Abstract
Differences in data size per class, also known as imbalanced data distribution, have become a common problem affecting data quality. Big Data scenarios pose a new challenge to traditional imbalanced classification algorithms, since they are not prepared to work with such amount of data. Split data strategies and lack of data in the minority class due to the use of MapReduce paradigm have posed new challenges for tackling the imbalance between classes in Big Data scenarios. Ensembles have been shown to be able to successfully address imbalanced data problems. Smart Data refers to data of enough quality to achieve high-performance models. The combination of ensembles and Smart Data, achieved through Big Data preprocessing, should be a great synergy. In this paper, we propose a novel Smart Data driven Decision Trees Ensemble methodology for addressing the imbalanced classification problem in Big Data domains, namely SD_DeTE methodology. This methodology is based on the learning of different decision trees using distributed quality data for the ensemble process. This quality data is achieved by fusing random discretization, principal components analysis, and clustering-based random oversampling for obtaining different Smart Data versions of the original data. Experiments carried out in 21 binary adapted datasets have shown that our methodology outperforms random forest.
Similar content being viewed by others



Avoid common mistakes on your manuscript.
Introduction
We are experiencing a constant revolution in terms of data generation and transmission speeds. Technologies such as 4G networks have been surpassed by faster standards like the novel 6G network, which is expected to revolutionize the Internet of Things (IoT) [1] and its different domains, such as the Internet of Healthcare Things (IoHT) [2]. This increasing amount of data contains very valuable insights for businesses. This is the era of Big Data [3]. Big Data can be defined as a high volume of data, generated at a high velocity, composed of a wide variety of data types, with a potential high value and high veracity. This conforms to what is known as the five Big Data V’s (among many others) [4].
Most of nowadays real-world data is generated from an Internet of Things (IoT) context. This IoT scenario is composed of a myriad of sensors that generate temporal data in the form of time series [5] or tabular data [6]. Real-world classification problems based on tabular data are not usually balanced. This means that one class (usually the one that contains the concept of interest) is underrepresented in the dataset [7]. This is known as imbalanced classification [8] and causes machine learning algorithms to bias towards the class with the greater representation. The imbalanced classification task has been extensively researched in the literature [8].
Imbalanced classification has a critical role in Big Data environments, where the imbalance between classes may be greater. This is known as imbalanced Big Data classification [9]. Despite the extensive list of imbalanced classification methods proposed in the literature, we can find only a handful of classic sampling proposals extended to Big Data domains, such as random oversampling (ROS), random undersampling (RUS) [10], or “Synthetic Minority Oversampling TEchnique” (SMOTE) [11, 12]. As stated by recent surveys [13, 14], current imbalanced Big Data proposals are usually a direct extension of classic oversampling imbalanced methods to Big Data environments. This entails a key issue for those methods, which is suffering from lack of data in the different maps within the already very small minority class space [13]. SMOTE and its extensions constitute the current state-of-the-art for imbalanced problems; however, it lacks a quality extension to Big Data environments due to suffering from the aforementioned issue [14]. This leads to a sub-par performance of these methods in Big Data domains [13].
In imbalanced Big Data scenarios, there is the challenge of new approaches that take into account the peculiarities of distributed MapReduce processing and the availability of several maps with imbalanced subsets that require their own processing [13]. In [14], the authors identified two gaps within the imbalanced Big Data classification scenario: “the few ensemble methods designed for Big Data problems, and perhaps even fewer for processing imbalance within Big Data.” This assessment for the design of efficient distributed algorithms, in particular ensembles, capable of analyzing the nature of maps by performing an imbalanced analysis of the data [9], drives our current proposal, advancing towards the use of Smart Data and ensembles.
Recently, the term Smart Data has emerged in the Big Data ecosystem. Smart Data refers to the challenge of extracting quality data from raw Big Data [3, 9]. This new concept aims to achieve quality data with value and veracity properties [15]. Data preprocessing clearly resembles the concept of Smart Data to ensure achieving quality data. Data preprocessing is also inherent in all imbalanced approaches [8]. In Big Data environments, Big Data preprocessing has a crucial role for enabling Smart Data [9]. On the other hand, ensembles have been established as the most popular algorithm-level solution for tackling the imbalanced classification problem [8, 16]. Ensembles and Smart Data have proven to perform consistently in Big Data environments when facing label noise [17, 18]. Our hypothesis in this paper is their combined use to tackle the imbalanced Big Data classification problem.
We propose a novel Smart Data driven Decision Trees Ensemble methodology for addressing the imbalanced Big Data classification, namely SD_DeTE methodology. SD_DeTE methodology produces a decision tree-based ensemble combined with Smart Data for introducing diversity in the datasets, creating different decision trees that result in an efficient distributed ensemble algorithm. Quality data is achieved through the application of several data preprocessing techniques in order to enable different Smart Data approaches of the dataset, that will enable the learning of better base classifiers and achieve efficient distributed algorithms. Therefore, SD_DeTE methodology is composed of a Smart Data generation process and an ensemble learning process:
-
1.
Smart Data: The first objective is to add the required level of diversity to the dataset. For this, the combination of random discretization (RD) and randomized principal component analysis (PCA), proposed in Principal Components Analysis Random Discretization Ensemble (PCARDE) algorithm [19], is used. For a data balancing step, a novel combination of clustering and ROS is presented. SD_DeTE methodology performs clustering to the expanded data resulting from the combination of RD and PCA datasets. Then, it balances the clusters using the ROS technique. The result of this process is a distributed Smart Data version of the dataset, with the appropriate level of diversity.
-
2.
Ensemble learning: This process creates the ensemble through the learning of different base classifiers using a decision tree as a classifier. The distributed Smart Data will produce better base classifiers.
To assess the performance of SD_DeTE methodology, we have conducted an extensive experimentation, using 21 binary adapted Big Data imbalanced datasets. All datasets have been selected from the latest literature in tabular data and Big Data. We have compared SD_DeTE methodology against Spark’s MLlib implementation of a decision tree, random forest [20], and PCARDE algorithm [19]. These three classifiers have been tested without any data balancing technique applied, and using RUS, ROS, and SMOTE techniques. Results obtained have been validated by different Bayesian Sign Tests, in order to assess if SD_DeTE methodology achieves statistically better performance than the rest of the tested methods [21].
