
Abstract
User and entity behavior analytics (UEBA) is an anomaly detection technique that identifies potential threat events in the enterprise's internal threat analysis and external intrusion detection. One limitation of existing methods in UEBA is that many algorithms use deterministic algorithms only for one category labeling and only compare with other samples within this category. In order to improve the efficiency of potential threat identification, we propose a model to detect multi-homed abnormal behavior based on fuzzy particle swarm clustering. Using the behavior frequency-inverse entities frequency (BF-IEF) technology, the method of measuring the similarity of entity and user behavior is optimized. To improve the iterative speed of the fuzzy clustering algorithm, the particle swarm is introduced into the search process of the category centroid. The entity's nearest neighbor relative anomaly factor (NNRAF) in multiple fuzzy categories is calculated according to the category membership matrix, and it is combined with boxplot to detect outliers. Our model solves the problem that the sample in UEBA is evaluated only in one certain class, and the characteristics of the particle swarm optimization algorithm can avoid clustering results falling into local optimal. The results show that compared with the traditional UEBA approach, the abnormal behavior detection ability of the new method is significantly improved, which can improve the ability of information systems to resist unknown threats in practical applications. In the experiment, the accuracy rate, accuracy rate, recall rate, and F1 score of the new method reach 0.92, 0.96, 0.90, and 0.93 respectively, which is significantly better than the traditional abnormal detections.
Similar content being viewed by others



Introduction
In the context of globalization, the network security situation of enterprises is complex and changeable, and the rapid development of the Internet faces more network security problems. Cyber security incidents that utilize business design or code flaws to achieve network intrusion and steal data frequently occur, resulting in bad social impacts1. While intrusion detection products based on machine learning are widely used, the complexity of business process design and implementation makes it difficult for conventional security products and technical ways to solve problems of the present. Security products such as intrusion prevention systems and intrusion detection systems2,3 generate a large number of logs and alarm information every day, and it is difficult to analyze all alarm information one by one. However, actual threatening behaviors such as external attacks and sensitive data leakage are often hidden behind many alarms, which are prone to false negatives and positives, affecting the judgment of analysts4.
In order to better detect potential threats and find security problems more accurately, User and Entity Behavior Analytics (UEBA) is proposed5. UEBA is developed on the basis of User and Behavior Analytics (UBA) and Security Information and Event Management (SIEM)6, and itâs a threat detection method that comprehensively evaluates the risks faced by the system through multi-dimensional7. The new Entity object (in UEBA) emphasizes the importance of device behavior in network attack and threat detection. Compared with traditional detection methods, UEBA further improves the accuracy and efficiency of threat detection and increases the expression function of risk judgment, which is beneficial to the system to discover unknown risks and enhance system security8.
With the increasing amount of data, the work of labeling samples has become more and more difficult. Currently, some scholars use unsupervised methods for UEBA research by clustering samples together and identifying outliers, such as K-Means9 and DBSCAN10,11. Gu et al.12 proposed a semi-supervised clustering algorithm for optimizing the result of DDoS detection, which can solve the problem of the result easily falling into local optimum by improving the selection of the initial center of the cluster. The model uses the K-Means algorithm to perform cluster analysis on the data, and then the clusters with a small number of elements are regarded as outliers, just like other anomaly detection models based on unsupervised clustering algorithms. In fact, it is not enough to use the clustering algorithm to identify abnormal samples. The clustering results should be combined with other detection methods to improve the detection accuracy. Waqas et al.13 proposed a graph clustering algorithm to solve the fraud detection problem in the email sending process. First, the email sending behavior of entities in the dataset was processed through graph clustering to obtain multi-user personalized communities. The dynamic changes in community network structure are one of the important indicators for detecting fraudulent accounts in email systems. However, considering the problem in Fig. 1, the top section does not detect the threat, while the bottom section does. May the samples need to be compared and analyzed in multiple dimensions, because many complex entity behaviors are hidden in normal samples. How to perform the multi-angle comparison of samples and detect threat behaviors hidden in a large number of samples is a significant but less researched issue.

An illustration of our motivation. Compared with the traditional deterministic clustering method, fuzzy clustering for the user and entity behavior is more indispensable in potential abnormal behavior detection.
The limitations of the current UEBA method motivated us to conduct this study. This paper proposes a novel Multi-homed Abnormal Behavior Detection Algorithm based on Fuzzy Particle Swarm Cluster (MAD-FPC) for User and Entity Behavior Analytics problems. The core mechanism behind MAD-FPC is to use fuzzy clustering algorithms to solve the problem of the lack of sample analytical perspectives in the process of abnormal user and entity behavior detection.
Compared with other UEBA algorithms, the main goal of our proposed MAD-FPC algorithm is to improve the detection effect of abnormal traffic data, and analyze traffic samples from multiple angles, so as to achieve a more accurate identification effect. The experimental results on the NSL-KDD dataset show that the FPC algorithm has fewer iterations compared with the FCM algorithm, and the MAD-FPC algorithm has better anomaly detection metrics compared with other algorithms (LOF, K-Means, Random Forest, One-Class SVM, and kNN). The FPC algorithm goes through two steps: the solution process of the particle swarm, and the calculation process of the membership degree. The time complexity of the particle swarm solution process is related to the number of particles p, the number of iterations q, and the calculation time t of each particle position, so the time complexity of the particle swarm solution process is O(pâÃâtâÃâq). The particle position needs to be calculated in combination with the fitness function, and the direct cosine similarity between each sample n and each class centroid m needs to be calculated, so time complexity of algorithm O(t)â=âO(nâÃâm). In the process of calculating the membership degree of fuzzy categories, it is related to the number of samples n and the number of categories m, and each sample needs to calculate the membership degree of each category, so the time complexity of the fuzzy process of clustering results is O(nâÃâm). So the time complexity of the FPC algorithm is O(pâÃânâÃâmâÃâq)â+âO(nâÃâm). Therefore, in the case of large sample size, the time complexity of the FPC algorithm is O(nâÃâm). In the MAD algorithm, the degree of anomaly of a sample is related to its k nearest neighbors in m fuzzy classes. If there are a total of n samples, the time complexity of the anomaly detection process is O(nâÃâmâÃâk). Since MAD-FPC has two processes of clustering and anomaly detection, the time complexity of the MAD-FPC algorithm is O(nâÃâm)â+âO(nâÃâmâÃâk). Since m and k are constants, in the case of a high number of samples, the time complexity of MAD-FPC is O(n). When dealing with massive traffic data, it is still necessary to deploy an online detection model in a way of modeling first and then detecting, which is also a common practice of existing network security equipment. First, find the category centroid through historical data, then process the real-time data stream, calculate the membership degree of traffic samples to each category, and then apply the multi-attribution anomaly detection algorithm to calculate the anomaly factor of the sample. When the traffic volume is low, the data clustering centroids can be retrained without affecting the actual business operation. This method of first modeling and then detecting can realize real-time detection of abnormal traffic data.
