Abstract
We consider the class of disjoint bilinear programs \( \max \, \{ {\textbf{x}}^T{\textbf{y}} \mid {\textbf{x}} \in {\mathcal {X}}, \;{\textbf{y}} \in {\mathcal {Y}}\}\) where \({\mathcal {X}}\) and \({\mathcal {Y}}\) are packing polytopes. We present an \(O(\frac{\log \log m_1}{\log m_1} \frac{\log \log m_2}{\log m_2})\)-approximation algorithm for this problem where \(m_1\) and \(m_2\) are the number of packing constraints in \({\mathcal {X}}\) and \({\mathcal {Y}}\) respectively. In particular, we show that there exists a near-optimal solution \((\tilde{{\textbf{x}}}, \tilde{{\textbf{y}}})\) such that \(\tilde{{\textbf{x}}}\) and \(\tilde{{\textbf{y}}}\) are “near-integral". We give an LP relaxation of the problem from which we obtain the near-optimal near-integral solution via randomized rounding. We show that our relaxation is tightly related to the widely used reformulation linearization technique. As an application of our techniques, we present a tight approximation for the two-stage adjustable robust optimization problem with covering constraints and right-hand side uncertainty where the separation problem is a bilinear optimization problem. In particular, based on the ideas above, we give an LP restriction of the two-stage problem that is an \(O(\frac{\log n}{\log \log n} \frac{\log L}{\log \log L})\)-approximation where L is the number of constraints in the uncertainty set. This significantly improves over state-of-the-art approximation bounds known for this problem. Furthermore, we show that our LP restriction gives a feasible affine policy for the two-stage robust problem with the same (or better) objective value. As a consequence, affine policies give an \(O(\frac{\log n}{\log \log n} \frac{\log L}{\log \log L})\)-approximation of the two-stage problem, significantly generalizing the previously known bounds on their performance.
Similar content being viewed by others

References
Adams, W.P., Sherali, H.D.: A tight linearization and an algorithm for zero-one quadratic programming problems. Manag. Sci. 32(10), 1274–1290 (1986)
Adams, W.P., Sherali, H.D.: Linearization strategies for a class of zero-one mixed integer programming problems. Oper. Res. 38(2), 217–226 (1990)
Adams, W.P., Sherali, H.D.: Mixed-integer bilinear programming problems. Math. Program. 59, 279–305 (1993)
Audet, C., Hansen, P., Jaumard, B., Savard, G.: A branch and cut algorithm for nonconvex quadratically constrained quadratic programming. Math. Program. 87, 131–152 (2000)
Bandi, C., Bertsimas, D.: Tractable stochastic analysis in high dimensions via robust optimization. Math. Program. 134(1), 23–70 (2012)
Ben-Tal, A., El Housni, O., Goyal, V.: A tractable approach for designing piecewise affine policies in two-stage adjustable robust optimization. Math. Program. 182, 57–102 (2020)
Ben-Tal, A., Goryashko, A., Guslitzer, E., Nemirovski, A.: Adjustable robust solutions of uncertain linear programs. Math. Program. 99, 351–376 (2004)
Bertsimas, D., Bidkhori, H.: On the performance of affine policies for two-stage adaptive optimization: a geometric perspective. Math. Program. 153(2), 577–594 (2015)
Bertsimas, D., Brown, D.B., Caramanis, C.: Theory and applications of robust optimization. SIAM Rev. 53(3), 464–501 (2011)
Bertsimas, D., Goyal, V.: On the power and limitations of affine policies in two-stage adaptive optimization. Math. Program. 134, 491–531 (2012)
Bertsimas, D., Iancu, D.A., Parrilo, P.A.: Optimality of affine policies in multistage robust optimization. Math. Oper. Res. 35(2), 363–394 (2010)
Bertsimas, D., Ruiter, F.: Duality in two-stage adaptive linear optimization: faster computation and stronger bounds. Informs J. Comput. 28, 500–511 (2016)
Bertsimas, D., Sim, M.: The price of robustness. Oper. Res. 52, 35–53 (2004)
Chen, X., Deng, X., Teng, S.H.: Settling the complexity of computing two-player Nash equilibria. J. ACM 56(3), 1–57 (2009)
Chernoff, H.: A measure of asymptotic efficiency for tests of a hypothesis based on the sum of observations. Ann. Math. Stat. 23(4), 493–507 (1952)
