Knowing where things are in an image or video can be helpful in many situations. For example, if you're creating a wildlife monitoring system, identifying animals in a video allows you to count how many are in a specific area, track their movements, and observe their behaviour over time. Thanks to object detection, this is now possible.
Object detection, a cornerstone of computer vision, has evolved from simple beginnings to become indispensable in various applications ranging from security surveillance to autonomous vehicles. It can create new opportunities in every industry and lead to new applications that weren't possible before. This blog post delves into the fundamentals of object detection, explores the evolution of its methodologies, and envisions its future.
What is object detection in machine learning?
Object detection identifies and locates objects within images or videos. Unlike image recognition, which categorizes an entire image, object detection pinpoints specific objects, differentiating between multiple entities within the same scene. This involves recognizing what an object is and determining its precise location in the image space.
Consider a traffic management system to understand the significance of object detection. By using object detection, the system can identify different types of vehicles, such as cars, buses, and motorcycles, within a traffic camera feed.
This allows the system to monitor traffic flow, detect congestion, and even identify real-time accidents. Locating each vehicle in the image space enables the system to measure distances between vehicles, track their speeds, and predict potential collisions.
Object detection utilizes advanced algorithms and neural networks to achieve high accuracy. These methods analyze visual data, extract features, and classify objects, often using techniques such as convolutional neural networks (CNNs) and region-based methods. Integrating object detection into various applications, from security systems to retail analytics, demonstrates its versatility and the transformative impact it can have across different sectors.
Object detection enhances our understanding and interpretation of visual information. It enables the development of innovative solutions that improve efficiency, safety, and decision-making in numerous fields.

Early traditional approaches in object detection
Initial attempts at object detection relied on template matching and featurebased methods. Template matching involved comparing new images to predefined templates or shapes to detect objects. However, this approach struggled with variations in object scale, rotation, and lighting conditions.