The main contributions of our work are as follows:
-
1.
We propose a fuzzy particle swarm clustering algorithm, which uses the fuzzy membership matrix to express the possibility of belonging to the class and solves the problem that the fuzzy clustering results easily converge to the local optimum using Swarm Intelligence.
-
2.
The fuzzy clustering results are analyzed using the relative structural relationship among the categories, and a structural anomaly evaluation index NNRAF is proposed to measure the abnormality of samples. This method can refine the measure of the degree of difference among samples and improve the ability to express abnormal situations.
-
3.
A multi-homed abnormal behavior detection model based on fuzzy particle swarm clustering (MAD-FPC) is constructed in detail and complete, which can better solve the problem of abnormal data identification in UEBA.
The rest of this paper is organized as follows. In the âRelated worksâ section, some related works are introduced. And âMethodologyâ section describes the feature engineering approach to the data, as well as the newly proposed fuzzy clustering and anomaly detection procedures. âResults and discussionâ section includes experimental parameter settings, analysis and discussion of experimental results, and comparisons of evaluating performance with other algorithms. The âConclusionâ section briefly summarizes the full text and makes further prospects for future work.
Related works
User and entity behavior analytics
UEBA is used to track and monitor some entities' abnormal behaviors, including users, IP addresses, hosts, etc., and can analyze potential malicious activities through contextual correlation of behaviors. Due to the lack of attack methods and the limit of detection capabilities, the target of threat detection was mostly abnormal rule matching14,15. The identification logic converted by expert experience is the primary method to detect abnormal behavior16, and the results were mostly in two states of "normal" and "abnormal". Later, new attack methods continued to increase, and new threat types continued to emerge, so researchers began to use other methods to identify unknown threats, such as evolutionary algorithms17, support vector machine18, knowledge graph19, etc.
Fuzzy C-means
FCM20 is a commonly used fuzzy clustering method that calculates the membership degree and the centroid of the category through multiple iterations to achieve the maximum intra-class similarity and the minimum inter-class similarity. In the UEBA problem, fuzzy clustering can assign the behavior of an entity to different categories, and a membership matrix expresses the relationship between samples and categories. Although the entity behavior analytics methods based on FCM optimize the results of entity behavior clustering, there are still problems in the process of using the FCM algorithm in UEBA, for example, the initialization parameters are difficult to select, and the results of clustering are easy to fall into the local optimum21. In order to better improve the clustering effect of the FCM algorithm, Wang et al.22 proposed a validity function to evaluate the clustering results according to the relative structure information of the data, and this method can accurately obtain the optimal number of clusters. Wu et al.23 added a sample feature called local data density to optimize the FCM algorithm, and one-dimensional data was extracted by distribution density characteristics of the eigenvalues. Wang22 and Wu23 gave us much inspiration for dealing with the relative positional relationship of data, and the shortcomings of FCM in finding the optimal solution cannot also be ignored. Therefore, we added a population-based stochastic optimization technique to the process of finding the centroid and a relative structure measurement method to the anomaly detection process.
Particle swarm optimization
PSO24 is an evolutionary search technology that finds the global optimal solution through repeated particles jumping. During the execution of PSO, all particles are assigned initial random positions and initial random velocities. Then the speed and direction of each particle are calculated by parameters initialized earlier, including the global optimal position and the optimal individual position. With continuous iterations, particles gather around one or more optimal points by exploring and exploiting existing vantage points in the search space. By considering the global optimal position and its own optimal position in the moving direction, PSO can avoid prematurely falling into the local optimal solution25. The genetic algorithm can be used as the focus of finding cluster centers, and Chicco et al.26 proposed an ant colony clustering to evolve the centroids of sets in the iterative process. We refer to this idea to optimize the process of finding fuzzy cluster centers.
Anomaly behavior detection
The abnormal behavior detection in the UEBA field mainly consists of external intrusion and internal threat detection. In terms of external intrusion identification, Pan et al.27 designed a dynamic residual generator to detect a variety of attack methods through an entity behavioral analysis filtering device, which solved the problem of a few types of abnormal detection in static detection models. Some scholars have also established an anomaly detection model to detect Cyber attacks based on CNN28,29, RNN30, long short-term memory (LSTM)31,32,33, GAN34,35, and deep autoencoder (DAE)36,37. In terms of insider threat identification, the research focuses on the analysis of enterprise employee behavior38, user portrait39,40, complex behavior modeling41, and so on. Intranet users often have very high system permissions, so their operations often have a more significant impact. Once an abnormal situation occurs, it may cause extremely serious losses. Therefore, the next stage of UEBA's research may focus on the analytics of enterprise employee behavior, which we considered as well.
However, most anomaly detection methods use a "hard division" strategy when clustering samples42. Each sample belongs to only one category, so one sample can only be compared with other samples within this category when performing anomaly calculations. The behavior of users and entities is not only complex but also camouflaged and should be analyzed in comparative experiments as much as possible. The correlation information between samples and various clusters can be well preserved if we use the fuzzy clustering algorithm to analyze user and entity behavior data. The threat degree of users and entities can be judged through multi-angle evaluation, so as to obtain more accurate abnormal detection results43.
Methodology
The overall processing flow of the user and entity behavior anomaly detection algorithm proposed in this paper is shown in Fig. 2, it includes three main parts:
-
1.
Feature engineering.
-
2.
Fuzzy particle swarm clustering (FPC).
-
3.
Multi-homed anomaly behavior detection (MAD).

An overview of our model. The overall processing process is divided into three parts, in the feature engineering phase, BF-IEF is mainly used to convert traffic data into entity behaviors. In the FPC stage, particle swarms are used to search for the clustering results, and the membership matrix is obtained. In the MAD process, we extracted the 2-nearest neighbors of point O in three classes, denoted by \({N}_{2}^{(m)}(O)\). After that, the NND of point O in each class is calculated and combined together to get NNRAF. Finally, anomaly detection is performed based on the boxplot.
First, we collect data in the network environment and perform vectorization and standardization operations. Moreover, a feature engineering called BF-IEF is used to derive the appropriateness of the behavior vector. Next, the fuzzy clustering results are obtained through the fuzzy particle swarm fuzzy clustering process, and then the fuzzy clustering results are subjected to multi-homed anomaly behavior detection.
BF-IEF feature engineering
In the traditional FCM algorithm, the Euclidean distance is mainly used to measure the similarity of vectors between the sample and the class center. But Euclidean distance measures the straight-line distance of each point in space, which is directly related to the position coordinates of each point, while cosine distance measures the angular relationship of vectors in space, which is more reflected in the difference in direction44. In the process of fuzzy clustering analytics of user and entity behaviors, we found it is better to use cosine similarity between vectors to distinguish behavior differences, so based on the TF-IDF (Term Frequency-Inverse Document Frequency) idea, we optimized the representation method of entity behavior vectors and used cosine similarity to analyze samples.
TF-IDF is a weighting technique often used in text mining to assess the importance of a word to one of the documents in a document set or corpus. The importance of a word increases proportionally to the number of times it appears in the document and decreases inversely proportional to its frequency in the corpus. The core idea is that if a word appears in an article with a high frequency and rarely appears in other articles, it is considered that the word or phrase has an excellent ability to distinguish the document to which it belongs from other documents.
Based on the idea of TF-IDF, we propose a feature engineering method for user and entity behavior. The method of calculating Behavior Frequency-Inverse Entities Frequency (BF-IEF) is as follows. Given an entity behavior B, the calculation method of entity behavior frequency (BF) of B is:
The meaning of formula (1) is that if B appears more times in the entity behavior set, it proves that B is the habit of the entity, so that B can distinguish the difference between this entity and other entities very well.
The reverse entity frequency IEF calculation method for behavior B is:
Adding one to the denominator in the formula is to prevent the denominator from being 0. The meaning of formula (2) is that if a behavior appears many times in many entity behavior sets, it proves that many entities are accustomed to doing this behavior, and the dissimilarity between entities cannot be well distinguished by this behavior.
The product of the frequency of the entity behavior and the frequency of the reverse entity is:
The meaning of formula (3) is that the more times a behavior appears in an entity's behavior set, and the fewer times it appears in other entities' set, the better it can represent this entity. Using the BF-IEF to process the data, the entity behavior vector can be expressed more accurately, and the clustering algorithm's accuracy can be enhanced simultaneously.
Based on the representation method of entity behavior vector and given the data sample x and the cluster category center v, the distance between the data sample and the cluster category center can be calculated. The vector similarity of Behavioral Measure (BM) can be calculated by the cosine similarity, and the calculation method is shown in formula (4):
Fuzzy particle swarm clustering (FPC)
The fuzzy set was proposed by Prof. A. Zadeh45 in 1965 based on fuzzy mathematics, which broke through the method of using inclusion and non-inclusion in classical sets to describe the relationship between elements and sets. Fuzzy sets perform soft division on sets and elements and use appropriate membership functions to describe the relationship between groups and pieces.
In fuzzy clustering, we use the degree of membership to represent the possibility of a sample x being included in class c, generally denoted as uij. The uij represents the membership degree of the ith sample to the jth category, whose value range is [0,1]. When uijâ=â0, it means that the ith sample must not belong to the jth category; when uijâ=â1, it means that the ith sample must belong to the jth category.
Assuming that the data set \(X=\{{x}_{1},{x}_{2},\dots ,{x}_{N}\}\), the clustering category \(C=\{{C}_{1},{C}_{2},\dots ,{C}_{C}\}\), the jth clustering category center \({v}_{j}\). The objective function of entity behavior Fuzzy Particle Swarm Clustering (FPC) algorithm is shown in formula (5):
Subject to:
In formula (5), m is a fuzzy coefficient and the value range of m is [1,â+ââ). The m is a parameter used to adjust the degree of clustering fuzziness. The larger the value of m, the more ambiguous the clustering result will be. Generally, most experiments take mâ=â2. It is worth noting that the sum of all membership degrees should be equal to 1, as in formula (6).
Using the Lagrangian multiplier method46, the Lagrangian Multiplier is introduced to transform Eqs. (5) and (6) into unconditional extreme value problems:
By derivation of the variables in formula (7), the extreme points of each variable can be obtained.
Taking the partial derivative for uij is equivalent to taking the partial derivative for the first half and the second half of the Langrangian function:
Calculate the two parts separately.
According to formula (9) and formula (10), there are:
Let formula (11) equal zero, then:
And because the degree of membership \({u}_{ij}\) is a non-negative value, then \({{m u}_{ij}}^{m-1}{BM\left({x}_{i},{v}_{j}\right)}^{2}\) is also a non-negative value. At the same time, the Lagrange multiplier \({\lambda }_{j}\) is non-negative, then:
Simultaneous formula (12) and formula (13), we can get:
By analyzing formula (14), we can get:
And we define
And based on above, we can derive that:
Substitute Eq. (17) into Eq. (15) to obtain the calculation formula of the final \({u}_{ij}\):
In order to get better clustering results, we use particle swarm optimization algorithm to optimize the process of finding cluster centers. In the PSO algorithm, the speed and direction of the particles are iterated by their own optimal solution and the global optimal solution, and the determination of the optimal solution is very related to the objective function. In the FPC algorithm, we redesigned the particle structure and objective function, and the particle will have a matrix structure during initialization to store the samples' relative position relationship with the center of each category.
It may be assumed that there are N particles in the D-dimensional space, and each particle has two characteristics: position characteristics, and velocity characteristics.