The rest of this paper is organized as follows: “Related Work” section gives a description of the imbalanced data classification and Big Data problem. “Smart Data Driven Decision Trees Ensemble Methodology for Imbalanced Big Data” section describes the proposal in detail. “Experimental Results” section shows all the experiments carried out to prove the performance of SD_DeTE methodology for several Big Data problems. Finally, “Conclusions” section concludes the paper.
Related Work
In this section, we provide an introduction to the class imbalance problem in classification, among with the different proposals to tackle it (“Imbalanced Data Classification” section). Then, the state of Big Data and MapReduce framework is analyzed in “Big Data and MapReduce” section. The state-of-the-art regarding imbalanced Big Data scenario is depicted in “Imbalanced Big Data” section.
Imbalanced Data Classification
In a binary classification problem, a dataset is said to be imbalanced when there is a notable difference in the number of instances belonging to different classes [8, 22]. The class with the larger number of instances is known as the majority class. Similarly, the class with the lower number of instances is known as the minority class and usually contains the concept of interest.
As stated earlier, this problem poses a major challenge to standard classifier learning algorithms, since they will bias towards the class with the greater representation, as their internal search process is guided by a global search measure weighted in favor of accuracy [9]. In datasets with a high imbalance ratio (IR), classifiers that maximize the accuracy will treat the minority class as noise and ignore it, achieving a high accuracy by only classifying the majority class, since more general rules will be preferred.
Many techniques have been proposed to tackle imbalanced data classification. However, ensembles have established themselves as the state-of-the-art in performance [8, 16, 23]. Because of their accuracy orientation, ensembles cannot be directly applied to imbalanced datasets, since the base classifiers will ignore the minority class. Their combination with other techniques that tackle the class imbalance problem can improve ensemble performance in these scenarios. These hybrid approaches involve the addition of a data sampling step that allows the classifier to better detect the different classes.
In the literature, data preprocessing methods for imbalanced data classification can be divided into different categories: oversampling methods, undersampling methods, and hybrid approaches [8, 9]. The former (such as ROS [24]) replicates the minority class instances until a certain balance is reached. On the other hand, undersampling techniques (such as RUS [24]) remove examples from the majority class until the proportion of classes is adjusted. Hybrid approaches combine the previous two techniques, usually starting with an oversampling of the data, followed by an undersampling step that removes samples from both classes, in order to remove noisy instances and improve the classifier performance.
The SMOTE algorithm, along with its many extensions [12, 25, 26], constitutes the current state-of-the-art in data preprocessing for imbalanced data. It adds synthetic instances from the minority class until the class distribution is balanced. Those new instances are created by the interpolation of several minority class instances that belong to the same neighborhood. SMOTE calculates the k nearest neighbors of each minority class example. Then, in the segment that connects every instance with its k closest neighbors, a synthetic instance is randomly created [27].
Clustering has also been employed effectively for the data imbalanced problem as a way to increase the density of points belonging to certain neighborhoods [28, 29]. These methods balance the data by localizing groups of instances belonging to different neighborhoods and then applying a data sampling technique, improving the later learning process [30, 31].
Performance evaluation is a key factor for assessing the classification performance. In binary classification problems, the confusion matrix (shown in Table 1) collects correctly and incorrectly classified examples from both classes.
Traditionally, accuracy (Eq. (1)) has been the most extended and widely used metric for assessing classification performance. However, accuracy is not a valid metric when dealing with imbalanced datasets, since it will not show the classification of both classes, only the majority class, and it will lead to wrong conclusions.
The geometric mean (GM), described in Eq. (2), attempts to maximize the accuracy of both minority and majority classes at the same time [32]. The accuracy of both minority and majority classes is represented by the true positive rate (TPR) \(= \frac{TP}{TP+FN}\) and true negative rate (TNR) \(= \frac{TN}{TN+FP}\).
Another popular evaluation metric for imbalanced data is the area under the curve (AUC) [33, 34]. AUC combines the classification performance of both classes, showing the trade-off between the TPR and false positive rate. This metric provides a single measure of a classifier performance, compared against a random classifier.
Big Data and MapReduce
In order to tackle Big Data problems, not only new algorithms are needed, but also new frameworks that operate in distributed clusters are required. Google introduced the MapReduce paradigm in 2004 [35]. This paradigm is nowadays the most popular and widely used paradigm for Big Data processing. It was born for allowing users to generate and/or process Big Data problems, while minimizing disk and network use.
MapReduce follows the simple but powerful divide-and-conquer approach. It can be divided into two phases, the map and reduce phase. Before entering the map stage, all data is split and distributed across the cluster by the master node. The map function applies a transformation to each key-value pair located in each computing node. This way, all data is processed independently in a distributed fashion. When the map phase is finished, all pairs of data belonging to the same key are redistributed across the cluster. Once all pairs belonging to the same key are located in the same computing node, the reduce stage begins. The reduce phase can be seen as an aggregation operation that generates the final values.
MapReduce is a programming paradigm for dealing with Big Data. Apache Hadoop is the most popular open-source implementation of the MapReduce paradigm [36]. Despite its popularity and performance, Hadoop presents some important limitations [37]:
-
Not suitable for iterative algorithms.
-
Very intensive disk usage. All map and reduce processes are read/write from/to disk.
-
No in-memory computation.
Apache Spark can be seen as the natural evolution of Hadoop. It is an open-source framework, focused on speed, easy of use, and advanced analytics [38]. Spark is the solution of Hadoop problems; it has in-memory computation and allows in-memory data persistence for iterative processes. Spark is built on top of a novel distributed data structure, namely Resilient Distributed Datasets (RDDs) [39]. These data structures are immutable and unsorted by nature. They can be persisted in memory for repetitive uses and tracked using a lineage, so that each split can be computed again in case of data lost. RDDs support two types of operations: transformations and actions. The former transforms the dataset by applying a function to each split and produces a new RDD. They are lazy operations, meaning that they are not computed until needed. On the other hand, actions trigger all previous transformations of an RDD and return a value.
In 2012, a distributed machine learning library was created as an extra component of Apache Spark, named MLlib [40]. It was released and open-sourced to the community in 2013. The number of contributions has been increasing steadily since its conception, making it the most popular machine learning library for Big Data processing nowadays. MLlib includes several algorithms for alike tasks, such as classification, clustering, regression, or data preprocessing.
