
nlpに関するclavierのブックマーク (154)
-
 clavier 2024/12/19
clavier 2024/12/19
-
【GraphRAG プロジェクトを立ち上げます】ナレッジグラフとLLMで「発想力を持つAI」の実現へ|Stockmark
こんにちは。ストックマークのリサーチャーの広田です。今日は私が新しく立ち上げた GraphRAG プロジェクトの仲間を募集するために、GraphRAG プロジェクトについて紹介したいと思います。 広田航 Researcher 大阪大学大学院情報科学研究科を卒業後、米国に渡り Megagon Labs で Conversational AI や entity matching の研究を行う。その後帰国しストックマークに参画。現在はナレッジグラフ構築や LLM を活用した情報抽出の研究を行う。 まず GraphRAG プロジェクトの背景を紹介したいと思います。 ストックマークは「価値創造の仕組みを再発明し人類を前進させる」というミッションを掲げ、「AIと人による新しい価値創造プロセスを発明する」を目指して Research Unit を組成しています。情報の量が急激に増えている現代において、情

-
2023-24年(上期)のKaggleコンペから学ぶ、NLPコンペの精度の上げ方
LLM関係のコンペがかなり多かったですね。 ベースラインノートブック 最近はほとんどのコンペがHuggingfaceのTrainerを使って学習が行われます(テーブルデータにおけるscikit-learnのような立ち位置です)。ChrisのNotebookは非常にシンプルにまとまっているのでぜひ参考にしてください。 分類(+RAG) 回帰、分類 固有表現抽出 NLP・精度上昇で検討すること データを増やす LLMによるデータ生成 + ラベリング(CommonLit2 1st, DAIGT 1st, LLM Sci Exam 5th, PIIDD 1st) LLMによるデータ生成は必ずしも効果があるとは限らない データ生成方法も現状はベストプラクティスはない Mistral, Mixtral系列でデータ生成がよさそうな感じはする なお、LLMがラベル付けできないタスクでは厳しい印象です TT

-
BigQueryとGemini 1.5 Proによるラーメン店クチコミの定量分析 - G-gen Tech Blog
G-gen の神谷です。本記事では、Google Maps API から取得したラーメン店のクチコミデータに対する定量分析手法をご紹介します。 従来の BigQuery による感情分析の有用性を踏まえつつ、Gemini 1.5 Pro の導入によって可能となった、より柔軟なデータの構造化や特定タスクの実行方法を解説します。 分析の背景と目的 可視化イメージ 分析の流れとアーキテクチャ クチコミデータ取得と BigQuery への保存 API キーの取得 データ取得のサンプルコード クチコミ数の制限と緩和策 料金 感情分析とデータパイプライン Dataform の利点 Dataform を使った感情分析のパイプライン定義例 感情分析の結果解釈 ML.GENERATE_TEXT(Gemini 1.5 Pro) 関数を使用した高度な分析 ユースケースに応じた独自の評価観点によるクチコミの定量化

-
RAGでの回答精度向上のためのテクニック集(応用編-A)
はじめまして。株式会社ナレッジセンスの門脇です。普段はエンジニア兼PMとして、「社内データに基づいて回答してくれる」チャットボットをエンタープライズ企業向けに提供しています(一応、200社以上に導入実績あり)。ここで開発しているチャットボットは、ChatGPTを始めとしたLLM(Large Language Models)を活用したサービスであり、その中でもRAG(Retrieval Augmented Generative)という仕組みをガッツリ利用しています。本記事では、RAG精度向上のための知見を共有していきます。 はじめに この記事は何 この記事は、LlamaIndexのAndrei氏による『A Cheat Sheet and Some Recipes For Building Advanced RAG』[1]という記事で紹介されている「RAGに関するチートシート」について、And

-
GPT連携アプリ開発時の必須知識、RAGをゼロから解説する。概要&Pythonコード例
こんにちは。わいけいです。 今回の記事では、生成AI界隈ではかなり浸透している RAG について改めて解説していきます。 「低予算で言語モデルを使ったアプリを開発したい」というときに真っ先に選択肢に上がるRAGですが、私自身もRAGを使ったアプリケーションの実装を業務の中で何度も行ってきました。 今回はその知見をシェア出来れば幸いです。 RAG(Retrieval-Augmented Generation)とは まず、 そもそもRAGとは何ぞや? というところから見ていきましょう。 RAG(Retrieval-Augmented Generation) は自然言語処理(NLP)と特に言語モデルの開発において使用される技術です。 この技術は、大規模な言語モデルが生成するテキストの品質と関連性を向上させるために、外部の情報源からの情報を取得(retrieval)して利用します。 要は、Chat

