 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFull-Stage Pseudo Label Quality Enhancement for Weakly-supervised Temporal Action Localization
Jul 12, 2024Weakly-supervised Temporal Action Localization (WSTAL) aims to localize actions in untrimmed videos using only video-level supervision. Latest WSTAL methods introduce pseudo label learning framework to bridge the gap between classification-based training and inferencing targets at localization, and achieve cutting-edge results. In these frameworks, a classification-based model is used to generate pseudo labels for a regression-based student model to learn from. However, the quality of pseudo labels in the framework, which is a key factor to the final result, is not carefully studied. In this paper, we propose a set of simple yet efficient pseudo label quality enhancement mechanisms to build our FuSTAL framework. FuSTAL enhances pseudo label quality at three stages: cross-video contrastive learning at proposal Generation-Stage, prior-based filtering at proposal Selection-Stage and EMA-based distillation at Training-Stage. These designs enhance pseudo label quality at different stages in the framework, and help produce more informative, less false and smoother action proposals. With the help of these comprehensive designs at all stages, FuSTAL achieves an average mAP of 50.8% on THUMOS'14, outperforming the previous best method by 1.2%, and becomes the first method to reach the milestone of 50%.
ExCP: Extreme LLM Checkpoint Compression via Weight-Momentum Joint Shrinking
Jun 17, 2024Large language models (LLM) have recently attracted significant attention in the field of artificial intelligence. However, the training process of these models poses significant challenges in terms of computational and storage capacities, thus compressing checkpoints has become an urgent problem. In this paper, we propose a novel Extreme Checkpoint Compression (ExCP) framework, which significantly reduces the required storage of training checkpoints while achieving nearly lossless performance. We first calculate the residuals of adjacent checkpoints to obtain the essential but sparse information for higher compression ratio. To further excavate the redundancy parameters in checkpoints, we then propose a weight-momentum joint shrinking method to utilize another important information during the model optimization, i.e., momentum. In particular, we exploit the information of both model and optimizer to discard as many parameters as possible while preserving critical information to ensure optimal performance. Furthermore, we utilize non-uniform quantization to further compress the storage of checkpoints. We extensively evaluate our proposed ExCP framework on several models ranging from 410M to 7B parameters and demonstrate significant storage reduction while maintaining strong performance. For instance, we achieve approximately $70\times$ compression for the Pythia-410M model, with the final performance being as accurate as the original model on various downstream tasks. Codes will be available at https://github.com/Gaffey/ExCP.
GeminiFusion: Efficient Pixel-wise Multimodal Fusion for Vision Transformer
Jun 04, 2024
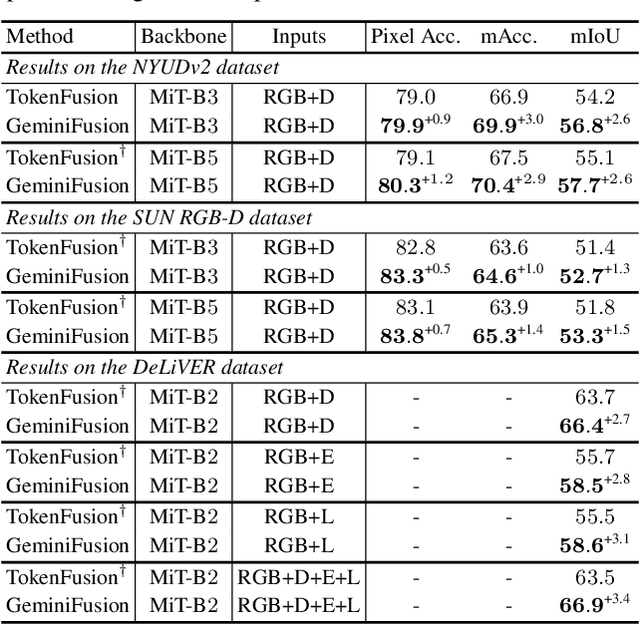
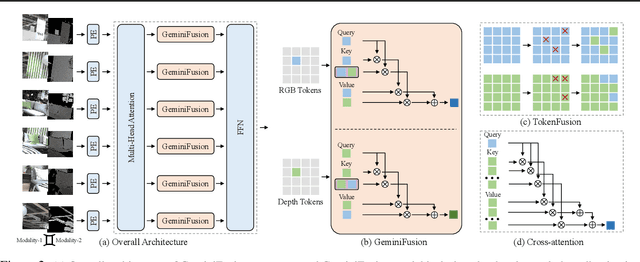