Imbalanced Big Data
With the automation in data acquisition and storage and the explosion of sensors and available data, the problem of imbalanced data classification has been severely affected. It is considered to be one of the worsened or even directly provoked problems by Big Data [9]. Moreover, classic algorithms are not able to tackle the imbalanced problem in a reasonable amount of time.
The imbalanced data classification problem has not been disregarded in Big Data. However, most of the proposals in the literature follow two main approaches: data sampling and distance-based solutions. The former consists of an adaptation of ROS and RUS methods to Big Data domains using the MapReduce paradigm [41]. Distance-based methods are mainly composed of different adaptations of SMOTE algorithm to Big Data environments, ranging from an exact version of SMOTE [11], SMOTE for multi-class problems [42], or a GPU-based SMOTE [12]. There are also proposals that combine both approaches in the form of an ensemble [43]. However, the SMOTE algorithm for Big Data scenarios is affected by the lack of data in the different maps and the presence of small disjuncts [13, 14].
In recent surveys [9, 13, 14], the authors agree that, in comparison with studies for standard problems, there is still little research devoted to address the problem of imbalanced classification in Big Data scenarios. There is a need for proposals born for and to tackle imbalanced Big Data problems effectively and efficiently. In particular, the design and implementation of new classifiers for Big Data frameworks, capable of internally processing the imbalanced situation, are of special interest [14]. The thorough design at the implementation level of algorithms to address imbalanced Big Data problems is one of the open challenges nowadays [9]. Therefore, we aim to provide an efficient and effective ensemble methodology design for the classification of imbalanced Big Data problems.
Smart Data Driven Decision Trees Ensemble Methodology for Imbalanced Big Data
In this section, we describe in detail the proposed ensemble methodology for imbalanced Big Data classification based on achieving diversity and quality data through data preprocessing methods together with decision trees to create the ensemble, SD_DeTE methodology. It has been designed under the distributed computing paradigm MapReduce and has been implemented for the Big Data framework Apache Spark [38], which is an extension of such paradigm, making it able to tackle Big Data problems efficiently. SD_DeTE methodology is available publicly as a Spark package in Spark’s third-party repository Spark Packages.Footnote 1
In “SD_DeTE Methodology: Smart Data” section, we explain the details of the Smart Data generation process of SD_DeTE methodology. “SD_DeTE Methodology: Ensemble” section details the ensemble learning process. “Spark Primitives” section describes the Spark primitives used for the implementation of the proposal. Finally, “SD_DeTE Methodology Implementation Details” depicts the implementation details of the methodology.
SD_DeTE Methodology: Smart Data
This ensemble classifier for imbalanced Big Data problems is based on the creation of smart datasets for improving the performance of the models learned from the different base classifiers. Diversity is key when working with ensembles. Diversity can be introduced through small changes in input data or small changes in the parameters of the classifier. With diversity in the base classifiers, ensembles will be more robust to noise and outliers and will achieve better performance [19]. SD_DeTE methodology achieves a Smart Data version of the dataset with the appropriate level of diversity by using the following two modules:
RD-PCA Module
SD_DeTE methodology achieves the required diversity by the use of several randomized data preprocessing methods, such as RD and PCA. RD method [44] discretizes the data in cuts intervals by randomly selecting \(cuts-1\) instances. Those selected values are sorted and used as thresholds for the discretization of each feature. This mechanism enables RD to produce diversity efficiently each time it is performed on such data. On the other hand, PCA selects a number of variables in a dataset, while retaining as much of the variation present in the dataset as possible. This selection is achieved by finding the combinations of the original features to produce principal components, which are uncorrelated. PCA always produces the same result for a fixed number of principal components. In order to achieve the required level of diversity, a random number of selected components is used. The number of components must be in the interval \([1, T-1]\), T being the total number of features of the input data.
Both RD and PCA methods are applied to the input data. Then, the resulting datasets of RD and PCA are joined together feature-wise. This data is a more informative version of the dataset with the appropriate level of diversity, as demonstrated in [19]. Such dataset needs to be balanced in order to correctly identify the minority and majority classes.
C-ROS Module
A novel combination of hierarchical clustering and oversampling is proposed. Bisecting k-Means is a hierarchical clustering method that uses a divisive (or “top-down”) approach [45]. The algorithm starts from a single cluster that contains all points. Iteratively, it finds divisible clusters on the bottom level and bisects each of them into two clusters using k-Means, until there are k leaf clusters in total or no leaf clusters are divisible. It has been chosen taking into account that it can often be much faster than regular k-Means. Bisecting k-Means has a linear time complexity. In case of a large number of clusters, Bisecting k-Means is even more efficient than k-Means since there is no need to compare every point to each cluster centroid. It just needs to consider the points in the cluster and their distances to two centroids.
Bisecting k-Means is applied to the resulting data from the join of RD and PCA for finding a random number of neighborhoods with a specified maximum of desired clusters. Found clusters are individually balanced using the ROS technique until an IR of 1 is reached. The result of this process is a balanced and smart dataset with the required level of diversity, which will improve the later learning process by enabling the ensemble to produce efficient distributed algorithms.
In Fig. 1, we can see a graphic representation of the Smart Data generation workflow of SD_DeTE methodology.
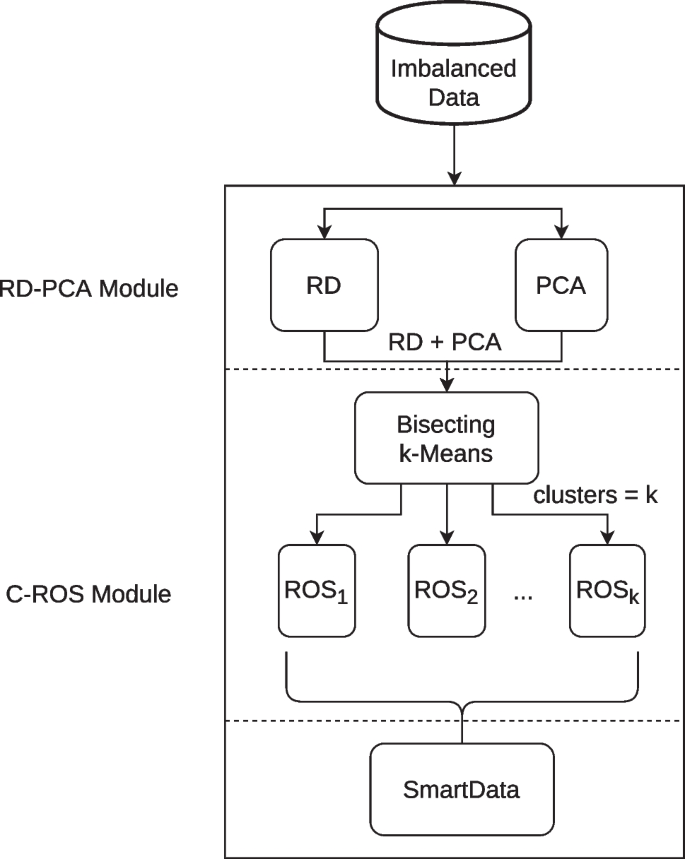
SD_DeTE methodology Smart Data generation flowchart
SD_DeTE Methodology: Ensemble
The two previous modules produce a smart version of the dataset with the appropriate level of diversity. As stated earlier, ensembles are the most popular solution for tackling imbalanced problems. SD_DeTE methodology uses the previously generated Smart Data for learning different quality base detectors that will produce a better ensemble method.
