Abstract
Most machine learning methods assume that the input data distribution is the same in the training and testing phases. However, in practice, this stationarity is usually not met and the distribution of inputs differs, leading to unexpected performance of the learned model in deployment. The issue in which the training and test data inputs follow different probability distributions while the input–output relationship remains unchanged is referred to as covariate shift. In this paper, the performance of conventional machine learning models was experimentally evaluated in the presence of covariate shift. Furthermore, a region-based evaluation was performed by decomposing the domain of probability density function of the input data to assess the classifier’s performance per domain region. Distributional changes were simulated in a two-dimensional classification problem. Subsequently, a higher four-dimensional experiments were conducted. Based on the experimental analysis, the Random Forests algorithm is the most robust classifier in the two-dimensional case, showing the lowest degradation rate for accuracy and F1-score metrics, with a range between 0.1% and 2.08%. Moreover, the results reveal that in higher-dimensional experiments, the performance of the models is predominantly influenced by the complexity of the classification function, leading to degradation rates exceeding 25% in most cases. It is also concluded that the models exhibit high bias toward the region with high density in the input space domain of the training samples.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Robustness to changes is one of the most exemplary properties of a high-quality machine learning (ML) model in this ever-shifting world. Maintaining this property will allow users to work with trustworthy ML systems that perform consistently and efficiently when exposed to the deployment environment. The issue arises from the assumption of most ML models that the data points are independently and identically distributed (i.i.d), which presume that the data are sampled from the same probability distribution. However, this assumption is often not satisfied in real-world applications [1]. This violation would cause the performance of the predictive model to degrade substantially in practice. The main reason for this model degradation is that probability theory forms a central foundation for many data mining and machine learning techniques [2], as it provides a framework for quantifying uncertainty [3].
Changes in the underlying probability distributions have been extensively studied in the literature [4, 5]. The situation in which there is an inconsistency between the joint probability distributions P(x, y) of the training and test datasets is called dataset shift [6]. Researchers have classified the general dataset shift phenomenon into several types based on the probabilistic source of change. These types are covariate shift, concept drift and prior probability shift [7]. Detailed taxonomy and definitions of change types can be found in our recent overview [8]. Covariate shift takes the form of a change between the marginal distributions of the training and test inputs \(P_{tr}(x)\) and \(P_{te}(x)\), while the conditional distribution \(P(y \mid x)\) remains unchanged [9, 10], whereas the concurrent occurrence of changes in both marginal and conditional distributions is called concept drift [11]. Another type of dataset shift occurs when the distribution of classes P(y) changes, known as prior probability shift [12]. The focus of this paper is on analyzing the behavior of ML models in covariate shift situations as it is one of the most common cases in practice [13].
Covariate shift could appear in many real-world domains, such as healthcare systems [14], computer vision [15], NLP [16], and social media [17]. In practice, many sources cause covariate shift situations. The main reason is that the training input is not a representative sample of the entire population [18]. In this case, the training samples do not represent the overall problem due to the biased data collection process toward a specific subpopulation, known as sample selection bias [19], for example, bias toward specific demographic groups. Therefore, the model will be implemented on an unseen distribution in deployment, which, as a consequence, would affect the performance of the model.
Analyzing the out-of-sample performance of ML models before deployment is not trivial because of the ubiquitousness of the system’s evolution in real-life applications. The classical way is to perform out-of-sample validation using held-out datasets through cross-validation or bootstrap techniques. These techniques assume stationarity in the data distribution of training and test data. Therefore, they cannot fully estimate the model’s success rate in the deployment environment where a distributional shift is likely to occur [20]. Another approach to validate the ML models’ performance is analyzing the accuracy and bias variability across data sub-populations. Exploring such variability would help diagnose the performance and potentially develop methods to mitigate its effects.
In this paper, the robustness of several common machine learning algorithms on synthetic data is evaluated in the presence of covariate shift in binary classification problems. An overall performance assessment and a region-based evaluation of the model’s robustness are performed by decomposing the probability density function (pdf) of the input space domain of the test samples according to the input density distribution ratio between the test and training data samples. To this end, the contributions of this paper are summarized as follows:
-
1.
An evaluation framework is presented to assess the robustness of common ML classifiers in several drift scenarios.
-
2.
Comprehensive comparisons and experiments are conducted to measure model degradation rates under covariate shift in different classification problem settings.
-
3.
Decomposition of the input space based on the ratio of test-to-training input densities is proposed to evaluate the models’ performance per domain-region.
For the sake of visualization, exhaustive comparison experiments are conducted on two-dimensional artificial classification problems with covariate shifts formulated by simulating a broad spectrum of distribution drifts before evaluating the model robustness using additional higher-dimensional datasets. The experiments in this paper are designed to address the following primary research questions:
RQ1: What are the main factors that affect the robustness of performance in covariate shift problems and lead to model degradation?
RQ2: Which ML classification algorithms tend to be more robust (vulnerable) to specific problem settings?
RQ3: How does the performance of the classifiers vary in the input space domain when decomposed by regions based on the test-to-training density ratio?
The remainder of this paper is organized as follows. Section 2 gives a general background on the covariate shift problem and provides an overview of the related work. Next, Sect. 3 contains a detailed explanation of the settings specified for the experiments. The methodology for the performance evaluation of the ML models is detailed in Sect. 4. Section 5 presents the results of the different experiments. Threats to validity are discussed in Sect. 6. Finally, Sect. 7 concludes the work and sets out future directions for further extended use of this paper.
2 Background and related work
This section provides an overview of the covariate shift problem and reviews the related work to evaluate the robustness of the ML model’s performance under covariate shift.
2.1 Problem formulation and notation
In binary classification problems, the goal is to obtain a prediction function \(f: X \longmapsto Y\) that has been trained on training dataset \(\mathcal {D}_{tr}=\left\{ \left( x_{i}, y_{i}\right) \right\} _{i=1}^{N}\) of size N drawn i.i.d from a joint distribution \(p_{tr}(x,y)\), where \(x_i \in \mathbb {R}^d\) is a d-dimensional data instance, or covariates vector \(\bf{x}\), and \(y_i \in \{-1,+1\}\) is the class label. The classifier’s performance is evaluated on a test dataset \(\mathcal {D}_{te}\) drawn from a joint distribution \(p_{te}(x,y)\). The classical method to learn the classifier is through solving the following empirical risk minimization (ERM) problem:
where \(\theta\) denotes the parameter vector, \(\mathbb {E}_{p_{te}(x,y)}\) is the expectation over the test distribution \(p_{te}(x,y)\), and \(\ell\) is a selected loss function. In stationary distributions, i.e., when \(p_{te}(x) = p_{tr}(x)\), ERM provides a consistent estimator [21]. While adaptation techniques are required for non-stationary distributions, such as covariate shift situations.
