
タグ
- すべて
- ネタ (3)
- .net (4)
- 1015day1 (2)
- 1015game1 (3)
- 2ch (6)
- DB (5)
- GC取得 (2)
- HDD (2)
- HotSPA2024 (3)
- LLM (5)
- MMD (2)
- PTFlive (2)
- QFT (6)
- RAG (3)
- RAID 5 (2)
- acl2020 (3)
- actor (3)
- addon (17)
- adobe (2)
- ai (22)
- akamai (2)
- algorithm (3)
- amazon (30)
- amd (7)
- amqp (4)
- android (49)
- apache (3)
- apartments (28)
- apartments95002 (2)
- apartments95129 (3)
- apartmentsaustin (2)
- apple (7)
- ar (2)
- architecture (6)
- art (3)
- artoolkit (2)
- atom (3)
- atompub (3)
- audio (4)
- austin (2)
- austinmarathon2024 (2)
- autohotkey (3)
- autopagerize (3)
- autotools (2)
- awk (3)
- aws (67)
- azure (16)
- babok (2)
- backup (8)
- bagel (2)
- baking (20)
- ballet (2)
- bash (2)
- bayeux (2)
- bbq (6)
- benzs500 (4)
- bert (3)
- bigtable (2)
- blogged (3)
- blogging (7)
- bookclub (2)
- bookmarklet (3)
- books (2)
- boost (6)
- boost.python (2)
- bot (6)
- brainfuck (3)
- bson (2)
- bto (2)
- c (12)
- c# (2)
- c++ (16)
- c++0x (5)
- cafe (2)
- career (79)
- cassandra (13)
- ccna (10)
- ccnp (7)
- cell phone (2)
- checkitout (2852)
- checkitout_dev (54)
- checkitout_research (73)
- chrome (11)
- cisco (9)
- clojure (8)
- cloud (18)
- clusters (2)
- codegolf (3)
- coherence (2)
- coke (2)
- comet (6)
- compiler (2)
- concurrency (24)
- conference (2)
- cooking (435)
- corba (2)
- corona (2)
- couchdb (16)
- counseling (3)
- coupon (2)
- ctypes (2)
- cuda (7)
- current (33)
- dallasgetaway2024 (3)
- database (113)
- datamining (14)
- datascience (3)
- datastore (13)
- dessin (3)
- dht (4)
- directcompute (5)
- dl (7)
- dmp (8)
- docker (2)
- doxygen (2)
- drizzle (13)
- dropbox (7)
- drupal (4)
- dryadlinq (2)
- dtrace (5)
- dynamo (4)
- ebay (2)
- ebook (3)
- ebooks (4)
- ebs (3)
- ec2 (44)
- eclipse (5)
- economy (4)
- education (2)
- emacs (6)
- emba (5)
- emobile (10)
- ereader (2)
- erlang (16)
- esb (2)
- estate (2)
- eucalyptus (3)
- evangelion (4)
- event (54)
- events (10)
- events2022 (2)
- events2024 (2)
- evernote (4)
- excel (7)
- facebook (6)
- fashion (5)
- fermi (3)
- ffa2 (4)
- fidelity (3)
- finance (28)
- firefox (62)
- firefox3 (2)
- fme (2)
- fortress (2)
- french (32)
- friendfeed (5)
- fujitsu (2)
- functionalprogramming (2)
- fusion (2)
- gae (38)
- galaxy (2)
- games (11)
- gc (3)
- gcc (3)
- geo (2)
- gfx (4)
- git (2)
- gmail (7)
- gmaps (2)
- gnu (2)
- google (84)
- googlereader (2)
- googlewave (2)
- gourmet (5)
- gpgpu (30)
- gpu (4)
- greader (2)
- greasemonkey (31)
- h (2)
- ha (3)
- hack (2)
- hacking (2)
- hadoop (51)
- hadoopstreaming (4)
- haiku (4)
- haskell (10)
- hatena (32)
- haystack (2)
- hbase (10)
- health (57)
- heartbeat (4)
- heroku (2)
- highavailability (3)
- hive (4)
- homeloan (5)
- housecleaning (2)
- household (5)
- houstonevents (7)
- houstonlife (2)
- houstonmarathon2024 (3)
- hpc (4)
- hpe (7)
- humor (8)
- hypertable (3)
- i18n (2)
- icfp (3)
- iclr2020 (2)
- ime (2)
- immigration (3)
- import (4)
- infiniband (5)
- infrastructure (3)