Learning Module
Using the previously acquired balanced and smart dataset, a decision tree is learned. This decision tree performs a recursive binary partitioning of the input feature space. The tree predicts the same label for each leaf partition. These partitions are chosen in a greedy manner, selecting the best split from the set of possible splits, maximizing the information gain at the tree node [46].
SD_DeTE methodology preprocessing and learning process is repeated iter times. In Fig. 2, we can see a graphic representation of the learning workflow of SD_DeTE methodology.
All previous steps constitute the learning phase of the ensemble. This phase is composed of iter sub-models, each of them containing the thresholds for RD and the weight matrices for PCA. For the prediction phase of the ensemble, for each data point, the same data preprocessing must be applied. First, data is discretized using the same cut points from RD calculated previously. Then, for selecting the same components as the learning phase, the same weight matrix obtained earlier for PCA at a given iteration is applied to the data. Next, the score of each class is predicted according to the decision tree. This score is calculated by the division of the instances at a leaf node, by the total number of instances. This process is repeated iter times, adding those scores for each instance and iteration. Once this process is finished, for each instance, the class with the largest score is selected as the decision of the ensemble.
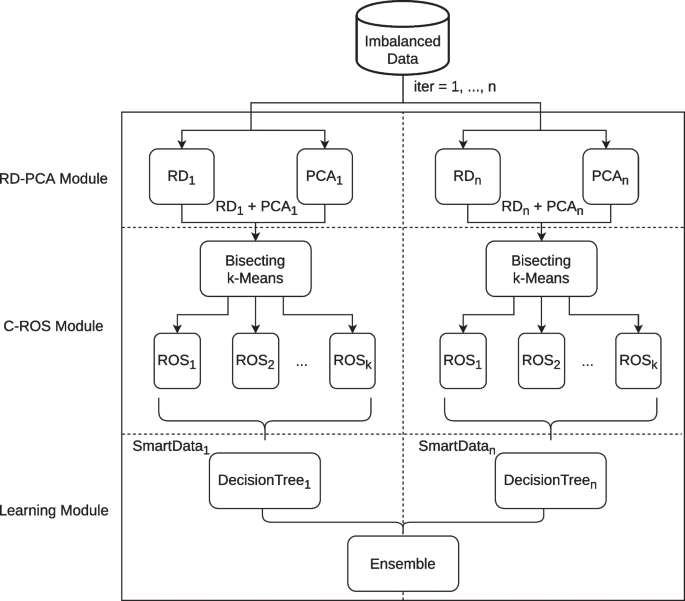
SD_DeTE methodology learning flowchart
Spark Primitives
For the implementation of the ensemble, some basic Spark primitives have been used. Here, we outline those more relevant for the ensembleFootnote 2:
-
Map: applies a transformation to each element of an RDD. Once that transformation has been applied, it returns a new RDD.
-
Union: merges two RDDs instance-wise and returns a new RDD.
-
Zip: zips two RDDs together.
-
Filter: selects all the instances in an RDD that satisfy a condition as a new RDD.
These Spark primitives from Spark API are used in the following section, where the implementation of SD_DeTE methodology is described.
SD_DeTE Methodology Implementation Details
This section describes all the implementation details of SD_DeTE methodology. Both learning and prediction phases are implemented under Apache Spark, following the MapReduce paradigm.
Ensemble Learning Phase
Algorithm 1 explains the ensemble learning phase of SD_DeTE methodology. This process is divided into five steps: RD and PCA calculation in order to introduce diversity to the dataset, cluster search for the discovery of neighborhoods, cluster balancing, and classifier learning.

SD_DeTE methodology learning algorithm
Step 1
As stated earlier, SD_DeTE methodology starts by discretizing the training data using the RD method (lines 8–14). This is performed through the random selection of \(cuts-1\) instances (line 8). Those thresholds are used to discretize the training data using a map function (lines 10–14). For every instance, we assign the corresponding discretized value to each instance’s attribute (lines 11–13).
Step 2
Once RD has been applied to the training data, PCA is performed to select randomly the best principal components (lines 16–19). First, a random number of components is selected in the interval \([1, T-1]\) (T being the total number of features of the training data) (line 16). Then, PCA is calculated on the training data, and the best components are selected (lines 17–18). Finally, the resulting data from RD and PCA are joined together feature-wise using a distributed zip function (line 19).
Step 3
With the desired level of diversity added to the dataset, the next step is the hierarchical clustering search (lines 21–23). We have used Spark’s MLlib distributed implementation of Bisecting k-Means. First, we select a random number of clusters, with a maximum of maxClust (line 21). Then, clusters are calculated using the previously RD and PCA zipped data (line 22). Once that process is finished, the same zipped data is predicted in order to assign a cluster to each data point (line 23). The prediction is done level-by-level from the root node to a leaf node, and at each node among its children, the closest to the input point is selected.
Step 4
Data balancing is applied to each individual cluster found. We apply the ROS technique to the minority class of each cluster until both minority and majority classes are equal (lines 25–29). First, an empty set is created for the allocation of the future new dataset (line 25). For each cluster, ROS is applied with an IR of 1 (line 27). That balanced and smart data is added to the empty set (line 28).
Step 5
Finally, a decision tree is learned using this smart and balanced dataset (line 31). This data preprocessing and learning process is repeated iter times, keeping each iteration, the computed thresholds for RD, the PCA weight matrices, and the learned tree model. Once all trees have been learned, the model is created and returned.
