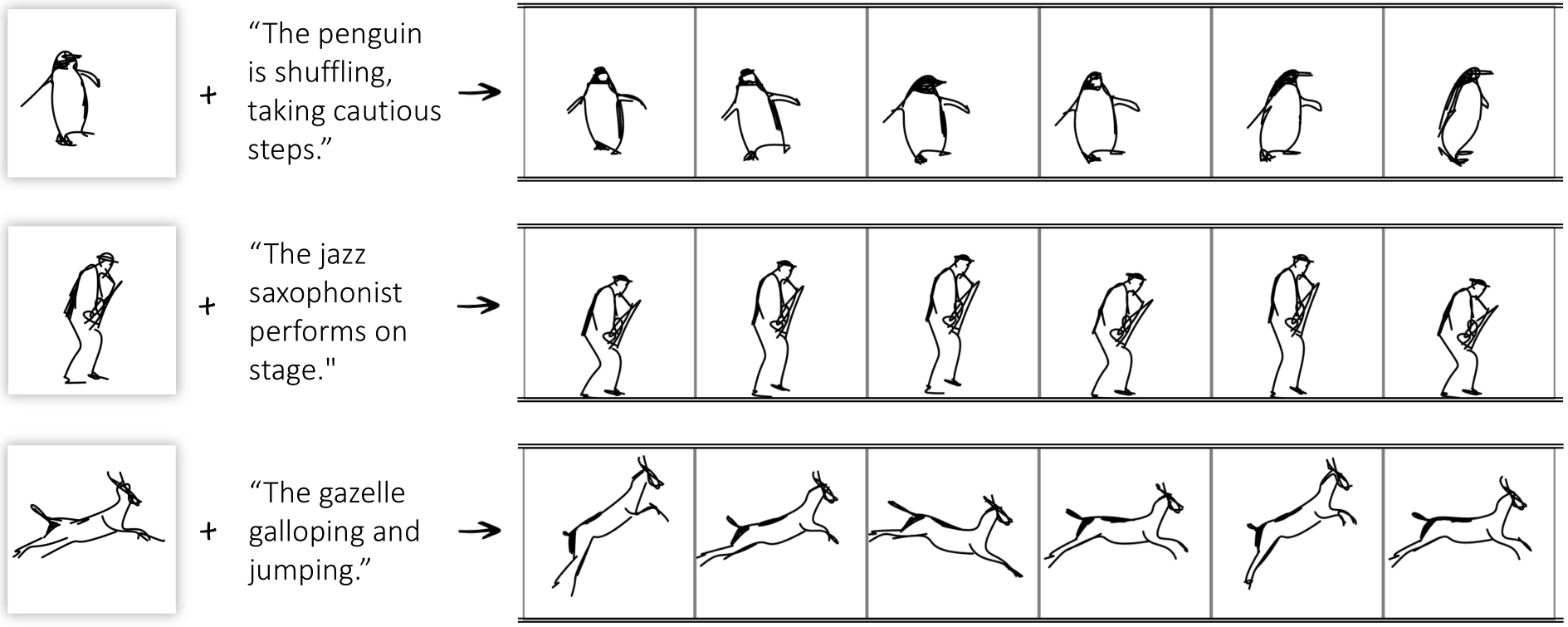
Figure 1. Given a still sketch in vector format and a text prompt describing a desired action, our method automatically animates the drawing with respect to the prompt. Please see the full animations in our project page: https://livesketch.github.io/
A sketch is one of the most intuitive and versatile tools humans use to convey their ideas visually. An animated sketch opens another dimension to the expression of ideas and is widely used by designers for a variety of purposes. Animating sketches is a laborious process, requiring extensive experience and professional design skills. In this work, we present a method that automatically adds motion to a single-subject sketch (hence, “breathing life into it”), merely by providing a text prompt indicating the desired motion. The output is a short animation provided in vector representation, which can be easily edited. Our method does not require extensive training, but instead leverages the motion prior of a large pretrained text-to-video diffusion model using a score-distillation loss to guide the placement of strokes. To promote natural and smooth motion and to better preserve the sketch’s appearance, we model the learned motion through two components. The first governs small local deformations and the second controls global affine transformations. Surprisingly, we find that even models that struggle to generate sketch videos on their own can still serve as a useful backbone for animating abstract representations.
Sketches serve as a fundamental and intuitive tool for visual expression and communication [3, 20, 25]. Sketches capture the essence of visual entities with a few strokes, allowing humans to communicate abstract visual ideas. In this paper, we propose a method to “breathe life” into a static sketch by generating semantically meaningful short videos from it. Such animations can be useful for storytelling, illustrations, websites, presentations, and just for fun.
Animating sketches using conventional tools (such as Adobe Animate and Toon Boom) is challenging even for experienced designers [75], requiring specific artistic expertise. Hence, long-standing research efforts in computer graphics sought to develop automatic tools to simplify this process. However, these tools face multiple hurdles, such as a need to identify the semantic component of the sketch, or learning to create motion that appears natural. As such, existing methods commonly rely on user-annotated skeletal key points [17, 73] or user-provided reference motions that align with the sketch semantics [9, 75, 87].
In this work, we propose to bring a given static sketch to life, based on a textual prompt, without the need for any human annotations or explicit reference motions. We do so by leveraging a pretrained text-to-video diffusion model [42]. Several recent works propose using the prior of such models to bring life to a static image [62, 83, 93]. However, sketches pose distinct challenges, which existing methods fail to tackle as they are not designed with this domain in mind. Our method takes the recent advancement in text-to-video models into this new realm, aiming to tackle the challenging task of sketch animation. For this purpose, we propose specific design choices considering the delicate characteristics of this abstract domain.
In line with prior sketch generation approaches [79, 80], we use a vector representation of sketches, defining a sketch as a set of strokes (cubic B´ezier curves) parameterized by their control points. Vector representations are popular among designers as they offer several advantages compared to pixel-based images. They are resolution-independent, i.e. can be scaled without losing quality. Moreover, they are easily editable: one can modify the sketch’s appearance by choosing different stroke styles or change its shape by dragging control points. Additionally, their sparsity promotes smooth motion while preventing pixelization and blurring. To bring a static sketch to life, we train a network to modify the stroke parameters for each video frame with respect to a given text prompt. Our method is optimization-based and requires no data or fine-tuning of large models. In addition, it can easily adapt to different text-to-video models, facilitating the use of future advancements in this field.
We seperate the object movement into two components: local motion and global motion. Local motion aims to capture isolated, local effects (a saxophone player bending their knee). Conversely, global motion affects the object shape as a whole and is modeled through a per-frame transformation matrix. It can thus capture rigid motion (a penguin hobbling across the frame), or coordinate effects (the same penguin growing in size as it approaches the camera). We find that this separation is crucial in generating motion that is both locally smooth and globally significant while remaining faithful to the original characteristics of the subject.
We animate sketches from various domains and demonstrate the effectiveness of our approach in producing smooth and natural motion that conveys the intent of the control text while better preserving the shape of the input sketch.
We compare our results with recent pixel-based ap-
We train the network using a score-distillation sampling (SDS) loss [66]. This loss was designed to leverage pretrained text-to-image diffusion models for the optimization of non-pixel representations (e.g., NeRFs [54, 57] or SVGs [37, 38]) to meet given text-based constraints. We use this loss to extract motion priors from pretrained textto-video diffusion models [31, 72, 83]. Importantly, this allows us to inherit the internet-scale knowledge embedded in such models, enabling animation for a wide range of subjects across multiple categories.
proaches highlighting the advantage of vector-based animation in the sketch domain. Our work allows anyone to breath life into their sketch in a simple and intuitive manner.
Sketches Free-hand sketching is a valuable tool for expressing ideas, concepts, and actions [20, 21, 29]. Extensive research has been conducted on the automatic generation of sketches [94]. Some works utilize pixel representation [39, 46, 74, 90], while others employ vector representation [6, 7, 13, 27, 49, 51, 55, 59, 69]. Several works propose a unified algorithm to produce sketches with a variety of styles [11, 52, 96] or at varying levels of abstraction [5, 60, 79, 80]. Traditional methods for sketch generation commonly rely on human-drawn sketch datasets. More recently, some works [22, 79, 80] incorporated the prior of large pretrained language-vision models to eliminate the dependency on such datasets. We also rely on such priors, and use a vector-based approach to depict our sketches, as it is a more natural representation for sketches and finds widespread use in character animation.