-
LangChain で社内チャットボット作ってみた
こんにちは、クラウドエース SRE ディビジョン所属の茜です。 今回は、現在最も普及している対話型 AI サービスである ChatGPT で使用されているモデルと、LLM を使ったアプリケーション開発に特化したライブラリである LangChain を用いて社内向けのチャットボットを作成します。 ターゲット 任意のデータを元に回答を行うチャットボットを作成したい方 任意のデータを元に回答させる仕組みを知りたい方 ChatGPT とは ChatGPT とは、ユーザーが入力した質問に対して、まるで人間のように自然な対話形式でAIが答えるチャットサービスです。2022 年 11 月に公開されて以来、回答精度の高さが話題となり、利用者が急増しています。 人工知能の研究開発機関「OpenAI」により開発されました。 執筆時点では、GPT-3.5、GPT-4 という大規模言語モデル (LLM) が使用さ

-
AzureでRAGをガンガン試行錯誤してみて得たナレッジを紹介します!/Azure RAG knowledge share
2024/1/31に開催された【StudyCo×KAGコラボ】Azure・AWSでLLMアプリ開発レベルアップ!事例&ハンズオンで発表した資料です。 AzureでRAGによる社内文章検索をやってみてさまざまな試行錯誤を通して得たナレッジを共有します!

-
Amazon Bedrock(ClaudeV2)でLambdaのコードを生成してみた - Taste of Tech Topics
こんにちは、最近久々にソロキャンプをしてきました菅野です。 AWS上で、 ChatGPTのようなテキスト生成AIを利用できるようになるサービス、Amazon Bedrockがリリースされました。 今回はBedrockで、LambdaのPythonコードを生成してもらいます。 利用するモデルは、ChatGPTと同レベルの性能を有しているClaudeV2を利用します。詳細はこちら。 Bedrockについて執筆した別記事もあわせてご覧ください。 acro-engineer.hatenablog.com acro-engineer.hatenablog.com S3に保存したCSVファイルの平均を求めるLambda関数を作成する 以下のようなcsvをS3からダウンロードし、一分毎、name毎の平均を返却するLambdaを作成してもらいます。 id,name,value,timestamp 1,da

-
LLM で長文から構造化データを抽出する - DROBEプロダクト開発ブログ
はじめに こんにちは、DROBE の都筑です。 みなさん LLM 使っていますか。今回は LLM を利用して長文から構造化データを抽出する手法について記載します。 構造化データの抽出 LLM を利用して構造化データを抽出することを Extraction と呼びます。 Extraction は以下のようなユースケースが考えられます。 テキスト情報から構造化したデータを抽出し DB にインサートする 外部 API を呼ぶために入力を解釈してパラメータを抽出する Extraction は非常に有用ですが、元となるテキストの最大長は利用する LLM の最大 token 数に依存します。 LLM と長文の処理 長文を LLM で扱うユースケースとしては文章要約がアプリケーションとして想定されることが多く、いくつかの方法が考案されています。LangChain の公式ドキュメントを覗くと、以下の 3 つ