The following input parameters are required: the dataset (data), the number of iterations of the ensemble (iter), the number of intervals for the discretization (cuts), and the maximum number of clusters (maxClust).
Ensemble Prediction Phase
The ensemble prediction phase is depicted in Algorithm 2. This process is faster than learning, since clustering and data balancing are not required for prediction. Only the application of RD and PCA is required, both using the same models obtained in the ensemble learning phase. This phase is divided in five steps:
Step 1
First, the data point is discretized using the same cut points from the learning phase (lines 10–13).
Step 2
Next, the principal components are calculated using the learning phase weight matrix for that particular iteration (line 15).
Step 3
The next step is to join both RD and PCA results feature-wise using a distributed zip function (line 17). The result is an expanded dataset with the features of both RD and PCA.
Step 4
Prediction is made for the data point using the decision tree learned in that particular iteration of the ensemble (line 19). The scores of each of the iter predictors are added.
Step 5
Once the instance has all iter scores, the class with the largest weight is selected as the decision of the ensemble and returned (lines 22–23).

DeTE_model prediction algorithm
Experimental Results
In this section, we describe the experimental study carried out to compare the performance of different approaches to deal with imbalanced Big Data problems against our ensemble methodology proposal. In “Experimental Setup” section, we show a description of all datasets employed in the comparison, followed by the performance metrics and parameters of the algorithms used. All hardware and software resources used to carry out the experimental study are also detailed. We detail the results of the performance metrics and analyze them using statistical tests in “Results and Analysis” section. “Computing Times and Complexity” section is devoted to the computing times of SD_DeTE methodology. Finally, we have conducted an additional experiment for showing the performance improvement achieved by our proposed clustering-based ROS technique in “Clustering-Based ROS vs ROS” section.
Experimental Setup
We have selected a wide spectrum of Big Datasets for assessing the performance of SD_DeTE methodology. These datasets have very different properties among them that will allow us to measure the performance and balancing capabilities of our proposal. Specifically, we have selected the Poker Hand dataset, the Record Linkage Comparison Patterns (RLCP), SUperSYmmetric particles (SUSY) and Higgs bosons (HIGGS) datasets [47], and the KDD Cup 1999 dataset, a dataset used for the Third International Knowledge Discovery and Data Mining Tools Competition. These binary adapted datasets have been extracted from the UCI Machine Learning Repository [48] and have been chosen attending to their size, making them suitable for Big Data scenarios and, therefore, unsuitable for iterative processing. We have also selected a real-world imbalanced dataset, the ECBDL14 dataset [49]. ECBDL14 dataset was used as a reference at the ML competition of the Evolutionary Computation for Big Data and Big Learning, under the international conference GECCO-2014. It is a highly imbalanced binary classification dataset, composed of 98% of negative instances. For this problem, we have used two subsets with the same IR and the best 90 features found in the competition [49].
Since some of the selected datasets have more than two classes, we have sampled binary datasets from them to address each case separately. In particular, we have selected new datasets using the majority classes against the minority classes. Table 2 shows all the details of the datasets, including the number of instances (#Inst.), number of attributes (#Atts.), class distribution, and IR.
All datasets have been partitioned using a fivefold cross-validation scheme. This means that all datasets have been partitioned in fivefolds, with 80% of instances devoted to training, and the rest 20% for testing. The results provided are the average of running the algorithms with the fivefolds per dataset.
We have carried out a comparison of SD_DeTE methodology against three classification methods: Spark’s MLlib distributed implementation of decision trees, random forest, and PCARDE algorithm, a data preprocessing-based ensemble present in Spark’s community repository Spark Packages [19]. For balancing the data when those classifiers are used, we have employed the most popular and widely used data balancing methods: RUS, ROS, and SMOTE. SMOTE is the state-of-the-art in performance, while ROS combined with random forest constitutes the current state-of-the-art in imbalanced Big Data scenario [10, 14].
For SMOTE algorithm, an implementation available in the Spark Packages repository has been used: SMOTE_BD [11]. The parameters used for the data preprocessing algorithms and the different classifiers are described in Table 3. Since ensembles correct errors across many base classifiers, we have chosen to increase the depth of the decision tree in SD_DeTE methodology for a better discrimination between both minority and majority classes. ROS and SMOTE_BD have been configured to balance the dataset to an \(IR = 1\).
As stated earlier, when dealing with imbalanced data, it is crucial to choose the right performance metric. Accuracy is not useful in imbalanced datasets, because we can achieve great accuracy by just classifying correctly the majority class, while the minority class is ignored. For this reason, we have selected the two most widely used metrics for imbalanced classification: GM and AUC.
The experimentation has been carried out in a cluster composed of 11 computing nodes and one master node. The computing nodes have the following hardware characteristics: 2 x Intel Core i7-4930K, 6 cores per processor, 3.40 GHz, 12 MB cache, 4 TB HDD, 64 GB RAM. Regarding software, we have used the following configuration: Apache Hadoop 2.9.1, Apache Spark 2.2.0, 198 cores (18 cores/node), 638 GB RAM (58 GB/node).
Results and Analysis
In this section, we present the results and an analysis of the performance metrics obtained by the selected methods. We denote with Baseline the application of the classifiers without using any imbalanced data treatment technique.
In Table 4 we can see the average results for the GM measure using the three classifiers combined with the three data preprocessing strategies, compared with SD_DeTE methodology. As can be observed, the Baseline with no data imbalanced handling often results in a GM value of 0. That value represents that one of the classes (the minority in particular) is being misclassified completely. All classifiers are benefiting from the data balancing done by RUS and ROS. All three classifiers achieve very similar results when using either RUS or ROS. This can be explained by the high data redundancy present in Big Data datasets. SMOTE_BD is able to achieve an improvement in the GM measure when using PCARDE algorithm as a classifier. SD_DeTE methodology is the best-performing method for almost every tested dataset. On average, SD_DeTE methodology achieves an improvement of nearly 0.5 points in the GM measure. This shows the good performance of the clustering-based data oversampling of SD_DeTE methodology.