- intel (11)
- internet (4)
- investing (2)
- iphone (57)
- ipython (3)
- ir (2)
- ironpython (11)
- irs (2)
- irvingmarathon2024 (2)
- is01 (5)
- isc23 (2)
- iscsi (2)
- itouch (2)
- java (36)
- java7 (8)
- javascript (15)
- jbi (2)
- jboss (2)
- jobs (3)
- jquery (2)
- json (5)
- junit (4)
- kafka (3)
- keepass (8)
- kinect (2)
- lapack (2)
- launchy (2)
- ldr (2)
- lehman brothers (4)
- life (152)
- lifehack (7)
- lifestream (2)
- linux (38)
- lisp (29)
- literature (2)
- losangeles (2)
- lpic (3)
- lucene (3)
- lustre (7)
- mac (25)
- machinelearning (5)
- mahout (2)
- management (2)
- mapreduce (27)
- marathon (5)
- marketing (2)
- markets (7)
- mathematics (3)
- mba (2)
- mecab (3)
- media (6)
- megastore (2)
- memcached (11)
- memory-centric (3)
- mentos (2)
- messagepack (2)
- metaprogramming (4)
- metro (2)
- mfah (4)
- microsoft (5)
- mileage (5)
- mixi (2)
- ml (34)
- mobile (60)
- mogilefs (2)
- mongodb (27)
- mongorecord (2)
- montecarlo (2)
- mouse (3)
- movie (3)
- mq (5)
- ms (8)
- multimedia (12)
- multiprocessing (5)
- music (6)
- mysql (64)
- neta (2)
- network (8)
- neworleans202312 (3)
- news (11)
- nips2023 (2)
- nlp (164)
- nomad (2)
- nosql (4)
- numpy (2)
- nutanix (3)
- nvidia (14)
- oauth (4)
- observability (4)
- onwriting (3)
- opensolaris (3)
- openstack (8)
- opera (10)
- optuna (4)
- oracle (5)
- oregonsunstone (4)
- parallel (3)
- pc (23)
- performance (3)
- perfume (10)
- perl (48)
- perl6 (8)
- pet (5)
- pfn (3)
- php (12)
- pig (7)
- plone (3)
- pmbok (5)
- postgresql (7)
- presentation (3)
- productivity (8)
- programming (81)
- protocolbuffers (5)
- pubsub (3)
- pycon2010 (8)
- pypy (9)
- pyqt (3)
- python (437)
- python3.0 (28)
- qt (5)
- quantumcomputing (6)
- radiko (4)
- ramdisk (8)
- recipe (20)
- recommendation (6)
- redis (3)
- reference (18)
- remedie (3)
- rentacar (3)
- research (160)
- research_db (3)
- rest (6)
- restaurant (5)
- riak (10)
- roadtrip (165)
- ror (4)
- rpc (4)
- rss (4)
- rtrt (3)
- ruby (46)
- rust (23)
- s3 (8)
- sc23 (3)
- scala (31)
- scalability (54)
- scheme (7)
- science (8)
- screen (5)
- search (11)
- security (47)
- sfapartments (3)
- shelby (5)
- shopping (275)
- simpledb (4)
- soa (6)
- software (14)
- spark (4)
- sql (3)
- sqs (3)
- ssd (9)
- ssh (8)
- storage (57)
- strangler_fig (3)
- streaming (5)
- supercomputing (70)
- taskqueue (4)
- tax (9)
- tech (31)
- tegra (23)
- tegra2 (10)
- tegra3 (3)
- thingstodohouston (7)
- thrift (7)
- thunderbird (4)
- tips (8)
- tmp (7)
- toblog (153)
- todo (6)
- tokyocabinet (4)
- tool (3)
- tools (13)
- toread (46)
- toview (13)
- towatch (58)
- trackback (5)
- traffic (3)
- travel (18)
- tumblr (6)
- twitter (123)
- ubuntu (13)
- umpc (45)
- undonut (4)
- unity (5)
- unix (24)
- usschools (7)
- vi (9)
- vim (36)
- virtualization (4)
- visa (3)
- vista (6)
- vmware (34)
- vnc (3)
- voltdb (9)
- wcf (4)
- web (5)
- webdev (13)
- webhook (3)
- webmd.com (3)
- webservice (9)
- wifi (5)
- wimax (6)
