
パートナーアライアンス部 森田です。有料会員の獲得施策や、それに関わるサービス内動線の最適化を担当しています。 記事の対象 仮説検証を通じて何かを改善をしたいと思っている人 仮説検証の際に「どれくらいのデータを集めたら良いか」分からない人 はじめに 仮説検証とは「仮説を立て、それを証明するためのデータを集め、真偽を確かめること」です。今回は仮説検証を行う際の手順と、その検証に必要なサンプルサイズの考え方を説明します。サンプルサイズの話のみ関心があるかたは、前半を飛ばし「サンプルサイズの決め方」を読んでください。 目次 記事の対象 はじめに 目次 仮説検証のつくりかた 1. 仮説をたてる 2. 施策/KPIを考える 3. 仮説検証後のアクションを決める 4. 対象を決める 5. サンプルサイズを計算する サンプルサイズの決め方 答えを先に サンプルサイズを決める二つの要素 「二つの平均値」と
統計に関するZAORIKUのブックマーク (148)
-
 ZAORIKU 2019/01/06
ZAORIKU 2019/01/06
-
Microsoft Word - EffectSize_KELES31.doc
『英語教育研究』31 (2008), 57-66. - 57 - 研究論文における効果量の報告のために ―基礎的概念と注意点― 水本 篤 (流通科学大学) 竹内 理 (関西大学) Basics and Considerations for Reporting Effect Sizes in Research Papers Atsushi MIZUMOTO (University of Marketing and Distribution Sciences) Osamu TAKEUCHI (Kansai University) キーワード: 効果量,統計的検定,検定力,サンプルサイズ,メタ分析 Keywords: effect size, statistical testing, power, sample size, meta‐analysis SUMMARY Reporting effe
-
The Death of the Statistical Tests of Hypotheses - DataScienceCentral.com
Home » UncategorizedThe Death of the Statistical Tests of Hypotheses Vincent GranvilleAugust 3, 2016 at 8:00 am Some foundations of statistical science have been questioned recently, especially the use and abuse of p-values. See also this article published in FiveThirtyEight.com. Statistical tests of hypotheses rely on p-values and other mysterious parameters and concepts that only the initiated c

-
Choosing the Correct Statistical Test in SAS, Stata, SPSS and R
The following table shows general guidelines for choosing a statistical analysis. We emphasize that these are general guidelines and should not be construed as hard and fast rules. Usually your data could be analyzed in multiple ways, each of which could yield legitimate answers. The table below covers a number of common analyses and helps you choose among them based on the number of dependent var
-
ベイズ統計の最高事後密度区間を Java で求める
ベイズ統計における「信用区間」の一つである最高事後密度区間 (Highest posterior density interval, HPDI) について、その区間を求める方法を調べて Java で実装してみたメモです。 最高事後密度区間とは? そもそもの 最高事後密度区間 を自分自身がちゃんと理解していないので、まずは定義を確認しておきます。 Web 上の日本語文献だと「確率分布の密度が高い部分の n%」みたいなゆるふわな説明が多かったので、あえて Cross Validated の What is a Highest Density Region (HDR)? の回答 を参考にしてみると、その定義は以下のようになるようです。 確率変数 $X$ の確率分布 $P(X)$ について、その確率密度関数を $f(x)$ とする。この $f(x)$ に対し、値が $f_\alpha$ 以上となる

-
一般社団法人 日本計量生物学会 The Biometric Society of Japan
2024.10.302024年度計量生物セミナーのご案内picture_as_pdf 2024.09.13 2025年度統計関連学会連合大会のお知らせ(第一報)picture_as_pdf 2025年度統計関連学会連合大会(関西大学 千里山キャンパス)のお知らせです。 2025年度統計関連学会連合大会について(開催日程:2025年9月7日(日)~11日(木)、開催方式:ハイブリッド方式(対面・オンライン併用)<検討中>)、各種企画について、一般講演や大会参加についてです。 詳細はPDFをご確認下さい。 2024.08.23ニュースレターNo.145picture_as_pdfを発行しました 2024.08.07 2024年度統計関連学会連合大会のお知らせ(第四報)picture_as_pdf 2024年度統計関連学会連合大会(東京理科大学神楽坂キャンパス)のお知らせです。 講演申込開始のお
-
-
統計の初心者のつまずきやすい点が分かる『統計的方法のしくみ』|Colorless Green Ideas
『統計的方法のしくみ』という本は、統計の初心者のつまずきやすい点をうまく説明してくれる。統計の教科書と併用する副読本として利用すると効果的であろう。 つまずきやすい点を解説した副読本 割とどんな分野でもそうだと思うが、初心者がつまずきやすい場所というものがある。例えば、小学校の算数の勉強を考えてみると、九九が覚えられないとか、割合の意味をうまく理解できないといったところがつまずきやすい場所になるだろう。 統計の勉強のときにも初心者がつまずきやすい場所がある。例えば、統計の教科書に出てくる Σ という記号の意味が分からなかったり、統計的仮説検定で用いられる「P 値」という概念を誤解したりすることがある。 今回紹介する『統計的方法のしくみ』という本は、こうした統計の初心者がつまずきやすいことについて解説をしている書籍である。 永田靖.(1996). 『統計的方法のしくみ』東京:日科技連出版社.

