Abstract
Existing work on task-oriented dialog systems generally assumes that the interaction of users with the system is restricted to the information stored in a closed data schema. However, in practice users may ask ‘out-of-schema’ questions, that is, questions that the system cannot answer, because the information does not exist in the schema. Failure to answer these questions may lead the users to drop out of the chat before reaching the success state (e.g. reserving a restaurant). A key challenge is that the number of these questions may be too high for a domain expert to answer them all. We formulate the problem of out-of-schema question detection and selection that identifies the most critical out-of-schema questions to answer, in order to maximize the expected success rate of the system. We propose a two-stage pipeline to solve the problem. In the first stage, we propose a novel in-context learning (ICL) approach to detect out-of-schema questions. In the second stage, we propose two algorithms for out-of-schema question selection (OQS): a naive approach that chooses a question based on its frequency in the dropped-out conversations, and a probabilistic approach that represents each conversation as a Markov chain and a question is picked based on its overall benefit. We propose and publish two new datasets for the problem, as existing datasets do not contain out-of-schema questions or user drop-outs. Our quantitative and simulation-based experimental analyses on these datasets measure how our methods can effectively identify out-of-schema questions and positively impact the success rate of the system.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Task-oriented conversational agents or chatbots are designed to provide users with specific predetermined services, such as booking a flight or reserving an event ticket. Such a chatbot must identify the intent (e.g. find restaurant) from the user utterances while also extracting necessary pieces of information, referred to as slots (e.g. restaurant cuisine). The end goal is to fill all the required slots, and complete the user-intended task, such as finding a restaurant specializing on a specific cuisine. These systems are often backed by a database, which is a collection of items with their attributes (slots) (Chen et al. 2020).
Existing work on task-oriented chatbots assumes a closed schema, that is, the interaction of users with the chatbot is limited to the information stored in the underlying database (Chen et al. 2020). However, in the real world, users often ask questions that the system cannot answer, because this information is out-of-schema, that

An example conversation for reserving a table at a restaurant where the user drops out when the system fails to answer an out-of-schema user query
is, this information is not available for the items in the database. For example, in Fig. 1 the system’s goal is to reserve a table at a restaurant for the user. The user proceeds with the conversation by providing a series of slot values to corresponding questions or suggestions from the chatbot. The user may also ask questions, such as “Are there any diabetes-friendly desserts?”. The system may be unable to answer this question as the information is absent from the service schema. We refer to such user queries as out-of-schema questions.
Not handling out-of-schema questions is costly, as the user may decide to drop out of the conversation, as shown in Fig. 1. User dropouts have a significant negative impact on the applications, such as decreased revenue in e-commerce chatbots.
Previous work has shown that users drop out of chatbot conversations more often when they ask a question to the bot, than when they respond to the bot by inputting information (Li et al. 2020). This study found that about 45% of users abandon the chatbot after just one “non-progress” event, that is, when the bot does not understand their intent or cannot handle it. Previous studies have shown that consumers are much more likely to repeat the same questions when researching a product, specifically related to a product’s determinant attributes (Fernando and Aw 2023). Periodically analyzing the chat log and answering these common questions offline to improve the effectiveness of a conversational AI system is common practice. For example, Ponnusamy et al. analyze recent Alexa chat logs periodically to discover unclear or error-prone user queries and retrain the system (Ponnusamy et al. 2020). A key challenge is that users may ask a large number of out-of-schema questions and it may be infeasible or too expensive for a domain expert to answer all of them.

A high-level overview of the two-stage pipeline for ranking 6 input dropped-out conversations. First, we detect which ones have out-of-schema questions and then we compute the benefit of answering these questions
This paper formulates the problem of detecting and selecting out-of-schema questions in a conversational system, and studies how to identify the most critical out-of-schema questions to answer, given a chat log, in order to maximize the expected success rate of the chatbot. We define a conversation as successful if the corresponding task is completed, for example, the user finds a suitable restaurant or books a flight.
The overview of our two-stage pipeline is shown in Fig. 2. In the first stage, we identify the out-of-schema questions from the dropped-out conversations using in-context learning, where a large language model makes predictions based on the task instruction and examples in the prompt. This approach does not require any fine-tuning i.e. no parameter updates and no annotated training data. This approach can handle out-of-schema questions in a new domain given a few examples without re-training meaning it is flexible and scalable. In the second stage, we calculate the potential benefits of answering each out-of-schema question and pick the ones with the highest benefit. Given a collection of conversations, identifying the best out-of-schema questions to answer is non-trivial, as different questions may have different impact on the success rate of the system. The impact is not only dependent on the frequency of a question but also on how close a question is to the success state of the conversation.
We propose two approaches to select the most critical out-of-schema questions: a naive approach of counting the frequency of each question, and a probabilistic Markov Chain-based approach. We refer to these approaches as ‘OQS algorithms’. The Frequency-based selection method picks the user questions that are asked in the highest number of failed conversations. The Markov Chain approach intuitively selects questions closer to the success state. By selecting such questions, the Markov Chain approach reduces the number of potential dropout paths, thereby increasing the likelihood of reaching the success state.
To evaluate the proposed OQS algorithms, we created two new datasets. Existing datasets such as MultiWoz Budzianowski et al. (2018), SNIPS (Coucke et al. 2018), ATIS (Liu et al. 2019), SGD (Rastogi et al. 2020), DST9 Track1 (Kim et al. 2020) are all grounded in the closed schema or external knowledge sources. None of these datasets contains user drop-outs due to the lack of available information. The only exception is Maqbool et al. dataset (Maqbool et al. 2022) which includes “off-script” (similar to our “out-of-schema”) user queries at the end of each dialog. However, all out-of-schema questions appear when all required slots have been filled, which is not realistic. Our new datasets overcome these limitations; they contain task-oriented conversations with out-of-schema user questions appearing at different positions.
The contributions of this paper are:
(1) We formulate the problem of detecting and selecting out-of-schema questions in a conversational system, and propose a two-stage pipeline to solve these problems.
(2) We propose an in-context learning (ICL) approach for detecting out-of-schema questions in a conversation.
(3) We propose two out-of-schema question selection (OQS) algorithms: Frequency-based and Markov Chain-based.
