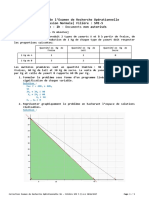
Corr TP2
Corr TP2
Télécharger au format pdf ou txt
Vous aimerez peut-être aussi
- Exo 0 Grue D'atelierDocument3 pagesExo 0 Grue D'atelierlino.plantePas encore d'évaluation
- TP03Document4 pagesTP03Ouahiba AhmidPas encore d'évaluation
- Compte-Rendu 2 POODocument3 pagesCompte-Rendu 2 POOAbdelbaki MissaouiPas encore d'évaluation
- TP4 ClassificationSupervisée StudentDocument11 pagesTP4 ClassificationSupervisée Studentmohamed anouar hassinePas encore d'évaluation
- Corr TP3Document15 pagesCorr TP3slim yaichPas encore d'évaluation
- Corr TP1Document11 pagesCorr TP1hamdi rebaiPas encore d'évaluation
- Ilovepdf MergedDocument99 pagesIlovepdf Mergedslim yaichPas encore d'évaluation
- Exercices: Abscisse Et Ordonnee) de Nouvelles Fonctions MembreDocument8 pagesExercices: Abscisse Et Ordonnee) de Nouvelles Fonctions MembreIlyas BennajehPas encore d'évaluation
- Chapitre 2 Manipulation DonneesDocument9 pagesChapitre 2 Manipulation DonneesPape Moussa DiopPas encore d'évaluation
- tp2 IA ML (ML) VxAliDocument7 pagestp2 IA ML (ML) VxAliachrefPas encore d'évaluation
- Analyse Des DonnéesDocument8 pagesAnalyse Des DonnéesAmira SaadaPas encore d'évaluation
- Ingénierie Numérique Et SimulationDocument36 pagesIngénierie Numérique Et Simulationnj100% (1)
- Travaux Dirigés 1 Les Bases Du Langage R: Master MIAGE S9 PR Aicha MAJDA FSJES Meknes 2023-2024Document6 pagesTravaux Dirigés 1 Les Bases Du Langage R: Master MIAGE S9 PR Aicha MAJDA FSJES Meknes 2023-2024omaymaPas encore d'évaluation
- Cours C++ (Complet)Document58 pagesCours C++ (Complet)abdoulPas encore d'évaluation
- TP - Python & MysqlDocument4 pagesTP - Python & MysqlParfait AYIPas encore d'évaluation
- Chap5 RécursivitéDocument5 pagesChap5 RécursivitéMohamed aminePas encore d'évaluation
- SAD - Chap 2Document83 pagesSAD - Chap 2Gazdallah AmiraPas encore d'évaluation
- TP PandasDocument12 pagesTP PandasHendou MohamedPas encore d'évaluation
- TP ScalaDocument2 pagesTP ScalafafaPas encore d'évaluation
- Cours XMLDocument175 pagesCours XMLNour EnPas encore d'évaluation
- TP SpinDocument4 pagesTP SpinAnonymous JJR7TduPas encore d'évaluation
- Les PointeursDocument15 pagesLes PointeursAmira GharbiPas encore d'évaluation
- Etude de Cas UmlDocument2 pagesEtude de Cas UmlSafae BelkhyrPas encore d'évaluation
- Algorithmique Et Structures de Donnees Les Listes Simplement ChaineesDocument7 pagesAlgorithmique Et Structures de Donnees Les Listes Simplement ChaineesKaouther KhalilPas encore d'évaluation
- Examen ASD MPI Janvier 2020Document3 pagesExamen ASD MPI Janvier 2020Mariem KsontiniPas encore d'évaluation
- Corr TP RévisionDocument6 pagesCorr TP Révisionslim yaichPas encore d'évaluation
- TD Machine Regression PythonDocument3 pagesTD Machine Regression Pythontest testPas encore d'évaluation
- Inteligence ArtificielDocument37 pagesInteligence ArtificielBruno Ndazoa0% (1)
