
第21回Sparkの設計と実装[2]~Sparkにおけるデータ共有の仕組みと耐障害性の実現方法 猿田浩輔,山田浩之 2016-06-08

第21回Sparkの設計と実装[2]~Sparkにおけるデータ共有の仕組みと耐障害性の実現方法 猿田浩輔,山田浩之 2016-06-08

2. 目次 1. 自己紹介 2. ユーザーローカルとアクセス解析 3. アクセス解析の基礎 4. アクセス解析システムの裏側 - リアルタイム集計 - 小バッチ集計 - 大規模バッチ集計 スライド49枚 2 12年9月23日日曜日 3. 自己紹介 • 三上俊輔 • 株式会社ユーザーローカル • 今年3月に筑波大学院を卒業 • 大学では分散ファイルシステムの研究 • 学生の時はCookpadのデータマイニン グ部門で2ヶ月ほどインターン 3 12年9月23日日曜日 4. 過去の研究、発表 • 研究ブログ:http://shun0102.net/ • 発表:「分散ファイルシステムGfarm 上でのHadoop MapReduce」など - http://www.slideshare.net/shun0102/ 4 12年9月23日日曜日

リクルート式Hadoopの使い方 - Presentation Transcript リクルート式Hadoopの使い方 株式会社リクルートMIT システム基盤推進室インフラソリューショングループ石川 信行 はじめに・・・ □名前 石川 信行 ( ground_beetle) □出身 福島県 いわき市 □経歴 ・2009年リクルート新卒入社 ・営業支援システムのコーダー(java)、DBAとして参加。 ・JavascriptのLibであるSenchaを用いたスマホサイト開発 ・現Hadoop推進担当 □趣味 ・外国産カブト虫飼育 ・スキューバダイビング ・海水魚飼育 リクルートの組織体制について 旅行C 営業 企画 自動車C 営業 企画 住宅C 営業 企画 MIT United 事業担当MIT 事業担当MIT 事業担当MIT ・マーケティング・分析チーム ・インフラ基盤チーム
『MarkeZine』が主催するマーケティング・イベント『MarkeZine Day』『MarkeZine Academy』『MarkeZine プレミアムセミナー』の 最新情報をはじめ、様々なイベント情報をまとめてご紹介します。 MarkeZine Day
次世代通信規格「5G(第5世代)」を使う大きなメリットは、4Gよりも高精細で遅延の少ない映像を配信できる点だ。この特徴を生かし、建設機械や医療機器を遠隔操作しようとする取り組みが広…続き 5Gがやってくる つながる機器は100万台 [有料会員限定] 5Gでロボット遠隔操作や遠隔医療、ドコモが公開

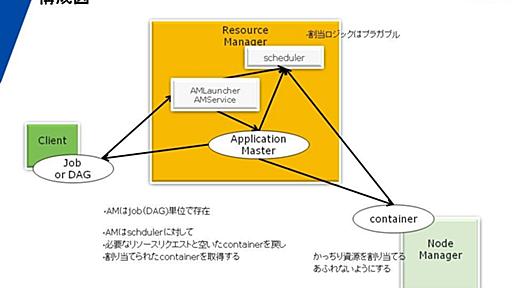
次世代Hadoopの開発が進んでいる。現状の推移では、少なくとも分散クラウドでの「OSSインフラ」としてはHadoopが最有力候補であることは間違いない。クラウド上での分散処理基盤での技術競争ではGoogleやAmazonが相当抜きんでいる現在、それに対抗しうる可能性があるOSSはHadoopの潮流の延長線上にしか考えられない。その形としてHadoop-MapReduce2.0があるように見える。現在の状態で自分なりの次世代Hadoopの理解をまとめておく。基本的に全部は見切れていないので、そのあたりはあしからず。基本的に次世代Hadoopの仕組みは大きく二つの要素からなる 現在のところの柱はHDFSとMapreduce2.0の二つだ。 まずMapReduce。これは従来の「MapReduce」というものからはほど遠い。むしろ「任意」の分散処理実行フレームワークにたいして、適切なリソースを
はじめに Hadoopとは、Googleの基盤技術であるMapReduceをJavaでオープンソース実装したもので、分散処理のフレームワークです。Hadoopを使うと、1台のサーバでは時間の掛かるような処理を、複数のサーバで分散処理させることができます。「処理を割り振ったサーバが壊れた場合どうするか」などの耐障害性の問題もHadoopが管理してくれるため、利用者は処理のアルゴリズムのみに集中することができるのです。素晴らしいですね。最近ではYahoo!やはてななど、様々な企業でも利用されるようになってきています。 Hadoop導入の背景 筆者はクックパッド株式会社に勤めています。open('http://cookpad.com'); return false;">クックパッドというサイトが有名だと思いますが、他にも携帯版クックパッドであるopen('http://m.cookpad.co