Given particles position features:
And particles velocity features:
We can get the position and velocity parameters of new particles in the process of population evolution. The calculation formula is:
Subject to:
In formula (19), i represents the result of the ith iteration, \({v}_{i}\) represents the speed of the particle at the ith iteration; rand() is a random function, and the random value is between (0, 1); \({pbest}_{i}\) represents the optimal position of the particle itself in the ith iteration; \({gbest}_{i}\) is the global optimal position in the ith iteration; and \({x}_{i}\) is the current position of the particle; \({c}_{1}\) and \({c}_{2}\) are learning factors, by taking \({c}_{1}={c}_{2}=2\). It is worth noting that in the particle swarm algorithm, it is also necessary to set a maximum value of particle velocity to ensure that the search process for the optimal value will not cause the situation that the step size is too large to cause the failure to converge. \({V}_{max}\) is the maximum speed, if \({v}_{i}>{V}_{max}\), then let \({v}_{i}={V}_{max}\).
We take the objective function of fuzzy clustering formula (5) as the fitness function of particle swarm, so as to ensure the judgment of individual optimal and local optimal. After each particle position iteration is completed, the current fitness value is compared with the previous fitness value, and it is determined whether the particle position needs to be updated. The detailed steps of the Fuzzy Particle Swarm Clustering Algorithm are as follows:

Algorithm 1 mainly performs the fuzzy clustering process. The optimal clustering point is obtained by repeated jumping of the particle swarm, and the membership relationship between the sample and the category is calculated according to the membership degree formula, and finally the membership degree cluster U is obtained. The next step is multi-homed anomaly detection.
Multi-homed abnormal behavior detection (MAD)
With the continuous development of network technology, abnormal situations used in entity behaviors show obvious complex and hidden characteristics47. Most of the existing anomaly detection algorithms analyze the behavior content based on a single dimension. Using traditional abnormal detection methods to analyze anomalies in the fuzzy clustering results will lose the "fuzzy" characteristics of the fuzzy clustering results. The local outlier factor (LOF) algorithm48 is a common density-based single-dimensional anomaly detection algorithm. It compares the local outlier factor between the node and the neighboring node to determine whether the node is abnormal. Based on the LOF algorithm, this paper designs a Multi-homed Abnormal Behavior Detection(MAD) algorithm to solve the anomaly detection problem of fuzzy clustering results.
Among all the data points in the same cluster, finding the kth point closest to point O, the distance between this point and point O is called the K-nearest neighbor distance, represented by KNND(O). The larger the KNND(O), the sparser the points around O, and the further away O is from the place where the amount of data is distributed.
It is worth noting that if point O belongs to M clusters as the result of fuzzy clustering, the number of KNND(O) will be M. This means that point O will have M KNND(O)s. All points from the kth point to point O are included in the k-nearest neighbors of point O, which can be represented by \({N}_{K}^{(m)}(O)\). The subscript K represents the number of neighbors, which is input by the user; the superscript m represents the neighbors of O in the mth category, and the value range of m is [1, M]. The reachable distance between point p and point O is defined as the maximum value of "k-nearest neighbor distance of point O" and "direct distance between point p and point O". The calculation method is as follows:
Another thing worth noting is that the reachable distance is directional, and the reachable distance from point p to point O may not be equal to the reachable distance from point O to point p. The nearest neighbor density(NND) of point O is used to measure the relative density of point O and other surrounding points in the same cluster. It is defined as the reciprocal of the average reachable distance between other points in the K neighborhood of each cluster and point O, and the calculation method is:
The superscript m represents the mth category, and by calculating the NND of samples that belong to the cluster of each point O, the neighbor density of O can be obtained. The lower the average distance, the higher the neighbor density. A high density of neighbors means that the data around the point is denser. In addition, there may be more than k points in the neighborhood of point O, so the sum of reachable distances should be normalized according to the actual situation.
In the MAD algorithm, we use the point O's Nearest Neighbor Relative Anomaly Factor (NNRAF) to measure the degree of abnormal of point O, and its anomaly factor score is the ratio of the average of samplesâ NND that are located around O in M categories to Oâs NND. The formula for calculating NNRAF is
Among them, m represents the mth cluster; \({N}_{k}^{(m)}\left(O\right)\) is the point where is within the k nearest neighbors of point O in the mth cluster; \({NND}^{\left(m\right)}(O)\) is Oâs NND in mth category; \({u}_{m}\) is the degree of membership of O to mth cluster.
Under normal circumstances, when using LOF for abnormal sample detection, 1 is used as a threshold for comparison. If the LOF of a point is less than 1, it proves that the point is surrounded by dense samples, and this point belongs to the normal category. The opposite is the case for greater than 1. In some datasets with a flat distribution, an NNRAF value greater than 0.8 may be an abnormal sample; while in some datasets with large distribution fluctuations, an NNRAF value greater than 2 may be a normal sample. Obviously, using a fixed threshold to detect NNRAF cannot flexibly handle the actual situation, and since the membership information of multiple clusters is added to the calculation process of the abnormal factor, the value of NNRAF changes greatly, so we decided to optimize the detection threshold of the algorithm by the boxplot.
The boxplot was proposed by American statistician John W. Tukey in 197749. It consists of five numerical points: Minimum (Q0 or 0th percentile), Maximum (Q4 or 100th percentile), Median (Q2 or 50th percentile), First quartile (Q1 or 25th percentile), and Third quartile (Q3 or 75th percentile). IQR means Interquartile Range, calculated by subtracting Q1 from Q3. Compared with the 3Ï Rule50, using the boxplot to detect outliers does not require the data to be normally distributed, which greatly increases the scope of the algorithm. When the boxplot is used for outlier detection, it mainly uses the five statistics in the data mentioned above. The calculation formula of the threshold (Th) is:
In general, values greater than Th should be flagged as abnormal. Using formula (24) can judge the non-normally distributed data, thereby improving the applicable scope of NNRAF. The detailed steps of the Multi-homed Abnormal Behavior Detection Algorithm are as follows:
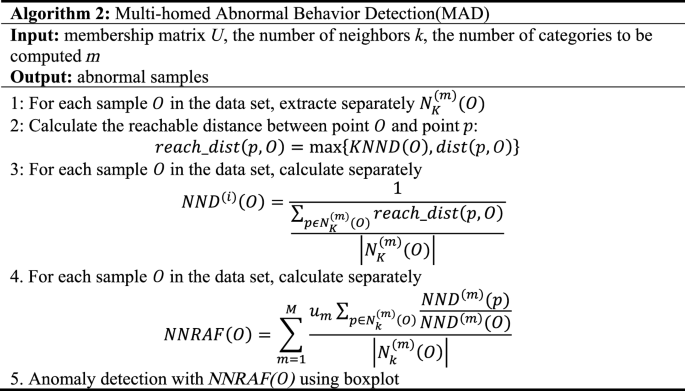
Algorithm 2 mainly performs the multi-homed anomaly detection process. Calculate its NND in each fuzzy class for each sample, and synthesize them together to get NNRAF, and finally use the boxplot for anomaly identification.
