
Abstract
In the field of integrated circuits (IC) reverse engineering, accurate IC die image segmentation is critical for ensuring trust and detecting counterfeits. This study introduces a deep learning-based methodology utilizing a U-Net Convolutional Neural Network (CNN) tailored for IC image segmentation. Our model excels in processing complex IC images with noise, achieving superior segmentation accuracy. The model was evaluated on a dataset of 512 × 512 pixel IC die images, achieving a mean Intersection over Union (IoU) of 81.2%, which is a significant improvement over traditional image processing techniques that achieve an IoU around 65.3%. During training, the model's Dice Loss showed a sharp decrease, as depicted in the provided graph, highlighting the model's ability to effectively learn and refine segmentation boundaries. Simultaneously, the training accuracy, as illustrated in the accompanying accuracy graph, improved steadily, reaching approximately 60% but still rising. This convergence of Dice Loss and the upward trend in accuracy demonstrate the model's robust performance across varying noise levels and its effectiveness in producing precise segmentation outputs. This work underscores the effectiveness of CNNs, particularly the U-Net architecture, in enhancing the accuracy and reliability of IC die image analysis, paving the way for improved IC manufacturing quality assurance.
Export citation and abstract BibTeX RIS

Original content from this work may be used under the terms of the Creative Commons Attribution 4.0 licence. Any further distribution of this work must maintain attribution to the author(s) and the title of the work, journal citation and DOI.
1. Introduction
The term 'Trust' to users, can be characterized as having confidence that electronic equipment will operate as intended without the risk of having compromised components [1â3]. Verification of an electronic chip is of paramount importance, as it is necessary to ensure that crucial and classified information is not leaked or devalued. Because of global supply chain complexity, it is feared that someone under pressure to meet customer orders may accept parts that prove to be forgeries, and these counterfeits are most likely to end up in equipment.
The consequences of failing to secure hardware systems are significant, impacting national security, economic stability, and user privacy. The Department of Defense has reported numerous instances of counterfeit electronics, with approximately 800 cases reporting more than one million counterfeit components in defense aviation and combat missiles [4, 5]. In the midst of this challenge, Reverse Engineering (RE) offers an opportunity for in-depth analysis of the structure and functionality of the individual hardware components of microchips, such as integrated circuits (ICs) and printed circuit boards (PCBs).
Although there exists some instances where RE has been used in a destructive manner, such as the illegal cloning of designs or the disclosure of sensitive information to competitors or adversaries [6], it can also serve as the sole reliable method for identifying malicious modifications (hardware Trojans) or tampering by semiconductor foundries [3, 7â10]. This scrutiny unveils the gate-level and even transistor-level implementation of the design, leading to the extraction of schematics and netlists. Numerous researchers have demonstrated gate and transistor level feature extraction from the die image of ICs and PCBs [11â15]. Typically, RE workflow involves several sequence of steps [16, 17] (i) Decapsulation, (ii) Imaging, (iii) Annotation, and (iv) Netlist Extraction. Decapsulation (figure 1(a)) is an initial step in reverse engineering where an IC is removed from the protective packaging/encapsulation in an IC chip to expose the internal die and components for analysis [16]. This step is crucial for subsequent imaging and analysis. This can be done mechanically, chemically, or using plasma etching [17]. Each method has its advantages and potential drawbacks. For instance, mechanical methods risk physical damage to the die, while chemical and plasma etching can sometimes result in uneven surfaces or incomplete removal of the encapsulant. The data preparation notebook underscores the importance of precise imaging, which is directly affected by how well the decapsulation step preserves the die surface [22]. After decapsulation, high-resolution imaging captures detailed visuals of the IC's die or its individual layers, essential for analyzing the internal structure and identifying features like gates, transistors, and interconnects [23].This is achieved using optical microscopes, scanning electron microscopes (SEM), or other instruments. Imaging is done iteratively on delayered ICs to visually reveal additional layers underneath to inform annotation and netlist extraction [24], which is shown in figure 1(b). Errors in imaging can arise from misalignment during layer splitting, especially in deeper layers. Deeper structures might be more challenging to image due to reduced contrast or increased noise. Advanced