tABLE OF cONTENTS
Web crawlers, also known as web spiders or web robots, are automated programs that browse the World Wide Web in search of specific information. They are used by search engines to index websites and gather data for various purposes.
When a web crawler is initiated, it begins by visiting a seed URL, which is a starting point for the crawl. From this initial page, the crawler follows the links and redirects on the page to discover new pages and continues this process until it has explored the entire site or a specified number of pages.
As the crawler navigates through the web, it extracts information such as the title, meta tags, and keywords of each page. This information is then stored in a database, allowing search engines to quickly retrieve relevant results when a user conducts a search.
In order to avoid getting stuck in an infinite loop or visiting irrelevant pages, web crawlers are programmed with certain rules and algorithms. For example, they may be programmed to ignore certain pages, such as those with login forms or those that have already been visited. They may also be programmed to prioritize certain pages, such as those with high PageRank or those that are frequently updated.
Web crawlers also have to be careful not to overburden a website with requests, as this can slow down the site and cause issues for users. To avoid this, they are typically programmed to limit the number of requests they make to a particular site and to wait for a certain amount of time before revisiting the site.
In addition to indexing websites, web crawlers can also be used for a variety of other purposes, such as monitoring the health of a website, tracking changes to a site, or collecting data for market research.
Overall, web crawlers are an essential component of the World Wide Web, allowing search engines to quickly and efficiently index and retrieve information from the vast amount of content available online. Without them, the process of searching for information on the web would be much slower and less efficient.
The history of web crawling can be traced back to the early days of the internet, when search engines first emerged as a way to index and organize the vast amounts of information available online. In the early 1990s, the first search engines, such as Archie and Veronica, used simple keyword-based algorithms to search for and index web pages.
As the internet continued to grow and the amount of information available online exploded, more sophisticated search engines, such as AltaVista and Lycos, emerged. These search engines used more advanced algorithms to better index and organize web pages, and also introduced the concept of web crawling, which involved sending out automated "bots" to systematically scan and index the entire internet.
However, the early web crawlers were limited in their capabilities and often ran into issues with duplicate content, spam, and other challenges. This led to the development of more sophisticated web crawling algorithms and technologies, such as the PageRank algorithm developed by Google.
With the rise of social media and other dynamic web content, web crawling has become even more complex and sophisticated. Today's web crawlers must be able to handle constantly changing web content, handle large amounts of data, and navigate complex web structures. They must also be able to recognize and avoid spam and other malicious content.
Web crawling has also become more important as the internet has become increasingly central to our daily lives. Search engines, social media platforms, and other online services rely on web crawling to provide us with the information we need and want. In addition, web crawling is also used for a variety of other purposes, such as data mining, market research, and even security and surveillance.
Overall, the history of web crawling has been one of continuous evolution and innovation. From the early days of keyword-based search algorithms, to today's sophisticated web crawlers, the technology has evolved to meet the changing needs of the internet and its users. As the internet continues to grow and change, it is likely that web crawling will continue to evolve and play an increasingly important role in our digital world.
Google's crawler, also known as Googlebot, is a critical component of the search giant's search engine. It is responsible for constantly scouring the internet, discovering new websites and pages, and adding them to Google's index.
This index is then used by the search engine to provide relevant results to users' queries.
Googlebot uses algorithms to determine which websites and pages to crawl. These algorithms take into account factors such as the relevance of a page's content to a user's query, the popularity of a website, and the quality of its content. Googlebot also uses algorithms to determine how frequently to crawl a particular website or page, often referred to as the website's crawl budget.
Once Googlebot has discovered a website or page, it will begin to crawl it. This involves following links on the page, extracting the content, and adding it to the index. Googlebot also analyzes the content of the page, using natural language processing algorithms to understand the meaning and context of the text. This allows Google to provide more accurate and relevant results to users.
Googlebot also has the ability to execute JavaScript and render web pages, allowing it to access and index content that is generated dynamically. This is especially important for modern websites that rely heavily on JavaScript and other technologies to generate content.
Googlebot also uses special techniques to crawl websites that require authentication, such as password-protected pages or private forums. In these cases, Googlebot will use the website's login information to access the content and index it.
