassing previous monocular and multi-view depth estimation methods.
Critical Analysis
The paper provides a thorough evaluation of M²Depth's performance, comparing it to a wide range of prior work on standard autonomous driving depth estimation benchmarks. The results clearly show the benefits of the spatial-temporal fusion approach and the incorporation of neural priors.
However, the paper does not deeply discuss the potential limitations or failure cases of the M²Depth system. For example, it is unclear how well the method would perform in challenging lighting conditions, such as very low light or strong shadows, or in complex urban environments with many occlusions. Additionally, the reliance on multiple camera inputs may limit the applicability of M²Depth to situations where only a single camera is available.
Further research could explore ways to make M²Depth more robust to diverse environmental conditions, or to adapt the approach to work with monocular or sparse multi-view inputs. Investigating the computational and memory requirements of the system would also be valuable, as efficiency is a key concern for real-world autonomous driving applications.
Conclusion
This paper presents a novel depth estimation network called M²Depth that leverages two-frame multi-camera inputs to predict reliable, scale-aware depth in autonomous driving scenarios. By fusing spatial and temporal cost volumes, and combining neural priors with internal features, M²Depth is able to outperform previous state-of-the-art depth estimation methods on standard benchmarks.
The ability to accurately estimate 3D depth from camera inputs is a critical capability for self-driving cars, enabling them to understand and navigate their surroundings safely. The innovations in M²Depth represent an important step forward in this area, and the techniques could potentially be applied to other computer vision tasks that require robust 3D perception.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📉
0
M${^2}$Depth: Self-supervised Two-Frame Multi-camera Metric Depth Estimation
Yingshuang Zou, Yikang Ding, Xi Qiu, Haoqian Wang, Haotian Zhang
This paper presents a novel self-supervised two-frame multi-camera metric depth estimation network, termed M${^2}$Depth, which is designed to predict reliable scale-aware surrounding depth in autonomous driving. Unlike the previous works that use multi-view images from a single time-step or multiple time-step images from a single camera, M${^2}$Depth takes temporally adjacent two-frame images from multiple cameras as inputs and produces high-quality surrounding depth. We first construct cost volumes in spatial and temporal domains individually and propose a spatial-temporal fusion module that integrates the spatial-temporal information to yield a strong volume presentation. We additionally combine the neural prior from SAM features with internal features to reduce the ambiguity between foreground and background and strengthen the depth edges. Extensive experimental results on nuScenes and DDAD benchmarks show M${^2}$Depth achieves state-of-the-art performance. More results can be found in https://heiheishuang.xyz/M2Depth .
Read more5/6/2024

0
Manydepth2: Motion-Aware Self-Supervised Monocular Depth Estimation in Dynamic Scenes
Kaichen Zhou, Jia-Wang Bian, Qian Xie, Jian-Qing Zheng, Niki Trigoni, Andrew Markham
