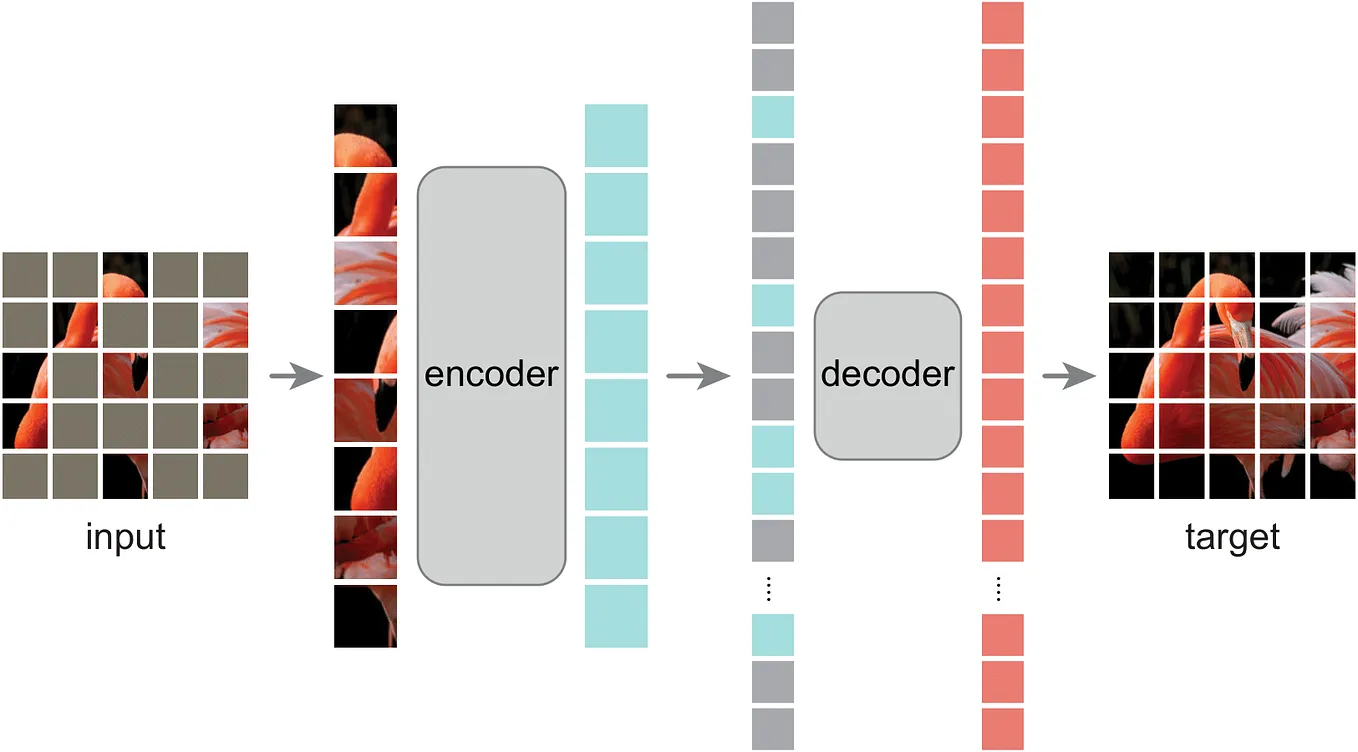
LokeshbadisaGSoC 2024 with ML4SCI | Masked Auto-Encoders for Efficient End-to-End Particle Reconstruction and…In this blog, I discuss my progress in Google Summer of Code 2024. The project which I worked on is “Masked Auto-Encoders for Efficient…Jul 24
Skylar Jean CallisinTowards Data ScienceTokens-to-Token Vision Transformers, ExplainedA Full Walk-Through of the Tokens-to-Token Vision Transformer, and Why It’s Better than the OriginalFeb 271
Skylar Jean CallisinTowards Data ScienceVision Transformers, ExplainedA Full Walk-Through of Vision Transformers in PyTorchFeb 2710Feb 2710
TashwinFrom Pixels to Predictions beyond CNN’s : The Vision Transformers (ViT)The google brain resesarch team introduced vision transformers in 2020, it uses attention mechanism of transformers model which was…Jul 23Jul 23
JorgecardeteinLevel Up CodingConvNeXt: In Search of the Last Convolutional LayerViTs are precise but not so efficient and CNNs are efficient but not so precise. Let’s create a precise and efficient neural networkJan 13Jan 13
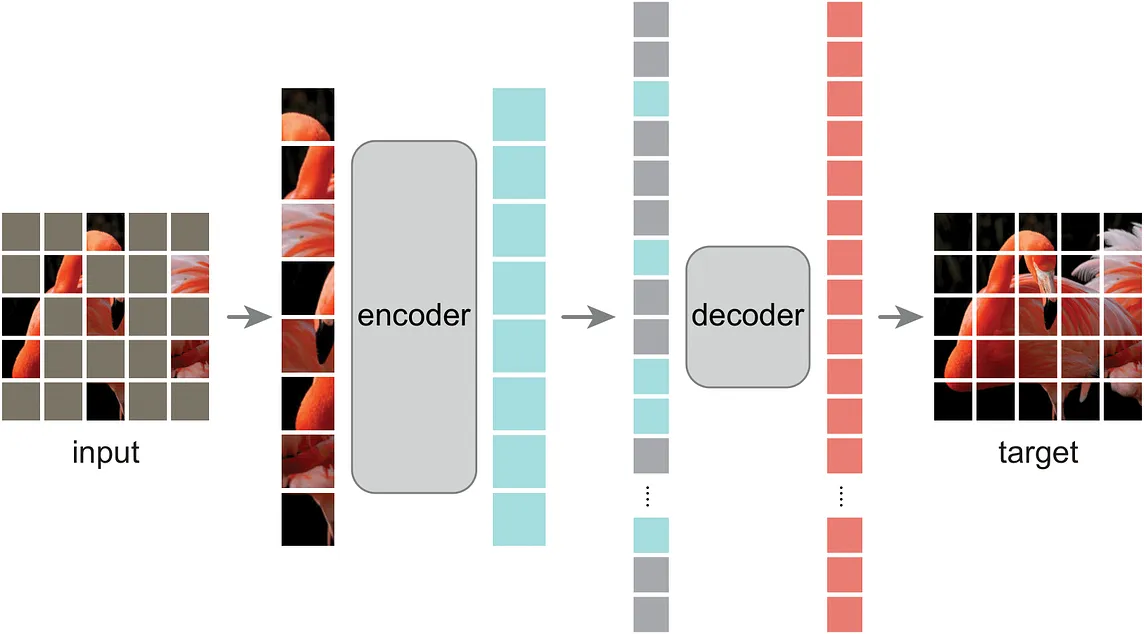
LokeshbadisaGSoC 2024 with ML4SCI | Masked Auto-Encoders for Efficient End-to-End Particle Reconstruction and…In this blog, I discuss my progress in Google Summer of Code 2024. The project which I worked on is “Masked Auto-Encoders for Efficient…Jul 24