2.2 Covariate shift adaptation
The minimization problem in Eq. 1 works well under the assumption that \(p_{te}(x,y)\) is the same as \(p_{tr}(x,y)\), which usually does not hold in practice. Thus, an adjustment to ERM introduced in Eq. 1 should be performed for dataset shift situations, that is, when \(p_{te}(x,y) \ne p_{tr}(x,y)\). A probabilistic source for the dataset shift is a change in the input data distributions, i.e., when \(p_{te}(x) \ne p_{tr}(x)\), which is referred to as distribution shift [22], also known as data drift [23]. As depicted in Fig. 1, covariate shift is a subset of the generic distribution shift situation when the conditional probability distribution that represents the input–output rule is the same between the training and the test data [24]:
One of the most common techniques to address the covariate shift problem is to employ an importance weighting function defined as: \(w(x) = \frac{p_{te}(x)}{p_{tr}(x)}\) which estimates the test-to-training density ratio [25]. Subsequently, the risk minimization problem in Eq. 1 is adjusted to the importance-weighted risk:

Visual representation of the relationship between the types of distributional change
There are many popular algorithms to compute the importance weights \(w(x_i)\), such as Kernel Mean Matching (KMM) [26], Kullback-Leibler Importance Estimation Procedure (KLIEP) [27] and least squares importance fitting (LSIF) [28]. It was shown that the importance weighting procedure can provide consistent learning under covariate shift, and thus increase the robustness of the performance in changing distributions [29]. However, the main drawback of the procedure is the high computational cost [30].
2.3 Measuring robustness to distribution shift
Much research is devoted to evaluating ML models’ performance under distribution shifts. Such an evaluation would be useful for determining the model’s performance after deployment, where the model might perform unexpectedly on unseen data points. A study has investigated the relationship between robustness and complexity of classifiers and concluded that complex classifiers remain more robust to changes than simple classifiers [31]. Similarly, in [32], the authors have tested the robustness of common classifiers in distributional shift situations. The drift was simulated by changing a particular attribute and assessing the influence on the information gain. The authors have concluded that ML models that use more attributes, such as K-Nearest-Neighbors (KNN), in making predictions tend to be more robust than those which rely on fewer attributes, such as Naive Bayes and Logistic Regression.
Several recent studies have investigated the variability in the model’s performance across data regions and sub-populations. MANDOLINE framework [33] was proposed to estimate the model’s performance under distribution shift. The framework uses a labeled validation set from the source distribution and an unlabeled set from the target distribution. Users can use their prior knowledge to group the data along the possible axes of distribution shift. Then, the reweighted performance estimates are computed. Another framework was proposed to proactively evaluate the model’s performance on the worst-case distribution [22]. Users choose two sets of variables, immutable variables whose distribution should remain unchanged and mutable variables whose distribution can be changed. The method identifies the sub-populations with the worst-case risk. Similarly, Sagawa et al. [34] developed a training procedure that uses prior knowledge to form groups in training data and minimizes worst-case loss over these data groups.
In contrast to previous studies, another line of research follows a different approach by predicting the model’s performance in distributional shift situations using the regression function. The Average Thresholded Confidence (ATC) method [35] was proposed to obtain a threshold on a model confidence score that enables the prediction of out-of-distribution model’s accuracy. In another recent study, Guillory et al. [36] proposed the so-called difference of confidences (DoC) method that predicts the model’s performance under distribution shift. DoC is used to directly estimate the classifier’s accuracy gap between the training and the target distributions. When lacking true labels for test sets, the authors [37] have derived distribution statistics that can benefit from the Automatic model Evaluation (AutoEval) problem and estimate the classifier’s accuracy.
Evaluating the model’s robustness has also been investigated in domain-specific problems. In image processing, the model’s performance has been evaluated for many prominent image classification benchmark datasets, such as CIFAR and ImageNet [38,39,40], MNIST [41]. The problems are constructed by inducing a wide range of distribution shifts. In natural language processing (NLP), Miller et al. [42] evaluated the model’s robustness to distribution shift using the popular Stanford Question Answering Dataset (SQuAD) [43]. The authors noted that training models on more out-of-distribution data did not lead to improved robustness for ML models. Despite the rich literature present in the area, the evaluation of the performance of the ML model per region decomposed by test-to-training density ratio has not been yet investigated and is provided by this paper.
3 Experimental settings
In this section, the specifications of the experiments performed using synthetic binary classification problems are illustrated. The experiments are simulated in a two-dimensional input space and a higher input space of four-dimensions. The experimental settings were made more diverse by selecting two- and four-dimensional space settings and omitting the three-dimensional case. And hence to gain a better insight into the performance of the different ML models in varied scenarios.
For the experiment design part, the training dataset is considered to be sampled from a standard Gaussian distribution \(X \sim \mathcal {N}_d(0, 1)\) throughout all experimental setups. Since any normally distributed variable X, with a particular population mean \(\mu\) and standard deviation \(\sigma\), can easily be transformed into a standard Gaussian distribution by applying equation \(z=\frac{X-\mu }{\sigma }\). Therefore, the training input density function is as follows:
where d is the dimension of the input space.
To generate the test data, several affine transformations are applied to the density of the training data. This method has been widely adopted in the literature to simulate the covariate shift problem in the dataset [10, 21]. The data points are considered to be sampled from a Gaussian distribution \(X \sim \mathcal {N}_d(\mu , \Sigma )\) for the test data. Therefore, the test input density function is given by:
where \(\mu \in \mathbb {R} ^d\) is the mean and \(\Sigma \in \mathcal {S}_{++}^{d}\) is the \(d \times d\) symmetric positive-definite covariance matrix whose (i, j)th entry is \(Cov[X_i, X_j]\). The statistics \(\mu\) and \(\Sigma\) represent the parameters of the affine transformations that simulate the drift in the experiments. Specifically, the mean \(\mu\) simulates a drift induced by translation, and \(\Sigma\) simulates a drift induced by scaling through the variance elements \(var (x_i) = \sigma _{ii}^2\), or rotation through the correlation coefficient \(\rho\) in the covariance elements \(cov (x_i, x_j) = \sigma _{ij}^2 = \rho \sigma _i\sigma _j\). For each drift type, the experiments are run in a two-dimensional input space and a higher four-dimensional input space.
Regarding the definition of class posterior probability functions, the formulations that are commonly used in covariate shift research have been followed [44, 45]. In particular, for the two-dimensional datasets settings, two different class posterior probability functions have been defined for classifying the points. The first function is defined as follows:
The second class posterior probability function that was designed is more complex to learn and is defined as follows:
Similarly, for the higher-dimensional datasets settings, Two different class posterior probability functions have been defined as follows:
where \(p(y=-1\mid X)= 1- p(y=+1 \mid X)\) and the optimal decision boundary is the set of points that satisfy \(p(y=-1\mid X)= p(y=+1 \mid X) = \frac{1}{2}\). For all experiments, training data points of size \(N_{tr} = 20000\) are sampled from the probability density function (pdf) defined in Eq. 4, test data points sampled from the same distribution of size \(N_{ts} = 20000\), and another test data points of size \(N_{td} = 20000\) sampled from the drifted distribution defined in Eq. 5. Parameter settings and specifications of the two-dimensional experiments are summarized in Table 5 in Appendix 1, and the four-dimensional experiments in Table 6 in Appendix 1. A more detailed description of each experiment is provided in the following subsections.