One of the key challenges for Googlebot is keeping up with the constantly changing nature of the internet. New websites and pages are created all the time, and existing ones are frequently updated. To address this, Googlebot is designed to be highly scalable, with the ability to crawl millions of pages per day.
Googlebot is also designed to be efficient, using techniques such as parallel crawling and load balancing to distribute the workload across multiple servers. This allows Googlebot to crawl large websites and pages quickly and efficiently.
In addition to crawling the web, Googlebot also monitors the health and performance of websites. This includes checking for broken links, server errors, and other issues that could affect the user experience. Googlebot also uses data from its crawls to generate reports and insights for website owners, providing valuable information on how their site is performing and how it can be improved.
Overall, Google's crawler is a critical component of the search engine, responsible for discovering and indexing the vast amount of information on the internet. Its ability to crawl and understand web pages allows Google to provide users with accurate and relevant results to their queries.
Headless Chrome is a version of the popular Google Chrome web browser that has been stripped of its graphical user interface (GUI), allowing it to be run on a command line interface (CLI) or in the background without the need for a visible UI. This makes it an ideal tool for automating web scraping and testing tasks, as well as for running web applications in a server environment.
One of the key features of Headless Chrome is its use of the Blink rendering engine, which is a fork of the WebKit engine that was developed by Google. This engine is used to interpret and render web pages, and it is known for its speed and efficiency.
One advantage of using Blink for rendering is that it allows Headless Chrome to execute JavaScript code in a more efficient manner. This is important for tasks such as web scraping, where large amounts of data need to be extracted from multiple web pages in a short amount of time.
Another advantage of using Blink is that it is closely integrated with the Chrome browser, which means that Headless Chrome can take advantage of the same features and tools that are available in the regular version of Chrome. This includes access to the Chrome DevTools, which can be used to debug and troubleshoot web applications.
Furthermore, Blink is also used by other popular browsers such as Opera and Microsoft Edge, which means that Headless Chrome can be used to test web applications across multiple browsers with minimal effort. This is an important consideration for developers who need to ensure that their web applications are compatible with different browsers.
In addition to its rendering capabilities, Headless Chrome also offers a number of other benefits for developers and users. For example, it allows users to run multiple instances of the browser at the same time, which is useful for testing different scenarios or running multiple tasks concurrently.
Headless Chrome also offers a number of command line flags that can be used to customize its behavior. This allows users to specify a particular user agent, set a custom window size, or disable certain features such as JavaScript or images.
Overall, the combination of Headless Chrome and the Blink rendering engine offers a powerful tool for automating web tasks and testing web applications. Its ability to execute JavaScript code efficiently, integrate with the Chrome browser, and support multiple browsers makes it an essential tool for developers and users alike.
Web crawlers, also known as web spiders or web robots, are automated programs that browse the internet and collect data from various websites. These crawlers play an important role in helping search engines index and rank websites, as well as providing valuable data for market research and other purposes. However, there are several challenges that web crawlers face in their pursuit of data.
One of the major challenges for web crawlers is the vastness of the internet. With over 1.75 billion websites currently in existence, it is impossible for a single web crawler to visit and collect data from all of them. This means that crawlers must be selective in the websites they visit, using algorithms and other methods to prioritize the most relevant and valuable sites. Even with these strategies, there are still countless websites that are never visited by web crawlers, making it difficult to obtain a complete and accurate picture of the internet.
Another challenge for web crawlers is the constantly changing nature of the internet. Websites are constantly being updated, added, and removed, making it difficult for crawlers to keep track of all the changes. Additionally, the content and structure of websites can vary greatly, making it difficult for crawlers to accurately parse and interpret the data they collect. These challenges can lead to incomplete or outdated data, which can impact the accuracy and usefulness of the information provided by web crawlers.
