
大震災の時分に何だが、Kyoto Cabinetベースで検索エンジンの核となる転置インデックスを作るのに適したDBを実装したという話。 転置インデックスとappend操作 多くの検索エンジンの核となる転置インデックスとは、検索語に一致する表現がどこに出てきたかという位置情報のリストを保持するものであり、検索語をキーとして位置情報リストを値とする連想配列である(転置インデックスを使わない検索エンジンもあるが)。この位置情報リストをposting listとか呼んだりするらしい。転置インデックスにもいくつか流儀があり、検索語をどのように切り分けるかで単語(分かち書き)方式とか文字N-gram方式とか呼ばれるものがあったりするが、いずれにせよ、小さいキーと、非常にでかい値を保持する連想配列を作ることには変わりない。 で、素朴に転置インデックスを作ろうとすると、検索対象の文書を解析しながら、得られ
dbに関するkgbuのブックマーク (149)
-
 kgbu 2011/03/11
kgbu 2011/03/11
-
開発メモ: Kyoto Cabinetのロック機構の改善
Kyoto CabinetはIO負荷が高い場合にCPU負荷も高くなりがちだという指摘を受けて、それを解決すべくロック機構を見直したという話。 スロットロック ハッシュテーブルの操作はハッシュバケット毎に完全に独立して実行できるのが強みだ。ハッシュテーブルは計算量が有利なだけでなく、並列性にも優れるということ。実際には下層のファイルIOで実装依存の排他制御が行われることになるが、ハッシュ層だけ見れば理想的な並列性を備えている。ただし、同じバケットに連なるレコード群の操作は互いに依存関係があるので、それらは一括して排他制御してやる必要がある。となると、バケット毎にロックを用意するのが理想だが、実際にはメモリを節約するために、予め決めた数のロックを用意して、ここのロックに複数のバケットを割り当てる構成をとる。リソース空間をスロットに分けるというイメージから、これをスロットロックと呼ぼう。 スロッ
-
ここまでできる! CouchDBパワーアップ作戦
これまでの連載を通して、CouchDBの基本的な概念と使い方、アプリケーションの作成方法までを解説してきました。ここからはさらに一歩踏み込んで、CouchDBをDBサーバやAPサーバとして実際に運用するときに役に立つ機能を紹介していきます。具体的には、次の3つのテーマを取り扱います。 全文検索を導入すれば、CouchDB内にあるすべてのドキュメントを対象に、特定のキーワードを指定して検索できます。ユーザー認証では、例えばDBの管理者権限を特定のユーザーのみに付与できます。ユーザー認証はまだ充実しているとはいえないレベルですが、現時点ではどのような選択肢があるかを紹介していきたいと思います。最後にCouchDBへの負荷を分散させる方法として、CouchDBのインスタンスをノードとして複数用意し、各ドキュメントを分散して配置するやり方を紹介します。これらの手段を目的に応じて生かすことができれば
-
開発メモ: Kyoto TycoonでテーブルDBを実現する
Kyoto Tycoonで、RDBMSのテーブルのように複数のコラムを持ったレコードを扱ったり、特定のコラムを対象にセカンダリインデックスを張ったりすることもできるという話。 テーブルDB Tokyo CabinetおよびTokyo Tyrantでは、テーブルDBという実装があった。最も率直なKVS(永続化連想配列)の実装としてお馴染みのTC/TTではあるが、valueに構造を持たせることによってマルチコラムを実現し、さらに更新処理にフックをかけてセカンダリインデックスを自動的に管理できるようにもしていた。結果として、「ドキュメント指向DB」とか「スキーマレスDB」とかいったような、ゆるふわな感じの用途で便利に使えるツールになっていると思う。 しかし、KyotoシリーズではテーブルDBは実装しない方針である。多機能すぎてメンテが大変だからだ。アプリケーション寄りの機能を提供するということは
-
開発メモ: スレーブエージェントによるKTからMySQL等へのレプリケーション
Kyoto TycoonからRDBMS等の他製品に対してレプリケーションを行う方法について述べる。 カスタマイズ機能群の最後のパーツ 以下のイラストのように、Kyoto Tycoonには、カスタマイズ性を高めるための様々な機能が実装されている。 HTTPの既存プロトコル上で任意のデータベース操作処理を実現するための「スクリプト言語拡張」。ユーザ定義の任意のプロトコルで任意のデータベース操作処理を実現するための「プラガブルサーバ」。既存のデータベース操作指示に対して任意の処理を行うための「プラガブルデータベース」。これら3つの機能を使えば、KTのほぼ全ての機能の振る舞いをユーザ定義のものに差し替えることができる。かなり究極的なカスタマイズ性を既に備えていると言える。 今回加わったのは、KTの外部の別システムとKTを連携させるための機能である。KTで更新ログを有効にすると、KTのデータベースに
