


Abstract
Cosmic voids are the largest and most underdense structures in the Universe. Their properties have been shown to encode precious information about the laws and constituents of the Universe. We show that machine-learning techniques can unlock the information in void features for cosmological parameter inference. We rely on thousands of void catalogs from the GIGANTES data set, where every catalog contains an average of 11,000 voids from a volume of 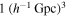 . We focus on three properties of cosmic voids: ellipticity, density contrast, and radius. We train (1) fully connected neural networks on histograms from individual void properties and (2) deep sets from void catalogs to perform likelihood-free inference on the value of cosmological parameters. We find that our best models are able to constrain the value of Ωm, σ8, and ns with mean relative errors of 10%, 4%, and 3%, respectively, without using any spatial information from the void catalogs. Our results provide an illustration for the use of machine learning to constrain cosmology with voids.
. We focus on three properties of cosmic voids: ellipticity, density contrast, and radius. We train (1) fully connected neural networks on histograms from individual void properties and (2) deep sets from void catalogs to perform likelihood-free inference on the value of cosmological parameters. We find that our best models are able to constrain the value of Ωm, σ8, and ns with mean relative errors of 10%, 4%, and 3%, respectively, without using any spatial information from the void catalogs. Our results provide an illustration for the use of machine learning to constrain cosmology with voids.
Export citation and abstract BibTeX RIS

Original content from this work may be used under the terms of the Creative Commons Attribution 4.0 licence. Any further distribution of this work must maintain attribution to the author(s) and the title of the work, journal citation and DOI.
1. Introduction
Cosmic voids, the underdense regions in the galaxy distribution, are dominated by dark energy and account for most of the volume of the Universe (Gregory & Thompson 1978; Jõeveer et al. 1978; Kirshner et al. 1981; Zeldovich et al. 1982; van de Weygaert & van Kampen 1993; Bond et al. 1996; Tikhonov & Karachentsev 2006). Thanks to their underdense feature, voids are particularly sensitive to cosmological information (Park & Lee 2007; Lavaux & Wandelt 2010; Bos et al. 2012; Lavaux & Wandelt 2012; Pisani et al. 2015, 2019; Hamaus et al. 2016; Mao et al. 2017; Chan et al. 2019; Ronconi et al. 2019; Sahlén 2019; Verza et al. 2019; Bayer et al. 2021; Kreisch et al. 2022; Wilson & Bean 2021; Contarini et al. 2022, 2023; Pelliciari et al. 2023). Until recently, void numbers were relatively low given the fact that voids are large regions and that the volume of surveys was relatively small. Nowadays, large-scale surveys are expected to enable big data approaches for studying voids, revealing their relationship to cosmological models in all its strength. Upcoming surveys will provide of the order of 105 voids each, gaining more than 1 order of magnitude in void numbers (Pisani et al. 2019; Moresco et al. 2022). Along with the large increase in available data from current and upcoming surveys, void data from simulations is also dramatically increasing (see, e.g., the extensive GIGANTES set of void catalogs in Kreisch et al. 2022)—enabling the usage of machine learning to analyze voids and find correlations with the value of cosmological parameters.
To extract cosmological information from voids, robust theoretical predictions are necessary for each of the different void statistics; examples include the void size function, providing the void number density as a function of void radii, and the void-galaxy cross-correlation function, corresponding to the density profile of voids (see, e.g., Hamaus et al. 2016; Verza et al. 2019; Pisani et al. 2019; Hamaus et al. 2020; Contarini et al. 2022). Additionally, relating theoretical predictions with measurements from observations is not always easy, since models are constructed by assuming ideal, isolated voids in the theoretical setup, different from voids measured in observations (Contarini et al. 2021; Stopyra et al. 2021). Therefore, the current extraction of cosmological information from voids is limited by the current progress in modeling void statistics. While most of the modeling effort is geared toward traditional void statistics such as the ones mentioned above, the relationship between other void properties and cosmological parameters needs further exploration. Machine learning provides a well-established framework to perform this task.
In the future, as the volume and density of sky surveys and simulations continue to grow, and more machine-learning methods are adopted into this field, we believe that void statistics will stand as an increasingly effective and competitive probe for cosmology (Baron 2019; Ntampaka et al. 2019; Lemos et al. 2022).
Two void properties deserve special attention: (1) the ellipticity and (2) the density contrast (Biswas et al. 2010; Lavaux & Wandelt 2010; Sutter et al. 2014a, 2015; Kreisch et al. 2022; Schuster et al. 2023). In this work, we intend to use them, plus the traditional void radius, to train neural networks to perform likelihood-free inference on the value of the cosmological parameters. We now discuss why these properties may carry cosmological information.
A common expectation of voids is that they should have spherical shapes (Icke 1984; Dubinski et al. 1993; van de Weygaert & van Kampen 1993). In reality, due to the counterbalance between the tidal effect of the dark matter and the expansion of the Universe, voids are in fact far from spherically symmetric on a one-to-one basis (Sheth & van de Weygaert 2004; Shandarin et al. 2006; Park & Lee 2007). Previous work shows that the void ellipticity distribution depends quite sensitively on cosmological parameters and is a promising probe for constraining the dark energy equation of state (Biswas et al. 2010; Lavaux & Wandelt 2010; Bos et al. 2012). In particular, Biswas et al. (2010) considered the void ellipticity distribution as a precision probe for dark energy parameters {w0, wa } using the Fisher forecasts framework. In this work, we instead focus on predicting Ωm (in a flat Universe corresponding to constraining ΩΛ = 1 − Ωm ). Furthermore, Sutter et al. (2014a, 2014b) investigated the match between analytical models of void ellipticity with simulations and observations. Other factors affect void ellipticities, including (but not limited to) the presence of redshift space distortions (Shoji & Lee 2012; Bos et al. 2012; Hamaus et al. 2020), the possibility of dark matter and dark energy interactions (Rezaei 2020), and modified gravity (Perico et al. 2019; Zivick et al. 2015). Despite the strong evidence of the sensitivity of void ellipticity to cosmology, there are still very limited studies aiming at using this property for cosmology.
A similar statement can be made for the density contrast of voids, a measure of voids' depths with respect to their edges, formally defined for popular Voronoi-based void finders as the ratio of the minimum density of the particle on the ridge of the void to the minimum density of the void (Neyrinck 2008). From a purely theoretical perspective, the void definition is linked to density contrast: voids can be defined as matter density fluctuations for which the mean density contrast in a sphere reaches a threshold value for an effective radius value. In void finding algorithms, density contrast has been a crucial factor for determining the probability of finding a void (e.g., Hoyle & Vogeley 2002; Padilla et al. 2005; Neyrinck 2008; Sutter et al. 2015), and studies show that the void density contrast can be a relevant quantity to distinguish and remove spurious voids in a sample (Cousinou et al. 2019). The void density contrast is linked to the void density profile, an observable that has been deeply investigated in previous works (e.g., Lavaux & Wandelt 2012; Sutter et al. 2012; Hamaus et al. 2014; Schuster et al. 2023). So far, however, only a few papers focus on directly utilizing the void density contrast as a stand-alone quantity to extract cosmological information.
In this paper, we attempt to answer the question of how much information is contained in these void properties. Given the expected complex and likely unknown likelihood of the data, we tackle this problem using machine learning. In particular, we aim to constrain the cosmological parameters {Ωm , Ωb , h, ns , σ8} from either histograms of void properties (e.g., the distribution of void ellipticities) or from void catalogs directly. With respect to standard statistics (e.g., the power spectrum), void properties may have different degeneracies when inferring the value of parameters, so their usage may help break those degeneracies and get tighter constraints (Bayer et al. 2021; Kreisch et al. 2022; Pelliciari et al. 2023; Contarini et al. 2023).
In this paper, we build on previous works that have quantified the amount of information contained in the void size function (Kreisch et al. 2022) and on void catalogs directly (Cranmer et al. 2021) using machine-learning techniques. Kreisch et al. (2022) carried out an initial proof-of-concept analysis, training neural networks to perform likelihood-free inference using the void size function. The void size function is one of the main void statistics expected to reach its golden era in the next few years (Pisani et al. 2015, 2019; Contarini et al. 2022), with a theoretical model recently reaching a high maturity level (Contarini et al. 2023). Cranmer et al. (2021) used deep sets to extract information from the three void properties we consider in this paper. However, in that work, we were interested in developing new pooling operations and in making our model more interpretable. On top of that, we assumed a Gaussian posterior. In this work, we instead aim to maximize the extraction of information and perform likelihood-free inference. Furthermore, we analyze the different void properties more completely.
This paper is organized as follows. Section 2 describes the data set and analysis tools used in this paper. It introduces the GIGANTES data set we employ, the algorithm for finding voids, and the definitions for void properties (radius, ellipticity, and density contrast). It also outlines the machine-learning process used for our results. Section 3 presents the results we obtained by training both fully connected neural networks on histograms from void properties and deep sets from void catalogs to perform likelihood-free inference of cosmological parameters. Finally, Section 4 draws the main conclusions of this work, showing that void properties provide valuable information to constrain our model of the Universe.