Training and test data points and the optimal decision boundary of the experiments
3.1 Drift simulated by translation
The first set of experiments was created by shifting the mean of the data \(\mu\) and fixing the covariance matrix \(\Sigma\). For this type of drift, two settings were created. One setting is characterized by the one-axis translation simulating a local concept drift case [46], and the other by the two-axis translation simulating a global concept drift case [47]. The details of the experiments are given as follows:
-
(a)
One-axis Translation: For the two-dimensional input space, the translation vector \(\begin{bmatrix} 3&0\end{bmatrix}^T\) is used to shift the original mean \(\begin{bmatrix} 0&0\end{bmatrix}^T\). Using the aforementioned drift parameters, two experiments have been created, one experiment whose class posterior probability function defined in Eq. 6, it is referred to as Exp1.1, and visualized in Fig. 2a, and the other one using the function defined in Eq. 7, it is referred to as Exp1.2, and visualized in Fig. 2b.
-
(b)
Two-axis Translation: For the two-dimensional space, the original mean is shifted by the translation vector \(\begin{bmatrix} 3&1\end{bmatrix}^T\). Exp1.3 refers to the experiment whose class posterior probability function defined in Eq. 6, and Exp1.4 using the function defined in Eq. 7. Exp1.3 and Exp1.4 are visualized in Fig. 2c and d, respectively. Similarly for the four-dimensional data, the original mean is shifted by the translation vector \(\begin{bmatrix} 0&-2&-1&1\end{bmatrix}^T\). The experiment whose class posterior probability function is defined in Eq. 8 is denoted as Exp2.1, while Exp2.2 denotes the experiment whose class posterior probability function is defined in Eq. 9.
3.2 Drift simulated by scaling
On the contrary of the drift explained in the previous Sect. 3.1, the data have been transformed by scaling the covariance matrix \(\Sigma\) and fixing the mean \(\mu\) of the data. In this set of experiments, two settings have been created, one setting for one-axis scaling simulating a local concept drift situation and another one for two-axis scaling simulating a global concept drift situation. To scale the covariance matrix \(\Sigma\) using the scalars \(s_i > 0\) for \(i =1,\dots ,d\) that represent the scaling factors for each axis direction, the scaling matrix can be written in matrix form as:
Therefore, the scaled covariance matrix \(\Sigma ^{'}\) can be found by computing the product \(\Sigma ^{'} = SS\Sigma\), the scaled covariance matrix is cataloged as:
where \(s_i\) is the scaling factor of dimension i and \(\sigma _{ij}\) is the covariance between dimensions i and j. The details of the experiments are given as follows:
-
(a)
One-axis scaling: For the two-dimensional input space, the scaling matrix \(S=\left[ \begin{array}{cc}2 &{} 0 \\ 0 &{} 1\end{array}\right]\) is used to transform the original covariance matrix \(\Sigma =\left[ \begin{array}{cc}1 &{} 0 \\ 0 &{} 1\end{array}\right]\). Applying Eq. 11, the scaled covariance matrix is \(\Sigma ^{'}=\left[ \begin{array}{cc}4 &{} 0 \\ 0 &{} 1\end{array}\right]\). Using the scaled covariance matrix \(\Sigma ^{'}\), two experiments have been created: Exp1.5, visualized in Fig. 2e, and Exp1.6, visualized in Fig. 2f, whose class posterior probability function defined in Eqs. 6 and 7, respectively.
-
(b)
Two-axis scaling: For the two-dimensional space, the original covariance matrix is transformed by the scaling matrix \(S=\left[ \begin{array}{cc}\sqrt{3} &{} 0 \\ 0 &{} \sqrt{2}\end{array}\right]\), resulting in a scaled covariance matrix \(\Sigma ^{'}=\left[ \begin{array}{cc}3&{} 0 \\ 0 &{} 2\end{array}\right]\). Exp1.7, visualized in Fig. 2g, and Exp1.8, visualized in Fig. 2h, refer to the experiments whose class posterior probability function defined in Eqs. 6 and 7, respectively. Similarly for the four-dimensional data, the original covariance matrix is transformed by the scaling matrix: \(S=\left[ \begin{array}{cccc}\sqrt{3} &{} 0 &{}0 &{} 0\\ 0 &{} \sqrt{2}&{}0&{}0\\ 0 &{} 0 &{}\sqrt{2} &{} 0\\ 0 &{} 0 &{} 0&{} \sqrt{3} \end{array}\right]\). By applying Eq. 10, the scaled covariance matrix is found: \(\Sigma ^{'}=\left[ \begin{array}{cccc}3 &{} 0 &{}0 &{} 0\\ 0 &{} 2&{}0&{}0\\ 0 &{} 0 &{}2 &{} 0\\ 0 &{} 0 &{} 0&{} 3 \end{array}\right]\). Exp2.3 and Exp2.4 denote the experiments whose class posterior probability function defined in Eqs. 8 and 9, respectively.
3.3 Drift simulated by translation and scaling
In this set of experiments, a combination of linear transformations of the data points is used by translating and scaling the dataset to simulate the drift. For two-dimensional data, translation is formed using the translation vector \(\begin{bmatrix} 3&1\end{bmatrix}^T\), while scaling is formed using the scaling matrix \(S=\left[ \begin{array}{cc}\sqrt{3} &{} 0 \\ 0 &{} \sqrt{2}\end{array}\right]\), resulting in a scaled covariance matrix \(\Sigma ^{'}=\left[ \begin{array}{cc}3&{} 0 \\ 0 &{} 2\end{array}\right]\).
Exp1.9, visualized in Fig. 2i, and Exp1.10, visualized in Fig. 2j, refer to the experiments whose class posterior probability function defined in Eqs. 6 and 7, respectively.
3.4 Drift simulated by translation, scaling and rotation
In this set of experiments, the drift is simulated by applying three different affine transformations to the dataset by translating, scaling, and rotating the data points. The covariance matrix after scaling and rotating can be calculated by means of the following matrix multiplication:
where R is the rotation matrix. Note that the order of the transformation methods affects the end results. In these experiments, the assumption is made that the data are being scaled and rotated.
For the rotation of the data points, a rotation matrix R is defined to rotate the data points through a desired angle \(\theta\) about their origin in space. In a two-dimensional space, the general definition of the rotation matrix R is given by the following equation:
For the four-dimensional space, a basic rotation matrix R is given by the following equation:
where \(\theta\) is the rotation angle.