(4) We create and publish two datasets for the problem.Footnote 1
(5) We evaluate our algorithms to solve the out-of-schema question detection and selection problems through both quantitative methods, including SOTA supervised and unsupervised models, and a realistic simulation approach. We achieve up to 48% improvement over the state-of-the-art for out-of-schema question detection, and 78% improvement in the OQS problem over simpler methods.
2 Background and problem formulation
2.1 Previous work
2.1.1 User drop-out from chatbot
Most slot-filling models (Kim et al. 2014; Abro et al. 2022; Larson and Leach 2022) ignore the possibility of a user dropping out of a conversation. Little work has studied this behavior. Even the metrics for task-oriented dialog systems evaluation, such as user satisfaction modeling, do not take user dropouts’ impact on the system’s success into consideration (Siro et al. 2022; Pan et al. 2022; Deng et al. 2022). Li et al. Li et al. (2020) studied different types of “Non-Progress” events in a banking chatbot, such as when a user has to reformulate their question. A key difference from our setting is that we have a clearly defined success state, whereas they are trying to learn when the user is dissatisfied with the chatbot, based on the Non-Progress events. Their work is descriptive, that is, they do not propose a method to decide what new information to ingest to the chatbot to improve its future performance. External knowledge-grounded beyond domain APIs. Kim et al. Kim et al. (2020) published a dataset containing ‘out of scope’ questions grounded in external knowledge by exploiting the MultiWoz (Budzianowski et al. 2018) dataset. Their work relies on a large amount of training data to fine-tune their BERT model (Devlin et al. 2018) for classifying the out-of-scope questions from their proposed dataset. However, their approach is less flexible, since their model needs to be retrained when new domains are introduced or for domains where enough training data is not available. To address the above challenges, we propose our in-context learning approach to detect out-of-schema questions which is flexible, easy-to-use, and scalable. We compare our out-of-schema question detection module’s performance to their proposed approach in Sect. 4.2. While their focus lies in searching for answers within external knowledge sources, our approach is significantly different than theirs. In this paper, we assume that only a human expert can answer these questions, so our focus is on ranking these questions to better utilize the expert’s time in selecting and answering questions. We recognize the limitations of human bandwidth and prioritize efficiency by strategically identifying and addressing the most critical questions. This is important for systems where frequent system updates are essential, emphasizing the significance of human involvement in addressing high-priority inquiries.
2.1.2 In-context learning in task-oriented dialog systems
Dialogue state tracking (DST) is an important module in many task-oriented dialogue systems. Hu et. alHu et al. (2022) proposed an in-context learning framework for DST, unlike previous studies which explored zero/few-shot DST, with finetuning pre-trained language models. They reformulated DST into a text-to-SQL problem and directly predicted the dialogue states without any parameter updates. Inspired by their work, we formulate our out-of-schema question detection problem into a question-answering task, utilizing few-shot examples.
2.2 Problem formulation

In-context learning context contains slot descriptions in the instructions, one of the two prompt choices, and a test dialog. <Answer3> for Prompt1 and <Answer> for Prompt2 determine if the last question is out-of-schema or not. For D-MultiWoz, the slot names are: pricerange, area, food, name, bookday, bookpeople and booktime (Complete prompt is shown in Appendix A)
A task-oriented chat log D comprises of conversations \(c_1\), \(c_2\), \(\ldots\), \(c_m\). A conversation, \(c_i\) consists of a sequence of turns, denoted as \(t_1,t_2,\ldots ,t_z\) and a boolean outcome value of SUCCESS or DROP, indicating if the conversation completed the desired user task or the user dropped out, respectively. Each turn \(t_j\) consists of an utterance, from the user or the chatbot, and a subset of the slots whose values are either requested or provided, as shown in Fig. 1.
There are two types of slots: the required slots (\(S=\{s_1,s_2,\ldots ,s_n\}\)) and the supporting slots. The system’s goal is to fill the n required slots with values extracted from the user utterances and then perform the relevant task for the user (Jurafsky and Martin 2009) i.e. reach the SUCCESS state. The supporting slots, which are the target of user questions, can provide additional information about an item and guide both the user and the system to reach SUCCESS. For example, the required slots may be ‘food’ and ‘area’, and the supporting slots may be ‘parking’ and ‘phone’. Supporting slots are further split to in-schema and out-of-schema. Supporting in-schema slots is not important in this paper, as the system can always provide this information if the user asks about these.
Consider the example shown in Fig. 1. We see a conversation, \(c_i \in D\) which consists of 6 turns (\(z = 6\)). The user provided three required slot values by the end of turn \(t_4\). The user then asks an out-of-schema question, Q at turn \(t_5\), requesting the value of an out-of-schema slot (‘diabetes-friendly’). The system cannot answer Q and the user drops out.
2.2.1 Problem definition
The input to the problem is a chat log D of dropped-out conversations, and an integer k. The expected output is the k out-of-schema questions that, if answered will maximally increase the expected number of successful conversations in D.
We assume that the domain expert answers out-of-schema questions offline, that is, we extract out-of-schema questions from a past chat log, and select some of them to answer. We also assume that many of these questions will be repeated in future chats, so their answers will increase the future success rate.
3 Proposed pipeline
In this section, we discuss our two-staged pipeline for detecting and selecting out-of-schema questions. The first stage of our pipeline detects out-of-schema conversations from a set of dropped-out conversations, D, and the second stage selects the most critical out-of-schema questions from these conversations using our OQS algorithms.