Cross-modal transformers have demonstrated superiority in various vision tasks by effectively integrating different modalities. This paper first critiques prior token exchange methods which replace less informative tokens with inter-modal features, and demonstrate exchange based methods underperform cross-attention mechanisms, while the computational demand of the latter inevitably restricts its use with longer sequences. To surmount the computational challenges, we propose GeminiFusion, a pixel-wise fusion approach that capitalizes on aligned cross-modal representations. GeminiFusion elegantly combines intra-modal and inter-modal attentions, dynamically integrating complementary information across modalities. We employ a layer-adaptive noise to adaptively control their interplay on a per-layer basis, thereby achieving a harmonized fusion process. Notably, GeminiFusion maintains linear complexity with respect to the number of input tokens, ensuring this multimodal framework operates with efficiency comparable to unimodal networks. Comprehensive evaluations across multimodal image-to-image translation, 3D object detection and arbitrary-modal semantic segmentation tasks, including RGB, depth, LiDAR, event data, etc. demonstrate the superior performance of our GeminiFusion against leading-edge techniques. The PyTorch code is available at https://github.com/JiaDingCN/GeminiFusion
SLAB: Efficient Transformers with Simplified Linear Attention and Progressive Re-parameterized Batch Normalization
May 19, 2024Transformers have become foundational architectures for both natural language and computer vision tasks. However, the high computational cost makes it quite challenging to deploy on resource-constraint devices. This paper investigates the computational bottleneck modules of efficient transformer, i.e., normalization layers and attention modules. LayerNorm is commonly used in transformer architectures but is not computational friendly due to statistic calculation during inference. However, replacing LayerNorm with more efficient BatchNorm in transformer often leads to inferior performance and collapse in training. To address this problem, we propose a novel method named PRepBN to progressively replace LayerNorm with re-parameterized BatchNorm in training. Moreover, we propose a simplified linear attention (SLA) module that is simple yet effective to achieve strong performance. Extensive experiments on image classification as well as object detection demonstrate the effectiveness of our proposed method. For example, our SLAB-Swin obtains $83.6\%$ top-1 accuracy on ImageNet-1K with $16.2$ms latency, which is $2.4$ms less than that of Flatten-Swin with $0.1\%$ higher accuracy. We also evaluated our method for language modeling task and obtain comparable performance and lower latency.Codes are publicly available at https://github.com/xinghaochen/SLAB and https://github.com/mindspore-lab/models/tree/master/research/huawei-noah/SLAB.
No Time to Waste: Squeeze Time into Channel for Mobile Video Understanding
May 14, 2024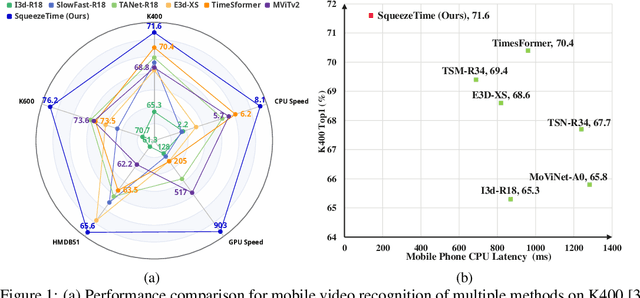
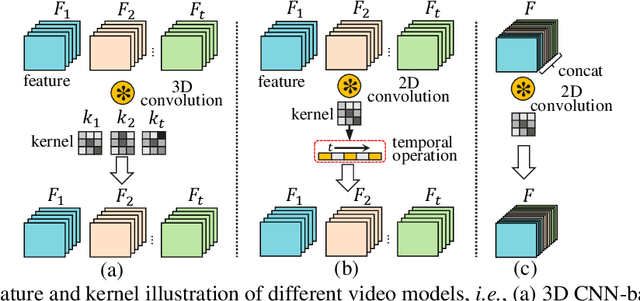
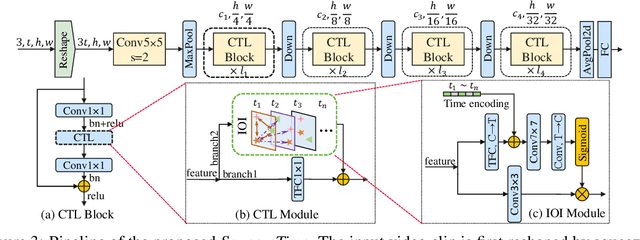

Current architectures for video understanding mainly build upon 3D convolutional blocks or 2D convolutions with additional operations for temporal modeling. However, these methods all regard the temporal axis as a separate dimension of the video sequence, which requires large computation and memory budgets and thus limits their usage on mobile devices. In this paper, we propose to squeeze the time axis of a video sequence into the channel dimension and present a lightweight video recognition network, term as \textit{SqueezeTime}, for mobile video understanding. To enhance the temporal modeling capability of the proposed network, we design a Channel-Time Learning (CTL) Block to capture temporal dynamics of the sequence. This module has two complementary branches, in which one branch is for