In our experimental settings, for the two-dimensional case, a translation vector \(\begin{bmatrix} 4&-1\end{bmatrix}^T\) is used to shift the original mean \(\mu\). For scaling and rotation, the scaling matrix \(S=\left[ \begin{array}{cc}2 &{} 0 \\ 0 &{} \sqrt{3}\end{array}\right]\) is used to scale and rotate the data by \(45^{\circ }\). This parameter setting would result in the following scaled and rotated covariance matrix by applying Eq. 12 and the rotation matrix defined in Eq. 13: \(\Sigma ^{''}=\left[ \begin{array}{cc}3.5&{} 0.5 \\ 0.5 &{} 3.5\end{array}\right]\).
Exp1.11, visualized in Fig. 2k, and Exp1.12, visualized in Fig. 2l, refer to the experiments whose class posterior probability function defined in Eqs. 6 and 7, respectively.
For four-dimensional data, the original mean \(\mu\) is shifted through the translation vector \(\begin{bmatrix} 0&-2&-1&1\end{bmatrix}^T\) and scale the data points through the scaling matrix \(S=\left[ \begin{array}{cccc}\sqrt{3} &{} 0 &{}0 &{} 0\\ 0 &{} \sqrt{2}&{}0&{}0\\ 0 &{} 0 &{}\sqrt{2} &{} 0\\ 0 &{} 0 &{} 0&{} \sqrt{3} \end{array}\right]\), and then rotate the scaled data points by \(45^{\circ }\). This parameter setting would result in the following scaled and rotated covariance matrix by applying Eq. 12 and the rotation matrix defined in Eq. 14:
\(\Sigma ^{''}=\left[ \begin{array}{cccc}2.5 &{} 0.5 &{}0 &{} 0\\ 0.5 &{} 2.5&{} 0 &{}0\\ 0 &{} 0 &{}2 &{} 0\\ 0 &{} 0 &{} 0&{} 3 \end{array}\right]\). Exp2.5 and Exp2.6 denote the experiments whose class posterior probability function is defined in Eqs. 8 and 9, respectively.
4 Evaluation methodology
In this section, the methodology to address the research questions and quantify the robustness of ML models’ performance to covariate shift situations is explained. The ML models used for evaluation are first iterated, followed by a description of the evaluation metrics used to assess performance. Lastly, the decomposition of the pdfs by the density ratio regions is described.
4.1 ML models
In this paper, the performance of several popular conventional ML algorithms is compared under covariate shift to address RQ1 and RQ2. To draw conclusions and gain better insight into the robustness to distributional shifts, the chosen ML algorithms have been diversified by selecting classification algorithms from different families.
The selected ML algorithms for our evaluation are the following:
-
Support vector machines (SVM): SVM [48] is one of the most popular ML classification algorithms. SVM classifies the points by finding the optimal separating hyperplane between the classes.
-
Logistic regression (LR): LR models are used to predict the likelihood of the target class and are usually solved by maximum likelihood methods [49]. For binary classification, the logistic regression model predicts the probability as follows:
$$\begin{aligned} p(y=\pm 1 \mid \bf{x}, \bf{w})= \frac{1}{1+\exp \left( -y \bf{w}^{\rm{T}} \bf{x}\right) }. \end{aligned}$$(15) -
Random forests (RF): Random forests are an ensemble of decision tree models and an extension of the bagging method [50]. It creates a collection of de-correlated decision trees and then aggregates the predictions of each individual tree.
-
Gaussian Naive Bayes (GNB): GNB is a simple probabilistic classification algorithm that implements Bayes’ Theorem [51]. It involves calculating the posterior probability by applying the Bayes rule:
$$\begin{aligned} p(y=\pm 1 \mid \bf{x}) = p(y=\pm 1) \frac{\prod _{i=1}^{d} p(x_i \mid y=\pm 1)}{p( \bf{x})}. \end{aligned}$$(16)GNB algorithm assumes that the class-conditional probability distribution, i.e., \(p(\bf{x} \mid y=\pm 1)\), follows the Gaussian distribution and estimates the mean and standard deviation parameters from the training data.
-
K-Nearest-Neighbors (KNN): KNN is a popular algorithm that uses the neighborhood of the data point to make predictions [52]. A voting mechanism is used to determine the class of the new data point. The votes are retrieved from the k data points that are the closest to the new data point.
4.2 Evaluation metrics
Observing the loss rate in the performance of ML models is a commonly adopted approach to measure the robustness of the learning algorithms to distributional changes [53, 54]. The performance is usually measured on two data samples, the training samples and out-of-distribution samples. This paper evaluates the robustness of the ML models used in the experiments using the degradation rate of different performance metrics, including accuracy, F-score, and Matthews coefficient of correlation (MCC). The percentage of data points that are correctly classified represents the accuracy of the model. With TP representing the count of true positives, TN represents the count of true negatives, FP represents the count of false positives, and FN the count of false negatives, the accuracy can be expressed as:
On the other hand, the F-score, also called the F1 score, is the harmonic mean between the precision and recall metrics [55]. Recall measures the ratio of positive data points that are correctly classified, whereas precision measures the ratio of data points that are classified as positive that are truly positive:
where
Similarly, MCC uses the confusion matrix to score the quality of the classification in the interval [−1, +1], with −1 denoting perfect misclassification and +1 denoting perfect classification, where 0 means prediction more of a random prediction:
4.3 PDF domain region decomposition
To address RQ3 and evaluate the performance on subpopulations of the dataset according to the density ratio between the test and training datasets, the input space domain of the test dataset is decomposed into two regions. The first region, denoted R1, is the region with a high density of the training dataset; i.e., where the density ratio is \(r = \frac{p_{te}(x)}{p_{tr}(x)} \le 1\). The other region denoted R2, is the region with high density of the test dataset, that is, where the density ratio \(r = \frac{p_{te}(x)}{p_{tr}(x)} >1\). To decompose the pdfs by density regions, the following equation must be solved:
Since the distribution is multivariate in our experiments, the pdfs are hypersurfaces of dimension d embedded in \((d+1)\)-dim space, and they intersect in a set of d-dim points that lie on a hypersurface \(\mathfrak {H}\), also embedded in (\(d+1\))-dim space; where d is the dimension of the data points. The solution of Eq. 22 would provide the hypersurface \(\mathfrak {H}\) equation.
Solving Eq. 22 for the d-dimensional case of our experiments; \(X \sim \mathcal {N}_d(\mu , \Sigma )\):
results in the hypersurface \({\mathfrak {H}}\) defined by the following equation:
The data points that lie in the region R1 are those points which satisfy the inequality:
otherwise, the points lie in the region R2.
Specifically, solving Eq. 22 for the two-dimensional datasets of our experiments; i.e., where the test input density is \(\left( \begin{array}{l}x \\ y\end{array}\right) \sim N\left[ \left( \begin{array}{l}\mu _{1} \\ \mu _{2}\end{array}\right) ,\left( \begin{array}{cc}\sigma _{1}^{2} &{} \rho \sigma _{1} \sigma _{2} \\ \rho \sigma _{1} \sigma _{2} &{} \sigma _{2}^{2}\end{array}\right) \right]\):
results in a 2D curve that lies on a surface \(\bf{S}\). We obtain the following equation defining the surface \(\bf{S}\) in the 3D space:
where:
The data points that lie in the region R1 are those points which satisfy the inequality:
otherwise, the points lie in the region R2.