One of the biggest challenges for web crawlers is the issue of web scraping and spamming. Web scraping refers to the practice of using web crawlers to collect data from websites without the permission of the website owners. This can be a major problem for web crawlers, as it can lead to the collection of inaccurate or irrelevant data, as well as damaging the reputation of the crawler and the organization it represents. In addition to web scraping, web crawlers also face the challenge of spamming, where they are used to generate fake traffic or manipulate search engine rankings. This can be a major issue for both web crawlers and the websites they visit, as it can lead to poor user experiences and decreased trust in the internet as a whole.
Another significant challenge for web crawlers is the issue of privacy and security. As web crawlers collect data from websites, they may inadvertently collect personal information from users. This can include names, email addresses, and other sensitive information, which can be a major concern for users and website owners. To address this issue, web crawlers must be careful to only collect data that is publicly available and to protect the privacy of users. A Robots Exclusion Standard has been created to address this, and allows webmasters the ability to instruct search engines what they can and cannot crawl and/or index. Additionally, web crawlers must also be aware of potential security threats, such as malware and hacking, which can compromise the data they collect and put both the crawler and the website at risk.
In conclusion, web crawlers face a number of challenges in their pursuit of data from the internet. From the vastness and constantly changing nature of the internet, to the issues of web scraping, spamming, and privacy and security, web crawlers must navigate a complex and ever-evolving landscape in order to provide accurate and valuable information to users and organizations.
XML sitemaps and web crawlers play a vital role in ensuring the smooth functioning and visibility of a website.
Both XML sitemaps and web crawlers work together to ensure that a website's pages are indexed and easily accessible to users.XML sitemaps are essentially a list of all the pages on a website that a web crawler should index.
These sitemaps are written in XML format and contain the URLs of all the pages on the website, along with metadata such as the last time the page was updated, the frequency at which the page is updated, and the importance of the page relative to other pages on the website. XML sitemaps are important because they provide a roadmap for web crawlers to follow as they index the website. Without an XML sitemap, a web crawler may miss some pages on the website, which can lead to a poor user experience and low visibility in search engines.
Web crawlers, also known as spiders or bots, are software programs that scan the internet and index websites. They follow links from one page to another and record the content of each page they visit. This indexed content is then used by search engines to generate search results when a user enters a search query. Web crawlers are essential for ensuring that a website is visible to users. Without web crawlers, a website would not be indexed and would not appear in search engine results.
The role of web crawlers and XML sitemaps is particularly important for websites with large amounts of content or those that are frequently updated. For example, an e-commerce website with thousands of products would need a web crawler to index all of its pages in order for users to be able to find the products they are searching for. Similarly, a news website that updates its content multiple times a day would need a web crawler to index its pages frequently to ensure that the latest news is available to users.
One of the challenges of using web crawlers is that they can consume a lot of resources, such as bandwidth and storage, as they index the website. This is where XML sitemaps come in. XML sitemaps allow website owners to specify which pages are most important and should be crawled first. This helps to reduce the workload on the web crawler and ensures that the most important pages are indexed first.
In addition to helping web crawlers index a website, XML sitemaps also serve as a way for website owners to communicate with search engines. By including metadata in the XML sitemap, website owners can provide search engines with information about the pages on their website, such as when they were last updated and how often they are updated. This information can help search engines to prioritize the pages on a website when generating search results.
There are several benefits to using XML sitemaps and web crawlers. For one, they help to improve the visibility of a website in search engines. By ensuring that all the pages on a website are indexed, web crawlers make it easier for users to find the website when they search for relevant keywords. This can lead to increased traffic and ultimately, increased revenue for the website owner.
In addition, XML sitemaps and web crawlers can help website owners to identify any issues with their website, such as broken links or pages that are not being indexed. By analyzing the data collected by web crawlers, website owners can identify and fix any problems that may be impacting the visibility of their website.
In conclusion, XML sitemaps and web crawlers play a crucial role in the functioning and visibility of a website. XML sitemaps provide a roadmap for web crawlers to follow as they index the website, while web crawlers ensure that the website's pages are accessible to users. By working together, XML sitemaps and web crawlers help to improve the user experience and increase the visibility of a website in search engines. They also allow website owners to identify and fix any issues that may be impacting the website's performance. Ultimately, the use of XML sitemaps and web crawlers is essential for the success of any website.
A crawl budget is the amount of resources a search engine is willing to allocate to crawling a website.