-
開発メモ: memcachedプロトコルをKTにプラグインする
高効率キャッシュサーバ兼データベースサーバであるKyoto Tycoonのネットワーク通信機構をプラグインで切り替えられるようにして、memcachedプロトコルにも対応したというお話。 プラガブルサーバ Apacheは、様々なモジュールを後付けのプラグインで組み込むことで、非常に柔軟に機能追加を行えるようになっている。MySQLもストレージエンジンをプラグインで切り替えられるようになっていて、非常に柔軟なソリューションが提供できるようになっている。そのようなプラグインできるモジュールをプラガブルモジュールと呼ぶことにしよう。 同じように、KTでもストレージエンジン(DBM層)をプラガブルモジュールにする予定ではあるが、今回はストレージエンジンの話ではない。逆に、ネットワーク層をプラガブルモジュールにしてしまうのだ。そうすると、任意のプロトコルでデータベースを操作できるようになる。 DBM
-
ホーム | Let's POSTGRES
メインコンテンツに移動 お知らせ Let’s Postgres 運営管理についてのお知らせ コンテンツメニュー 導入検討 と 入門 インストール 運用管理 チューニング 新機能: 17 / 16/ 15 / 14 / 13 / 12 / 11 / 10 / 9.6 / 9.5 / 9.3 トラブルシュート サポートとFAQ 事例紹介 イベントレポート リンク集 レプリケーション / クラスタ構成 XML / PostGIS / 拡張モジュール パーティショニング / テキスト検索 Window関数 / 再帰SQL / 外部データ連携 文書: 16 / 15 / 14 / 13 / 12 / 11 / 10 / 9.6 Let's PostgreSQL は特定非営利活動法人日本PostgreSQLユーザ会が運営しています。 RSS feed
-
pgbenchの使いこなし — Let's Postgres
SRA OSS, Inc. 日本支社 石井 達夫 pgbenchとは pgbenchはPostgreSQLに同梱されているシンプルなベンチマークツールです。最初のバージョンは筆者により作成され、日本のPostgreSQLメーリングリストで1999年に公開されました。その後pgbenchはcontribという付属追加プログラムとして、PostgreSQLのソースコードとともに配布されるようになりました。どのバージョンでPostgreSQLに取り込まれたのかはPostgreSQL付属のドキュメント(HISTORY)には書かれていないので定かではないのですが、コミットログを見ると、おそらく2000年にリリースされたPostgreSQL 7.0で導入されたと思われます。その後数多くの改良がたくさんの人によって行われ、現在に至っています。 pgbenchを利用することにより、自分の使っているPost
-
-
Google Developer Day 2010 Japan : 高性能な Android アプリを作るには
.app 1 .dev 1 #11WeeksOfAndroid 13 #11WeeksOfAndroid Android TV 1 #Android11 3 #DevFest16 1 #DevFest17 1 #DevFest18 1 #DevFest19 1 #DevFest20 1 #DevFest21 1 #DevFest22 1 #DevFest23 1 #hack4jp 3 11 weeks of Android 2 A MESSAGE FROM OUR CEO 1 A/B Testing 1 A4A 4 Accelerator 6 Accessibility 1 accuracy 1 Actions on Google 16 Activation Atlas 1 address validation API 1 Addy Osmani 1 ADK 2 AdMob 32 Ads

-
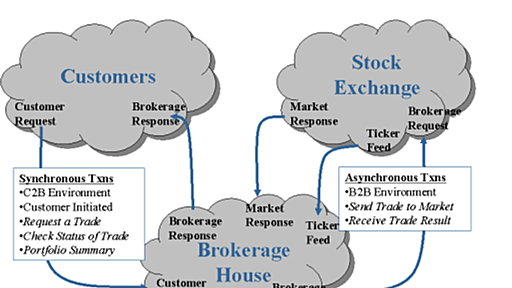
データベース負荷テストツールまとめ(4) - SH2の日記
データベース負荷テストツールまとめの第4回です。 データベース負荷テストツールまとめ(1) TPC-B、TPC-Wベースのツールを6つ紹介 データベース負荷テストツールまとめ(2) TPC-Cベースのツールを6つ紹介 データベース負荷テストツールまとめ(3) TPC-Hベースのツールを2つ紹介 今回はTPC-Eベースのツールを見ていきたいと思います。 TPC-Eとは TPC-EはRDBMSベンチマーク仕様の一つで、オンライントランザクション(OLTP)の性能を測定するものです。証券会社の業務をモデルとして取引や市場の監視、メンテナンス処理を行い、1秒あたりに行った取引件数を性能の指標値とします。 OLTPのベンチマークとしてはこれまでTPC-Cがよく用いられてきました。しかしTPC-Cは1992年の策定から実に18年が経過しており、その間コンピュータのCPU性能はムーアの法則にしたがって伸
-
HBaseとはどんなNoSQLデータベースなのか? 日本語で読める情報を集めてみた
Facebookが新しいサービス「Messages」の基盤として、NoSQLデータベースの「HBase」を選択したことを、先日の記事「Facebookが新サービスの基盤にしたのは、MySQLでもCassandraでもなく、HBaseだった」で紹介しました。 HBaseは、Facebookによると次のような特徴を備えていると説明されてます。 負荷に対して非常に高いスケーラビリティと性能を発揮 CassandraよりもシンプルなConsistency Model(一貫性モデル)を備えている 自動ロードバランス、フェイルオーバー、圧縮機能 サーバーごとに数十個のシャードを割り当て可能、などなど このHBaseはどのようなデータベースなのでしょうか? 情報を集めてみました。 HBase入門のプレゼンテーション 最初に紹介するのは「HBaseエバンジェリスト」Tatsuya Kawano氏のプレゼン

-
ソーシャルゲームのためのMySQL入門 | BLOG - DeNA Engineering
こんにちはこんにちは。最近お腹痛いばっかり言ってることで有名なiwanagaです。 DeNAは外部的にはプラットフォーム的な部分の方がフィーチャーされることが多いですが、実はソーシャルゲームの提供も行っています。怪盗ロワイヤルとか、どこかで聞いたことがあるのではないでしょうか。 僕はDeNAでソーシャルゲームが誕生した辺りからずっとサーバサイドを見てきましたが、そんな運用の中で自分が貯めてきた知見とかTIPSをご紹介したいと思います。 かれこれ10タイトル近くはレビューしたり運用したりしてるため結構言いたいことはいっぱいあるので、小出しにしつつ評判よければ次も書きます。 ソーシャルゲームのためのMySQL入門一覧 ソーシャルゲームのためのMySQL入門 - Technology of DeNA ソーシャルゲームのためのMySQL入門2 - Technology of DeNA 「MySQL

-
Net_KyotoTycoon - Openpear
Net_KyotoTycoon Subversion Repository: http://openpear.org/repository/Net_KyotoTycoon / Latest Release: no release Kyoto Tycoon client library for PHP. System requirement. PHP5.3 HTTP_Request2 PHPUnit3.5 Usage <?php require_once 'Net/KyotoTycoon.php'; $kt = new \Net\KyotoTycoon(array('port' => 19780)); $kt->set('test_php', 'Hello KyotoTycoon!!'); var_dump($kt->get('test_php')); // Hello KyotoTYco
-
-
開発メモ: MapReduce on Kyoto Cabinet
Googleで実用化されHadoopで流行しているところの分散処理フレームワークMapReduceをKyoto Cabinetにおいても実現してみた。その解説。 ローカルなMapReduce MapReduceは多数のマシンが連携して分散処理を行うためのフレームワークなので、プロセス組み込みDBMであって分散など全く関係ない世界に生きているKCでMapReduceを実行して意味があるのだろうか。答えは、「あんまりない」である。それにもかかわらず実装したのは、何となく話題性がありそうだからってのが最大の理由なのだが、もうひとつ理由がある。 スクリプト言語で集計処理をやろうとすると、めっちゃメモリ食うしCPUパワーを使うわりに遅いからである。1000万件のソートってだけでスクリプト言語だと結構辛いからね。そこで、MapReduceフレームワークをC++で実装してmapとreduceだけをスクリ