3.1 Out-of-schema question detection
Large language models (LLMs) have demonstrated impressive performance across a wide spectrum of question-answering (QA) domains (Kojima et al. 2022; Wang et al. 2023; Zhao et al. 2023). Leveraging an in-context learning few-shot setting (Brown et al. 2020), we reformulate the task as a question-answering task. The prompt templates are shown in Fig. 3. We consider two different choices of question formats in order to ensure the robustness of our method. The general instruction contains the task and slot descriptions associated with the task ontology, directly posing a question to identify out-of-schema or in-schema (Prompt2) or posing 3 consecutive questions to elicit chain-of-thought reasoning (Prompt1) (Wei et al. 2022), a set of examples, and finally a test dialog ending with a user turn. Each example consists of a dropped-out dialog concluding with a user turn. The task of the LLM is to answer the question(s) given the dialog history. The chain-of-thought prompt (Prompt1) identifies an out-of-schema question step by step, first by checking if the last user turn contains any slot values, then checking if the last turn is a question about a slot, and finally checking if the last turn is a question about undefined information. The response to the third question determines whether the last user turn constitutes an out-of-schema question. The problem can be formulated as:
where, \(f(c_i)\) returns the conversation \(c_i\) and the out-of-schema question, Q associated with it (the last user turn), if the last user turn is an out-of-schema question. The final output of this stage is the set of conversations having out-of-schema questions, \(D_o\subseteq D\) and the set of out-of-schema questions, \(\mathbb {Q}\). For example, in Fig. 2, the output from the first stage is \(D_o= {c_1, c_2, c_3, c_4, c_6}\) and \(\mathbb {Q} = {Q1, Q2, Q3}\).
Note that posing the task as a question-answering task and providing good examples gives the large language model a better understanding of the task and examples. We also experimented with different prompting techniques such as posing the task as a classification task, or providing different sets of instructions. The setting shown in Fig. 3 performed the best in different contexts for all the datasets. A detailed example prompt is shown in Appendix A.
3.2 OQS algorithms
In this stage, our two OQS algorithms select the k most critical out-of-schema questions from the collection of out-of-schema questions, \(\mathbb {Q}\) (present in the chat log \(D_o\)) returned by the out-of-schema question detection stage. This stage involves modeling each conversation first and then calculating the benefit of each out-of-schema question within the modeled conversations.
The proposed OQS algorithms compute the total benefit B(Q) for each out-of-schema question \(Q \in \mathbb {Q}\), and select the set of k questions I with the highest benefit, that is, \(I=\arg \max _{I\subseteq \mathbb {Q}:|I|=k}\sum _{Q\in I}B(Q)\), where \(B(Q) = \sum _{i=1}^{|D_o|} benefit(Q,c_i)\).
Here \(benefit(Q,c_i)\) is the benefit of answering Q for a single conversation \(c_i\). As we will see, the proposed algorithms use different ways to model the conversations and compute \(benefit(Q,c_i)\).
3.2.1 Frequency-based selection

a Markov chain modeling of a conversation, where each state represents a user action: \(s_i\) means the user has provided \(i-1\) slot values so far, \(q_i\) means that the user asks a question and \(SUCCESS~ \& ~ DROP\) are the two absorbing states. b Shows the state transitions in the dotted box of a in more detail. \(r_i\) and \(w_i\) mean that the system knows or does not know the answer to \(q_i\), respectively
The Frequency-based Selection method models a conversation as a set of out-of-schema questions, and picks the most frequent ones across all conversations. The benefit of a question Q with respect to a conversation \(c_i\) in out-of-schema conversations \(D_o\) is defined as: \(benefit(Q,c_i) = 1, ~if ~Q \in c_i; ~0, ~otherwise\).
3.2.2 Markov chain-based selection

a Markov chain representation of conversation, \(c_i\) from Fig. 1 where slots \(`food', `area' ~and~ `price\_range'\) have been filled, b & c are replays of conversation, \(c_i\) shown in a when q is answered and not answered respectively. \(S_Q^a(c_i)\) & \(S_Q^b(c_i)\) (the success probabilities of replaying conversation \(c_i\) after and before Q is answered, respectively) are calculated using Algorithm 1. It should be noted that once the user decides to go back to state \(s_4\) irrespective of Q being answered or not, they may or may not ask a new out-of-schema question, leading to transitions to either \(q_4\) or \(s_5\). The \(\ldots\) refer to the states between \(s_4\) and \(s_n\)
To address the limitations of the Frequency-based Selection, mainly that the position of a question is not considered (meaning how far it is asked from the success state), we model the user behavior when interacting with a chatbot system. Previous studies have shown the effectiveness of Markov Chains in modeling and explaining the user query behavior (Jansen et al. 2009), reformulating queries during interactions with systems via absorbing random walk for both web and virtual assistants (Wang et al. 2015; Ponnusamy et al. 2020), and modeling query utility (Zhu et al. 2012). These approaches have been proven to be highly scalable and interpretable due to intuitive definitions of transition probabilities. In our approach, we first model the interactions between a user and the system in a task-oriented dialog as a Markov chain, where the states and transitions are determined by the user actions. Then, we use this model to measure the benefit of answering a question, which accurately estimates the impact of answering that question on the overall system success rate.
3.2.3 Conversation modeling
The overall modeling flow is illustrated in Fig. 4. In each turn of the conversation, the user either provides a slot value \(s_i\) or asks a question Q (we assume one at a time for simplicity), leading to state transitions \(s_i \rightarrow s_{i+1}\) or \(s_i \rightarrow q_i\) (corresponding substates (\(r_i\) or \(w_i\)) shown in Fig. 4b). The states \(s_i\) indicate that the system is waiting for the value of slot \(s_i\), while states \(q_i\) represent the user asking a question. If an in-schema question is asked, the system responds correctly (substate \(r_i\)) and transitions back to slot-filling (state \(s_i\)). In the case of an out-of-schema question, the system has no answer (substate \(w_i\)), and the user may either drop out (state DROP) or continue (returning to state \(s_i\)). The diagram includes absorbing states DROP and SUCCESS, indicating the end of the conversation. There is also an “initial” state \(s_0\) for the start of the Markov chain. Each conversation can be represented as a path in Fig. 4a, terminating in either SUCCESS or DROP. The transition probabilities are specified in Table 1. Figure 5a demonstrates the modeling of a conversation, where \(n=7\) required slots named: restaurant_food, restaurant_area, restaurant_price_range, restaurant_name, restaurant_bookday, restaurant_bookpeople and restaurant_booktime need to be filled to reserve a restaurant table.
3.2.4 Benefit score calculation

Calculating benefit of an out-of-schema question
In this section, we discuss how to compute the benefit of answering an out-of-schema question, Q concerning a chat log of dropped-out conversations \(D_o\), given the conversation modeling in Sect. 3.2.3.