Feature-based methods improved upon this by identifying unique features within an object (e.g., edges or corners) that were invariant to scale and rotation. Algorithms like SIFT (ScaleInvariant Feature Transform) and SURF (Speeded Up Robust Features) were popular. Despite their advancements, these methods were still limited by their inability to handle large variations in object appearance, background clutter, and occlusion. The computational complexity and the manual engineering of features made these approaches less scalable and adaptable to new object categories or changes in visual appearance.
Deep learning vs. machine learning
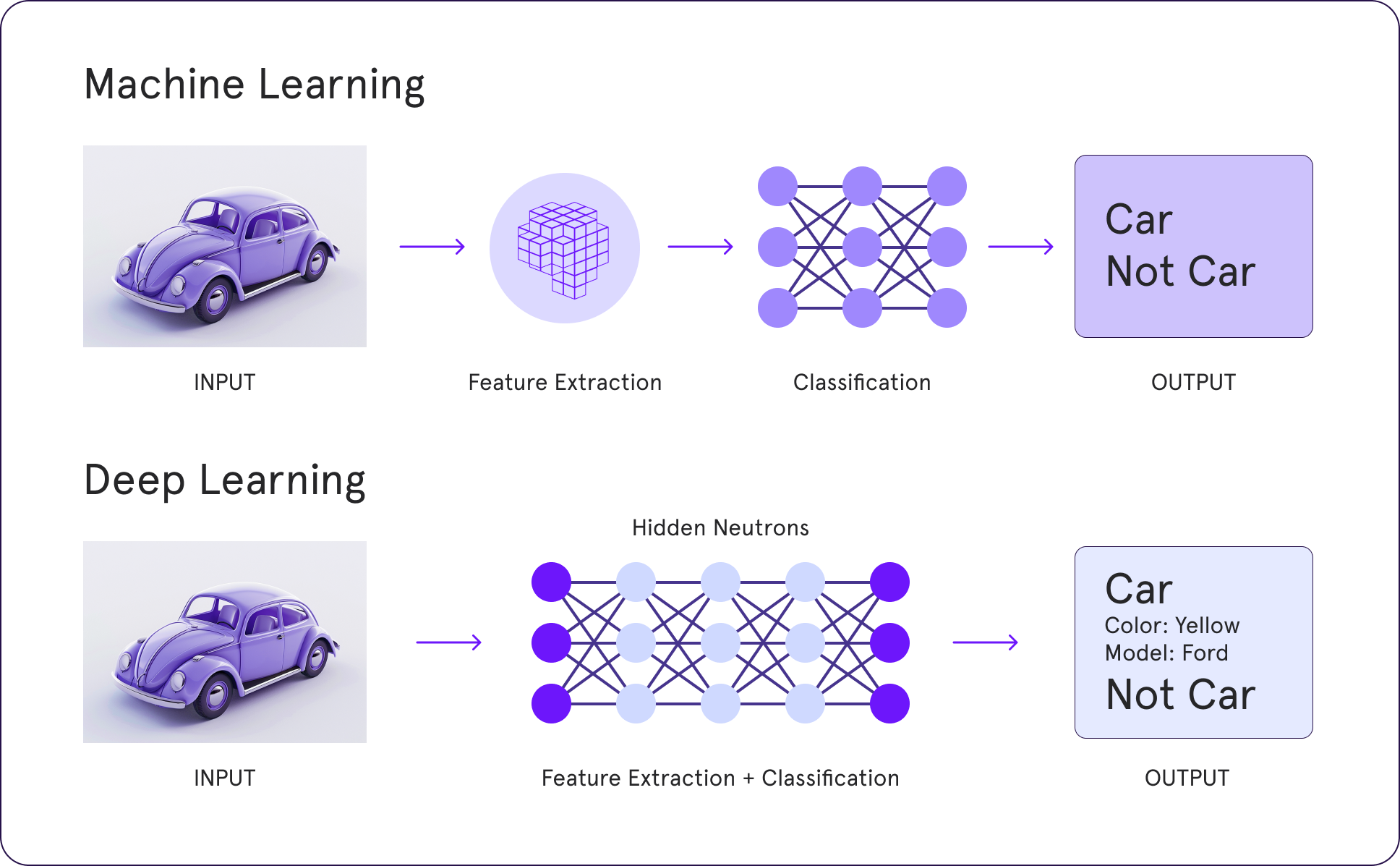
Deep learning vs Machine Learning
The advent of deep learning marked a revolutionary shift in object detection. Unlike traditional machine learning, which relies on handcrafted features, deep learning algorithms automatically learn hierarchical feature representations from data. This capability has significantly improved accuracy and robustness in object detection.
Convolutional Neural Networks (CNNs) have been at the forefront of this shift. They process images in layers, with each layer learning more complex features. Early CNN architectures like AlexNet and VGG16 laid the groundwork. At the same time, more sophisticated designs like Faster R-CNN, SSD (Single Shot MultiBox Detector), and YOLO (You Only Look Once) further advanced the field by increasing detection speed and accuracy.
Machine Learning and Deep Learning are crucial approaches to object detection, but they differ significantly in their methodologies, capabilities, and applications.
Machine Learning in Object Detection
Machine Learning (ML) involves training models using algorithms that learn patterns from data. Traditional ML approaches for object detection often rely on feature extraction methods combined with classifiers like Support Vector Machines (SVMs) or decision trees.
Key Characteristics:
- Feature Engineering: Requires manual feature extraction and selection to identify the relevant attributes of objects within images.
- Algorithms: Utilize methods such as HOG (Histogram of Oriented Gradients) and SVM for detecting objects.
- Training Data: Labeled data is generally needed to train models, but the required data is less than for deep learning.
- Performance: Effective for more straightforward and structured datasets but may struggle with complex variations and large-scale datasets.
- Example: In a facial recognition system, ML might use features like the distance between eyes, nose shape, and other predefined attributes to recognize faces.
