AWS Machine Learning Blog
Monks boosts processing speed by four times for real-time diffusion AI image generation using Amazon SageMaker and AWS Inferentia2
This post is co-written with Benjamin Moody from Monks.
Monks is the global, purely digital, unitary operating brand of S4Capital plc. With a legacy of innovation and specialized expertise, Monks combines an extraordinary range of global marketing and technology services to accelerate business possibilities and redefine how brands and businesses interact with the world. Its integration of systems and workflows delivers unfettered content production, scaled experiences, enterprise-grade technology and data science fueled by AI—managed by the industry’s best and most diverse digital talent—to help the world’s trailblazing companies outmaneuver and outpace their competition.
Monks leads the way in crafting cutting-edge brand experiences. We shape modern brands through innovative and forward-thinking solutions. As brand experience experts, we harness the synergy of strategy, creativity, and in-house production to deliver exceptional results. Tasked with using the latest advancements in AWS services and machine learning (ML) acceleration, our team embarked on an ambitious project to revolutionize real-time image generation. Specifically, we focused on using AWS Inferentia2 chips with Amazon SageMaker to enhance the performance and cost-efficiency of our image generation processes..
Initially, our setup faced significant challenges regarding scalability and cost management. The primary issues were maintaining consistent inference performance under varying loads, while providing generative experience for the end-user. Traditional compute resources were not only costly but also failed to meet the low latency requirements. This scenario prompted us to explore more advanced solutions from AWS that could offer high-performance computing and cost-effective scalability.
The adoption of AWS Inferentia2 chips and SageMaker asynchronous inference endpoints emerged as a promising solution. These technologies promised to address our core challenges by significantly enhancing processing speed (AWS Inferentia2 chips were four times faster in our initial benchmarks) and reducing costs through fully managed auto scaling inference endpoints.
In this post, we share how we used AWS Inferentia2 chips with SageMaker asynchronous inference to optimize the performance by four times and achieve a 60% reduction in cost per image for our real-time diffusion AI image generation.
Solution overview
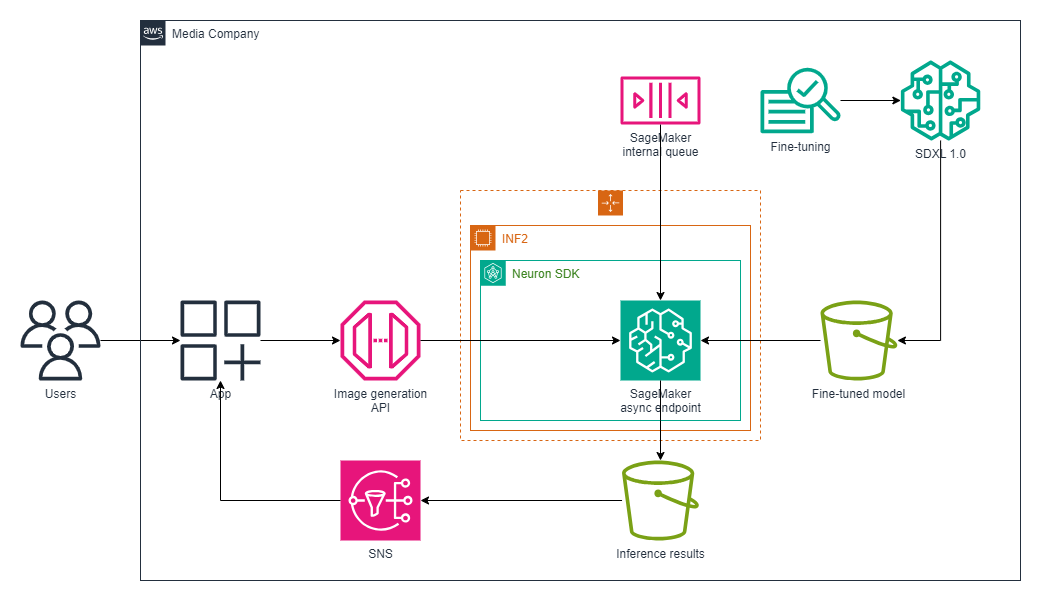
The combination of SageMaker asynchronous inference with AWS Inferentia2 allowed us to efficiently handle requests that had large payloads and long processing times while maintaining low latency requirements. A prerequisite was to fine-tune the Stable Diffusion XL model with domain-specific images which were stored in Amazon Simple Storage Service (Amazon S3). For this, we used Amazon SageMaker JumpStart. For more details, refer to Fine-Tune a Model.
