AWS Architecture Blog
Field Notes: Building a Data Service for Autonomous Driving Systems Development using Amazon EKS
Many aspects of autonomous driving (AD) system development are based on data that capture real-life driving scenarios. Therefore, research and development professionals working on AD systems need to handle an ever-changing array of interesting datasets composed from the real-life driving data. In this blog post, we address a key problem in AD system development, which is how to dynamically compose interesting datasets from real-life driving data and serve them at scale in near real-time.
The first challenge in composing large interesting datasets is high latency. If you have to wait for the entire dataset to be composed before you can start consuming the dataset, you may have to wait for several minutes, or even hours. This latency slows down AD system research and development. The second challenge is creating a data service that can cost-efficiently serve the dynamically composed datasets at scale. In this blog post, we propose solutions to both these challenges.
For the challenge of high latency, we propose dynamically composing the data sets as chunked data streams, and serving them using a Amazon FSx for Lustre high-performance file-system. Chunked data streams immediately solve the latency issue, because you do not need to compose the entire stream before it can be consumed. For the challenge of cost-efficiently serving the datasets at scale, we propose using Amazon EKS with auto-scaling features.
Overview of the Data Service Architecture
The data service described in this post dynamically composes and serves data streams of selected sensor modalities for a specified drive scene selected from the A2D2 driving dataset. The data stream is dynamically composed from the extracted A2D2 drive scene data stored in Amazon S3 object data store, and the accompanying meta-data stored in an Amazon Redshift data warehouse. While the data service described in this post uses the Robot Operating System (ROS), the data service can be easily adapted for use with other robotic systems.