Deep Learning in Object Detection
Deep Learning (DL) is a subset of ML that uses neural networks with many layers (hence "deep") to learn representations from data automatically. Convolutional Neural Networks (CNNs) are particularly well-suited for image-related tasks.
Key Characteristics:
- Automatic Feature Extraction: Deep learning models learn to extract features automatically during training, eliminating the need for manual feature engineering.
- Algorithms: Common architectures include YOLO (You Only Look Once), SSD (Single Shot Multibox Detector), and R-CNN (Region-based Convolutional Neural Networks).
- Training Data: Requires large amounts of labelled data and significant computational resources for training.
- Performance: Can handle complex variations and large-scale datasets, achieving higher accuracy and robustness in object detection tasks.
- Example: In autonomous driving, deep learning models can detect and classify multiple objects, such as cars, pedestrians, and traffic signs, in real-time, adapting to diverse and dynamic environments.
While both ML and DL have their strengths, DL has become the dominant approach for object detection due to its superior performance in handling complex and large-scale data. ML, however, can still be helpful for more straightforward applications where computational resources or large datasets are limited. The choice between ML and DL ultimately depends on the specific requirements of the object detection task at hand.
How Object Detection Works
Object detection is a complex process that enables a computer to identify and localize objects within an image or video. Here’s a detailed look into the technical steps involved:
1. Image Preprocessing
The first step involves preprocessing the input image. This typically includes resizing the image to a standard dimension, normalizing pixel values, and converting the image into a format suitable for the neural network. Preprocessing helps standardize the input, making it easier for the network to process.
The next step is feature extraction, where the computer analyzes the image to detect low-level features such as edges, corners, and textures. Convolutional Neural Networks (CNNs) are commonly used for this purpose. Convolutional layers apply filters to the image to create feature maps, capturing essential details about the image content.
3. Region Proposal
Once features are extracted, the network proposes potential regions where objects might be located. Techniques like Region Proposal Networks (RPNs) generate bounding boxes around areas of interest. These regions are then fed into further layers for detailed analysis.
4. Classification and Localization
The network performs two tasks for each proposed region: classification and localization. Classification involves identifying the object within the region, while localization fine-tunes the bounding box coordinates to enclose the object precisely. This is often achieved through layers that output class scores and bounding box offsets.
5. Non-Maximum Suppression
To eliminate redundant and overlapping bounding boxes, non-maximum suppression (NMS) is applied. NMS ensures that only the most confident detections are retained, reducing false positives and improving the accuracy of the detected objects.
6. Bounding Box Regression
Bounding box regression is a refinement step where the network adjusts the positions of the bounding boxes to more accurately fit the detected objects. This involves regressing the coordinates of the bounding boxes based on the predicted offsets from the network.
7. Post-processing
Finally, post-processing steps are applied to ensure the accuracy and reliability of the detections. This may include techniques like thresholding, where detections with low confidence scores are discarded, and further refinements to ensure the bounding boxes are well-aligned with the objects.
Transformers, originally designed for natural language processing tasks, have recently made significant inroads in computer vision, including object detection. Their ability to handle sequences of data and capture longrange dependencies makes them wellsuited for analyzing the spatial relationships between objects in an image.
Models like DETR (Detection Transformer) and its successors have shown promising results, merging the capabilities of CNNs and transformers to efficiently process both global image features and fine details necessary for detecting objects. This approach has simplified the object detection pipeline, eliminating the need for many handtuned components present in traditional models.