temporal importance learning and another branch with temporal position restoring capability is to enhance inter-temporal object modeling ability. The proposed SqueezeTime is much lightweight and fast with high accuracies for mobile video understanding. Extensive experiments on various video recognition and action detection benchmarks, i.e., Kinetics400, Kinetics600, HMDB51, AVA2.1 and THUMOS14, demonstrate the superiority of our model. For example, our SqueezeTime achieves $+1.2\%$ accuracy and $+80\%$ GPU throughput gain on Kinetics400 than prior methods. Codes are publicly available at https://github.com/xinghaochen/SqueezeTime and https://github.com/mindspore-lab/models/tree/master/research/huawei-noah/SqueezeTime.
Semantic and Spatial Adaptive Pixel-level Classifier for Semantic Segmentation
May 10, 2024Vanilla pixel-level classifiers for semantic segmentation are based on a certain paradigm, involving the inner product of fixed prototypes obtained from the training set and pixel features in the test image. This approach, however, encounters significant limitations, i.e., feature deviation in the semantic domain and information loss in the spatial domain. The former struggles with large intra-class variance among pixel features from different images, while the latter fails to utilize the structured information of semantic objects effectively. This leads to blurred mask boundaries as well as a deficiency of fine-grained recognition capability. In this paper, we propose a novel Semantic and Spatial Adaptive (SSA) classifier to address the above challenges. Specifically, we employ the coarse masks obtained from the fixed prototypes as a guide to adjust the fixed prototype towards the center of the semantic and spatial domains in the test image. The adapted prototypes in semantic and spatial domains are then simultaneously considered to accomplish classification decisions. In addition, we propose an online multi-domain distillation learning strategy to improve the adaption process. Experimental results on three publicly available benchmarks show that the proposed SSA significantly improves the segmentation performance of the baseline models with only a minimal increase in computational cost. Code is available at https://github.com/xwmaxwma/SSA.
Context-Guided Spatial Feature Reconstruction for Efficient Semantic Segmentation
May 10, 2024
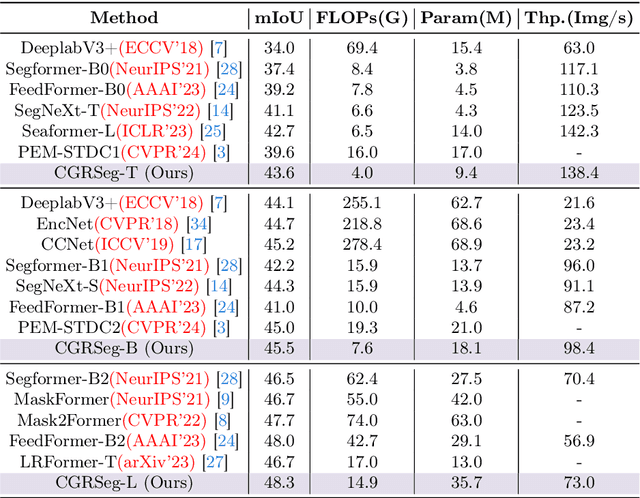


Semantic segmentation is an important task for many applications but it is still quite challenging to achieve advanced performance with limited computational costs. In this paper, we present CGRSeg, an efficient yet competitive segmentation framework based on context-guided spatial feature reconstruction. A Rectangular Self-Calibration Module is carefully designed for spatial feature reconstruction and pyramid context extraction. It captures the global context in both horizontal and vertical directions and gets the axial global context to explicitly model rectangular key areas. A shape self-calibration function is designed to make the key areas more close to the foreground object. Besides, a lightweight Dynamic Prototype Guided head is proposed to improve the classification of foreground objects by explicit class embedding. Our CGRSeg is extensively evaluated on ADE20K, COCO-Stuff, and Pascal Context benchmarks, and achieves state-of-the-art semantic performance. Specifically, it achieves $43.6\%$ mIoU on ADE20K with only $4.0$ GFLOPs, which is $0.9\%$ and $2.5\%$ mIoU better than SeaFormer and SegNeXt but with about $38.0\%$ fewer GFLOPs. Code is available at https://github.com/nizhenliang/CGRSeg.