Sketch-based animation A long-standing area of interest in computer graphics aims to develop intuitive tools for creating life-like animations from still inputs. In character animation, motion is often represented as a temporal sequence of poses. These poses are commonly represented via user provided annotations, such as stick figures [14], skeletons [45, 64], or partial bone lines [63]. An alternative line of work represents motion through user provided 2D paths [15, 24, 35, 77], or through space-time curves [26]. However, these approaches still require some expertise and manual work to adjust different keyframes. Some methods assist animation by interactively predicting what users will draw next [1, 81, 91]. However, they still require manual sketching operations for each keyframe.
Rather than relying on user-created motion, some works propose to extract motion from real videos by statistical analysis of datasets [58], or using dynamic deformations extracted from driving videos [75]. Others turn to physicallybased motion effects [40, 92], or learn to synthesize animations of hand-drawn 2D characters using images of the character in various poses [17, 30, 67]. Zhang et al. [98] presented a method for transferring motion between vectorgraphics videos using a “motion vectorization” pipeline.
Drawing on 3D literature, some works aim to ”wake up” a photo or a painting, extracting a textured human mesh from the image and moving it using pre-defined animations [32, 41, 86]. More recently, given a hand-drawn sketch of a human figure, Smith et al. [73] construct a character rig onto which they re-target motion capture data. Their approach is similarly limited to human figures and a predefined set of movements. Moreover, it commonly requires
direct human intervention to fix skeleton joint estimations.
In contrast to these methods, our method requires only a single sketch and no skeletons or explicit references. Instead, it leverages the strong prior of text-to-video generative models and generalizes across a wide range of animations described by free-form prompts.
Text-to-video generation Early works explored expanding the capabilities of recurrent neural networks [4, 10, 16], GANs [43, 50, 65, 78, 100], and auto-regressive transformers [85, 88, 89, 95] from image generation to video generation. However, these works primarily focused on generating videos within limited domains.
More recent research extends the capabilities of powerful text-to-image diffusion models to video generation by incorporating additional temporal attention modules into existing models or by temporally aligning an image decoder [8, 53, 71, 84]. Commonly, such alignment is performed in a latent space [2, 19, 48, 53, 82, 99]. Others train cascaded diffusion models [31], or learn to directly generate videos within a lower-dimensional 3D latent space [28].
We propose to extract the motion prior from such models [72] and apply it to a vector sketch representation.
Image-to-video generation A closely related research area is image-to-video generation, where the goal is to animate an input image. Make-It-Move [33] train an encoderdecoder architecture to generate video sequences conditioned on an input image and a driving text prompt. Latent Motion Diffusion [34] learn the optical flow between pairs of video frames and use a 3D-UNet-based diffusion model to generate the resulting video sequence. CoDi [76] align multiple modalities (text, image, audio, and video) to a shared conditioning space and output space. ModelScope [82] train a latent video diffusion model, conditioned on an image input. Others first caption an image, then use the caption to condition a text-to-video model [53]. VideoCrafter [12] train a model conditioned on both text and image, with a special focus preserving the content, structure, and style of this image. Gen-2 [70] also operate in this domain, though their model’s details are not public.
While showing impressive results in the pixel domain, these methods struggle to generalize to sketches. Our method is designed for sketches, constraining the outputs to vector representations that better preserve both the domain, and the characteristics of the input sketch.
Vector representation Vector graphics allow us to create visual images directly from geometric shapes such as points, lines, curves, and polygons. Unlike raster images (represented with pixels), vector representation is resolution-free, more compact, and easier to modify. This quality makes vector images the preferred choice for various design applications, such as logo design, prints, animation, CAD, typography, web design, infographics, and illustrations. Scalable Vector Graphics (SVG) stands out as a popular vector image format due to its excellent support for interactivity and animation. We employ a differentiable rasterizer [47] to convert a vector image into its pixel-based image. This lets us manipulate the vector content using raster-based loss functions, as described below.
Score-Distillation Sampling The score-distillation sampling (SDS) loss, first proposed in Poole et al. [66], serves as a means for extracting a signal from a pretrained text-to-image diffusion model.
In their seminal work, Poole et al. propose to first use a parametric image synthesis model (e.g., a NeRF [56]) to generate an image x. This image is then noised to some intermediate diffusion time step t:
![]()
where  are parameters dependant on the noising schedule of the pretrained diffusion model, and
are parameters dependant on the noising schedule of the pretrained diffusion model, and ![]() is a noise sample.
is a noise sample.
The noised image is then passed through the diffusion model, conditioned on a text-prompt c describing some desired scene. The diffusion model’s output, ![]() , is a prediction of the noise added to the image. The deviation of this prediction from the true noise,
, is a prediction of the noise added to the image. The deviation of this prediction from the true noise, ![]() , can serve as a measure of the difference between the input image and one that better matches the prompt. This measure can then be used to approximate the gradients to the initial image synthesis model’s parameters,
, can serve as a measure of the difference between the input image and one that better matches the prompt. This measure can then be used to approximate the gradients to the initial image synthesis model’s parameters, 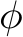 , that would better align its outputs with the prompt. Specifically,
, that would better align its outputs with the prompt. Specifically,

where w(t) is a constant that depends on ![]() . This optimization process is repeated, with the parametric model converging toward outputs that match the conditioning prompt.
. This optimization process is repeated, with the parametric model converging toward outputs that match the conditioning prompt.
In our work, we use this approach to extract the motion prior learned by a text-to-video diffusion model.
Our method begins with two inputs: a user-provided static sketch in vector format, and a text prompt describing the desired motion. Our goal is to generate a short video, in the same vector format, which depicts the sketched subject acting in a manner consistent with the prompt. We therefore define three objectives that our approach should strive to meet: (1) the output video should match the text prompt, (2) the characteristics of the original sketch should be preserved, and (3) the generated motion should appear natural and smooth. Below, we outline the design choices we use to meet each of these objectives.
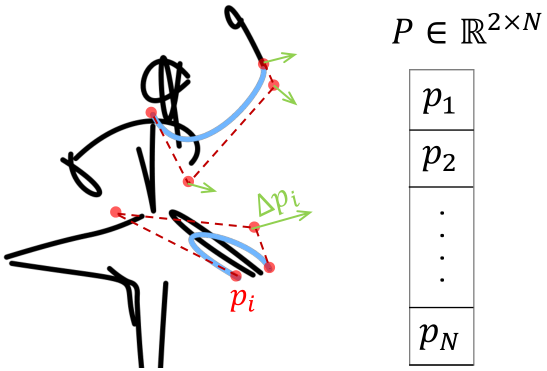
Figure 2. Data representation. Each curve (black/blue) is a cubic B´ezier curve with 4 control points (red, shown for blue curves). The total number of control points in the sketch is denoted by N. For each frame and point ![]() , we learn a displacement
, we learn a displacement ![]()
4.1. Representation
The input vector image is represented as a set of strokes placed over a white background, where each stroke is a twodimensional B´ezier curve with four control points. Each control point is represented by its coordinates: ![]()
![]() . We denote the set of control points in a single frame with
. We denote the set of control points in a single frame with ![]() , where N denotes the total number of points in the input sketch (see Figure 2). This number will remain fixed across all generated frames. We define a video with k frames as a sequence of k such sets of control points, and denote it by
, where N denotes the total number of points in the input sketch (see Figure 2). This number will remain fixed across all generated frames. We define a video with k frames as a sequence of k such sets of control points, and denote it by  .Let
.Let 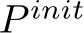 denote the set of points in the initial sketch.
denote the set of points in the initial sketch.
control points, and denote it by 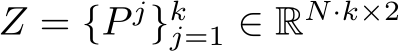 .Let
.Let 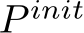 denote the set of points in the initial sketch. We duplicate
denote the set of points in the initial sketch. We duplicate 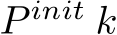 times to create the initial set of frames
times to create the initial set of frames ![]() . Our goal is to convert such a static sequence of frames into a sequence of frames animating the subject according to the motion described in the text prompt. We formulate this task as learning a set of 2D displacements
. Our goal is to convert such a static sequence of frames into a sequence of frames animating the subject according to the motion described in the text prompt. We formulate this task as learning a set of 2D displacements 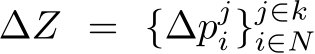 , indicating the displacement of each point
, indicating the displacement of each point ![]() , for each frame j (Fig. 2, in green).
, for each frame j (Fig. 2, in green).
4.2. Text-Driven Optimization
We begin by addressing our first objective: creating an output animation that aligns with the text prompt. We model the animation using a “neural displacement field” (Sec. 4.3), a small network M that receives as input the initial point set ![]() and predicts their displacements
and predicts their displacements ![]() . To train this network, we distill the motion prior encapsulated in a pretrained text-to-video diffusion model [83], using the SDS loss of Eq. (2).