The surface \(\bf{S}\) has a particular shape based on the type of drift simulated in the pdf of the dataset. Specifically, in the case of drifts simulated by two-axis translation, the surface \(\bf{S}\) is a vertical plane in the 3D space defined by the following equation:
For a translation on one axis, the surface \(\bf{S}\) is a vertical plane that is parallel to the xz-plane or the yz-plane. In particular, if the translation is along the x-axis, the surface \(\bf{S}\) is a vertical plane parallel to the yz-plane and is given by equation:
On the contrary, if the translation is along the y-axis, the surface \(\bf{S}\) is a vertical plane parallel to the xz-plane and is given by equation:
In the case of two-axis scaling; \(\sigma _1 > 1\) and \(\sigma _2 > 1\); the surface \(\bf{S}\) is an elliptic cylinder defined by equation:
where:
and:
In the special case of scaling at the same magnitude in both dimensions; i.e., \(\sigma _1 =\sigma _2 \implies \alpha =\beta\); the surface \(\bf{S}\) is a right-circular cylinder.
In the case of a one-axis scaling, the two pdfs intersect in curves that lie on two parallel planes. If \(\sigma _1 =1\); these parallel planes are defined by the following equation:
Whereas if \(\sigma _2 =1\); the parallel planes are defined by the following equation:
Similarly, in the case of translation and scaling at the same time, the surface where the two pdfs intersect is a cylinder that is centered at \(\left( \frac{\mu _{1}}{1-\sigma _{1}^{2}}, \frac{\mu _{2}}{1-\sigma _{2}^{2}}\right)\). Figure 3 shows the densities of the training and test data along with the corresponding intersection surface between the two pdfs of the two-dimensional experiments.

Training and test input densities decomposed by the R1 and R2 regions and the intersection surface
5 Empirical results and analysis
The results of the experiments detailed in Sect. 3 will be scrutinized in this section to answer the research questions. Specifically, the overall results of applying the ML models to different datasets characterized by various types of drift will be presented. Additionally, a model-wise performance analysis will follow. To execute the experiments, the scikit-learn libraryFootnote 1was utilized, a widely used open-source Python ML package that provides the implementation of several classification algorithms.
5.1 Degradation rate in evaluation metrics
Changes in data distribution usually lead to a degradation of performance metrics [56]. To measure the performance loss after the drift and address RQ1, the degradation rate is calculated, this rate represents the percentage of the performance drop of the ML model on the drifted dataset. Table 1 recapitulates the results of the two-dimensional experiments across the different performance metrics of the ML models.
The first observation from the results is that the Random Forests algorithm demonstrated a high robustness level in most experiments across all performance metrics. This is an advantage of ensemble-based methods that can alleviate the biases of the datasets by combining individual classifiers’ votes [57]. However, this is not the case in the four-dimensional experiment results summarized in Table 2. RF has shown much poorer robustness in higher-dimensional data. This could be attributable to the fact that learners which use more covariates to make predictions tend to show greater robustness than those that rely on a subset of covariates [32]. The default value provided by the scikit-learn library was used to select the parameter that controls the subset of covariates used to find the best tree split in the Random Forests algorithm. The library assigns the square root value of the total covariates to the parameter. Furthermore, LR showed the highest degradation rate in most of the two-dimensional experiments, which is a recognized drawback of the algorithm in the case of out-of-sample predictions, where the maximum likelihood estimator tends to display poor performance due to the overfitting effect [58].
For the rest of the models, there are no precise general conclusions that can be deduced, since each model’s degradation rates were affected by the settings of the experiments. It can be seen from Table 1 that SVM is the model with the second lowest degradation rate after RF in most cases where multiple drifts were simulated, that is, in experiments Exp1.9 to Exp1.12. On the other hand, GNB and KNN are highly affected by multiple drifts since p(x) has been altered to a great extent. Each model’s performance will be further investigated in the following subsection.
In terms of the effects of the complexity of the decision surface, it can be seen that the performance on the test data is worse and the degradation rates are higher in the four-dimensional experiments than in the two-dimensional cases when using the more complex decision function \(F_2\), except for the LR and GNB algorithms, as they display low degradation rates due to poor performance on the original dataset. This can be associated with the positive correlation between the complexity of the decision boundary and the dimensional space of the problem [59]. Furthermore, the effect of the complexity of the decision boundary is more discernible in experiments with mixed drifts, i.e., a higher magnitude of drift.
To see how the performance metrics are acting in the experiments, the correlation matrices of the two- and four-dimensional experiments between the degradation rates of different performance metrics used to evaluate the models have been plotted. The correlation matrices are shown in Figs. 4 and 5. From the matrices it can be seen that a strong correlation between the degradation rates of the performance metrics in the two-dimensional experiments (see Fig. 4). This indicates that the performance has been stirred in the same direction across the different metrics. However, this correlation between the degradation rates is lower in the four-dimensional experiments (see Fig. 5). Furthermore, by comparing the degradation rates in Tables 1 and 2, it can be seen that the MCC metric is the most affected by changes, showing higher rates than accuracy and F-score. However, accuracy and F-score have shown similar degradation rates in most experiments.
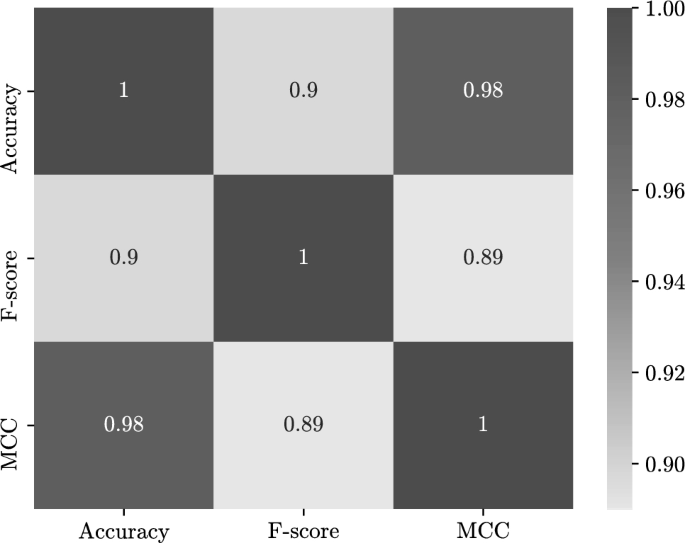
Correlation between degradation rates of performance metrics in the two-dimensional experiments
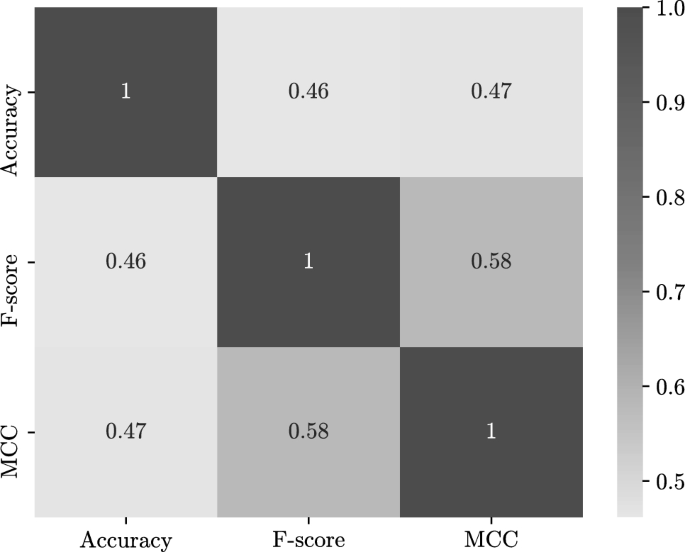
Correlation between degradation rates of performance metrics in the four-dimensional experiments
5.2 Model-wise analysis
In this section, the ML model’s performance in the different experimental settings to address RQ2 is scrutinized. The model-wise results of the two-dimensional experiments are organized in Fig. 6, while Fig. 7 details the results of the four-dimensional experiments. The common ground between all ML models in the two-dimensional datasets is that they are mostly damaged in the experiments formulated by three types of transformation, i.e., in experiments Exp1.11 and Exp1.12. Whereas in the four-dimensional datasets, the models are more affected by the complexity of the classification function, i.e., in the experiments where the true classification function is \(F_2\), namely, the experiments with even numbers.