The solution workflow consists of the following components:
- Endpoint creation – We created an asynchronous inference endpoint using our existing SageMaker models, using AWS Inferentia2 chips for higher price/performance.
- Request handling – Requests were queued by SageMaker upon invocation. Users submitted their image generation requests, where the input payload was placed in Amazon S3. SageMaker then queued the request for processing.
- Processing and output – After processing, the results were stored back in Amazon S3 in a specified output bucket. During periods of inactivity, SageMaker automatically scaled the instance count to zero, significantly reducing costs because charges only occurred when the endpoint was actively processing requests.
- Notifications – Completion notifications were set up through Amazon Simple Notification Service (Amazon SNS), notifying users of success or errors.
The following diagram illustrates our solution architecture and process workflow.
In the following sections, we discuss the key components of the solution in more detail.
SageMaker asynchronous endpoints
SageMaker asynchronous endpoints queue incoming requests to process them asynchronously, which is ideal for large inference payloads (up to 1 GB) or inference requests with long processing times (up to 60 minutes) that need to be processed as requests arrive. The ability to serve long-running requests enabled Monks to effectively serve their use case. Auto scaling the instance count to zero allows you to design cost-optimal inference in response to spiky traffic, so you only pay for when the instances are serving traffic. You can also scale the endpoint instance count to zero in the absence of outstanding requests and scale back up when new requests arrive.
To learn how to create a SageMaker asynchronous endpoint, attach auto scaling policies, and invoke an asynchronous endpoint, refer to Create an Asynchronous Inference Endpoint.
AWS Inferentia2 chips, which powered the SageMaker asynchronous endpoints, are AWS AI chips optimized to deliver high performance for deep learning inference applications at lowest cost. Integrated within SageMaker asynchronous inference endpoints, AWS Inferentia2 chips support scale-out distributed inference with ultra-high-speed connectivity between chips. This setup was ideal for deploying our large-scale generative AI model across multiple accelerators efficiently and cost-effectively.
In the context of our high-profile nationwide campaign, the use of asynchronous computing was key in managing peak and unexpected spikes in concurrent requests to our inference infrastructure, which was expected to be in the hundreds of concurrent requests per second. Asynchronous inference endpoints, like those provided by SageMaker, offer dynamic scalability and efficient task management.
The solution offered the following benefits:
- Efficient handling of longer processing times – SageMaker asynchronous inference endpoints are perfect for scenarios where each request might involve substantial computational work. These fully managed endpoints queue incoming inference requests and process them asynchronously. This method was particularly advantageous in our application, because it allowed the system to manage fluctuating demand efficiently. The ability to process requests asynchronously makes sure our infrastructure can handle large unexpected spikes in traffic without causing delays in response times.
- Cost-effective resource utilization – One of the most significant advantages of using asynchronous inference endpoints is their impact on cost management. These endpoints can automatically scale the compute resources down to zero in periods of inactivity, without the risk of dropping or losing requests as resources scale back up.
Custom scaling policies using Amazon CloudWatch metrics
SageMaker endpoint auto scaling behavior is defined through the use of a scaling policy, which helps us scale to multiple users using the application concurrently This policy defines how and when to scale resources up or down to provide optimal performance and cost-efficiency.
SageMaker synchronous inference endpoints are typically scaled using the InvocationsPerInstance metric, which helps determine event triggers based on real-time demands. However, for SageMaker asynchronous endpoints, this metric isn’t available due to their asynchronous nature.
We encountered challenges with alternative metrics such as ApproximateBacklogSizePerInstance because they didn’t meet our real-time requirements. The inherent delay in these metrics resulted in unacceptable latency in our scaling processes.
Consequently, we sought a custom metric that could more accurately reflect the real-time load on our SageMaker instances.
Amazon CloudWatch custom metrics provide a powerful tool for monitoring and managing your applications and services in the AWS Cloud.
We had previously established a range of custom metrics to monitor various aspects of our infrastructure, including a particularly crucial one for tracking cache misses during image generation. Due to the nature of asynchronous endpoints, which don’t provide the InvocationsPerInstance metric, this custom cache miss metric became essential. It enabled us to gauge the number of requests contributing to the size of the endpoint queue. With this insight into the number of requests, one of our senior developers began to explore additional metrics available through CloudWatch to calculate the asynchronous endpoint capacity and utilization rate. We used the following calculations:
InferenceCapacity= (CPU utilization * 60) / (InferenceTimeInSeconds*InstanceGPUCount)- Number of inference requests = (served from cache + cache misses)
- Usage rate = (number of requests) / (
InferenceCapacity)
The calculations included the following variables:
- CPU utilization – Represents the average CPU utilization percentage of the SageMaker instances (
CPUUtilizationCloudWatch metric). It provides a snapshot of how much CPU resources are currently being used by the instances. - InferenceCapacity – The total number of inference tasks that the system can process per minute, calculated based on the average CPU utilization and scaled by the number of GPUs available (inf2.48xlarge has 12 GPUs). This metric provides an estimate of the system’s throughput capability per minute.
- Multiply by 60 / Divide by InferenceTimeInSeconds – This step effectively adjusts the
CPUUtilizationmetric to reflect how it translates into jobs per minute, assuming each job takes 10 seconds. Therefore, (CPU utilization * 60) / 10 represents the theoretical maximum number of jobs that can be processed in one minute based on current or typical CPU utilization. - Multiply by 12 – Because the inf2.48xlarge instance has 12 GPUs, this multiplication provides a total capacity in terms of how many jobs all GPUs can handle collectively in 1 minute.
- Multiply by 60 / Divide by InferenceTimeInSeconds – This step effectively adjusts the
- Number of inference requests (served from cache + cache misses) – We monitor the total number of inference requests processed, distinguishing between those served from cache and those requiring real-time processing due to cache misses. This helps us gauge the overall workload.
- Usage rate (number of inference requests) / (InferenceCapacity) – This formula determines the rate of resource usage by comparing the number of operations that invoke new tasks (number of requests) to the total inference capacity (
InferenceCapacity).
A higher InferenceCapacity value suggests that we have either scaled up our resources or that our instances are under-utilized. Conversely, a lower capacity value could indicate that we’re reaching our capacity limits and might need to scale out to maintain performance.
Our custom usage rate metric quantifies the usage rate of available SageMaker instance capacity. It’s a composite measure that factors in both the image generation tasks that weren’t served from cache and those that resulted in a cache miss, relative to the total capacity metric. The usage rate is intended to provide insights into how much of the total provisioned SageMaker instance capacity is actively being used for image generation operations. It serves as a key indicator of operational efficiency and helps identify the workload’s operational demands.
We then used the usage rate metric as our auto scaling trigger metric. The use of this trigger in our auto scaling policy made sure SageMaker instances were neither over-provisioned nor under-provisioned. A high value for usage rate might indicate the need to scale up resources to maintain performance. A low value, on the other hand, could signal under-utilization, indicating a potential for cost optimization by scaling down resources.
We applied our custom metrics as triggers for a scaling policy:
Deployment on AWS Inferentia2 chips
The integration of AWS Inferentia2 chips into our SageMaker inference endpoints not only resulted in a four-times increase in inference performance for our finely-tuned Stable Diffusion XL model, but also significantly enhanced cost-efficiency. Specifically, SageMaker instances powered by these chips reduced our deployment costs by 60% compared to other comparable instances on AWS. This substantial reduction in cost, coupled with improved performance, underscores the value of using AWS Inferentia2 for intensive computational tasks such as real-time diffusion AI image generation.