. To train this network, we distill the motion prior encapsulated in a pretrained text-to-video diffusion model [83], using the SDS loss of Eq. (2).
At each training iteration (illustrated in Fig. 3), we add the predicted displacement vector ![]() (marked in purple) to the initial set of points
(marked in purple) to the initial set of points ![]() to form the sequence Z. We then use a differentiable rasterizer R [47], to transfer each set of per-frame points
to form the sequence Z. We then use a differentiable rasterizer R [47], to transfer each set of per-frame points ![]() to its corresponding frame in pixel space, denoted as
to its corresponding frame in pixel space, denoted as ![]() . The animated sketch is then defined by the concatenation of the rasterized frames,
. The animated sketch is then defined by the concatenation of the rasterized frames, ![]() .
.
Next, we sample a diffusion timestep t and noise ![]() N (0, 1). We use these to add noise to the rasterized video
N (0, 1). We use these to add noise to the rasterized video
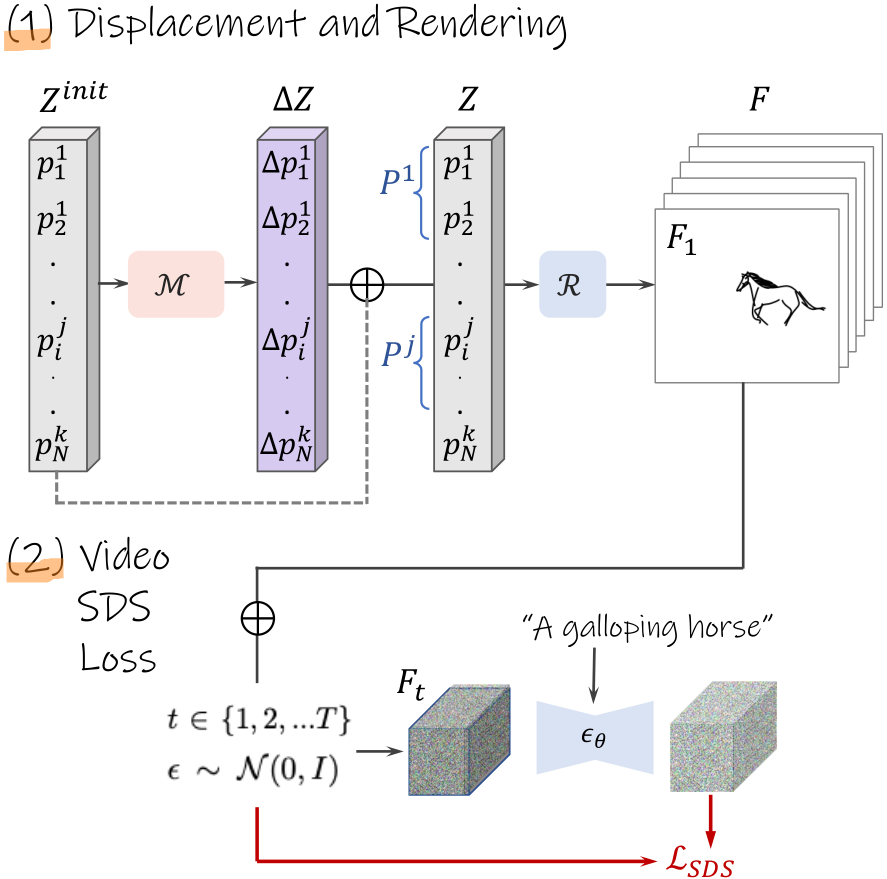
Figure 3. Text-driven optimization. At each training iteration: (1) We duplicate the initial control points across k frames and sum them with their predicted offsets. We render each frame and concatenate them to create the output video. (2) We use the SDS loss to extract a signal from a pretrained text-to-video model, which is used to update M, the model that predicts the offsets.
according to the diffusion schedule, creating ![]() . This noisy video is then denoised using the pretrained text-to-video diffusion model
. This noisy video is then denoised using the pretrained text-to-video diffusion model ![]() , where the diffusion model is conditioned on a prompt describing an animated scene (e.g., “a galloping horse”). Finally, we use Eq. (2) to update the parameters of M and repeat the process iteratively.
, where the diffusion model is conditioned on a prompt describing an animated scene (e.g., “a galloping horse”). Finally, we use Eq. (2) to update the parameters of M and repeat the process iteratively.
The SDS loss thus guides M to learn displacements whose corresponding rasterized animation aligns with the desired text prompt. The extent of this alignment, and hence the intensity of the motion, is determined by optimization hyperparameters such as the diffusion guidance scale and learning rates. However, we find that increasing these parameters typically leads to artifacts such as jitter and shapedeformations, compromising both the fidelity of the original sketch and the fluidity of natural motion (see Sec. 5.2). As such, SDS alone fails to address our additional goals: (2) preserving the input sketch characteristics, and (3) creating natural motion. Instead, we tackle these goals through the design of our displacement field, M.
4.3. Neural Displacement Field
We approach the network design with the intent of producing smoother motion with reduced shape deformations. We hypothesize that the artifacts observed with the unconstrained SDS optimization approach can be attributed in part to two mechanisms: (1) The SDS loss can be minimized by deforming the generated shape into one that better aligns with the text-to-video model’s semantic prior
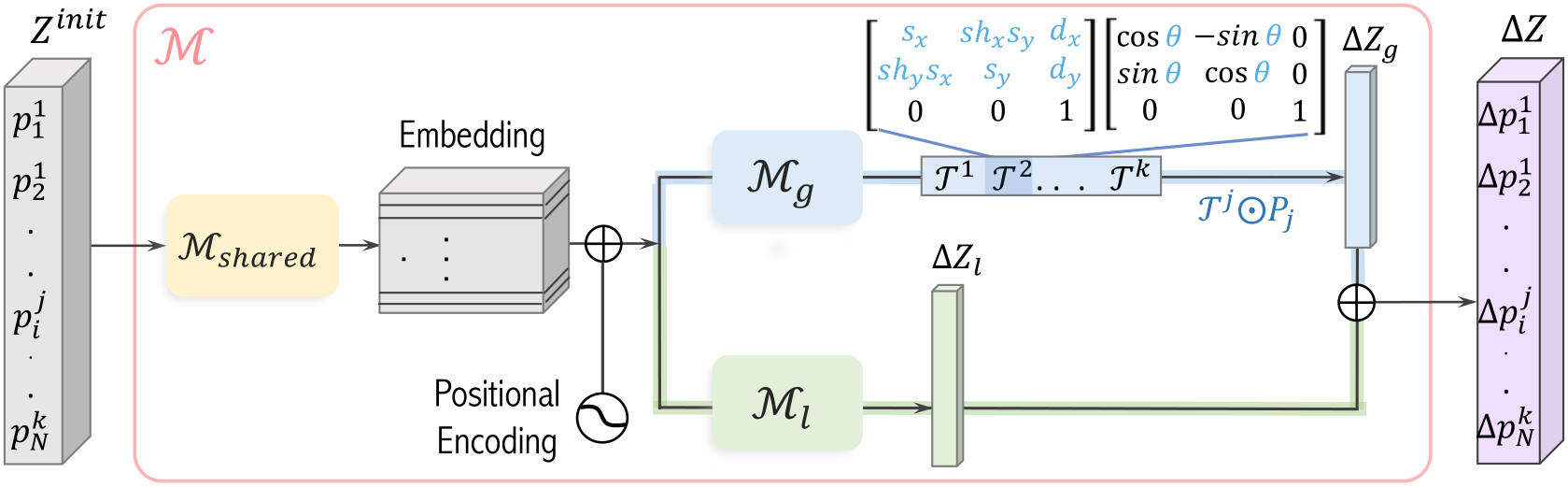
Figure 4. Network architecture. The input to the network is the initial set of control points 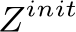 (left, gray), and the output is a set of displacements
(left, gray), and the output is a set of displacements ![]() . The network consists of three parts: Each control point
. The network consists of three parts: Each control point 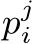 is projected with
is projected with ![]() into a latent representation and summed with a positional encoding. These point features are passed to two different branches to predict global and local motion. The local motion predictor
into a latent representation and summed with a positional encoding. These point features are passed to two different branches to predict global and local motion. The local motion predictor ![]() (green) is a simple MLP that predicts an offset for each point (
(green) is a simple MLP that predicts an offset for each point (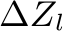 ), representing unconstrained local motion. The global motion predictor
), representing unconstrained local motion. The global motion predictor ![]() (blue) predicts a per-frame transformation matrix
(blue) predicts a per-frame transformation matrix ![]() which applies scaling, shear, rotation, and translation.
which applies scaling, shear, rotation, and translation. ![]() is then applied to all points
is then applied to all points  in the corresponding frame to produce
in the corresponding frame to produce ![]() is given by the sum:
is given by the sum: ![]()
(e.g., prompting for a scuttling crab may lead to undesired changes in the shape of the crab itself). (2) Smooth motion requires small displacements at the local scale, and the network struggles to reconcile these with the large changes required for global translations. We propose to tackle both of these challenges by modeling our motion through two components: An unconstrained local-motion path, which models small deformations, and a global path which models affine transformations applied uniformly to an entire frame. This split will allow the network to separately model motion along both scales while restricting semantic changes in the path that controls greater scale movement. Below we outline the specific network design choices, as well as the parametrization that allows us to achieve this split.