In the two-dimensional experiments, as shown in Fig. 6a, the SVM algorithm was found to be more susceptible to scaling than to translating the data distribution, i.e., in experiments Exp1.5 \(-\)1.8. This is interwoven with the decision boundary built by the SVM algorithm for the classification problem. Scaling the covariance matrix will lead to changes in the dispersion of the data points that could require a change in the shape of the decision boundary, whereas translating the mean would require shifting the decision boundary without adjusting its shape. In contrast, as shown in Fig. 6b, the LR algorithm has shown poorer performance in the translated one-axis distribution and the scaled two-axis distribution. RF algorithm has exhibited a steady degradation rate that increases with the complexity of the drift simulated in the dataset, as shown in Fig. 6c. Similarly to RF, GNB and KNN algorithms have shown relative degradation rates to the types of drift simulated in the data distribution, by scoring low degradation rates in experiments that include single drifts, and higher rates in experiments that include mixed types of drift, as shown in Fig. 6d and e.
In four-dimensional experiments, it is clear that performance degradation is most dominant by the complexity of the class posterior probability function used across all ML models; see Fig. 7. Specifically, the MCC metric was the most sensitive, showing the highest degradation rates in all experiments. However, the degradation rates of accuracy and F-score are quite close to each other.

Model-wise performance evaluation in two-dimensional experiments

Model-wise performance evaluation in four-dimensional experiments
5.3 Region-based performance evaluation
After evaluating the overall performance of the ML models in the presence of distributional shifts, the performance of the ML models have been evaluated on subpopulations of the data to address RQ3. To ensure an impartial evaluation, we assessed the performance on 10,000 data points in each region. The findings of the region-based evaluation of the two-dimensional experiments are shown in Tables 3 and 4 for the four-dimensional experiments.
From the results, it can be seen that the performance of the different ML models is very high in the R1 region, that is, in the region with a high training input density in most experiments. However, the models are more erroneous in the R2 region, that is, in the region with a low training input density. This is an important observation that the models tend to be accurate in the high-training input density regions and work well in such regions, even though the distribution has changed. Furthermore, upon comparing Tables 1 and 3, and Tables 2 and 4, it can be observed that the results obtained from data sampled from the same training distribution are similar to the outcomes observed in region R1. This is because the majority of data points are concentrated in this region due to a higher training input density. Likewise, for the drifted distribution, the results are similar to those obtained from region R2 since the test density is high in this region, resulting in a higher number of data points contributing to the experiments.
This result can be beneficial for interpreting where models tend to fail when making predictions. Additionally, it can be used to develop an adaptive solution for covariate shift situations, where a region-based importance weight can be introduced to correct the bias and ensure high-robustness in the affected regions. Moreover, introducing such region-based importance weights can reduce the cost of computing point-wise importance weights to region-wise importance weights in the cases of large datasets. This would also solve the drawback of the conventional importance weighting technique, where w(x) can become unbounded and very large for a few points, leading to large variances of the estimated ratios [60].
In the two-dimensional experiments, it can be seen that the LR and GNB algorithms perform poorly in the R1 region in the experiments with mixed drifts. However, they do not tend to be sensitive to this region in the four-dimensional experiments, as they exhibit similar performance across the evaluation metrics in all the experiments. It is also noteworthy to see that the RF algorithm has a high performance in R1 in all two- and four-dimensional experiments in all evaluation metrics, and most of the misclassifications were in the R2 region. Similarly to the overall robustness results presented in the previous section, the MCC appears to be the most susceptible metric compared to accuracy and F-score in the R2 region, showing higher performance loss rates. Furthermore, the complexity of the decision function has been shown to have a higher impact on the R2 region.
The performance of ML models in the context of region-based analysis was further investigated by conducting an examination of the data points based on the density ratio values. Specifically, the region R1 consists of data points with a density ratio of a positive number that is less than 1, while region R2 includes data points with a density ratio higher than 1. To provide a comprehensive overview of the density ratio values in the experiments, quartiles were calculated, which can be found summarized in Table 7 for the two-dimensional experiments, and Table 8 in the appendix Sect. B. The performance metric used in this analysis is the accuracy, as it was found to have high correlations with other performance metrics, see Tables 4 and 5. Therefore, similar insights could be obtained by analyzing the different performance metrics.
The performance of the ML models in each quartile of the density ratio for the two-dimensional experiments is shown in Fig. 8. As can be observed, in most cases, the performance of the models degrades significantly as the density ratio increases, indicating that the models become less reliable as we move further from the training domain region. In particular, SVM exhibits the highest level of sensitivity as the density ratio increases, while RF demonstrates the highest level of robustness at high density ratio values. Similar trends are observed in the four-dimensional experiments, as shown in Fig. 9. However, LR and NB notably exhibit relatively stable performance across the density ratio quartiles in most experiments.

Accuracy of machine learning models for each quartile of test-to-training density ratios in the two-dimensional experiments

Accuracy of machine learning models for each quartile of test-to-training density ratios in the four-dimensional experiments
6 Threats to validity
Like any other empirical study, the main threat to external validity is related to the generalization of the findings. Although the scope of this paper is to compare the performance of different ML algorithms under distributional shifts, the default parameters provided by the scikit-learn library have been used. Using a fixed set of parameters would narrow the focus to monitor the performance of the different algorithms rather than to monitor the same algorithm under different parameter settings. Furthermore, taking the impact of the models’ parameters into account as a factor, in addition to the drift parameters, would extend the parameter space of the experiments expansively. However, different parameter settings would yield different results clearly, but we argue that the concluding remarks would be the same.