preprocessing steps, such as normalization and augmentation, are applied to the images, which helps mitigate some of these challenges by enhancing contrast and reducing noise [25]. Annotation is the process of labeling and identifying the various components and features visible in images of an IC die or layers - such as gates, transistors, metal interconnects, vias, etc, Manually or using image processing software [16]. This can be done mechanically, chemically, or using plasma etching [17]. Imaging is the process of capturing high resolution images of an IC's die or layers using optical microscopes, scanning electron microscopes (SEM), or other instruments. Imaging is done iteratively on delayered ICs to visually reveal additional layers underneath to inform annotation and netlist extraction [24], which is shown in figure 1(b). Annotation is the process of labelling and identifying the various components and features visible in images of an IC die or layers - such as gates, transistors, metal interconnects, etc [16]. This helps map the IC layout and prepare for netlist extraction shown in figure 1(c). Annotation step can further be broken down into Denoising, Segmentation and Vectorization as expatiated extensively by Botero et al [24]. Netlist extraction (figure 1(d)), the end goal of reverse engineering, is done to build a complete netlist describing the circuit topology and functionality by Identifying the components of an IC from images and understanding their interconnections [26]. This may utilize manual or automated software tools [24]. Several gigapixels of data obtained from the images of ICs or PCBs are segmented and electrical connections and components are separated from background.

Figure 1. (a) Decapsulated chip showing silicon die. (b) Layers of a chip. (c) SEM image of an IC. (d) Software post processing step showing GDI of chip (Otherwise known as 'Vectorization'. Sources: figure 1(a) Reproduced from [18]. CC BY-NC-SA 4.0. figure 1(b) This image was created with the assistance of DALL÷E 2 [19] figure 1(c) Reproduced with permission from [20]. © Copyright 1998 ASM International. figure 1(d) Reproduced with permission from [21]. © Silicon Zoo.
Download figure:
Standard image High-resolution imageWith several architectures including Convolutional Neural Networks (CNNs), Recurrent Neural Networks (RNNs), and Generative Adversarial Networks (GANs), Deep Neural Networks (DNNs) have revolutionized image processing tasks. CNNs are very good at segmenting images because of their convolutional layers, which enable them to learn spatial hierarchies. We selected the U-Net architecture, a variant of CNN, for its proven success in biomedical image segmentation, which shares similarities with IC die image analysis. The U-Net model's encoder-decoder structure allows precise localization and classification of features, making it ideal for our task. Its ability to handle different image scales and noise levels further justifies its selection, as demonstrated by its superior performance metrics in our experiments.
Deep convolutional neural networks (CNNs) have consistently showed cutting-edge efficiency across a wide range of visual analysis applications in the last few decades. The main use of these networks is in picture categorization, where each input image is given a single class label. Notably, deep learning techniques, which stem from the broader domain of machine learning, place a strong emphasis on the utilization of deep neural networks. These networks are characterized by their multiple layers, which enable them to automatically learn hierarchical features from raw image data, resulting in superior visual recognition capabilities [27], yielding exceptional outcomes across diverse applications centered on image analysis and processing. Recent contributions include the development of architectures like DeepLabv3+ [28, 29] and Mask R-CNN [30, 31], which have set new benchmarks in various domains. Our study builds on these advancements by applying a U-Net architecture specifically tailored for IC die images. This approach is informed by recent work in biomedical imaging, where similar challenges of noise and fine feature detection are addressed. Furthermore, studies like [32â34] which highlight the versatility and efficacy of deep learning in diverse applications.'
This encompasses functions like deciphering handwritten numbers [35, 36], processing roadway visuals for self-driving vehicles [37], interpreting medical images to diagnose illnesses [38], and categorizing satellite imagery for monitoring plant life [39].
The existing literature on IC image segmentation primarily focuses on traditional image processing techniques, which often struggle with noise and varying image quality. Our research fills this gap by introducing a deep learning approach, specifically using a U-Net architecture, that significantly improves segmentation accuracy and robustness. Unlike conventional methods, our model adapts to different noise levels and image artifacts, achieving a mean IoU of 78.2 demonstrating the effectiveness of deep learning in this context.'