MAD-FPC flow chart
Based on fuzzy particle swarm clustering algorithm (FPC) and multi-homed abnormal behavior detection algorithm (MAD), a fuzzy-based multi-homed anomaly detection MAD-FPC algorithm is designed. First, the BF-IEF technology is used to normalize and initialize the entity behavior, and then the fuzzy clustering results of each entity behavior are obtained by multiple iterations, and next the relative anomalies of the samples are calculated according to the cluster membership matrix, and finally, the boxplot is used for detection. The algorithm flow is shown in Fig. 3.
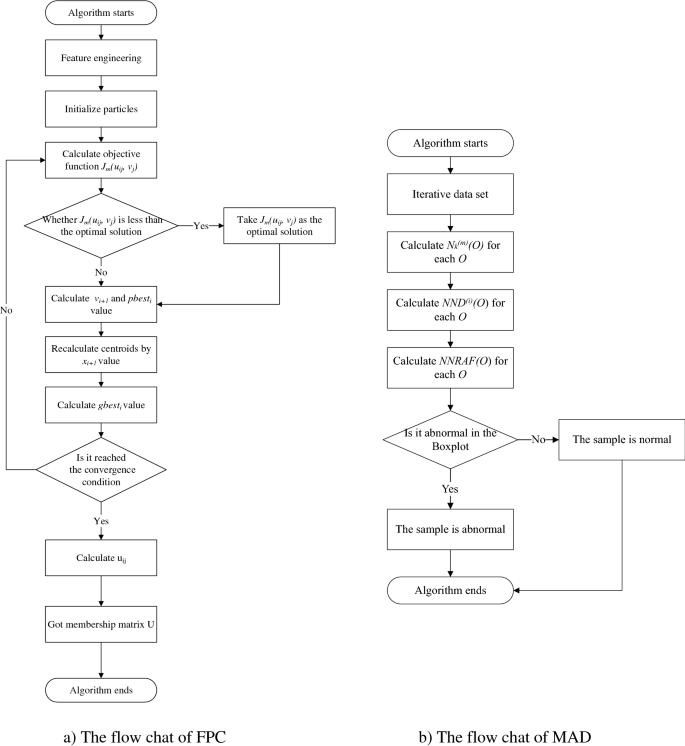
MAD-FPC flow chart.
Results and discussion
Data description and preliminary processing
In order to verify the effectiveness of the anomaly detection algorithm, this paper uses NSL-KDD51 data to simulate the connection behavior of entities and users in network communication. We preprocessed the data with feature engineering, and each connection after processing has a total of 43 features. In the process of feature engineering, the character-type discrete data is processed by using One-Hot encoding. In order to better distinguish each connection, we use the BF-IEF weighting technique described in âBF-IEF Feature Engineeringâ section to concatenate the three features of "Protocol Type", "Service" and "Flag" as user and entity behaviors. In addition, we also use the normalization method to scale other data numerically to compress them between 0 and 1. The normalization method is:
NSL-KDD is an improved version of the KDD CUP 99 dataset. It solves the problems of data redundancy and duplication of test and training data in KDD CUP 99 and optimizes the sample ratio to a certain extent. The data distribution of NSL-KDD is shown in Table 1:
We use the KDDTrain+ for training and the KDDTest+ for testing. This dataset includes 4 types of abnormal traffic, namely DOS, Probe, U2R, and R2L. DOS, which stands for Denial-of-Service, has occupied the largest proportion of abnormal samples. Probe (PROBING) stands for surveillance and probing. U2R (USER-TO-ROOT) is unauthorized access to superuser privileges by a local unprivileged user. R2L (REMOTE-TO-LOCAL) is unauthorized access from a remote host. These four types of anomalies include 38 attack subtypes, and the specific corresponding situations are shown in Table 2.
Evaluation indicators
In the process of evaluating the algorithm, we calculated various indicators based on the confusion matrix. The confusion matrix is shown in Table 3:
Among them, TP (true positive) represents that a positive sample is predicted to be a positive sample; FP (false positive) represents that a negative sample is predicted to be a positive sample; FN (false negative) represents that a positive sample is predicted to be a negative sample; TN (true negative) represents a negative sample is predicted to be a negative sample. Several evaluation indicators can be obtained based on the confusion matrix. The commonly used indicators are accuracy (Acc), precision (P), recall (R), and F1 value. The specific calculation method is as follows:
In addition, the receiver operating characteristic curve (ROC) and the area under the ROC curve (AUC) were used to evaluate the algorithm.
Analysis of MAD-FPC
This experiment was run on an Intel core i7-9750H@2.6Â GHz processor, 16G memory, and Python 3.7.2 environment. The recognition results of the multi-classification experiments are counted according to the attack categories, which are Normal, DOS, Probe, U2R, and R2L. In terms of parameter selection, the fuzzy clustering hyperparameter m is set to 2, and the C value is set to 5.
Analysis of fuzzy clustering results
The fuzziness of the FPC algorithm is reflected in the fact that a sample can belong to multiple categories at the same time, and the value of the membership degree determines the magnitude of the correlation. The fuzzy clustering results are shown in Fig. 4. We randomly select several samples to display the membership degree. If the value of the membership degree is larger, the sample is more likely to belong to this class. The values of the membership degrees of each class corresponding to each sample are summed up to 1.

Examples of FPC algorithm results.