Ćustić, A., Sokol, V., Punnen, A.P., Bhattacharya, B.: The bilinear assignment problem: complexity and polynomially solvable special cases. Math. Program. 166(1–2), 185–205 (2017)
Dhamdhere, K., Goyal, V., Ravi, R., Singh, M.: How to pay, come what may: approximation algorithms for demand-robust covering problems. In: 46th Annual IEEE Symposium on Foundations of Computer Science (FOCS’05), pp. 367–376 (2005)
El Housni, O., Goyal, V.: Beyond worst-case: a probabilistic analysis of affine policies in dynamic optimization. In: Proceedings of the 31st International Conference on Neural Information Processing Systems, pp. 4759–4767 (2017)
El Housni, O., Goyal, V.: On the optimality of affine policies for budgeted uncertainty sets. Math. Oper. Res. 46(2), 674–711 (2021)
El Housni, O., Goyal, V., Hanguir, O., Stein, C.: Matching drivers to riders: a two-stage robust approach. In: Approximation, Randomization, and Combinatorial Optimization. Algorithms and Techniques (APPROX/RANDOM 2021), vol. 207, pp. 12:1–12:22 (2021)
El Housni, O., Goyal, V., Shmoys, D.: On the power of static assignment policies for robust facility location problems. In: International Conference on Integer Programming and Combinatorial Optimization, pp. 252–267 (2021)
Feige, U., Jain, K., Mahdian, M., Mirrokni, V.: Robust combinatorial optimization with exponential scenarios. In: Fischetti, M., Williamson, D.P. (eds.) Integer Programming and Combinatorial Optimization, pp. 439–453 (2007)
Firouzbakht, K., Noubir, G., Salehi, M.: Linearly constrained bimatrix games in wireless communications. IEEE Trans. Commun. 64(1), 429–440 (2016)
Freire, A.S., Moreno, E., Vielma, J.P.: An integer linear programming approach for bilinear integer programming. Oper. Res. Lett. 40(2), 74–77 (2012)
Geoffrion, A.: Generalized benders decomposition. J. Optim. Theory Appl. 10, 237–260 (1972)
Gounaris, C., Repoussis, P., Tarantilis, C., Wiesemann, W., Floudas, C.: An adaptive memory programming framework for the robust capacitated vehicle routing problem. Transp. Sci. 50, 1139–1393 (2014)
Gupta, A., Nagarajan, V., Ravi, R.: Thresholded covering algorithms for robust and max–min optimization. Math. Program. 146, 583–615 (2014)
Gupta, A., Nagarajan, V., Ravi, R.: Robust and maxmin optimization under matroid and knapsack uncertainty sets. ACM Trans. Algorithms 12(1), 1–21 (2015)
Gupte, A., Ahmed, S., Cheon, M.S., Dey, S.: Solving mixed integer bilinear problems using milp formulations. SIAM J. Optim. 23(2), 721–744 (2013)
Gupte, A., Ahmed, S., Dey, S.S., Cheon, M.S.: Relaxations and discretizations for the pooling problem. J. Global Optim. 67, 631–669 (2017)
Hadjiyiannis, M.J., Goulart, P.J., Kuhn, D.: A scenario approach for estimating the suboptimality of linear decision rules in two-stage robust optimization. In: 2011 50th IEEE Conference on Decision and Control and European Control Conference, pp. 7386–7391. IEEE (2011)
Harjunkoski, I., Westerlund, T., Pörn, R., Skrifvars, H.: Different transformations for solving non-convex trim-loss problems by minlp. Eur. J. Oper. Res. 105, 594–603 (1998)
Konno, H.: A cutting plane algorithm for solving bilinear programs. Math. Program. 11, 14–27 (1976)
Lim, C., Smith, J.C.: Algorithms for discrete and continuous multicommodity flow network interdiction problems. IIE Trans. 39(1), 15–26 (2007)
Mangasarian, O., Stone, H.: Two-person nonzero-sum games and quadratic programming. J. Math. Anal. Appl. 9(3), 348–355 (1964)
Rebennack, S., Nahapetyan, A., Pardalos, P.: Bilinear modeling solution approach for fixed charge network flow problems. Optim. Lett. 3, 347–355 (2009)
Schaefer, T.J.: The complexity of satisfiability problems. In: Proceedings of the Tenth Annual ACM Symposium on Theory of Computing, STOC ’78, pp. 216–226. Association for Computing Machinery, New York (1978)
Sherali, H.D., Adams, W.P.: A hierarchy of relaxations between the continuous and convex hull representations for zero-one programming problems. SIAM J. Discret. Math. 3(3), 411–430 (1990)
Sherali, H.D., Adams, W.P.: A hierarchy of relaxations and convex hull characterizations for mixed-integer zero-one programming problems. Discret. Appl. Math. 52(1), 83–106 (1994)
Sherali, H.D., Adams, W.P.: A reformulation-linearization technique (rlt) for semi-infinite and convex programs under mixed 0–1 and general discrete restrictions. Discret. Appl. Math. 157(6), 1319–1333 (2009)
Sherali, H.D., Alameddine, A.: A new reformulation-linearization technique for bilinear programming problems. J. Global Optim. 2, 379–410 (1992)
Sherali, H.D., Smith, J.C., Adams, W.P.: Reduced first-level representations via the reformulation-linearization technique: results, counterexamples, and computations. Discret. Appl. Math. 101(1–3), 247–267 (2000)
Sherali, H.D., Tuncbilek, C.H.: A global optimization algorithm for polynomial programming problems using a reformulation-linearization technique. J. Global Optim. 2, 101–112 (1992)
Soland, R.: Optimal facility location with concave costs. Oper. Res. 22, 373–382 (1974)
Tawarmalani, M., Richard, J.P.P., Chung, K.: Strong valid inequalities for orthogonal disjunctions and bilinear covering sets. Math. Program. 124(1–2), 481–512 (2010)
Thieu, T.V.: A note on the solution of bilinear programming problems by reduction to concave minimization. Math. Program. 41(1–3), 249–260 (1988)
Vaish, H., Shetty, C.M.: The bilinear programming problem. Naval Res. Logist. Q. 23(2), 303–309 (1976)
Xu, G., Burer, S.: A copositive approach for two-stage adjustable robust optimization with uncertain right-hand sides. Comput. Optim. Appl. 70(1), 33–59 (2018)
Zhen, J., den Hertog, D., Sim, M.: Adjustable robust optimization via Fourier–Motzkin elimination. Oper. Res. 66(4), 1086–1100 (2018)
Zhen, J., Marandi, A., de Moor, D., den Hertog, D., Vandenberghe, L.: Disjoint bilinear optimization: a two-stage robust optimization perspective. INFORMS J. Comput. (2022)
Acknowledgements
The authors gratefully acknowledge Prof. Mohit Tawarmalani for valuable comments and discussions on an earlier version of the paper. The authors also thank the associate editor and the anonymous reviewers for their valuable suggestions and comments.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
A preliminary version of this paper with the same title was published in Integer Programming and Combinatorial Optimization (IPCO) 2022.
Appendices
Appendix A: Chernoff bounds
Proof of Chernoff bounds (a)
From Markov’s inequality we have for all \(t>0\),
Denote \(p_i\) the parameter of the Bernoulli \({\chi }_i\). By independence, we have
where the inequality holds because \(1+x \le e^x\) for all \(x \in {\mathbb {R}}\). By taking \(t=\ln ( 1+ \delta ) >0\), the right hand side becomes
where the first inequality holds because \( (1+x)^{\epsilon } \le 1+ \alpha x\) for any \(x \ge 0\) and \(\epsilon \in [0,1]\) and the second one because \(s \ge {\mathbb {E}}({\varXi } )= \sum _{i=1}^r \epsilon _i p_i\). Hence, we have
On the other hand,
Therefore,
\(\square \)
Proof of Chernoff bounds (b)
From Markov’s inequality we have for all \(t< 0\),
Denote \(p_i\) the parameter of the Bernoulli \({\chi }_i\). By independence, we have
where the inequality holds because \(1+x \le e^x\) for all \(x \in {\mathbb {R}}\). We take \(t=\ln ( 1- \delta ) < 0\). We have \( t \le - \delta \), hence,
where the inequality holds because \( (1-x)^{\epsilon } \le 1- \epsilon x\) for any \( 0< x <1\) and \(\epsilon \in [0,1]\). Therefore,
On the other hand,
Therefore,
Finally, we have for any \(0<\delta < 1\),
which implies
and consequently
\(\square \)
Appendix B: Proof of Theorem 4
Our proof uses a polynomial time transformation from the Monotone Not-All-Equal 3-satisfiability (MNAE3SAT) NP-complete problem (Schaefer [37]). In the (MNAE3SAT), we are given a collection of Boolean variables and a collection of clauses, each of which combines three variables. (MNAE3SAT) is the problem of determining if there exists a truth assignment where each close has at least one true and one false literal. This is a subclass of the Not-All-Equal 3-satisfiability problem where the variables are never negated.
Consider an instance \({\mathcal {I}}\) of (MNAE3SAT), let \({\mathcal {V}}\) be the set of variables of \({\mathcal {I}}\) and let \({\mathcal {C}}\) be the set of clauses. Let \({\textbf{A}} \in \{0,1\}^{|{\mathcal {C}}| \times |{\mathcal {V}}|}\) be the variable-clause incidence matrix such that for every variable \(v \in {\mathcal {V}} \) and clause \(c \in {\mathcal {C}}\) we have \(A_{cv}=1\) if and only if the variable v belongs to the clause c. We consider the following instance of CDB denoted by \({\mathcal {I}}'\),
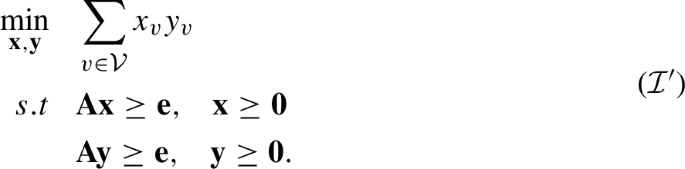
Let \(z_{{\mathcal {I}}'}\) denote the optimum of \({\mathcal {I}}'\). We show that \({\mathcal {I}}\) has a truth assignment where each clause has at least one true and one false literal if and only if \(z_{{\mathcal {I}}'} = 0\).
First, suppose \(z_{{\mathcal {I}}'} = 0\). Let \(({\textbf{x}}, {\textbf{y}})\) be an optimal solution of \({\mathcal {I}}'\). Let \(\tilde{{\textbf{x}}}\) such that \({\tilde{x}}_v = \mathbb {1}_{\{x_v > 0\}}\) for all \(v \in {\mathcal {V}}\). We claim that \((\tilde{{\textbf{x}}}, {\textbf{e}} - \tilde{{\textbf{x}}})\) is also an optimal solution of \({\mathcal {I}}\). In fact, for all \(c \in {\mathcal {C}}\), we have,
hence,
since the entries of \({\textbf{A}}\) are in \(\{0,1\}\). Therefore,
Finally, \({\textbf{A}} \tilde{{\textbf{x}}} \ge {\textbf{e}}\). Similarly, for all \(c \in {\mathcal {C}}\) we have,
hence,
since the entries of \({\textbf{A}}\) are in \(\{0,1\}\). Therefore,
where the equality follows from the fact that \(y_v = 0\) for all v such that \({\tilde{x}}_v = 1\). Note that \(\sum _{v \in {\mathcal {V}} } x_vy_v = z_{{\mathcal {I}}'} = 0\). This implies that \({\textbf{A}}({\textbf{e}} - \tilde{{\textbf{x}}}) \ge {\textbf{e}}\). Therefore, \((\tilde{{\textbf{x}}}, {\textbf{e}} - \tilde{{\textbf{x}}})\) is a feasible solution of \({\mathcal {I}}'\) with objective value \(\sum _{v \in {\mathcal {V}} } {\tilde{x}}_v(1-{\tilde{x}}_v) = 0 = z_{{\mathcal {I}}'}\). It is therefore an optimal solution. Consider now the truth assignment where a variable v is set to be true if and only if \({\tilde{x}}_v = 1\). We show that each clause in such assignment has at least one true and one false literal. In particular, consider a clause \(c \in {\mathcal {C}}\), since,
there must be a variable v belonging to the clause c such that \({\tilde{x}}_v = 1\). Similarly, since
there must be a variable v belonging to the clause c such that \({\tilde{x}}_v = 0\). This implies that our assignment is such that the clause c has at least one true and one false literal.