-
-
「1000年に1度」の意味:頻度と確率を混同しちゃダメ! - Take a Risk:林岳彦の研究メモ
今回の大地震を巡って、ときおり頻度と確率が混同されているように思われるので、整理のためのメモをしておきたいと思います。 「1000年に1度」=「今年1年間に大地震が起きる確率が1/1000」? 今回の大地震は869年に起きた貞観地震以来の規模ということで、「1000年に1度の」と形容されることがあります。では、このような「1000年の1度の」大地震を、確率論的リスク分析のモデルに取り入れたい場合にはどのように記述すればよいでしょうか? 「今年1年間に大地震が起きる確率が1/1000」というモデリングでもよいでしょうか? 実は、それではダメです。 「頻度イコール確率」と短絡してはいけない 「頻度イコール確率」という解釈が成り立つためには、少なくとも以下の二つの条件が満たされている必要があります。 (1)充分に長い系列の中で頻度が観測されている (2)事象が独立に起こる (1)の方は、厳密なこ
-
最古企業は大阪の「1400歳超」!? 日本企業の年齢 | ZUNNY インフォグラフィック・ニュース
昨今では、大企業でも経営難に陥るなど「大企業=安泰」とは言えない景況になっている。中小企業より大企業、法人より個人経営の方が寿命は長いというデータもあるが、都道府県によっても違いがあるようだ。さらに、創業から1000年以上経つ超長寿企業があることも判明! 日本企業の「年齢」にまつわるトリビアを紹介したい。 企業の平均年齢が一番高いのは山形県で「41.7歳」。次点に京都府、新潟県と続く。城下町として発展した地域、港があり昔から貿易で栄えた地域、また、戦争の被害が少なかった地域などが上位に挙がっている印象だ。 創業100年を超える長寿企業の輩出率では京都府が1位、企業数では東京都が1位となっている。東京都や神奈川県など都市部の企業平均年齢が低いのは、新たに創業する企業も多いことが要因のようだ。なお、大阪府にある「金剛組」は、現存する世界最古の企業ともいわれている。 (文=吉田良雄 デザイン=Z

-
Spurious Correlations
correlation is not causation random · discover · next page → don't miss spurious scholar, where each of these is an academic paper View details about correlation #1,402 The Big Bang Theory: A Procreative Catalyst? An Examination of the Relationship between Viewership of a Pop Culture Phenomenon and Online Searches for Baby-Making Techniques Show GenAI's made-up explanation As more people tuned in

-
Biclustering - 驚異のアニヲタ社会復帰の予備
読んだ。 Bioinformatics. 2016 Oct 6. Nucleic Acids Res. 2009 Aug;37(15):e101. Biclustering をするQUBIC という手法をR で実装しました。クッソ速いです、とのこと。 そもそもbiclustering とはなにかというと、ヒートマップクラスタリングをするときに行もしくは列でクラスタリングをするが、行と列の一部を使ったsubcluster というものができて、それが生物学的に意味があるのではないかという感じのやり方。 ベイズ的にbiclustering をするbaybi パッケージもあるらしい。 cran にないっぽいのでこちら を参考に install.packages("baybi", repos="http://R-Forge.R-project.org") 3次元で上からクラスタリングを描いている上の

-
Spurious Correlations
correlation is not causation random · discover · next page → don't miss spurious scholar, where each of these is an academic paper View details about correlation #5,844 The Rock & The Undead: A Correlation Study Between Dwayne Johnson's Movie Appearances and Google Searches for 'Zombies' Show GenAI's made-up explanation The Rock's blockbuster movies were so electrifying, they reanimated an interes
-
「知恵ノート」は終了いたしました - Yahoo!知恵袋
平素よりYahoo!知恵袋をご利用いただきありがとうございます。 2017年11月30日をもちまして、「知恵ノート」機能の提供を終了いたしました。 これまでご利用いただきました皆様にはご迷惑をおかけすることとなり、誠に申し訳ございません。 長年のご愛顧、心よりお礼申しあげます。 引き続き、Yahoo!知恵袋の「Q&A」機能をご利用ください。 Yahoo!知恵袋トップ 知恵ノートサービス終了のお知らせ プライバシー - 利用規約 - メディアステートメント - ガイドライン - ご意見・ご要望 - ヘルプ・お問い合わせ JASRAC許諾番号:9008249113Y38200 Copyright (C) 2018 Yahoo Japan Corporation. All Rights Reserved.