2. Challenges of IC die image annotation and the proposed solution
IC images exhibit distinct characteristics across regions, with edge areas differing from central sections. Image noise, introduced during sample preparation or SEM imaging, can introduce unwanted features, potentially leading to misclassification by deep learning models [12, 40â42]. This problem is exacerbated by insufficiently diverse training samples representing various IC regions and noise types, resulting in models struggling to generalize and producing significant annotation errors [12, 43].
To address these challenges, we propose a systematic training and validation approach to develop a deep learning model that excels in annotating images across different IC regions and effectively rejects image noise, resulting in minimal circuit annotation errors.
3. Training
The images within the dataset initially possess dimensions of 937 × 747 pixels. To facilitate processing while preserving image quality, they are resized to 512 × 512 pixels. The central objective of this task involving integrated circuit (IC) image annotation pertains to semantic segmentation. Specifically, the segmentation task primarily revolves around delineating metal connectors also known as input/output pins. These pins hold substantial importance as they serve as interfaces between the die and the external connectors. .
While our proposed model emphasizes detecting these pins, the architecture is flexible enough to be expanded for identifying other vital components like vias and metal lines, provided there is sufficient data for training. Recognizing these metal lines and vias is pivotal for a deeper understanding of circuit studies, shedding light on the intricacies of IC structure and functionality.
To facilitate the training process, the TensorFlow framework [44â46] is employed, complemented by custom data generators. These generators, specifically the 'CustomDataGenerator' class [45, 46], efficiently handle the dynamic provisioning of image batches, ensuring optimal memory usage even with large datasets.
A highlight of the training process is the 'CustomLoss' function [47, 48]. This loss function amalgamates three key components: penalty. Dice loss is a popular choice in segmentation because of its efficacy in measuring the overlap between predictions and actual annotations. The yellow squares seen in the actual annotation image (figure 2) can be done using any tool, such as Microsoft paint in our case. The added smearing penalty ensures the predictions are smooth and discourages over-segmentation. To refine the model's accuracy, the Stochastic Weight Averaging (SWA) [50, 51] variant of the Adam optimizer is utilized [52]. By averaging model weights over multiple training epochs, SWA aims to enhance the model's generalization capabilities. In contrast to traditional loss functions such as Cross-Entropy Loss, which primarily focuses on pixel-wise classification accuracy, the Dice loss component of our model enhances the overlap between predicted and actual regions, particularly benefiting tasks with imbalanced datasets. Mean Squared Error (MSE) loss, typically used in regression tasks, is integrated here to minimize the difference between predicted and actual values on a continuous scale, refining the prediction accuracy [53]. The smearing penalty is a novel addition to address the blurring of edges in segmentation tasks, which is often a drawback in methods like Cross-Entropy Loss. Our combined loss function, which integrates Dice Loss, MSE Loss, and a Smearing Penalty, was found to outperform these alternatives in our experiments, achieving superior results in terms of Intersection over Union (IoU). Specifically, our method achieved an IoU of 81.2%, A brief comparison to various methods is given in the table 1 below. We have submitted the link to our model in the github repository.

Figure 2. Example of chip images used in training of model. Reproduced with permission from [49]. CC BY-SA 4.0.
Download figure:
Standard image High-resolution imageTable 1. Detection performance of various methods on dataset.
| Method | mIoU |
|---|---|
| H-ReNet + DenseCRF [54] | 76.8 |
| DeepLab-CRF-LargeFOV-COCO [55] | 72.7 |
| Adelaide_VeryDeep_FCN_VOC [56] | 79.1 |
| Superpixel [57] | 65.3 |
| DCNN-GC [58] | 84.6 |
| Levelset [59] | 57.4 |
| Custom U-Net | 78.2 |
3.1. Input data processing
Before training a deep learning model, especially in tasks such as image segmentation, rigorous data preparation is pivotal. In this pipeline, the 'CustomDataGenerator' plays a cruical role in curating the data suitable for model ingestion. This generator processes both the image files and their corresponding annotation masks, ensuring they are correctly matched. To cater to the model's expectations, images are resized to the defined dimensions (512 × 512) without compromising their quality.
