

2022年も、人工知能の分野は急速に発展しました。本記事では、最新の深層学習の論文を何百本と読み解いて分かった「2022年の最重要トレンド」を詳細な参考文献と共に紹介します。人工知能の分野は、進歩が早くてキャッチアップが大変ですが、本記事を読めば、大まかなトレンドと重要研究をおさえられるように書きました。なお、厳密には 2022年に発表されたものではなくても、トレンドを理解する上で重要な論文は全て含めるようにしています。
1. Stable Diffusion

2022年の人工知能業界におけるトップニュースは、間違いなくこの「Stable Diffusion」でしょう。任意のテキストから画像を生成できる自由度や、生成される画像のクオリティの高さに加え、ソースコードおよびモデルが全てオープンソースとして公開されており、AI 業界およびアート業界に強いインパクトを与えました。またその後、生成の質を改善し、数々の機能を追加した Stable Diffusion バージョン 2 およびバージョン 2.1 も公開されています。
技術的には、Stable Diffusion は、テキストと画像の類似度をとらえる CLIP (Radford et al., 2021) と、潜在空間上で高解像度・高速な生成を実現する拡散モデル LDM (Latent Diffusion Model; Rombach et al., 2021) を組み合わせたものです。どちらも 2021 年に既に発表されたものですが、Stable Diffusion は、LAION-Aesthetics と呼ばれる「美しい」画像のみを集めたデータセットを用いて訓練されているという特徴があります。
なお、Stable Diffusion の技術的背景や、理解するための論文解説等については、以下の記事で詳しく解説しましたのでそちらをご覧ください (ちなみに、本記事の冒頭のカバー画像も、Stable Diffusion 2.1 を使って生成したものです)。
 萩原 正人
萩原 正人
2. 拡散モデル (画像・ビデオ生成)

上述の Stable Diffusion のコア技術が、拡散モデル (diffusion model) です。拡散モデルの研究開発は、2020年〜2021年から大きく盛り上がっており、ここ最近では最も「ホットな」手法だと言えましょう。2022年は、特にこの拡散モデルによる画像およびビデオ生成の質が大きく向上した年でした。
画像生成については、OpenAI による DALL·E 2 (Ramesh et al., 2022)、Google による Imagen (Saharia et al., 2022) が、拡散モデルにより非常に高画質の画像生成を実現して話題になりました。また、これ自体は拡散モデルではないのですが、Google から画像生成モデル Parti (Yu et al., 2022) も発表されています。
さらに、拡散モデルを用いて動画 (ビデオ) を生成する手法もいくつか立て続けに発表されました。代表的なものに、Google から発表された Imagen Video (Ho et al., 2022) および Meta から発表された Make-A-Video (Singer et al., 2022) があります。また、こちらは拡散モデルではありませんが、同時期に Google から発表された Phenaki (Villegas et al., 2022) や、清華大学の CogVideo (Hong et al., 2022) 等も、高品質のビデオ生成を達成しています。
拡散モデルの発展とともに、拡散モデルを応用した画像生成・編集手法も数多く提案されています。代表的なものに、「画像」を単語に変換して概念を指定する「反転」拡散モデル (Gal et al., 2022) や、テキストによる自由な画像編集を実現した Imagic (Kawar et al., 2022) などがあります。また、LAION-5B など、超大規模な画像・テキストデータセットの公開も、オープンな研究開発を後押ししています。
拡散モデルについては、その理論についても発展が続いています。代表的なものに、拡散確率モデル (DPM) の後ろ向き過程の分散を解析的に解いて高速・高品質の生成を可能にした Analytic-DPM (Bao et al., 2022)、拡散モデルを統一的に比較・改善した EDM (Karras et al., 2022) などがあります。
藤井 亮宏 藤井 亮宏
藤井 亮宏 藤井 亮宏
藤井 亮宏
3. 拡散モデル (その他のドメイン)