Conversely, suppose there exists a truth assignment of \({{\mathcal {I}}}\) where each clause has at least one false and one true literal. We show that \(z_{{\mathcal {I}}'} = 0\). In particular, define \({\textbf{x}}\) such that for all \(v \in {\mathcal {V}}\) we have \(x_v = 1\) if and only if v is assigned true. We have for all \(c \in {\mathcal {C}}\),
since at least one of the variables of c is assigned true. And,
since at least one of the variables of c is assigned false. Hence, \(({\textbf{x}}, {\textbf{e}} - {\textbf{x}})\) is feasible for \({\mathcal {I}}'\) with objective value \(\sum _{v \in {\mathcal {V}}} x_v(1-x_v) = 0\). It is therefore an optimal solution and \(z_{{\mathcal {I}}'} = 0\).
If there exists a polynomial time algorithm approximating CDB to some finite factor, such an algorithm can be used to decide in polynomial time whether \(z_{{\mathcal {I}}'} = 0\) or not, which is equivalent to solving \({\mathcal {I}}\) in polynomial time; a contradiction. \(\square \)
Appendix C: Derivation of the first level relaxation of the RLT hierarchy
Let us begin by writing PDB in the following equivalent epigraph form,
Reformulation phase. In the reformulation phase we add to the above program the polynomial constraints we get from multiplying all the linear constraints by linear constraints by \(x_i\), \(y_i\), \((1-x_i)\) and \((1-y_i)\) for all \(i \in [n]\). We get the following equivalent formulation of PDB,
Linearization phase. We replace the bilinear terms \(x_iy_j\), \(x_ix_j\) and \(y_iy_j\) in the above LP with their respective lower-bounds \(u_{ij}\), \(v_{i,j}\), \(w_{i,j}\). We get the following linear relaxation of PDB,
The above LP is known as the first level relaxation of the RLT hierarchy. The above LP can be further simplified as follows: the constraints in \({\textbf{v}}\) and \({\textbf{w}}\) in the above are redundant and can be removed without loss of generality. In fact, for any feasible solution \({\textbf{x}}, {\textbf{y}}, {\textbf{u}}\) of the resulting LP, one can take \(v_{i,j}=x_ix_j\) and \(w_{i,j}=y_iy_j\) to get a feasible solution of the above LP with same cost, and conversely for every feasible solution \({\textbf{x}}, {\textbf{y}}, {\textbf{u}}, {\textbf{v}}, {\textbf{w}}\) of the above LP, the solution \({\textbf{x}}, {\textbf{y}}, {\textbf{u}}\) is a feasible solution of the resulting LP with same cost. Also, the first (resp. sixth) set of constraints in the above LP can be obtained by summing the fourth and fifth (resp. seventh and eighth) set of constraints and can therefore be removed as well. We get the following equivalent LP relaxation of PDB that we refer to in this paper as the first level relaxation of the RLT hierarchy,
Appendix D: Proof of Lemma 4
Let \(\varvec{\omega }^*\) be an optimal solution of \({{\mathcal {Q}}^{\textsf{LP}}(\beta {\textbf{x}})}\), consider \({\tilde{\omega }}_1, \dots , {\tilde{\omega }}_m\) i.i.d. Bernoulli random variables such that \({\mathbb {P}}({\tilde{\omega }}_i = 1) = \omega ^*_i\) for all \(i \in [m]\) and let \(({\textbf{h}}, {\textbf{z}})\) such that \(h_i = \frac{\gamma _i{\tilde{\omega }}_i}{\beta }\) and \(z_i = \frac{\theta _i{\tilde{\omega }}_i}{\eta }\) for all \(i \in [m]\). We show that \(({\textbf{h}}, {\textbf{z}})\) satisfies the properties (5) with a constant probability. In particular, we have,
where the first inequality follows from a union bound on n constraints. The second equality holds because for all \(j \in [n]\) such that \(d_j = 0\) we have
Note that \(d_j = 0\) implies