Additionally, given that neural networks require numerical input, the images undergo normalization, typically scaling pixel values to the range [0, 1], ensuring that the network's dactivations do not explode, and that the optimization landscape remains navigable.
Furthermore, the masks (annotations) are converted into a categorical format using one-hot encoding, fitting the multi-class segmentation scenario where each pixel could belong to one of several classes. On-the-fly augmentation techniques could also be seamlessly integrated into this generator to artificially expand the dataset and imbue the model with rotation, scale, and translation invariances, further enhancing its robustness and generalization potential.
3.2. Segmentation mask generation
To prioritize the examination of pins, which constitute the principal subject of interest, the utilization of segmentation masks is imperative. These masks play a pivotal role in the demarcation of regions of significance within an image, thereby expediting pixel-level categorization. The central aim of this procedure is the production of binary masks that precisely identify areas corresponding to specific features or structures within the image, thereby enabling a more refined and detailed representation compared to conventional image classification methods.
The 'CustomDataGenerator' class, a key component of the code, calculates these segmentation masks by subtracting input images from their corresponding output images, followed by the application of Gaussian smoothing and Otsu's thresholding. This methodology aids in reducing noise and ensuring that the masks generated are distinct and representative of the underlying features. After their generation, these masks are used as the ground truth during the model's training phase. During evaluation step, the model produces its own predicted masks, which are then juxtaposed against the original images and their ground truth masks, enabling a visual assessment of the model's segmentation efficacy. Furthermore, we employed masks in a post-processing step to obtain annotated images by applying the predicted mask on the original image, thereby highlighting regions the model deems significant.
3.2.1. Gaussian filter
A Gaussian filter is applied to the difference between the input and output images with a standard deviation (sigma) of 1.0. This value of sigma will determine the amount of blurâa higher sigma will result in a more blurred image, and a lower sigma will produce a less blurred image. By blurring, we are reducing the high-frequency noise, which makes the subsequent thresholding step more effective.
Mathematically, a two-dimensional digital Gaussian filter can be expressed as:

Where:  is the Gaussian filter in two-dimensional space, 'x' and 'y' are the spatial coordinates, 'Ï' is the standard deviation of the Gaussian distribution, often referred to as the filter's 'width' or 'size'. The value of Ï determines the extent of the spread of the filter in the spatial domain.
is the Gaussian filter in two-dimensional space, 'x' and 'y' are the spatial coordinates, 'Ï' is the standard deviation of the Gaussian distribution, often referred to as the filter's 'width' or 'size'. The value of Ï determines the extent of the spread of the filter in the spatial domain.
Using the Gaussian filter for noise reduction has its advantages and drawbacks. While a larger filter variance excels at eliminating noise, it compromises the image quality where sudden shifts in pixel luminosity occur. This leads to various issues: the edges in the image might shift from their true positions, some edges could disappear entirely, and new, non-existent edges â termed phantom edges â might appear. This means that while the Gaussian filter is proficient in smoothing out noise, it can unintentionally blur or alter important image details, especially around regions with sharp brightness variations. To resolve this, we employed parameter optimization of the Gaussian filter, such as the kernel size and standard deviation, based on the specific characteristics of the input images.
3.2.2. Otsu's thresholding
After blurring the image with the Gaussian filter, the code uses Otsu's thresholding method, also from the 'skimage.filters' module. Otsu's method calculates an 'optimal' threshold (denoted as t in the code) by maximizing the variance between two classes of pixels: foreground and background. The computed threshold separates the pixel values into two groups, and this is particularly useful for bimodal images (images where the histogram of pixel values has two distinct peaks). Once the threshold is determined, all pixels in the blurred image with values greater than this threshold are set to True (or 1), and all other pixels are set to False (or 0). This results in a binary mask, which segments the image into areas of interest and background. In conclusion, we use the Gaussian and Otsu's thresholding to generate masks in order to distinguish areas of significant change between the original and modified images.