大規模データの分散処理を支えるJavaソフトウェアフレームワークであり、フリーソフトウェアとして配布されている「Apache Hadoop」。その作者ダグ・カティング(Doug Cutting)さんが「Cloud Computing World Tokyo 2011」&「Next Generation Data Center 2011」において「Apache Hadoop: A New Paradigm for Data Processing」という講演をしていたので聞きに行ってきました。 満員の客席。 皆様を前にして講演できることを大変光栄に思っております。「Apache Hadoop」について皆様に伝えていきますが、これはまさにデータ処理の新たなるパラダイムを提供するものではないかと私は思っております。 まずは簡単に自己紹介をさせていただきましょう。私は25年に渡ってシリコンバレーで仕

Facebookは大規模なデータ処理の基盤としてHBaseを利用しています。なぜFacebookはHBaseを用いているのか、どのように利用しているのでしょうか? 7月1日に都内で行われた勉強会で、Facebookのソフトウェアエンジニアであるジョナサン・グレイ(Jonathan Gray)氏による解説が行われました。 解説はほぼスライドの内容そのままでした。当日使われた日本語訳されたスライドが公開されているので、ポイントとなるページを紹介しましょう。 Realtime Apache Hadoop at Facebook なぜリアルタイムデータの分析に、Hadoop/HBaseを使うのか? MySQLは安定しているが、分散システムとして設計されておらず、サイズにも上限がある。一方、Hadoopはスケーラブルだがプログラミングが難しく、ランダムな書き込みや読み込みに向いていない。 Faceb

Hadoopを使ってTwitterやFacebook上での「影響力」を数値化しているKloutというサービスがあるそうです。大変興味深かったので翻訳してみました。元記事のCloudera社とKout社の許可を頂いて掲載しています(@shiumachiさん、ありがとうございます!) Using Hadoop to Measure Influence | Apache Hadoop for the Enterprise | Cloudera ソーシャルメディア上の影響力測定サービス「Klout」とはKlout | The Standard for InfluenceKloutのゴールは影響力の数値化の分野でのスタンダードになることだ。近年のソーシャルメディアの普及により、多くの測定可能な友達関係に関する情報が手に入るようになってきている。Facebookユーザには、平均して130人の友達がいる
NTTデータが、オープンソースの分散バッチ処理ソフト「Hadoop」を使ったシステム構築事業で、2012年度に100億円を売り上げる目標であることが明らかになった。2010年10月12日(米国時間)に米国ニューヨークで開催された「Hadoop World 2010」で、NTTデータの山田伸一常務が発表した。2012年度までに30件のシステム構築、100件のサポート契約を目指す。 Hadoopは分散処理システムを構築するためのミドルウエア。一般的なPCサーバー100台で、およそ200Tバイトのデータを解析できる大型データ分析システムを構築できる。NTTデータは2010年7月に、Hadoopを使ったシステム構築・運用支援サービス「BizXaaSクラウド構築サービス Hadoop構築・運用ソリューション」を開始。10月にはHadoop専業ベンチャーの米クラウデラと提携し、クラウデラ製のHadoo

