 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDualCoTs: Dual Chain-of-Thoughts Prompting for Sentiment Lexicon Expansion of Idioms
Sep 26, 2024Idioms represent a ubiquitous vehicle for conveying sentiments in the realm of everyday discourse, rendering the nuanced analysis of idiom sentiment crucial for a comprehensive understanding of emotional expression within real-world texts. Nevertheless, the existing corpora dedicated to idiom sentiment analysis considerably limit research in text sentiment analysis. In this paper, we propose an innovative approach to automatically expand the sentiment lexicon for idioms, leveraging the capabilities of large language models through the application of Chain-of-Thought prompting. To demonstrate the effectiveness of this approach, we integrate multiple existing resources and construct an emotional idiom lexicon expansion dataset (called EmoIdiomE), which encompasses a comprehensive repository of Chinese and English idioms. Then we designed the Dual Chain-of-Thoughts (DualCoTs) method, which combines insights from linguistics and psycholinguistics, to demonstrate the effectiveness of using large models to automatically expand the sentiment lexicon for idioms. Experiments show that DualCoTs is effective in idioms sentiment lexicon expansion in both Chinese and English. For reproducibility, we will release the data and code upon acceptance.
Agents in Software Engineering: Survey, Landscape, and Vision
Sep 13, 2024In recent years, Large Language Models (LLMs) have achieved remarkable success and have been widely used in various downstream tasks, especially in the tasks of the software engineering (SE) field. We find that many studies combining LLMs with SE have employed the concept of agents either explicitly or implicitly. However, there is a lack of an in-depth survey to sort out the development context of existing works, analyze how existing works combine the LLM-based agent technologies to optimize various tasks, and clarify the framework of LLM-based agents in SE. In this paper, we conduct the first survey of the studies on combining LLM-based agents with SE and present a framework of LLM-based agents in SE which includes three key modules: perception, memory, and action. We also summarize the current challenges in combining the two fields and propose future opportunities in response to existing challenges. We maintain a GitHub repository of the related papers at: https://github.com/DeepSoftwareAnalytics/Awesome-Agent4SE.
LIME-M: Less Is More for Evaluation of MLLMs
Sep 10, 2024
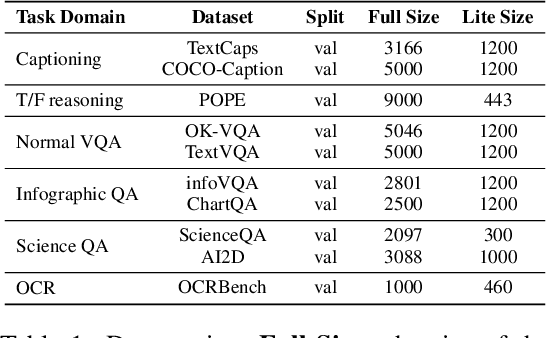
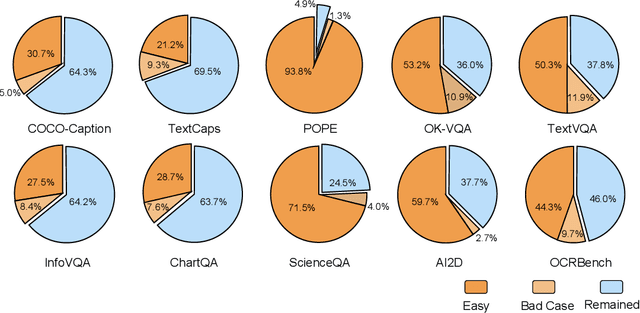
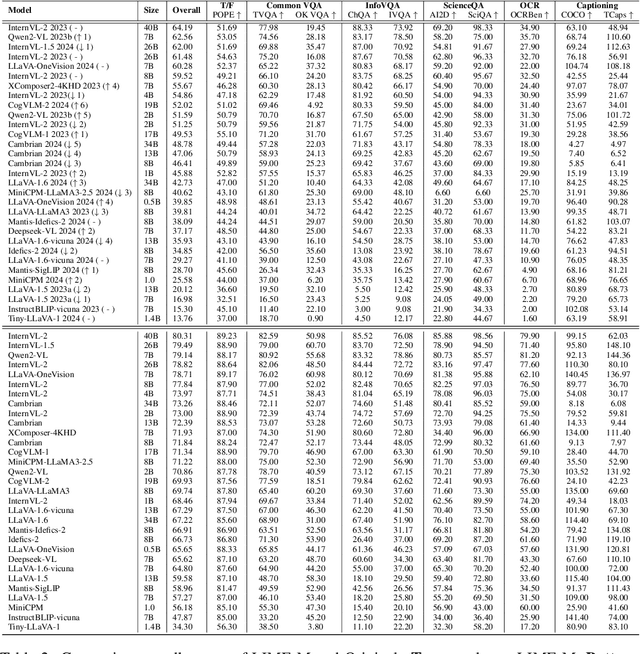
With the remarkable success achieved by Multimodal Large Language Models (MLLMs), numerous benchmarks have been designed to assess MLLMs' ability to guide their development in image perception tasks (e.g., image captioning and visual question answering). However, the existence of numerous benchmarks results in a substantial computational burden when evaluating model performance across all of them. Moreover, these benchmarks contain many overly simple problems or challenging samples, which do not effectively differentiate the capabilities among various MLLMs. To address these challenges, we propose a pipeline to process the existing benchmarks, which consists of two modules: (1) Semi-Automated Screening Process and (2) Eliminating Answer Leakage. The Semi-Automated Screening Process filters out samples that cannot distinguish the model's capabilities by synthesizing various MLLMs and manually evaluating them. The Eliminate Answer Leakage module filters samples whose answers can be inferred without images. Finally, we curate the LIME-M: Less Is More for Evaluation of Multimodal LLMs, a lightweight Multimodal benchmark that can more effectively evaluate the performance of different models. Our experiments demonstrate that: LIME-M can better distinguish the performance of different MLLMs with fewer samples (24% of the original) and reduced time (23% of the original); LIME-M eliminates answer leakage, focusing mainly on the information within images; The current automatic metric (i.e., CIDEr) is insufficient for evaluating MLLMs' capabilities in captioning. Moreover, removing the caption task score when calculating the overall score provides a more accurate reflection of model performance differences. All our codes and data are released at https://github.com/kangreen0210/LIME-M.
MMEvol: Empowering Multimodal Large Language Models with Evol-Instruct
Sep 09, 2024The development of Multimodal Large Language Models (MLLMs) has seen significant advancements. However, the quantity and quality of multimodal instruction data have emerged as significant bottlenecks in their progress. Manually creating multimodal instruction data is both time-consuming and inefficient, posing challenges in producing instructions of high complexity. Moreover, distilling instruction data from black-box commercial models (e.g., GPT-4o, GPT-4V) often results in simplistic instruction data, which constrains performance to that of these models. The challenge of curating diverse and complex instruction data remains substantial. We propose MMEvol, a novel multimodal instruction data evolution framework that combines fine-grained perception evolution, cognitive reasoning evolution, and interaction evolution. This iterative approach breaks through data quality bottlenecks to generate a complex and diverse image-text instruction dataset, thereby empowering MLLMs with enhanced capabilities. Beginning with an initial set of instructions, SEED-163K, we utilize MMEvol to systematically broadens the diversity of instruction types, integrates reasoning steps to enhance cognitive capabilities, and extracts detailed information from images to improve visual understanding and robustness. To comprehensively evaluate the effectiveness of our data, we train LLaVA-NeXT using the evolved data and conduct experiments across 13 vision-language tasks. Compared to the baseline trained with seed data, our approach achieves an average accuracy improvement of 3.1 points and reaches state-of-the-art (SOTA) performance on 9 of these tasks.
Training on the Benchmark Is Not All You Need
Sep 03, 2024The success of Large Language Models (LLMs) relies heavily on the huge amount of pre-training data learned in the pre-training phase. The opacity of the pre-training process and the training data causes the results of many benchmark tests to become unreliable. If any model has been trained on a benchmark test set, it can seriously hinder the health of the field. In order to automate and efficiently test the capabilities of large language models, numerous mainstream benchmarks adopt a multiple-choice format. As the swapping of the contents of multiple-choice options does not affect the meaning of the question itself, we propose a simple and effective data leakage detection method based on this property. Specifically, we shuffle the contents of the options in the data to generate the corresponding derived data sets, and then detect data leakage based on the model's log probability distribution over the derived data sets. If there is a maximum and outlier in the set of log probabilities, it indicates that the data is leaked. Our method is able to work under black-box conditions without access to model training data or weights, effectively identifying data leakage from benchmark test sets in model pre-training data, including both normal scenarios and complex scenarios where options may have been shuffled intentionally or unintentionally. Through experiments based on two LLMs and benchmark designs, we demonstrate the effectiveness of our method. In addition, we evaluate the degree of data leakage of 31 mainstream open-source LLMs on four benchmark datasets and give a ranking of the leaked LLMs for each benchmark, and we find that the Qwen family of LLMs has the highest degree of data leakage.