Since we use the particle swarm process to optimize the original fuzzy clustering algorithm, we pay special attention to the relationship between the number of iterations and the fitness value in the experiment. Because we redesigned the FPC algorithm's fitness function (formula 5), it is different from the fitness function of the FCM algorithm, especially in terms of changes in the difference. The absolute value of "Fitness Value" of the FCM algorithm is relatively large, while the absolute value of the "FitnessValue" of the FPC algorithm is relatively small, so it is difficult to compare the differences when the two graphs are placed together. In order to compare the iterative convergence speed of these two algorithms, we designed the "Loss Index" to dynamically measure the range of fitness values. The Y-axis coordinate stands for the loss value, equal to the current adaptation value minus the minimum adaptation value (the minimum changes dynamically if the current value is less than the minimum), and the X-axis coordinate represents the number of iterations. We run FPC and FCM 10 times with each iteration times set to 100 to get the Loss Value. Figure 5 shows the changes in the loss index during the execution of the algorithms. It can be seen from the figures that with the continuous increase in the number of iterations, the fitness values of the two algorithms both decrease and finally converges to a smaller interval. Compared with FPC, the convergence speed of the FCM algorithm is slower, and the optimal clustering effect can only be achieved at the 60th iteration. The FPC algorithm uses the particle swarm to find the center of the fuzzy clustering, so the convergence speed is faster than that of the FCM algorithm, and the better clustering effect has been achieved in the 23rd iteration. Near the 40th iteration, the best result on the training set was reached (representing the Loss index equals 0). As the program continues to execute, the particle swarm shows a certain instability causing the fitness value to jump up and down violently. The reason for this is that the learning rate is a fixed value, although it can converge at a fast speed in the early stage, the particles may cross the optimal position in the later stage when moving. However, on the whole, the performance of the FPC algorithm is still better than the FCM algorithm.

The change of loss index of the FPC algorithm and the FCM algorithm.
Due to the characteristics of the loss value, when the current value is less than the known minimum value, the global minimum Loss Value will be exchanged, resulting in a point where Loss Valueâ=â0. Table 4 is the comparison of Loss Value in the iterative process.
It can be seen from Table 4 that the convergence speed of the FPC algorithm is significantly faster than that of the FCM algorithm, and after the number of iterations exceeds 60, the value of Loss Value is 0 for 11 times, which means that the optimal value of FPC Values are swapped 11 times. Meanwhile, FCM has only exchanged 7 times. Therefore, the particle swarm jumping behavior of FPC plays a very important role in the process of finding the optimal clustering result, which is also one of our innovations.
Analysis of anomaly detection results
We compute the NNRAF for each sample and detect outliers in it using boxplot. In Fig. 6, the outliers detected by the boxplot have been marked in red, and we can see that a large number of data NNRAF values are relatively low, mainly concentrated within 3. The NNRAF values of abnormal samples also show a certain density trend, most of which are between 30 and 3, and the highest NNRAF value obtained by calculation is 63.13200726.

Anomaly detection results of NNRAF by using boxplot.
We selected LOF, K-Means, Random Forest,One-Class SVM, kNN and the MAD-FPC algorithm we proposed to compare the anomaly detection effect. In terms of the number of abnormal behaviors detected, the number of abnormal behaviors detected by the algorithm proposed in this paper is roughly the same as that detected by the random forest algorithm. Among the 12,833 abnormal samples, a total of 10,851 non-Normal data were identified by MAD-FPC. The anomaly detection results in the binary classification of complete data are shown in Fig. 7.

Comparison of abnormal detections in LOF, K-Means, Random Forest, One-Class SVM, kNN and the MAD-FPC.
Comparisons of evaluating performance
The detection result of the Normal class is to analyze the data set as a whole, regard DOS, Probe, U2R, and R2L as anomalies, and then judge the anomaly detection ability of the MAD-FPC algorithm. The multi-homed detection experiment is to first split the data set according to the class and then mix it with the Normal class data to judge the anomaly detection performance from normal samples. Table 5 shows the evaluation indicators of the 6 algorithms on multi-category data. The overall performance of the MAD-FPC algorithm is the best, and the random forest is slightly weaker. At the same time, we also noticed that due to the small number of samples in the U2R and R2L categories, the model might learn little knowledge in modeling these two types of data. The detection effect of the MAD-FPC algorithm on these two categories is weaker than that of other categories. Therefore, the problem of the small amount of sample data in the U2R and R2L categories affects the average value of the final evaluation index to a certain extent.
Combined with Fig. 8, although the number of outliers detected by the MAD-FPC algorithm is not as high as that detected by the random forest algorithm, its overall evaluation index is better than the random forest algorithm, so the MAD-FPC algorithm is more suitable for detecting abnormal data.

Comparison of ROC curves of different algorithms.
From the ROC curve of each subgraph in Fig. 8, the MAD-FPC algorithm performs best in the anomaly detection experiment of the full dataset. The improved fuzzy clustering based on BF-IEF optimization technology can better distinguish the behavior of various entities, so as to obtain a better fuzzy clustering effect. Moreover, in the classification anomaly detection test, the diversity of entity categories is reduced, and the advantage of the MAD-FPC algorithm in the use of multi-homed attribution information is reduced, so the detection advantage presented is not as large as that in the full data set anomaly detection test. Compared with the traditional LOF algorithm, the MAD-FPC algorithm, which has been improved by the attribute of the multi-homed of the entity sample, calculates the abnormal factor of more dimensions and can detect more abnormal points.
In addition, we also tested the real-time recognition ability of the MAD-FPC algorithm using a simulated data set, and the specific results are shown in Table 6. The structure of the simulated data is made by imitating NSL-KDD data, and the simulated attack is carried out in the virtual environment of the network security laboratory. Set the centroid of the training data set to the fuzzy cluster centroid of the real-time recognition experiment to initialize the experimental parameters. When the data flow starts to attack, the degree of membership of the sample is directly calculated, then the NNRAF of the sample is calculated, and finally, the 3Ï Rule based on the boxplot is used for anomaly detection. Since the training results are used directly, the detection efficiency can reach real-time. The experiment shows that the MAD-FPC algorithm is also superior to other algorithms in small-batch online detection, and is suitable for all-weather deployment detection as an incremental detection model for entity behavior.
From the experimental results, the overall performance of the MAD-FPC algorithm for entity behavior anomaly detection is better than the LOF, K-Means, Random Forest, One-Class SVM, and kNN algorithms, especially in the abnormal detection of the Normal category. In practical applications, the main function of entity behavior analysis is to find abnormal samples in user and entity behavior data, so the MAD-FPC algorithm is more suitable for anomaly detection of current entity behavior than the other three algorithms.