業界トップ のエンタープライズ Hadoop 企業 Cloudera に入社しました http://www.cloudera.co.jp/ 今年の6月に、「平成21年度 産学連携ソフトウェア工学実践事業報告書」というドキュメント群が経産省から公表されました。 そのうちの一つに、NTTデータに委託されたHadoopに関する実証実験の報告書がありましたので、今更ながら読んでみることにしました。 Hadoop界隈の人はもうみんなとっくに読んでるのかもしれませんけど。 http://www.meti.go.jp/policy/mono_info_service/joho/downloadfiles/2010software_research/clou_dist_software.pdf 「高信頼クラウド実現用ソフトウェア開発(分散制御処理技術等に係るデータセンター高信頼化に向けた実証事業)」という

shard環境中では、すべてのshardで並行してデータ処理が走ります。 (注意: 2010/2/2: shard内でのmap/reduceはペンティング中ですが、すぐに戻ります) map/reduce はデータベース [command] を経由して、呼び出されます。 データバースは一時的なコレクションを出力結果用に作成します。この一時的なコレクションは、クライアントのコネクションが閉じたとき、または明示的にdropされた場合削除されます。また、永続的な出力用のコレクション名を指定することもできます。 map と reduce ファンクションはJavaScriptで書き、サーバ上で実行されます。 コマンドの文法: db.runCommand( { mapreduce : <collection>, map : <map ファンクション名>, reduce : <reduce フ
 1台構成のHadoopを30分で試してみる(CentOS + Cloudera)
1台構成のHadoopを30分で試してみる(CentOS + Cloudera)
(参考) Cloudera社のHadoopパッケージの情報 http://archive.cloudera.com/docs/ 必要なもの ・CentOS5かCentOS6のLinux環境1台(ここではCentOS5.6とCentOS6.0を使いました。CentOSの他バージョンや、Fedora、Redhat等でも大丈夫だと思います) ・インターネット接続 ・Sun社Javaパッケージ(パッケージファイルをインターネットから取得) ・Cloudera社のCDH3のHadoopパッケージ(yumでインターネットからインストール) 作業手順 0. 準備 0-1. Sun社Javaパッケージの取得 http://java.sun.com/javase/downloads/にて、 Java SE 6の[Download]ボタンを押して出る「Java SE Downloads」のページから必要なもの

 1台でHBase, Hive, Pig, HUE(旧Cloudera Desktop)を試してみる(Ubuntu + Cloudera)
1台でHBase, Hive, Pig, HUE(旧Cloudera Desktop)を試してみる(Ubuntu + Cloudera)
必要なもの ・Linux(Ubuntu)+Cloudera版Hadoop環境(1台)→ 構築方法はこちら ・インターネット接続 ・Cloudera社のCDH3のHBase, Hive, Pig, HUEのパッケージ(aptでインターネットからインストール) 作業手順 以下の、1. HBase, 2. Pig, 3. Hive, 4. HUEの手順は、独立して試すことができますし、一つの環境でまとめて試すこともできます。(それぞれデータの管理は別々です。) 1. HBase 1-1. インストール: Linux環境にて、rootで作業します。 1-1-1. HBaseをインストールします。 apt-get -y install hadoop-hbase apt-get -y install hadoop-hbase-master apt-get -y install hadoop-hbase

2010年07月12日20:12 CentOS に Hadoop, Pig, Hive, HBase をインストール CentOS5.4 に Hadoop, Pig, Hive, HBase をインストールする備忘録です。まずは JDK をインストールします。JDK6 以上が必要です。 # http://java.sun.com/javase/ja/6/download.html から JDK6 をダウンロード sudo sh jdk-6u21-linux-i586-rpm.bin java -version # 1.6.0_21 次に、yum で簡単にインストールするために、リポジトリを追加します。これでインストールが格段に楽になりますね。 wget http://archive.cloudera.com/redhat/cdh/cloudera-cdh3.repo sudo mv clo
リリース、障害情報などのサービスのお知らせ
最新の人気エントリーの配信
j次のブックマーク
k前のブックマーク
lあとで読む
eコメント一覧を開く
oページを開く


