

Abstract
Generative adversarial networks (GANs) have rapidly emerged as powerful tools for generating realistic and diverse data across various domains, including computer vision and other applied areas, since their inception in 2014. Consisting of a discriminative network and a generative network engaged in a minimax game, GANs have revolutionized the field of generative modeling. In February 2018, GAN secured the leading spot on the 'Top Ten Global Breakthrough Technologies List' issued by the Massachusetts Science and Technology Review. Over the years, numerous advancements have been proposed, leading to a rich array of GAN variants, such as conditional GAN, Wasserstein GAN, cycle-consistent GAN, and StyleGAN, among many others. This survey aims to provide a general overview of GANs, summarizing the latent architecture, validation metrics, and application areas of the most widely recognized variants. We also delve into recent theoretical developments, exploring the profound connection between the adversarial principle underlying GAN and Jensen–Shannon divergence while discussing the optimality characteristics of the GAN framework. The efficiency of GAN variants and their model architectures will be evaluated along with training obstacles as well as training solutions. In addition, a detailed discussion will be provided, examining the integration of GANs with newly developed deep learning frameworks such as transformers, physics-informed neural networks, large language models, and diffusion models. Finally, we reveal several issues as well as future research outlines in this field.

Original content from this work may be used under the terms of the Creative Commons Attribution 4.0 license. Any further distribution of this work must maintain attribution to the author(s) and the title of the work, journal citation and DOI.
1. Introduction
Generative adversarial networks (GANs) have emerged as a transformative deep learning approach for generating high-quality and diverse data. In GAN, a generator network produces data, while a discriminator network evaluates the authenticity of the generated data. Through an adversarial mechanism, the discriminator learns to distinguish between real and fake data, while the generator aims to produce data that is indistinguishable from real data.
Since their introduction in 2014 by Goodfellow et al [1], GANs have witnessed remarkable advancements, leading to the development of numerous specialized variants that excel in creating data across diverse fields. Conditional GAN (CGAN) [2] enables the generation of data based on specific conditions or desired qualities, such as synthesizing photos of a particular class. Cycle-consistent GAN (CycleGAN) [3] have proven effective in image-to-image translation tasks, even in the absence of paired data. StackGAN [4] has demonstrated the ability to generate high-resolution images from textual descriptions, pushing the boundaries of visual realism. Progressive GAN [5] has achieved exceptional results in producing high-quality images with increasing resolution. StyleGAN [6], known for its versatility, generates images with a wide range of styles and distinctive features. Furthermore, GANs have extended beyond visual domains and shown potential in generating textual [7], musical [8], three-dimensional (3D) modeling [9], future cities [10], time series [11] data among many others.
The success of GANs has led to their adoption in various applications, such as image and video synthesis, data augmentation, super-resolution, inpainting, anomaly detection, and image editing. GANs have also been employed to address data scarcity issues in machine learning, where they generate synthetic data to improve the effectiveness of models trained on limited datasets [12]. Additionally, GANs have found utility in creating realistic simulations for video games and virtual reality environments, enhancing user experiences and immersive interactions [13]. To ensure the comprehensiveness of this survey, we conducted an extensive review of the research papers encompassing both theoretical advancements and practical applications of GAN. Our survey draws insights from diverse fields, including computer vision (CV), natural language processing (NLP), autonomous vehicles, time series, medical domain, and many others. Notable papers that significantly contributed to our survey include Goodfellow et al [1] for introducing the GAN framework, Mirza and Osindero [2] for pioneering CGAN, Zhu et al [3] for introducing CycleGAN, Karras et al [5] for their seminal work on progressive GAN, and Chen et al [14] for the breakthroughs achieved with information maximizing GAN (InfoGAN), among many others.
Despite their remarkable achievements, GANs face several challenges in practice. One prominent issue is the instability of the training process, which can result in mode collapse (MC) or oscillation [15]. Another challenge lies in evaluating generated data, as conventional assessment criteria may not adequately capture the diversity and realism of the synthesized samples [16]. Furthermore, GANs have been observed to exhibit biases, particularly concerning gender and race, potentially reflecting the biases present in the training data [17, 18]. To overcome the limitations of GAN, various modified training approaches and hybridization with popular deep learning architectures such as transformers [19], physics-informed neural network (PINN) [20], large language models (LLMs) [21], and diffusion models [22] have been proposed in the literature. These modified methodologies have shown promise in enhancing the synthetic data generation capabilities of GANs.
Finally, GANs have emerged as an effective tool for producing high-quality and varied data in several disciplines. Notwithstanding the difficulties connected with their use, GANs have shown outstanding results and have the potential to drive innovation in fields such as CV, machine learning, and virtual reality. This in-depth analysis covers the accomplishments and limitations of GAN, as well as the promise of these approaches for future research and applications. This comprehensive survey aims to explore both the achievements and challenges of GAN. Throughout the manuscript, we have used both acronyms, 'GAN' and 'GANs', to denote the GANs framework. The contributions of the article can be summarized as follows:
- Exploration of vanilla GAN and their applications: we offer an elaborate description of the GAN model, encompassing its architectural particulars and the mathematical optimization functions it employs. We summarize the areas where GANs have emerged as a promising tool in efficiently solving real-world problems with their generative capabilities.
- Evolution of state-of-the-art GAN models across the decade: our comprehensive analysis encompasses a wide range of cutting-edge GAN adaptations crafted to address practical challenges across various domains. We delve into their structural designs, practical uses, execution methods, and constraints. We present an intricate chronological breakdown of GAN model advancements to facilitate a lucid understanding of the field's progress. Furthermore, we evaluate recent field surveys, outlining their pros and cons while tackling these aspects within our survey.
- Theoretical advancements of GANs: we give a technical overview of the theoretical developments of GANs by exploring the connections between adversarial training and Jensen–Shannon (JS) divergence and discussing their optimality features.
- Assessment of GAN models: we provide a comprehensive breakdown of the essential performance measures utilized to assess both the caliber and range of samples produced by GANs. These metrics notably fluctuate depending on the specific domains of application.
- Limitations of GANs: we critically examine the constraints associated with GANs, primarily stemming from learning instability issues, and discuss various enhancement strategies to alleviate these challenges.
- Anticipating future trajectories: in addition to evaluating the pros and cons of current GAN-centric approaches, we illuminate the hybridization of emerging deep learning models such as transformers, PINNs, LLMs, and diffusion models with GANs. We outline potential avenues for research within this domain by summarizing several open scientific problems.
This survey is structured in the following manner. Section 2 digs into related works and recent surveys, giving background information and emphasizing the most significant developments in GAN over the decade. Section 3 is a concise overview of GAN describing the fundamental components and intricate details of its architecture. In section 4, we examine the wide range of fields that GANs have influenced, such as CV, NLP, time series, and audio, among many others. Subsequently, section 5 reviews the innovations and applications of popular GAN-based frameworks from various domains along with their implementation software and discusses their limitations. This section also provides a timeline for the GAN models to have a clear vision of the development of this field. Section 6 summarizes the recent theoretical results of GAN and its variants. Section 7 reviews the metrics used for evaluating GAN-based models. Section 8 analyzes the limitations of GANs and presents its remedial measures. Section 9 discusses the potential and usability of GANs with the development of new deep learning technologies such as transformers, PINNs, LLMs, and diffusion models. Section 10 proposes potential directions for further research in this field. Finally, section 11 concludes the survey by indicating prospective directions for future research projects while offering a closing assessment of the successes and limits of GANs.
2. Related works and recent surveys
GANs are a promising deep learning framework for generating artificial data that closely resembles real-world data [1]. Early GAN-related research focused on creating realistic visuals. Radford et al proposed a deep convolutional GAN (DCGAN) in 2015 [23], which utilized convolutional layers, batch normalization, and a specific loss function to generate high-quality images. DCGAN introduced important innovations in image generation. In 2017, Karras et al [5] introduced progressive growing GAN (ProGAN), which generates higher quality and resolution images compared to vanilla GAN. ProGAN trains multiple generators and discriminators in a stepwise manner, gradually increasing the resolution of the generated images. The results demonstrated the ability of ProGAN to produce images closely resembling genuine photos for various datasets, including the CelebA dataset [24].
GANs have found applications beyond image generation, including video production and text generation. Vondrick et al proposed a video generation GAN (VGAN) in 2018 [25], capable of producing realistic and diverse videos by learning to track and anticipate object motion. The VGAN architecture consisted of a motion estimation network and a video-generating network, jointly trained to generate high-quality videos. The results showcased VGAN's ability to produce realistic and varied films, enabling applications like video prediction and synthesis. Text generation is another domain where GAN has been utilized. In 2017, Yu et al introduced SeqGAN, a GAN-based text generation model [26]. SeqGAN achieved realistic and diverse text generation capabilities by maximizing a reinforcement learning goal. The model included a generator responsible for text creation and a discriminator assessing the quality of the generated text. Through reinforcement learning, the generator was trained to maximize the predicted reward based on the discriminator's evaluation. The findings demonstrated that SeqGAN outperformed previous text generation algorithms, producing more varied and lifelike text. These advancements in GAN applications for video and text generation highlight the versatility and potential of GAN frameworks in diverse domains.
Another popular area of research focuses on addressing medical questions using GANs, as highlighted in the recent paper by Tan et al where a GAN-based scale invariant post-processing approach is proposed for lung segmentation in CT scans [27]. A similar framework called RescueNet, developed by Nema et al combines domain-specific segmentation methods and general-purpose adversarial learning for segmenting brain tumors [28]. Their study suggests a promising technique for brain tumor segmentation and advances the development of systems capable of answering complex medical inquiries. Despite the significant breakthroughs, there are still unresolved issues in GAN architectures and applications. One prominent challenge is the instability of GAN training, which can be influenced by various factors such as architecture, loss function, and optimization technique. In 2017, Arjovsky and Bottou proposed a solution called Wasserstein GAN (WGAN) [15], introducing a novel loss function and optimization algorithm to address stability issues in GAN training. Their approach improved stability and performance on datasets like CIFAR-10 [29] and ImageNet [30].
Related survey. The existing body of research exploring various analytic tasks with GAN is accompanied by numerous surveys, which predominantly concentrate on specific perspectives within constrained domains, particularly CV and NLP. For instance, the survey by Jabbar et al [31] explores applications of GANs in various industries, including CV, NLP, music, and medicine. They also highlight noteworthy academic publications and real-world instances to demonstrate the influence and promise of GANs in certain application domains. The study tackles the difficulties and problems related to GAN training and discusses their variations. The authors [31] investigate several training strategies, including minimax optimization, training stability, and assessment measures. They examine the typical challenges that arise during GAN training, such as MC and training instability, and they give numerous solutions researchers have suggested to address these problems. However, it does not specifically concentrate on GAN-based methods for imbalanced time series, geoscience, and other data types and fails to reflect the most recent advancements in the field. The survey by Xia et al [32] focuses on two primary categories of techniques for GAN inversion: optimization-based methods and reconstruction-based methods. To locate the hidden code that optimally reconstructs the supplied output, optimization-based approaches formulate an optimization issue. On the other hand, reconstruction-based approaches use different methods, such as feature matching or autoencoders, to estimate the latent code directly. An in-depth discussion of these strategies' advantages, disadvantages, and trade-offs is provided in the article. The non-convexity of the optimization issue and the lack of ground truth data for assessment are only two of the difficulties faced in GAN inversion highlighted in this article. The authors [32] additionally go through specific evaluation standards and measures designed for CV tasks. In addition, the study discusses current developments and variants in GAN inversion, such as techniques for managing CGAN, detaching latent variables, and dealing with different modalities. Aspect modification, domain adaptability, and unsupervised learning are a few of the applications and potential future directions of GAN inversion that are covered. A recent study by Durgadevi et al [33] presents a comprehensive overview of numerous GAN variants proposed until 2020. Since their inception, GANs have evolved significantly, leading researchers to propose various enhancements and modifications to address the prevalent challenges. These alterations encompass diverse aspects such as architectural design, training methods, or both. In this survey [33], the authors delve into the application and impact of GANs in different domains, including image processing, medicine, face detection, and text transferring. The survey by Alom et al [34] covers various aspects of the deep learning paradigm, such as fundamental ideas, algorithms, architectures, and contemporary developments, including convolutional neural networks (CNNs), recurrent neural networks, deep belief networks, generative models, transfer learning, and reinforcement learning. The survey of Nandhini et al [35] thoroughly investigates the application of deep CNNs and deep GANs in computational image analysis driven by visual perception. The designs and methodology used, the outcomes of the experiments, and possible uses for these approaches are covered in the paper. Overall, this study provides a retrospective review of the development of GANs for the deep learning-based image analysis community. The survey by Kulkarni et al [36] presents an overview of various strategies, techniques, and developments used in GAN-based music generation. The survey of Sampath et al [37] summarizes the current advances in the GAN landscape for CV tasks, including classification, object detection, and segmentation in an imbalanced dataset. Another survey by Brophy et al [38] attempts to review various discrete and continuous GAN models designed for time series-related applications. The study by Xun et al [39] reviews more than 120 GAN-based models designed for region-specific medical image segmentation published until 2021. Another recent survey by Ji et al [40] summarizes the task-oriented GAN architectures developed for symbolic music generation, but other application domains are overlooked. The survey by Wang et al [41] reviews various architecture-variant and loss-variant GAN frameworks designed for addressing practical challenges relevant to CV tasks. Another survey by Gui et al [42] provides a comprehensive review of task-oriented GAN applications and showcases the theoretical properties of GAN and its variants. The study by Iglesias et al [43] summarizes the architecture of the latest GAN variants, optimization of the loss functions, and validation metrics in some promising application domains, including CV, language generation, and data augmentation. The survey by Li et al [44] reviews the theoretical advancements in GAN and provides an overview of GAN variants' mathematical and statistical properties. A detailed comparison between our survey and others is presented in table 1.
Table 1. Comparison of our survey and other related GAN surveys ( signifies 'Fully covered', signifies 'Partially covered', and signifies 'Not covered').
| Domain | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Theoretical | *Evaluation | Computer | Natural Language | Time | Urban | Imbalanced | ||||
| Year | Survey | insights | metrics | vision | processing | Music | Medical | series | planning | classification |
| 2019 | Kulkarni et al [36] | ❒ | ✘ | ✘ | ✘ | ✔ | ✘ | ✘ | ✘ | ✘ |
| 2021 | Jabbar et al [31] | ✔ | ✘ | ✔ | ✔ | ✔ | ✔ | ✘ | ✘ | ✘ |
| 2021 | Durgadevi et al [33] | ❒ | ✘ | ❒ | ❒ | ✘ | ❒ | ✘ | ✘ | ✘ |
| 2021 | Nandhini et al [35] | ✘ | ✘ | ✔ | ✘ | ✘ | ✘ | ✘ | ✘ | ✘ |
| 2021 | Wang et al [41] | ❒ | ✘ | ✔ | ✘ | ✘ | ✘ | ✘ | ✘ | ✘ |
| 2021 | Sampath et al [37] | ❒ | ✘ | ❒ | ✘ | ✘ | ✘ | ✘ | ✘ | ❒ |
| 2021 | Gui et al [42] | ✔ | ✔ | ✔ | ✔ | ❒ | ❒ | ✘ | ✘ | ✘ |
| 2021 | Li et al [44] | ✔ | ✔ | ❒ | ❒ | ✘ | ✘ | ✘ | ✘ | ✘ |
| 2022 | Xia et al [32] | ✔ | ✔ | ❒ | ✘ | ✘ | ✘ | ✘ | ✘ | ✘ |
| 2022 | Xun et al [39] | ❒ | ✘ | ✘ | ✘ | ✘ | ✔ | ✘ | ✘ | ✘ |
| 2023 | Ji et al [40] | ✘ | ✔ | ✘ | ✘ | ✔ | ✘ | ✘ | ✘ | ✘ |
| 2023 | Iglesias et al [43] | ❒ | ✔ | ✔ | ❒ | ✘ | ❒ | ✘ | ✘ | ❒ |
| 2023 | Brophy et al [38] | ✔ | ✔ | ✘ | ✘ | ✘ | ✘ | ✔ | ✘ | ✘ |
| 2023+ | Our survey | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ |
Although there are several papers reviewing GAN architecture and its domain-specific applications, none concurrently emphasize applications of GAN in geoscience, urban planning, data privacy, imbalanced learning, and time series problems in a comprehensive manner. Methods developed to deal with these practical problems are underrepresented in past surveys. Moreover, the stability of GAN training, assessment of the produced data, and ethical issues with GANs are some issues that still need to be resolved. More study in these areas is required to exploit the future potential of GANs fully. To fill the gap, this survey offers a comprehensive and up-to-date review of GANs, encompassing mainstream tasks ranging from audio, video, and image analysis to NLP, privacy, geophysics, and many more. Specifically, we provide several applied areas of GAN and discuss existing works from task and methodology-oriented perspectives. Then, we delve into multiple popular application sectors within the existing GAN research with their limitations and propose several potential future research directions. Our survey is intended for general machine learning practitioners interested in exploring and keeping abreast of the latest advancements in GAN for multi-purpose use. It is also suitable for domain experts applying GANs to new applications or exploring novel possibilities building on recent advances.
3. Overview of GAN
GANs signify a pivotal advancement in artificial intelligence (AI), offering a robust framework to craft synthetic data that closely resembles real-world information [45]. Consisting of two interconnected neural networks, the generator and discriminator, GANs engage in a dynamic adversarial process redefining the landscape of deep generative modeling [1, 46]. By orchestrating this interplay, GANs transcend data generation frontiers across various domains, from crafting images to generating language, demonstrating a profound influence on reshaping how machines comprehend and replicate intricate data distributions. This dynamic is facilitated through the generator (G) network, which produces new data samples based on the input data distribution. In contrast, the discriminator (D) network is devoted to discerning genuine data from their synthetic counterparts.
From a mathematical viewpoint, the G network considers a latent space z from the noise distribution pz as input and generates synthetic samples G(z). Its goal is to generate data that is indistinguishable from real data samples x originating from the probability distribution pdata. On the other hand, D takes both real data samples x from the actual dataset and fake data samples G(z) generated by G as input and classifies whether the input data is real or fake. It essentially acts as a 'critic' that evaluates the quality of the generated data. The training process consists of both networks working in a two-player zero-sum game [43]. While G aims to produce more realistic outcomes, D enhances its ability to distinguish between real and fake samples. This dynamic prompts both players to evolve in tandem: if G generates superior outputs, it becomes tougher for D to discern them. Conversely, if D becomes more accurate, G faces greater difficulty in deceiving D. This process resembles a minimax game, where D strives to maximize accuracy while G seeks to minimize it [47]. The goal is to find a balance where G produces increasingly convincing data while D becomes better at classifying real data from fake ones. The mathematical expression of this minimax loss function can be represented as:

where the probability values  and
and  represent the discriminator's outputs for real and fake samples, respectively. The first term in equation (1) encourages D to correctly classify real data by maximizing
represent the discriminator's outputs for real and fake samples, respectively. The first term in equation (1) encourages D to correctly classify real data by maximizing  , whereas the second term encourages G to produce realistic data that D classifies as real by minimizing
, whereas the second term encourages G to produce realistic data that D classifies as real by minimizing  . In essence, G aims to minimize the loss while D aims to maximize it, leading to a continual back-and-forth training process. Throughout the training, the generator's performance improves as it learns to generate more realistic data, and the discriminator's performance improves as it becomes better at distinguishing real from fake data. Ideally, this competition results in a generator that produces data that is virtually indistinguishable from real data, as judged by the discriminator. A visual representation of the GAN's architectural details and its primary functions is presented in figure 1.
. In essence, G aims to minimize the loss while D aims to maximize it, leading to a continual back-and-forth training process. Throughout the training, the generator's performance improves as it learns to generate more realistic data, and the discriminator's performance improves as it becomes better at distinguishing real from fake data. Ideally, this competition results in a generator that produces data that is virtually indistinguishable from real data, as judged by the discriminator. A visual representation of the GAN's architectural details and its primary functions is presented in figure 1.

Figure 1. Architecture of GANs and its primary functions. In this example, different analytical tasks of GANs are categorized into synthetic data generation, style transfer, data augmentation, and anomaly detection.
Download figure:
Standard image High-resolution imageDuring the inception of GAN in 2014, Goodfellow et al [1] proved the existence of a unique solution for the minimax loss function. This solution became popular as Nash equilibrium (NE), which reflects the equilibrium point where the generator's capacity to generate realistic data matches the discriminator's capacity to distinguish between real and fake data, resulting in high-quality synthetic data that closely resembles the true underlying data distribution [48]. However, recent studies have revealed that attaining NE in GANs is not guaranteed and can be challenging due to various factors, including architecture choices, hyperparameters, and convergence difficulties [49, 50]. Researchers have developed multiple techniques to address these challenges and enhance GAN's training stability, such as different loss functions and architectures over the decade [51]. These alterations of GAN include architectural changes, loss function-based modifications, and many others. They encompass various variations, each with unique attributes and applications, driving significant advancements in generative modeling. Figure 2 visually depicts the timeline of key developments in GAN research.
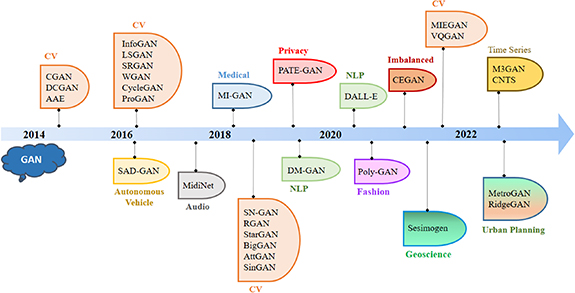
Figure 2. Timeline of the application-based GAN architectures reviewed in this study. In this figure, CV indicates the computer vision domain and NLP indicates the field of natural language processing.
Download figure:
Standard image High-resolution image4. Application
GANs have emerged as one of the most prominent advancements in machine learning over recent years. GAN models have demonstrated their efficacy in domains where prior models fell short while substantially enhancing performance in other scenarios. This section will comprehensively explore the pivotal domains where GAN architectures have been deployed. While much of the recent research has concentrated on employing GANs to generate novel synthesized data, emulating distinct data distributions, our exploration in this section will highlight the broader applications of GANs, extending to areas such as video game development [52], urban planning [10] and others. We also visually showcase the application domains of GAN in figure 3.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
Figure 3. Diverse applications of generative adversarial networks (GANs) in various applied domains.
Download figure:
Standard image High-resolution image{kind=link}
{kind=link}
4.1. Image generation
Among the most promising domains harnessing the capabilities of GANs is CV. Notably, the generation of realistic images stands as one of the paramount applications of GANs [6, 53]. The capacity of GANs to craft authentic images depicting characters, animals, and objects that lack real-world existence holds immense significance [54]. This capability of GAN finds application in diverse projects, from refining facial recognition algorithms to fabricating immersive virtual environments for video games and commercial campaigns [55]. Moreover, GANs have proven instrumental in generating true-to-life virtual realms, a boon for both gaming and advertising ventures. By crafting synthetic landscapes and structures, GANs empower game designers and developers to construct captivating, realistic virtual worlds, thereby elevating the overall player experience [5]. The deployment of GANs in this context offers a swift, cost-effective, and efficient alternative to traditional manual design and modeling approaches, enabling the production of high-quality graphics.
4.2. Video synthesis
In addition to generating high-quality images, GANs offer the potential to create synthetic videos, a more complex task due to coherence requirements [56]. GANs, combining generators and discriminators, excel in this challenge [57]. The discriminator learns to differentiate real from synthetic frames, while the generator produces visually authentic video frames. GANs find widespread use in replicating real-world actions, enhancing surveillance and animations [58]. One of GAN's most popular and controversial applications is the evolution of deepfake [59]. Deepfakes are AI-generated media that blend a person's likeness with another's context using GANs. While they offer creative potential, deepfakes raise ethical concerns, requiring a holistic approach to detect them [60, 61].
4.3. Augmenting data
GANs possess the capability to generate synthetic data, which can be harnessed to bolster actual data and enhance the performance of deep learning models. This approach is instrumental in mitigating concerns related to data scarcity and refining model accuracy [62]. GANs provide an effective avenue for fortifying machine learning and deep learning frameworks with authentic data. Addressing the challenge of limited data availability, GANs enable the creation of larger, more diverse datasets by generating artificial samples that closely emulate real data [63]. GAN-based data augmentation strategies have showcased promising outcomes across various domains, offering the potential to enhance model precision and transcend the constraints posed by insufficient data [64].
4.4. Style transfer
GANs can transfer the style of one image to another, creating an entirely new image [65]. This method can be applied to develop novel artistic features or enhance the visual attractiveness of pictures. By facilitating the development of fresh artistic trends and boosting the aesthetic appeal of images, GAN-based style transfer approaches have transformed the area of CV [3, 66]. These methods have been used in various fields, such as digital art, photography, and graphic design, and they continue to inspire new developments and studies in the area.
4.5. NLP
Over the past few years, GANs have been adapted to process text data, resulting in groundbreaking advancements within the realm of NLP. One notable application involves text generation, where GANs can create coherent and contextually relevant textual content. For instance, the text GAN framework utilizes long short-term memory networks [67] as the generator and CNN as the discriminator to synthesize novel text using adversarial training [68]. Furthermore, GANs play a role in text style transfer, allowing alterations in writing styles while preserving content and enhancing the adaptability of generated material [69]. In sentiment analysis, GANs generate text with specific emotional tones, thereby aiding model training and dataset augmentation for sentiment classification tasks. Additionally, GANs are instrumental in text-to-image synthesis, translating textual descriptions into visual representations, proving valuable in fields like accessibility and multimedia content creation [4]. GANs have also been harnessed to enhance machine translation software, refining translation precision and fluidity [26, 70].
4.6. Music generation
GANs are revolutionizing music creation by tapping into existing compositions' patterns and structures [71]. This technology fosters original music composition and assists musicians in their creative journey. Previous studies have showcased GANs' role in generating music, offering possibilities for novel designs and artist support [72, 73]. Beyond composition, GANs empower musicians to explore new styles by generating melodies, harmonies, and rhythms as creative sparks. They also enable style transfer, allowing musicians to reimagine their music in diverse genres and cultural contexts. Moreover, GANs have ventured into musical collaboration, aiding improvisation by responding to musicians' input with harmonious suggestions. In essence, GANs redefine music creation by assisting composers in originality and fostering innovative style exploration [74]. This fusion of human creativity and computational ability promises to shape the future of the music industry.
4.7. Medical domain
In the dynamic landscape of the medical domain, GANs have emerged as a game-changing technology with multifaceted benefits. Integrating GANs with medical data holds immense potential in enhancing disease diagnosis by creating synthetic medical images, thereby eliminating the problem of limited data. This expanding diversity and quantity of data made possible by GANs empower the data-driven diagnostic models to deliver more precise and reliable predictions, aiding healthcare practitioners in making accurate diagnoses and ultimately enhancing patient care [75–77]. Another significant application of GAN is in drug discovery, where it can process and generate molecular structures with desired properties [78, 79]. GAN-driven molecular generation accelerates the process of identifying potential drug candidates, saving time and resources in searching for novel therapeutic compounds. Moreover, GANs extend their impact to surgical training and planning by producing realistic surgical scenarios and simulations [80] and also aid in generating patient-specific medical images, allowing healthcare practitioners to tailor treatment plans to individual patient characteristics [81].
4.8. Urban planning
With rapid urbanization, predicting transportation patterns is essential for sustainable urban planning and traffic management. Recent advancements in GAN-based methods to simulate hyper-realistic urban patterns, including CityGAN [82], CGAN with physical constraints [83], and metropolitan GAN (MetroGAN) [84], have become popular in urban science fields. These GANs can generate synthetic urban universes that mimic global urban patterns, and quantifying landscape structures of these GAN-generated new cities using spatial pattern analysis helps to understand landscape dynamics and improve sustainable urban planning. In a recent study, a novel RidgeGAN model [10] is proposed that evaluates the sustainability of urban sprawl associated with infrastructure development and transportation systems in medium and small-sized cities.
4.9. Geoscience and remote sensing
In geoscience, there are also recent applications of GANs with novel ways of generating 'new' samples that can easily outperform state-of-the-art geostatistical tools. This is very appealing in applications like reservoir modeling, as geologists and reservoir engineers are usually tasked to work with multiple realizations of the subsurface and provide probabilistic estimates to support the subsequent decision-making process. A few examples of early applications of GANs in geoscience are the reconstruction of 3D porous media [85]; generating geologically realistic 3D reservoir facies models using deep learning of sedimentary architecture [86]; and SeismoGen: seismic waveform synthesis using GAN with application to seismic data augmentation [87].
4.10. Autonomous vehicles
Machine learning models for autonomous driving can be trained using synthetic pictures of real-world situations created using GANs. This method helps to mitigate the safety concerns of autonomous cars by getting beyond the restrictions of real-world testing [88]. A potential method for training autonomous driving models is using GANs to produce synthetic visuals [89]. It makes it possible to investigate a wide range of complex scenarios, improving the performance and safety of the models. Recent studies have illustrated the usefulness and promise of this method for bridging the gap between driving simulations and actual driving situations, ultimately promoting the development of autonomous cars [90, 91].
4.11. Fashion and design
GANs find utility in generating fresh patterns and designs for clothing, aiding designers in crafting innovative collections. This technology extends its impact on online shopping experiences by producing images of apparel on virtual models, offering customers a realistic preview of how garments would appear on them during online purchases [92]. Within fashion and design, GANs have become a valuable asset, empowering designers to stretch their creative boundaries by facilitating the creation of novel patterns and designs [93]. Furthermore, GAN-driven virtual try-on systems enhance the convenience of online shopping, granting shoppers lifelike insights into how clothing would fit and appear on them. Several diverse research efforts in this domain have explored the significant contributions of GAN in the evolution of the fashion and design industry [94, 95].
4.12. Imbalanced pattern classification
A prevalent yet intricate issue encountered in pattern recognition is referred to as 'class imbalance', signifying disparities in the frequencies of class labels [96]. To address this challenge, GANs can be used to generate synthetic data for the minority class of various imbalanced datasets as a method of intelligent oversampling [97]. Pioneering approaches such as balancing GAN [98] and classification enhancement GAN (CEGAN) [99] have been developed to restore balance in the distributions of imbalanced datasets and enhance the precision of the data-driven models.
4.13. Time series anomaly detection
In recent years, there has been a significant surge in the availability of real-time sensor data across diverse domains, including healthcare systems, power plants, industries, and many others. These vast datasets are often accompanied by several anomalous events, eventually diminishing the modeling capabilities of any machine learning and deep learning frameworks. To address this issue, anomaly detection for multivariate time series data has become critical for time series analysts [100]. In this context, GANs have become a powerful technology. In recent studies, various GAN-based time series anomaly detection techniques namely, dilated convolutional transformer GAN [101], M2GAN [102], cooperative network time series (CNTS) [103], time-series anomaly detection using generative adversarial networks (TADGAN) [104], and many others have been developed that leverage the power of adversarial training to detect the presence of anomalous data efficiently.
4.14. Data privacy
GANs offer the possibility of generating synthetic data that retains the original data's statistical characteristics while safeguarding sensitive information. This approach serves as a means to ensure privacy protection for individuals while enabling the secure utilization of data for research and analytical purposes [105]. A recent study by Torfi and Fox has demonstrated how GAN can be leveraged to generate synthetic data that mimics the statistical properties of the real dataset, thus preserving data privacy [106]. This development creates new opportunities for private data sharing and analysis, offering insightful information while maintaining privacy.
In conclusion, GANs have many applications across diverse domains, from generating realistic images and movies to aiding in medical diagnosis [1, 6]. The restrictions of data scarcity can be eliminated, and personal information can be safeguarded by developing synthetic data that closely resembles actual data [107]. As GANs develop further, we can witness more cutting-edge applications in real-data problems [23]. In summary, GANs offer a wide range of applications in various sectors and can completely change how we produce and use data [108, 109]. Future GAN applications will likely have even more fascinating uses as the technology develops toward generative AI [110].
5. Variants of GAN
In this section, we will have a broad review of some of the GAN models based on their distinct characteristics and practical uses. Additionally, we discuss the mathematical formulation of these GAN variants, using standard notations as discussed in section 3 and present their implementation software in table 2.
Table 2. Software links for the GANs.
CGAN. The CGAN is a popular version of GAN that generates data by considering external inputs, such as labels or classes. It was introduced by Mirza and Osindero in 2014 [2] and has since been widely used in CV applications, including image synthesis, image-to-image translation, and text-to-image synthesis. Unlike the conventional GAN, both G and D of the CGAN architecture receive conditional information y that serves as a guide for G to produce data that aligns with the specified conditions. The loss function for the CGAN framework is given by:

The CGAN model, as discussed in the literature [2, 134], possesses the following key features:
- CGANs generate customized data that is specific to a given input, e.g. a CGAN trained on animal photos can produce images of a particular animal based on the input.
- Unlike vanilla GAN, CGAN benefits from additional inputs, resulting in synthetic data of higher quality. It exhibits improved coherence, structure, and aesthetic resemblance to real samples.
- CGANs demonstrate superior noise resistance compared to other artificial neural networks due to the utilization of external input to guide the data generation process.
While the CGAN model is known for its versatility, it is also accompanied by several limitations. It is prone to overfitting with scarce or noisy input data, requires explicit labels or classes in the input dataset, is vulnerable to adversarial attacks, and becomes computationally complex with high-dimensional complex datasets [135, 136]. Considering both the advantages and disadvantages of the CGAN model mentioned above, it proves to be a valuable tool for generating data based on external input [137]. However, it is important to take into account these limitations and drawbacks when applying CGANs to address specific problems. Future research can examine alternative conditioning methods, including the use of natural language descriptions or a variety of circumstances [138].
DCGAN. DCGAN introduced by Radford et al in 2015 [23] marks a significant breakthrough in the realm of generative AI, particularly for image generation. Representing a specialized variation of the GAN architecture, DCGANs seamlessly combine CNN and GAN techniques to yield high-quality, photorealistic images with intricate details. With the ability to autonomously learn and generate images without additional control, DCGANs prove their usefulness in unsupervised learning scenarios. DCGANs stand out for their relatively manageable training process, owing to sophisticated architectural components like strided convolutions, batch normalization, and leaky rectified linear unit activation functions [23]. From the experimental perspective, DCGANs have generated excellent results for large-scale picture datasets like CIFAR-10 and ImageNet, [139]. Nonetheless, it is worth noting that DCGANs exhibit elevated computational demands, sensitivity to hyperparameters, and susceptibility to challenges such as restricted diversity of generated images and MC [140]. Despite these limitations, DCGANs find successful applications across domains encompassing image synthesis, style transfer, and image super-resolution. Their far-reaching impact on the field of generative modeling continues to inspire advancements and innovation.
Adversarial autoencoders (AAEs). AAE framework, proposed by Makhzani et al in 2015, is a hybridization of autoencoders with adversarial training [111]. This model has garnered significant attention due to its potential for variational inference by aligning the aggregated posterior of the hidden code vector with a chosen prior distribution. This approach ensures that meaningful outcomes emerge from various regions of the prior space. Consequently, the AAE's decoder acquires the capability to learn a sophisticated generative model, effectively mapping the imposed prior to the data distribution. AAEs produce disentangled representations, showcase noise resistance, and generate high-quality images. The components within the AAE framework offer notable advantages over alternative generative models. Through adversarial training, AAEs excel in capturing complex data distributions and generating detailed, high-quality images. Their ability to learn disentangled representations in separate latent dimensions empowers precise image control, encompassing alterations to object properties. AAEs exhibit resilience to input variations, making them valuable for noisy data scenarios. Their encoder–decoder design supports denoising and surpasses other models in semi-supervised classification [111]. However, like other generative models, AAEs can encounter MC, demand substantial computational resources, and necessitate cautious hyperparameter tuning. Striking the right balance between adversarial training and autoencoder loss poses a challenge. AAEs lack explicit control over generated samples, hindering targeted data traits in fine-grained control contexts [141]. Yet, the application scope of AAEs is notably expanded by the enhanced encoder, decoder, and discriminator networks, even surpassing traditional autoencoders.
InfoGAN. InfoGAN, a modification of GAN, is designed to learn disentangled representations of data by maximizing the mutual information between a subset of the generator's input and the generated output. It was introduced by Chen et al in 2016 [14]. The loss function formulation for the generator in InfoGAN is as follows:

where  is the mutual information between the generator's output G(z) and the learned latent code c, and λ is a hyperparameter that regulates the trade-off between the adversarial loss and the mutual information term. The information-theoretic approach employed in the InfoGAN framework enhances its ability to learn representations that facilitate data exploration, interpretation, and manipulation tasks. Unlike supervised methods, InfoGAN does not rely on explicit supervision or labeling, making it a flexible and scalable option for unsupervised learning tasks like image generation and data augmentation. However, the InfoGAN framework may struggle to learn meaningful and interpretable representations for high-dimensional complex datasets, and its benefits may not always justify the additional complexity and computational cost. Overall, InfoGAN shows promising results in learning disentangled representations, but its effectiveness depends on specific goals, data characteristics, and available resources [142]. Ongoing research and advancements hold the potential to address limitations and further improve this approach in the future.
is the mutual information between the generator's output G(z) and the learned latent code c, and λ is a hyperparameter that regulates the trade-off between the adversarial loss and the mutual information term. The information-theoretic approach employed in the InfoGAN framework enhances its ability to learn representations that facilitate data exploration, interpretation, and manipulation tasks. Unlike supervised methods, InfoGAN does not rely on explicit supervision or labeling, making it a flexible and scalable option for unsupervised learning tasks like image generation and data augmentation. However, the InfoGAN framework may struggle to learn meaningful and interpretable representations for high-dimensional complex datasets, and its benefits may not always justify the additional complexity and computational cost. Overall, InfoGAN shows promising results in learning disentangled representations, but its effectiveness depends on specific goals, data characteristics, and available resources [142]. Ongoing research and advancements hold the potential to address limitations and further improve this approach in the future.
Synthetic autonomous driving using GANs (SAD-GAN). The SAD-GAN model, introduced by Ghosh et al in 2016, is designed to generate synthetic driving scenes using the GAN approach [112]. This model's core concept involves training a controller trainer network using images and keypress data to replicate human learning. To create synthetic driving scenes, the SAD-GAN is trained on labeled data from a racing game, consisting of images portraying a driver's bike and its surroundings. A key press logger software is employed to capture key press data during bike rides. The framework's architecture is inspired by DCGAN [23]. The generator takes a current-time input image and produces the subsequent-time synthetic image. Meanwhile, the discriminator receives the real latest-time image, generates its feature map via convolution, and compares real and synthetic scenes to train the generator through a minimax game. The SAD-GAN framework offers an autonomous driving prediction algorithm suitable for manual driving as a recommendation system. Nevertheless, like DCGAN, it requires substantial computation and is susceptible to MC, limiting its real-time applications.
LSGAN. Traditional GAN models typically utilize a discriminator modeled as a classifier with the sigmoid cross entropy loss function. However, this loss function choice can result in vanishing gradients during training, resulting in impaired learning of the deep representations. To address this concern, Mao et al introduced a novel approach called least squares GAN (LSGAN) in 2017, which employs the least squares loss function for the discriminator instead [113]. Mathematically, the generator loss function  and the discriminator loss function
and the discriminator loss function  of LSGAN model is expressed as follows:
of LSGAN model is expressed as follows:

where a–b encoding scheme represents the labels for fake data and real data for D, and c denotes the values that G wants D to believe for fake data. The LSGAN framework represents a notable advancement over traditional GANs, offering improved stability and convergence during training while generating higher-quality synthetic data. It has outperformed regular GANs in generating realistic images, as measured by inception score (IS), across various datasets such as CIFAR-10 [113]. However, LSGANs often produce fuzzy images due to the use of squared loss in the objective function. The generated images often lack sharpness and fine details, as the loss function penalizes large discrepancies between fake and real images but neglects smaller variations. Researchers have addressed this issue by modifying the loss function in subsequent studies, aiming to enhance the sharpness of synthetic images [117, 143]. While LSGANs show promise in generating high-quality images, ongoing research and development are focused on overcoming their limitations in producing crisp and detailed results.
Super resolution GAN (SRGAN). SRGAN, introduced by Ledig et al in 2017, is a GAN-based framework for image super-resolution [114]. It generates high-resolution images from low-resolution inputs with an upscaling factor of 4 using a generator and discriminator networks. To achieve super-resolution, SRGAN incorporates a perceptual loss function, combining content and adversarial losses. Mathematically, the perceptual loss is expressed as:

where  represents the content loss and
represents the content loss and  is the adversarial loss. The content loss used in the SRGAN framework relies on a pre-trained VGG-19 model and it provides the network information regarding the quality and content of the generated image. On the other hand, the adversarial loss is responsible for ensuring the generation of realistic images from the generator network. SRGANs offer the ability to generate high-quality images with enhanced details and textures, resulting in improved overall image quality. They excel in producing visually appealing and realistic images, as confirmed by studies on perceptual quality [65]. SRGANs exhibit noise resistance, enabling them to handle low-quality or noisy input images while still delivering high-quality outputs [144]. Moreover, this model demonstrates flexibility and applicability across various domains, including video processing, medical imaging, and satellite imaging [114]. However, training SRGANs can be computationally expensive, especially for complex models or large datasets. Additionally, like other GANs, the interpretability of SRGANs can be challenging, making it difficult to understand the underlying learning process of the generator. Furthermore, while SRGANs excel in image synthesis, they may not perform as effectively with text or audio inputs, limiting their range of applications.
is the adversarial loss. The content loss used in the SRGAN framework relies on a pre-trained VGG-19 model and it provides the network information regarding the quality and content of the generated image. On the other hand, the adversarial loss is responsible for ensuring the generation of realistic images from the generator network. SRGANs offer the ability to generate high-quality images with enhanced details and textures, resulting in improved overall image quality. They excel in producing visually appealing and realistic images, as confirmed by studies on perceptual quality [65]. SRGANs exhibit noise resistance, enabling them to handle low-quality or noisy input images while still delivering high-quality outputs [144]. Moreover, this model demonstrates flexibility and applicability across various domains, including video processing, medical imaging, and satellite imaging [114]. However, training SRGANs can be computationally expensive, especially for complex models or large datasets. Additionally, like other GANs, the interpretability of SRGANs can be challenging, making it difficult to understand the underlying learning process of the generator. Furthermore, while SRGANs excel in image synthesis, they may not perform as effectively with text or audio inputs, limiting their range of applications.
WGAN. The WGAN was introduced by Arjovsky and Bottou in 2017 and is a loss function optimization variant of GAN that improves training stability and mitigates MC [15]. It employs the Wasserstein distance to enhance realistic sample generation and ensure meaningful gradients. By introducing a critic network and weight clipping, WGAN achieves training stability. It finds applications in image synthesis, style transfer, and data generation. The formulation of the WGAN framework utilizes the Wasserstein-1 distance or the Earth Mover distance to measure the distance between real and generated data distributions. Mathematically, the Wasserstein distance for transforming the distribution  to distribution
to distribution  can be expressed as:
can be expressed as:

In the WGAN model, the discriminator function D is designed as a critic network that estimates the Wasserstein distance between the real and generated data distribution instead of probability values as in conventional GAN. These scores reflect the degree of similarity or dissimilarity between the input sample and the real data distribution. The training of the critic in WGAN involves optimizing its parameters to maximize the difference in critic values between real and generated samples. By clipping the discriminator weights, the discriminator loss function in WGAN is adjusted to enforce the Lipschitz continuity requirement, but the fundamental structure of the loss functions is maintained. In general, WGANs have demonstrated improved training stability compared to traditional GANs. They are less sensitive to hyperparameters and more resistant to MC [117]. The use of the Wasserstein distance facilitates smoother optimization and better gradient flow, resulting in faster training and higher-quality samples. However, calculating the Wasserstein distance can be computationally expensive [145]. Although WGANs offer enhanced stability, careful tuning of hyperparameters and network designs is still necessary for satisfactory results. Furthermore, WGANs are primarily suited for generating images and may have limited applicability to other types of data. In summary, WGANs represent a promising advancement in the field of GANs, addressing their limitations and providing insights into distribution distances, but the applicability of WGANs to real-world problems requires careful consideration of its challenges.
CycleGAN. CycleGAN, introduced by Zhu et al in 2017, is an unsupervised image-to-image translation framework that eliminates the need for paired training data, unlike traditional GANs [3]. It relies on cycle consistency, allowing images to be translated between two domains using two generators and two discriminators while preserving coherence. One generator GXY
translates images from the source domain X to the target domain Y, and the other GYX
performs the reverse. In other words the function GYX
is such that  . On the other hand, the discriminators distinguish between real and translated images generated by the generators. To train this architecture, the cycle consistency loss of CycleGAN plays a crucial role by enforcing consistency between the original and round-trip translated images, the so-called forward and backward consistency. This ensures generators produce meaningful translations, preserving important content and characteristics across domains. Mathematically, the cycle consistency loss function can be expressed as:
. On the other hand, the discriminators distinguish between real and translated images generated by the generators. To train this architecture, the cycle consistency loss of CycleGAN plays a crucial role by enforcing consistency between the original and round-trip translated images, the so-called forward and backward consistency. This ensures generators produce meaningful translations, preserving important content and characteristics across domains. Mathematically, the cycle consistency loss function can be expressed as:

The main advantage of CycleGAN lies in its ability to produce high-quality images with remarkable visual fidelity. It excels in various image-to-image translation tasks, including style transfer, colorization, and object transformation. Moreover, its computational efficiency allows training on large datasets. However, CycleGAN often suffers from MC and the increasing amount of parameters reduces its efficiency [146]. Despite its limitations, CycleGAN remains a valuable tool for image translation, and ongoing research for any data translation task aims to address its shortcomings [147]. For example, it shows promising results in medical imaging domain adaptation [148].
ProGAN. In 2017, Karras et al introduced the ProGAN, addressing the limitations of traditional GANs, such as training instability and low-resolution output [5]. ProGAN utilizes a progressive growth technique, gradually increasing the size and complexity of the generator and discriminator networks during training. This incremental approach enables the model to learn coarse characteristics and refine them, producing high-resolution images. By starting with low-resolution image generation and progressively adding layers and details, ProGAN achieves training stability and generates visually realistic images of superior quality. This technique has found successful applications in various domains, including image synthesis, super-resolution, and style transfer. During training, the resolution of the generated images is increased progressively from a low resolution (e.g.  ) to a high resolution (e.g.
) to a high resolution (e.g.  ). At each resolution level, the generator and discriminator networks are updated using a combination of loss functions. Unlike the conventional GAN framework, progressive updates at increasing resolutions ensure high-quality image synthesis with fine features and textures throughout training. ProGAN offers better scalability, enabling the generation of images at any resolution. It exhibits improved stability during training, overcoming issues like MC. The flexibility of ProGAN makes it suitable for various image synthesis applications, including satellite imaging, video processing, and medical imaging [5]. However, training ProGAN can be computationally expensive, especially for large datasets or complex models. Interpretability may pose challenges, as with other GANs, making it difficult to discern the learned representations. Additionally, ProGAN's generalization to new or unexplored data may be limited, requiring further fine-tuning or training on fresh datasets [149].
). At each resolution level, the generator and discriminator networks are updated using a combination of loss functions. Unlike the conventional GAN framework, progressive updates at increasing resolutions ensure high-quality image synthesis with fine features and textures throughout training. ProGAN offers better scalability, enabling the generation of images at any resolution. It exhibits improved stability during training, overcoming issues like MC. The flexibility of ProGAN makes it suitable for various image synthesis applications, including satellite imaging, video processing, and medical imaging [5]. However, training ProGAN can be computationally expensive, especially for large datasets or complex models. Interpretability may pose challenges, as with other GANs, making it difficult to discern the learned representations. Additionally, ProGAN's generalization to new or unexplored data may be limited, requiring further fine-tuning or training on fresh datasets [149].
MidiNet. MidiNet, proposed by Yang et al in 2017, attempts to generate melodies or a series of musical instrument digital interface (MIDI) notes in the symbolic domain [8]. Unlike other music generation frameworks, such as WaveNet [150] and Song from physics-informed (PI) [151], the MidiNet model can generate melodies either from scratch or by combining the melodies of previous bars. The architectural configuration of the MidiNet framework is motivated by the DCGAN model [23]. The MidiNet model combines a CNN generator with a conditioner CNN in the first phase of training. While the former CNN is employed to generate synthetic melodies based on the random noise vector, the latter provides the available prior knowledge about other melodies in the form of an encoded vector as an optional input to the generator. Once the melody is generated, it is processed with a CNN-based discriminator, which consists of a few convolutional layers and a fully connected network. The discriminator is optimized using a cross-entropy loss function to efficiently detect whether the input is real or generated ones. For training the overall network in MidiNet, the minimax loss function is combined with feature mapping and one-sided label smoothing to ensure learning stability and versatility in the generated content. The MidiNet framework proposes a unique CNN-GAN structure for the generation of symbolic melodies. Its ability to synthesize artificial music in the presence or absence of prior knowledge is very useful in the audio domain. However, due to the use of a CNN-based structure, its computational complexity significantly increases in comparison to the standard GAN model. Further research in this domain is required to understand the capabilities of MidiNet in multi-track music generation while simultaneously reducing its running time.
Spectral normalization GAN (SN-GAN). SN-GAN is a GAN variant that utilizes spectral normalization to stabilize the training of the generator and discriminator networks [119]. In conventional GANs, training can be unstable due to a powerful discriminator or poor-quality generator samples. SN-GAN addresses this by constraining the Lipschitz constant of the discriminator, preventing it from dominating the training process. Spectral normalization normalizes the discriminator's weight matrices, ensuring a stable maximum value and preventing the amplification of minor input perturbations. SN-GAN produces high-quality samples with improved stability and convergence compared to traditional GANs. The adversarial training process used in the SN-GAN framework, similar to the conventional GAN (as in equation (1)), encourages G to produce more realistic samples that can fool D, while D learns to accurately distinguish between real and generated samples. Several benefits of the SN-GAN model over the standard GAN include increased stability in training the generator and discriminator by constraining the Lipschitz constant of the discriminator. This mitigates issues like gradient explosion and MC, resulting in high-quality examples with fine features and edges. SN-GAN is relatively simple to implement and can be integrated into existing GAN systems. However, the computation of singular values during the normalization process adds to the computational burden, potentially extending training time and requiring more memory. SN-GAN's reliance on the spectral norm assumption of discriminator weights may limit its applicability to specific GAN architectures. While SN-GANs may exhibit slower convergence and reduced sample diversity compared to conventional GANs, they excel in stability and sample quality.
Relativistic GAN (RGAN). RGAN introduces a relativistic discriminator to enhance the stability and quality of GAN-generated samples [120]. Unlike traditional GANs, where the discriminator determines if a sample is real or fake, the RGAN discriminator estimates the probability that a genuine sample is more realistic than a fake sample and vice versa. It compares the likelihood of a true sample being real with the likelihood of a fake sample being real. This approach guides the generator to produce more realistic samples than the discriminator's current estimates for both real and fake samples. To ensure this relativistic nature of RGAN, samples are considered from both real and fake data pairs  , where
, where  represents the real data and
represents the real data and  symbolize its fake counterpart. Mathematically, the generator and discriminator loss functions of the RGAN framework can be expressed as:
symbolize its fake counterpart. Mathematically, the generator and discriminator loss functions of the RGAN framework can be expressed as:

where  is the non-transformed layer and
is the non-transformed layer and  are scalar-to-scalar functions. The term
are scalar-to-scalar functions. The term  of the modified loss function can be interpreted as the likelihood that the given fake data is more realistic than randomly sampled real data. The relativistic discriminator in RGAN enhances stability by mitigating issues like MC and vanishing gradients, commonly observed in conventional GANs [120]. RGAN surpasses regular GANs in generating high-quality samples. It also exhibits improved resilience against adversarial attacks, ensuring sample security. However, these advantages come at the expense of higher computational requirements compared to regular GANs owing to the use of relativistic discriminator [145]. Additionally, RGAN necessitates careful hyperparameter tuning, including learning rate and regularization parameters, for optimal performance [152–154]. Furthermore, the efficacy of RGAN depends on the specific use case, limiting its universal applicability.
of the modified loss function can be interpreted as the likelihood that the given fake data is more realistic than randomly sampled real data. The relativistic discriminator in RGAN enhances stability by mitigating issues like MC and vanishing gradients, commonly observed in conventional GANs [120]. RGAN surpasses regular GANs in generating high-quality samples. It also exhibits improved resilience against adversarial attacks, ensuring sample security. However, these advantages come at the expense of higher computational requirements compared to regular GANs owing to the use of relativistic discriminator [145]. Additionally, RGAN necessitates careful hyperparameter tuning, including learning rate and regularization parameters, for optimal performance [152–154]. Furthermore, the efficacy of RGAN depends on the specific use case, limiting its universal applicability.
StarGAN. StarGAN, a type of GAN model introduced in the work of Choi et al [122], is specifically designed for multi-domain image-to-image translations. In contrast to the CycleGAN model [3] that focuses on translating images between two specific domains, StarGAN offers the capability to perform translations across a diverse range of domains using a single generator and discriminator. This model trains the generator network G to map the input image x to an output image y conditioned on the randomly generated target domain label c i.e.  . In the case of the discriminator network D, an additional classifier is used to produce the probability distribution for both source and domain labels
. In the case of the discriminator network D, an additional classifier is used to produce the probability distribution for both source and domain labels  . To ensure an efficient multi-domain image translation, this framework utilizes several loss functions, namely the adversarial loss, the domain classification loss, and the reconstruction loss. The conventional adversarial loss ensures the generation of high-quality realistic images. The domain classification loss of real images optimizes D to accurately classify x to their input domain label cʹ, whereas the domain classification loss of fake images optimizes G to generate images that can be classified as the generated target domain c. Overall, the domain classification loss ensures the coherent multi-domain image classification in the StarGAN model. Furthermore, to ensure that the translated images retain the characteristics of the input image and exclusively modify the domain-related features, a reconstruction loss is used in training the generator network. The overall objective function of the StarGAN model is mathematically expressed as:
. To ensure an efficient multi-domain image translation, this framework utilizes several loss functions, namely the adversarial loss, the domain classification loss, and the reconstruction loss. The conventional adversarial loss ensures the generation of high-quality realistic images. The domain classification loss of real images optimizes D to accurately classify x to their input domain label cʹ, whereas the domain classification loss of fake images optimizes G to generate images that can be classified as the generated target domain c. Overall, the domain classification loss ensures the coherent multi-domain image classification in the StarGAN model. Furthermore, to ensure that the translated images retain the characteristics of the input image and exclusively modify the domain-related features, a reconstruction loss is used in training the generator network. The overall objective function of the StarGAN model is mathematically expressed as:

where λ1 and λ2 are the hyper-parameters that control the effect of the domain classification loss and the reconstruction loss in the StarGAN model, respectively. The training process involves iteratively optimizing the components of the loss functions to achieve high-quality multi-domain image-to-image translations. The StarGAN framework offers several advantages in multi-domain image translation tasks. It utilizes a single generator-discriminator network for all domains, reducing computational complexity. StarGAN can effectively learn domain mappings with limited or unpaired data and preserve the identity of input images in the same target domain. However, it has several drawbacks, including a complex loss function that leads to a time-consuming training process [155, 156]. Additionally, regulating image quality and handling translations between complex domains with significant appearance or structural changes can be challenging in StarGAN [157]. Moreover, this model can be used to manipulate images to a considerable extent which might lead to ethical concerns [158].
BigGAN. BigGAN, introduced by Brock et al in 2018, is an innovative methodology for training GAN on a large scale to achieve a high-quality synthesis of natural images [110]. It aims to address the challenge of generating high-quality images with high resolutions, which traditional GANs struggle to achieve [32]. BigGAN stands out by employing large-scale architecture and a unique truncation technique that allows for the generation of high-fidelity images with intricate details and textures. The model is capable of producing images of various resolutions, reaching up to  pixels, and has been trained on a substantial dataset of images. Similar to GAN (as in equation (1)), during the training of the BigGAN model, gradient descent techniques are used to update the parameters of G and D. The discriminator aims to maximize the objective, while the generator aims to minimize it. BigGAN introduces architectural modifications to enhance image quality and diversity. It incorporates class-CGANs and self-attention mechanisms. Regularization techniques like orthogonal regularization and truncation tricks stabilize and control the generator's output. Data augmentation methods, such as progressive resizing and interpolation, are employed to handle high-resolution images effectively. The modified training approach in the BigGAN architecture enables the generation of high-quality images with detailed features and textures, surpassing the capabilities of regular GANs. This enhanced model offers scalability, addresses MC issues, and has broad applications in fields such as video processing, satellite imaging, and medical imaging. However, it is computationally demanding, especially when dealing with large datasets or complex models [159, 160]. Additionally, the generalization of the framework to new, unseen data is limited, requiring further fine-tuning or training on fresh datasets [161].
pixels, and has been trained on a substantial dataset of images. Similar to GAN (as in equation (1)), during the training of the BigGAN model, gradient descent techniques are used to update the parameters of G and D. The discriminator aims to maximize the objective, while the generator aims to minimize it. BigGAN introduces architectural modifications to enhance image quality and diversity. It incorporates class-CGANs and self-attention mechanisms. Regularization techniques like orthogonal regularization and truncation tricks stabilize and control the generator's output. Data augmentation methods, such as progressive resizing and interpolation, are employed to handle high-resolution images effectively. The modified training approach in the BigGAN architecture enables the generation of high-quality images with detailed features and textures, surpassing the capabilities of regular GANs. This enhanced model offers scalability, addresses MC issues, and has broad applications in fields such as video processing, satellite imaging, and medical imaging. However, it is computationally demanding, especially when dealing with large datasets or complex models [159, 160]. Additionally, the generalization of the framework to new, unseen data is limited, requiring further fine-tuning or training on fresh datasets [161].
Medical imaging GAN (MI-GAN). In the field of deep learning, constrained data sizes within the medical domain pose a significant challenge for supervised learning tasks, elevating concerns about overfitting. To address this, Iqbal and Ali introduced MI-GAN in 2018, an innovative GAN framework tailored for medical imaging [123]. MI-GAN is specialized in generating synthetic retinal vessel images along with segmented masks based on limited input data. The architecture of the MI-GAN framework's generator network adopts an encoder–decoder structure. Given a random noise vector, the encoder functions as a feature extractor, capturing local and global data representations through its fully connected neural network design. These learned representations are then channeled into the decoder using skip connections, facilitating the generation of segmented images. The generator's enhancements encompass the integration of global standard segmented images and style transfer mechanisms, refining the segmented image generation process. Consequently, the modified MI-GAN generator is trained using a blend of adversarial, segmentation, and style transfer loss functions. In contrast, the discriminator network within the MI-GAN model consists of multiple convolutional layers, and it is trained using adversarial loss functions to effectively distinguish between real and generated images. MI-GAN refines the CGAN model for retinal image synthesis and segmentation. Remarkably, despite being trained with a mere ten real examples, this model holds tremendous potential in medical image generation. Nonetheless, this approach relies on spatial alignment to achieve superior outcomes, which can often be scarce [162].
AttGAN. AttGAN, also known as attribute GAN, is a variation of the GAN framework that focuses on generating images with customizable properties such as age, gender, and expression. It was introduced by He et al in 2019 in their work 'AttGAN: Facial Attribute Editing by Only Changing What You Want' [124]. AttGAN aims to allow users to modify specific facial attributes while preserving the overall identity and appearance of the face. By manipulating attribute vectors, users can control the desired changes in the facial attributes, resulting in realistic and visually appealing image transformations. The AttGAN framework combines two subnetworks an encoder GEnc and a decoder GDec in place of G of conventional GAN and it utilizes an attribute classifier C with the discriminator network. During the training phase, given an input image  with a set of n-dimensional binary attribute
with a set of n-dimensional binary attribute  , GEnc encodes
, GEnc encodes  into a latent vector representation i.e.
into a latent vector representation i.e.  . Simultaneously, GDec is employed for editing the attributes of
. Simultaneously, GDec is employed for editing the attributes of  to another set of n-dimensional attributes
to another set of n-dimensional attributes  i.e. the edited image
i.e. the edited image  is constructed as
is constructed as  . To perform this unsupervised learning task, C is used with the encoder–decoder pair to constrain
. To perform this unsupervised learning task, C is used with the encoder–decoder pair to constrain  to possess the desired qualities. Moreover, the adversarial loss used in the training process ensures realistic image generation. On the other hand, a reconstruction loss is utilized in the framework to allow for satisfactory preservation of attributes, excluding details in the network. This loss ensures that the interaction between the latent vector s with attribute
to possess the desired qualities. Moreover, the adversarial loss used in the training process ensures realistic image generation. On the other hand, a reconstruction loss is utilized in the framework to allow for satisfactory preservation of attributes, excluding details in the network. This loss ensures that the interaction between the latent vector s with attribute  will always produce
will always produce  and the interaction between s with attribute
and the interaction between s with attribute  will always produce
will always produce  , approximating the input image
, approximating the input image  . Thus the overall loss function for the encoder–decoder-based generator of AttGAN can be expressed as:
. Thus the overall loss function for the encoder–decoder-based generator of AttGAN can be expressed as:

and the loss for the classifier and the discriminator is formulated as:

where  is the cross entropy loss, and
is the cross entropy loss, and  are hyperparameters for balancing the losses. AttGAN offers several benefits in the image generation domain, including precise control over the attributes of generated images, allowing users to modify age, gender, expression, and other qualities. It provides flexibility by adapting to multiple domains and tasks, enabling customization and flexibility in image synthesis applications. The model produces realistic images that approximate the desired attributes while maintaining the visual aspects of the original image. However, ethical considerations regarding representation, identity, and privacy must be addressed when using AttGAN or similar models [17, 163]. The computational complexity of AttGAN requires significant resources and may pose challenges for deployment in production settings or on resource-limited devices. Additionally, AttGAN relies on labeled data with attribute annotations, which may not always be readily available. The model's performance and generalizability can be influenced by the quantity and quality of the attribute annotations [164]. The distribution and diversity of the training data can also impact the model's performance and ability to handle uncommon or out-of-distribution features [165]. In conclusion, AttGAN provides precise attribute control, flexibility, and realistic image generation capabilities, but careful ethical considerations, resource requirements, and data dependencies should be taken into account when utilizing the model in practical applications.
are hyperparameters for balancing the losses. AttGAN offers several benefits in the image generation domain, including precise control over the attributes of generated images, allowing users to modify age, gender, expression, and other qualities. It provides flexibility by adapting to multiple domains and tasks, enabling customization and flexibility in image synthesis applications. The model produces realistic images that approximate the desired attributes while maintaining the visual aspects of the original image. However, ethical considerations regarding representation, identity, and privacy must be addressed when using AttGAN or similar models [17, 163]. The computational complexity of AttGAN requires significant resources and may pose challenges for deployment in production settings or on resource-limited devices. Additionally, AttGAN relies on labeled data with attribute annotations, which may not always be readily available. The model's performance and generalizability can be influenced by the quantity and quality of the attribute annotations [164]. The distribution and diversity of the training data can also impact the model's performance and ability to handle uncommon or out-of-distribution features [165]. In conclusion, AttGAN provides precise attribute control, flexibility, and realistic image generation capabilities, but careful ethical considerations, resource requirements, and data dependencies should be taken into account when utilizing the model in practical applications.
Dynamic memory GAN (DM-GAN). The DM-GAN introduced by Zhu et al in 2019 combines the power of GANs with a memory-augmented neural network design to overcome the limitations of conventional GANs [127, 166]. By addressing issues like MC and lack of fine-grained control, DM-GAN aims to improve the image synthesis process. This deep learning model focuses on generating realistic images from text descriptions, tackling two main challenges in existing methods. Firstly, it addresses the impact of initial image quality on the refinement process, ensuring satisfactory results. Secondly, DM-GAN considers the importance of each word in conveying image content by incorporating a dynamic memory module. The two-stage training of the DM-GAN framework initially transforms the textual description into an internal representation using a text encoder and a deep generator model is utilized to generate an initial image based on the encoded text and random noise. In the subsequent dynamic memory-based image refinement step, the generated fuzzy image is processed using a memory writing gate to select relevant text information based on the initial image content and a response gate to fuse information from memories and image features. These advancements enable DM-GAN to generate high-quality images from text descriptions accurately. The dynamic memory module of DM-GAN enhances image generation by capturing long-range relationships and maintaining global context, resulting in persuasive and visually appealing images. It provides fine-grained control over attribute-guided synthesis and increases diversity by addressing MC. However, DM-GAN's computational complexity and memory management pose challenges, and it relies on labeled data [167, 168]. The model's interpretability is limited due to the complexity of the memory module [169, 170]. In conclusion, DM-GAN offers enhanced image generation capabilities with control, diversity, and robustness, while considerations such as computational resources, data availability, and interpretability should be considered.
Single-image GAN (SinGAN)). SinGAN is an unconditional generative model introduced by Shaham, et al in 2019 for learning the internal statistics from a single image without the need for additional training data [128]. SinGAN allows for a wide range of image synthesis and manipulation tasks, including animation, editing, harmonization, and super-resolution, among many others. The key innovation of SinGAN is the use of a multi-scale pyramid of GANs, where each GAN is responsible for generating images at a different scale. This hierarchical structure enables SinGAN to capture both the global and local characteristics of the input image, resulting in high-quality and coherent output images. By training on a single image, SinGAN eliminates the need for a large dataset, making it a versatile and practical tool for image generation tasks. During the training phase of SinGAN, a hierarchical structure called the multi-scale pyramid is utilized. This pyramid consists of a series of generators denoted as  . The generators take input patches of the image at different downsampled levels, represented as
. The generators take input patches of the image at different downsampled levels, represented as  , where each level is downsampled by a factor of rn
(r > 1). The generators, along with their corresponding discriminators Dn
, are trained using adversarial training. The goal is to generate realistic samples that cannot be distinguished from the downsampled image xn
. The SinGAN architecture consists of five convolutional blocks in both Gn
and Dn
networks. Each block consists of a
, where each level is downsampled by a factor of rn
(r > 1). The generators, along with their corresponding discriminators Dn
, are trained using adversarial training. The goal is to generate realistic samples that cannot be distinguished from the downsampled image xn
. The SinGAN architecture consists of five convolutional blocks in both Gn
and Dn
networks. Each block consists of a  convolutional layer with 32 kernels, followed by batch normalization and LeakyReLU activation. The patch size for the discriminator remains fixed at
convolutional layer with 32 kernels, followed by batch normalization and LeakyReLU activation. The patch size for the discriminator remains fixed at  across all pyramid levels. During training, the generator and discriminator networks are iteratively updated to optimize a combination of adversarial loss and reconstruction loss. As the training progresses to higher pyramid levels, the generator incorporates the output from the previous level, enabling it to capture finer details and generate more realistic images. To enhance the model's ability to handle diverse variations, noise injection is introduced during training, where random noise patterns are added to the input image at each scale. This helps in generating diverse outputs. The training process continues until convergence, where the generator is capable of synthesizing images that closely resemble the training image at all scales of the pyramid. SinGAN offers numerous advantages in image manipulation tasks, requiring minimal data. It enables controlled alteration, synthesis, and modification of images, allowing users to adjust lighting, colors, textures, and objects. The model produces aesthetically realistic and visually consistent results that align with the input image. Its multi-stage training process captures global and local characteristics, resulting in high-quality outputs. However, SinGAN lacks explicit control over specific image traits and quality depends on input image quality and quantity [171]. Ethical considerations should be addressed, and the model is computationally complex with limited interpretability [172]. Nevertheless, SinGAN's multi-stage training has gained popularity due to its versatility and the powerful image generation capabilities it offers.
across all pyramid levels. During training, the generator and discriminator networks are iteratively updated to optimize a combination of adversarial loss and reconstruction loss. As the training progresses to higher pyramid levels, the generator incorporates the output from the previous level, enabling it to capture finer details and generate more realistic images. To enhance the model's ability to handle diverse variations, noise injection is introduced during training, where random noise patterns are added to the input image at each scale. This helps in generating diverse outputs. The training process continues until convergence, where the generator is capable of synthesizing images that closely resemble the training image at all scales of the pyramid. SinGAN offers numerous advantages in image manipulation tasks, requiring minimal data. It enables controlled alteration, synthesis, and modification of images, allowing users to adjust lighting, colors, textures, and objects. The model produces aesthetically realistic and visually consistent results that align with the input image. Its multi-stage training process captures global and local characteristics, resulting in high-quality outputs. However, SinGAN lacks explicit control over specific image traits and quality depends on input image quality and quantity [171]. Ethical considerations should be addressed, and the model is computationally complex with limited interpretability [172]. Nevertheless, SinGAN's multi-stage training has gained popularity due to its versatility and the powerful image generation capabilities it offers.
Private aggregation of teacher ensembles GAN (PATE-GAN). In our data-centric world, safeguarding data privacy is paramount, ensuring the protection of individual rights, ethical data handling, and establishing a reliable digital environment. It ensures a harmonious blend of leveraging the benefits of data-driven technologies while respecting individual's autonomy and rights. To uphold these concerns and to enable the ethical usage of real-world data in various machine-learning frameworks, Jordan et al in 2019 proposed the PATE-GAN framework [126]. Combining the differential privacy principles of PATE with the generative prowess of GANs, PATE-GAN generates synthetic data for training algorithms while aiming for a positive societal impact. Similar to the conventional GAN model, PATE-GAN comprises of a generator network that receives a latent vector as input and provides generated data as an output. However, in the discriminator aspect, PATE-GAN innovatively integrates the PATE mechanism involving multiple teacher discriminators and a single student discriminator. The teacher discriminators classify real and generated samples within their dataset segments, while the student discriminator employs the labels aggregated from the teacher discriminators to classify generated samples. The framework's training employs an asymmetric adversarial process, where teachers aim to enhance their loss relative to the generator, the generator targets the student's loss, and the student seeks to optimize its loss against the teachers. This arrangement with the student discriminator ensures differential privacy concerning the original dataset.
POLY-GAN. Introduced by Pandey and Savakis in 2020, Poly-GAN is a novel CGAN architecture aimed at fashion synthesis [95]. This architecture is designed to automatically dress human model images in diverse poses with different clothing items. Poly-GAN employs an encoder-decoder structure with skip connections for tasks like image alignment, stitching, and inpainting. The training procedure of the Poly-GAN framework consists of four steps. This model takes input images, including a reference garment and a model image for clothing placement. Initially, pre-processing involves using a pre-trained localization-classification-regression (LCR)-Net++ pose estimator [173] to extract the model's pose skeleton and a U-Net++ segmentation network [144, 174] to obtain the segmented mask of the old garment from the model image. The Poly-GAN pipeline begins by passing the reference garment and generated RGB pose skeleton through the generator to create a garment image that aligns with the skeleton's shape. The architecture of G follows an encoder–decoder structure. The encoder incorporates three components: a Conv module for propagating pose skeleton information at each layer, a ResNet module for generating a feature vector [175], and a Conv-norm module with two convolutional layers to process the other two modules' outputs. On the other hand, the decoder learns to produce the desired garment image based on pose condition embedding sent by the encoder using skip connections. The transformed garment image and segmented pose skeleton are sent as inputs to the second stage of the network for image stitching, yielding an image of the pose skeleton with the reference attire. In the third stage, the model performs inpainting to eliminate any irregularities in the generated model image. The discriminator, similar in structure to SR-GAN [114], is employed during these stages to differentiate real from fake images. Finally, in the fourth stage, post-processing is applied, stitching the model's head to the image to produce the final output. The Poly-GAN framework utilizes adversarial, GAN, and identity losses for training, ensuring high image quality and minimizing texture and color discrepancies from real images. Poly-GAN presents an advancement in fashion synthesis compared to other models [176], as it operates with multiple conditional inputs and achieves satisfactory fitting results without requiring 3D model information [177]. However, the generated images can exhibit texture deformation and body part loss, affecting the fitting outcomes [178]. Further research is needed to address these issues in this domain.
Mobile image enhancement GAN (MIEGAN). MIEGAN, introduced by Pan et al in 2021, is a novel approach within the realm of GAN-based architectures, with the primary objective of elevating the visual caliber of images taken via mobile devices [129]. This endeavor involves several modifications to the conventional GAN architecture. The MIEGAN model utilizes a multi-module cascade generative network, which combines an autoencoder and a feature transformer. The encoder of this modified generator comprises of two streams, with the second stream being responsible for enhancing the regions with low luminance—a common issue in mobile photography leading to reduced clarity. In the feature transformative module, the local and global information of the image is further captured using a dual network structure. Furthermore, to enhance the generative network's ability to produce images of superior visual quality, an adaptive multi-scale discriminator is employed in lieu of a standard single discriminator in the MIEGAN model. This multi-scale discriminator serves to differentiate between real and fake images on both global and local scales. An adaptable weight allocation strategy is utilized in the discriminator to harmonize the evaluations from the global and local discriminators. Additionally, this model is trained based on a contrast loss mechanism and a mixed loss function, further enhancing the generated images' visual quality. Despite the image quality enhancement capabilities of the MIEGAN framework, their high computation complexity poses a significant challenge for their real-time application in mobile photography.
Vector quantized GAN (VQGAN). VQGAN introduces a novel methodology that merges the capabilities of GAN with vector quantization techniques to generate high-quality images [130]. This approach effectively leverages the synergies between the localized interactions of CNN and the extended interactions of transformers [19] in tasks involving the conditional synthesis of data. The distinctive architecture of VQGAN not only yields images of exceptional quality but also empowers a degree of creative influence, enabling the manipulation of various attributes within the generated content. The training process of the VQGAN architecture unfolds in two pivotal phases. Initially, a variational autoencoder and decoder are trained, as opposed to the conventional GAN generator network. This training aims to reconstruct the image by utilizing a discrete latent vector representation derived from the input image. This intermediate representation is subsequently linked to a codebook, efficiently capturing the underlying semantic information. To augment the fidelity of the reconstructed image, a discriminator is incorporated into the autoencoder structure. The training of the autoencoder model, the codebook, and the discriminator involves optimizing a fusion of adversarial loss and perceptual loss functions. In the subsequent phase, the codebook indices, constituting the intermediate image representations, are fed into transformers. These transformers are trained through a transformer loss mechanism, guiding them to predict the succeeding indices within the encoded sequence, resulting in an improved codebook representation. Finally, the decoder utilizes the information from the codebook to generate images of higher resolutions. The unique aspect of VQGAN lies in its ability to allow users to manipulate generated images in creative ways. By modifying the quantized codes, users can control specific features of the generated content, thereby unlocking a spectrum of artistic potentials. Nonetheless, the caliber of the images generated by VQGAN depends largely on its input data, necessitating expansive datasets and substantial computational resources to produce images of exceptional excellence [179]. Consequently, this restricts its immediate applicability in real-time case studies. Moreover, the codebook representation used in the vector quantization process can significantly reduce the variation in the generated images [180].
DALL-E. DALL-E is an advanced text-to-image generative framework created by OpenAI that utilizes a two-stage process to generate images from textual prompts [132, 133]. It combines the concepts of GANs and transformers to generate highly realistic and coherent images from textual descriptions. What sets DALL-E apart is its ability to generate realistic art and images from textual descriptions that may describe completely novel concepts or objects. The working principle of the pre-trained DALL-E model comprises of two phases. The first stage involves a prior model that generates a contrastive language-image pretraining (CLIP) [181] image embedding, capturing the essential gist of the image based on the provided caption. In the second stage, a decoder model known as GLIDE takes the image embedding and reconstructs the image itself, gradually removing noise and generating a realistic and visually coherent image. The CLIP model, consisting of a text encoder and an image encoder, is trained using contrastive training to learn the relationship between images and their corresponding captions. This allows the model to generate the CLIP text embedding from the input caption. Further, the prior model of DALL-E processes this text representation to generate the CLIP image embedding. In the case of the decoder, DALL-E utilizes a diffusion model [22], which generates the image by using CLIP image embedding and the CLIP text embedding as an additional input. DALL-E's two-stage process offers advantages in prioritizing high-level semantics and enabling intuitive transformations. It excels in generating creative and imaginative images based on textual descriptions, making it valuable for creative tasks. However, training DALL-E requires substantial computational resources and presents challenges in fine-tuning and attribute control. Ethical concerns and biases surrounding AI-generated content also arise [182, 183]. Moreover, the lack of interpretability and explainability of this framework restricts its applications in legal, medical, or safety-sensitive domains [184]. Nevertheless, DALL-E represents a significant advancement in image synthesis and has garnered attention for its creative potential. Ongoing research, such as DALL-E 2 [185], continues to push the boundaries of this field and attempts to mitigate the explainability concerns [186].
CEGAN. Class imbalance is a prevalent challenge across many real-world datasets. In the context of classification tasks, this skewed distribution of classes leads to a significant bias favoring the majority class. Previous studies have suggested oversampling approaches involving the artificial generation of samples from the minority class as an efficient mechanism to mitigate this issue. The CEGAN model introduces a solution to address the class imbalance issue through the utilization of a GAN-based framework, as outlined in the work by Suh et al [99]. This model particularly focuses on enhancing the quality of data generated from the minority class, thereby mitigating the classifier's bias toward the distribution of the majority class. Differing from the conventional GAN model, the CEGAN framework combines three distinct networks—a generator, a discriminator, and a classifier. The training process of the CEGAN model involves a two-step sequence. The generator generates synthetic data in the initial phase using input noise and real class labels. Simultaneously, the discriminator distinguishes between real and synthetic data, while the classifier assigns class labels to input samples. The subsequent stage involves the integration of the generated samples with the original training data, creating an augmented dataset for training the classifier. The CEGAN framework serves as an efficient methodology that incorporates techniques such as data augmentation, noise reduction, and ambiguity reduction to effectively tackle class imbalance problems. Notably, this approach overcomes the limitations associated with traditional resampling techniques, as it avoids the need to modify the original dataset.
SeismoGen. SeismoGen is a seismic waveform synthesis technique that utilizes GAN for seismic data augmentation [87]. The motivation behind SeismoGen arises from the need for abundant labeled data for accurate earthquake detection models. To overcome the scarcity of seismic waveform datasets, Wang et al introduced the SeismoGen framework, employing GAN to generate realistic multi-labeled waveform data based on limited real seismic datasets. Incorporating this additional dataset enhances the training of machine learning-based seismic analysis models, leading to more robust predictions for out-of-sample datasets. The mathematical formulation of the SeismoGen framework follows the WGAN [109] framework and can be expressed as:

where the noise z is a standard normal variable and λ is a hyperparameter. The primary objective is to minimize the difference between the true seismic waveforms and the synthetic waveforms generated by the SeismoGen. This is achieved by iteratively optimizing LG and LD to find an equilibrium between the generator and discriminator networks. SeismoGen has demonstrated its ability to generate highly realistic seismic waveforms, making it valuable for seismic waveform analysis and data augmentation. Its conditional generation feature allows users to produce waveforms labeled with specific categories, enhancing its versatility for various applications. SeismoGen is scalable and capable of generating large databases of artificial waveforms, which is beneficial for tasks requiring extensive training data. However, SeismoGen's effectiveness is influenced by the quality and distribution of the training data. It does not model the expected waveform move-out, which is relevant in various seismic research. Additionally, due to imbalanced real seismic waveform datasets, SeismoGen struggles to generate data with rare characteristics. Moreover, the computational cost of training and using SeismoGen may be a limiting factor, especially for real-time seismic hazard assessment applications. As a relatively new technology, there might be some potential for unexpected behavior when using SeismoGen, as its full capabilities and limitations are yet to be fully explored.
MetroGAN. Zhang et al introduced MetroGAN as a geographically informed generative deep learning model for urban morphology simulation [84]. MetroGAN incorporates a progressive growing structure to learn urban features at various scales and leverages physical geography constraints through geographical loss to ensure that urban areas are not generated on water bodies. The generation of cities with MetroGAN involves a global city dataset comprising three layers: terrain (digital elevation model), water, and nighttime lights, effectively capturing the physical geography characteristics and socioeconomic development of cities. The model detects and represents over 10 000 cities worldwide as 100 km × 100 km images. The mathematical formulation of the MetroGAN framework is a modified version of the LSGAN model [113], which can be expressed as follows:

where images x with corresponding labels y and a random vector z in the latent space are fed into G to produce simulated images  . Both real input pairs (x, y) and simulated pairs
. Both real input pairs (x, y) and simulated pairs  are then presented to D to distinguish real images from fake ones and also to assess if the input pairs match. The objective loss function comprises different terms, including least square adversarial loss (from the first two expectation terms), L1 loss denoted as
are then presented to D to distinguish real images from fake ones and also to assess if the input pairs match. The objective loss function comprises different terms, including least square adversarial loss (from the first two expectation terms), L1 loss denoted as  , and a geographical loss with hyperparameters
, and a geographical loss with hyperparameters  and
and  , respectively. The geographical loss (last term) utilizes Hadamard product
, respectively. The geographical loss (last term) utilizes Hadamard product  to filter out pixels that generate urban areas on water area xwater. MetroGAN, a robust urban morphology simulation model, has several notable advantages and limitations. On the positive side, it incorporates geographical knowledge, resulting in enhanced performance. Its progressive growing structure allows for stable learning at different scales, while multi-layer input ensures precise city layout generation. The model's evaluation framework covers various aspects, ensuring the quality of its output. Furthermore, MetroGAN finds wide applications in urban science and data augmentation. However, these strengths come with challenges, including high computational costs due to extensive data requirements and dependence on data quality, which may hinder its performance with noisy or missing data. Additionally, the model lacks interpretability, making it difficult to understand the reasoning behind its predictions, and it may struggle to effectively represent all intricate features of complex urban systems.
to filter out pixels that generate urban areas on water area xwater. MetroGAN, a robust urban morphology simulation model, has several notable advantages and limitations. On the positive side, it incorporates geographical knowledge, resulting in enhanced performance. Its progressive growing structure allows for stable learning at different scales, while multi-layer input ensures precise city layout generation. The model's evaluation framework covers various aspects, ensuring the quality of its output. Furthermore, MetroGAN finds wide applications in urban science and data augmentation. However, these strengths come with challenges, including high computational costs due to extensive data requirements and dependence on data quality, which may hinder its performance with noisy or missing data. Additionally, the model lacks interpretability, making it difficult to understand the reasoning behind its predictions, and it may struggle to effectively represent all intricate features of complex urban systems.
M3GAN. Anomaly detection in multi-dimensional time series data has received tremendous attention in the fields of medicine, fault diagnosis, network intrusion, and climate change. In this work, the authors have proposed the M2GAN (a GAN framework based on a masking strategy for multi-dimensional anomaly detection) and M3GAN (M2GAN for mutable filter) for improving the robustness and accuracy of GAN-based anomaly detection methods. M2GAN generates fake samples by directly reconstructing real samples, which are sufficiently realistic [102]. This is done by extracting various information from the original data by the mask method which improves the robustness of the model. M3GAN fuses the fast Fourier transform [187] and wavelet decomposition [188] to obtain a mutable filter to process the raw data so that the model can learn various types of anomalies. The architecture of the M2GAN framework utilizes the AAE [111] instead of the conventional GAN model generator for generating realistic fake data. A masking strategy of the AAE enhances the variability within the original time series and overcomes the MC problem. For the discriminator network, this framework employs an AnoGAN [189] architecture that distinguishes between normal data and anomalous data using DCGAN [23]. The M3GAN model combines a dynamic switch-based adaptive filter selection mechanism with the multidimensional anomaly detection capabilities of the M2GAN model. This approach allows one to select the most suitable filter for the given data that better exploits the complex characteristics of the series, leading to improved accuracy in anomaly detection. Both M2GAN and M3GAN architectures excel in spotting anomalies in multi-dimensional time series data, offering adaptability for dynamic settings. Its capacity to generate synthetic data aids tasks like diverse model training. However, their high computational complexity leads to extended processing times. Moreover, their limited interpretability also poses a significant challenge in understanding the marked anomalies. Further research is needed in this domain to address these issues and provide support for adaptive filter parameters in M3GAN.
CNTS. CNTS, introduced by Yang et al in 2023, is a reconstruction-based unsupervised anomaly detection technique for time series data [103]. This model aims to overcome the limitations of the previous generative methods that were sensitive to outliers and showed sub-optimal anomaly detection performance due to their emphasis on time series reconstruction. The CNTS framework consists of two FEDformer [190] networks, namely a reconstructor (R) and a detector (D). The reconstructor aims to regenerate the series that closely matches the known data distribution (without anomalies) i.e. data reconstruction. On the other hand, the detector focuses on identifying the values that deviate from the fitted data distribution, effectively detecting anomalies. Despite having different purposes, these two networks are trained using a cooperative mode, enabling them to leverage mutual information. During the training phase, the reconstruction error of R serves as a labeling mechanism for D, while D provides crucial information to R regarding the presence of anomalies, enhancing the robustness to outliers. Thus the multi-objective function of the CNTS model can be expressed as:

where xi
is the value for the ith,  time stamp of the input series,
time stamp of the input series,  and
and  denotes the parameters of D and R, while
denotes the parameters of D and R, while  and
and  represent their corresponding loss functions, respectively. The categorical label
represent their corresponding loss functions, respectively. The categorical label  indicates the presence of anomalies as identified by D and helps to remove data with high anomaly scores, thereby reducing their impact on the training of R. The cooperative training approach employed by CNTS allows it to model complex temporal patterns present in real-world time series data, thus significantly enhancing its performance in various anomaly detection tasks. The flexibility and adaptability of the CNTS model make it robust to the presence of outliers in the series. However, the presence of the dual-network architecture of the CNTS model increases its computational complexity, hindering its real-time applicability. Moreover, the lack of interpretability of the model poses a significant challenge to its potential use cases. Furthermore, the success of the CNTS model is contingent on the availability of representative and diverse time series datasets and the choice of sub-networks. Further research in this domain is required to comment on the performance of the model for diverse datasets and appropriate sub-network choices.
indicates the presence of anomalies as identified by D and helps to remove data with high anomaly scores, thereby reducing their impact on the training of R. The cooperative training approach employed by CNTS allows it to model complex temporal patterns present in real-world time series data, thus significantly enhancing its performance in various anomaly detection tasks. The flexibility and adaptability of the CNTS model make it robust to the presence of outliers in the series. However, the presence of the dual-network architecture of the CNTS model increases its computational complexity, hindering its real-time applicability. Moreover, the lack of interpretability of the model poses a significant challenge to its potential use cases. Furthermore, the success of the CNTS model is contingent on the availability of representative and diverse time series datasets and the choice of sub-networks. Further research in this domain is required to comment on the performance of the model for diverse datasets and appropriate sub-network choices.
RidgeGAN. RidgeGAN, introduced by Thottolil et al in 2023, is a hybridization of the nonlinear kernel ridge regression (KRR) [191, 192] and the generative CityGAN model [10]. This framework aims to predict the transportation network of the future small and medium-sized cities of India by analyzing the spatial indicators of human settlement patterns. This prediction is crucial for facilitating sustainable urban planning and traffic management systems. The RidgeGAN framework operates in three steps. Firstly, it generates an urban Universe for India based on spatial patterns by learning urban morphology using the CityGAN model [82]. Secondly, it utilizes KRR to study the relationship between the human settlement indices and the transportation indices (TIs) of 503 real small and medium-sized cities in India. Finally, the KKR model's regression framework is applied to the synthetic hyper-realistic samples of future cities and their TI is predicted. RidgeGAN framework has applications in diverse areas, such as analyzing urban land patterns, forecasting essential urban infrastructure, and assisting policymakers in achieving a more inclusive and effective planning process. Moreover, this model is especially valuable when designing the transportation network of developing nations with limited or partial real data, as the model can produce data that closely resembles actual urban morphology and helps in data augmentation. However, the framework fails to showcase its performance for the generated human settlements, which is crucial in the urban planning procedure. Further studies in this domain are indeed required to understand the suitability of the framework for large cities as well.
6. Recent theoretical advancements of GAN
Empirical studies have shown the great success of GAN and their variants in producing state-of-the-art results in diverse domains ranging from image, video, and text generation to automatic vehicles, time series, and drug discovery, among many others. The mathematical reasoning of GANs is to approximate the unknown distribution of a given data by optimizing an objective function through an adversarial game between a family of generators and a family of discriminators. Biau et al [193] analyzed the mathematical and statistical properties of GANs by establishing connections between adversarial principles and JS divergence. Their work provides the large sample properties for the estimated distribution parameters and a result toward the central limit theorem. Another cousin approach of GAN, called WGAN, has more stable training dynamics than typical GANs. Biau et al [194] studied the convergence of empirical WGANs when sample size approaches infinity. More recently, the rate of convergence for density estimation with GANs has been studied in [195]. In particular, they studied the non-asymptotic properties of the vanilla GAN and derived a theoretical guarantee of the density estimation with GANs under a proper choice of deep neural network classes representing generators and discriminators. It suggests that the resulting estimates converge to the true density ( ) in terms of the JS divergence at the rate of
) in terms of the JS divergence at the rate of  , where n is the sample size, β determines the smoothness of
, where n is the sample size, β determines the smoothness of  , and d is the data dimension. In theorem 2 of [195] if the choice of G and D to be classes of neural networks with rectified quadratic unit activation functions, the rates of convergence for the estimate
, and d is the data dimension. In theorem 2 of [195] if the choice of G and D to be classes of neural networks with rectified quadratic unit activation functions, the rates of convergence for the estimate  to the true density
to the true density  in terms of JS divergence holds the following inequality with probability at least
in terms of JS divergence holds the following inequality with probability at least  ;
;

The above mathematical result suggests that the convergence rate of vanilla GAN's density estimate in the JS divergence is faster than  when
when  ; therefore, the obtained rate is minimax optimal for the considered class of densities. Meitz [196] studied statistical inference for GAN by addressing two critical issues for the generator and discriminator's parameters, namely consistent estimation and confidence sets. Mbacke et al [197] studied probably approximately correct (PAC)-Bayesian generalization bound for WGANs based on Wasserstein distance and total variational distance. The generalization properties of GANs try to answer the following question: how do we certify that the learned distribution
; therefore, the obtained rate is minimax optimal for the considered class of densities. Meitz [196] studied statistical inference for GAN by addressing two critical issues for the generator and discriminator's parameters, namely consistent estimation and confidence sets. Mbacke et al [197] studied probably approximately correct (PAC)-Bayesian generalization bound for WGANs based on Wasserstein distance and total variational distance. The generalization properties of GANs try to answer the following question: how do we certify that the learned distribution  is 'close' to the true one
is 'close' to the true one  ? This question is pivotal since the true distribution
? This question is pivotal since the true distribution  is unknown in real problems, and generative models can only access its empirical counterpart. Liu et al [198] studied how well GAN can approximate the target distribution under various notions of distributional convergence. Lin et al [199] showed that GAN-generated samples inherently satisfy some (weak) privacy guarantees under certain conditions. Another study offers a theoretical perspective on why GANs sometimes fail for certain generation tasks, in particular, sequential tasks such as natural language generation [200]. Further research on the comparative theoretical aspects, both pros and cons, of different generative approaches will enhance support for the wide applications of GANs and address their limitations.
is unknown in real problems, and generative models can only access its empirical counterpart. Liu et al [198] studied how well GAN can approximate the target distribution under various notions of distributional convergence. Lin et al [199] showed that GAN-generated samples inherently satisfy some (weak) privacy guarantees under certain conditions. Another study offers a theoretical perspective on why GANs sometimes fail for certain generation tasks, in particular, sequential tasks such as natural language generation [200]. Further research on the comparative theoretical aspects, both pros and cons, of different generative approaches will enhance support for the wide applications of GANs and address their limitations.
7. Evaluation measures
In contrast to conventional deep learning architectures that employ convergence-based optimization of the objective function, generative models like GANs utilize a minimax loss function, trained iteratively to establish equilibrium between the generator and discriminator networks [1]. The absence of an objective loss function for GAN training restricts the ability of loss measurements to assess training progress or model performance. To address this challenge, a mix of qualitative and quantitative GAN evaluation approaches has been developed [201]. These evaluation measures vary based on the quality and diversity of the generated synthetic data and the potential applications of the generated data [202].
Owing to the lack of consensus among the researchers on the use of a universal metric to gauge the performance of the deep generative models, different metrics have been developed in the last decade with their unique strengths and particular applicability [47]. This section will briefly overview the popular evaluation measures used in different applications.
7.1. IS
The IS is a widely used metric to assess the quality and diversity of GAN-generated samples [203]. It leverages a pre-trained neural network classifier called Inception v3 [204], which was initially trained on the ImageNet [205] dataset containing a diverse range of real-world images categorized into 1000 classes. The IS measures the quality of generated samples based on their classification probabilities predicted by Inception v3. Higher-quality samples are expected to be strongly classified into specific classes, implying low entropy. In general, the IS value ranges between 1 and the number of classes in the classifier, reflecting the diversity of the generated samples, with higher scores indicating better performance. Nevertheless, the IS does come with a number of limitations. It encounters challenges when dealing with instances of MC, wherein the generated samples by GANs are extremely similar, causing artificially inflated IS values that do not accurately represent diversity. Additionally, it relies on the performance of the Inception v3 model, which might not always align with human perception of image quality. To mitigate these drawbacks of IS, several modified versions have been proposed in the literature. For example, the modified IS attempts to address the MC problem in GAN by evaluating the diversity of images with the same category [206]. Other modification of IS includes the mode score, which evaluates the quality and diversity of the generated data by considering the prior data distribution of the labels [207].
7.2. Fréchet inception distance
The Fréchet inception distance (FID) is a widely used evaluation metric that measures the quality and diversity of GAN-generated images [49]. It calculates the similarities and differences between the distributions of real and generated images using the Fréchet distance, which is a form of the Wasserstein-2 distance. The FID metric calculates the mean and covariance of both the real and generated images and then computes the distance between their distributions. Mathematically the FID is expressed as:

where (µ, Σ) and (µw
,  ) represent the mean and covariance pair for the real images and the generated images, respectively. The strength of FID lies in its ability to account for various forms of contamination, such as Gaussian noise, Gaussian blur, black rectangles, and swirls, among others. FID's incorporation of these factors contributes to a more robust evaluation of GAN-generated images. As a widely accepted and utilized metric, FID offers a common ground for comparing results across different GAN architectures, promoting a standardized approach for assessing image quality [5, 6, 208].
) represent the mean and covariance pair for the real images and the generated images, respectively. The strength of FID lies in its ability to account for various forms of contamination, such as Gaussian noise, Gaussian blur, black rectangles, and swirls, among others. FID's incorporation of these factors contributes to a more robust evaluation of GAN-generated images. As a widely accepted and utilized metric, FID offers a common ground for comparing results across different GAN architectures, promoting a standardized approach for assessing image quality [5, 6, 208].
7.3. Multi-scale structural similarity
The multi-scale structural similarity metric (MS-SSIM), an extension of the traditional structural similarity index (SSIM), serves as an effective measure for evaluating the quality of GAN-generated images [209]. MS-SSIM focuses on comparing image structures, including luminance and contrast, across different scales. This metric comprehensively evaluates the similarity between the real and synthesized datasets, considering their structural and geometric aspects. Moreover, the ability of MS-SSIM to account for strong dependencies between closely correlated pixels enhances its sensitivity to perceptual quality.
7.4. Classifier two-sample test
Classifier two-sample test (C2ST) is a classification-based approach that evaluates the generalization capabilities of GAN for any synthetic data generation task [210]. This metric utilizes a classifier (for example, one-nearest neighbor [211]) to distinguish between the real and generated samples. The performance of this classifier is then used as a metric to determine the quality of the generated samples. The C2ST metric provides an essential tool for measuring the performance of GAN-based architectures for any applied domains since the classifier is not restricted to a specific data type. Moreover, it focuses on the discriminative aspect of the generated data quality and complements other evaluation metrics that focus on the distributional and perceptual aspects of the generated data.
7.5. Music evaluation metric
Evaluating the quality of music generated by GANs presents unique challenges due to the subjective nature of musical perception. Traditional quantitative metrics like those used for image evaluation may not fully capture the richness and complexity of musical content. However, several methods have been developed to assess the quality and coherence of GAN-generated music. Certain objective evaluation metrics encompass factors such as musical characteristics, structure, style, uniqueness, and tonality, drawing from statistical representations [40]. Amid these, subjective listening is the most reliable metric for evaluating GAN-generated music. This approach encompasses melody, harmony, rhythm, and emotional resonance, furnishing insightful glimpses into the musical caliber.
7.6. Maximum mean discrepancy
Maximum mean discrepancy (MMD) is a statistical measure that quantifies the dissimilarity between two probability distributions. In the context of GAN evaluation, MMD is employed to assess the quality of generated samples by comparing them with real data distributions based on their mean values in a high-dimensional space [212]. A lower MMD score indicates that the difference between the two data distributions is relatively smaller; hence the synthetic data is similar to the original data.
7.7. Time series evaluation metric
Assessing time series GAN models presents a notable challenge due to the temporal dependencies inherent in the data. Traditional evaluation metrics tailored to static image datasets struggle to capture the intricate patterns found in sequential data. As a result, a combined approach of qualitative and quantitative measures is employed for evaluation purposes [38]. Qualitative assessment relies primarily on human visual judgment when examining the generated samples. However, these methods lack objectivity. A range of quantitative evaluation techniques is employed within GAN-based time series evaluation to address this limitation. These encompass metrics such as root mean square error, Wasserstein-1 distance, dynamic time warping, and Pearson correlation coefficient.
7.8. Uncertainty quantification in GANs
Uncertainty quantification (UQ) plays a vital role in characterizing and estimating the uncertainties in both computation and real-world applications. Due to the fact that the analysis of physical processes based on computer models is riddled with uncertainty, therefore, it has to be addressed to perform 'trustworthy' model-based inference [213]. Oberdiek et al presented a method to quantify uncertainties of deep neural networks in image classification based on GANs. By employing GANs to generate out-of-distribution (OoD) samples, their methodology enables the classifier to effectively gauge uncertainties for both OoD examples and minor positives [214]. He et al presented a survey on UQ models for deep neural networks based on two types of uncertainty sources, namely data uncertainty and model uncertainty [215]. They highlighted that GAN-based models can capture the structure of data uncertainty; however, they are hard to train. Another survey [216] highlighted various measures to quantify uncertainties in deep neural networks. However, validating existing methods remains difficult due to the lack of uncertain ground truths.
8. Limitations and scope for improvement
Although GANs have brought a transformative shift in generative modeling, addressing the substantial challenges embedded within their training process that demand careful consideration [203] is crucial. Various architectural modifications of GAN (as discussed in section 5) aim to address specific GAN-related issues and optimize their overall performance. This section summarizes the different obstacles in GAN and discusses their potential remedies.
8.1. MC
The foremost challenge during GANs training is MC, a phenomenon where the generator's output becomes constrained, yielding repetitive samples that lack the comprehensive range of the target data distribution [133]. MC arises when the generator does not explore the full spectrum of potential outputs and instead generates identical outputs for distinct inputs from the latent space. This issue can manifest due to an overpowering discriminator or insufficient feedback for the generator to diversify its outputs [217]. Partial and complete MC are its two variants, with the former leading to a limited diversity in generated data and the latter resulting in entirely uniform patterns across generated samples. While partial MC is common, complete MC is relatively rare [47].
Many efforts have been made to tackle the MC problem [218, 219]. Some of these approaches include the application of unrolled GAN [220] where the generator network is updated by unrolling the discriminator's update steps, unlike the conventional GAN, where D is first updated while G is kept fixed and G is updated based on the updated D. Moreover, mini-batch discrimination is often used to mitigate the MC problem [203]. In this approach, instead of modeling each data example independently, D processes multiple data examples in mini-batches. The use of modified loss functions, for example, LSGAN [113], WGAN [109], CycleGAN [3] also reduces the MC problem.
8.2. Vanishing gradients
The vanishing gradients problem is another significant challenge encountered during the training phase of GANs. This issue emerges due to the complex architecture of GANs, where both G and D need to maintain a balance and learn collaboratively [221]. During the training process, as gradients are backpropagated through the layers of the network, they can diminish drastically, leading to stagnancy in learning. This circumstance can occur when the discriminator becomes very accurate, such as when  or when D is inadequately trained and fails to differentiate between real and generated data. Consequently, the loss function might approach zero, hindering constructive feedback to the generator and restricting the generation of high-quality data. Several strategies have been proposed to address vanishing gradients in GANs. One approach is to use a modified loss function, such as the LSGAN [113], that mitigates the vanishing gradient problem to a considerable extent. Furthermore, advanced optimization algorithms, alternative activation functions, and batch normalization strategies are often adopted to reduce the effect of vanishing gradients during GAN training.
or when D is inadequately trained and fails to differentiate between real and generated data. Consequently, the loss function might approach zero, hindering constructive feedback to the generator and restricting the generation of high-quality data. Several strategies have been proposed to address vanishing gradients in GANs. One approach is to use a modified loss function, such as the LSGAN [113], that mitigates the vanishing gradient problem to a considerable extent. Furthermore, advanced optimization algorithms, alternative activation functions, and batch normalization strategies are often adopted to reduce the effect of vanishing gradients during GAN training.
8.3. Learning instability and NE
The architectural characteristics of GAN involve a complex interplay between the two deep neural networks in an adversarial manner. Their training happens in a cooperative yet competitive way using a zero-sum game strategy where both G and D aim to optimize their respective objective functions to achieve the NE i.e. a state beyond which they can not improve their performance unilaterally [48]. While this cooperative architecture aims to optimize a global loss function, the optimization problems the individual networks face are fundamentally opposing. Due to this complexity in the loss function, there can be situations where some minor adjustments in one network can trigger substantial modifications in the other. Moreover, when both networks aim to optimize their loss functions independently without coordination, attaining the NE can be hard. Such instances of desynchronization between the networks can lead to instability in the overall learning process and substantially increase the computation time [222]. To counter this challenge, recent advancements in GAN architectures have been focusing on enhancing training stability. The feature matching technique improves the stability of the GAN framework by introducing an alternative cost function for G combining the output of the discriminator [203]. Additionally, historical averaging of the parameters [203], unrolled GAN [220], and gradient penalty [117] strategies mitigate learning instability and promote convergence of the model.
8.4. Stopping problem
During GAN training, determining the appropriate time at which the networks are fully optimized is crucial for addressing the problems related to overfitting and underfitting. However, in GANs, determining the state of the networks based on their respective loss functions is impossible due to the minimax objective function. To address this issue related to the GANs stopping criterion, researchers often employ an early stopping approach where the training halts based on a predefined threshold or the lack of improvement in evaluation metrics.
8.5. Internal distributional shift
The internal distributional shift, often called internal covariate shift refers to the changing distribution in the network activations of the current layer w.r.t the previous layer. In the context of GAN, when the generator's parameters are updated, the distribution of its output may change, leading to internal distributional shifts in subsequent layers and causing the discriminator's learning to lag behind. This phenomenon affects the convergence of the GAN training process, and the computational complexity of the network significantly increases to counter the shifts. To address this issue, the batch normalization technique is widely adopted in various applications of GAN [223].
9. Discussion
Over the past decade, GANs have emerged as the foremost and pivotal generative architecture within the areas of CV, NLP, and related fields. To enhance the performance of GAN architecture, numerous studies have focused on the following: (i) the generation of high-quality samples, (ii) diversity in the simulated samples, and (iii) stabilizing the training algorithm. Constant efforts and improvements of the GAN model have resulted in plausible sample generation, text/image-to-image translations, data augmentation, style transfer, anomaly detection, and other applied domains.
Recent advancements in machine learning with the help of diffusion models [22, 224, 225], also known as score-based generative models, have made a strong impression on a variety of tasks, including image denoising, image inpainting, image super-resolution, and image generation. The primary goal of diffusion models is to learn the latent structure of the dataset by modeling the way in which data points diffuse through the latent space. [226] has shown that diffusion models outperform GANs on image synthesis due to their better stability and non-existence of MC. However, the cost of synthesizing new samples and computational time for making realistic images lead to its shortcomings when applied to real-time application [227, 228]. Due to the fact that GANs need fine-tuning in their hyperparameters, transformers [19] have been used to enhance the results of GANs that can adopt self-attention layers. This helps design larger models and replace the neural network models of G and D within the GAN structure. TransGAN [229] introduces a GAN architecture without convolutions by using Transformers in both G and D of the GAN, resulting in improved high-resolution image generation. Lv et al [230] presented an intersection of GANs and transformers to predict pedestrian paths. Although transformers and their variants have several advantages, they suffer from high computational (time and resource) complexity [231]. More recently, PINNs [20] was introduced as a universal function approximator that can incorporate knowledge of physical laws to govern the data in the learning process. PINNs overcome the low data availability issue [232] in which GANs and transformers lack robustness, rendering them ineffective scenarios. A GAN framework based on a PI discriminator (PID) for UQ is used to inform the knowledge of physics during the learning of both G and D models. PID-GAN [233] does not suffer from an imbalance of generator gradient from multiple losses. Another architecture, namely PI-GAN [234], tackles the problem of sequence generation with limited data. It integrates a transition module in the generator part that can iteratively construct the sequence with only one initial point as input. Solving differential equations using GANs to learn the loss function was presented in the differential equation GAN model [235]. Combining GANs with PINNs achieved competitive solution accuracies with popularly used numerical methods.
LLMs [21] became a very popular choice for their ability to understand and generate human language. LLMs are neural networks that are trained on massive text datasets to understand the relationship between words and phrases. This enables LLMs to generate text that is both coherent and grammatically correct. Recently, LLMs and their cousin ChatGPT revolutionized the field of NLP, question-answering, and creative writing. LLMs and their variants are also used to create creative content such as poems, scripts, and codes. GANs and LLMs are two powerful co-existing models where the former is used to generate realistic images. Mega-TTS [236] adopt a VQGAN [130] based acoustic model and a latent-code language model called Prosody-LLM (P-LLM) [237] to solve zero-shot text-to-speech at scale with intrinsic inductive bias. Future work in the hybridization of GANs with several other architectures will be a promising field of research.
10. Future research directions
Despite the substantial advancements achieved by GAN-based frameworks over the past decade, there remain a number of challenges spanning both theoretical and practical aspects that require further exploration in future research. In this section, we identify these gaps that necessitate deeper investigation to enhance our comprehension of GANs. The summary is presented below:
10.1. Fundamental questions on the theory of GANs
Recent advancements in the theory of GAN by [193, 194, 198] explored the role of the discriminator family in terms of JS divergence and some large sample properties (convergence and asymptotic normality) of the parameter describing the empirically selected generator. However, a fundamental question of how well GANs can approximate the target distribution  remained largely unanswered. From the theoretical perspective, there is still a mystery about the role and impact of the discriminator on the quality of the approximation. The universal consistency and convergence rate of GANs and their variants remain an open problem.
remained largely unanswered. From the theoretical perspective, there is still a mystery about the role and impact of the discriminator on the quality of the approximation. The universal consistency and convergence rate of GANs and their variants remain an open problem.
10.2. Improvement of training stability and diversity
Achieving the NE in GAN frameworks, which is essential for the generator to learn the actual sample distribution, requires stable training mechanisms [238, 239]. However, attaining this optimal balance between the generator and discriminator remains challenging. Various approaches have been explored, such as WGAN [109], SN-GAN [119], one-sided label smoothing [204], and WGAN with gradient penalty [117], to enhance training stability. Additionally, addressing MC, a common GAN issue that leads to limited sample diversity, has prompted strategies like WGAN [109], U-GAN [220], generator regulating GAN [240], and adaptive GAN [241]. Future research could focus on devising techniques to stabilize GAN training and alleviate problems like MC through regularization methods, alternative loss functions, and optimized hyperparameters. Incorporating methods like multi-modal GANs, designed to generate diverse outputs from a single input, might contribute to enhancing sample diversity [240].
10.3. Data scarcity in GAN
Addressing the issue of data scarcity in GANs stands as a crucial research trajectory. To expand GAN applications, forthcoming investigations could focus on devising training strategies for scenarios with limited data. Approaches such as few-shot GANs, transfer learning, and domain adaptation offer the potential to enhance GAN performance when data is scarce [242, 243]. This challenge becomes especially pertinent when acquiring substantial datasets poses difficulties. Additionally, refining training algorithms for maximal data utility could be pursued. Bolstering GAN effectiveness in low-data situations holds pivotal significance for broader adoption across various industries and domains.
10.4. Ethics and privacy
Since its inception in 2014, GAN development has yielded substantial benefits in research and real-world applications. However, the inappropriate utilization of GANs can give rise to latent societal issues such as producing deceptive content, malicious images, fabricated news, deepfakes, prejudiced portrayals, and compromising individual safety [244]. To tackle these issues, the establishment of ethical guidelines and regulations is imperative [245]. Future research avenues might center on developing robust techniques to detect and alleviate ethical concerns associated with GANs while also advocating their ethical and responsible deployment in diverse fields. Essential to this effort is the creation of forgery detection methods capable of effectively identifying AI-generated content, including images produced through GANs. Furthermore, GANs can be susceptible to adversarial attacks, wherein minor modifications to input data result in visually convincing yet incorrect outputs [140, 246]. Future investigations could prioritize the development of robust GANs that can withstand such attacks alongside methods for identifying and countering them. Ensuring the integrity and reliability of GANs is of utmost importance, particularly in contexts like authentication, content verification, and cybersecurity [217, 247].
10.5. Real-time implementation and scalability
While GANs have shown immense potential, their resource-intensive nature hinders real-time usage and scalability. Recent GAN variants like ProGAN [5] and Att-GAN [124] aim to address this complexity. Future efforts might focus on crafting efficient GAN architectures capable of generating high-quality samples in real-time, which is vital for constrained platforms like mobile devices and edge computing. Integrating GANs with reinforcement learning, transfer learning, and supervised learning, as seen in RidgeGAN [10], opens opportunities for hybrid models with expanded capabilities. Research should delve into hybrid approaches, leveraging GANs alongside other techniques for enhanced generative potential. Additionally, exploring multimodal GANs that produce diverse outputs from multiple modalities can unlock novel avenues for creating complex data [248].
10.6. Human-centric GANs
GANs have the potential to enable human–machine creative cooperation [249]. Future research could emphasize human-centric GANs, integrating human feedback, preferences, and creativity into the generative process. This direction might pave the way for interactive and co-creative GANs, enabling the production of outputs aligned with human preferences and needs while also involving users in active participation during the generation process.
10.7. Other innovative applications and industry usage
Initially designed for generating realistic images, GANs have exhibited impressive performance in CV. While their application has extended to domains like time series generation [102, 103], audio synthesis [8], and autonomous vehicles [112], their use outside CV remains somewhat constrained. The divergent nature of image and non-image data introduces challenges, particularly in non-image contexts like NLP, where discrete values such as words and characters predominate [200]. Future research can aim to overcome these challenges and enhance GANs' capabilities in discrete data scenarios. Furthermore, exploring unique applications of GANs in fields like finance, education, and entertainment offers the potential to introduce new possibilities and positively impact various industries [250]. Collaborative efforts across disciplines could also harness diverse expertise, fostering synergies to enhance GANs' adaptability across a broad spectrum of applications [251].
11. Conclusion
In this article, we presented a GAN survey, GAN variants, and a detailed analysis of the wide range of GAN applications in several applied domains. In addition, we reviewed the recent theoretical developments in the GAN literature and the most common evaluation metrics. Despite all these, one of the core contributions of this survey is to discuss several obstacles of various GAN architectures and their potential solutions for future research. Overall, we discuss GANs' potential to facilitate practical applications not only in image, audio, and text but also in relatively uncommon areas such as time series analysis, geospatial data analysis, and imbalanced learning. In the discussion section , apart from GANs' significant success, we detail the failures of GANs due to their time complexity and unstable training. Although GANs have been phenomenal for the generation of hyper-realistic data, current progress in deep learning depicts an alternative narrative. Recently developed architectures such as diffusion models have demonstrated significant success and outperformed GANs on image synthesis. On the other hand, transformers, a deep learning architecture based on a multi-head attention mechanism, has been used within GAN architecture to enhance its performance. Furthermore, LLMs, a widely utilized deep learning structure designed for comprehending and producing natural language, have been incorporated into GAN architecture to bolster its effectiveness. The hybridization of PINN and GAN, namely PI-GAN, can solve inverse and mixed stochastic problems based on a limited number of scattered measurements. On the contrary, GANs' ability to rely on large data for training, using physical laws inside GANs in the form of stochastic differential equations, can mitigate the limited data problem. Several hybrid approaches combining GAN with other powerful deep learners are showing great merit and success, as discussed in the discussion section. Finally, the article summarizes and criticizes several applications of GANs over the last decade.
Acknowledgment
The authors would like to acknowledge the associate editor and learned reviewers of the journal for their valuable suggestions.
Data availability statement
No new data were created or analyzed in this study.