State-of-the-art (SOTA) object detection models
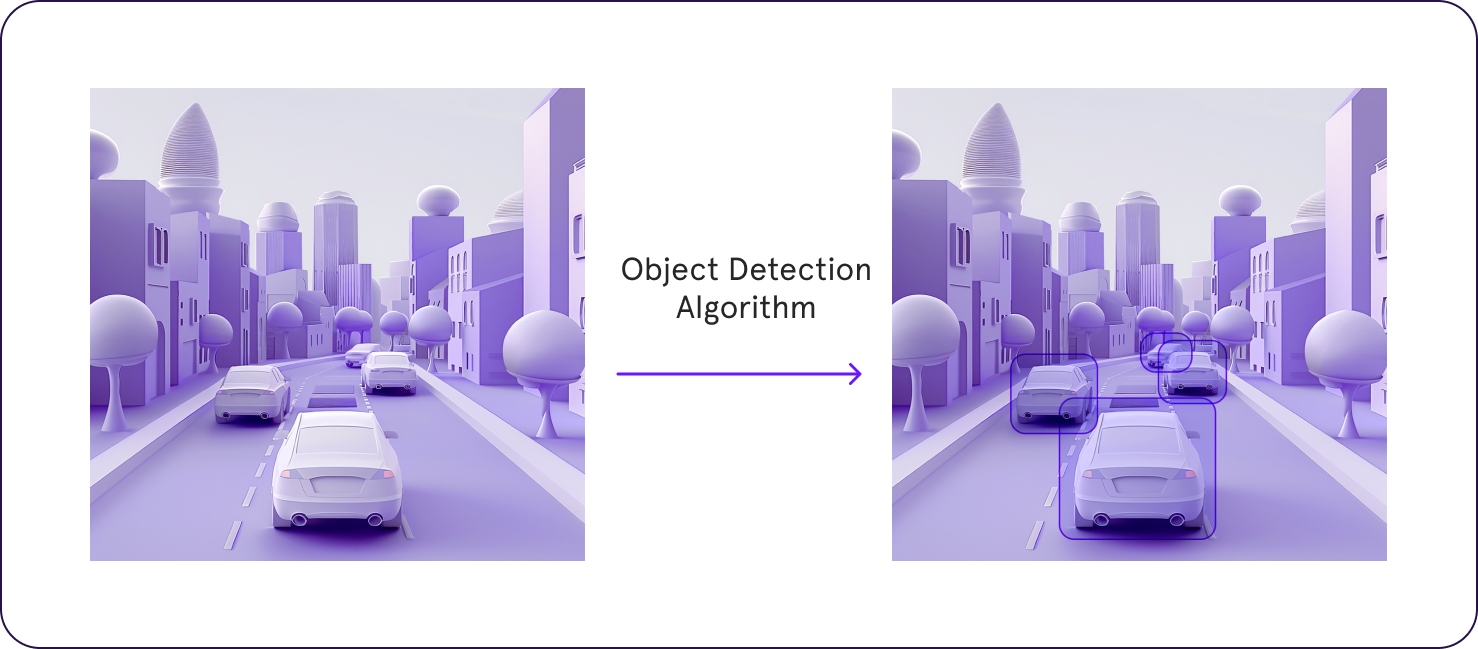
The current state-of-the-art in object detection is represented by models that combine the strengths of deep learning architectures, especially CNNs and transformers, with advanced optimization and training strategies. These models achieve remarkable precision and speed, making realtime object detection feasible for even complex scenarios.
Techniques like Few-Shot Learning and Zero-Shot Learning are pushing the boundaries further, enabling models to detect objects they have never seen during training. Continuous improvements in network efficiency, training methodologies, and data augmentation strategies also contribute to the ongoing advancement of SOTA models.
The future of object detection

The future of object detection lies in the development of more efficient, accurate, and adaptable models. This includes exploring new architectures, improving the interpretability of models, and reducing their dependency on large labeled datasets. The integration of object detection with other technologies, such as augmented reality and edge computing, opens new avenues for application, enhancing both the scope and the impact of object detection systems.
Advancements in unsupervised and semisupervised learning methods could significantly reduce the need for labeled training data, addressing one of the major challenges in training object detection models. Furthermore, the ongoing research into ethical AI and bias mitigation is crucial for ensuring that object detection technologies are used responsibly and fairly.