This budget is determined by a number of factors, including the size and complexity of the website, the frequency of updates, and the quality and relevance of the content.
The size of a website's crawl budget is directly related to its overall traffic and popularity. Larger, more popular websites are likely to have a higher crawl budget, as they are considered more important and valuable to search engines. On the other hand, smaller, less popular websites may have a lower crawl budget, as they are considered less important and valuable.
The complexity of a website also plays a role in determining its crawl budget. Websites with a large number of pages and a complex structure may require more resources to crawl, which can lead to a lower crawl budget. On the other hand, websites with a simple structure and fewer pages may require fewer resources to crawl, which can lead to a higher crawl budget.
The frequency of updates to a website can also impact its crawl budget. Websites that are updated regularly with fresh, relevant content are likely to have a higher crawl budget, as they are considered more valuable to search engines. Websites that are not updated regularly or have outdated content may have a lower crawl budget, as they are considered less valuable.
The quality and relevance of a website's content is also a key factor in determining its crawl budget. Websites with high-quality, relevant content are likely to have a higher crawl budget, as they are considered more valuable to search engines. Websites with low-quality, irrelevant content may have a lower crawl budget, as they are considered less valuable.
Overall, a website's crawl budget is determined by a combination of factors, including its size, complexity, frequency of updates, and quality and relevance of content. By understanding and optimizing these factors, website owners can improve their crawl budget and increase their visibility in search engine results.
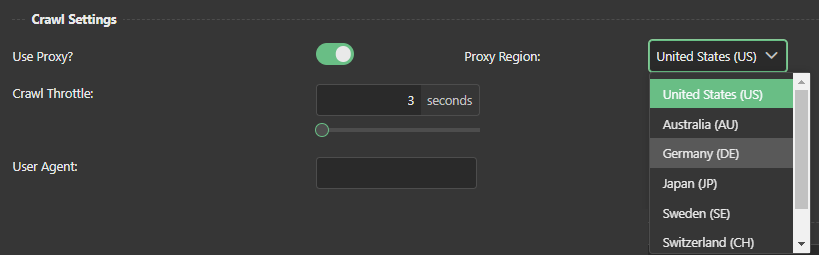
Proxy crawlers, also known as web crawlers or web spiders, are automated tools used to browse the internet and collect data from websites. They are commonly used by search engines, market research companies, and online businesses to gather information and improve their online presence.
A proxy crawler works by simulating a human user visiting a website and navigating through its pages. It follows links on the page and continues to crawl until it has collected all the information it needs. This information is then processed and stored in a database for future use.
One of the key benefits of using a proxy crawler is that it allows for large amounts of data to be collected quickly and efficiently. This is particularly useful for search engines, as they need to gather vast amounts of data from a wide range of websites in order to provide relevant and accurate search results.
Another advantage of proxy crawlers is that they can be customized to collect specific types of data. For example, a market research company may use a proxy crawler to collect information on product prices, availability, and customer reviews. This allows them to gain valuable insights into the market and make informed decisions.
One of the challenges of using proxy crawlers is that they can often be blocked by websites. This can happen if the website has implemented security measures to prevent automated access, or if the crawler is behaving in a way that is deemed suspicious or malicious. In such cases, the crawler may need to use a proxy server in order to access the website.
A proxy server acts as an intermediary between the proxy crawler and the website, allowing the crawler to access the website without revealing its true identity. This can help to avoid being blocked, but it also comes with its own set of challenges. For example, if the proxy server is slow or unreliable, it can impact the performance of the crawler and the quality of the data it collects.
Another potential issue with proxy crawlers is that they can sometimes be used for unethical purposes, such as scraping sensitive information or conducting cyber attacks. It is important for businesses and organizations to ensure that their proxy crawlers are used in a responsible and ethical manner, in accordance with relevant laws and regulations.
In conclusion, proxy crawlers are valuable tools that can help businesses and organizations to gather information and improve their online presence. They can be customized to collect specific types of data, and they can operate quickly and efficiently. However, they can also be blocked by websites, and they can be used for unethical purposes if not used responsibly.