- Design PatternDocument10 pagesDesign PatternMoustapha BERPas encore d'évaluation
- TP Compilation CorrectionDocument22 pagesTP Compilation Correctionhaifahelawi20010% (1)
- Correction TP Initiation RDocument22 pagesCorrection TP Initiation Rgerald904640Pas encore d'évaluation
- td1 Solution PDFDocument7 pagestd1 Solution PDFtestttPas encore d'évaluation
- TP Python BDDDocument4 pagesTP Python BDDcastle.lili1009Pas encore d'évaluation
- TD 1 SDDocument4 pagesTD 1 SDAyoub BenPas encore d'évaluation
- TP0 Debuter Avec Le Language CDocument21 pagesTP0 Debuter Avec Le Language CSana RefaiPas encore d'évaluation
- TP1 Java AvanceDocument34 pagesTP1 Java AvanceKukuMaluPas encore d'évaluation
- Designs PatternsDocument23 pagesDesigns PatternsBrahim Ben SaadaPas encore d'évaluation
- Chapitre 5 - Apprentissage Par RenforcementDocument27 pagesChapitre 5 - Apprentissage Par RenforcementChaima BelhediPas encore d'évaluation
- Python - Les ClassesDocument24 pagesPython - Les ClassesMounir NidaliiPas encore d'évaluation
- Java FX Partie5Document44 pagesJava FX Partie5ÄnÂss FîQhîPas encore d'évaluation
- DS GLDocument2 pagesDS GLabdallah ben zribiaPas encore d'évaluation
- TD JavaDocument3 pagesTD Javakasraouizied100% (1)
- TD4 Igl1 2023 CorrigeDocument4 pagesTD4 Igl1 2023 Corrigedeutchayvan36Pas encore d'évaluation
- Cours GL ModelisationDocument193 pagesCours GL Modelisationkhaled19lmdPas encore d'évaluation
- Cours Patron Partie 4Document19 pagesCours Patron Partie 4Houda TekayaPas encore d'évaluation
- Dzi5u-7 Les Diagrammes de ComposantsDocument22 pagesDzi5u-7 Les Diagrammes de ComposantsColmain NassiriPas encore d'évaluation
- Commandes HadoopDocument5 pagesCommandes HadoopOumayma TajirPas encore d'évaluation
- TP Intégration Des DonnéesDocument2 pagesTP Intégration Des Donnéeskevin landryPas encore d'évaluation
- Cours HeritageDocument37 pagesCours HeritageCha MaàPas encore d'évaluation
- TP 4 HeritageDocument2 pagesTP 4 HeritageAdil SoufiPas encore d'évaluation
- Proposition de Corrigé IADocument9 pagesProposition de Corrigé IADahouiPas encore d'évaluation
- Analyse de Donnees-ACPDocument20 pagesAnalyse de Donnees-ACPReine Manuela Kuigoua KwetoPas encore d'évaluation
- RAPPORTDocument70 pagesRAPPORTAnonymous uzzfJo8sPas encore d'évaluation
- Java FX Partie6Document50 pagesJava FX Partie6ÄnÂss FîQhîPas encore d'évaluation
- TP5 - Poo.Document6 pagesTP5 - Poo.HAMZA TAHIRIPas encore d'évaluation
- Tp2: Agrégats Dans MongodbDocument6 pagesTp2: Agrégats Dans MongodbIam MePas encore d'évaluation
- Exercices Optimisation RépartieDocument1 pageExercices Optimisation RépartieDjihan FerrPas encore d'évaluation
- Manuel Exos Tech WebDocument53 pagesManuel Exos Tech WebYouness Nachid-Idrissi0% (1)
- DevoirDocument2 pagesDevoirCado YaPas encore d'évaluation
- TD CorrigéDocument19 pagesTD Corrigéabdelaati wafaPas encore d'évaluation
- TP 2Document3 pagesTP 2slim yaichPas encore d'évaluation