Bayesian Sign Test heatmap of DT, RF, and PCARDE best results, against SD_DeTE methodology for GM measure
The AUC average results are depicted in Table 5. Again, the Baseline with no preprocessing achieves low values of AUC. The first difference when comparing AUC with the GM measure is that AUC shows a value of 0.5 when a full class is completely misclassified. RUS and ROS methods are producing very similar results in terms of AUC measure. Regarding SMOTE_BD, as observed with the GM measure, only the PCARDE algorithm is able to achieve an AUC improvement with respect to RUS and ROS. The same improvement seen with the GM measure can be seen with the AUC measure for SD_DeTE methodology. It is the best-performing data preprocessing and ensemble method among the different strategies tested.
If we attend to the relation between the IR and the performance of SD_DeTE methodology, we observe that SD_DeTE methodology is not affected by the different IR’s presence in the tested datasets. SD_DeTE methodology is a very stable ensemble method, achieving almost the same performance for an increasing IR for the same dataset. This behavior can be seen in Susy and Higgs datasets, which have an IR ranging from 4 up to 16, and both the GM and AUC measures are unaffected by the increasing IR. Moreover, some of the tested datasets have an extremely high IR, such as poker0_vs_6 and poker1_vs_6 datasets, with an IR of 337.81 and 308.77 respectively. For such datasets, SD_DeTE methodology is the best-performing method, with a difference of more than 5% better performance.
Results presented have shown the excellent performance of our proposed methodology. In other machine learning branches, such as natural language processing, it is common to use a separate dataset in order to improve the performance of one particular problem [50]. SD_DeTE methodology extrapolates this idea, performing data fusion from two different methods, such as RD and PCA, in order to increase the available data, and to allow the decision tree to select better variables to split, showing better results than the rest of the methods analyzed.

Bayesian Sign Test heatmap of DT, RF, and PCARDE best results, against SD_DeTE methodology for AUC measure
For a deeper analysis of the results, we have performed a Bayesian Sign Test in order to analyze if SD_DeTE methodology is statistically better than the rest of the methods [21]. Bayesian Sign Tests obtain a distribution of the differences between two algorithms and make a decision when 95% of the distribution is in one of the three regions: left, rope (region of practical equivalence), or right [51].
The Bayesian Sign Test is applied to the mean GM and AUC measures of each dataset. We have selected the best-performing scenario for each classification method depending on the measure employed. In Fig. 3, we can see a comparison of SD_DeTE methodology against the decision tree with ROS, random forest with RUS, and PCARDE algorithm with SMOTE_BD, all using the GM measure. On the other hand, for the AUC measure (shown in Fig. 4), the decision tree is combined with RUS, random forest with ROS, and PCARDE algorithm with SMOTE_BD. As we can observe, both GM and AUC Bayesian Sign Tests are showing very similar results. The probability of the difference being to the left is minimal for SD_DeTE methodology. This means that the Bayesian Sign Test indicates a zero probability for these classification methods to perform better than our proposal.
These results have shown the importance of choosing the correct imbalanced data treatment. SD_DeTE methodology stands as the best choice for dealing with imbalanced Big Datasets, being able to create an ensemble with efficient distributed algorithms by using Smart Data. SD_DeTE methodology has achieved statistically the best performance in both GM and AUC for almost every tested dataset, proving its efficiency when dealing with Big Data imbalanced datasets.

Average results for the imbalanced Big Data cases of study using the GM measure
Computing Times and Complexity
In order to assess the performance in Big Data scenarios, we shall analyze the computing times for SD_DeTE methodology and the rest of the methods. In classification tasks, prediction times are more important than learning times, since models are only learned once but used multiple times in prediction. Such times can be seen in Table 6. As expected, the decision tree is the fastest in prediction, since it only requires to predict a simple tree. Random forest also achieves good prediction times, since neither the decision tree nor random forest uses any data preprocessing techniques when predicting. In spite of this, SD_DeTE methodology is very competitive in prediction, being less than one second slower than PCARDE. SD_DeTE is able to predict Big imbalanced Datasets in a short amount of time.

Average results for the imbalanced Big Data cases of study using the AUC measure
The computational complexity of SD_DeTE is reduced to the PCA time complexity. PCA computational complexity is known to be \(O(p^2n + p^3)\), being n the number of data points, and p the number of features. \(O(p^2n)\) is for the computation of the covariance matrix, and \(O(p^3)\) of the eigen-value decomposition. On the other hand, k-Means (and its variant Bisecting k-Means), despite belonging to the family of hierarchical clustering methods, which have quadratic time complexity \(O(n^2)\), has a linear computational complexity of O(n). Random discretization also has linear computational complexity. The decision tree has a computational complexity of O(nlog(n)). For the ensemble, we repeat this process iter times, so the final computational complexity is \(O(iter(p^2n + p^3 + n + nlog(n)))\).
Clustering-Based ROS vs ROS
Basic data over- and undersampling methods replicate and remove instances randomly. Replicating problematic instances, such as borderline instances, will lead to the classifier performing poorly. This problem is aggravated in Big Data environments, where the partitioning of the data will lead to smaller subsets of the dataset with a few instances. In SD_DeTE, with the incorporation of the clustering step, we divide the majority and minority classes by similarity, ensuring that we replicate instances in the proper regions in order to maintain spatial coherency among instances [42].
We have conducted an additional experiment for analyzing the performance of our proposed clustering-based ROS. Figures 5 and 6 show the results of SD_DeTE methodology against SD_DeTE methodology without using the clustering-based ROS (only performing ROS), using both GM and AUC measures. The full results can be found in Appendix Tables 7 and 8.
SD_DeTE methodology, using the proposed clustering-based ROS, achieves the best results overall. On average, it is improving the performance in both GM and AUC measures by 1 full point. There are datasets where this difference is even more noticeable, such as poker0_vs_2, in which the difference increases to more than 8 points. This shows the excellent performance of the proposed clustering-based ROS in the SD_DeTE methodology.
Conclusions
In this paper, we have proposed a novel Smart Data driven Decision Trees Ensemble methodology for addressing the imbalanced classification problem in Big Data domains, namely SD_DeTE methodology. SD_DeTE methodology makes use of the combination of different data preprocessing methods for improving the quality of the data used in the learning of the ensemble. This quality data is able to produce an ensemble composed of efficient distributed algorithms. SD_DeTE methodology uses RD and PCA for achieving diversity in the Smart Data sets for the ensemble process, plus a novel combination of clustering and oversampling with ROS for achieving a balanced and smart dataset while adding another level of diversity.