-
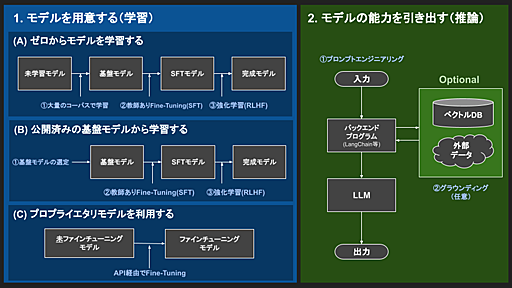
LLM開発のフロー | フューチャー技術ブログ
はじめにこんにちは、SAIG/MLOpsチームでアルバイトをしている板野・平野です。 今回は、昨今注目されている大規模言語モデル(LLM)の開発においてMLOpsチームがやるべきことを考えるため、まずはLLM開発の流れを調査・整理しました。 本記事はその内容を「LLM開発のフロー」という題目でまとめたものです。LLMを本番運用するときに考慮すべきこと、LLM開発・運用を支援するサービスやツール・LLMシステムの構成例などについては、「LLM開発でMLOpsチームがやるべきこと」と題して別記事でご紹介していますので、ぜひ併せてご覧ください。 ここでのLLM開発とは、「LLM自体の開発」および「LLMを活用したシステム開発」の両方を含みます。また、「LLM自体の開発」は学習フェーズ、「LLMを活用したシステム開発」は推論フェーズ、として記載しています。 本記事ではLLM開発における各フェーズの
-
llama2のファインチューニング(QLORA)のメモ|Kan Hatakeyama
2023/11/13追記以下の記事は、Llama2が公開されて数日後に書いた内容です。 公開から数ヶ月経った23年11月時点では、諸々の洗練された方法が出てきていますので、そちらも参照されることをおすすめします。 (以下、元記事です) 話題のLamma2をファインチューニングします。 QLoRAライブラリを使うパターンと、公式推奨の2つを試しました。前者が個人的にはオススメです。 前提Hugging faceで配布されている公式のモデルが必要です。以下を参考に、ダウンロードしておきます。 データセット作成 (7/20 15:20追記 設定ミスってたので修正しました) test.jsonを適当に作ります。 [ { "input": "", "output": "### Human: 富士山といえば?### Assistant: なすび" }, { "input": "", "output":

-
【Techの道も一歩から】第11回「言語処理でのちょっとした前処理」 - Sansan株式会社 | 公式メディア「mimi」
こんにちは。DSOC R&Dグループの高橋寛治です。 形態素解析や系列ラベリングの際の素性抽出などでは、いつも似たようなコードを書きがちです。 今回はその作業を減らすための備忘録として、これらのちょっとした前処理について紹介します。 形態素解析 日本語を対象にした自然言語処理における形態素解析とは、単語分割と品詞付与を指しています。 日本語は単語に分かち書きされていないため、ほとんどのタスクの前段となる非常に重要な処理です。 Pythonで日本語形態素解析を行う際には、MeCabやPure PythonのJanomeがよく使われるかと思います。 私は、MeCabのPython 3バインディングであるmecab-python3をよく使います。 シンプルなインタフェースでMeCabの形態素解析機能がPythonで利用可能です。 まずは、mecab-python3を用いて形態素解析を行い、得られ
-
高速な文字列探索:Daachorseの技術解説 - LegalOn Technologies Engineering Blog
こんにちは。LegalForce Researchで研究員をしている神田 (@kampersanda) です。 LegalForce Researchでは現在、高速なパターンマッチングマシン Daachorse(ダークホース)を開発・運用しています。文字列処理の基礎である複数パターン検索を提供するRust製ライブラリです。以下のレポジトリで公開されています。 github.com 本記事はDaachorseの技術仕様を解説します。具体的には、 複数パターン検索に関係する基礎技術(トライ木・Aho–Corasick法・ダブル配列) Daachorseの実装の工夫と性能 を解説します。 以下のような方を読者として想定します。 文字列処理アルゴリズムやデータ構造に興味のある方 自然言語処理の要素技術に興味のある方 Rustライブラリに興味がある方 Daachorseについて 複数パターン検索の基
-
Elasticsearchで日本語を同義語展開する
全文検索における同義語展開の必要性 全文検索では、基本的に文字列のマッチにより検索を行います。しかし我々が言葉を扱うときには、同じものを違う表現で指し示すことが多々あります。 例えば「独占禁止法」と呼ばれる法律があります。これは経済憲法とも言われる大変重要な法律なのですが、日本では「昭和二十二年法律第五十四号(私的独占の禁止及び公正取引の確保に関する法律)」という法律がそれに該当し、独占禁止法という名前にはなっていません。これを皆、「独占禁止法」や「独禁法」といった代替可能な別表現(同義語)で呼んでいるわけです。 同法律には法令用語で言うところの「題名」は付されておらず、頭書の名称は制定時の公布文から引用したいわゆる「件名」である。独占禁止法ないし独禁法と略称されることも多い。 もし「独禁法」で検索して当該法律がヒットしなければ、ユーザーとしては不満足でしょう。検索システムのクオリティを向