Despite advancements in self-supervised monocular depth estimation, challenges persist in dynamic scenarios due to the dependence on assumptions about a static world. In this paper, we present Manydepth2, a Motion-Guided Cost Volume Depth Net, to achieve precise depth estimation for both dynamic objects and static backgrounds, all while maintaining computational efficiency. To tackle the challenges posed by dynamic content, we incorporate optical flow and coarse monocular depth to create a novel static reference frame. This frame is then utilized to build a motion-guided cost volume in collaboration with the target frame. Additionally, to enhance the accuracy and resilience of the network structure, we introduce an attention-based depth net architecture to effectively integrate information from feature maps with varying resolutions. Compared to methods with similar computational costs, Manydepth2 achieves a significant reduction of approximately five percent in root-mean-square error for self-supervised monocular depth estimation on the KITTI-2015 dataset. The code could be found: https://github.com/kaichen-z/Manydepth2
Read more9/24/2024
0
SM4Depth: Seamless Monocular Metric Depth Estimation across Multiple Cameras and Scenes by One Model
Yihao Liu, Feng Xue, Anlong Ming, Mingshuai Zhao, Huadong Ma, Nicu Sebe
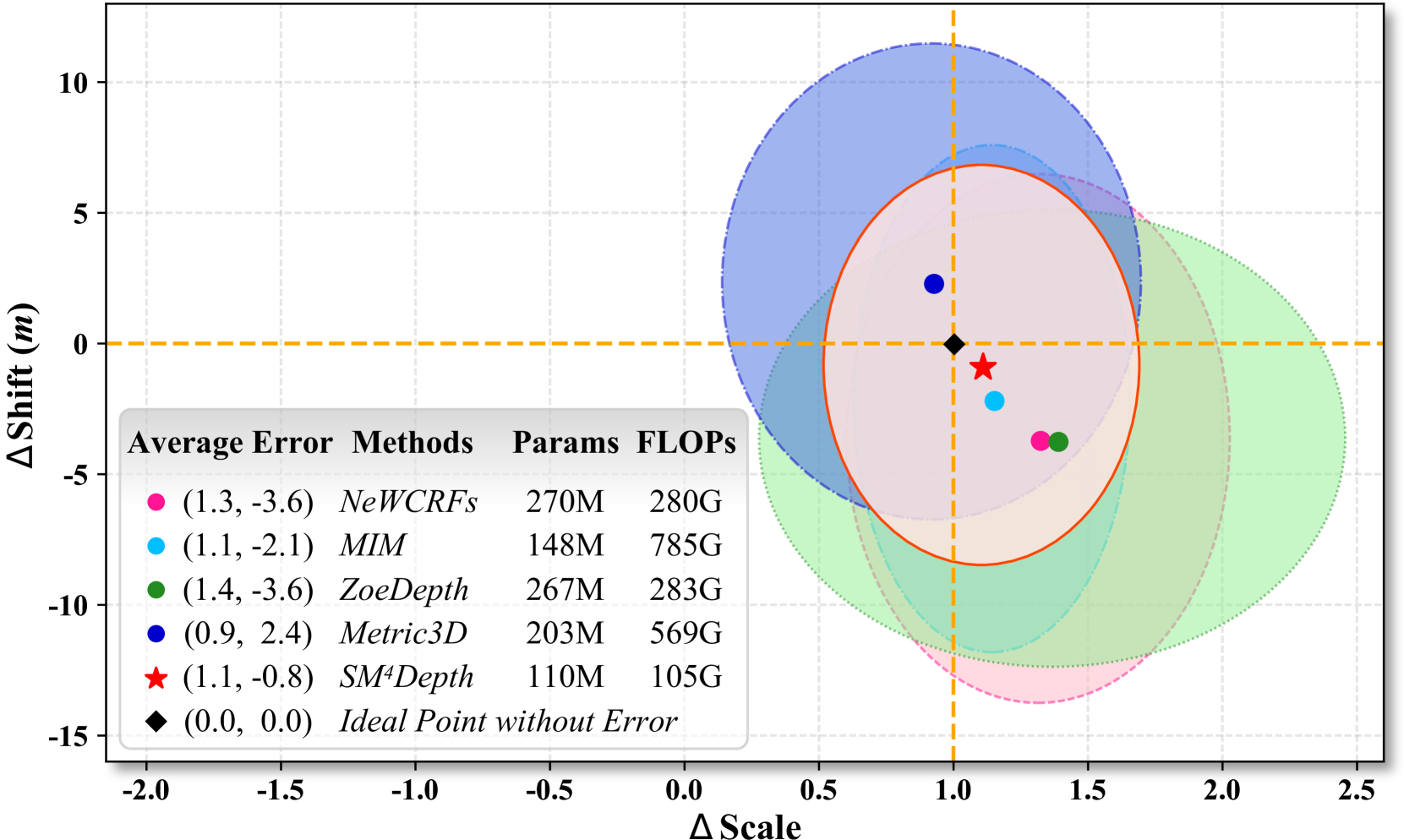
In the last year, universal monocular metric depth estimation (universal MMDE) has gained considerable attention, serving as the foundation model for various multimedia tasks, such as video and image editing. Nonetheless, current approaches face challenges in maintaining consistent accuracy across diverse scenes without scene-specific parameters and pre-training, hindering the practicality of MMDE. Furthermore, these methods rely on extensive datasets comprising millions, if not tens of millions, of data for training, leading to significant time and hardware expenses. This paper presents SM$^4$Depth, a model that seamlessly works for both indoor and outdoor scenes, without needing extensive training data and GPU clusters. Firstly, to obtain consistent depth across diverse scenes, we propose a novel metric scale modeling, i.e., variation-based unnormalized depth bins. It reduces the ambiguity of the conventional metric bins and enables better adaptation to large depth gaps of scenes during training. Secondly, we propose a divide and conquer solution to reduce reliance on massive training data. Instead of estimating directly from the vast solution space, the metric bins are estimated from multiple solution sub-spaces to reduce complexity. Additionally, we introduce an uncut depth dataset, BUPT Depth, to evaluate the depth accuracy and consistency across various indoor and outdoor scenes. Trained on a consumer-grade GPU using just 150K RGB-D pairs, SM$^4$Depth achieves outstanding performance on the most never-before-seen datasets, especially maintaining consistent accuracy across indoors and outdoors. The code can be found https://github.com/mRobotit/SM4Depth.
Read more8/16/2024

0
DoubleTake: Geometry Guided Depth Estimation
Mohamed Sayed, Filippo Aleotti, Jamie Watson, Zawar Qureshi, Guillermo Garcia-Hernando, Gabriel Brostow, Sara Vicente, Michael Firman
Estimating depth from a sequence of posed RGB images is a fundamental computer vision task, with applications in augmented reality, path planning etc. Prior work typically makes use of previous frames in a multi view stereo framework, relying on matching textures in a local neighborhood. In contrast, our model leverages historical predictions by giving the latest 3D geometry data as an extra input to our network. This self-generated geometric hint can encode information from areas of the scene not covered by the keyframes and it is more regularized when compared to individual predicted depth maps for previous frames. We introduce a Hint MLP which combines cost volume features with a hint of the prior geometry, rendered as a depth map from the current camera location, together with a measure of the confidence in the prior geometry. We demonstrate that our method, which can run at interactive speeds, achieves state-of-the-art estimates of depth and 3D scene reconstruction in both offline and incremental evaluation scenarios.
Read more7/16/2024