by feasibility of \(\varvec{\omega }^*\) in \({{\mathcal {Q}}^{\textsf{LP}}(\beta {\textbf{x}})}\). Therefore,
almost surely. The second inequality follows from the Chernoff bounds (a) with \(\delta = \eta - 1\) and \(s=1\). In particular, \(\frac{\theta _i B_{ij}}{d_j} \in [0,1]\) by definition of \(\theta _i\) for all \(i \in [m]\) and \(j \in [n]\) such that \(d_j > 0\) and for all \(j \in [n]\) such that \(d_j > 0\) we have,
by feasibility of \(\varvec{\omega }^*\). Next, note that
Therefore, there exists a constant \(c > 0\) such that,
By a similar argument there exists a constant \(c' > 0\),
Finally we have,
Let \({\mathcal {I}}\) denote the subset of indices \(i \in [m]\) such that
Since \(\varvec{\omega }^*\) is the optimal solution of the maximization problem \({{\mathcal {Q}}^{\textsf{LP}}(\beta {\textbf{x}})}\) we can suppose without loss of generality that \(\omega ^*_i = 0\) for all \(i \notin {\mathcal {I}}\). In fact, the packing constraints of \({{\mathcal {Q}}^{\textsf{LP}}(\beta {\textbf{x}})}\) are down-closed (i.e., for every \(\varvec{\omega } \le \varvec{\omega }'\), if \(\varvec{\omega }'\) is feasible then \(\varvec{\omega }\) is also feasible), hence setting \(\omega ^*_i = 0\) for all \(i \notin {\mathcal {I}}\) still gives a feasible solution of \({{\mathcal {Q}}^{\textsf{LP}}(\beta {\textbf{x}})}\) and can only increase the objective value. Hence, \({\tilde{\omega }}_i = 0\) almost surely for all \(i \notin {\mathcal {I}}\) and we have,
where the last inequality follows from Chernoff bounds (b) with \(\delta =1/2\). In particular we have for all \(i \in {\mathcal {I}}\)
This is because the unit vector \({\textbf{e}}_i\) is feasible for \({{\mathcal {Q}}^{\textsf{LP}}(\beta {\textbf{x}})}\) for all \(i \in {\mathcal {I}}\) which implies
We also have,
Combining inequalities (8), (9) and (10) we get that \(({\textbf{h}}, {\textbf{z}})\) verifies the properties (5) with probability at least
which is greater than a constant for n and L large enough. Which concludes the proof of the structural property. \(\square \)
Appendix E: On Assumption 1
Assumption 1 can be made without loss of generality. To show this, we construct for every instance I of AR a new instance \({\tilde{I}}\) such that Assumption 1 holds under \({\tilde{I}}\) and the optimal value of \({\tilde{I}}\) is within a factor 2 of the value of I. This implies that our LP approximation from Sect. 4 under \({\tilde{I}}\) is an \(O(\frac{\log n}{\log \log n} \frac{\log L}{\log \log L})\) approximation for I. In particular, consider an instance I of AR given by,
To I we associate the following modified instance \({\tilde{I}}\),
where
Note that \({\tilde{I}}\) is indeed an instance of AR as the first and second-stage cost vectors \(\left( \begin{matrix} {\textbf{c}}\\ {\textbf{d}} \end{matrix}\right) \) and \({\textbf{d}}\) and the second-stage matrix \({\textbf{B}}\) all have non-negative coefficients and the first stage feasible set \(\tilde{{\mathcal {X}}}\) is still a polyhedral cone. Assumption 1 is verified under \({\tilde{I}}\) by definition of \(\tilde{{\mathcal {X}}}\). We now show that \({\tilde{I}}\) gives a 2-approximation of I. In particular, we prove the following lemma,
Lemma 6
\(z_{I} \le z_{{\tilde{I}}} \le 2 z_{I}\)
Proof
First of all, let \(\tilde{{\textbf{x}}}^*, \tilde{{\textbf{y}}}_0^*\) be an optimal solution of \({\tilde{I}}\). For every \(h \in {\mathcal {U}}\) we have,
Hence,
where the last inequality follows by feasibility of \({\tilde{\textbf{x}}}^*\) for I.