拡散モデルが画像・ビデオ生成分野において目覚ましい発展を遂げるのと同時に、他ドメイン・分野への応用が進んでいます。以下は、2022年に発表された代表的な拡散モデルベースの生成手法です。
- 言語
- 単語ベクトルを拡散モデルで生成する言語モデル Diffusion-LM (Li et al., 2022)
- 「アナログのビット」拡散モデルで離散データを生成するビット拡散 (bit diffusion; Chen et al., 2022)
- 拡散モデルを系列変換に適用できるようにした DiffuSeq (Gong et al., 2022)
- 音声・音楽
- 拡散モデルを使ってテキストからオーディオを生成する Diffsound (Yang et al., 2022)
- 複数パートの音符表現から音楽を生成する Spectrogram Diffusion (Hawthorne et al., 2022)
- 音楽のスペクトグラムを画像と見なしてテキストから音楽を生成する Riffusion
- 3D モデル
- 2D の拡散モデルのみを用いて 3D モデルを生成する DreamFusion (Poole et al., 2022)
- 高品質・高解像度の 3D メッシュモデルを生成する Magic3D (Lin et al., 2022)
- テキストから高速に 3D ポイントクラウドを生成する Point-E (Nichol et al., 2022, オープンソース実装)
ドメインによっては、生成の品質が従来手法 (例えば、自己回帰的なトランスフォーマー) に匹敵する場合も見られ、今後も生成モデルの選択肢の一つとして存在感を増していくものと考えられます。
萩原 正人 萩原 正人
萩原 正人
4. ChatGPT

OpenAI から 11月末に発表された ChatGPT は、Stable Diffusion、Whisper (後述) と並ぶ 2022年の「AI 三大事件」の一つであると言って間違いないでしょう。GPT-3 のような強力な言語モデルは既に存在していましたが、人間との対話および有用さに最適化した ChatGPT は、その生成の質および汎用性から瞬く間に大きな話題となり、なんとリリースから5日間で 100万ユーザーを達成するに至りました。
ChatGPT を強力にしているコア技術が「人間によるフィードバックを用いた強化学習 (以下 RLHF; reinforcement learning from human feedback)」で、これは、人間のフィードバックに基づき強化学習によって言語モデルを微調整する手法です。ChatGPT については、詳細な技術論文等は出版されていませんが、公式ブログ記事で ChatGPT の「きょうだいモデル (sibling model)」と言われている InstructGPT (Ouyang et al., 2022) に最も近いと考えられています。
なお、言語モデルの振る舞いと、人間の嗜好・利害を一致させることを「アラインメント (alignment)」問題と呼びますが、人間からのフィードバックに基づいて言語モデルをアラインメントさせる研究に取り組んでいるのは、OpenAI だけではありません。DeepMind は、情報を探す対話エージェントに RHLF を適用し、より安全・助けになるモデル Sparrow (Glaese et al., 2022) を発表していますし、Anthropic は、最近の論文 (Bai et al., 2022) で、言語モデルのアラインメント、特に、「助けになる (helpful)」「無害な (harmless)」要素に注目し、RHLF と同様の手法を用いて言語モデルを訓練・評価しています。
ChatGPT については、有害・差別的な言語を出力しないよう注意深く訓練されているように見えますが、事実関係を間違えたりと、従来の言語モデルによく見られるような問題が依然として存在しています。また、誰でも高品質な文書を簡単に作られるようになり、Stack Overflow で ChatGPT の利用が禁止されたり、大学レベルのエッセイにおける不正が社会問題化したりしています。
最後に、「草の根的 AI コミュニティ」Eleuther AI の一部門である CarperAI では、HuggingFace Transformers のモデルを RLHF によって訓練する trlx など、強化学習・RLHF に関するオープンソースの実装・モデルを多数リリースしています。また、最新の深層学習モデルのオープンソース実装で有名な lucidrains 氏も、言語モデルを RLHF によって訓練する実装を公開しています。ただ、OpenAI は、ChatGPT の訓練に必要な「人間のアノテーションに従来手法の10倍以上もの予算をかけている」という噂もあり、潤沢な資金力を持った大企業以外がこれらの技術を再現することを難しくしています。
萩原 正人
5. 強化学習

2022年は、強化学習の存在感が一層と増した年でもありました。10月には、高速な行列乗算のアルゴリズムを発見する AlphaTensor が DeepMind から発表されましたが、これは囲碁などで成果を上げた AlphaZero を発展させた強化学習によって訓練されています。また、上で書いたように、OpenAI による ChatGPT は、人間にとって有用かつ無害な応答をするように強化学習によって訓練されています。
強化学習の分野では、状態と行動の系列を言語モデルのトークン列のように自己回帰的に予測する Decision Transformers (Chen et al., 2021) や Trajectory Transformer (Janner et al., 2021) が、シンプルながらも高い性能を上げて、オフライン強化学習において強いインパクトを残しました。
この Decision Transformer と近いアーキテクチャを持ちながら、なんと 604個ものタスクを単一のモデルで解けるようにした超マルチモーダル・超マルチタスクの「万能エージェント」Gato (Reed et al., 2022) が発表され、話題を呼びました。他にも、Minecraft の環境とウェブからの大規模データセット、およびそれらを利用したエージェントを学習した MineDojo (Fan et al., 2022) が、機械学習分野のトップ会議 NeurIPS 2022 で論文賞を受賞しています。
萩原 正人 萩原 正人
萩原 正人
6. 言語モデル