-
経済指標ダッシュボード
日本経済の動向を把握するのに役に立つ経済指標を一覧できます。国内総生産(GDP)成長率や物価上昇率など政府・日銀が注目する指標から金融市場の指標まで、データやグラフの保存もできます。

-
2016年春アニメで「一番見られた作品」は? なぜか東芝が公開
http://m.timeon.jp/analytics/anime-2016sp/ 本文内には「2016年春 (4~6月期) に新たに放送されたアニメ番組 (主要 36作品) の、レグザ使用者での見られ方をまとめてみました。」という記載が。 ……ということで、アニメの視聴に関する、ものすごく詳細なデータが掲載されています。ちなみに、関東で稼働しているネットワーク対応のレグザのうち、約10万台の情報を集計・分類した結果をまとめたものだそうです。“視聴率調査”みたいなものですが、単純な視聴率だけではなくざっくりというと、放送中のアニメを「生でみた人」、HDDなどに録画して「後から再生してみた人」、とりあえず「予約だけはしていた人」の3つに分類して集計されています。 その情報から“平均総接触率”の高低、“ライブ率と再生率”の相関、接触率の多寡でグループ分けして、“各回の見られ方”がどう推移して
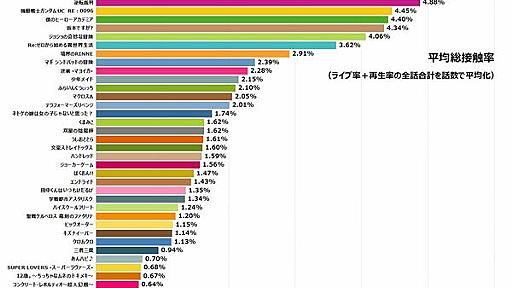
-
オンラインで無料で読める統計書プラス32冊|Colorless Green Ideas
はじめに 数年前に「オンラインで無料で読める統計書22冊」という記事を書いた。タイトルにあるように、オンラインで無料で読める統計書として、入門者向けから高度なものまで合わせて22冊紹介した。 その後、オンラインで無料で読める統計書をさらに発掘したので、ここに紹介しておきたい。今回新しく紹介するのは、32冊である。「オンラインで無料で読める統計書22冊」と合わせてご覧いただきたい。 統計学の入門 まずは、統計学を始めて学ぶ人に向けて書かれた書籍を紹介しよう。 村上正康・安田正實.(1989). 『統計学演習』東京:培風館. 統計学を始めて学ぶ人のための入門書。 記述統計、確率分布、推定・検定の基礎、簡単な線形回帰といった内容を扱っている。入門書としてはオーソドックスなところを扱っていると言えよう。 中澤港.(2003).『Rによる統計解析の基礎』東京:ピアソン・エデュケーション. 統計学を始

-
Apache Hadoop YARN: Avoiding 6 Time-Consuming "Gotchas" | Cloudera Developer Blog
For the inaugural episode of Women Leaders in Technology on The AI Forecast, we welcomed Kari Briski – Vice President AI Software Product Management at NVIDIA. Kari shared the stories and strategies that inform her leadership style (like GSD or “getting stuff done”), what it means to trust your instinct, and the advice she gives to young women embarking on a career in technology and to women furth

-
多重比較
多重比較 multiple comparison (Post-hoc test) 検定の多重性の理解は重要! 1)多重比較とは 3つ以上の群で、個々の群と群を検定する場合に、有意水準を上げずに(第一種過誤率を保ったまま)行う検定法。 ANOVA(分散分析)で、有意差があった場合にどの群とどの群に有意差があるか調べる場合に使用されることが多い。 2)多重性とは ひとつの実験系で、統計的検定を繰り返すことをいう。 検定を繰り返すことにより、1回のみ検定を行った場合より第一種過誤率が大きくなってしまう。 すなわち、有意差がでる可能性が高くなってしまう。 3)なぜ、多重比較が必要か 分散分析のところでも述べたが、多群の比較をおこなうのに例えば2標本t検定を繰り返すと有意水準があまくなってしまうのである。 A,B,Cの3群について、A-B,A-C,B-Cの すべてについて2標本t検定を行


公式Twitter
- @HatenaBookmark
リリース、障害情報などのサービスのお知らせ
- @hatebu
最新の人気エントリーの配信
キーボードショートカット一覧
j次のブックマーク
k前のブックマーク
lあとで読む
eコメント一覧を開く
oページを開く


Copyright © 2005-2025 Hatena. All Rights Reserved.
設定を変更しました