On the other hand, the experiments have been conducted using synthetic data, which might not always be similar and mimic the real-world context. As a result, this may affect the generalization of our findings to real-world datasets. Despite this, in the literature, synthetic datasets are widely used in research on changing environments [9, 20], as they include information about drift, such as drift time and type [61, 62], and they provide valuable insights and a basis for further research. Moreover, real-world datasets lack annotations of ground-truth changes, and their underlying PDFs are often unknown [63]. Additionally, these generated datasets allow us to work on controlled classification settings and simulate various drift situations, and draw concrete conclusions about the performance of the ML models.
7 Conclusion
In this paper, the robustness of the performance of popular machine learning algorithms was investigated in covariate shift situations through an exhaustive comparative study. Several problems using a tractable classification framework have been generated. Each problem is parameterized by specific conditions that simulate a particular type of change. Our results show that the Random Forests algorithm is the most robust algorithm in the two-dimensional experiments, showing the lowest degradation rates in the evaluation metrics. The complexity of the classification rule has a major impact on the performance in higher-dimensional experiments.
The decomposition of the input space domain into regions based on the test-to-training density ratio have allowed to diagnose the models’ performance on subpopulations of the data points. The experimental results show the high bias of the algorithms in the regions where the training input density is high, despite inducing a change in the distribution of the test data points. Our future work will consist of using this observation to develop a covariate shift solution based on region-based importance weights.
Additionally, and to address the threats presented in Sect. 6, we would like to investigate the effects of the models’ hyperparameters in coping with distributional changes. Also, the impact of using real-world datasets in our evaluation environment. Another potential continuation for future research could be the evaluation of deep learning-based models to further validate the conclusions drawn from conventional ML models.
Data availibility
The datasets generated during and/or analyzed during the current study are not publicly available currently. However, the authors are willing to provide the data per request.
References
L’heureux A, Grolinger K, Elyamany HF, Capretz MA (2017) Machine learning with big data, challenges and approaches. IEEE Access 5:7776–7797
Witten IH, Frank E, Hall MA, Pal CJ (2017) Probabilistic methods. In: Witten IH, Frank E, Hall MA, Pal CJ (eds.) Data mining (Fourth Edition), Fourth edition edn., pp 335–416. Morgan Kaufmann, San Francisco, CA, USA
Brownlee J (2019) Probability for machine learning: discover how to harness uncertainty with Python
Gama Ja, Žliobaitundefined I, Bifet A, Pechenizkiy M, Bouchachia A (2014) A survey on concept drift adaptation. ACM Comput Surv 46(4)
Lu J, Liu A, Dong F, Gu F, Gama J, Zhang G (2019) Learning under concept drift: a review. IEEE Trans Knowl Data Eng 31(12):2346–2363
Moreno-Torres JG, Raeder T, Alaiz-Rodríguez R, Chawla NV, Herrera F (2012) A unifying view on dataset shift in classification. Pattern Recogn 45(1):521–530
Raza H, Prasad G, Li Y (2015) EWMA model based shift-detection methods for detecting covariate shifts in non-stationary environments. Pattern Recogn 48(3):659–669
Bayram F, Ahmed BS, Kassler A (2022) From concept drift to model degradation: an overview on performance-aware drift detectors. Knowl-Based Syst 245:108632
Shimodaira H (2000) Improving predictive inference under covariate shift by weighting the log-likelihood function. J Stat Plann Inf 90(2):227–244
Sugiyama M, Kawanabe M (2012) Machine learning in non-stationary environments: introduction to covariate shift adaptation. The MIT Press, Cambridge
Tsymbal A (2004) The problem of concept drift: definitions and related work. Computer Science Department. Trinity College, Dublin
Tasche D (2017) Fisher consistency for prior probability shift. J Mach Learn Res 18(1):3338–3369
Li F, Lam H, Prusty S (2020) Robust importance weighting for covariate shift. In: International conference on artificial intelligence and statistics, pp 352–362. PMLR
Subbaswamy A, Saria S (2020) From development to deployment: dataset shift, causality, and shift-stable models in health ai. Biostatistics 21(2):345–352
Schneider S, Rusak E, Eck L, Bringmann O, Brendel W, Bethge M (2020) Improving robustness against common corruptions by covariate shift adaptation. Adv Neural Inf Process Syst 33:11539–11551
Duchi JC, Hashimoto T, Namkoong, H (2019) Distributionally robust losses against mixture covariate shifts. Under Rev 2
Fei G, Liu B (2015) Social media text classification under negative covariate shift. In: Proceedings of the 2015 conference on empirical methods in natural language processing, pp 2347–2356
He H, Zha S, Wang H (2019) Unlearn dataset bias in natural language inference by fitting the residual. arXiv preprint arXiv:1908.10763
Wiemann PF, Klein N, Kneib T (2022) Correcting for sample selection bias in Bayesian distributional regression models. Comput Stat Data Anal 168:107382
Tsuboi Y, Kashima H, Hido S, Bickel S, Sugiyama M (2009) Direct density ratio estimation for large-scale covariate shift adaptation. J Inf Process 17:138–155
Sugiyama M, Krauledat M, Müller K-R (2007) Covariate shift adaptation by importance weighted cross validation. J Mach Learn Res 8(5)
Subbaswamy A, Adams R, Saria S (2021) Evaluating model robustness and stability to dataset shift. In: International conference on artificial intelligence and statistics, pp 2611–2619. PMLR
Liu H, Wu Y, Cao Y, Lv W, Han H, Li Z, Chang J (2020) Well logging based lithology identification model establishment under data drift: a transfer learning method. Sensors 20(13):3643
Sakai T, Shimizu N (2019) Covariate shift adaptation on learning from positive and unlabeled data. In: Proceedings of the AAAI conference on artificial intelligence, vol 33, pp 4838–4845
Quionero-Candela J, Sugiyama M, Schwaighofer A, Lawrence ND (2009) Dataset shift in machine learning. The MIT Press, Cambridge
Huang J, Gretton A, Borgwardt K, Schölkopf B, Smola A (2006) Correcting sample selection bias by unlabeled data. Adv Neural Inf Process Syst 19
Sugiyama M, Nakajima S, Kashima H, Buenau P, Kawanabe M (2007) Direct importance estimation with model selection and its application to covariate shift adaptation. Adv Neural Inf Process Syst 20
Kanamori T, Hido S, Sugiyama M (2009) A least-squares approach to direct importance estimation. J Mach Learn Res 10:1391–1445
Sugiyama M, Suzuki T, Nakajima S, Kashima H, von Bünau P, Kawanabe M (2008) Direct importance estimation for covariate shift adaptation. Ann Inst Stat Math 60(4):699–746
