AWS Big Data Blog
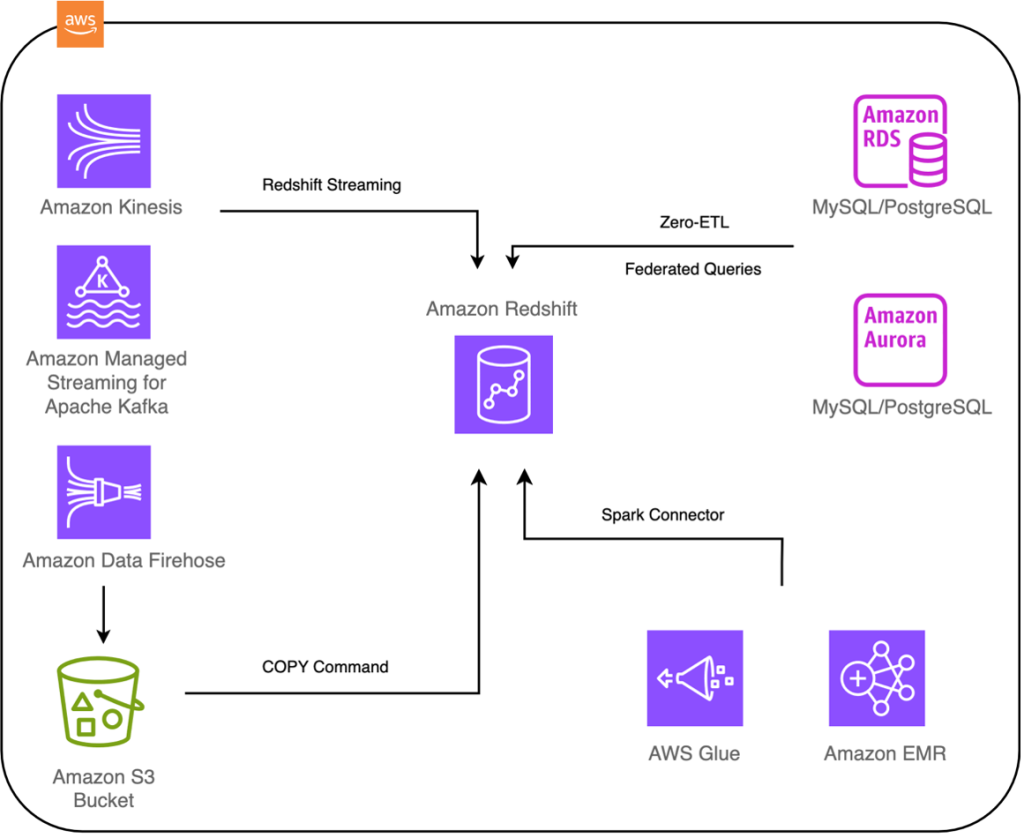
Amazon Redshift data ingestion options
Amazon Redshift, a warehousing service, offers a variety of options for ingesting data from diverse sources into its high-performance, scalable environment. Whether your data resides in operational databases, data lakes, on-premises systems, Amazon Elastic Compute Cloud (Amazon EC2), or other AWS services, Amazon Redshift provides multiple ingestion methods to meet your specific needs. The currently […]

Integrate sparse and dense vectors to enhance knowledge retrieval in RAG using Amazon OpenSearch Service
In this post, instead of using the BM25 algorithm, we introduce sparse vector retrieval. This approach offers improved term expansion while maintaining interpretability. We walk through the steps of integrating sparse and dense vectors for knowledge retrieval using Amazon OpenSearch Service and run some experiments on some public datasets to show its advantages.
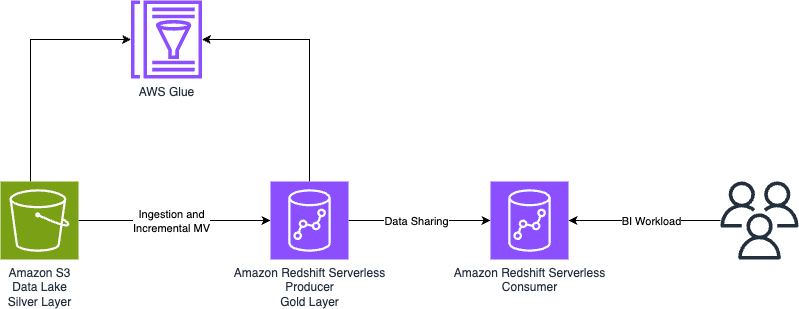
Use the AWS CDK with the Data Solutions Framework to provision and manage Amazon Redshift Serverless
In this post, we demonstrate how to use the AWS CDK and DSF to create a multi-data warehouse platform based on Amazon Redshift Serverless. DSF simplifies the provisioning of Redshift Serverless, initialization and cataloging of data, and data sharing between different data warehouse deployments.