Shared backbone Recall that our network, illustrated in Fig. 4, aims to map the initial control point set ![]() to their per-frame displacements
to their per-frame displacements ![]() . Our first step is to create a shared feature backbone which will feed the separate motion paths. This component is built of an embedding step, where the coordinates of each control point are projected using a shared matrix
. Our first step is to create a shared feature backbone which will feed the separate motion paths. This component is built of an embedding step, where the coordinates of each control point are projected using a shared matrix ![]() , and then summed with a positional encoding that depends on the frame index, and on the order of the point in the sketch. These point features are then fed into two parallel prediction paths: local, and global (Fig. 4, green and blue paths, respectively).
, and then summed with a positional encoding that depends on the frame index, and on the order of the point in the sketch. These point features are then fed into two parallel prediction paths: local, and global (Fig. 4, green and blue paths, respectively).
Local path The local path is parameterized by ![]() , a small MLP that takes the shared features and maps them to an offset
, a small MLP that takes the shared features and maps them to an offset 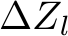 for every control point in
for every control point in ![]() . Here, the goal is to allow the network to learn unconstrained motion on its own to best match the given prompt. Indeed, in Sec. 5 we show that an unconstrained branch is crucial for the model to create meaningful motion. On the other hand, using this path to create displacements on the scale needed for global changes requires stronger SDS guidance or larger learning rates, leading to jitter and unwanted deformations at the local level. Hence, we delegate these changes to the global motion path. We note that similar behavior can be observed when directly optimizing the control points (i.e. without a network, following [37, 38], see Sec. 5.2).
. Here, the goal is to allow the network to learn unconstrained motion on its own to best match the given prompt. Indeed, in Sec. 5 we show that an unconstrained branch is crucial for the model to create meaningful motion. On the other hand, using this path to create displacements on the scale needed for global changes requires stronger SDS guidance or larger learning rates, leading to jitter and unwanted deformations at the local level. Hence, we delegate these changes to the global motion path. We note that similar behavior can be observed when directly optimizing the control points (i.e. without a network, following [37, 38], see Sec. 5.2).
Global path The goal of the global displacement prediction branch is to allow the model to capture meaningful global movements such as center-of-mass translation, rotation, or scaling, while maintaining the object’s original shape. This path consists of a neural network, 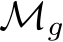 , that predicts a single global transformation matrix for each frame
, that predicts a single global transformation matrix for each frame ![]() . The matrix is then used to transform all control points of that frame, ensuring that the shape remains coherent. Specifically, we model the global motion as the sequential application of scaling, shear, rotation, and translation. These are parameterized using their standard affine matrix form (Fig. 4), which contains two parameters each for scale, shear, and translation, and one for rotation. Denoting the successive application of these transforms for frame j by
. The matrix is then used to transform all control points of that frame, ensuring that the shape remains coherent. Specifically, we model the global motion as the sequential application of scaling, shear, rotation, and translation. These are parameterized using their standard affine matrix form (Fig. 4), which contains two parameters each for scale, shear, and translation, and one for rotation. Denoting the successive application of these transforms for frame j by ![]() , the global branch displacement for each point in this frame is then given by:
, the global branch displacement for each point in this frame is then given by:  .
.
We further extend the user’s control over the individual components of the generated motion by adding a scaling parameter for each type of transformation: ![]() and
and 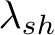 for translation, rotation, scale, and shear, respectively. For example, let
for translation, rotation, scale, and shear, respectively. For example, let  denote the network’s predicted translation parameters. We re-scale them as:
denote the network’s predicted translation parameters. We re-scale them as: 
![]() . This allows us to attenuate specific aspects of motion that are undesired. For example, we can keep a subject roughly stationary by setting
. This allows us to attenuate specific aspects of motion that are undesired. For example, we can keep a subject roughly stationary by setting  . By modeling global changes through constrained transformations, applied uniformly to the entire frame, we limit the model’s ability to create arbitrary deformations while preserving its ability to create large translations or coordinated effects.
. By modeling global changes through constrained transformations, applied uniformly to the entire frame, we limit the model’s ability to create arbitrary deformations while preserving its ability to create large translations or coordinated effects.

Figure 5. Qualitative results. Our model converts an initial sketch and a driving prompt describing some desired motion into a short video depicting the sketch moving according to the prompt. See the supplementary for the full videos and additional results.
Our final predicted displacements ![]() are the sum of the two branches:
are the sum of the two branches: ![]() . The strength of these two terms (governed by the learning rates and guidance scales used to optimize each branch) will affect a tradeoff between our first goal (text-to-video alignment), and the other two goals (preserving the shape of the sketch and creating smooth and natural motion). As such, users can use this tradeoff to gain additional control over the generated video. For instance, prioritizing the preservation of sketch appearance by using a low learning rate for the local path, while affording greater freedom to global motion. See supplementary for examples.
. The strength of these two terms (governed by the learning rates and guidance scales used to optimize each branch) will affect a tradeoff between our first goal (text-to-video alignment), and the other two goals (preserving the shape of the sketch and creating smooth and natural motion). As such, users can use this tradeoff to gain additional control over the generated video. For instance, prioritizing the preservation of sketch appearance by using a low learning rate for the local path, while affording greater freedom to global motion. See supplementary for examples.
4.4. Training Details
We alternate between optimizing the local path and optimizing the global path. The shared backbone is optimized in both cases. Unless otherwise noted, we set the SDS guidance scale to 30 for the local path and 40 for the global path. We use Adam [44] with a learning rate of  for the global path and a learning rate of
for the global path and a learning rate of ![]() for the local path. We find it useful to apply augmentations (random crops and perspective transformations) to the rendered videos during training. We further set
for the local path. We find it useful to apply augmentations (random crops and perspective transformations) to the rendered videos during training. We further set ![]()
![]() . For our diffusion backbone, we use ModelScope text-to-video [82], but observe similar results with other backbones (see the supplementary file).
. For our diffusion backbone, we use ModelScope text-to-video [82], but observe similar results with other backbones (see the supplementary file).
We optimize the networks for 1, 000 steps, taking roughly 30 minutes per video on a single A100 GPU. In practice, the model often converges after 500 steps (15 minutes). For additional training details, see the supplementary.
We begin by showcasing our method’s ability to animate a diverse set of sketches, following an array of text prompts (see Fig. 5 and supplementary videos). Our method can cap-
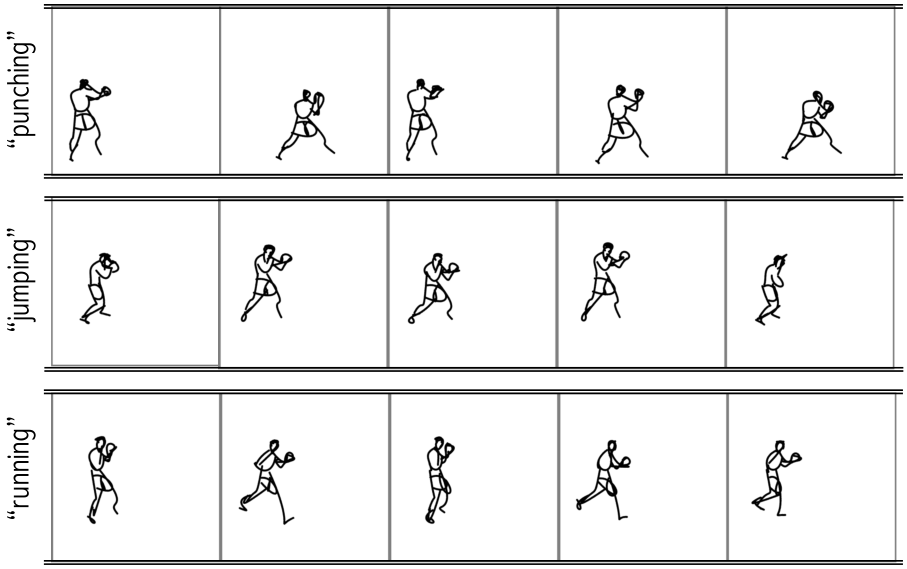
Figure 6. Our method can be used to animate the same sketch according to different prompts. These are typically restricted to actions that the portrayed subject would naturally perform. See the supplementary videos for more examples.
ture the delicate swaying of a dolphin in the water, follow a ballerina’s dance routine, or mimic the gentle motion of wine swirling in a glass. Notably, it can apply these motions to sketches without any common skeleton or an explicit notation of parts. Moreover, our approach can animate the same sketch using different prompts (see Fig. 6), extending the freedom and diversity of text-to-video models to the more abstract sketch domain. Additional examples and full videos can be found in the supplementary materials.
5.1. Comparisons
As no prior art directly tackles the reference-free sketch animation task, we explore two alternative approaches: pixel-based image-to-video approaches, and skeleton-based methods that build on pre-defined motions.
In the pixel-based scenario, we compare our method with four models: (1) ZeroScope image-to-video [53] which au-
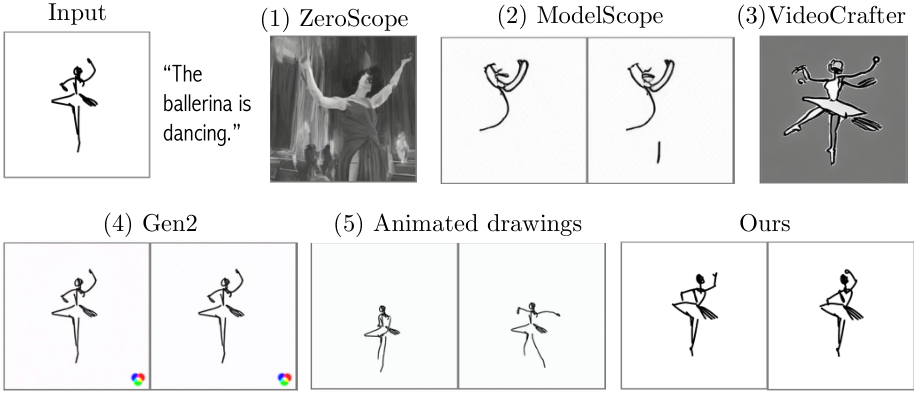
Figure 7. Qualitative comparisons. Image-to-video models suffer from artifacts and struggle to preserve the sketch shape (or even remain in a sketch domain). Animated drawings relies on skeletons and pre-captured reference motions. Hence, it cannot generalize to new domains. See the supplementary videos for more examples.
tomatically captions the image [97] and uses the caption to prompt a text-to-video model. (2) ModelScope [82] image-to-video, which is directly conditioned on the image. (3) VideoCrafter [12] which is conditioned on both the image and the given text prompt, and (4) Gen-2 [70], a commercial web-based tool, conditioned on both image and text.
The results are shown in Fig. 7. We select representative frames from the output videos. The full videos are available in the supplementary material.
The results of ZeroScope and VideoCrafter show significant artifacts, and commonly fail to even produce a sketch. ModelScope fare batter, but struggle to preserve the shape of the sketch. Gen-2 either struggle to animate the sketch, or transforms it into a real image, depending on the input parameters (see the supplementary videos).
We further compare our approach with a skeleton and reference-based method [73] (Fig. 7, Animated Drawings). This method accounts for the sketch-based nature of our data and can better preserve its shape. However, it requires per-sketch manual annotations and is restricted to a predetermined set of human motions. Hence, it struggles to animate subjects which cannot be matched to a human skeleton, or whose motion does not align with the presets (see supplementary). In contrast, our method inherits the diversity of the text-to-video model and generalizes to multiple target classes without annotations or explicit references.
We additionally evaluate our method quantitatively. We compare with open methods that require no human intervention and can be evaluated at scale (ZeroScope [53], ModelScope [82], and Videocrafter [12]). We follow [79] and collect sketches spanning three categories: humans, animals, and objects. We asked ChatGPT to randomly select ten instances per category and suggest prompts describing their typical motion. We used CLIPasso [80] to generate a sketch for each subject. We applied our method and the alternative methods to these sketches and prompts, resulting in 30 animations per method (videos in the supplementary).
Following pixel-based methods [12, 19], we use CLIP [68] to measure the “sketch-to-video” consistency,
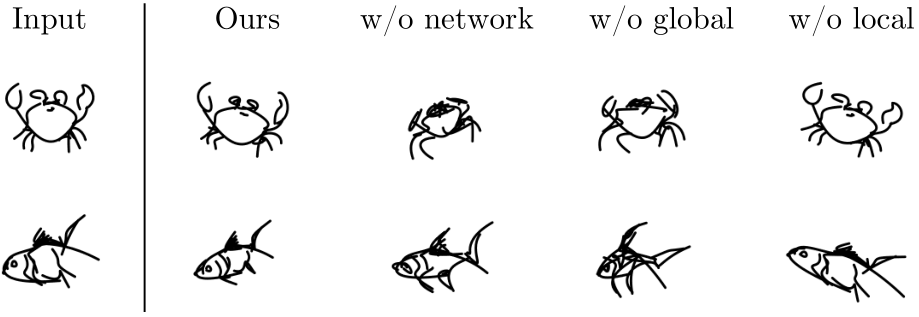
Figure 8. Qualitative ablation. Removing the neural network or the global path leads to shape deviations or jittery motion due to the need for higher learning rates (see supplementary videos). Modeling only global movement improves shape consistency, but fails to create realistic motion.
defined as the average cosine similarity between the video’s frames and the input sketch used to produce it.
We further evaluate the alignment between the generated videos and their corresponding prompts (“text-to-video alignment”). We use X-CLIP [61], a model that extends CLIP to video recognition. Here, we compare to the only baseline which is jointly guided by both image and text [12].
All results are provided in Tab. 1a. Our method outperforms the baselines on sketch-to-video consistency. In particular, it achieves significant gains over ModelScope whose text-to-video model serves as our prior. Moreover, our approach better aligns with the prompted motion, despite the use of a weaker text-to-video model as a backbone. These results, and in particular the ModelScope scores, demonstrate the importance of the vector representation which assists us in successfully extracting a motion prior without the low quality and artifacts introduced when trying to create sketches in the pixel domain. To ensure the method’s performance generalizes to human-drawn sketches, we conduct further evaluations using the TU-Berlin sketch dataset [18]. Details and results are provided in the supplementary.
5.2. Ablation Study
We further validate our suggested components through an ablation study. In particular, we evaluate the effect of using the neural prior in place of direct coordinate optimization and the effect of the global-local separation.
Qualitative results are shown in Fig. 8 (the corresponding videos are provided in the supplementary materials). As can be observed, removing the neural network can lead to increased jitter and harms shape preservation. Removing the global path leads to diminished movement across the frame and less coherent shape transformations. In contrast, removing the local path leads to unrealistic wobbling while keeping the original sketch almost unchanged.
In Tab. 1b, we show quantitative results, following the same protocol as in Sec. 5.1. The sketch-to-video consistency results align with the qualitative observations. However, we observe that the metric for text-to-video alignment [61] is not sensitive enough to gauge the difference between our ablation setups (standard errors are larger than the gaps).

Table 1. Quantitative metrics. (a) CLIP-based consistency and text-video alignment comparisons to open-source image-to-video baselines. (b) The same CLIP-metrics used for an ablation study. (c) User study results. We pit our full model against each ablation setup. The blue bar indicates the percent of responders that preferred our full model over each baseline. Dashed area is one standard error.
We additionally conduct a user study, based on a twoalternative forced-choice setup. Each user is shown two videos (one output from the full method, and one from a random ablation setup) and asked to select: (1) the video that better preserves the appearance of the initial sketch, and (2) the video that better matches the motion outlined in the prompt. We collected responses from 31 participants over 30 pairs. The results are provided in Tab. 1c.
Users considered the full method’s text-to-video alignment to be on-par or better than all ablation setups. When considering sketch-to-video consistency, our method is preferred over both setups that create reasonable motion (no network and no global). Removing the local path leads to higher consistency with respect to the original frame, largely because the sketch remains almost unchanged. Our full method allows for more expressive motion, while still showing remarkable preservation of the input sketch.
In the supplementary materials, we provide further analysis on the effects of our hyperparameter choices, and highlight an emergent trade-off between shape preservation and the quality of generated motion.
While our work enables sketch-animation across various classes and prompts, it comes with limitations. First, we build upon the sketch representation of [80]. However, sketches can be represented in many forms with different types of curves and primitive shapes. Using our method with other sketch representations could result in performance degradation. For instance, in Fig. 9(1) the surfer’s scale has significantly changed. Similarly, sketches with C1 continuity are not supported by the differentiable rasterizer, and hence cannot be used with our method. Addressing the diversity of vector sketches requires further development.
Second, our method assumes a single-subject input sketch (a common scenario in character animation techniques). When applied to scene sketches or sketches with multiple objects, we observe reduced result quality. For example in Fig. 9(2), the basketball cannot be separated from the player, contrary to the natural motion of dribbling.
Third, our method faces a trade-off between motion quality and sketch fidelity, and a diligent balance should
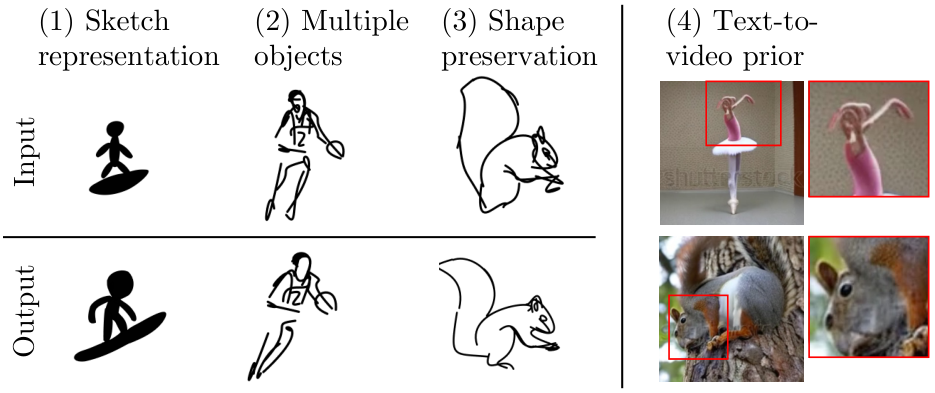
Figure 9. Method limitations. The method may struggle with certain sketch representations, fail to tackle multiple objects or complex scenes, or create undesired shape changes. Moreover, it is restricted to motions which the text-to-video prior can create.
be achieved between the two. In Fig. 9(3), the animated squirrel’s appearance differs from the input sketch. This is more apparent with sketches that deviate significantly from the standard depiction of the subject (e.g. amateur drawings of animals). There, the diffusion prior is highly motivated to “fix” the shape, before adding motion. The trade-off is further discussed in the supplementary material. Potential improvement lies in adopting a mesh-based representation with an approximate rigidity loss [36], or by trying to enforce consistency in the diffusion feature space [23].
Finally, our approach inherits the limitations of text-to-video priors. These are trained on large-scale data, but may be unaware of specific motions, portray strong biases, or produce significant artifacts (Fig. 9, right). However, our method is agnostic to the backbone model and hence could likely by used with better models as they become available.
We presented a technique to breath life into a given static sketch, following a text prompt. Our method builds on the motion prior captured by powerful text-to-video models. We show that even though these models struggle with generating sketches directly, they can still comprehend such abstract representations in a semantically meaningful way, creating smooth and appealing motions. We hope that our work will facilitate further research to provide intuitive and practical tools for sketch animation that incorporate recent advances in text-based video generation.
[1] Aseem Agarwala, Aaron Hertzmann, David Salesin, and Steven Seitz. Keyframe-based tracking of rotoscoping and animation. ACM Trans. Graph., 23:584–591, 2004. 2
[2] Jie An, Songyang Zhang, Harry Yang, Sonal Gupta, JiaBin Huang, Jiebo Luo, and Xi Yin. Latent-shift: Latent diffusion with temporal shift for efficient text-to-video generation. arXiv preprint arXiv:2304.08477, 2023. 3
[3] Maxime Aubert, Adam Brumm, Muhammad Ramli, Thomas Sutikna, E Wahyu Saptomo, Budianto Hakim, Michael J Morwood, Gerrit D van den Bergh, Leslie Kinsley, and Anthony Dosseto. Pleistocene cave art from sulawesi, indonesia. Nature, 514(7521):223–227, 2014. 1
[4] Mohammad Babaeizadeh, Chelsea Finn, Dumitru Erhan, Roy H Campbell, and Sergey Levine. Stochastic variational video prediction. arXiv preprint arXiv:1710.11252, 2017. 3
[5] Itamar Berger, Ariel Shamir, Moshe Mahler, Elizabeth Carter, and Jessica Hodgins. Style and abstraction in portrait sketching. ACM Trans. Graph., 32(4), 2013. 2
[6] Ayan Kumar Bhunia, Ayan Das, Umar Riaz Muhammad, Yongxin Yang, Timothy M. Hospedales, Tao Xiang, Yulia Gryaditskaya, and Yi-Zhe Song. Pixelor: a competitive sketching ai agent. so you think you can sketch? ACM Trans. Graph., 39:166:1–166:15, 2020. 2
[7] Ankan Kumar Bhunia, Salman Khan, Hisham Cholakkal, Rao Muhammad Anwer, Fahad Shahbaz Khan, Jorma Laaksonen, and Michael Felsberg. Doodleformer: Creative sketch drawing with transformers. ECCV, 2022. 2
[8] Andreas Blattmann, Robin Rombach, Huan Ling, Tim Dockhorn, Seung Wook Kim, Sanja Fidler, and Karsten Kreis. Align your latents: High-resolution video synthesis with latent diffusion models. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2023. 3
[9] Christoph Bregler, Lorie Loeb, Erika Chuang, and Hrishi Deshpande. Turning to the masters: Motion capturing cartoons. ACM Transactions on Graphics (TOG), 21(3):399– 407, 2002. 1
[10] Lluis Castrejon, Nicolas Ballas, and Aaron Courville. Improved conditional vrnns for video prediction. In Proceedings of the IEEE/CVF international conference on computer vision, pages 7608–7617, 2019. 3
[11] Caroline Chan, Fr´edo Durand, and Phillip Isola. Learning to generate line drawings that convey geometry and semantics. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7915–7925, 2022. 2
[12] Haoxin Chen, Menghan Xia, Yingqing He, Yong Zhang, Xiaodong Cun, Shaoshu Yang, Jinbo Xing, Yaofang Liu, Qifeng Chen, Xintao Wang, Chao Weng, and Ying Shan. Videocrafter1: Open diffusion models for high-quality video generation, 2023. 3, 7
[13] Yajing Chen, Shikui Tu, Yuqi Yi, and Lei Xu. Sketch-pix2seq: a model to generate sketches of multiple categories. ArXiv, abs/1709.04121, 2017. 2
[14] James Davis, Maneesh Agrawala, Erika Chuang, Zoran Popovi´c, and David Salesin. A sketching interface for ar-
ticulated figure animation. In Acm siggraph 2006 courses, pages 15–es. 2006. 2
[15] Richard C. Davis, Brien Colwell, and James A. Landay. Ksketch: A ’kinetic’ sketch pad for novice animators. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, page 413–422, New York, NY, USA, 2008. Association for Computing Machinery. 2
[16] Emily Denton and Rob Fergus. Stochastic video generation with a learned prior. In International conference on machine learning, pages 1174–1183. PMLR, 2018. 3
[17] Marek Dvoroˇzn´ak, Wilmot Li, Vladimir G Kim, and Daniel S`ykora. Toonsynth: example-based synthesis of handcolored cartoon animations. ACM Transactions on Graphics (TOG), 37(4):1–11, 2018. 1, 2
[18] Mathias Eitz, James Hays, and Marc Alexa. How do humans sketch objects? ACM Trans. Graph. (Proc. SIGGRAPH), 31(4):44:1–44:10, 2012. 7
[19] Patrick Esser, Johnathan Chiu, Parmida Atighehchian, Jonathan Granskog, and Anastasis Germanidis. Structure and content-guided video synthesis with diffusion models. arXiv preprint arXiv:2302.03011, 2023. 3, 7
[20] Judy Fan, Wilma A. Bainbridge, Rebecca Chamberlain, and Jeffrey D. Wammes. Drawing as a versatile cognitive tool. Nature Reviews Psychology, 2:556 – 568, 2023. 1, 2
[21] Judith E. Fan, Daniel L. K. Yamins, and Nicholas B. TurkBrowne. Common object representations for visual production and recognition. Cognitive science, 42 8:2670–2698, 2018. 2