The data service runs in Kubernetes Pods in an Amazon EKS cluster configured to use a Horizontal Pod Autoscaler and EKS Cluster Autoscaler. An Amazon Managed Service For Apache Kafka (MSK) cluster provides the communication channel between the data service, and the data clients. The data service implements a request-response paradigm over Apache Kafka topics. However, the response data is not sent back over the Kafka topics. Instead, the data service stages the response data in Amazon S3, Amazon FSx for Lustre, or Amazon EFS, as specified in the data client request, and only the location of the staged response data is sent back to the data client over the Kafka topics. The data client directly reads the response data from its staged location.
The data client running in a ROS enabled Amazon EC2 instance plays back the received data stream into ROS topics, whereby it can be nominally consumed by any ROS node subscribing to the ROS topics. The solution architecture diagram for the data service is shown in Figure 1.
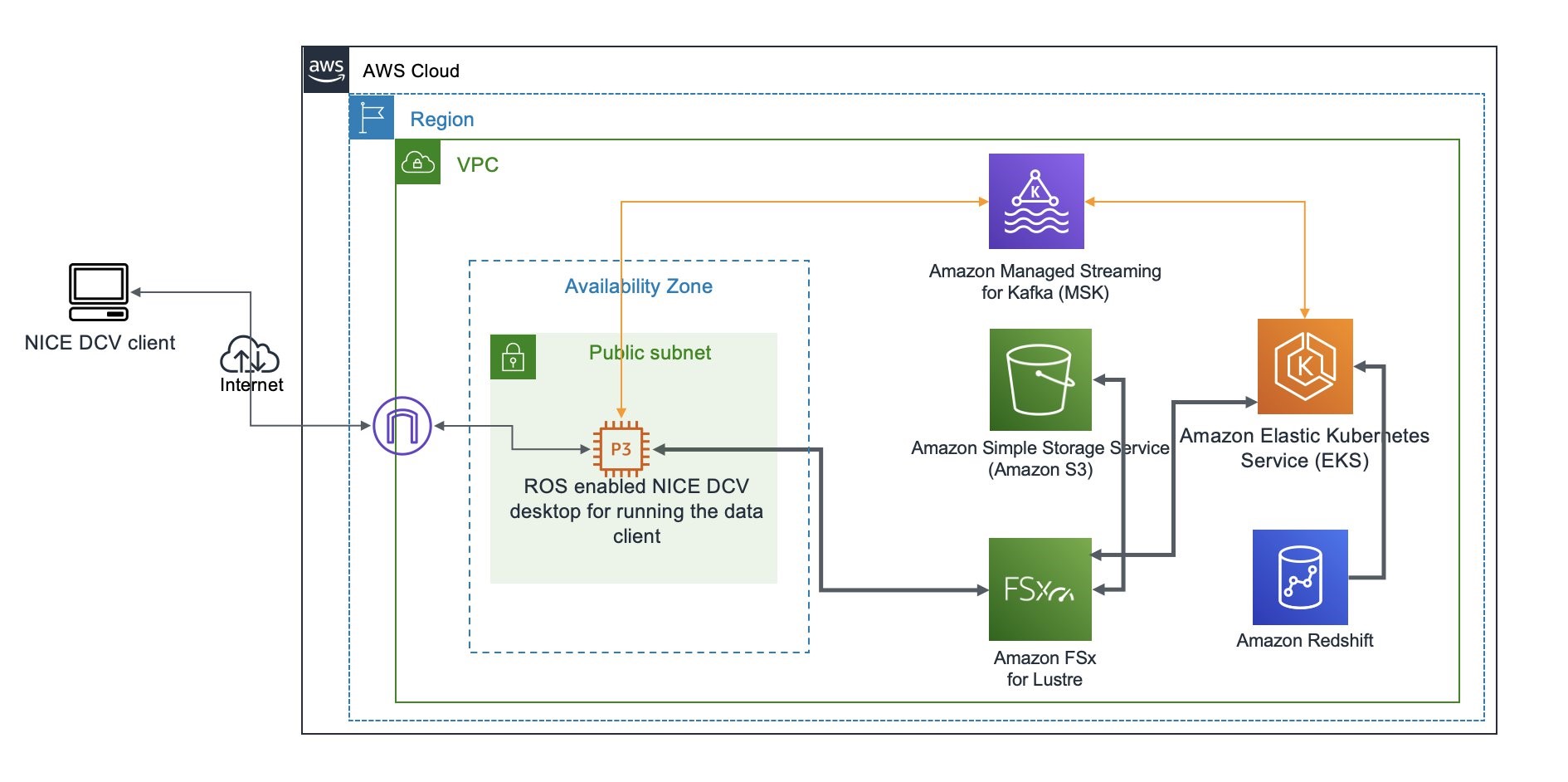
Figure 1 – Data service solution architecture with default configuration
Data Client Request
Imagine the data client wants to request drive scene data in ROS bag file format from A2D2 autonomous driving dataset for vehicle id a2d2, drive scene id 20190401145936, starting at timestamp 1554121593909500 (microseconds) , and stopping at timestamp 1554122334971448 (microseconds). The data client wants the response to include data only from the camera/front_left sensor encoded in sensor_msgs/Image ROS data type, and the lidar/front_left sensor encoded in sensor_msgs/PointCloud2 ROS data type. The data client wants the response data to be streamed back chunked in series of rosbag files, each file spanning 1000000 microseconds of the drive scene. The data client wants the chunked response rosbag files to be staged on a shared Amazon FSx for Lustre file system.
Finally, the data client wants the camera/front_left sensor data to be played back on /a2d2/camera/front_left ROS topic, and the lidar/front_left sensor data to be played back on /a2d2/lidar/front_left ROS topic.
The data client can encode such a data request using the following JSON object, and send it to the Kafka bootstrap servers b-1.msk-cluster-1:9092,b-2.msk-cluster-1:9092 on the Apache Kafka topic named a2d2.