-
spaCyのDependencyMatcherでレビュー文から情報を抽出してみる
これは、自然言語処理 Advent Calendar 2021の20日目の記事です。 新卒2年目のエンジニア、吉成です。 普段はフォルシアのDXプラットフォーム部・技術研究所という2つの部署に所属し、web開発と自然言語処理の二足の草鞋を履いています。二兎を追う者は一兎をも得ずという言葉もありますが、今はひーひー言いながらも二兎を追えるエンジニアを目指しています。 ところで皆さん、依存構造解析してますか? 依存構造解析は自然言語処理の実応用において重要な基礎解析の1つです。文中のどの単語(あるいは句)がどの単語(句)に依存しているか、またそれらの単語(句)間はどんな関係を持っているのか(依存構造)を解析します。一般的に依存構造解析は、文を単語や形態素に分割したり、単語や形態素に品詞のラベルを付与したりする形態素解析と呼ばれる処理の後に行われます。 (画像:「部屋から見える夜景が美しかった。

-
Ginzaで形態素解析、係り受け解析、固有表現抽出、ユーザー辞書追加 - iMind Developers Blog
概要 Ginzaを使ってNLPでよく使ういくつかの処理を動かしてみる。 バージョン情報 ginza==2.2.0 Python 3.7.4 インストール pipで入れられる。 $ pip install "https://github.com/megagonlabs/ginza/releases/download/latest/ginza-latest.tar.gz" 詳細は下記参照。 https://megagonlabs.github.io/ginza/ 形態素解析 Ginzaは内部的にはSudachiPyを利用している。 import spacy nlp = spacy.load('ja_ginza') doc = nlp('庭にいる犬が鳴いてる') for sent in doc.sents: for token in sent: print( 'token.i={}'.forma
-
言語処理100本ノック(2024年度)
Copied from: Public/Study NLP100 2023 実践的な課題に取り組みながら,プログラミング,データ分析,研究のスキルを楽しく習得することを目指します.具体的には, Unix環境でのターミナルの操作. 研究室の実験環境の体験. Pythonプログラミングのチュートリアル. Pythonの実行環境のインストール. Pythonの基礎. Jupyter notebook, IPython, pipの使い方など. この勉強会では言語処理100本ノック 2020を教材として用います.自然言語処理に関するプログラムを実際に作ってもらい,互いにコードレビューを行います. 問題に対する答えは一つではありません.どんな方法でも構いませんので,自力で問題を解き,他人のコードを読むことで,よいプログラムとは何かを体感してください. This study group aims at

-
トピックモデルを使って問い合わせ内容を分析した話 - Classi開発者ブログ
この記事はClassi developers Advent Calendar 2021の18日目の記事です。 昨日は基盤インフラチームのめるさんによる「バックエンドエンジニアが基盤インフラチームに異動して半年ほど経った話」でした。 こんにちは、データAI部でデータサイエンティストをしている高木です。 弊社では顧客である先生、生徒、保護者からClassiの機能や契約に関する問い合わせを日々頂いております。 これらの問い合わせの内容を分析し、Classiの現状の課題や今後解決していくための施策などを社内で検討しています。 今回は問い合わせ内容を言語処理技術の一つであるトピックモデルを使って分析した内容についてご紹介します。 なぜ分析する必要があったのか? Classiへの問い合わせやその対応の内容は、担当者によってテキスト化された状態で管理されています。 弊社のカスタマーサポート・カスタマーサ

-
ヤフーにおける自然言語処理モデルBERTの利用
ヤフー株式会社は、2023年10月1日にLINEヤフー株式会社になりました。LINEヤフー株式会社の新しいブログはこちらです。LINEヤフー Tech Blog こんにちは。Yahoo! JAPAN研究所で自然言語処理の研究開発をしている柴田です。 私は自然言語処理の研究と、最新の自然言語処理技術を社内のサービスに適用できるようにする開発の両方を行っています。今日は後者の話をします。 この記事ではBERTというモデルに焦点をあて、BERTの概要と、社内でのBERTの利用、最後に具体例として検索クエリのカテゴリ分類について紹介します。 ※この記事で取り扱っているデータは、プライバシーポリシーの範囲内で取得したデータを個人が特定できない状態に加工しています。 1. BERTとは 2018年にGoogleからBERT (Bidirectional Encoder Representations




公式Twitter
- @HatenaBookmark
リリース、障害情報などのサービスのお知らせ
- @hatebu
最新の人気エントリーの配信
キーボードショートカット一覧
j次のブックマーク
k前のブックマーク
lあとで読む
eコメント一覧を開く
oページを開く