For the inverse inequality, let \({\textbf{x}}^*\) be an optimal solution of I, and let \({\textbf{y}}(0) \in {\hbox {argmin}}_{{\textbf{y}}\ge 0} \left\{ {\textbf{d}}^T {\textbf{y}} \;|\; {\textbf{A}}{\textbf{x}}^* + {\textbf{B}}{\textbf{y}} \ge {\textbf{0}}\right\} \). We have,
where the first inequality follows from the fact that \({\textbf{0}}\) is a feasible scenario of the uncertainty set and the last inequality follows by feasibility of \(({\textbf{x}}^*, {\textbf{y}}(0))\) for \({\tilde{I}}\) and because \({\textbf{c}}^T{\textbf{x}}^* \ge 0\). \(\square \)
Remark 1
Note that for every feasible affine policy of \({\tilde{I}}\) given by the first stage solution \((\tilde{{\textbf{x}}}, \tilde{{\textbf{y}}}_0)\) and the second-stage affine function \(\tilde{{\textbf{y}}}_\textsf{AFF}\), the affine policy given by the first stage solution \( \tilde{{\textbf{x}}}\) and the second-stage affine function \({\textbf{y}}_\textsf{AFF} =\tilde{{\textbf{y}}}_\textsf{AFF} + \tilde{{\textbf{y}}}_0\) is a feasible affine policy of I with same worst-case cost. This implies that the results of Sect. 5 also hold in the general case. In particular, the affine policies constructed in Sect. 5 under \({\tilde{I}}\) can be used to construct affine policies for I that are an \(O(\frac{\log n}{\log \log n} \frac{\log L}{\log \log L})\) approximation for I.
An example of an application of the two-stage problem where Assumption 1 does not hold is the following two-stage network design problem: consider a directed graph D(V, A) where each arc \(a \in A\) is associated with a first-stage cost \(c_a \ge 0\) and each node \(v \in V\) is associated with a second stage cost \(d_v \ge 0\) and receives an uncertain demand \(h_v \ge 0\). The decision maker chooses a flow vector \(f \in {\mathbb {R}}_+^{A}\) where \(f_{vw}\) represents the quantity of supply to node w coming from node v and incurs the first stage cost \(\sum _{vw} c_{vw} f_{vw}\), the demands are then revealed and the decision maker incurs a second-stage cost \(d_v \cdot (h_v + \sum _{w: vw \in A} f_{vw} - \sum _{w: wv \in A} f_{wv})^+\) for each node v where the flow balance \(\sum _{w: wv \in A} f_{wv} - \sum _{w: vw \in A} f_{vw}\) is lower than the demand \(h_v\). This example can be modeled as an instance of AR where \({\textbf{B}}={\textbf{I}}\) and \({\textbf{A}}\) is the incidence matrix of the considered directed graph. The flow vector f such that \(f_{vw}=1\) for some arc vw and \(f_{v'w'}=0\) for every other arc \(v'w'\) is such that \(({\textbf{A}}{\textbf{f}})_v = -1 < 0\).
Appendix F: Derivation of the LP formulation corresponding to the generalization of Algorithm 2 of El Housni and Goyal [19] to packing uncertainty sets
When the second-stage variable \({\textbf{y}}\) is restricted to affine policies of the form \({\textbf{y}}({\textbf{h}})=\sum _i \nu _i {\textbf{v}}_i h_i + {\textbf{q}},\) for some \(\nu _1, \dots , \nu _m \in {\mathbb {R}}\) and \({\textbf{q}} \in {\mathbb {R}}^{n}\), the two-stage problem AR becomes,
We use standard duality techniques to derive formulation EG. The first constraint is equivalent to
By taking the dual of the maximization problem, the constraint is equivalent to
Where \({\textbf{Y}} := [{\textbf{v}}_1, \dots , {\textbf{v}}_m]\). We then drop the min and introduce \({\textbf{v}} \) as a variable to obtain the following linear constraints,
We use the same technique for the second sets of constraints, i.e.,
By taking the dual of the maximization problem for each row and dropping the \(\min \) we get the following formulation of these constraints
Similarly, the last constraint
is equivalent to
Putting all together, we get the following formulation,
\(\square \)
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
El Housni, O., Foussoul, A. & Goyal, V. LP-based approximations for disjoint bilinear and two-stage adjustable robust optimization. Math. Program. 206, 239–281 (2024). https://doi.org/10.1007/s10107-023-02004-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10107-023-02004-9
Keywords
- Disjoint bilinear programming
- Two-stage robust optimization
- Approximation algorithms
- RLT
- Affine policies