The benefit of a question Q with respect to a single conversation, \(c_i\), is defined as the increase in the success rate in chat log \(D_o\): \(benefit(Q,c_i) = (S_Q^a(c_i) -S_Q^b(c_i)),~ ~if ~ Q \in c_i; ~0~ ~otherwise\),
where \(S_Q^a(c_i)\), \(S_Q^b(c_i)\) are the success probabilities of replaying conversation \(c_i\) after and before Q is answered, respectively.
We define a replay of a conversation \(c_i\) as a hypothetical future conversation that is identical to \(c_i\) up to the point when out-of-schema question Q is asked. Figure 5b and c represent the replays of the conversation model shown in Fig. 5a, after and before the question Q is answered respectively. The probability of a random user reaching the SUCCESS state is calculated for both replays. If Q is not answered by the system, the user will drop out with probability \(Pr^{qd}\) which equals \((1-Pr^{qr}) \cdot Pr^{wd}\); and with probability \(Pr^{qs}\) which equals \(1 \cdot Pr_{qr} + (1-Pr^{qr}) \cdot (1-Pr^{wd})\), will go back to the last slot state \(s_i\) and continue the conversation (following Fig. 4b).
The benefit calculation algorithm (Algorithm 1) takes an out-of-schema question Q, a chat log of dropped-out conversations \(D_o\), a set of required slots \(S = {s_1,\cdots ,s_n}\), and the transition probabilities \(\tau\) of Table 1 as inputs. It outputs the benefit B(Q) for each out-of-schema question Q in \(D_o\). The algorithm checks for each conversation \(c_i\) in \(D_o\) whether question Q has been asked. If not, the algorithm proceeds to the next conversation \(c_{i+1}\). If question \(Q \in c_i\), the algorithm determines the remaining required slots (\(R\subseteq S\)) that need to be filled to reach SUCCESS. If a random user repeats conversation \(c_i\) up to the point when question Q is asked and by this time \(i-1\) slots have been filled, these remaining slots comprise the states \(s_i,\ldots , s_{n}\) in the Markov chain representation of the replay. The algorithm creates two adjacency matrices representing two Markov chains, \(M_a\) and \(M_b\), for replaying conversation \(c_i\) when question Q is and is not answered, respectively. The only difference between these two Markov representations is that \(M_a\) starts with \(start =\) substate \(r_i\), assuming that the system answers the question correctly, and \(M_b\) starts with \(start =\) substate \(w_i\), assuming that the system failed to answer question Q. The PageRank formula (Brin and Page 1998) is then used to calculate the probability of reaching the SUCCESS state in both replays. We use a damping factor of 0.99 (\(\approx 1\)), which intuitively means the random user always follows a transition edge, while at the same time guaranteeing to lead to one of the absorbing states. We calculate the PageRanks of all the states of the Markov chain until the results converge. The benefit of answering Q for this conversation \(c_i\) is calculated as the increase in the PageRank of the SUCCESS state when Q is answered (\(S_{Q}^a\)) compared to when Q is not answered (\(S_{Q}^b\)). The total benefit score B(Q) is obtained by summing \(benefit(Q,c_i)\) over all conversations.
4 Empirical evaluation
In this section, we first present the datasets we built for the OQS task. Then we present our experimental setup and results.
4.1 OQS datasets

Transformation of an original conversation from MultiWoz dataset to one conversation of our D-MultiWoz dataset; the dotted red box is part of the original conversation which is removed in our D-MultiWoz conversation and turn \(t_5\) now becomes the out-of-schema question
The existing datasets mentioned in Sect. 1 are widely used for dialog state tracking tasks. However, none of these datasets contain out-of-schema user questions leading to users dropping out without achieving the goal they had in mind. Maqbool et al. built a dataset (Maqbool et al. 2022) including off-script user questions seeking additional information but these questions always appeared after all the required slots have been filled.
For our OQS task, we need a dataset having multi-turn conversations and a number of out-of-schema user questions that can be asked at any point of the conversation leading users to drop out. We extended two existing datasets (Budzianowski et al. 2018; Maqbool et al. 2022). The summary of our proposed datasets is given in Table 2. Our first dataset, D-MultiWoz (D stands for “Drop-out”), extends the latest version of the MultiWoz (2.2) Budzianowski et al. (2018). We chose the “restaurant” domain and inserted five categories of unique out-of-schema questions in the existing conversations. Our second dataset, D-SGD, is a modified version of the dataset provided by Maqbool et al. (2022). They built their dataset by including Amazon Mechanical Turk queries to the SGD (Rastogi et al. 2020) dataset. However, the queries always appear after all the required slots have been filled and the system has successfully booked an event ticket. D-SGD contains the same conversations with out-of-schema questions appearing at different points of the conversations after different numbers of filled slots.
4.1.1 D-multiwoz dataset
4.1.1.1 Limitations of multiWoz dataset
Multiwoz (Budzianowski et al. 2018) is a large-scale Wizard-of-Woz multi-turn conversational corpus spanning over eight domains. Each conversation consists of a goal, a set of user and system turns. In each turn, a user either requests a slot value or provides one. An out-of-schema question is never asked, and users never drop out. We overcame the aforementioned limitations by injecting out-of-schema questions and user dropouts into the conversations of MultiWoz.
4.1.1.2 Modifications in D-MultiWoz
We refined the MultiWoz dataset to include out-of-schema questions leading to user dropouts. We define five categories of questions (initial, area, food, price_range and restaurant), which may be asked based on the slots that have already been filled, as shown in Table 3. We create at least one new conversation (see below for the case where we add more than one) by inserting an out-of-schema question for each conversation in MultiWoz. The modification steps are shown for an example conversation in Fig. 6. The modification involves selecting a random user turn (t), inserting a chosen question following Table 3, responding with “I don’t know" from the system, and truncating the dialogue thereafter. If the initial turn is selected (\(t=1\)), the process is repeated to avoid using the very first turn again.
Note that the MultiWoz dataset contains data from eight domains. We chose the ‘Restaurant’ domain due to its broader scope for inserting various categories of out-of-schema questions after different slots. Our new dataset, D-Multiwoz contains 523 conversations each having one of the 240 unique out-of-schema questions and leading to dropouts of the user. Some questions are repeated across multiple conversations in the dataset.