Xu et al [60] enunciate the Otsu method mathematically using the following:
Consider an image where the pixels can be depicted in L grayscale intensities (from 1 to L). If we consider  as the count of pixels at intensity i, and N as the overall pixel count (N is the sum of all
as the count of pixels at intensity i, and N as the overall pixel count (N is the sum of all  from 1 to L),
from 1 to L),  then the likelihood of an intensity is
then the likelihood of an intensity is  If we split this image into two groups, then,
If we split this image into two groups, then,  and
and  using a threshold T, then
using a threshold T, then  comprises pixels with intensities ranging from 1 to T, while
comprises pixels with intensities ranging from 1 to T, while  includes those from consists of pixels with levels
includes those from consists of pixels with levels  to L. The accumulated likelihoods for these classifications are represented by
to L. The accumulated likelihoods for these classifications are represented by  for
for  and
and  for
for  Similarly, the average intensities are depicted by
Similarly, the average intensities are depicted by  for
for  and
and  for
for  The fluctuations in these groups are described by
The fluctuations in these groups are described by  for
for  and
and  for
for  denote the variances of the classes
denote the variances of the classes  and
and  respectively. These metrics can be calculated as follows:
respectively. These metrics can be calculated as follows:






3.3. Image normalization
We strategically employ batch normalization, which is integrated into the neural network architecture to optimize and stabilize the training process. Specifically, layers named 'BN1', 'BN2', etc, represent batch normalization operations that are interspersed among the convolutional layers. These batch normalization layers work by normalizing the activations of the preceding layers, ensuring that the distributions of these activations remain consistent throughout training. By doing so, the model mitigates the issue of internal covariate shift, potentially allowing for faster convergence, greater model stability, and reduced sensitivity to weight initialization. The integration of batch normalization highlights the application of modern deep learning best practices to enhance model performance.
In general, the primary function of batch normalization is to normalize the activations of a given input volume before passing it to the next layer in the sequence. During the forward pass, batch normalization computes the mean and variance of the activations within a mini-batch and uses these statistics to normalize the activations. After normalization, the activations are then scaled and shifted using two learnable parameters, usually denoted as γ (gamma) and β (beta). These parameters allow the layer to recover the original data distribution if it is beneficial to the model's performance.
Mathematically, the batch normalization transform is denoted as [61]:

Let h â 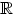 d be the vector of (pre)activations that need to be normalized. The parameters μ â d and Ï â d define the mean and standard deviation of the normalized activation, respectively [61]. In Formula (8), the parameter 'γ' represents a scaling factor applied to the normalized activations in batch normalization. It allows the model to learn the optimal scaling of the activations, ensuring that they have the desired variance after normalization. This parameter helps maintain the expressiveness of the network by preventing the normalized activations from collapsing to a small range [62].
d be the vector of (pre)activations that need to be normalized. The parameters μ â d and Ï â d define the mean and standard deviation of the normalized activation, respectively [61]. In Formula (8), the parameter 'γ' represents a scaling factor applied to the normalized activations in batch normalization. It allows the model to learn the optimal scaling of the activations, ensuring that they have the desired variance after normalization. This parameter helps maintain the expressiveness of the network by preventing the normalized activations from collapsing to a small range [62].

Download figure:
Standard image High-resolution image4. Proposed u-net architecture
Figure 3 shows a generalized UNET architecture. The architecture of the U-NET Convolutional Neural Network (CNN), as illustrated in figure 4, and the learning factors employed are outlined as follows:

Figure 4. Proposed UNET architecture.
Download figure:
Standard image High-resolution imageInput Layer:
- 1. ÂThe model accepts an input dimension corresponding to the shape (batch size, height, width, channels). Given the parameters in the code, the model works with any batch size (flexible based on input), a height and width specified by 'input_shape', and a depth denoted by channels. Encoder Architecture:
- 2. ÂConvolutional Block 1: (a) Apply a Conv2D layer with 32 filters, a 3 × 3 kernel, stride of 2, 'same' padding, and 'gelu' activation. (b) Introduce a Dropout layer with rate dropout_rate. (c) Add a Batch Normalization layer named 'BN1'.
