Transformers in music recommendation
August 16, 2024
Anushya Subbiah and Vikram Aggarwal, Software Engineers, Google Research
Quick links
Users have more choices for listening to music than ever before. Popular services boast of massive and varied catalogs. The YouTube Music catalog, for example, has over 100M songs globally. It follows that item recommendations are a core part of these products. Recommender systems make sense of the item catalog and are critical for tuning the catalog for the user’s tastes and needs. In products that provide recommendations, user actions on the recommended items — such as skip, like, or dislike — provide an important signal about user preferences. Observing and learning from these actions can lead to better recommendation systems. In YouTube Music, leveraging this signal is critical to understanding a user's musical taste.
Consider a scenario where a user typically likes slow-tempo songs. When presented with an uptempo song, the user would typically skip it. However, at the gym, when they’re in a workout session, they like more uptempo music. In such a situation, we want to continue learning from their prior history to understand their musical preferences. At the same time, we want to discount prior skips of uptempo songs when recommending workout music.
Below we illustrate the users’ music listening experience, with music songs shown as items and with the user’s actions as text beneath. In current recommendation systems that don’t consider the broader context, we would predict that the user will skip an uptempo song, resulting in demoting a potentially relevant and valuable song.

The below figure shows the same user journey as before, but in a different situation, where upbeat music may be more relevant. We still utilize their previous music listening, while recommending upbeat music that is close to their usual music listening. In effect, we are learning which previous actions are relevant in the current task of ranking music, and which actions are irrelevant.

A typical user will perform hundreds of like, dislike, and skip actions, and this sequence of input data, though information-rich, quickly becomes unwieldy. To add to this complexity, users perform different numbers of actions. While a typical user might have hundreds of actions, user behavior can vary between a small number of actions to a very large number of actions, and a good ranking system must be flexible in handling different input sizes.
In this post we discuss how we’ve applied transformers, which are well-suited to processing sequences of input data, to improve the recommendation system in YouTube Music. This recommendation system consists of three key stages: item retrieval, item ranking, and filtering. Prior user actions are usually added to the ranking models as an input feature. Our approach adapts the Transformer architecture from generative models for the task of understanding the sequential nature of user actions, and blends that with ranking models personalized for that user. Using transformers to incorporate different user actions based on the current user context helps steer music recommendations directly towards the user’s current need. For signed-in users, this approach allows us to incorporate a user’s history without having to explicitly identify what in a user’s history is valuable to the ranking task.
Retrieval, ranking, and filtering
In existing models, it was difficult to identify which user actions were relevant to the user’s current needs. To understand such models, we need to look at typical recommendation systems. These systems are usually set up as three distinct stages. First, retrieval systems retrieve thousands of relevant items (documents, songs, etc.) from a large corpus. Second, ranking systems evaluate the retrieved results, so that the items that are more relevant and important to the user’s needs are assigned a higher score. The key complexity of ranking comes from the value judgment between concepts such as relevance, importance, novelty, and assigning a numerical value to these fuzzy concepts. Finally, a filtering stage sorts the ranked list by scores, and reduces the sorted list to a short list that is shown to the user. When designing and deploying a ranking model, it is hard to manually select and apply relative weights to specific user actions out of the many hundreds or thousands that they may commonly take.
Transformers make sense of sequences
Transformers are well-suited to a class of problems where we need to make sense of a sequence of input data. While transformers have been used to improve ranking functions, previous approaches have not focused on user actions: Transformer models like RankFormer have used item candidates (as opposed to user-actions) as input, classical language transformers like BERT are used to rank language output, or BERT-like models are used in recommendations, as in Bert4Rec.
The Transformer architecture consists of self-attention layers to make sense of sequential input. Transformer models have shown incredible performance on translation or classification tasks, even with ambiguous input text. The self-attention layers capture the relationship between words of text in a sentence, which suggests that they might be able to resolve the relationship between user actions as well. The attention layers in transformers learn attention weights between the pieces of input (tokens), which are akin to word relationships in the input sentence.