In view of the results, we can conclude the following:
-
The combination of RD and PCA for adding diversity to the ensemble algorithm achieves excellent performance in imbalanced big datasets.
-
The proposed addition of hierarchical clustering and ROS for balancing the data has proven to be able to effectively produce balanced datasets, while adding another level of diversity to the ensemble.
-
SD_DeTE methodology has proven to be able to achieve efficient distributed algorithms using Smart Data, producing an ensemble capable of tackling Big Data imbalanced problems efficiently and effectively.
In summary, addressing imbalanced classification is an ongoing and vital research endeavor. Future research should strive to create more adaptive, interpretable, and fair models, while also considering the practical challenges posed by real-world applications in various domains. The urgency of making rapid decisions in these applications demands not only high predictive accuracy but also low-latency processing, adding an additional layer of complexity. Addressing imbalanced classification in real time is fundamental for timely and accurate responses to evolving situations, ensuring the effectiveness of machine learning solutions in applications where immediate action is key [52, 53]. By pursuing these research directions, we can make significant strides towards improving the reliability and effectiveness of imbalanced classification solutions.
Data Availability
The datasets analyzed during the current study are available in the UCI repository [48] and available from the corresponding author on reasonable request.
Notes
For a complete description of Spark’s operations, please refer to Spark’s API: http://spark.apache.org/docs/latest/api/scala/index.html.
References
Bansal M, Chana I, Clarke S. A survey on IoT Big data: Current status, 13 V’s challenges, and future directions. ACM Comput Surv. 53(6).
Kaiser MS, Zenia N, Tabassum F, Mamun SA, Rahman MA, Islam MS, Mahmud M. 6G access network for intelligent Internet of Healthcare Things: Opportunity, challenges, and research directions. In: Kaiser MS, Bandyopadhyay A, Mahmud M, Ray K, editors. Proceedings of International Conference on Trends in Computational and Cognitive Engineering. Singapore: Springer Singapore; 2021. pp. 317–28.
Ramírez-Gallego S, Fernández A, García S, Chen M, Herrera F. Big data: Tutorial and guidelines on information and process fusion for analytics algorithms with MapReduce. Inf Fusion. 2018;42:51–61.
Khan N, Naim A, Hussain MR, Naveed QN, Ahmad N, Qamar S. The 51 v’s of big data: Survey, technologies, characteristics, opportunities, issues and challenges. In: Proceedings of the International Conference on Omni-Layer Intelligent Systems, COINS ’19. New York: Association for Computing Machinery; 2019. pp. 19–24.
Ge M, Bangui H, Buhnova B. Big data for Internet of Things: a survey. Futur Gener Comput Syst. 2018;87:601–14.
Shwartz-Ziv R, Armon A. Tabular data: Deep learning is not all you need. arXiv:2106.03253 [Preprint]. 2021. Available from: http://arxiv.org/abs/2106.03253.
Thabtah F, Hammoud S, Kamalov F, Gonsalves A. Data imbalance in classification: Experimental evaluation. Inf Sci. 2020;513:429–41.
Fernández A, García S, Galar M, Prati RC, Krawczyk B, Herrera F. Learning from imbalanced data sets. Springer; 2018.
Luengo J, García-Gil D, Ramírez-Gallego S, García S, Herrera F. Big data preprocessing - enabling smart data. Springer; 2020.
Fernández A, del Río S, Chawla NV, Herrera F. An insight into imbalanced big data classification: Outcomes and challenges. Complex Intell Syst. 2017;3(2):105–20.
Basgall MJ, Hasperué W, Naiouf M, Fernández A, Herrera F. SMOTE-BD: an exact and scalable oversampling method for imbalanced classification in big data. J Comput Sci Technol. 2018;18(03).
Gutiérrez PD, Lastra M, Benítez JM, Herrera F. SMOTE-GPU: Big data preprocessing on commodity hardware for imbalanced classification. Progr Artif Intell. 2017;6(4):347–54.
Leevy JL, Khoshgoftaar TM, Bauder RA, Seliya N. A survey on addressing high-class imbalance in big data. J Big Data. 2018;5(1):1–30.
Juez-Gil M, Arnaiz-González Á, Rodríguez JJ, García-Osorio C. Experimental evaluation of ensemble classifiers for imbalance in big data. Appl Soft Comput. 2021;108.
Xie X, Zhang Q. An edge-cloud-aided incremental tensor-based fuzzy c-means approach with big data fusion for exploring smart data. Inf Fusion. 2021;76:168–74.
Galar M, Fernández A, Barrenechea E, Bustince H, Herrera F. A review on ensembles for the class imbalance problem: Bagging-, boosting-, and hybrid-based approaches. IEEE Trans Syst Man Cybern C Appl Rev. 2012;42(4):463–84.
García-Gil D, Luengo J, García S, Herrera F. Enabling smart data: Noise filtering in big data classification. Inf Sci. 2019;479:135–52.
García-Gil D, Luque-Sánchez F, Luengo J, García S, Herrera F. From big to smart data: Iterative ensemble filter for noise filtering in big data classification. Int J Intell Syst. 2019;34(12):3260–74.
García-Gil D, Ramírez-Gallego S, García S, Herrera F. Principal components analysis random discretization ensemble for big data. Knowl Based Syst. 2018;150:166–74.
Meng X, Bradley J, Yavuz B, Sparks E, Venkataraman S, Liu D, Freeman J, Tsai D, Amde M, Owen S, Xin D, Xin R, Franklin MJ, Zadeh R, Zaharia M, Talwalkar A. MLlib: Machine learning in Apache Spark. J Mach Learn Res. 2016;17(34):1–7.
Carrasco J, García S, del Mar Rueda M. rNPBST: An R package covering non-parametric and Bayesian statistical tests. In: Martínez de Pisón FJ, Urraca R, Quintián H, Corchado E, editors. Hybrid artificial intelligent systems. Cham: Springer International Publishing; 2017. p. 281–92.
Wu X, Wen C, Wang Z, Liu W, Yang J. A novel ensemble-learning-based convolution neural network for handling imbalanced data. Cogn Comput. 2023;1–14.
Bi J, Zhang C. An empirical comparison on state-of-the-art multi-class imbalance learning algorithms and a new diversified ensemble learning scheme. Knowl Based Syst. 2018;158:81–93.