Lower Layer Matters: Alleviating Hallucination via Multi-Layer Fusion Contrastive Decoding with Truthfulness Refocused
Aug 16, 2024

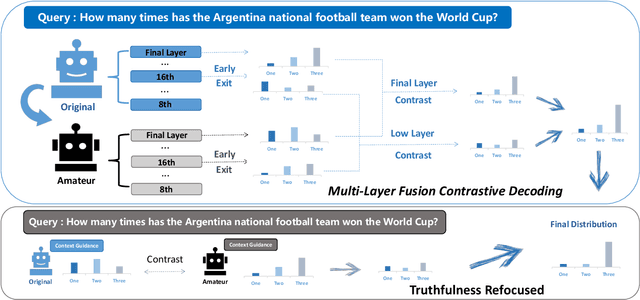
Large Language Models (LLMs) have demonstrated exceptional performance across various natural language processing tasks, yet they occasionally tend to yield content that factually inaccurate or discordant with the expected output, a phenomenon empirically referred to as "hallucination". To tackle this issue, recent works have investigated contrastive decoding between the original model and an amateur model with induced hallucination, which has shown promising results. Nonetheless, this method may undermine the output distribution of the original LLM caused by its coarse contrast and simplistic subtraction operation, potentially leading to errors in certain cases. In this paper, we introduce a novel contrastive decoding framework termed LOL (LOwer Layer Matters). Our approach involves concatenating the contrastive decoding of both the final and lower layers between the original model and the amateur model, thereby achieving multi-layer fusion to aid in the mitigation of hallucination. Additionally, we incorporate a truthfulness refocused module that leverages contextual guidance to enhance factual encoding, further capturing truthfulness during contrastive decoding. Extensive experiments conducted on two publicly available datasets illustrate that our proposed LOL framework can substantially alleviate hallucination while surpassing existing baselines in most cases. Compared with the best baseline, we improve by average 4.5 points on all metrics of TruthfulQA. The source code is coming soon.
AgentCourt: Simulating Court with Adversarial Evolvable Lawyer Agents
Aug 15, 2024
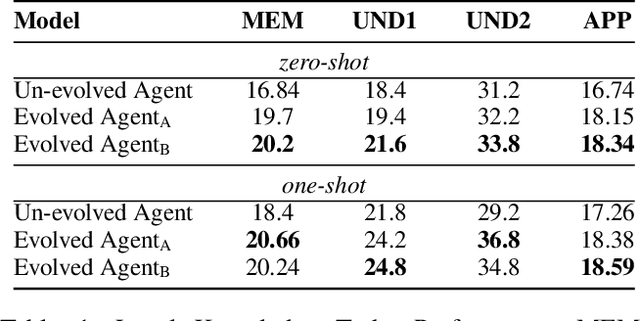


In this paper, we present a simulation system called AgentCourt that simulates the entire courtroom process. The judge, plaintiff's lawyer, defense lawyer, and other participants are autonomous agents driven by large language models (LLMs). Our core goal is to enable lawyer agents to learn how to argue a case, as well as improving their overall legal skills, through courtroom process simulation. To achieve this goal, we propose an adversarial evolutionary approach for the lawyer-agent. Since AgentCourt can simulate the occurrence and development of court hearings based on a knowledge base and LLM, the lawyer agents can continuously learn and accumulate experience from real court cases. The simulation experiments show that after two lawyer-agents have engaged in a thousand adversarial legal cases in AgentCourt (which can take a decade for real-world lawyers), compared to their pre-evolutionary state, the evolved lawyer agents exhibit consistent improvement in their ability to handle legal tasks. To enhance the credibility of our experimental results, we enlisted a panel of professional lawyers to evaluate our simulations. The evaluation indicates that the evolved lawyer agents exhibit notable advancements in responsiveness, as well as expertise and logical rigor. This work paves the way for advancing LLM-driven agent technology in legal scenarios. Code is available at https://github.com/relic-yuexi/AgentCourt.