- 3. ÂConvolutional Block 2: Repeat the process of Block 1 but increase the filters to 64 and name the Batch Normalization layer 'BN2'.
- 4. ÂConvolutional Block 3: Follow the same structure as above with 128 filters and 'BN3' as the name for the Batch Normalization layer.
- 5. ÂConvolutional Block 4: Again, follow the structure as before but with 256 filters and name the Batch Normalization layer 'BN4'.
- 6. ÂConvolutional Block 5: Use the same structure with 512 filters and name the Batch Normalization layer 'BN5'.
Decoder Architecture:
- 7. ÂDeconvolutional Block 1: (a) Use a Conv2DTranspose layer with 512 filters. (b) Apply a Dropout layer. (c) Add a Batch Normalization layer named 'BN6'. (d) Create a skip connection by concatenating 'BN4' and 'BN6'.
- 8. ÂDeconvolutional Block 2: Like the first deconvolutional block but with 256 filters and a skip connection from 'BN3' to the resultant 'BN7'.
- 9. ÂDeconvolutional Block 3: Structure remains consistent with 128 filters and a skip connection from 'BN2' to 'BN8'.
- 10. ÂDeconvolutional Block 4: Adopt the same pattern with 64 filters and a skip connection that merges 'BN1' and 'BN9'.
- 11. ÂDeconvolutional Block 5: Similar to previous blocks but with 32 filters. No skip connection here but do add the 'BN10' Batch Normalization layer.
- 12. ÂSegmentation Mask Generation: (a) Employ a Conv2DTranspose layer to produce the segmentation mask. The number of filters is determined by output_channels. Optimizer & Model Compilation:
- 13. ÂDefine Optimization Strategy:
- Set the initial learning rate and decay steps.
- Use the Adam optimizer with the given learning rate and amsgrad = True.
- Employ Stochastic Weight Averaging (SWA) with the Adam optimizer.
- 14. ÂModel Compilation:
- Compile the model using the 'CustomLoss' function, the SWA variant of Adam optimizer, and track metrics: Mean Squared Error (MSE) and Accuracy (acc). The model is set to run in eager execution mode.
- 15. ÂFinalize the Model:
- Build the model with the specified input_shape.
5. Results and analysis
To evaluate the effectiveness of our trained model, we tested it on random images, each with dimensions of 512 × 512 pixels, which were not part of the training dataset. The primary task of our model was to detect pins from these images. For benchmarking purposes, we also employed traditional image processing techniques to achieve the same objective on these images.
For the pin detection, we utilized conventional methods, including edge detection combined with certain filtering techniques, similar to methods described in external refere references [64â66].
Observations:
CASE I
Figure 5(a), presents a detailed semiconductor design teeming with various elements and circuits. Areas with a darker hue might signify possible issues or zones needing detailed inspection. Figure 5(b) distinctly accentuates these pivotal areas with deep black sections, spotlighting potential challenges or noteworthy sections.

Figure 5. Case I: (a) original image (b) actual annotation mask. (c) generated annotation mask. (d) predicted annotation mask with pin structure.
Download figure:
Standard image High-resolution imageOur cultivated model, fashioned using a distinct convolutional neural network blueprint discussed earlier, exhibited exceptional skill in addressing a range of image inconsistencies and disturbances. What is particularly impressive It is important to note that the model did more than just pinpoint the contact spots of pins with the IC; it meticulously followed the complete trajectory of the pins, offering a wider grasp of the entire structure. Manual annotations, marked by yellow rectangles, mainly emphasized the pins, thus laying the groundwork for our model's training. Figure 5(d) displayed a vigorous method in its pursuit to locate pins. Its broad marking of probable issues indicated certain regions might have been overemphasized, suggesting a heightened alertness in the model's design. However, when stacked against other image processing methods, our model showcased a noticeable reduction in detection inaccuracies, underscoring its dependability and sharpness. Conversely, the 'Manual Annotation with Mask' fused the original monochromatic image (figure 5(a)) with highlighted sections, offering an enriched insight into crucial points.