Conclusion
With the continuous development of network technology and the continuous expansion of enterprise business scale, the network security threats that enterprises face have become increasingly complex and changeable. Therefore, studying entity behavior anomaly detection methods can further reduce the network security threats enterprises face. Inspired by the above discussion, in this work, we proposed an anomaly detection algorithm based on fuzzy clustering and multi-homed cluster attribution, which was mainly used in entity behavior analysis. Firstly, an entity behavior fuzzy clustering algorithm is designed based on the behavior measurement method using differences between entity behavior and other entity behavior. The membership matrix between the entity behavior and the category is obtained through particle swarm optimization and correlation calculation, which solves the problem of a single analysis angle of the deterministic clustering algorithm. Then, based on the membership degree matrix, a multi-homed attribution anomaly detection algorithm is designed to analyze the relative structure of the entity's behavior in each class and judge the anomaly of the point. The MAD-FPC algorithm solves the shortcomings of the traditional anomaly detection algorithm's "hard division" of entity behavior. It obtains more accurate detection results by calculating the degree of an anomaly in different classes.
In the future, we will continue UEBA research and establish a network security protection model to identify unknown abnormal traffic. Deploying this model in cybersecurity protective equipment increases the influence of our research findings not only in the industrial circles but also in the academic sector.
Data availability
NSL-KDD is a well-known public data set in the cyber security field. The data is openly available at https://www.unb.ca/cic/datasets/nsl.html. The more specific feature engineering approach that supports the findings of this study is available from the corresponding author upon reasonable request.
References
Vivek, S. & Conner, H. Urban road network vulnerability and resilience to large-scale attacks. Saf. Sci. 147, 105575 (2022).
Singh, A., Amutha, J., Nagar, J., Sharma, S. & Lee, C.-C. AutoML-ID: Automated machine learning model for intrusion detection using wireless sensor network. Sci. Rep. 12, 9074 (2022).
Gallenmuller, S., Naab, J., Adam, I. & Carle, G. 5G URLLC: A case study on low-latency intrusion prevention. IEEE Commun. Mag. 58, 35â41 (2020).
Gupta, R., Tanwar, S., Tyagi, S. & Kumar, N. Machine learning models for secure data analytics: A taxonomy and threat model. Comput. Commun. 153, 406â440 (2020).
Gartner. Market Guide for User and Entity Behavior Analytics. https://www.gartner.com/en/documents/3134524 (2015).
Singh, K., Singh, P. & Kumar, K. User behavior analytics-based classification of application layer HTTP-GET flood attacks. J. Netw. Comput. Appl. 112, 97â114 (2018).
Shashanka, M., Shen, M.-Y. & Wang, J. User and entity behavior analytics for enterprise security. In 2016 IEEE International Conference on Big Data (Big Data) 1867â1874 (IEEE, 2016).
Alexey, L., Mikhail, P. & Anatoliy, B. Scalable data processing approach and anomaly detection method for user and entity behavior analytics platform. In IDC: International Symposium on Intelligent and Distributed Computing 344â349 (Springer, 2020).
Al-Yaseen, W. L., Othman, Z. A. & Nazri, M. Multi-level hybrid support vector machine and extreme learning machine based on modified K-means for intrusion detection system. Expert Syst. Appl. 67, 296â303 (2017).
Chen, Y. et al. A fast clustering algorithm based on pruning unnecessary distance computations in DBSCAN for high-dimensional data. Pattern Recogn. 83, 357â387 (2018).
Tang, D., Zhang, S., Chen, J. & Wang, X. The detection of low-rate DoS attacks using the SADBSCAN algorithm. Inf. Sci. 565, 229â247 (2021).
Gu, Y., Li, K., Guo, Z. & Wang, Y. Semi-supervised K-means DDoS detection method using hybrid feature selection algorithm. IEEE Access 7, 64351â64365 (2019).
Nawaz, W., Khan, K.-U. & Lee, Y.-K. A multi-user perspective for personalized email communities. Expert Syst. Appl. 54, 265â283 (2016).
Jiang, J., Han, G., Liu, L., Shu, L. & Guizani, M. Outlier detection approaches based on machine learning in the Internet-of-Things. IEEE Wirel. Commun. 27, 53â59 (2020).
Lunt, T. F. & Jagannathan, R. A prototype real-time intrusion-detection expert system. In 1988 IEEE Symposium on Security and Privacy 59â66 (IEEE, 1988).
Hoglund, G. W. & Valcarce, E. M. The âESSENSEâ of intrusion detection: A knowledge-based approach to security monitoring and control. In 7th International Conference on Industrial and Engineering Applications of Artificial Intelligence and Expert Systems 201â209 (ACM, 1994).
Khan, M. A. & Abuhasel, K. A. An evolutionary multi-hidden Markov model for intelligent threat sensing in industrial internet of things. J. Supercomput. 77, 1â15 (2020).
Gang, Z., Jian, Y., Liang, Z. & Cai, Y. G. Prior knowledge SVM-based intrusion detection framework. In Third International Conference on Natural Computation (ICNC 2007) Vol. 2 489â493 (IEEE, 2007).
Lewicki, A. & Pancerz, K. Ant-based clustering for flow graph mining. Int. J. Appl. Math. Comput. Sci. 30, 561â572 (2020).
Chen, Y., Zhou, S., Zhang, X., Li, D. & Fu, C. Improved fuzzy c-means clustering by varying the fuzziness parameter. Pattern Recogn. Lett. 157, 60â66 (2022).
Hamza, A., Mokhtari, N., Brahimi, A. & Boukra, A. CSFCM: An improved fuzzy C-Means image segmentation algorithm using a cooperative approach. Expert Syst. Appl. 166, 114063 (2021).
Wang, H. Y., Wang, J. S. & Zhu, L. F. A new validity function of FCM clustering algorithm based on intra-class compactness and inter-class separation. J. Intell. Fuzzy Syst. 40, 1â22 (2021).
Wu, N., Wang, K., Wan, L. & Liu, N. A source number estimation algorithm based on data local density and fuzzy C-means clustering. Wirel. Commun. Mob. Comput. 2021, 1â7 (2021).