Synthesizing Text-to-SQL Data from Weak and Strong LLMs
Aug 06, 2024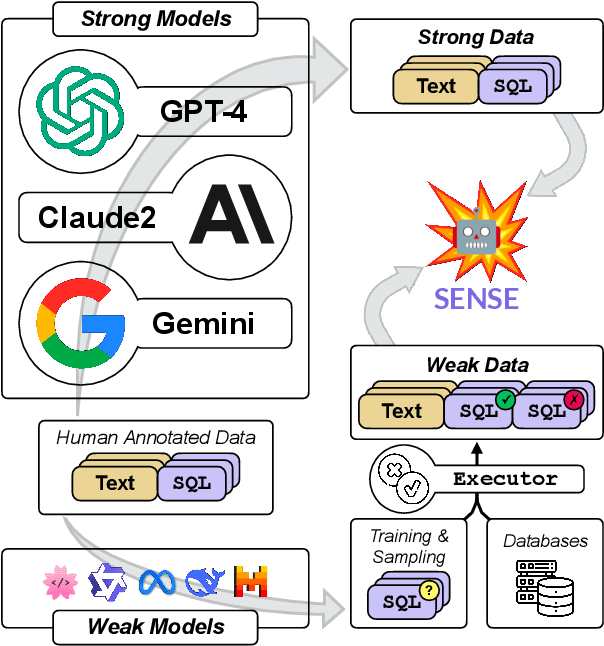


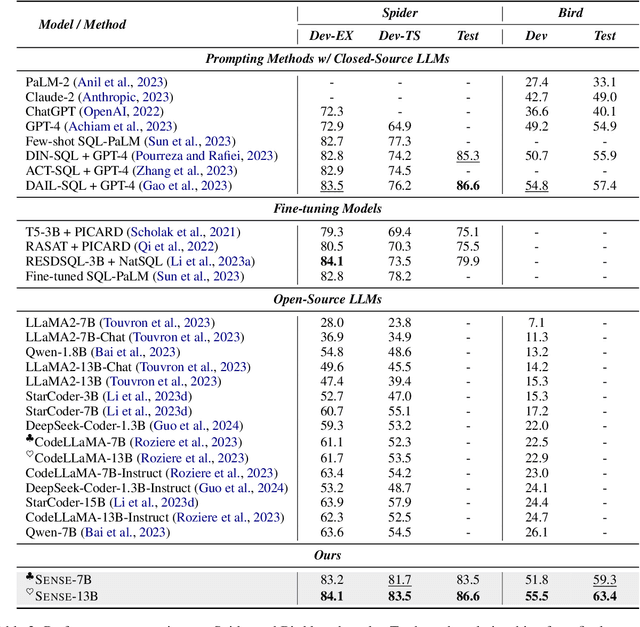
The capability gap between open-source and closed-source large language models (LLMs) remains a challenge in text-to-SQL tasks. In this paper, we introduce a synthetic data approach that combines data produced by larger, more powerful models (strong models) with error information data generated by smaller, not well-aligned models (weak models). The method not only enhances the domain generalization of text-to-SQL models but also explores the potential of error data supervision through preference learning. Furthermore, we employ the synthetic data approach for instruction tuning on open-source LLMs, resulting SENSE, a specialized text-to-SQL model. The effectiveness of SENSE is demonstrated through state-of-the-art results on the SPIDER and BIRD benchmarks, bridging the performance gap between open-source models and methods prompted by closed-source models.
DeliLaw: A Chinese Legal Counselling System Based on a Large Language Model
Aug 01, 2024Traditional legal retrieval systems designed to retrieve legal documents, statutes, precedents, and other legal information are unable to give satisfactory answers due to lack of semantic understanding of specific questions. Large Language Models (LLMs) have achieved excellent results in a variety of natural language processing tasks, which inspired us that we train a LLM in the legal domain to help legal retrieval. However, in the Chinese legal domain, due to the complexity of legal questions and the rigour of legal articles, there is no legal large model with satisfactory practical application yet. In this paper, we present DeliLaw, a Chinese legal counselling system based on a large language model. DeliLaw integrates a legal retrieval module and a case retrieval module to overcome the model hallucination. Users can consult professional legal questions, search for legal articles and relevant judgement cases, etc. on the DeliLaw system in a dialogue mode. In addition, DeliLaw supports the use of English for counseling. we provide the address of the system: https://data.delilegal.com/lawQuestion.
CollectiveSFT: Scaling Large Language Models for Chinese Medical Benchmark with Collective Instructions in Healthcare
Jul 29, 2024

The rapid progress in Large Language Models (LLMs) has prompted the creation of numerous benchmarks to evaluate their capabilities.This study focuses on the Comprehensive Medical Benchmark in Chinese (CMB), showcasing how dataset diversity and distribution in supervised fine-tuning (SFT) may enhance LLM performance.Remarkably, We successfully trained a smaller base model to achieve scores comparable to larger models, indicating that a diverse and well-distributed dataset can optimize performance regardless of model size.This study suggests that even smaller models may reach high performance levels with carefully curated and varied datasets.By integrating a wide range of instructional content, our approach addresses potential issues such as data quality inconsistencies. Our results imply that a broader spectrum of training data may enhance a model's ability to generalize and perform effectively across different medical scenarios, highlighting the importance of dataset quality and diversity in fine-tuning processes.