4.1.2 D-SGD dataset
4.1.2.1 Limitations of the augmented SGD dataset in Maqbool et al. (2022)
Maqbool et. al curated the SGD Dataset by adding self-contained off-script questions, focusing on anaphora resolution. Their questions were mostly asked after filling all the required slots and completing key tasks, like booking tickets. This limits insights into how question timing affects their value in task completion. This focus leaves a gap in understanding how the questions’ position impacts the success state for evaluating OQS algorithms.
4.1.2.2 Modifications in D-SGD
The construction of the D-SGD dataset aims to explore the handling of out-of-schema questions by including them at different conversation stages. We move a self-contained question from the end of each conversation to an earlier user turn, replacing the original utterance (e.g., moving \(t_7\) to \(t_5\) in Fig. 7), and eliminating the subsequent conversation. Our dataset specifically focuses on the intent of booking event tickets, chosen for its increased complexity compared to finding events, and offers a greater challenge for addressing the OQS problem.

Transformation of an original conversation from Maqbool et al.’s dataset (Maqbool et al. 2022) to one conversation of our D-SGD dataset; the dotted red box is part of the original conversation which is removed in our D-SGD conversation and turn \(t_7\) now becomes \(t_5\)
4.2 Experimental setup
4.2.1 Out-of-schema question detection experimental details
We implement our ICL approach on instruction-tuned open-source LLMs, including Flan-t5-xl (Chung et al. 2022), Llama-2-7B (Touvron et al. 2023) and closed-source bigger LLMs: GPT-4 (OpenAI 2023) and GPT\(-\)3.5 (Brown et al. 2020) following the prompts shown in Fig. 3 with 5 examples. We evaluate our Out-of-schema Question detection method on our two datasets: D-MultiWoz and D-SGD, along with the ‘restaurant’ domain (to keep it consistent with D-MultiWoz evaluation) of ‘DST9 Track1’ dataset of external knowledge-grounded ‘out of scope’ questions provided by Kim et al. (2020). We use Kim et. al. BERT-based Devlin et al. (2018) Neural Classifier fine-tuned on out-of-domain question detection as one of our baselines to compare with our ICL approach. As we formulate our task as a yes/no question-answering, we also show comparisons with supervised QA models T5-base, Roberta-base and BERT-large fine-tuned on boolean QA [32-34](Clark et al. 2019) as baselines (More details in Appendix B.4). We demonstrate the results in Sect. 4.3.
4.2.1.1 OQS algorithms experimental details
We evaluate our OQS algorithms in three different ways. First, we measure how much applying each algorithm brings the conversations closer to the success state, that is, how much we reduce the number of hops (slots) distance from the current state to the success state (Sect. 4.3). We perform a simulation of conversations, based on realistic parameters, to measure the increase in the success rate after applying the proposed algorithms (Sect. 4.3). The simulation uses parameters computed based on the datasets (following Table 1) where possible. We also analyze the performance of our OQS algorithms using few-shot prompting in GPT-4, where GPT-4 estimates the probability of completion of each conversation based on the information collected so far (Sect. 4.3). Hackl et al. (2023) demonstrated GPT-4’s consistent human-level accuracy in automated evaluation tasks across multiple iterations, time spans, and stylistic variations.
We evaluate the two OQS algorithms on the D-MultiWoz and D-SGD datasets. The questions in the DST9 Track1 dataset (Kim et al. 2020) are inherently grounded in existing knowledge resources. This characteristic contradicts the primary objective of our work, which is to identify and prioritize the most critical questions, whose answers are not known, for the system admins. And so we exclude this dataset from the evaluations of the OQS algorithms.
To define the SUCCESS state, we establish a set of required slots S for each dataset. The D-SGD dataset has four predefined slots, while the D-MultiWoz dataset lacks a specific set of required slots. For D-MultiWoz, we individually determine required slots for each conversation based on the number of slots filled in the original MultiWoz conversation before reaching success. As such, different conversations have varying numbers and sets of required slots, which are all subsets of this set of slots: restaurant-food, restaurant-area, restaurant-pricerange, restaurant-name, restaurant-bookday, restaurant-bookpeople, and restaurant-booktime. Transition probabilities from Table 5 are used for Markov-based evaluation, with \(Pr^{sq}\) computed from the datasets Table 1. Authors selected values for \(Pr^{qr}\) (probability of system responding correctly) and \(Pr^{wd}\) (probability of dropout) to ensure a diverse set of experiments, as these values are constant for our datasets (all out-of-schema questions lead to dropout, \(Pr^{qr}=0\) and \(Pr^{wd}=1\)). Four values for \(Pr^{wd}\) were used to model users with varying degrees of patience when their questions are not answered. Additionally, alongside our proposed methods, we include a Random method, selecting k random out-of-schema questions, as there are no established baselines for the problem.

a number of conversations where the top-ranked questions appear up to 1, 2 and 3 hops away from SUCCESS for D-SGD (top) and D-MultiWoz (bottom), \(Pr^{qr} = 0.2\); b same for D-MultiWoz only, \(Pr^{qr} = 0.5\)
4.3 Experimental results
4.3.1 Evaluation of Out-of-schema Question detection framework
Table 4 shows that GPT-4 achieves the overall best performance on all three datasets for all three metrics for both prompt choices. We believe that the superior performance of GPT-4 is due to its stronger reasoning capabilities. Bang et al. also showed evidence of GPT-4’s superior ability against other LLMs and GPT\(-\)3.5 for varied reasoning tasks, including classification and question-answering (Bang et al. 2023). Our results highlight the QA reasoning limitations of the supervised models and smaller open-source LLMs in comparison with GPT-4. However, all the LLMs achieve comparable or better performance than the supervised baselines on unseen datasets at least for one of the prompt settings. The authors in the paper (Kim et al. 2020) mentioned that the BERT classifier works well when restricted only to their training dataset or similar. Both of our datasets have some common slots such as ‘location’, ‘date’, ‘number of people’, which are similar to their training data. Our analysis suggests that this resemblance contributes to the high precision of the baseline on D-MultiWoz and D-SGD. However, the baseline can only identify around 35% of the total out-of-schema questions whereas GPT-4 achieves up to 48% improvement on D-MultiWoz and D-SGD, and upto 10% improvement on their test set over the baseline in detecting out-of-schema questions.