Skylar Jean CallisinTowards Data ScienceTokens-to-Token Vision Transformers, ExplainedA Full Walk-Through of the Tokens-to-Token Vision Transformer, and Why It’s Better than the OriginalFeb 271
Skylar Jean CallisinTowards Data ScienceVision Transformers, ExplainedA Full Walk-Through of Vision Transformers in PyTorchFeb 2710
TashwinFrom Pixels to Predictions beyond CNN’s : The Vision Transformers (ViT)The google brain resesarch team introduced vision transformers in 2020, it uses attention mechanism of transformers model which was…Jul 23
JorgecardeteinLevel Up CodingConvNeXt: In Search of the Last Convolutional LayerViTs are precise but not so efficient and CNNs are efficient but not so precise. Let’s create a precise and efficient neural networkJan 13
Skylar Jean CallisinTowards Data SciencePosition Embeddings for Vision Transformers, ExplainedThe Math and the Code Behind Position Embeddings in Vision TransformersFeb 273
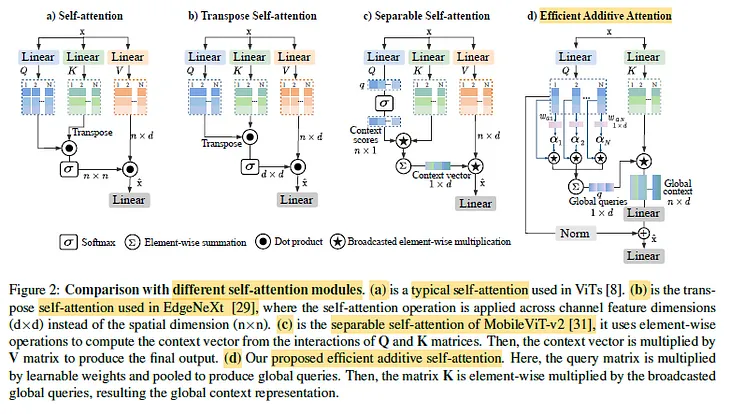
Sik-Ho TsangReview — SwiftFormer: Efficient Additive Attention for Transformer-based Real-time Mobile…SwiftFormer: Efficient Additive Attention for Transformer-based Real-time Mobile Vision Applications SwiftFormer, by Mohamed bin Zayed…Jul 21
Skylar Jean CallisinTowards Data ScienceAttention for Vision Transformers, ExplainedThe Math and the Code Behind Attention Layers in Computer VisionFeb 274