Accelerate data integration with Salesforce and AWS using AWS Glue
To meet the demands of diverse data integration use cases, AWS Glue now supports SaaS connectivity for Salesforce. This enables users to quickly preview and transfer their customer relationship management (CRM) data, fetch the schema dynamically on request, and query the data. This post explores the new Salesforce connector for AWS Glue and demonstrates how to build a modern extract, transform, and load (ETL) pipeline with AWS Glue ETL scripts.

Integrate Tableau and Microsoft Entra ID with Amazon Redshift using AWS IAM Identity Center
This blog post provides a step-by-step guide to integrating IAM Identity Center with Microsoft Entra ID as the IdP and configuring Amazon Redshift as an AWS managed application. Additionally, you’ll learn how to set up the Amazon Redshift driver in Tableau, enabling SSO directly within Tableau Desktop.
Introducing job queuing to scale your AWS Glue workloads
Today, we are pleased to announce the general availability of AWS Glue job queuing. Job queuing increases scalability and improves the customer experience of managing AWS Glue jobs. With this new capability, you no longer need to manage concurrency of your AWS Glue job runs and attempt retries just to avoid job failures due to high concurrency. This post demonstrates how job queuing helps you scale your Glue workloads and how job queuing works.

Harness Zero Copy data sharing from Salesforce Data Cloud to Amazon Redshift for Unified Analytics – Part 1
In a previous post, we showed how Zero Copy data federation empowers businesses to access Amazon Redshift data within the Salesforce Data Cloud to enrich customer 360 data with operational data. This two-part series explores how analytics teams can access customer 360 data from Salesforce Data Cloud within Amazon Redshift to generate insights on unified data without the overhead of extract, transform, and load (ETL) pipelines. In this post, we cover data sharing between Salesforce Data Cloud and customers’ AWS accounts in the same AWS Region. Part 2 covers cross-Region data sharing between Salesforce Data Cloud and customers’ AWS accounts.

Attribute Amazon EMR on EC2 costs to your end-users
In this post, we share a chargeback model that you can use to track and allocate the costs of Spark workloads running on Amazon EMR on EC2 clusters. We describe an approach that assigns Amazon EMR costs to different jobs, teams, or lines of business. You can use this feature to distribute costs across various business units. This can assist you in monitoring the return on investment for your Spark-based workloads.

Copy and mask PII between Amazon RDS databases using visual ETL jobs in AWS Glue Studio
In this post, I’ll walk you through how to copy data from one Amazon Relational Database Service (Amazon RDS) for PostgreSQL database to another, while scrubbing PII along the way using AWS Glue. You will learn how to prepare a multi-account environment to access the databases from AWS Glue, and how to model an ETL data flow that automatically masks PII as part of the transfer process, so that no sensitive information will be copied to the target database in its original form.

Amazon EMR 7.1 runtime for Apache Spark and Iceberg can run Spark workloads 2.7 times faster than Apache Spark 3.5.1 and Iceberg 1.5.2
In this post, we explore the performance benefits of using the Amazon EMR runtime for Apache Spark and Apache Iceberg compared to running the same workloads with open source Spark 3.5.1 on Iceberg tables. Iceberg is a popular open source high-performance format for large analytic tables. Our benchmarks demonstrate that Amazon EMR can run TPC-DS […]