Sixu, L., Muqing, W. & Min, Z. Particle swarm optimization and artificial bee colony algorithm for clustering and mobile based software-defined wireless sensor networks. Wirel. Netw. 28, 1671â1688 (2022).
Cui, Y., Meng, X. & Qiao, J. A multi-objective particle swarm optimization algorithm based on two-archive mechanism. Appl. Soft Comput. 119, 108532 (2022).
Chicco, G., Ionel, O.-M. & Porumb, R. Electrical load pattern grouping based on centroid model with ant colony clustering. IEEE Trans. Power Syst. 28, 1706â1715 (2013).
Pan, K., Palensky, P. & Esfahani, P. M. From static to dynamic anomaly detection with application to power system cyber security. IEEE Trans. Power Syst. 35, 1584â1596 (2020).
Wei, W., Ming, Z., Zeng, X., Ye, X. & Sheng, Y. Malware traffic classification using convolutional neural network for representation learning. In 2017 International Conference on Information Networking 712â717 (IEEE, 2017).
Priyanga, P. S., Krithivasan, K., Pravinraj, S. & Shankar, S. Detection of cyberattacks in industrial control systems using enhanced principal component analysis and hypergraph-based convolution neural network (EPCA-HG-CNN). IEEE Trans. Ind. Appl. 56, 4394â4404 (2020).
Hongyu, L., Bo, L., Ming, L. & Hanbing, Y. CNN and RNN based payload classification methods for attack detection. Knowl. Based Syst. 163, 332â341 (2019).
Liu, J. C., Yang, C. T., Chan, Y. W., Kristiani, E. & Jiang, W. J. Cyberattack detection model using deep learning in a network log system with data visualization. J. Supercomput. 8, 1â20 (2021).
Li, Q., Wang, F., Wang, J. & Li, W. LSTM-based SQL injection detection method for intelligent transportation system. IEEE Trans. Veh. Technol. 68, 4182â4191 (2019).
Tang, P., Qiu, W., Huang, Z., Lian, H. & Liu, G. Detection of SQL injection based on artificial neural network. Knowl. Based Syst. 190, 105528 (2020).
Yue, Z. A. & Zga, B. Gaussian discriminative analysis aided GAN for imbalanced big data augmentation and fault classification. J. Process Control 92, 271â287 (2020).
Usama, M., Asim, M., Latif, S., Qadir, J. & Al-Fuqaha, A. Generative adversarial networks for launching and thwarting adversarial attacks on network intrusion detection systems. In International Wireless Communications and Mobile Computing Conference 78â83 (IEEE, 2019).
Ahmed, A., Krishnan, V., Foroutan, S. A., Touhiduzzaman, M. & Suresh, S. Cyber physical security analytics for anomalies in transmission protection systems. IEEE Trans. Ind. Appl. 55, 6313â6323 (2019).
Yang, Y., Zheng, K., Wu, C. & Yang, Y. Improving the classification effectiveness of intrusion detection by using improved conditional variational AutoEncoder and deep neural network. Sensors 19, 2528 (2019).
Ahn, J. & Han, R. Personalized behavior pattern recognition and unusual event detection for mobile users. Mob. Inf. Syst. 9, 99â122 (2013).
Yang, A., Zhuansun, Y., Liu, C., Li, J. & Zhang, C. Design of intrusion detection system for internet of things based on improved BP neural network. IEEE Access 7, 106043â106052 (2019).
Ahmim, A., Derdour, M. & Ferrag, M. A. An intrusion detection system based on combining probability predictions of a tree of classifiers. Int. J. Commun. Syst. 31, 1â17 (2018).
Belouch, M., El, S. & Idhammad, M. A two-stage classifier approach using RepTree algorithm for network intrusion detection. Int. J. Adv. Comput. Sci. Appl. 8, 389â394 (2017).
Lin, Z. & Li, H. Extract the network communities based on fuzzy clustering theory. Mod. Phys. Lett. B 35, 2150311 (2021).
Manickam, M., Ramaraj, N. & Chellappan, C. A combined PFCM and recurrent neural network-based intrusion detection system for cloud environment. Int. J. Bus. Intell. Data Min. 14, 504â527 (2019).
Liu, D., Chen, X. & Peng, D. Some cosine similarity measures and distance measures between q-rung orthopair fuzzy sets. Int. J. Intell. Syst. 34, 1572â1587 (2019).
Zadeh, L. A. Fuzzy sets. Inf. Control 8, 338â353 (1965).
Li, M. Generalized lagrange multiplier method and KKT conditions with an application to distributed optimization. IEEE Trans. Circuits Syst. II Express Briefs 66, 252â256 (2019).
Su, T., Shi, Y., Yu, J., Yue, C. & Zhou, F. Nonlinear compensation algorithm for multidimensional temporal data: A missing value imputation for the power grid applications. Knowl. Based Syst. 215, 1â13 (2021).
Gao, J. et al. Cube-based incremental outlier detection for streaming computing. Inf. Sci. 517, 361â376 (2020).
Gilani, L. & Tahir, S. F. Activity recognition and anomaly detection in smart homes. Neurocomputing 423, 362 (2020).
Lehmann, P.D.-I.R. The 3Ï-rule for outlier detection from the viewpoint of geodetic adjustment. J. Surv. Eng. 139, 157â165 (2015).
Canadian Institute for Cybersecurity. NSL-KDD Datasets. https://www.unb.ca/cic/datasets/nsl.html.
Funding
This work was supported by the National Key Research and Development Program of China under Grant No. 2018YFB0804701; the Natural Science Foundation of China under Grant No. 62072239; the S&T Program of Hebei under Grant No. 20377725D.
Author information
Authors and Affiliations
Contributions
G.Z., N.Y. and Z.C. conceived the original idea and supervised this work. J.C. performed the analyses, computations and wrote the first draft of the manuscript. G.Z. revised the manuscript. G.Z. gave the funding support. All authors reviewed the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Cui, J., Zhang, G., Chen, Z. et al. Multi-homed abnormal behavior detection algorithm based on fuzzy particle swarm cluster in user and entity behavior analytics. Sci Rep 12, 22349 (2022). https://doi.org/10.1038/s41598-022-26142-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-022-26142-w
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