{
"servers": "b-1.msk-cluster-1:9092,b-2.msk-cluster-1:9092",
"requests": [{
"kafka_topic": "a2d2",
"vehicle_id": "a2d2",
"scene_id": "20190401145936",
"sensor_id": ["lidar/front_left", "camera/front_left"],
"start_ts": 1554121593909500,
"stop_ts": 1554122334971448,
"ros_topic": {"lidar/front_left": "/a2d2/lidar/front_left",
"camera/front_left": "/a2d2/camera/front_left"},
"data_type": {"lidar/front_left": "sensor_msgs/PointCloud2",
"camera/front_left": "sensor_msgs/Image"},
"step": 1000000,
"accept": "fsx/multipart/rosbag",
"preview": false
}]
}
At any given time, one or more EKS pods in the data service are listening for messages on the Kafka topic a2d2. The EKS pod that picks the request message responds to the request by composing the requested data as a series of rosbag files, and staging them on FSx for Lustre, as requested in the "accept": "fsx/multipart/rosbag" field.
Each rosbag in the response is dynamically composed from the drive scene data stored in Amazon S3, using the meta-data stored in Amazon Redshift. Each rosbag contains drive scene data for a single time step. In the preceding example, the time step is specified as "step": 1000000 (microseconds).
Visualizing the Data Service Response
If a human is interested in visualizing the data response, one can use any ROS visualization tool. One such tool is rviz. This tool can be run on the ROS desktop. In the following screenshot, we show the visualization of the response using rviz tool for the example data request shown previously.

Figure 2 – Visualization of response using rviz tool
Dynamically Transforming the Coordinate Frames
The data service supports dynamically transforming the composed data from one coordinate frame to another frame. A typical use case is to transform the data from a sensor specific coordinate frame to AV (ego) coordinate frame. Such transformation request can be included in the data client request.
For example, imagine the data client wants to compose a data stream from all the LiDAR sensors, and transform the point cloud data into the vehicle’s coordinate frame. The example configuration c-config-lidar.json allows you to do that. Following is a visualization of the LiDAR point cloud data transformed to the vehicle coordinate frame and visualized in the rviz tool from a top-down perspective.

Figure 3 – Top-down rviz visualization of point-cloud data transformed to ego vehicle view
Walkthrough
In this walkthrough, we use the A2D2 autonomous driving dataset. The complete code for this walk-through and reference documentation is available in the associated Github repository. So before we get into the walk-through, clone the Github repository on your laptop using the Git clone command. Next, ensure these prerequisites are satisfied.
The approximate cost of the walk-through of this tutorial with default configuration is US $2,000. The actual cost may vary considerably based on actual configuration, and the duration used for the walk-through.
Configure the data service
To configure the data service, we need to create a new AWS CloudFormation stack in the AWS console using the cfn/mozart.yml template from the cloned repository on your laptop.
This template creates AWS Identity and Access Management (IAM) resources, so when you create the CloudFormation Stack using the console, in the review step, you must check I acknowledge that AWS CloudFormation might create IAM resources. The stack input parameters you must specify are the following:

For all other stack input parameters, default values are recommended during the first walkthrough. Review the complete list of all the template input parameters in the Github repository reference.
- Once the stack status in CloudFormation console is
CREATE_COMPLETE, find the ROS desktop instance launched in your stack in the Amazon EC2 console, and connect to the instance using SSH as userubuntu, using your SSH key pair. The ROS desktop instance is named as<name-of-stack>-desktop. - When you connect to the ROS desktop using SSH, and you see the message
"Cloud init in progress. Machine will REBOOT after cloud init is complete!!", disconnect and try later after about 20 minutes. The desktop installs the NICE DCV server on first-time startup, and reboots after the install is complete. - If the message
NICE DCV server is enabled!appears, run the commandsudo passwd ubuntuto set a new strong password for userubuntu. Now you are ready to connect to the desktop using the NICE DCV client. - Download and install the NICE DCV client on your laptop.