2020年に GPT-3 が発表されてから話題に事欠かない巨大言語モデル界隈ですが、上で書いた ChatGPT 以外にも様々な動きがありました。2022年に発表された代表的な言語モデルを以下に挙げます。
- 対話用の超大規模言語モデル LaMDA (137B パラメータ, Thoppilan et al., 2022)
- 「密な」言語モデルとしては最大規模の PaLM (540B パラメータ, Chowdhery et al., 2022)
- DeepSpeed と Megatron を使って訓練した巨大言語モデル Megatron-Turing NLG (530B パラメータ, Smith et al., 2022)
- 計算量に対して最適な性能を達成した言語モデル Chinchilla (70B パラメータ, Hoffmann et al., 2022)
- 言語モデルの目的関数・アーキテクチャを統一するフレームワーク UL2 (Tay et al., 2022)
また、言語モデルに関しては、単にスケールを追求するだけでなく、その「賢い訓練・利用法」についても研究開発が進んでいます。
代表的なものに、2021年にも取り上げた「指示チューニング (instruction tuning)」がありますが、これは、言語モデルを多数のタスクの記述および例示によって訓練することによって、未知タスクへの汎化能力を高める手法です。指示チューニングを用いて訓練した「最強の言語モデル」Flan-PaLM (Chung et al., 2022) は、非常に高い性能を達成しています。この指示チューニングの訓練・評価のためには、大規模かつ多様なタスクを含めた高品質なデータセットが必要になります。61個のタスクを含めた Natural Instructions (Mishra et al., 2022)、1,600 個以上のタスクを含めた Super-NaturalInstructions (Wang et al., 2022)、コミュニティによって作成された 204 タスクを含んだ BIG-bench (Srivastava et al., 2022) など、大規模なデータセット・ベンチマークが公開され、研究開発を後押ししています。
また、思考の道筋 (chain of thoughts; CoT, Wei et al., 2022) や、メモ用紙 (scratchpad; Nye et al., 2021) など、推論の中間結果を言語モデルに出力させてタスク性能を上げる技術や、言語モデルに検算させる「検証モデル (verifier, Cobbe et al., 2021)」 などの手法が開発されています。
他にも、分野に特化した言語モデルが数多く発表されています。ボードゲーム「ディプロマシー」を人間レベルで戦える AI である CICERO や、科学技術文書に特化した言語モデル Galactica (Taylor et al., 2022) などが話題になりました。なお、Glactica については、出力に事実的な誤りやバイアスが散見されるにも関わらず、それらしい「科学的」文章を出力できる危険性が多数の研究者等から指摘され、デモが公開後3日で閉鎖になるという事態になりました。
萩原 正人 萩原 正人
萩原 正人 萩原 正人
萩原 正人 萩原 正人
萩原 正人
7. オープンソース AI
![]()
近年の AI 業界では「オープンソース」「草の根的」コミュニティの存在感が増しています。HuggingFace, Eleuther AI, LAION, Stability.AI など、数々の企業・コミュニティが、多数のオープンソース実装・モデル等を公開しています。代表的なものに、以下のものがあります:
- (発表時) 最大のオープンソース言語モデル GPT-NeoX-20B (Black et al., 2022)
- コード、モデル、「学習ログ」まで全てオープンソースの巨大言語モデル OPT (Zhang et al., 2022)
- オープンソースのマルチリンガル巨大言語モデル BLOOM (BigScience Workshop, 2022)
- OPT を指示チューニングによって訓練したオープンソースモデル OPT-IML (Iyer et al., 2022、モデル+実装)
- オープンソースの英語・中国語バイリンガル大規模言語モデル GLM-130B (Zeng et al., 2022)
なお、これらのコミュニティのメンバー間では、メッセージアプリの Discord のサーバーを用いて主にコミュニケーションがされています。誰でも参加できる公開サーバーで意思決定や Q&A なども含めてやりとりに全てアクセス・参加できる一方で、非英語圏の AI 関係者には少し参加の敷居が高く、また、検索エンジンなどオープンなインターネットに情報が残らないという欠点もあります。
萩原 正人8. 音声認識・生成

2022年の「AI 三大事件」の最後の一つは、OpenAI から発表された Whisper を挙げたいと思います。なんと 68 万時間もの訓練データで訓練された大規模な音声認識 (ASR; automatic speech recognition) モデルで、英語の音声認識において人間の (有料) 書き起こしサービスにも匹敵、日本語を含むその他の言語の認識でも非常に高い性能を達成しています。その後、日本語のカタカナ認識モデル を含め Whisper を様々な言語・データセットで微調整する方法なども公開されており、コミュニティでの利用が広がっています。
2022年は、音声の生成においても、大きな進展がありました。テキストから任意の音声を生成する AudioGen (Kreuk et al., 2022)、音声のみから高品質な言語生成を実現する「音声言語モデル」AudioLM (Borsos et al., 2022)、一般の環境音・効果音・音楽などとテキストの関係をとらえる大規模モデル CLAP (Wu et al., 2022) などが代表的な例です。特に、CLIP を皮切りに「テキスト→画像」生成技術が大きく発展したのを考えると、CLAP などの基礎技術には今後の発展が大きく期待でき、音声の分野においても、画像生成 AI 分野で起こったような急激なイノベーションが起こる可能性もあります。
音声表現の分野では、汎用の音声表現ベンチマークである HEAR (Turian et al., 2022)、音声・画像・言語、何でもベクトル化する表現学習手法 data2vec (Baevski et al., 2022) とその後続手法 data2vec 2.0 (Baevski et al., 2022) などが発表されました。
音楽生成の分野では、音符と演奏表現によって制御可能にした音の生成手法である MIDI-DDSP (Wu et al., 2021)、VAE の仕組みを使った高速・高品質なオーディオ生成 RAVE (Caillon and Esling, 2021)、音楽のスペクトグラムを画像と見なしてテキストから音楽を生成する Riffusion などが話題となりました。
萩原 正人 萩原 正人
萩原 正人 萩原 正人
萩原 正人
9. マルチモーダル・制御
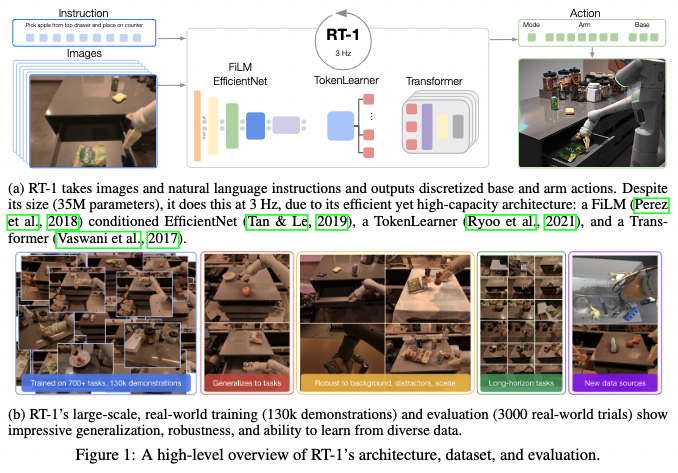
単一の手法・モデルで、ビジョン・言語・音声・制御など、様々な種類の入力と出力を統一的に扱える「マルチモーダル」手法も発展しています。
上述の超マルチモーダル・超マルチタスク「万能エージェント」Gato (Reed et al., 2022) や、少数の例示で多様なタスクを解く「GPT-3 の視覚×言語版」Flamingo (Alayrac et al., 2022) などがその代表的な例です。
また、言語モデルが単語を予測するのと同じしくみを用いて、トランスフォーマーなどのモデルに「行動の系列」を予測させることにより、制御が可能になります。「万能エージェント」Gato はこの仕組みを用いた万能エージェントですし、DeepMind の研究 (Humphreys et al., 2022) ではコンピューター (マウスとキーボード) を自然言語によって制御し、自動検索や航空券の予約など簡単なタスクを実行するエージェントを実現しています。トランスフォーマーを最初に提案した論文の著者 (Vaswani 氏) らの立ち上げたスタートアップ Adept は、自然言語でタスクを指定して、情報検索やスプレッドシートの操作などの制御を実現する「行動用トランスフォーマー ACT-1」を発表しています。
最後に、単一のモデルでロボットを制御し、多数のタスクに対応・汎化できる Robotics Transformer (RT-1; Brohan et al., 2022) も 12 月に発表されています。
2021年の記事で述べたように、統一的なモデルや手法を用いて様々なモダリティー、タスクを扱う「AI 分野の大統一」は、2022年も着実に進みつつあります。
萩原 正人10. 計算量削減