[22] Kevin Frans, Lisa B. Soros, and Olaf Witkowski. Clipdraw: Exploring text-to-drawing synthesis through language-image encoders. CoRR, abs/2106.14843, 2021. 2
[23] Michal Geyer, Omer Bar-Tal, Shai Bagon, and Tali Dekel. Tokenflow: Consistent diffusion features for consistent video editing. arXiv preprint arxiv:2307.10373, 2023. 8
[24] Michael Gleicher. Motion path editing. In Proceedings of the 2001 Symposium on Interactive 3D Graphics, page 195–202, New York, NY, USA, 2001. Association for Computing Machinery. 2
[25] Ernst Hans Gombrich. The story of art. Phaidon London, 1995. 1
[26] Martin Guay, R´emi Ronfard, Michael Gleicher, and MariePaule Cani. Space-time sketching of character animation. ACM Transactions on Graphics (ToG), 34(4):1–10, 2015. 2
[27] David Ha and Douglas Eck. A neural representation of sketch drawings. CoRR, abs/1704.03477, 2017. 2
[28] Yingqing He, Tianyu Yang, Yong Zhang, Ying Shan, and Qifeng Chen. Latent video diffusion models for highfidelity long video generation. 2022. 3
[29] Aaron Hertzmann. Why do line drawings work? a realism hypothesis. Perception, 49:439 – 451, 2020. 2
[30] Tobias Hinz, Matthew Fisher, Oliver Wang, Eli Shechtman, and Stefan Wermter. Charactergan: Few-shot keypoint character animation and reposing. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 1988–1997, 2022. 2
[31] Jonathan Ho, William Chan, Chitwan Saharia, Jay Whang, Ruiqi Gao, Alexey Gritsenko, Diederik P Kingma, Ben
Poole, Mohammad Norouzi, David J Fleet, et al. Imagen video: High definition video generation with diffusion models. arXiv preprint arXiv:2210.02303, 2022. 2, 3
[32] Alexander Hornung, Ellen Dekkers, and Leif Kobbelt. Character animation from 2d pictures and 3d motion data. ACM Trans. Graph., 26(1):1–es, 2007. 2
[33] Yaosi Hu, Chong Luo, and Zhenzhong Chen. Make it move: controllable image-to-video generation with text descriptions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18219– 18228, 2022. 3
[34] Yaosi Hu, Zhenzhong Chen, and Chong Luo. Lamd: Latent motion diffusion for video generation, 2023. 3
[35] Takeo Igarashi, Rieko Kadobayashi, Kenji Mase, and Hidehiko Tanaka. Path drawing for 3d walkthrough. In Proceedings of the 11th Annual ACM Symposium on User Interface Software and Technology, page 173–174, New York, NY, USA, 1998. Association for Computing Machinery. 2
[36] Takeo Igarashi, Tomer Moscovich, and John F. Hughes. As-rigid-as-possible shape manipulation. ACM Trans. Graph., 24(3):1134–1141, 2005. 8
[37] Shir Iluz, Yael Vinker, Amir Hertz, Daniel Berio, Daniel Cohen-Or, and Ariel Shamir. Word-as-image for semantic typography. ACM Trans. Graph., 42(4), 2023. 2, 5
[38] Ajay Jain, Amber Xie, and Pieter Abbeel. Vectorfusion: Text-to-svg by abstracting pixel-based diffusion models. arXiv, 2022. 2, 5
[39] Moritz Kampelm¨uhler and Axel Pinz. Synthesizing humanlike sketches from natural images using a conditional convolutional decoder. CoRR, abs/2003.07101, 2020. 2
[40] Rubaiat Kazi, Fanny Chevalier, Tovi Grossman, Shengdong Zhao, and George Fitzmaurice. Draco: Bringing life to illustrations with kinetic textures. Conference on Human Factors in Computing Systems - Proceedings, 2014. 2
[41] Levon Khachatryan. Tex-an mesh: Textured and animatable human body mesh reconstruction from a single image. https://github.com/lev1khachatryan/Tex-An Mesh, 2020. 2
[42] Levon Khachatryan, Andranik Movsisyan, Vahram Tadevosyan, Roberto Henschel, Zhangyang Wang, Shant Navasardyan, and Humphrey Shi. Text2video-zero: Text-to-image diffusion models are zero-shot video generators. arXiv preprint arXiv:2303.13439, 2023. 2
[43] Doyeon Kim, Donggyu Joo, and Junmo Kim. Tivgan: Text to image to video generation with step-by-step evolutionary generator. IEEE Access, 8:153113–153122, 2020. 3
[44] Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014. 6
[45] Zohar Levi and Craig Gotsman. ArtiSketch: A System for Articulated Sketch Modeling. Computer Graphics Forum, 2013. 2
[46] Mengtian Li, Zhe Lin, Radomir Mech, Ersin Yumer, and Deva Ramanan. Photo-sketching: Inferring contour drawings from images, 2019. 2
[47] Tzu-Mao Li, Michal Luk´aˇc, Gharbi Micha¨el, and Jonathan Ragan-Kelley. Differentiable vector graphics rasterization for editing and learning. ACM Trans. Graph. (Proc. SIGGRAPH Asia), 39(6):193:1–193:15, 2020. 3, 4
[48] Xin Li, Wenqing Chu, Ye Wu, Weihang Yuan, Fanglong Liu, Qi Zhang, Fu Li, Haocheng Feng, Errui Ding, and Jingdong Wang. Videogen: A reference-guided latent diffusion approach for high definition text-to-video generation. arXiv preprint arXiv:2309.00398, 2023. 3
[49] Yi Li, Yi-Zhe Song, Timothy M. Hospedales, and Shaogang Gong. Free-hand sketch synthesis with deformable stroke models. CoRR, abs/1510.02644, 2015. 2
[50] Yitong Li, Martin Min, Dinghan Shen, David Carlson, and Lawrence Carin. Video generation from text. In Proceedings of the AAAI conference on artificial intelligence, 2018. 3
[51] Hangyu Lin, Yanwei Fu, Yu-Gang Jiang, and X. Xue. Sketch-bert: Learning sketch bidirectional encoder representation from transformers by self-supervised learning of sketch gestalt. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 6757–6766, 2020. 2
[52] Difan Liu, Matthew Fisher, Aaron Hertzmann, and Evangelos Kalogerakis. Neural strokes: Stylized line drawing of 3d shapes. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 14204– 14213, 2021. 2
[53] Zhengxiong Luo, Dayou Chen, Yingya Zhang, Yan Huang, Liang Wang, Yujun Shen, Deli Zhao, Jingren Zhou, and Tieniu Tan. Videofusion: Decomposed diffusion models for high-quality video generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023. 3, 6, 7
[54] Gal Metzer, Elad Richardson, Or Patashnik, Raja Giryes, and Daniel Cohen-Or. Latent-nerf for shape-guided generation of 3d shapes and textures. arXiv preprint arXiv:2211.07600, 2022. 2
[55] Daniela Mihai and Jonathon Hare. Learning to draw: Emergent communication through sketching. Advances in Neural Information Processing Systems, 34:7153–7166, 2021. 2
[56] Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis. In European Conference on Computer Vision, pages 405–421. Springer, 2020. 3
[57] Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis. Communications of the ACM, 65(1):99–106, 2021. 2
[58] Jianyuan Min, Yen-Lin Chen, and Jinxiang Chai. Interactive generation of human animation with deformable motion models. ACM Trans. Graph., 29(1), 2009. 2
[59] Haoran Mo, Edgar Simo-Serra, Chengying Gao, Changqing Zou, and Ruomei Wang. General virtual sketching framework for vector line art. ACM Transactions on Graphics (Proceedings of ACM SIGGRAPH 2021), 40 (4):51:1–51:14, 2021. 2
[60] Umar Riaz Muhammad, Yongxin Yang, Yi-Zhe Song, Tao Xiang, and Timothy M. Hospedales. Learning deep sketch abstraction. CoRR, abs/1804.04804, 2018. 2
[61] Bolin Ni, Houwen Peng, Minghao Chen, Songyang Zhang, Gaofeng Meng, Jianlong Fu, Shiming Xiang, and Haibin Ling. Expanding language-image pretrained models for general video recognition. 2022. 7
[62] Haomiao Ni, Changhao Shi, Kai Li, Sharon X. Huang, and Martin Renqiang Min. Conditional image-to-video generation with latent flow diffusion models, 2023. 2