2. Methods
2.1. The GIGANTES Data Set
In this paper, we train our models on data from GIGANTES, a void catalog suite containing over 1 billion cosmic voids created by running the void finder VIDE (Sutter et al. 2015) on the spatial distribution of halos from the QUIJOTE simulations (Villaescusa-Navarro et al. 2020). VIDE is a well-established public Voronoi-watershed void finder toolkit based on ZOBOV (Neyrinck 2008) and used in a variety of papers (see, e.g., Hamaus et al. 2015, 2016, 2017, 2022; Baldi & Villaescusa-Navarro 2016; Kreisch et al. 2022; Contarini et al. 2022; Douglass et al. 2023). It is the primary tool used to create the GIGANTES data set. While VIDE has a wide variety of features, one of the most important properties is its ability to capture shape, which has proven to be particularly effective in extracting cosmological information (e.g., compared to a spherical void finder; see Kreisch et al. 2022). Different techniques can be used to model voids (see, e.g., Baddeley et al. 2015; Okabe et al. 2000; Colberg et al. 2008; Cautun et al. 2018). Using the Voronoi tessellation and the watershed transform (Platen et al. 2007), VIDE is able to identify voids in dark matter or tracer distributions and provides void information including void position (R.A., decl., redshift, or x, y, z; depending on whether the catalog is from observations and light cones, or from a simulation box), void radius (calculated as

where V is the total volume of the Voronoi cells that the void contains), void ellipticity (see Section 2.2), and void density contrast (see Section 2.2), among others.
GIGANTES is the first data set built for analyzing cosmic voids with machine-learning techniques. It provides void catalogs for over 7000 cosmologies, including fiducial and nonfiducial ones, and covers redshifts z = 0.0, 0.5, 1.0, and 2.0, both in real space and in redshift space. Cosmological parameters {Ωm , Ωb , h, ns , σ8, Mv , w} are varied throughout the simulations.
The data set for our paper is constituted by the void catalogs from the high-resolution QUIJOTE Latin hypercube simulations at z = 0.0. Thus, we have 2000 void catalogs covering a volume of  each, from 2000 cosmological parameters arranged in a Latin hypercube with boundaries defined by
each, from 2000 cosmological parameters arranged in a Latin hypercube with boundaries defined by





On average, each catalog contains about 11,000 voids. The large number of catalogs and voids allows us to train models to perform likelihood-free inference. In this work, we quantify how much information is embedded into (1) the distribution of void ellipticities, (2) the distribution of void density contrasts, and (3) void catalogs that contain radius, ellipticity, and density contrast for each void. We now describe how the ellipticity and density contrast are computed for each void.
2.2. Void Ellipticity and Density Contrast
The ellipticity of a void is computed by VIDE from the eigenvalues and eigenvectors of the inertia tensor (Sutter et al. 2015) and defined as

where J1 and J3 are the smallest and largest eigenvalues of the inertia tensor, which is calculated as

and complemented with cyclic permutations. Here, Npis the number of particles in the void while xi , yi , and zi represent the cartesian coordinates of the particle i with respect to the void macrocenter. The macrocenter in the VIDE algorithm is defined as

where x i and Vi are the positions and Voronoi cell volumes of each particle i in the void (Sutter et al. 2015).
The void density contrast,
5
Δ, is defined
6
as the ratio of the minimum density along the ridge of the void, Δridge, versus the minimum density in the void,  :
:

We show in Figure 1 the ellipticity and density contrast as a function of void radii. The void radii are binned from 10.5 to 61.5 Mpc h−1, and the error bars are the standard deviations of the mean for each bin. For comparison purposes, in Figure 1 we use the same void radius range as in the GIGANTES analysis (Kreisch et al. 2022), that is from 10.5 to 61.5 Mpc h−1. As Figure 1 shows, when the void radius is under 30 Mpc h−1, void ellipticity decreases as the void radius increases. In this range, smaller voids are more elliptical than larger voids. This is also consistent with voids found in the Magneticum simulation (Schuster et al. 2023) and voids in the Sloan Digital Sky Survey Data Release 9 (Sutter et al. 2014b), and with the expectation that small voids are less evolved structures (Sheth & van de Weygaert 2004). For voids with radii larger than 30 Mpc h−1, we notice that an increase in radius leads to a mild increase in the mean values of ellipticity. However, this increase is accompanied by a notable expansion of the error bars, which can be attributed to the scarcity of voids within that range. The bottom panel shows that the void density contrast increases with the void radius. This is likely related to the locations of the detected voids since smaller voids are more commonly found in denser regions or by the edges of the larger voids, corresponding to local overdensities. Therefore, there might be smaller changes in matter density across smaller voids. On the other side, larger voids have usually been evolving for a longer time than small voids (Sheth & van de Weygaert 2004). Therefore, even if dark energy generically has a late-time impact, larger voids were dominated by dark energy earlier than smaller voids. Consequently, dark energy within large voids has had more time to make those voids larger and consequently emptier, causing a greater density contrast. Figures 2 and 3 show examples from our data set of voids with different ellipticities and density contrasts (respectively).