近年の巨大モデルは、訓練に大量の計算機リソースと大規模なデータセットを必要とするため、GAFAM 等の資金力を持つ大企業以外では再現できにくいという「AI 格差」が指摘されています。モデルやデータのスケールを追求した研究の一方で、学習や推論にかかるコストをいかに下げるか、という研究も活発に行われています。
コンピューター・ビジョンの分野では、ビジョン・トランスフォーマーが画像分類などのタスクで高い性能を上げています。一方で、入力サイズの2乗に計算量が比例してしまうというトランスフォーマーの欠点を補うための手法、例えば DiNA (Hassani and Shi, 2022) や Token Merging (Bolya et al., 2022) 等が提案されています。また、ConvNet (畳み込みニューラルネットワーク) を現代的な手法で訓練することによりビジョン・トランスフォーマーに匹敵させた ConvNeXt (Liu et al., 2022) も発表され、「ConvNet vs ViT」の決着にはもう少しかかりそうです。さらに、NeRF (Neural Radiance Field) を始めとする様々なグラフィックスタスクにおいて、高速な学習を可能にした Instant NGP (Müller et al., 2022) が SIGGRAPH 2022 でベストペーパー賞を受賞しています。
言語処理の分野では、計算量に対して最適な性能を達成した言語モデル Chinchilla (70B パラメータ, Hoffmann et al., 2022) が、比較的少ないパラメータ数で他のさらに大規模なモデルに匹敵する性能を上げていますし、UL2R (Tay et al., 2022) は、0.1% の追加訓練だけで言語モデルの性能を大幅に向上させています。また、12月に「一夜漬け (cramming) BERT」と呼ばれる、BERT 的な言語モデルを単一の GPU 上で1日だけ訓練し、同等の性能を達成した研究も発表されています (Geiping and Goldstein, 2022)。
機械学習一般については、訓練データの枝刈りを使い、少ないデータで高精度モデルを訓練する手法 (Sorscher et al., 2022) が発表され、注目を集めました。同論文は NeurIPS 2022 の論文賞にも選ばれています。
萩原 正人 萩原 正人藤井 亮宏
萩原 正人藤井 亮宏
おわりに — 今後の AI はどう発展するか
進歩の激しい AI の分野において、将来の方向を予測することは非常に難しいと考えています。一方で、近年の AI の発展を見ると、少なくとも向こう2〜3年間については「トランスフォーマー+自己回帰的な予測」に基づく大規模言語モデルが、ある種の「AI 分野の OS・インターフェース」的な役割を果たして発展していくと考えるのが自然です。
一つの方向性は、この言語モデルをマルチモーダルにするというもので、これは言語モデルに「目と耳」を持たせる技術であると考えると分かりやすいでしょう。これについては Flamingo (Alayrac et al., 2022) など既に多数の研究がありますが、これが実用化すると、例えば ChatGPT に画像を見せて「この写真に写っている製品の型番は何か」といった質問に答えさせたり、動画を見せて「この映画のあらすじを日本語でまとめて」といった対話ができるようになる可能性が出てきます。
もう一つの方向性は、この言語モデルに制御機構を持たせるというもので、これは言語モデルに「手と足」を持たせる技術であると考えると分かりやすいでしょう。本記事でも述べた Gato (Reed et al., 2022) や RT-1 (Brohan et al., 2022) など、既に研究が進んでいますが、まず始めにはブラウザやターミナルの操作など、マウスとキーボードで可能な範囲から実用化が進むと思います。これが可能になると、ChatGPT に「Amazon でこの漫画の最新刊を買っておいて」などの指示が出せるようになります。
これらの技術が実用化した時、言語モデルはまさに「バーチャルアシスタント」と呼ぶにふさわしく、社会に大きなインパクトを与えるのは必至です。もちろん、コンピューターの制御を言語モデルに渡した時点で、その安全性を確保する重要性はさらに高まるのは間違いなく、AI の技術を人間の利害と一致させる「アラインメント」の技術も一層と重要になると予想されます。
最後になりましたが、本記事の執筆にあたって、本ブログの共同執筆者である藤井さん、塚越さんにアドバイスをいただきました。この場を借りてお礼申し上げます。また、本記事の執筆には以下のリンクを参照にしました。