[63] A. Cengiz ¨Oztireli, Ilya Baran, Tiberiu Popa, Boris Dalstein, Robert W. Sumner, and Markus Gross. Differential blending for expressive sketch-based posing. In Proceedings of the 2013 ACM SIGGRAPH/Eurographics Symposium on Computer Animation, New York, NY, USA, 2013. ACM. 2
[64] Junjun Pan and Jian J. Zhang. Sketch-Based SkeletonDriven 2D Animation and Motion Capture, pages 164–181. Springer Berlin Heidelberg, Berlin, Heidelberg, 2011. 2
[65] Yingwei Pan, Zhaofan Qiu, Ting Yao, Houqiang Li, and Tao Mei. To create what you tell: Generating videos from captions. In Proceedings of the 25th ACM international conference on Multimedia, pages 1789–1798, 2017. 3
[66] Ben Poole, Ajay Jain, Jonathan T Barron, and Ben Mildenhall. Dreamfusion: Text-to-3d using 2d diffusion. In The Eleventh International Conference on Learning Representations, 2022. 2, 3
[67] Omid Poursaeed, Vladimir Kim, Eli Shechtman, Jun Saito, and Serge Belongie. Neural puppet: Generative layered cartoon characters. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 3346–3356, 2020. 2
[68] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748–8763. PMLR, 2021. 7
[69] Leo Sampaio Ferraz Ribeiro, Tu Bui, John P. Collomosse, and Moacir Antonelli Ponti. Sketchformer: Transformer-based representation for sketched structure. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 14141–14150, 2020. 2
[70] Runway. Gen-2: Text driven video generation. https://research.runwayml.com/gen2, 2023. 3, 7
[71] Uriel Singer, Adam Polyak, Thomas Hayes, Xi Yin, Jie An, Songyang Zhang, Qiyuan Hu, Harry Yang, Oron Ashual, Oran Gafni, et al. Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:2209.14792, 2022. 3
[72] Uriel Singer, Shelly Sheynin, Adam Polyak, Oron Ashual, Iurii Makarov, Filippos Kokkinos, Naman Goyal, Andrea Vedaldi, Devi Parikh, Justin Johnson, et al. Text-to-4d dynamic scene generation. arXiv preprint arXiv:2301.11280, 2023. 2, 3
[73] Harrison Jesse Smith, Qingyuan Zheng, Yifei Li, Somya Jain, and Jessica K Hodgins. A method for animating children’s drawings of the human figure. ACM Transactions on Graphics, 42(3):1–15, 2023. 1, 2, 7
[74] Jifei Song, Kaiyue Pang, Yi-Zhe Song, Tao Xiang, and Timothy Hospedales. Learning to sketch with shortcut cycle consistency, 2018. 2
[75] Qingkun Su, Xue Bai, Hongbo Fu, Chiew-Lan Tai, and Jue Wang. Live sketch: Video-driven dynamic deformation of static drawings. In Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems, pages 1–12, 2018. 1, 2
[76] Zineng Tang, Ziyi Yang, Chenguang Zhu, Michael Zeng, and Mohit Bansal. Any-to-any generation via composable diffusion. 2023. 3
[77] Matthew Thorne, David Burke, and Michiel Van De Panne. Motion doodles: an interface for sketching character motion. ACM Transactions on Graphics (ToG), 23(3):424– 431, 2004. 2
[78] Yu Tian, Jian Ren, Menglei Chai, Kyle Olszewski, Xi Peng, Dimitris N. Metaxas, and Sergey Tulyakov. A good image generator is what you need for high-resolution video synthesis. In International Conference on Learning Representations, 2021. 3
[79] Yael Vinker, Yuval Alaluf, Daniel Cohen-Or, and Ariel Shamir. Clipascene: Scene sketching with different types and levels of abstraction. 2022. 2, 7
[80] Yael Vinker, Ehsan Pajouheshgar, Jessica Y. Bo, Roman Christian Bachmann, Amit Haim Bermano, Daniel Cohen-Or, Amir Zamir, and Ariel Shamir. Clipasso: Semantically-aware object sketching. ACM Trans. Graph., 41(4), 2022. 2, 7, 8
[81] Jue Wang, Yingqing Xu, Heung-Yeung Shum, and Michael F. Cohen. Video tooning. In ACM SIGGRAPH 2004 Papers, page 574–583, New York, NY, USA, 2004. Association for Computing Machinery. 2
[82] Jiuniu Wang, Hangjie Yuan, Dayou Chen, Yingya Zhang, Xiang Wang, and Shiwei Zhang. Modelscope text-to-video technical report. arXiv preprint arXiv:2308.06571, 2023. 3, 6, 7
[83] Xiang* Wang, Hangjie* Yuan, Shiwei* Zhang, Dayou* Chen, Jiuniu Wang, Yingya Zhang, Yujun Shen, Deli Zhao, and Jingren Zhou. Videocomposer: Compositional video synthesis with motion controllability. arXiv preprint arXiv:2306.02018, 2023. 2, 4
[84] Yaohui Wang, Xinyuan Chen, Xin Ma, Shangchen Zhou, Ziqi Huang, Yi Wang, Ceyuan Yang, Yinan He, Jiashuo Yu, Peiqing Yang, et al. Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:2309.15103, 2023. 3
[85] Dirk Weissenborn, Oscar T¨ackstr¨om, and Jakob Uszkoreit. Scaling autoregressive video models. arXiv preprint arXiv:1906.02634, 2019. 3
[86] Chung-Yi Weng, Brian Curless, and Ira KemelmacherShlizerman. Photo wake-up: 3d character animation from a single photo. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5901–5910, 2018. 2
[87] Chung-Yi Weng, Brian Curless, and Ira KemelmacherShlizerman. Photo wake-up: 3d character animation from a single photo. In Proceedings of the IEEE/CVF conference
on computer vision and pattern recognition, pages 5908– 5917, 2019. 1
[88] Chenfei Wu, Lun Huang, Qianxi Zhang, Binyang Li, Lei Ji, Fan Yang, Guillermo Sapiro, and Nan Duan. Godiva: Generating open-domain videos from natural descriptions. arXiv preprint arXiv:2104.14806, 2021. 3
[89] Chenfei Wu, Jian Liang, Lei Ji, Fan Yang, Yuejian Fang, Daxin Jiang, and Nan Duan. N¨uwa: Visual synthesis pretraining for neural visual world creation. In European conference on computer vision, pages 720–736. Springer, 2022. 3
[90] Saining Xie and Zhuowen Tu. Holistically-nested edge detection. In Proceedings of the IEEE international conference on computer vision, pages 1395–1403, 2015. 2
[91] Jun Xing, Li-Yi Wei, Takaaki Shiratori, and Koji Yatani. Autocomplete hand-drawn animations. ACM Trans. Graph., 34(6), 2015. 2
[92] Jun Xing, Rubaiat Kazi, Tovi Grossman, Li-Yi Wei, Jos Stam, and George Fitzmaurice. Energy-brushes: Interactive tools for illustrating stylized elemental dynamics. pages 755–766, 2016. 2
[93] Jinbo Xing, Menghan Xia, Yong Zhang, Haoxin Chen, Xintao Wang, Tien-Tsin Wong, and Ying Shan. Dynamicrafter: Animating open-domain images with video diffusion priors. arXiv preprint arXiv:2310.12190, 2023. 2
[94] Peng Xu, Timothy M. Hospedales, Qiyue Yin, Yi-Zhe Song, Tao Xiang, and Liang Wang. Deep learning for free-hand sketch: A survey and a toolbox, 2020. 2
[95] Wilson Yan, Yunzhi Zhang, Pieter Abbeel, and Aravind Srinivas. Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:2104.10157, 2021. 3
[96] Ran Yi, Yong-Jin Liu, Yu-Kun Lai, and Paul L Rosin. Unpaired portrait drawing generation via asymmetric cycle mapping. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8217– 8225, 2020. 2
[97] Jiahui Yu, Zirui Wang, Vijay Vasudevan, Legg Yeung, Mojtaba Seyedhosseini, and Yonghui Wu. Coca: Contrastive captioners are image-text foundation models. 2022. 7
[98] Sharon Zhang, Jiaju Ma, Jiajun Wu, Daniel Ritchie, and Maneesh Agrawala. Editing motion graphics video via motion vectorization and transformation. ACM Transactions on Graphics, 42(6):1–13, 2023. 2
[99] Daquan Zhou, Weimin Wang, Hanshu Yan, Weiwei Lv, Yizhe Zhu, and Jiashi Feng. Magicvideo: Efficient video generation with latent diffusion models, 2023. 3
[100] Jingyuan Zhu, Huimin Ma, Jiansheng Chen, and Jian Yuan. Motionvideogan: A novel video generator based on the motion space learned from image pairs. IEEE Transactions on Multimedia, 2023. 3