Given the importance of swift response times for our specific use case, we established an acceptance criterion of single digit second latency.
SageMaker instances equipped with AWS Inferentia2 chips successfully optimized our infrastructure to deliver image generation in just 9.7 seconds. This enhancement not only met our performance requirements at a low cost, but also provided a seamless and engaging user experience owing to the high availability of Inferentia2 chips.
The effort to integrate with the Neuron SDK also proved highly beneficial. The optimized model not only met our performance criteria, but also enhanced the overall efficiency of our inference processes.
Results and benefits
The implementation of SageMaker asynchronous inference endpoints significantly enhanced our architecture’s ability to handle varying traffic loads and optimize resource utilization, leading to marked improvements in performance and cost-efficiency:
- Inference performance – The AWS Inferentia2 setup processed an average of 27,796 images per instance per hour, giving us 2x improvement in throughput over comparable accelerated compute instances.
- Inference savings – In addition to performance enhancements, the AWS Inferentia2 configurations achieved a 60% reduction in cost per image compared to the original estimation. The cost for processing each image with AWS Inferentia2 was $0.000425. Although the initial requirement to compile models for the AWS Inferentia2 chips introduced an additional time investment, the substantial throughput gains and significant cost reductions justified this effort. For demanding workloads that necessitate high throughput without compromising budget constraints, AWS Inferentia2 instances are certainly worthy of consideration.
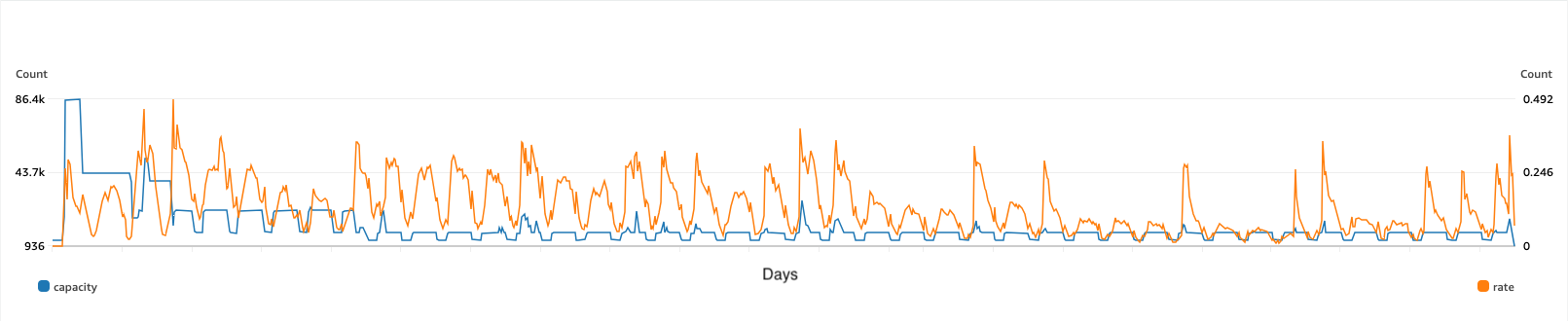
- Smoothing out traffic spikes – We effectively smoothed out spikes in traffic to provide continual real-time experience for end-users. As shown in the following figure, the SageMaker asynchronous endpoint auto scaling and managed queue is preventing significant drift from our goal of single digit second latency per image generation.

- Scheduled scaling to manage demand – We can scale up and back down on schedule to cover more predictable traffic demands, reducing inference costs while supplying demand. The following figure illustrates the impact of auto scaling reacting to unexpected demand as well as scaling up and down on a schedule.
Conclusion
In this post, we discussed the potential benefits of applying SageMaker and AWS Inferentia2 chips within a production-ready generative AI application. SageMaker fully managed asynchronous endpoints provide an application time to react to both unexpected and predictable demand in a structured manner, even for high-demand applications such as image-based generative AI. Despite the learning curve involved in compiling the Stable Diffusion XL model to run on AWS Inferentia2 chips, using AWS Inferentia2 allowed us to achieve our demanding low-latency inference requirements, providing an excellent user experience, all while remaining cost-efficient.