- Output 15Document8 pagesOutput 15slim yaich100% (1)
- CorrectionDocument5 pagesCorrectionslim yaichPas encore d'évaluation
- SujetDocument6 pagesSujetslim yaichPas encore d'évaluation
- Corr TP RévisionDocument6 pagesCorr TP Révisionslim yaichPas encore d'évaluation
- TP 3Document5 pagesTP 3slim yaich0% (1)
- SQL Server Integration Services: Versions 2019 À 2012Document2 pagesSQL Server Integration Services: Versions 2019 À 2012slim yaichPas encore d'évaluation
- TP 1Document2 pagesTP 1slim yaichPas encore d'évaluation
- Chapitre1 SE GIDocument25 pagesChapitre1 SE GIslim yaichPas encore d'évaluation
- COURS ENTREPRENEURIAT IIT VEF S1 22 23 VEF-compresse-2 RotatedDocument20 pagesCOURS ENTREPRENEURIAT IIT VEF S1 22 23 VEF-compresse-2 Rotatedslim yaichPas encore d'évaluation
- Chapitre 2 - VirtualisationDocument88 pagesChapitre 2 - Virtualisationslim yaichPas encore d'évaluation
- ChapitreAteliers SSISDocument41 pagesChapitreAteliers SSISslim yaichPas encore d'évaluation
- Chap3 SEDocument26 pagesChap3 SEslim yaichPas encore d'évaluation
- SQL Server - Implémenter Un DataWarehouseDocument2 pagesSQL Server - Implémenter Un DataWarehouseslim yaichPas encore d'évaluation
- Quatlites Et Valeurs DentrepreneuriatDocument37 pagesQuatlites Et Valeurs Dentrepreneuriatslim yaichPas encore d'évaluation
- SQL Server, Business Intelligence: Cours Pratique de 5 Jours Réf: SBU - Prix 2022: 3 190 HTDocument3 pagesSQL Server, Business Intelligence: Cours Pratique de 5 Jours Réf: SBU - Prix 2022: 3 190 HTslim yaichPas encore d'évaluation
- Corrige Exam 2013Document2 pagesCorrige Exam 2013slim yaichPas encore d'évaluation
- Brochure Mini Master - BI & Data Analysis - Job SkillZDocument9 pagesBrochure Mini Master - BI & Data Analysis - Job SkillZslim yaichPas encore d'évaluation
- Output 4Document3 pagesOutput 4slim yaichPas encore d'évaluation
- Output 6Document6 pagesOutput 6slim yaichPas encore d'évaluation
- Output 14Document5 pagesOutput 14slim yaich100% (1)
- Entrepôt de DonnéesDocument24 pagesEntrepôt de Donnéesslim yaichPas encore d'évaluation
- Output 12Document3 pagesOutput 12slim yaich100% (1)
- CTRL DM m2 2011Document5 pagesCTRL DM m2 2011slim yaichPas encore d'évaluation
- Ex Amen FDA Ratt 2016Document6 pagesEx Amen FDA Ratt 2016slim yaichPas encore d'évaluation
- Ex Amen FDA 2016Document7 pagesEx Amen FDA 2016slim yaichPas encore d'évaluation
- Aide Mémoire de Certaines Commandes Linux PDFDocument10 pagesAide Mémoire de Certaines Commandes Linux PDFMohammed ZaryouchPas encore d'évaluation
- Cours Mec FluorescenceDocument54 pagesCours Mec FluorescenceAlain BeauPas encore d'évaluation
- TP Excel Les Fonctions Logiques N3Document2 pagesTP Excel Les Fonctions Logiques N3kahighojucie100% (2)
- Sia Go To Sleep PianoDocument4 pagesSia Go To Sleep PianohotpaganiniPas encore d'évaluation