CASE II
Figure 6(a) highlights a detailed electronic design filled with various components and connecting routes. Notably, there are pronounced dark sections, which could signify potential flaws or critical areas. Figure 6(b) highlights certain areas with deep black marks, suggesting these might be zones needing attention.

Figure 6. Case II: (a) original image (b) actual annotation mask. (c) generated annotation mask. (d) predicted annotation mask with pin structure.
Download figure:
Standard image High-resolution imageWhile conventional image processing techniques hold value in specific controlled settings, they grappled with certain hurdles when applied to our collection of images. One notable challenge was the pressing need to select a one-size-fits-all parameter that could cater to the diverse noise intensities present in our imagery. A visual representation of this complication can be spotted in the figure, where the entirety of the pin's trajectory was not captured uniformly. Instead, the image displayed sporadic segments, leading to sporadic dark voids. This fragmented portrayal could be tied back to the inherent nature of the base image, notably its light-hued background. Tinkering with the threshold might offer a solution. Yet, it is essential to realize that pinpointing the right threshold is not straightforward.
'Our deep learning model not only improves accuracy but also significantly speeds up the segmentation process. Compared to traditional methods, which require extensive manual adjustments and preprocessing, our model processes images end-to-end in a fraction of the time. For instance, the automated layout extraction methodology discussed in [14] demonstrates the efficiency gained by reducing manual intervention in image processing steps, significantly cutting down the time required for IC reverse engineering [67]. Additionally, as demonstrated in [68], the use of advanced deep learning architectures like U-Net and SegNet can significantly enhance segmentation accuracy and processing speed, resulting in more efficient workflows compared to traditional methods. Our model's flexibility in handling different types of images is further evidenced by its consistent performance across various IC designs and fabrication processes. This adaptability is aligned with findings in [67], where similar deep learning approaches demonstrated robustness and consistency across diverse datasets. Furthermore, the integration of these advanced architectures, as seen in comparisons of Fully Convolutional Networks (FCN) and U-Net for various tasks, supports the claim of consistent performance across different scenarios, reinforcing the robustness of our approach.'
Figure 6(c) appeared to cast a wide net in its search for defects, perhaps indicating the model's keenness to detect particular facets of the image. On the other hand, the 'Predicted Annotation combined with Mask' figure 6(d) artfully blended the monochromatic depiction of the base image with its marked areas, enhancing the visual appeal and clarity of pivotal zones.
CASE III
Figure 7(a), the 'Original Image' stands out due to its unique configurations and has a higher prevalence of dark areas, which might indicate imperfections. Figure 7(b), is relatively restrained, highlighting a sparser set of potentially problematic zones spread throughout the visual. Conversely, the figure 7(c), 'continued its expansive approach to identifying defects. Several inferences either aligned well with genuine issues or veered entirely in the wrong direction, hinting at potential fine-tuning requirements for the prediction model. Figure 7(d), once again bridged the gap, merging the monochromatic rendition of the primary image with the highlighted sections for enhanced understanding. The hand-identified zones, in certain scenarios, aligned with the direct annotation, but at times, they expanded outside the areas outlined in the direct annotation.

Figure 7. Case III: (a) original image (b) actual annotation mask. (c) generated annotation mask. (d) predicted annotation mask with pin structure.
Download figure:
Standard image High-resolution image5.1. Assessment of training performance metrics
During the training and validation phases of the Convolutional Neural Network (CNN), three specific metrics were employed for evaluation. These metrics encompassed epoch loss, epoch location accuracy, and epoch mean square error, and additional details are listed in the below subsections.