To learn more about SageMaker deployment options for your generative AI use cases, refer to the blog series Model hosting patterns in Amazon SageMaker. You can get started with hosting a Stable Diffusion model with SageMaker and AWS Inferentia2 by using the following example.
Discover how Monks serves as a comprehensive digital partner by integrating a wide array of solutions. These encompass media, data, social platforms, studio production, brand strategy, and cutting-edge technology. Through this integration, Monks enables efficient content creation, scalable experiences, and AI-driven data insights, all powered by top-tier industry talent.
About the Authors
 Benjamin Moody is a Senior Solutions Architect at Monks. He focuses on designing and managing high-performance, robust, and secure architectures, utilizing a broad range of AWS services. Ben is particularly adept at handling projects with complex requirements, including those involving generative AI at scale. Outside of work, he enjoys snowboarding and traveling.
Benjamin Moody is a Senior Solutions Architect at Monks. He focuses on designing and managing high-performance, robust, and secure architectures, utilizing a broad range of AWS services. Ben is particularly adept at handling projects with complex requirements, including those involving generative AI at scale. Outside of work, he enjoys snowboarding and traveling.
 Karan Jain is a Senior Machine Learning Specialist at AWS, where he leads the worldwide Go-To-Market strategy for Amazon SageMaker Inference. He helps customers accelerate their generative AI and ML journey on AWS by providing guidance on deployment, cost-optimization, and GTM strategy. He has led product, marketing, and business development efforts across industries for over 10 years, and is passionate about mapping complex service features to customer solutions.
Karan Jain is a Senior Machine Learning Specialist at AWS, where he leads the worldwide Go-To-Market strategy for Amazon SageMaker Inference. He helps customers accelerate their generative AI and ML journey on AWS by providing guidance on deployment, cost-optimization, and GTM strategy. He has led product, marketing, and business development efforts across industries for over 10 years, and is passionate about mapping complex service features to customer solutions.
 Raghu Ramesha is a Senior Gen AI/ML Specialist Solutions Architect with AWS. He focuses on helping enterprise customers build and deploy AI/ ML production workloads to Amazon SageMaker at scale. He specializes in generative AI, machine learning, and computer vision domains, and holds a master’s degree in Computer Science from UT Dallas. In his free time, he enjoys traveling and photography.
Raghu Ramesha is a Senior Gen AI/ML Specialist Solutions Architect with AWS. He focuses on helping enterprise customers build and deploy AI/ ML production workloads to Amazon SageMaker at scale. He specializes in generative AI, machine learning, and computer vision domains, and holds a master’s degree in Computer Science from UT Dallas. In his free time, he enjoys traveling and photography.
 Rupinder Grewal is a Senior Gen AI/ML Specialist Solutions Architect with AWS. He currently focuses on model serving and MLOps on SageMaker. Prior to this role, he worked as a Machine Learning Engineer building and hosting models. Outside of work, he enjoys playing tennis and biking on mountain trails.
Rupinder Grewal is a Senior Gen AI/ML Specialist Solutions Architect with AWS. He currently focuses on model serving and MLOps on SageMaker. Prior to this role, he worked as a Machine Learning Engineer building and hosting models. Outside of work, he enjoys playing tennis and biking on mountain trails.
 Parag Srivastava is a Senior Solutions Architect at AWS, where he has been helping customers in successfully applying generative AI to real-life business scenarios. During his professional career, he has been extensively involved in complex digital transformation projects. He is also passionate about building innovative solutions around geospatial aspects of addresses.
Parag Srivastava is a Senior Solutions Architect at AWS, where he has been helping customers in successfully applying generative AI to real-life business scenarios. During his professional career, he has been extensively involved in complex digital transformation projects. He is also passionate about building innovative solutions around geospatial aspects of addresses.