Our ICL approaches achieve comparable or better performance on all three datasets having different slots and goals without any training cost or data. The supervised bert-large model tends to have a very high recall, however, the precision is low implicating its tendency to mark all utterances as ‘out-of-schema’ without properly learning the differences. Flan-t5-xl performs very poorly on Prompt1 and comparably to Llama2-7B for Prompt2 indicating its limitations in understanding longer/step-by-step task specifications. On the contrary, step-by-step reasoning help improve the performance of Llama2 and GPT\(-\)3.5. However, GPT-4 outperforms all baselines and LLMs with a substantial performance gap for all contexts and scenarios. (More experiments in Appendix B.1).
4.3.2 Evaluation of OQS algorithms using distance from SUCCESS state
In this experiment, we assume that the questions selected by the OQS algorithms are answered for each conversation in a dataset, denoted as \(\mathbb {D}\). Let \(D' \subseteq \mathbb {D}\), be the set of out-of-schema conversations ending in question Q. For a conversation \(c_i\) in \(D'\) with \(x_i\) filled slots out of a total of n required slots, the conversation is considered \(n - x_i\) hops away from the SUCCESS state. We count the number of conversations in \(D'\) that are 1, 2, or 3 hops away, considering different values of \(Pr^{wd}\), \(Pr^{qr}\), and k for both the D-SGD and D-MultiWoz datasets.
The results in Fig. 8 show that the Markov-based Top k question selection significantly brings a higher number of conversations closer to the success state across different values of \(Pr^{wd}\), assuming \(Pr^{qr}\) is set to 0.2. The Markov-based algorithm consistently outperforms the Frequency-based and Random approaches, with a more evident superiority for larger values of k. Note that, the Frequency-based method performs porrly with larger k due to ties in frequencies, resulting in random selection from questions with the same frequency. For brevity, we show only one graph for \(Pr^{qr} = 0.5\), as similar trends are observed in other cases (Fig. 8b).
In the above discussion, we view each question as unique. However, in practice, different questions may have similar or identical meanings. For that, we also study OQS-Cluster, where we first cluster the questions based on their semantics, and then pick the Top k clusters to answer. The details of this setting is shown in Appendix B.2.
4.3.3 Evaluation of OQS algorithms using Success Rate for Simulated Users
We evaluated our algorithms by running simulated conversations, where the system has been taught the answers to the top-k questions selected by the corresponding OQS algorithm. The evaluation measures the increase in success rate achieved by addressing the Top k questions, to scenarios where the system couldn’t answer these questions.
We use conversation replays from \(D_o\), as defined in Sect. 3.2.4, up to the point when an out-of-schema question Q was asked. If the Q is one of the Top k questions selected by the OQS algorithm, then we set \(Pr^{qr}\) to 1 (as in Fig. 5b), otherwise we set it to 0 (as in Fig. 5c) for that particular path. Each simulated conversation continued until reaching a SUCCESS or DROP state following the transition probabilities shown in Table 1 and chooses a path following Fig. 4. We performed 100 such simulations for each conversation in the chat log, considering four distinct user profiles with varying degrees of patience (different values of \(Pr^{wd}\) as shown in Table 5).
Our metric for evaluation was the percentage increase in success rate, calculated as the difference between successful runs with and without training on the top-k questions. Specifically, let \(S_k\) (and \(S_0\)) be the total number of successful simulated runs when the system has been taught (and not been taught) the answers to the top k questions. Then, our evaluation metric is defined as: \(\%~increase~in~success~rate = \frac{S_k - S_0}{S_0} \times 100\%\).
We present our simulation results in Table 6. The values of \(S_0\) are shown in the last two columns of Table 6. We show the comparisons among the three approaches for four different user profiles and for four different values of k, when \(Pr^{qr}=0.2\).
The results demonstrate that the Markov-based approach is superior than the other two, showcasing up to a 78% improvement compared to Frequency-based and up to 313% improvement compared to the Random approach across different user profiles and values of k. This improvement is particularly higher when the likelihood of user dropouts (\(Pr^{wd}\)) is higher, emphasizing the effectiveness of considering question position, especially in scenarios where dropouts are more frequent.
4.3.4 Evaluation of OQS algorithms using GPT-4 Chat completion estimation
In addition to our standard evaluations, we extended the performance analysis of the OQS algorithms in a few-shot setting using GPT-4. Specifically, we prompted GPT-4 to estimate the likelihood of the system successfully gathering all required information and making a reservation, given a dropped-out conversation due to an out-of-schema question being asked. We provided two few-shot examples, one with a very low chance of completion and another with a very high chance of chat completion. The detailed prompt for this setting is available in Appendix B.1. We calculate the average score of conversations containing the Top-k questions. We compare GPT-4 scores on the conversations with the Top-k out-of-schema questions ranked by the two OQS algorithms.
Table 7 shows that all 4 variants of the Markov-based ranking are scored higher than the Frequency-based ranking on both datasets. This signifies that Markov-based methods are better at predicting the success of task-oriented dialog systems. As an additional verification measure, the authors conducted a random selection of 50 evaluations by GPT-4, confirming that the obtained results are reasonable.
5 Conclusion
We address the significant challenge of handling out-of-schema questions in task-oriented dialog systems, which, if unaddressed, could lead to user dropouts. We highlight the bandwidth limitation of humans to manually respond to the potentially vast number of these questions, and introduce a novel two-stage pipeline for the detection and selection of the most significant out-of-schema questions aimed at enhancing system success rates. We publish two datasets, specifically designed to include out-of-schema questions and user dropouts. Our experimental evaluation, utilizing both quantitative and simulation-based analysis, shows that our few-shot ICL approach achieves a new state-of-the-art in detecting out-of-schema/scope questions, and our OQS algorithms, especially the Markov-based method, significantly increase the success rate of task-oriented dialog systems. We release our datasets publicly to elicit future research in this area.
5.1 Limitations
In our work, we assume uniform dropout probability for all unanswered questions due to the unavailability of any dataset to classify the importance of a user question based on its effect on conversation dropout. In future, we will explore the semantics of out-of-schema questions to predict the dropout likelihood. Our analysis also does not consider the varying costs of answering different questions. For example, getting the address of restaurants from public sources might be easier than verifying its vegan options, which could be more labor-intensive. Integrating the cost of answers with their benefits in our OQS algorithms is an area for future exploration. Further, we focus on situations where the system lacks the information to answer a question, rather than failures in understanding the question’s intent, which has been covered by existing research.