Transformers in generative models.
This is how we utilize the Transformer architecture to encode user actions on YouTube Music. In the user journey involving uptempo music above, we saw how some actions were less important than others. For example, when the user is listening to music at the gym, the user may prefer high-energy upbeat music that they would normally skip, hence related actions (e.g., the skip action in this example) should get a lower attention weight. However, when a user is listening to music in other settings, user actions should get more attention. There should be a difference in attention weight applied to music context versus a user’s music history based upon the activity the user is performing. For example, when a user is at the gym they might listen to music that is more upbeat, but not too far from what they usually listen to. Or when they are driving, they might prefer to explore more new music.
Transformers for ranking in YouTube Music
Our architecture combines a Transformer with an existing ranking model to learn the combined ranking that best blends user actions with listening history (see diagram below). In this diagram, information flows from the bottom to the top: the inputs to the Transformer are shown at the bottom, and the produced ranking score is shown at the top. “Items” here are music tracks that we want to rank, with the goal to produce a ranking score for each music “item” given to it, with other signals (also called features) provided as input.
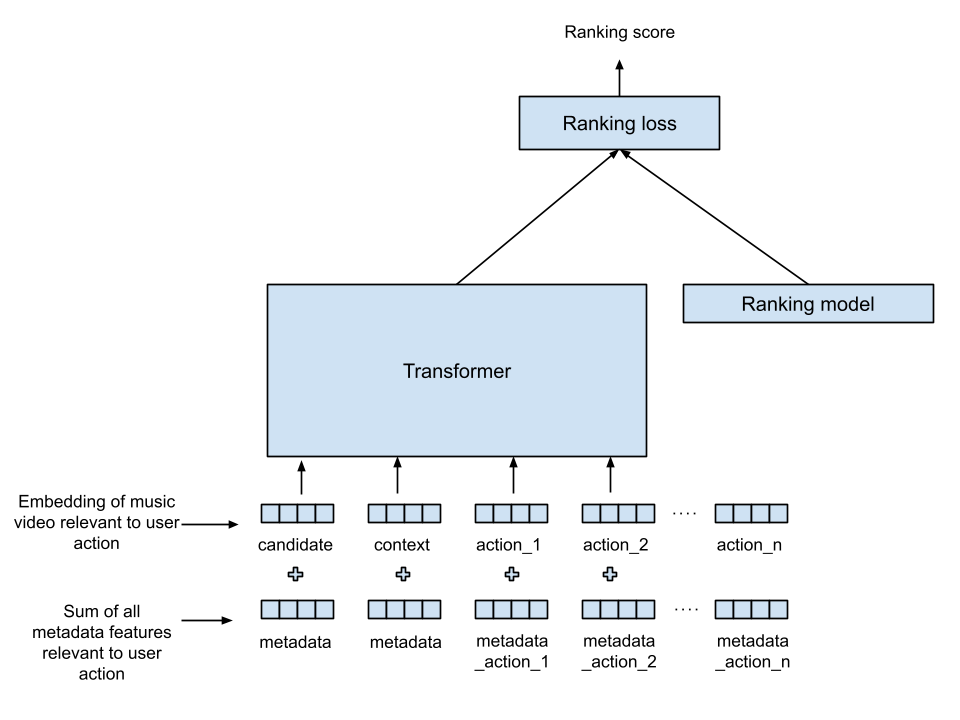
Transformers and Ranker in the joint music recommendation task.
Here are the signals describing the user action at each time step:
- Intention of the action: interrupt a music track, select a music track to listen to, autoplay.
- Salience of the action: percentage of the music track that was played, time since prior user-action.
- Other metadata: artist, language of the music.
- Music track: music track identifier corresponding to the user-action.
Music tracks corresponding to user actions are represented by a vector of numbers called the track embedding. This music-track embedding is used as an input in both the Transformer and the existing ranking model. User-action signals, like intention and metadata, are turned into vectors with the same length as the length of the track embedding. This operation, called a projection, allows us to combine the signals simply by adding the two vectors: user-action signals and the track embedding, producing input vectors (called tokens) for the Transformer. The tokens provided as inputs to the Transformer are used to score the retrieved music items. When considering the user’s history, we include the previous user actions and the music the user is currently listening to, as both capture valuable user context. The output vector from the Transformer is combined with the existing ranking model inputs, using a multi-layer neural network. The Transformer is co-trained with the ranking model, for multiple ranking objectives.
Offline analysis and live experiments demonstrate that using this Transformer significantly improves the performance of the ranking model, leading to a reduction in skip-rate and an increase in time users spend listening to music. Skipping less frequently indicates that on average, users like the recommendations more. Increased session length indicates that users are happier with the overall experience. These two metrics demonstrate the improvement in user satisfaction for YouTube Music.
Future work
We see two main opportunities to build on this work. The first would be to adapt the technique to other parts of the recommendation system such as retrieval models. There are also a variety of nonsequential features, which are used as inputs to the prior ranking model, that we are also exploring for incorporation. Currently, these are combined after the Transformer stage, and we predict that incorporating them within the Transformer would allow for improved self-attention between the sequential features, like user-actions, and non-sequential features such as artist popularity, user language, music popularity and more.
Acknowledgements
Thanks to colleagues Reza Mirghaderi, Li Yang, Chieh Lo, Jungkhun Byun, Gergo Varady, and Sally Goldman, for their collaboration on this effort.
Quick links
Other posts of interest
-

November 11, 2024
Generating zero-shot personalized portraits- Generative AI ·
- Machine Intelligence
-

November 7, 2024
Relationships are complicated! An analysis of relationships between datasets on the Web- Data Mining & Modeling ·
- Human-Computer Interaction and Visualization ·
- Natural Language Processing ·
- Open Source Models & Datasets
-

October 23, 2024
Scalable self-improvement for compiler optimization- Algorithms & Theory ·
- Machine Intelligence