- windows (25)
- windows7 (19)
- windows8 (4)
- wireless (3)
- wordpress (7)
- work (445)
- wpf (3)
- ws-day1 (3)
- xcode (3)
- xmpp (7)
- yahoo (14)
- yapcasia2009 (3)
- zfs (6)
- zookeeper (3)
- zsh (5)
- あとで (4)
- あとで書く (180)
- あとで見る (7)
- あとで試す (34)
- あとで読む (464)
- あとで調査 (6)
- いい話 (57)
- いつか試す (3)
- おせち (5)
- お察し下さい (4)
- お役立ち (8)
- これはすごい (11)
- これはひどい (7)
- ご理解とご協力 (6)
- ぬこ (4)
- はてな (30)
- はてなハイク (5)
- みけ猫 (4)
- アメリカ終了 (3)
- コロナ (5)
- コロナウイルス (3)
- ジブリ (5)
- ストレージ (3)
- ダラス観光 (3)
- テニス (3)
- トンデモ (11)
- ニコニコ動画 (7)
- ニコニコ生放送 (8)
- ニコ生 (5)
- ニセ科学 (3)
- ニュース (4)
- ニューヨーク (33)
- ネタ (321)
- ハイク (8)
- ハハハ、ファック (3)
- ハワイ旅行 (3)
- ベンチマーク (3)
- メタブ (30)
- モルガン・スタンレー (3)
- 一時帰国 (82)
- 一時帰国-風俗 (3)
- 一時帰国2024 (10)
- 一時帰国2024-2 (33)
- 一時帰国2025 (11)
- 世界旅行 (10)
- 人力検索 (4)
- 便利ツール (3)
- 分報 (7)
- 増田文学 (4)
- 富士山登山 (3)
- 小嶋陽菜 (3)
- 彼氏が○○に乗ってた (4)
- 政治 (7)
- 料理 (7)
- 日本旅行 (4)
- 書いた (32)
- 本文読んでない (29)
- 東京カフェ (8)
- 校正に来ました (3)
- 海外出産 (3)
- 温泉 (3)
- 群馬 (3)
- 藤川優里 (3)
- 読み物 (9)
- 財産分与 (3)
- 野村 (3)
- 顔文字 (6)
- 麻生太郎 (4)
- チキュウオワタ\(^o (4)
- checkitout (2852)
- あとで読む (464)
- work (445)
- python (437)
- cooking (435)
- ネタ (321)
- shopping (275)
- あとで書く (180)
- roadtrip (165)
- nlp (164)
llmとLLMに関するrawwellのブックマーク (5)
-
 rawwell 2024/08/10
rawwell 2024/08/10 “This property ensures that the model can only attend to previous positions in the sequence, not future positions, in order to generate predictions sequentially.”
“This property ensures that the model can only attend to previous positions in the sequence, not future positions, in order to generate predictions sequentially.”- LLM
- research
リンク -
実務におけるRAG 〜学びと現場のノウハウ〜 | ドクセル
スライド概要 実務においてRAG(Retrieval-Augumented Generation)をたっぷり経験したhoxo-mの学びと現場のノウハウをまとめた

-
-
-
LLM Inference Series: 4. KV caching, a deeper look
In the previous post, we introduced KV caching, a common optimization of the inference process of LLMs that make compute requirements of the (self-)attention mechanism to scale linearly rather than quadratically in the total sequence length (prompt + generated completions). More concretely, KV caching consists to spare the recomputation of key and value tensors of past tokens at each generation st
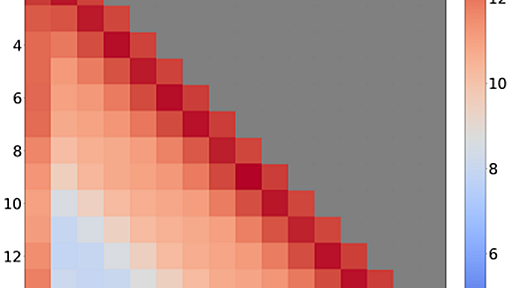 rawwell 2024/07/12
"Another possible optimization not covered by PagedAttention is reusing the key-value cache across requests. This would apply when the prompts share a common prefix, which commonly occurs in multi-round use cases like chat and agents or when using prompt templates (Figure 4)."
rawwell 2024/07/12
"Another possible optimization not covered by PagedAttention is reusing the key-value cache across requests. This would apply when the prompts share a common prefix, which commonly occurs in multi-round use cases like chat and agents or when using prompt templates (Figure 4)." -
 1
1
公式Twitter
- @HatenaBookmark
リリース、障害情報などのサービスのお知らせ
- @hatebu
最新の人気エントリーの配信
処理を実行中です
キーボードショートカット一覧
j次のブックマーク
k前のブックマーク
lあとで読む
eコメント一覧を開く
oページを開く


設定を変更しましたx