Notes
Our code and data available at: https://github.com/jannatmeem95/Out-of-schema-experiments.git.
References
Abro WA, Qi G, Aamir M, Ali Z (2022) Joint intent detection and slot filling using weighted finite state transducer and bert. Appl Intell 52(15):17356–17370
Bang Y, Cahyawijaya S, Lee N, Dai W, Su D, Wilie B, Lovenia H, Ji Z, Yu T, Chung W, et al (2023) A multitask, multilingual, multimodal evaluation of ChatGPT on reasoning, hallucination, and interactivity
Bert-large-uncased-wwm-finetuned-boolq. https://huggingface.co/lewtun/bert-large-uncaseda-wwm-finetuned-boolq
Brin S, Page L (1998) The anatomy of a large-scale hypertextual web search engine. Comput Netw ISDN Syst 30(1–7):107–117
Brown T, Mann B, Ryder N, Subbiah M, Kaplan JD, Dhariwal P, Neelakantan A, Shyam P, Sastry G, Askell A (2020) Language models are few-shot learners. Adv Neural Inf Process Syst 33:1877–1901
Budzianowski P, Wen T-H, Tseng B-H, Casanueva I, Ultes S, Ramadan O, Gašić M (2018) Multiwoz–a large-scale multi-domain wizard-of-oz dataset for task-oriented dialogue modelling. arXiv preprint arXiv:1810.00278
Chen L, Lv B, Wang C, Zhu S, Tan B, Yu K (2020) Schema-guided multi-domain dialogue state tracking with graph attention neural networks. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, pp. 7521–7528
Chung HW, Hou L, Longpre S, Zoph B, Tay Y, Fedus W, Li Y, Wang X, Dehghani M, Brahma S, et al (2022) Scaling instruction-finetuned language models. arXiv preprint arXiv:2210.11416
Clark C, Lee K, Chang M-W, Kwiatkowski T, Collins M, Toutanova K (2019) Boolq: Exploring the surprising difficulty of natural yes/no questions. arXiv preprint arXiv:1905.10044
Coucke A, Saade A, Ball A, Bluche T, Caulier A, Leroy D, Doumouro C, Gisselbrecht T, Caltagirone F, Lavril T, et al (2018) Snips voice platform: an embedded spoken language understanding system for private-by-design voice interfaces. arXiv preprint arXiv:1805.10190
Deng Y, Zhang W, Lam W, Cheng H, Meng H (2022) User satisfaction estimation with sequential dialogue act modeling in goal-oriented conversational systems. In: Proceedings of the ACM web conference 2022, pp. 2998–3008
Devlin J, Chang M-W, Lee K, Toutanova K (2018) Bert: pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805
Fernando AG, Aw EC-X (2023) What do consumers want? a methodological framework to identify determinant product attributes from consumers’ online questions. J Retail Consum Serv 73:103335
Hackl V, Müller AE, Granitzer M, Sailer M (2023) Is gpt-4 a reliable rater? evaluating consistency in gpt-4 text ratings. arXiv preprint arXiv:2308.02575
Hu Y, Lee C-H, Xie T, Yu T, Smith NA, Ostendorf M (2022) In-context learning for few-shot dialogue state tracking. arXiv preprint arXiv:2203.08568
Jansen BJ, Booth DL, Spink A (2009) Patterns of query reformulation during web searching. J Am Soc Inform Sci Technol 60(7):1358–1371
Jurafsky D, Martin JH (2009) Speech and language processing: an introduction to natural language processing, computational linguistics, and speech recognition
Kim S, Eric M, Gopalakrishnan K, Hedayatnia B, Liu Y, Hakkani-Tur D (2020) Beyond domain apis: task-oriented conversational modeling with unstructured knowledge access. arXiv preprint arXiv:2006.03533
Kim Y, Hassan A, White RW, Zitouni I (2014) Modeling dwell time to predict click-level satisfaction. In: Proceedings of the 7th ACM International conference on web search and data mining, pp. 193–202
Kojima T, Gu SS, Reid M, Matsuo Y, Iwasawa Y (2022) Large language models are zero-shot reasoners. Adv Neural Inf Process Syst 35:22199–22213
Larson S, Leach K (2022) A survey of intent classification and slot-filling datasets for task-oriented dialog. arXiv preprint arXiv:2207.13211
Li C-H, Yeh S-F, Chang T-J, Tsai M-H, Chen K, Chang Y-J (2020) A conversation analysis of non-progress and coping strategies with a banking task-oriented chatbot. In: Proceedings of the 2020 CHI conference on human factors in computing systems, pp. 1–12
Liu X, Eshghi A, Swietojanski P, Rieser V (2019) Benchmarking natural language understanding services for building conversational agents. arXiv preprint arXiv:1903.05566
Maqbool MH, Xu L, Siddique A, Montazeri N, Hristidis V, Foroosh H (2022) Zero-label anaphora resolution for off-script user queries in goal-oriented dialog systems. In: 2022 IEEE 16th international conference on semantic computing (ICSC). IEEE, pp. 217–224
OpenAI, R (2023) Gpt-4 technical report. arXiv:2303.08774
Pan Y, Ma M, Pflugfelder B, Groh G (2022) User satisfaction modeling with domain adaptation in task-oriented dialogue systems. In: Proceedings of the 23rd Annual meeting of the special interest group on discourse and dialogue, pp. 630–636
Ponnusamy P, Ghias AR, Guo C, Sarikaya R (2020) Feedback-based self-learning in large-scale conversational ai agents. In: Proceedings of the AAAI conference on artificial intelligence, vol. 34, pp. 13180–13187
Rastogi A, Zang X, Sunkara S, Gupta R, Khaitan P (2020) Towards scalable multi-domain conversational agents: The schema-guided dialogue dataset. In: Proceedings of the AAAI conference on artificial intelligence, vol. 34, pp. 8689–8696
Roberta-base-boolq. https://huggingface.co/shahrukhx01/roberta-base-boolq
Siro C, Aliannejadi M, Rijke M (2022) Understanding user satisfaction with task-oriented dialogue systems. In: Proceedings of the 45th International ACM SIGIR conference on research and development in information retrieval, pp. 2018–2023
t5-base-finetuned-boolq. https://huggingface.co/mrm8488/t5-base-finetuned-boolq
Touvron H, Martin L, Stone K, Albert P, Almahairi A, Babaei Y, Bashlykov N, Batra S, Bhargava P, Bhosale S, et al (2023) Llama 2: open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288
