TDengine OSS
Open-source time-series database with built-in stream processing, caching, and data subscription
Fast data ingestion through SQL or schemaless writing
Efficient SQL queries including nested queries and UDF
Windowed queries & extensions to SQL for time series data
Cluster support with cloud native scalability
Built-in caching eliminates the need to deploy Redis
Built-in stream processing eliminates the need to deploy Spark or Flink
Built-in data subscription eliminates the need to deploy Kafka
Client libraries for mainstream programming languages
Why Developers Choose TDengine
Over 700k Installations and 23k GitHub Stars
High Performance
TDengine is the only time series database to solve the high-cardinality issue, supporting billions of data collection points while outperforming other time series databases in ingestion, querying, and compression.
Cloud Native
TDengine provides the six elements — distributed design, scalability, elasticity, resiliency, observability, and automation — required of a true cloud native database and can run on public, private, or hybrid clouds.
Easy to Use
TDengine significantly reduces the effort to deploy and maintain a time series database. It provides simple interfaces and seamless integrations for third-party tools, giving users and developers easy access to data.
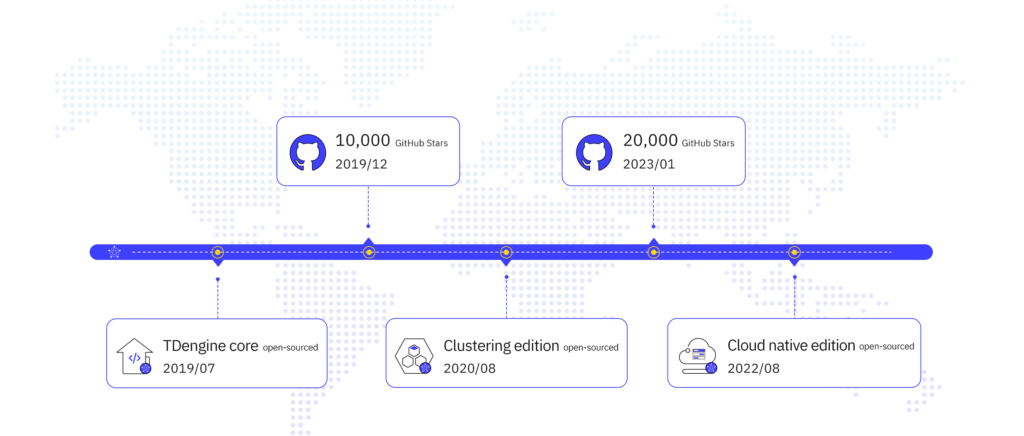
TDengine’s Open Source Journey
Join the Community
All community members are invited to submit issues and pull requests to the TDengine GitHub repository.
Submit IssueYou can join our Discord server and communicate directly with team members for assistance with your TDengine deployment.
Join DiscordLearn about the different features included in TDengine OSS, TDengine Enterprise, and TDengine Cloud
Compare Features