Figure 1. Void density contrast and ellipticity as a function of radii from all the simulations in the high-resolution QUIJOTE Latin hypercube simulations at z = 0.0. The blue dots and error bars represent the mean and the standard deviation in the mean of each bin. Void radii are binned from 10.5 to 61.5 Mpc h−1.
Download figure:
Standard image High-resolution image
Figure 2. Examples of voids with different ellipticities. We use VIDE to find the Voronoi cells of a void and plot the Voronoi cells of each void to show the void geometry. Small spheres inside each void represent its Voronoi cells. We show four randomly selected voids and arrange them by their ellipticities. We note that there is a large variety in the morphology of voids, so the voids shown in the figure should not be seen as representatives of their class.
Download figure:
Standard image High-resolution image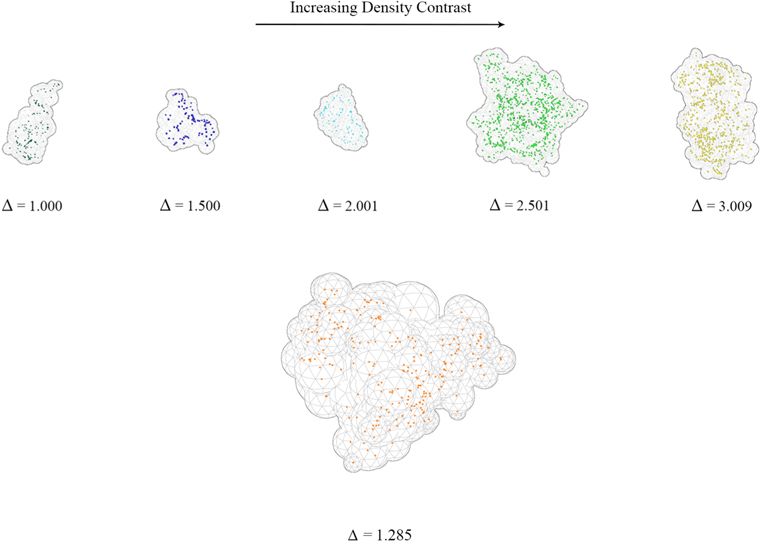
Figure 3. Examples of voids with different density contrasts. The gray wireframes show the geometries of the voids formed by the Voronoi cells of each void, similar to Figure 2. The colored dots inside each void represent halos. Voids in the top row are arranged by increasing density contrast (from left to right). The larger void at the bottom allows a clearer view of a void with a density contrast of 1.285, the mean value in the catalogs.
Download figure:
Standard image High-resolution imageIn our analysis, we do not impose any cut to the voids properties (e.g., only considering voids with ellipticities smaller than a given value) since machine-learning methods can learn to marginalize over features that are not correlated with cosmology (Villaescusa-Navarro et al. 2021).
2.3. Machine Learning
The large GIGANTES data set enables cosmic void exploration with machine-learning methodologies. In this work, we train neural networks to perform likelihood-free inference on the value of five cosmological parameters: {Ωm , Ωb , h, ns , σ8}. We make use of two different architectures that perform likelihood-free inference but whose input is different:
- 1.Fully connected layers. The inputs to these models are one-dimensional arrays. In our case, the data can be either the distribution of void ellipticities or the distribution of void density contrasts.
- 2.Deep sets. The inputs to these models are void catalogs. The catalogs will contain a set of voids (each catalog can have a different number of voids) where each void will be characterized by three properties: (1) ellipticity, (2) density contrast, and (3) radius.
In Figure 4, we provide a visual explanation of these two architectures.
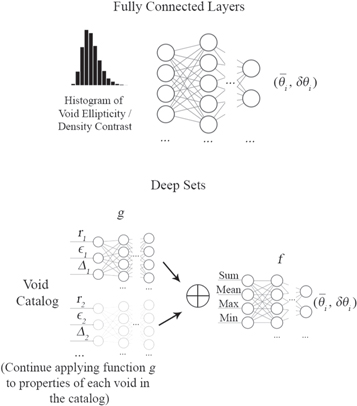
Figure 4. Visualizations of the two machine-learning architectures used in this paper. While fully connected layers are one of the most commonly used neural network architectures, deep sets are able to extract information directly from the void catalog regardless of the number of voids in the catalog. Functions f and g in the deep sets architecture are modeled with fully connected layers.  represents a permutation invariant operation. More details about the deep sets architecture are given in Section 3.3.
represents a permutation invariant operation. More details about the deep sets architecture are given in Section 3.3.
Download figure:
Standard image High-resolution imageThe output of the two models is a one-dimensional array with 10 values (two values per parameter): five numbers for the posterior mean and five numbers for the posterior standard deviation. In order to train the networks to output these quantities, we use the loss function of moment networks (Jeffrey & Wandelt 2020). To avoid problems that arise from different terms having different amplitudes, we use the change described in Villaescusa-Navarro et al. (2022). Thus, the loss function we employ is

where F(x) and G(x) are functions that will output the marginal posterior mean and standard deviation when input x in batch B for the true value of parameters θ. The sum runs over all elements in a given batch and the functions are parameterized as fully connected layers or deep sets as described above. In the next section, we provide further details on the architecture and training procedure.
In order to evaluate the accuracy and precision of the model, we make use of four different statistics: (1) the coefficient of determination(R2), (2) the root mean squared error (RMSE), (3) the mean magnitude of the relative error (MMRE), and (4) the normalized chi-squared, defined as

where mean and standard deviation represent the posterior mean and standard deviation predicted by the model, corresponding to F(x) and G(x) in Equation (11). This measurement is directly related to the second term that we want to minimize in the loss function. The normalized chi-squared is useful to determine whether the error bars are accurately determined: a value larger/smaller than 1 indicates that the errors are underestimated/overestimated. On the other hand, we mostly rely on the R2 values to evaluate the linear correlations between our models' predictions and the true values.
3. Results
In this section, we show the results we obtain when inferring the value of cosmological parameters using the models trained with the different inputs. We split the data set into training (80%), validation (10%), and testing (10%) sets. We choose the best model of each architecture based on the model's performance on the validation set and show the results from the test sets. We first present the results for the histograms, and later we display the results of the deep sets. While the models are trained to infer the value of all five cosmological parameters, they may only be able to infer the value of some of them. In this case, we only display the results for the parameter(s) that can be inferred. We include in the Appendix the plots for cases when our models are not able to infer the parameters.
All of the errors we report correspond to aleatoric errors. We have also estimated the epistemic errors (associated with the error from the network itself) by training 10 different models with the best value of the hyperparameters and computing the standard deviation of the posterior means. We find the epistemic errors to be significantly smaller than the aleatoric ones: for the histograms, they are about one-seventh of the aleatoric ones, while for the deep sets, the ratio is one-third. Since the error budget is dominated by the aleatoric errors, we do not report the value of the epistemic errors.
3.1. Ellipticity Histograms
We start by training fully connected layers on ellipticity histograms that are constructed as follows. First, all the voids in a given simulation are selected. Second, the void ellipticities are assigned to 18 equally spaced bins from  = 0.0 to = 1.0. Next, the number count in each bin is divided by the total number of voids in the considered simulations. In this way, we construct 2000 ellipticity histograms, one per simulation. We further preprocess the data so that each bin has a mean of 0.0 and a standard deviation of 1.0.
= 0.0 to = 1.0. Next, the number count in each bin is divided by the total number of voids in the considered simulations. In this way, we construct 2000 ellipticity histograms, one per simulation. We further preprocess the data so that each bin has a mean of 0.0 and a standard deviation of 1.0.
The architecture of the model consists of a series of blocks that contain a fully connected layer with a LeakyRelu nonlinear activation function and a dropout layer. We note that the last layer only contains a fully connected layer. To find the hyperparameters for our model, we use the TPESampler in Optuna package (Akiba et al. 2019) to perform Bayesian optimization over the following ranges of each hyperparameter:
- 1.Number of hidden layers ∈ [1, 5].
- 2.Number of neurons in each hidden layer ∈ [4, 1000].
- 3.Learning rate ∈ [0.1, 1.0 × 10−5].
- 4.Weight decay ∈ [1.0, 1.0 × 10−8].
- 5.Dropout rate ∈ [0.2, 0.8].
The optimization is carried out by minimizing the validation loss for a total of 1000 trials. For each trial, the training is performed through gradient descent using the AdamW optimizer (Loshchilov & Hutter 2017) for 1000 epochs and a batch size of 128.