Chapaneri SV, Jayaswal DJ (2019) Covariate shift adaptation for structured regression with Frank–Wolfe algorithms. IEEE Access 7:73804–73818
Alaiz-Rodríguez R, Japkowicz N (2008) Assessing the impact of changing environments on classifier performance. In: Conference of the Canadian society for computational studies of intelligence, pp 13–24. Springer
Abbasian H, Drummond C, Japkowicz N, Matwin S (2010) Robustness of classifiers to changing environments. In: Canadian conference on artificial intelligence, pp 232–243. Springer
Chen M, Goel K, Sohoni NS, Poms F, Fatahalian K, Ré C (2021) Mandoline: Model evaluation under distribution shift. In: International conference on machine learning, pp 1617–1629. PMLR
Sagawa S, Koh PW, Hashimoto TB, Liang, P (2019) Distributionally robust neural networks for group shifts: On the importance of regularization for worst-case generalization. arXiv preprint arXiv:1911.08731
Garg S, Balakrishnan S, Lipton ZC, Neyshabur B, Sedghi H (2022) Leveraging unlabeled data to predict out-of-distribution performance. In: ICLR
Guillory D, Shankar V, Ebrahimi S, Darrell T, Schmidt L (2021) Predicting with confidence on unseen distributions. In: Proceedings of the IEEE/CVF international conference on computer vision, pp 1134–1144
Deng W, Zheng L (2021) Are labels always necessary for classifier accuracy evaluation? In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 15069–15078
Recht B, Roelofs R, Schmidt L, Shankar V (2019) Do imagenet classifiers generalize to imagenet? In: International conference on machine learning, pp 5389–5400. PMLR
Taori R, Dave A, Shankar V, Carlini N, Recht B, Schmidt L (2020) Measuring robustness to natural distribution shifts in image classification. Adv Neural Inf Process Syst 33:18583–18599
Miller JP, Taori R, Raghunathan A, Sagawa S, Koh PW, Shankar V, Liang P, Carmon Y, Schmidt L (2021) Accuracy on the line: on the strong correlation between out-of-distribution and in-distribution generalization. In: International conference on machine learning, pp 7721–7735. PMLR
Yadav C, Bottou L (2019) Cold case: The lost mnist digits. Adv Neural Inf Process Syst 32
Miller J, Krauth K, Recht B, Schmidt L (2020) The effect of natural distribution shift on question answering models. In: International conference on machine learning, pp 6905–6916. PMLR
Rajpurkar P, Zhang J, Lopyrev K, Liang P (2016) Squad: 100,000+ questions for machine comprehension of text. arXiv preprint arXiv:1606.05250
Sugiyama M, Krauledat M, Müller K-R (2007) Covariate shift adaptation by importance weighted cross validation. J Mach Learn Res 8(5):1–21
Hachiya H, Sugiyama M, Ueda N (2012) Importance-weighted least-squares probabilistic classifier for covariate shift adaptation with application to human activity recognition. Neurocomputing 80:93–101
Almeida PR, Oliveira LS, Britto AS Jr, Sabourin R (2018) Adapting dynamic classifier selection for concept drift. Expert Syst Appl 104:67–85
Khamassi I, Mouchaweh MS, Hammami M, Ghédira K (2018) Discussion and review on evolving data streams and concept drift adapting. Evol Syst 9:1–23
Cortes C, Vapnik V (1995) Support-vector networks. Mach Learn 20(3):273–297
Hastie T, Tibshirani R, Friedman JH, Friedman JH (2009) The elements of statistical learning: data mining, inference, and prediction, vol 2. Springer, New York
Breiman L (2001) Random forests. Mach Learn 45(1):5–32
Bishop CM, Nasrabadi NM (2006) Pattern recognition and machine learning, vol 4. Springer, New York
Hand DJ (2007) Principles of data mining. Drug Saf 30(7):621–622
Ovadia Y, Fertig E, Ren J, Nado Z, Sculley D, Nowozin S, Dillon J, Lakshminarayanan B, Snoek J (2019) Can you trust your model’s uncertainty? Evaluating predictive uncertainty under dataset shift. Adv Neural Inf Process Syst 32
Amodei D, Olah C, Steinhardt J, Christiano P, Schulman J, Mané D (2016) Concrete problems in AI safety. arXiv preprint arXiv:1606.06565
Lesch S, Kleinbauer T, Alexandersson J (2005) A new metric for the evaluation of dialog act classification. In: Proceedings of the 9th workshop on the semantics and pragmatics of dialogue (SEMDIAL: DIALOR), Nancy, France, pp 143–6. Citeseer
Rabanser S, Günnemann S, Lipton Z (2019) Failing loudly: an empirical study of methods for detecting dataset shift. Adv Neural Inf Process Syst 32
Clark C, Yatskar M, Zettlemoyer L (2019) Don’t take the easy way out: ensemble based methods for avoiding known dataset biases. arXiv preprint arXiv:1909.03683
Shafieezadeh Abadeh S, Mohajerin Esfahani PM, Kuhn D (2015) Distributionally robust logistic regression. Adv Neural Inf Process Syst 28
Atashpaz-Gargari E, Sima C, Braga-Neto UM, Dougherty ER (2013) Relationship between the accuracy of classifier error estimation and complexity of decision boundary. Pattern Recogn 46(5):1315–1322
Cortes C, Mohri M (2014) Domain adaptation and sample bias correction theory and algorithm for regression. Theoret Comput Sci 519:103–126
Micevska S, Awad A, Sakr S (2021) SDDM: an interpretable statistical concept drift detection method for data streams. J Intell Inf Syst 56(3):459–484
Lima M, A Fagundes R.A.d (2021) A comparative study on concept drift detectors for regression. In: Brazilian conference on intelligent systems, pp 390–405. Springer
Cano A, Krawczyk B (2020) Kappa updated ensemble for drifting data stream mining. Mach Learn 109:175–218
Acknowledgements
This work has been funded by the Knowledge Foundation of Sweden (KKS) through the Synergy Project AIDA - A Holistic AI-driven Networking and Processing Framework for Industrial IoT (Rek:20200067).
Funding
Open access funding provided by Karlstad University.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors have no conflicts of interest to declare that are relevant to the content of this article.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix A Summary of experimental settings
This Appendix provides a summary of the parameter settings and specifications used in the two-dimensional and four-dimensional experiments conducted in this paper. Tables 5 and 6 list the key parameters and their respective values for the two-dimensional and four-dimensional experiments, respectively.
Appendix B Summary of quartile values for test-to-training density ratios
This appendix section includes summary tables of quartile values for test-to-training density ratios in the two-dimensional and four-dimensional experiments. Table 7 shows the quartile values for the two-dimensional experiments, while Table 8 shows the quartile values for the four-dimensional experiments. The reported values include the minimum value (0), the 25th percentile (25), the median value (50), the 75th percentile (75) and the maximum value (100). These quartile values are useful in assessing the spread of the test-to-training density ratios.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Bayram, F., Ahmed, B.S. A domain-region based evaluation of ML performance robustness to covariate shift. Neural Comput & Applic 35, 17555–17577 (2023). https://doi.org/10.1007/s00521-023-08622-w
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-023-08622-w