-
Technical Memo: Memory Saving Associative Array by Kyoto Cabinet and MessagePack
Kyoto Cabinet features on-memory database which can be used as associative array of strings. MessagePack is a binary-based efficient object serialization library. Combination of the two provides you associative array to contain generic objects. Space Efficiency of Kyoto Cabinet Let's suppose that we should manage 1 million simple records whose key and value are 10 bytes strings. The following is a
-
Welcome to Swift’s documentation! — Swift 2.35.0.dev92 documentation
Welcome to Swift’s documentation!¶ Swift is a highly available, distributed, eventually consistent object/blob store. Organizations can use Swift to store lots of data efficiently, safely, and cheaply. This documentation is generated by the Sphinx toolkit and lives in the source tree. Additional documentation on Swift and other components of OpenStack can be found on the OpenStack wiki and at http
-
node-kyoto-tycoon - SWDYH
node-kyoto-tycoon http://github.com/swdyh/node-kyoto-tycoon KyotoTycoonのNode.js用ライブラリを作りました。まだだいぶ荒削りな状態で、KyotoTycoonのAPIを簡単にラップした感じのものです。APIも変わるかもしれないし、バグもたぶんあると思いますが試してみてください。 Node.jsが新しめでないとHTTPのKeep-Aliveが使えないので、古いNode.jsを使っている場合は、新しいNode.jsを入れて使ってください。(Keep-Aliveが使えなくても動きますが、カーソル関連は使えないと思います) インストール npmを使う % npm install kyoto-tycoonソースから % git clone http://github.com/swdyh/node-kyoto-tycoon.gi
-
開発メモ: HTTP記録機能付きプロクシによるレプリケーション
HTTPプロクシに更新ログを取らせれば、HTTPベースのいかなるサービスの内部状態もレプリケーションできるんじゃないのか? という検討の過程を晒してみる。 背景 保守性の観点からKyoto Tycoon自体にはレプリケーション機能を持たせないことにしたが、実際のユースケースではレプリケーションが欲しくなることが多いこともわかっている。なので、外部機能によって何とかレプリケーションを実現したい今日この頃である。 KTにレプリケーションを実装しないもう一つの理由は、レプリケーションのための更新ログを記録するための処理がDBの更新処理よりも重いという本末転倒なことになっているからである。更新ログはレコードそのものに対して冗長なのでwriteの量も多いし、シーケンシャルアクセスなのでディスクには優しいが、データが際限なく増えるのでそれでも重い処理になる。また、DBはレコード単位の整合性だけを確保す

公式Twitter
- @HatenaBookmark
リリース、障害情報などのサービスのお知らせ
- @hatebu
最新の人気エントリーの配信
キーボードショートカット一覧
j次のブックマーク
k前のブックマーク
lあとで読む
eコメント一覧を開く
oページを開く


Copyright © 2005-2024 Hatena. All Rights Reserved.
設定を変更しました