We find that the model trained on ellipticity histograms can only infer the value of Ωm , and we show the results of inferring the value of this parameter from the ellipticity histograms of the test set in the top row of Figure 5. We find that the model is able to infer the value of Ωm with an RMSE value of 0.06 and a mean relative error of 19%. We report the values of the four accuracy metrics in Table 1.
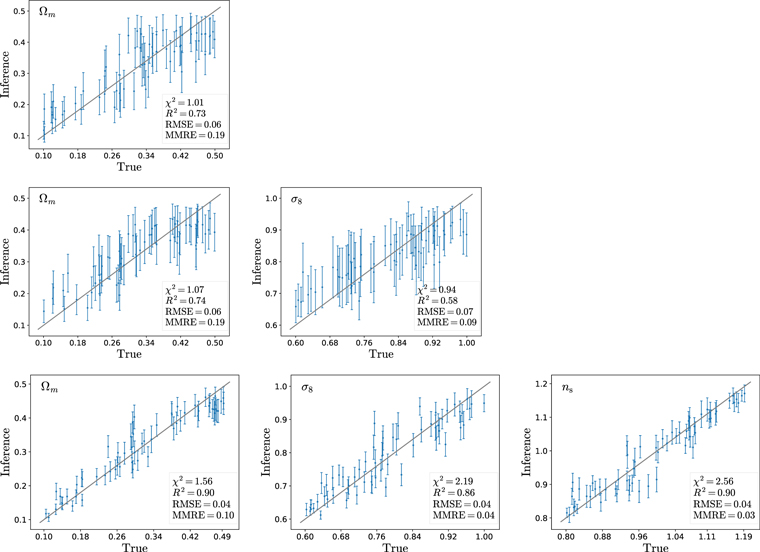
Figure 5. We train different models to perform likelihood-free inference on the value of the cosmological parameters. Top row: we use fully connected layers to infer the value of Ωm from histograms that describe the distribution of void ellipticities. Middle row: we train fully connected layers to infer the value of Ωm and σ8 from the histograms that characterize the distribution of the density contrast of voids. Bottom row: we train deep sets on void catalogs to infer the value of Ωm , σ8, and ns . Our model takes a void catalog as input (containing all the voids in a given simulation), where every void is characterized by three properties: (1) ellipticity, (2) density contrast, and (3) radius. In all the cases, the models predict the posterior mean and standard deviation for each parameter. As expected, deep sets perform better than the histogram models. The bottom right part of the panels shows the accuracy metrics calculated from all the results obtained from the 198 values in the testing set. We find that the deep set model is able to infer the correct value of Ωm (left column), σ8 (middle column), and ns (right column) with a mean relative error of 10%, 3%, and 4%, respectively.
Download figure:
Standard image High-resolution imageTable 1. Accuracy Metrics on the Considered Cosmological Parameters Achieved from the Various Methods and Data Sets Used in This Work
| Type | Histograms | Deep Sets | ||||
|---|---|---|---|---|---|---|
| Void Property | Ellipticity | Density Contrast | Ellipticity, Density Contrast, Radius | |||
| Parameter | Ωm | Ωm | σ8 | Ωm | ns | σ8 |
| χ2 | 1.01 | 1.07 | 0.94 | 1.56 | 2.56 | 2.19 |
| R2 | 0.73 | 0.74 | 0.58 | 0.90 | 0.90 | 0.86 |
| RMSE | 0.06 | 0.06 | 0.07 | 0.04 | 0.04 | 0.04 |
| MMRE | 0.19 | 0.19 | 0.09 | 0.10 | 0.03 | 0.04 |
Download table as: ASCIITypeset image
3.2. Density Contrast Histograms
We also train fully connected layers on density contrast histograms, which are constructed and standardized in the same way as the ellipticity histograms. They contain 18 bins equally spaced from Δ = 1.0 to Δ = 3.0. The model architecture, training procedure, and hyperparameter tuning are the same as the ones outlined above.
In this case, we find that the model is able to infer both Ωm and σ8. We show the results of this model in the middle row of Figure 5. For Ωm , the accuracy and precision of the model are comparable to the one achieved by the model trained on ellipticity histograms. For σ8, the model can infer its value with a mean relative error of 9%. From the values of the χ2, we can conclude that the magnitudes of the error bars are well estimated. Looking at the value of the R2, we can see that the estimate of Ωm is more accurate than the estimate of σ8. We report all the accuracy metrics in Table 1.
We have also trained neural networks using both ellipticity and density contrast histograms. In this case, the input to the network is a one-dimensional vector with 36 dimensions: 18 from the ellipticity histogram and 18 from the density contrast histogram. Using this setup, we find similar results as the ones we obtain using the density contrast histograms, possibly indicating that the information in the two statistics may be somewhat redundant.