TinySAM: Pushing the Envelope for Efficient Segment Anything Model
Dec 21, 2023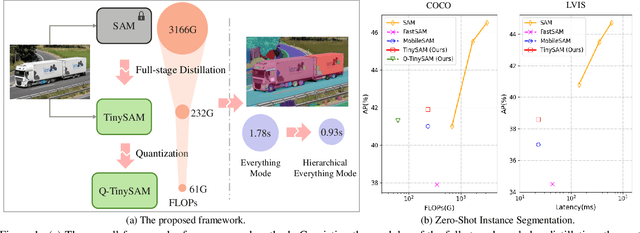

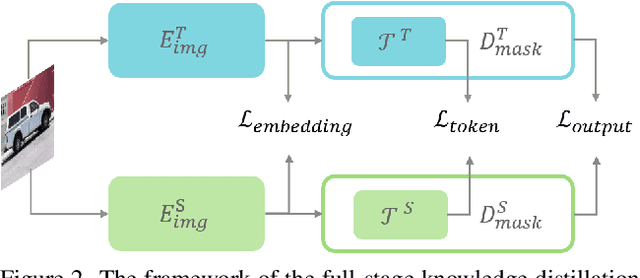
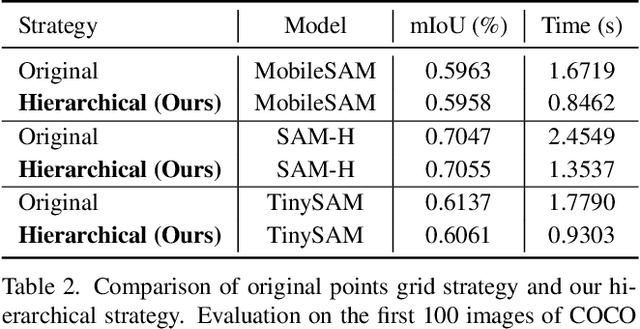
Recently segment anything model (SAM) has shown powerful segmentation capability and has drawn great attention in computer vision fields. Massive following works have developed various applications based on the pretrained SAM and achieved impressive performance on downstream vision tasks. However, SAM consists of heavy architectures and requires massive computational capacity, which hinders the further application of SAM on computation constrained edge devices. To this end, in this paper we propose a framework to obtain a tiny segment anything model (TinySAM) while maintaining the strong zero-shot performance. We first propose a full-stage knowledge distillation method with online hard prompt sampling strategy to distill a lightweight student model. We also adapt the post-training quantization to the promptable segmentation task and further reduce the computational cost. Moreover, a hierarchical segmenting everything strategy is proposed to accelerate the everything inference by $2\times$ with almost no performance degradation. With all these proposed methods, our TinySAM leads to orders of magnitude computational reduction and pushes the envelope for efficient segment anything task. Extensive experiments on various zero-shot transfer tasks demonstrate the significantly advantageous performance of our TinySAM against counterpart methods. Pre-trained models and codes will be available at https://github.com/xinghaochen/TinySAM and https://gitee.com/mindspore/models/tree/master/research/cv/TinySAM.