Wang J, Huang JZ, Wu D et al (2015) Recommending high utility queries via query-reformulation graph. Math Probl Eng. https://doi.org/10.1055/2015956468
Wang J, Li J, Zhao H (2023) Self-prompted chain-of-thought on large language models for open-domain multi-hop reasoning. arXiv preprint arXiv:2310.13552
Wei J, Wang X, Schuurmans D, Bosma M, Xia F, Chi E, Le QV, Zhou D (2022) Chain-of-thought prompting elicits reasoning in large language models. Adv Neural Inf Process Syst 35:24824–24837
Zhao R, Li X, Joty S, Qin C, Bing L (2023) Verify-and-edit: a knowledge-enhanced chain-of-thought framework. arXiv preprint arXiv:2305.03268
Zhu X, Guo J, Cheng X, Lan Y (2012) More than relevance: high utility query recommendation by mining users’ search behaviors. In: Proceedings of the 21st ACM international conference on information and knowledge management, pp. 1814–1818
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Human and animal rights
This project does not involve any live subjects (human or animal), and no personal or restricted data were collected from any source or subject. Although the LLMs may sometimes generate fake information i.e. hallucinate, our experiments do not involve LLMs in creating any harmful content and, thus raise no ethical concern. As per our knowledge, there are no ethical implications for this project.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix A: Prompt for out-of-schema question detection stage
Figures 9 and 10 shows the full version of Prompt1 for few-shot settings for the D-MultiWoz dataset. Here we are including 5 examples. Notice that the test instance is preceded by “### Start of example” but the answers need to be completed by the LLM. The LLM output is at the end.

Full Prompt1 (part 1) for Out-of-schema Question detection stage

Full Prompt1 (part 2) for Out-of-schema Question detection stage
Appendix B: Evaluation
1.1 Robustness of the in-context Learning approach
We have run additional experiments with different contexts/prompts with different parameter settings using GPT\(-\)3.5 and GPT 4. We experimented with Prompt1 instructions but with a varying number of examples provided in the prompt and varying the temperature and \(top\_p\) parameters of the OpenAI Chat Completion API. We chose these two parameters as these two are primarily responsible for variations in LLM responses. Owing to the substantial costs associated with the OpenAI API, our performance comparison of the new experiments is limited to a random sample of 50 test cases from the sets correctly identified by GPT\(-\)3.5 and GPT-4 respectively under the original 5-shot Prompt1 setting. These experimental results are demonstrated in Tables8 and 9. The results demonstrate the robustness of GPT-4’s superiority irrespective of the parameter values and the amount of information fed as the context. Moreover, the effect of introducing diversity (high temperature and \(top\_p\) values) to the LLM responses, is almost insignificant. We believe this is due to our task formulation as a yes/no QA, which does not have much scope for the LLMs to generate creative and verbose answers.
1.2 Evaluation for Paraphrasing-extension
We also extend our OQS algorithms for different questions having the same meaning i.e. paraphrased questions. We cluster the paraphrased questions using K-means clustering and then pick the Top k clusters with the highest benefit. The benefit of a cluster C is defined as:
The quantitative evaluation results for OQS-Cluster on D-MultiWoz and D-SGD is shown in Fig. 13. We observe that Markov-based Top k cluster selection brings a significantly higher number of conversations closer to the success state, by reducing the number of hops from the current state to the success state for both D-SGD and D-MultiWoz dataset and for four different values of \(Pr^{wd}\).
1.3 GPT-4 evaluation of OQS algorithms
Prompt for Evaluation Figures 11 and 12 show the full version of the prompt for the evaluation of the out-of-schema questions in the D-MultiWoz dataset. We only include two examples. The task is to score each conversation as unlikely, somewhat likely, likely, or very likely based on the information collected so far. Notice that the test instance is provided at the end of the prompt but the answers need to be completed by the LLM. The LLM output is at the end.
The GPT scores are mapped to numbers for quantitative evaluation as follows: unlikely: 0.25, somewhat likely: 0.5, likely: 0.75, and very likely: 1.

Full prompt (part 1) for GPT-4 evaluation of Out-of-schema Questions Selection
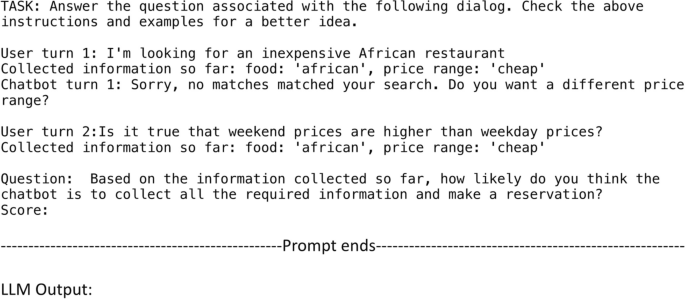
Full prompt (part 2) for GPT-4 evaluation of Out-of-schema Questions Selection

a number of conversations where the questions in the top ranked clusters appear up to 1, 2 and 3 hops away from SUCCESS for D-SGD (top) and D-MultiWoz (bottom), \(Pr^{qr} = 0.2\); b same for D-MultiWoz only, \(Pr^{qr} = 0.5\)
1.4 Evaluation of supervised QA models
For the experiments with the boolean QA fine-tuned supervised models for the Out-of-schema Question Detection stage, we construct the question and context following Fig. 14. \(DIALOG\_HISTORY\) represents the test case for which the model is supposed to answer. The ‘yes’ and ‘no’ responses of the model corresponds to a in-schema and a out-of-schema question respectively.

Context provided to the supervised boolQ models
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Meem, J.A., Rashid, M.S. & Hristidis, V. Modeling the impact of out-of-schema questions in task-oriented dialog systems. Data Min Knowl Disc 38, 2466–2494 (2024). https://doi.org/10.1007/s10618-024-01039-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10618-024-01039-6