3.3. Deep Sets
We now illustrate a different architecture to extract information from the void catalogs directly. In this work, we are not quantifying the cosmological information encoded in the clustering of voids, but just on their intrinsic properties. For this reason, we make use of deep sets (Zaheer et al. 2017): an architecture that is able to work with sets of objects whose number may vary from set to set. Each object in the set has a collection of properties associated with it, p . Our goal is to train a model on void catalogs, to perform likelihood-free inference on the value of the cosmological parameters θ .
Our model will take all the voids in a given simulation as input and output the posterior mean ( ) and standard deviation (δ
θi
) of the cosmological parameter i. Every void is characterized by three numbers: (1) its ellipticity, (2) its density contrast, and (3) its radius. We relate the input and the output through
) and standard deviation (δ
θi
) of the cosmological parameter i. Every void is characterized by three numbers: (1) its ellipticity, (2) its density contrast, and (3) its radius. We relate the input and the output through

where f and g are neural networks (in this case fully connected layers) and  is a permutation invariant operation that applies to all the elements in the deep sets. In our case, we use four different permutation invariant operations: (1) the sum, (2) the mean, (3) the maximum, and (4) the minimum. The result of these four operations is concatenated before being passed to the last fully connected layer f.
is a permutation invariant operation that applies to all the elements in the deep sets. In our case, we use four different permutation invariant operations: (1) the sum, (2) the mean, (3) the maximum, and (4) the minimum. The result of these four operations is concatenated before being passed to the last fully connected layer f.
The neural networks g and f are parameterized as three and four fully connected layers where the number of neurons in the latent space is considered as a hyperparameter. We use the LeakyRelu activation functions with slope −0.2 in all layers but the last. We train the model for 2000 epochs with a batch size of six using the same loss function in Equation (11) in order to perform likelihood-free inference.
Similar to the hyperparameter optimization process of the fully connected layers, we use Optuna to perform Bayesian optimization for the deep sets model. The ranges of the hyperparameters are defined below:
- 1.Number of neurons in each hidden layer ∈ [10, 1000].
- 2.Learning rate ∈ [1.0 × 10−4, 1.0 × 10−8].
- 3.Weight decay ∈ [1.0 × 10−3, 1.0 × 10−12].
Here, we only perform 50 trials to optimize hyperparameters because of the longer training time. Optuna is run to minimize the value of the validation loss. While we train the model to predict the value of the five cosmological parameters we consider, we find that we are only able to infer the value of Ωm , ns , and σ8. We show the results in Figure 5.
Our model is able to infer the value of Ωm , ns , and σ8 with a mean relative error of approximately 10%, 3%, and 4%, respectively. This represents a significant improvement over the results we obtained using histograms of the void ellipticities or density contrasts, and is also reflected in the values of the R2 statistics. This is of course expected, given that with a sufficiently complex model, this method will not throw away information when we input the data to the networks. 7 We note that for ns and σ8, our model achieves a slightly high value of χ2. We have checked that this is mainly driven by a single void catalog that has a slightly extreme cosmology. If we had removed this catalog, the obtained χ2 would be much closer to 1. Thus, we think our error bars are not strongly underestimated.
The reason for unsuccessful predictions could simply be the lack of information in the data sets we are using. However, we note that the parameter Ωb will only change the amplitude and shape of the initial power spectrum in N-body simulations. Other works have shown that this effect is smaller than the ones induced by other parameters, such as Ωm and σ8 (see, e.g., Uhlemann et al. 2020).
We note that these results could be further improved if more void properties were to be used, or if the network would exploit clustering information (Makinen et al. 2022; Shao et al. 2022; Villanueva-Domingo & Villaescusa-Navarro 2022).
4. Conclusions
In this work, we have shown how to connect void properties to the value of cosmological parameters through machine learning. We have trained several models to perform likelihood-free inference on the value of cosmological parameters from several void properties. We find that each individual property—ellipticity and density contrast—is sensitive to cosmological parameters and that their combination with void radius yields the tightest constraints.
Currently, void ellipticity has not been used to extract constraints from data, due to the lack of robust modeling for the considered void properties. However, other void statistics have been used to provide constraints from data that showcase the constraining power of voids. The void-galaxy cross-correlation function has been used to constrain Ωm
(Hamaus et al. 2020), finding a value of 0.310 with a relative error of 5% (compared to the reference value 0.315 ± 2% in Planck Collaboration et al. 2020). This work relies on data from the BOSS survey (Alam et al. 2017), whose volume is much larger than the volume of the simulation box we used in this work—it is, therefore, expected that we have a larger error. The void size function has also been used to constrain cosmological parameters in the BOSS survey, obtaining  and
and  constraints (Contarini et al. 2023).
constraints (Contarini et al. 2023).
We note that there are several caveats in this work. First, we have identified voids from the spatial distribution of dark matter halos in real space. A more realistic exercise will be to find voids from galaxies in redshift space. Second, we have assumed that the considered void properties are robust to uncertainties from N-body codes and hydrodynamic effects. While dark matter halo positions and velocities have been found to be robust to these effects (Shao et al. 2022), the same exercise needs to be performed for the void properties considered in this work (see also Schuster et al. 2023). Third, we have neglected the effect of super-sample covariance in our analysis due to the finite volume of the QUIJOTE simulations. However, a recent study has shown that the effect of super-sample covariance on the void size function is small (Bayer et al. 2023).
We emphasize that in this work we have only attempted to extract information from a few void properties. Our constraints can be improved by using more void properties (e.g., the number of galaxies in a void, or the value of the external tidal tensor affecting the void), or by exploiting the clustering of voids (e.g., by using graph neural networks; see Makinen et al. 2022; Shao et al. 2022; Villanueva-Domingo & Villaescusa-Navarro 2022), which we leave for future work.
Additionally, in future work, we plan to investigate if combining void properties with traditional clustering statistics (e.g., halo power spectrum) yields tighter constraints on the value of cosmological parameters or whether the cosmic void information is somehow redundant to what machine learning can extract from traditional statistics. Finally, the distribution of void ellipticity was proven to be sensitive to the dark energy equation of state parameters (w0 and wa ) as well (Biswas et al. 2010): it would, therefore, be interesting to use the methods presented in this paper to constrain the dark energy equation of state parameters and compare constraints from machine learning to those from the Fisher forecasts in Biswas et al. (2010). Since the data set we use here does not vary w0 and wa , we leave this for future work.
This work sets the path for future research directions. We have shown that void properties encode information about the value of cosmological parameters and that machine learning provides access to that information. If the challenges discussed above can be controlled, we could train these methods on voids from numerical simulations and test them on voids from large-scale surveys, such as DESI (DESI Collaboration et al. 2016), Euclid (Laureijs et al. 2011), Roman (Spergel et al. 2015), SPHEREx (Doré et al. 2018), and Subaru Prime Focus Spectrograph (Tamura et al. 2016), in order to extract cosmological information about our Universe.
Acknowledgments
We thank Allister Liu, Samuel Keene, Wenhan Zhou, and Carolina Cuesta-Lazaro for helpful discussions and suggestions for this work. The Center for Computational Astrophysics at the Flatiron Institute is supported by the Simons Foundation.
Appendix: Unsuccessful Inferences
Figures 6–8 show the plots where our machine-learning models are unable to predict the parameters.

Figure 6. Plots representing the results for the unconstrained parameters using fully connected layers with density contrast histograms.
Download figure:
Standard image High-resolution image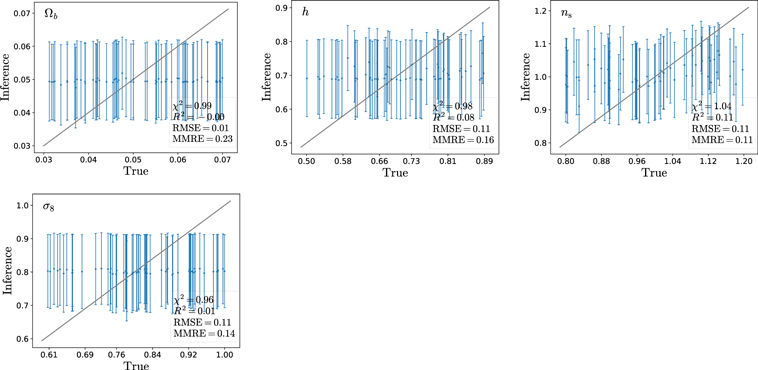
Figure 7. Plots representing the results for unconstrained parameters using fully connected layers with ellipticity histograms.
Download figure:
Standard image High-resolution image
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Figure 8. Plots representing the results for the unconstrained parameters using deep sets with void radius, ellipticity, and density contrast all together.
Download figure:
Standard image High-resolution image{kind=link}
{kind=link}
Footnotes
- 5
In Sutter et al. (2015), r is used to represent void density contrast. However, to avoid confusion with radius, we use here Δ instead of r for the void density contrast.
- 6
This definition for the density contrast is used by ZOBOV, by VIDE, and consequently, in the GIGANTES catalogs.
- 7
When we use histograms, we are losing information as we can only sample the distribution with a finite number of bins.