- Use the NICE DCV Client to login to the desktop as user
ubuntu - When you first login to the desktop using the NICE DCV client, you may be asked if you would like to upgrade the OS version. Do not upgrade the OS version.
Now you are ready to proceed with the following steps. For all the commands in this blog, we assume the working directory to be ~/amazon-eks-autonomous-driving-data-service on the ROS desktop.
If you used an IAM role to create the stack above, you must manually configure the credentials associated with the IAM role in the ~/.aws/credentials file with the following fields:
aws_access_key_id=
aws_secret_access_key=
aws_session_token=
If you used an IAM user to create the stack, you do not have to manually configure the credentials. In the working directory, run the command:
./scripts/configure-eks-auth.sh
When successfully running this command, the following confirmation appears AWS Credentials Removed.
Configure the EKS cluster environment
In this step, we configure the EKS cluster environment by running the command:
./scripts/setup-dev.sh
This step also builds and pushes the data service container image into Amazon ECR.
Prepare the A2D2 data
Before we can run the A2D2 data service, we need to extract the raw A2D2 data into your S3 bucket, extract the metadata from the raw data, and upload the metadata into the Redshift cluster. We execute these three steps using an AWS Step Functions state machine. To create and run the AWS Step Functions state machine, run the following command in the working directory:
./scripts/a2d2-etl-steps.sh
Note the executionArn of the state machine execution in the output of the previous command. To check the status of the execution, use following command, replacing executionArn below with your value:
aws stepfunctions describe-execution --execution-arn executionArn
The state machine execution time depends on many variable factors, and may take anywhere from 4 – 24 hours, or possibly longer. All the AWS Batch jobs started as part of the state machine automatically reattempt in case of failure.
Run the data service
The data service is deployed using a Helm Chart, and runs as a kubernetes deployment in EKS. To start the data service, execute the following command in the working directory:
kubectl get pods -n a2d2
Run the data service client
To visualize the response data requested by the A2D2 data client, we will use the rviz tool on the ROS desktop. Open a terminal on the desktop, and run rviz.
In the rviz tool, use File>Open Config to select /home/ubuntu/amazon-eks-autonomous-driving-data-service/a2d2/config/a2d2.rviz as the rviz config. You should notice that the rviz tool is now configured with two areas, one for visualizing image data, and the other for visualizing point cloud data.
To run the data client, open a new terminal on the desktop, and execute the following command in the root directory of the cloned Github repository on the ROS desktop:
python ./a2d2/src/data_client.py --config ./a2d2/config/c-config-ex1.json 1>/tmp/a.out 2>&1 &
After a brief delay, you should be able to preview the response data in the rviz tool. You can set "preview": false in the data client config file, ./a2d2/config/c-config-ex1.json, and rerun the preceding command to view the complete response. For maximum performance, pre-load S3 data to FSx for Lustre.
Hard reset of the data service
This step is for reference purposes. If at any time you need to do a hard reset of the data service, you can do so by executing:
helm delete a2d2-data-service
This will delete all data service EKS pods immediately. All in-flight service responses will be aborted. Because the connection between the data client and data service is asynchronous, the data clients may wait indefinitely, and you may need to cleanup the data client processes manually on the ROS desktop using operating system tools. Note, each data client instance spawns multiple Python processes. You may also want to cleanup /fsx/rosbag directory.
Clean Up
When you no longer need the data service, delete the AWS CloudFormation stack from the AWS CloudFormation console. Deleting the stack will shut down the desktop instance, and delete the EFS and FSx for Lustre file-systems created in the stack. The Amazon S3 bucket is not deleted.
Conclusion
In this post, we demonstrated how to build a data service that can dynamically compose near real-time chunked data streams at scale using EKS, Redshift, MSK, and FSx for Lustre. By using a data service, you increase agility, flexibility and cost-efficiency in AD system research and development.
Related reading: Field Notes: Deploy and Visualize ROS Bag Data on AWS using rviz and Webviz for Autonomous Driving