DECO: Query-Based End-to-End Object Detection with ConvNets
Dec 21, 2023Detection Transformer (DETR) and its variants have shown great potential for accurate object detection in recent years. The mechanism of object query enables DETR family to directly obtain a fixed number of object predictions and streamlines the detection pipeline. Meanwhile, recent studies also reveal that with proper architecture design, convolution networks (ConvNets) also achieve competitive performance with transformers, \eg, ConvNeXt. To this end, in this paper we explore whether we could build a query-based end-to-end object detection framework with ConvNets instead of sophisticated transformer architecture. The proposed framework, \ie, Detection ConvNet (DECO), is composed of a backbone and convolutional encoder-decoder architecture. We carefully design the DECO encoder and propose a novel mechanism for our DECO decoder to perform interaction between object queries and image features via convolutional layers. We compare the proposed DECO against prior detectors on the challenging COCO benchmark. Despite its simplicity, our DECO achieves competitive performance in terms of detection accuracy and running speed. Specifically, with the ResNet-50 and ConvNeXt-Tiny backbone, DECO obtains $38.6\%$ and $40.8\%$ AP on COCO \textit{val} set with $35$ and $28$ FPS respectively and outperforms the DETR model. Incorporated with advanced multi-scale feature module, our DECO+ achieves $47.8\%$ AP with $34$ FPS. We hope the proposed DECO brings another perspective for designing object detection framework.
PPT: Token Pruning and Pooling for Efficient Vision Transformers
Oct 03, 2023
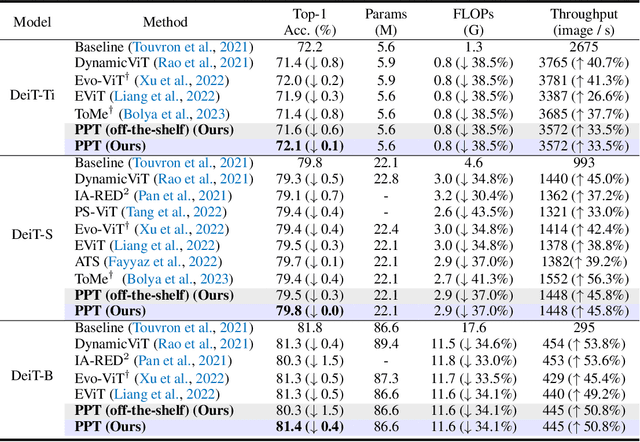

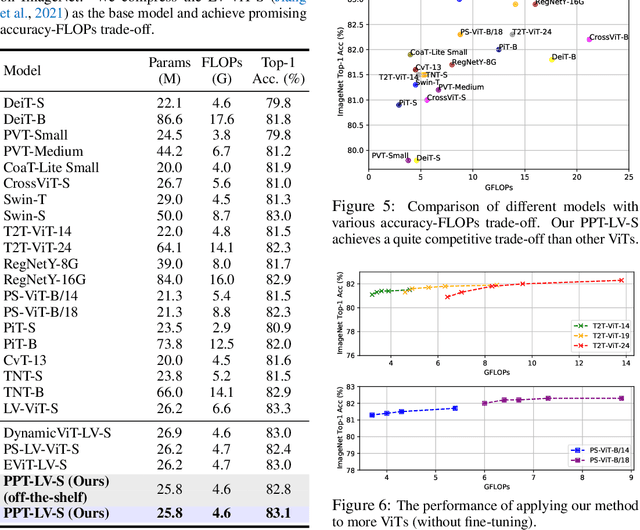
Vision Transformers (ViTs) have emerged as powerful models in the field of computer vision, delivering superior performance across various vision tasks. However, the high computational complexity poses a significant barrier to their practical applications in real-world scenarios. Motivated by the fact that not all tokens contribute equally to the final predictions and fewer tokens bring less computational cost, reducing redundant tokens has become a prevailing paradigm for accelerating vision transformers. However, we argue that it is not optimal to either only reduce inattentive redundancy by token pruning, or only reduce duplicative redundancy by token merging. To this end, in this paper we propose a novel acceleration framework, namely token Pruning & Pooling Transformers (PPT), to adaptively tackle these two types of redundancy in different layers. By heuristically integrating both token pruning and token pooling techniques in ViTs without additional trainable parameters, PPT effectively reduces the model complexity while maintaining its predictive accuracy. For example, PPT reduces over 37% FLOPs and improves the throughput by over 45% for DeiT-S without any accuracy drop on the ImageNet dataset.