AWS Machine Learning Blog
Category: Amazon OpenSearch Service

Accelerate performance using a custom chunking mechanism with Amazon Bedrock
This post explores how Accenture used the customization capabilities of Knowledge Bases for Amazon Bedrock to incorporate their data processing workflow and custom logic to create a custom chunking mechanism that enhances the performance of Retrieval Augmented Generation (RAG) and unlock the potential of your PDF data.

How Deltek uses Amazon Bedrock for question and answering on government solicitation documents
This post provides an overview of a custom solution developed by the AWS Generative AI Innovation Center (GenAIIC) for Deltek, a globally recognized standard for project-based businesses in both government contracting and professional services. Deltek serves over 30,000 clients with industry-specific software and information solutions. In this collaboration, the AWS GenAIIC team created a RAG-based solution for Deltek to enable Q&A on single and multiple government solicitation documents. The solution uses AWS services including Amazon Textract, Amazon OpenSearch Service, and Amazon Bedrock.

Catalog, query, and search audio programs with Amazon Transcribe and Amazon Bedrock Knowledge Bases
Information retrieval systems have powered the information age through their ability to crawl and sift through massive amounts of data and quickly return accurate and relevant results. These systems, such as search engines and databases, typically work by indexing on keywords and fields contained in data files. However, much of our data in the digital […]

Implement web crawling in Amazon Bedrock Knowledge Bases
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading artificial intelligence (AI) companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI. With […]

Introducing guardrails in Amazon Bedrock Knowledge Bases
Amazon Bedrock Knowledge Bases is a fully managed capability that helps you securely connect foundation models (FMs) in Amazon Bedrock to your company data using Retrieval Augmented Generation (RAG). This feature streamlines the entire RAG workflow, from ingestion to retrieval and prompt augmentation, eliminating the need for custom data source integrations and data flow management. […]

Implement exact match with Amazon Lex QnAIntent
This post is a continuation of Creating Natural Conversations with Amazon Lex QnAIntent and Amazon Bedrock Knowledge Base. In summary, we explored new capabilities available through Amazon Lex QnAIntent, powered by Amazon Bedrock, that enable you to harness natural language understanding and your own knowledge repositories to provide real-time, conversational experiences. In many cases, Amazon […]

Implement serverless semantic search of image and live video with Amazon Titan Multimodal Embeddings
In today’s data-driven world, industries across various sectors are accumulating massive amounts of video data through cameras installed in their warehouses, clinics, roads, metro stations, stores, factories, or even private facilities. This video data holds immense potential for analysis and monitoring of incidents that may occur in these locations. From fire hazards to broken equipment, […]
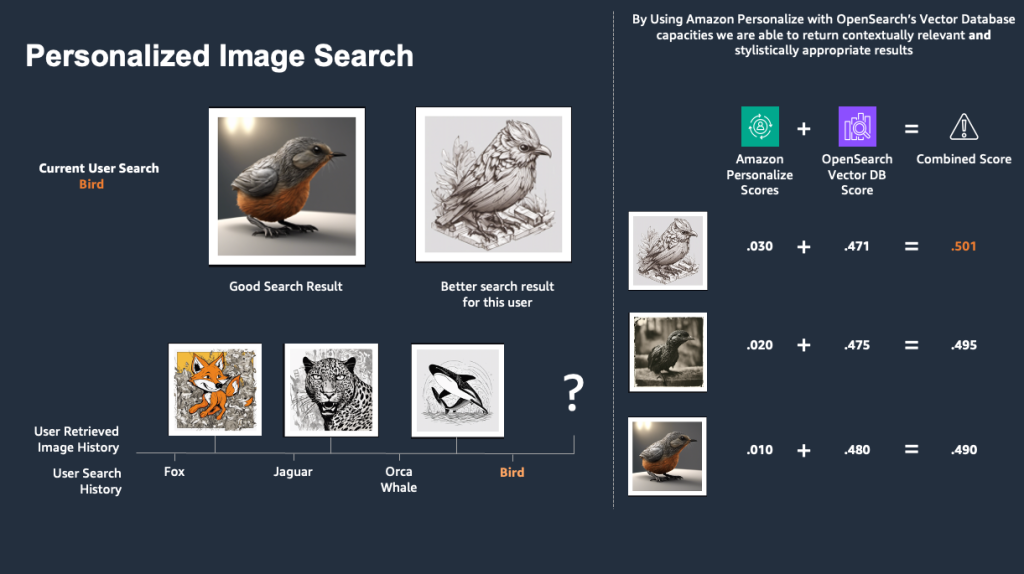
Enhance image search experiences with Amazon Personalize, Amazon OpenSearch Service, and Amazon Titan Multimodal Embeddings in Amazon Bedrock
A variety of different techniques have been used for returning images relevant to search queries. Historically, the idea of creating a joint embedding space to facilitate image captioning or text-to-image search has been of interest to machine learning (ML) practitioners and businesses for quite a while. Contrastive Language–Image Pre-training (CLIP) and Bootstrapping Language-Image Pre-training (BLIP) […]

How Veritone uses Amazon Bedrock, Amazon Rekognition, Amazon Transcribe, and information retrieval to update their video search pipeline
This post is co-written with Tim Camara, Senior Product Manager at Veritone. Veritone is an artificial intelligence (AI) company based in Irvine, California. Founded in 2014, Veritone empowers people with AI-powered software and solutions for various applications, including media processing, analytics, advertising, and more. It offers solutions for media transcription, facial recognition, content summarization, object […]

Build a contextual text and image search engine for product recommendations using Amazon Bedrock and Amazon OpenSearch Serverless
In this post, we show how to build a contextual text and image search engine for product recommendations using the Amazon Titan Multimodal Embeddings model, available in Amazon Bedrock, with Amazon OpenSearch Serverless.