Batista GEAPA, Prati RC, Monard MC. A study of the behavior of several methods for balancing machine learning training data. SIGKDD Explor Newsl. 2004;6(1):20–9.
Juez-Gil M, Arnaiz-Gonzalez A, Rodriguez JJ, Lopez-Nozal C, Garcia-Osorio C. Approx-SMOTE: Fast SMOTE for big data on Apache Spark. Neurocomputing. 2021;464:432–7.
Fernández A, García S, Herrera F, Chawla NV. SMOTE for learning from imbalanced data: Progress and challenges, marking the 15-year anniversary. J Artif Intell Res. 2018;61:863–905.
Ma J, Afolabi DO, Ren J, Zhen A. Predicting seminal quality via imbalanced learning with evolutionary safe-level synthetic minority over-sampling technique. Cogn Comput. 2019;1–12.
Nejatian S, Parvin H, Faraji E. Using sub-sampling and ensemble clustering techniques to improve performance of imbalanced classification. Neurocomputing. 2018;276:55–66.
Le HL, Landa-Silva D, Galar M, Garcia S, Triguero I. EUSC: a clustering-based surrogate model to accelerate evolutionary undersampling in imbalanced classification. Appl Soft Comput. 2021;101.
Lin W-C, Tsai C-F, Hu Y-H, Jhang J-S. Clustering-based undersampling in class-imbalanced data. Inf Sci. 2017;409:17–26.
Zhang Y-P, Zhang L-N, Wang Y-C. Cluster-based majority under-sampling approaches for class imbalance learning. In: 2010 2nd IEEE International Conference on Information and Financial Engineering. IEEE; 2010. pp. 400–4.
Barandela R, Sánchez J, García V, Rangel E. Strategies for learning in class imbalance problems. Pattern Recogn. 2003;36(3):849–51.
Huang J, Ling CX. Using AUC and accuracy in evaluating learning algorithms. IEEE Trans Knowl Data Eng. 2005;17(3):299–310.
Yang T, Ying Y. AUC maximization in the era of big data and AI: a survey. ACM Comput Surv. 2022;55(8):1–37.
Dean J, Ghemawat S. MapReduce: Simplified data processing on large clusters. In: Proceedings of the 6th Conference on Symposium on Operating Systems Design & Implementation - Volume 6, OSDI’04, USENIX Association, USA. 2004. p. 10.
White T. Hadoop: the definitive guide. O’Reilly Media, Inc.; 2012.
Lin J. MapReduce is good enough? If all you have is a hammer, throw away everything that’s not a nail! Big Data. 2013;1(1):28–37.
Hamstra M, Karau H, Zaharia M, Konwinski A, Wendell P. Learning spark: Lightning-fast big data analytics. O’Reilly Media; 2015.
Zaharia M, Chowdhury M, Das T, Dave A, Ma J, McCauly M, Franklin MJ, Shenker S, Stoica I. Resilient distributed datasets: a fault-tolerant abstraction for in-memory cluster computing. In: Proceedings of the 9th USENIX Symposium on Networked Systems Design and Implementation (NSDI 12). San Jose: USENIX; 2012. pp. 15–28.
Meng X, Bradley J, Yavuz B, Sparks E, Venkataraman S, Liu D, Freeman J, Tsai D, Amde M, Owen S, et al. MLlib: Machine learning in Apache Spark. J Mach Learn Res. 2016;17(1):1235–41.
del Río S, López V, Benítez JM, Herrera F. On the use of MapReduce for imbalanced big data using random forest. Inf Sci. 2014;285:112–37.
Sleeman WC IV, Krawczyk B. Multi-class imbalanced big data classification on spark. Knowl Based Syst. 2021;212:106598.
Zhai J, Zhang S, Wang C. The classification of imbalanced large data sets based on MapReduce and ensemble of ELM classifiers. Int J Mach Learn Cybern. 2017;8(3):1009–17.
Ahmad A, Brown G. Random projection random discretization ensembles-ensembles of linear multivariate decision trees. IEEE Trans Knowl Data Eng. 2014;26(5):1225–39.
Steinbach M, Karypis G, Kumar V, et al. A comparison of document clustering techniques. In: KDD Workshop on Text Mining, Vol. 400, Boston. 2000. pp. 525–6.
Rokach L, Maimon O. Data mining with decision trees: Theory and applications. 2nd ed. USA: World Scientific Publishing Co. Inc.; 2014.
Baldi P, Sadowski P, Whiteson D. Searching for exotic particles in high-energy physics with deep learning. Nat Commun. 2014;5:4308.
Dua D, Graff C. UCI machine learning repository. 2017. http://archive.ics.uci.edu/ml.
Triguero I, del Río S, López V, Bacardit J, Benítez JM, Herrera F. ROSEFW-RF: the winner algorithm for the ECBDL’14 big data competition: an extremely imbalanced big data bioinformatics problem. Knowl Based Syst. 2015;87:69–79.
Adiba FI, Islam T, Kaiser MS, Mahmud M, Rahman MA. Effect of corpora on classification of fake news using Naive Bayes classifier. Int J Autom Artif Intell Mach Learn. 2020;1(1):80–92.
Benavoli A, Corani G, Demšar J, Zaffalon M. Time for a change: a tutorial for comparing multiple classifiers through Bayesian analysis. J Mach Learn Res. 2017;18(1):2653–88.
Jagadeesan J, Kirupanithi DN, et al., An optimized ensemble support vector machine-based extreme learning model for real-time big data analytics and disaster prediction. Cogn Comput. 2023;1–23.
Rahman MA, Brown DJ, Mahmud M, Harris M, Shopland N, Heym N, Sumich A, Turabee ZB, Standen B, Downes D, et al. Enhancing biofeedback-driven self-guided virtual reality exposure therapy through arousal detection from multimodal data using machine learning. Brain Inform. 2023;10(1):1–18.
Funding
Funding for open access publishing: Universidad de Granada/CBUA. This work is supported by the Spanish National Research Project PID2020-119478GB-I00. The research is also supported by the Swedish Research Council (project number: 2016-05431).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Ethical Approval
This article does not contain any studies with human participants performed by any of the authors.
Conflict of Interest
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
García-Gil, D., García, S., Xiong, N. et al. Smart Data Driven Decision Trees Ensemble Methodology for Imbalanced Big Data. Cogn Comput 16, 1572–1588 (2024). https://doi.org/10.1007/s12559-024-10295-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12559-024-10295-z