- Introduction A L'econometrie Luxembourg 2008-2009Document335 pagesIntroduction A L'econometrie Luxembourg 2008-2009Wajdi FrikhaPas encore d'évaluation
- Chapitre III - Alimentation D'un Entrepôt de DonnéesDocument19 pagesChapitre III - Alimentation D'un Entrepôt de DonnéesfsaidaniPas encore d'évaluation
- Cours Reperage Et Configuration Du PlanDocument6 pagesCours Reperage Et Configuration Du PlanthierryPas encore d'évaluation
- Mathématique-Groupe de Répétition Le Quantique-Probatoire Blanc N°1 Série CD - CamerounDocument2 pagesMathématique-Groupe de Répétition Le Quantique-Probatoire Blanc N°1 Série CD - Cameroungillesngouana1Pas encore d'évaluation
- Compte Rendu TP1 Mohamed Ouni 3éme Info G2Document17 pagesCompte Rendu TP1 Mohamed Ouni 3éme Info G2benzemaouni2001Pas encore d'évaluation
- Compte Rendu Des Epreuves Ecrites 2006Document96 pagesCompte Rendu Des Epreuves Ecrites 2006Mus ChrifiPas encore d'évaluation
- SEQ 5 - Stabilité Des Entités ChimiquesDocument4 pagesSEQ 5 - Stabilité Des Entités ChimiquesSpectre UnPas encore d'évaluation
- TD N° 5 InterpolationDocument2 pagesTD N° 5 InterpolationSaf MelhaouiPas encore d'évaluation
- Memento JCLDocument2 pagesMemento JCLKamel SadkiPas encore d'évaluation
- Equations InequationDocument5 pagesEquations Inequationamine ismaili alaouiPas encore d'évaluation
- IntegrationDocument3 pagesIntegrationtarekPas encore d'évaluation
- Triangles Cours de Maths en 5eme Avec Lecon en Cinquieme en PDFDocument6 pagesTriangles Cours de Maths en 5eme Avec Lecon en Cinquieme en PDFRi TalPas encore d'évaluation
- TP Hec - RasDocument10 pagesTP Hec - RasnouhailaPas encore d'évaluation
- Cercle Harmonie PDFDocument3 pagesCercle Harmonie PDFNicolas Deleury100% (1)
- Srit1 Initiation A L'algorithmique 2016 Chapitre 1 Notion de Base TermineDocument11 pagesSrit1 Initiation A L'algorithmique 2016 Chapitre 1 Notion de Base TermineAbdul Jalil SanaPas encore d'évaluation
- Cours 2 Fevrier - Ampli Differentiel Et InstrumentationDocument27 pagesCours 2 Fevrier - Ampli Differentiel Et InstrumentationfdemamiPas encore d'évaluation
- Excorr SN RO SMI5 1617Document5 pagesExcorr SN RO SMI5 1617anasPas encore d'évaluation
- Examen BlancDocument12 pagesExamen BlancDessou Jean-marcPas encore d'évaluation
- CM1 - Mef - GCCD 2023-2024Document191 pagesCM1 - Mef - GCCD 2023-2024samakaPas encore d'évaluation
- LoisDocument2 pagesLoisthegsaad2Pas encore d'évaluation
- DOSSIER TECHNIQUE Theo ZUFFI Final VersionDocument7 pagesDOSSIER TECHNIQUE Theo ZUFFI Final VersionTheo OzPas encore d'évaluation
- Séance TP1 Doc ÉlèvesDocument2 pagesSéance TP1 Doc Élèvesrecompense-promenades0dPas encore d'évaluation
- Introd CompositesDocument44 pagesIntrod CompositesFradjPas encore d'évaluation
- J Lacan Acte Analytique Valas CompletDocument271 pagesJ Lacan Acte Analytique Valas CompletCarlos LoboPas encore d'évaluation
- 2021-2022 2a Appromecaphy TPDocument3 pages2021-2022 2a Appromecaphy TPbergerPas encore d'évaluation