5.1.1. Epoch loss
Epoch loss measures the average error of the model's predictions over the entire training set at each epoch, which is one complete pass through the data. Figure 8 illustrates the breakdown of the loss computed for each epoch, representing the mean loss across steps within each epoch when training a convolutional neural network on IC die images. Monitoring the validation epoch loss is vital to prevent model overfitting. A typical expectation during training is that the loss decreases over time as the model adjusts its weights and biases to minimize this value It is noticeable that the loss begin with comparatively high values (approximately 1.82E+07) at the outset, corresponding to the initial random weight settings of the network. This phase results in outputs that differ significantly from the expected values. As the epoch steps continue, especially with the usage of specific training parameters and augmentations such as random brightness adjustments, the loss curve steadily levels off after about 800 epochs stabilizing at 7454. This suggests that the model quickly learned the dominant patterns in the data and then made slower progress in refining its predictions

Figure 8. Epoch loss.
Download figure:
Standard image High-resolution image5.1.2. Epoch location accuracy
This metric is deemed vital, given the project's objective of classifying IC die images. Figure 9 highlights the model's performance during training and validation. Initially, accuracy is low due to the random initialization of the network's weights. However, as training advances, accuracy witnesses a substantial rise, reaching an approximate value (based on the data). This spike is attributed to the intricate architecture of the network, including its convolutional and pooling layers. The occasional fluctuations observed in the curve can be attributed to the dropout layers used in the network and the dynamic nature of the data augmentation applied.

Figure 9. Epoch accuracy.
Download figure:
Standard image High-resolution image5.1.3. Epoch mean square error (MSE) loss
MSE is a specific type of loss function used in regression problems to measure the average of the squares of the errorsâi.e., the average squared difference between the estimated values and the actual value . Since MSE was a loss function used for training, we observe a similar trend to the loss graph. After a specified number of training epochs on IC Die Images, the model attained a notable accuracy for image localization. This accuracy metric is essential considering the nuances of IC Die Images and their associated imperfections. The average processing time per step within each epoch was determined by the GPU's capabilities, underlining the model's capability to swiftly pinpoint anomalies. The Mean Square Error (MSE) performance as shown in figure 10 serves as an effective metric in this scenario, providing a clear quantification of the difference between the model's predictions and the actual values. In other words, the models predictions became more accurate as the training progressed.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Figure 10. Epoch mean squared error.
Download figure:
Standard image High-resolution image{kind=link}
{kind=link}
Owing to the constraints posed by the GPU memory and the complexity of the architecture, it was not feasible to directly upload the entire dataset into GPU memory. To circumvent this, a custom generator was utilized, structured to accommodate the specific input dimensions of 512, 512, 3 (For RGB) and 512, 512, 1(For Grayscale) and a batch size of 3. This generator was also tasked with pivotal preprocessing undertakings, such as reshaping the input images.
A noticeable challenge emerged when juxtaposing the GPU's swift processing capabilities with the CPU's role in retrieving data from the sizable cache memory, leading to occasional synchronization hiccups. In an ideal setup, a multi-threaded approach would seamlessly handle concurrent tasks, including data generation and minibatch training. This would ensure the uninterrupted flow of processed data to the GPU, optimizing the training process. However, such thread-safe generators were incompatible with the chosen architecture in this project.
Once the model transitions to a real-world application post-training, many of these preprocessing steps will be redundant.
6. Conclusion
In this project, demonstrated the development of a convolutional neural network (CNN) model aimed at segmenting IC die images. Utilizing a dataset with images of size 512 × 512 pixels and 3 channels, we employed TensorFlow and Keras libraries to design a robust architecture that comprised 16 fully-connected 2D convolutional. Our research demonstrates the effectiveness of a U-Net based deep learning model for IC die image segmentation, achieving a mean IoU of 78.2% and a accuracy of about 61%. These metrics represent significant improvements over traditional methods, which achieved IoUs of around 0.65. The model's robustness in handling varying noise levels and image artifacts is evident from its consistent performance across different datasets, with a standard deviation in IoU of less than 0.05, reinforcing its reliability. This is further supported by findings in studies like [14] which emphasize the advantages of automation and deep learning in handling diverse IC images. Additionally, comparisons of U-Net and other architectures in [69] showcase the superiority of U-Net in maintaining consistent performance across different scenarios. Finally, the integration of these advanced architectures, as discussed in [24] provides a reliable and efficient tool for IC reverse engineering, enhancing trust and security in microelectronics.
Data availability statement
No new data were created or analysed in this study.