[Execution state] complete ledger - using maxDepthTouched instead of maxDepth metric #1747
Comments
|
This should save about 640MB over a 30GB checkpoint, which is indeed non-negligible. I can get started on this task whenever you give me the green light. One caveat though is that this change would mean that the Since other tasks within this epic will also likely impact the encoding format however, I think this is a non-issue, but please let me know if I am making any wrong assumptions there. |
|
The current situation is that:
Ideally I think we want to change this so that the This means we have a few options to set the trie's attribute when we update, none of which seem ideal to me:
There are probably other solutions I'm missing, so feel free to suggest them if you have ideas, or to tell me which one is the most convenient of the aforementioned three. In our implementation in the Flow DPS, we went with the first approach, and have a |
|
Hi @Ullaakut
I agree. Out of the three options, I like option 3 (using callback) even though it adds another argument to the Maybe to keep it simple, callback function only needs to be called when creating new (compact) leaf. Instead of updating |
|
Hi @fxamacker, I am fine with going this way then sure, but I'm curious about your thoughts on the solution #1 here? It seems to me like while it is overkill for this specific task, having the |
|
Hi @Ullaakut, I have two concerns about option #1.
In DPS, the In Flow, mtrie being immutable allows us to create mtrieB from mtrieA, and still have mtrieA available. I think this and maybe other aspects might be difficult to achieve by attaching update function to the trie. Please let me know what you think. Maybe I misunderstood or missed something. |
|
Hi @fxamacker, thanks for your detailed answer! Are there lots of cases where the trie needs to be immutable in Flow? We got around this on our side by, in the only case where we want to create an Either way, I am fine with the callback, so we can most definitely go for that :) |
|
Hi @Ullaakut,
Unless I'm mistaken, it seems changes to In the following code blocks from DPS trie, https://github.com/optakt/flow-dps/blob/trie-improvements/service/mapper/transitions.go#L374-L377 // We then apply the update to the relevant tree, as retrieved from the
// forest, and save the updated tree in the forest. If the tree is not new,
// we should error, as that should not happen.
paths, payloads := pathsPayloads(update)
newTree := trie.NewTrie(t.log, tree.RootNode(), tree.Store())
for i := range paths {
newTree.Insert(paths[i], payloads[i])
}// NewTrie creates a new trie using the given root node and payload store.
func NewTrie(log zerolog.Logger, root Node, store dps.Store) *Trie {
t := Trie{
log: log.With().Str("subcomponent", "trie").Logger(),
root: root,
store: store,
}
return &t
} |
|
Hi @fxamacker! Thanks for your quick and thoughtful answers :) As shown in this test where we compare the FlowGo approach and the FlowDPS approach, both result in not mutating the original trie. Unless I made a mistake in my methodology? But it seems to me like the way FlowGo updates a trie is essentially the same, it basically creates a new trie (effectively a wrapper around the root node) from the same root node. Or did I miss something there? I'm curious because I didn't spend much time thinking about it and I am not sure why it actually works and does not mutate the original trie, in both cases. To me it seems like since we're dealing only with pointers, as long as we reuse the pointer of the root node of one trie to made modifications to the trie, both tries should be changed, but effectively it seems not to be the case since calling |
|
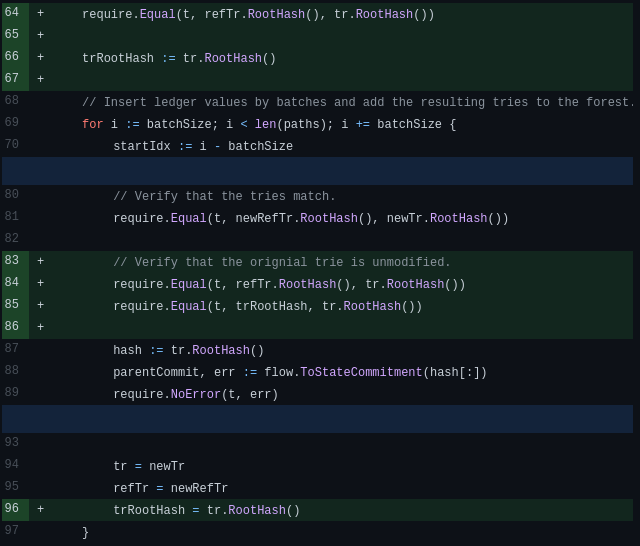
Hi @Ullaakut, thanks for the followup and extra details. Your link to DPS forest_integration_test.go was very helpful. I added extra comparison checks to forest_integration_test.go in DPS. Running the updated test indicates mutability. Changes to DPS forest_integration_test.go are at https://github.com/fxamacker/flow-dps/pull/1/files and this diff includes line 84 shown in the test error trace.
|
|
@fxamacker Indeed, my methodology was completely wrong 😄 It makes total sense then. That might be the reason behind a mismatch I failed to identify, so I'll look into fixing it to make the mechanism preserve immutability. Thanks for the clear explanations, it really helps :) |
Currently, each node holds a uint64 for the regCount and a uint16 for a maxDepth. The first one captures the number of registers s and the second one captures the maximum depth under that subtree. the maxDepth can be replaced with an update level metric that captures the maximum depth that was reached during the update without the nodes keeping the information about the maxDepth.
by removing that value from the intermediate nodes we can save a good amount of memory
The text was updated successfully, but these errors were encountered: