Dimension Independent Data Sets Approximation and Applications to Classification
Abstract.
We revisit the classical kernel method of approximation/interpolation theory in a very specific context motivated by the desire to obtain a robust procedure to approximate discrete data sets by (super)level sets of functions that are merely continuous at the data set arguments but are otherwise smooth. Special functions, called data signals, are defined for any given data set and are used to succesfully solve supervised classification problems in a robust way that depends continuously on the data set. The efficacy of the method is illustrated with a series of low dimensional examples and by its application to the standard benchmark high dimensional problem of MNIST digit classification.
Key words and phrases:
Kernel based interpolation, supervised classification, data analysis1. Introduction
The problem of finding a function that explains a given set of data is a fundamental problem in mathematics and statistics. If the data are assumed to be the discrete manifestation of a function defined on a continuous (as opposed to discrete) domain of definition, the problem can be viewed as an approximation problem where the data can be leveraged to help identify a sensible approximation to the function. Often one resorts the prior knowledge about the target function to reduce the set of candidates from which to choose a good approximation, if not the best approximation. Within this framework, an extensive mathematical knowledge has been obtained over the past several decades along with a variety of powerful tools (see [5], in particular, for the philosophical approach taken here). In the current world, where data about almost anything you can imagine or wish for is available, one of the most interesting and often challening problems consists in extracting information, knowledge, and structure from high dimensional data. A variety of commonly used approaches belong to a category referred to as Machine Learning. Neural networks in all forms and shapes are particularly widespread due to their success in dealing with a series of challenging problems. Another class is that of Support-Vector Machines (SVM) [4], which were very popular before being somewhat superseded by improved neural networks . While they often use linear classification via hyperlanes, the so-called kernel trick [1, 2] makes it possible for them to capture nonlinear decision boundaries albeit at the cost of working in a higher dimensional space to which the data is mapped but that admits an efficient computation of scalar products (via a suitable kernel). A connection between SVMs and neural networks was discovered in [3] and has since been investigated by many more authors. The method proposed here is philosophically in the category of SVMs but distinguishes itself by directly working with the data at hand without embedding into a higher dimensional feature space. We first review a classical method of inexact interpolation that yields a continuous function approximating a given data set. We do so by taking a PDE perspective that reveals important features that are exploited in order to obtain the announced stable method of classification even when the distribution of available data is not uniform in space and, possibly, noisy. In high dimension, even large data sets are often sparse due to the so-called curse of dimensionality. Moreover, the data is often supported on lower dimensional manifolds, where even dense data make up a thin slice of the ambient space. In the latter case, it is demonstrated in this paper that, while the data may not be sufficient for the reliable identification of a well-defined global approximant, it can still be used fruitfully (in a global or local fashion) for data analysis purposes. This is mainly due to the fact that the proposed method is capable of connecting the dots (data points) into a manifold by capturing geometric features of the data.
It is widely understood and accepted that a function interpolating discrete data should be at least continuous so as to provide a certain stability of prediction and resilience in the face of noise. In learning problems this is sometimes expressed as local constancy, even if that does not require continuity. Unless the data is known to stem from a very smooth underlying function, but, typically, even in that case, it should also not be exceedingly smooth, as this would lead to some blurring and reduce its ability to capture sharp transitions. It would, moreover, be advantageous for the interpolating function to depend at least continuously on the data set it is constructed from. This would make it robust with respect to data uncertainty and thus defensible, for example, against what in the learning community would be referred to as adversarial attacks. These in fact use the very sensititve dependence of the model parameters on the training set.
The starting point is a set of data consisting of point/value pairs
where , and , , for . In order to enforce minimal regularity on the interpolant function
we take it from the space
Thanks to the general Sobolev inequality it holds that
| (1.1) |
where the containing space is that of bounded and uniformly Hölder continuous functions of exponent . In order to obtain stability we may sacrifice some interpolation accuracy by not necessarily requiring the exact validity of
| (1.2) |
Then, for approximate interpolation, is determined by minimization of the energy functional given by
| (1.3) | ||||
| (1.4) |
for and where the normalizing constant will be explicitly given in the next section. For exact interpolation is determined by minimization of with constraints (1.2) that shall be summarized as . Formally, it is set
| (1.5) |
While in many practical problems the dimension can be very large and the constant astronomical, this approach remains viable since the minimizers can be identified by solving a well-posed linear system of equations for any . The rest of the paper is organized as follows. In the next section we provide a detailed description of the method and obtain some of its basic mathematical properties. In the following section, we discuss a variety of numerical experiments that showcase the viability and efficacy of the method.
2. The Method
In order to derive a concrete method it needs to be shown that minimizers of can be computed efficiently. We first observe that the functional has a unique minimizer no matter what the given data set is.
Theorem 2.1.
The functional has a unique minimizer for any given data set .
Proof.
Take first. Thanks to the embedding (1.1) the functional is continuous. It is clearly also strictly convex as a quadratic functional since the first term is the square of a norm. Strongly lower semi-continuous convex functionals on a Hilbert space are known to be weakly lower-semicontinuous and so is therefore . It is also coercive since closed bounded sets in are relatively weakly compact by the Banach-Alaoglu Theorem. A weakly lower-semicontinuous and coercive functional possesses a minimum, which, by strict convexity, is necessarily unique. The case uses essentially the same argument where the full function space is replaced by the convex closed subset of functions satisfying . ∎
Now that a unique continuous interpolant has been obtained for each given data set , it needs to be determined in a usable form. The next step consists in deriving the Euler-Lagrange equation for .
Theorem 2.2.
The minimizer for satisfies the equation (system)
| (2.1) |
in the weak sense, i.e. the equation holds in the space or, equivalently it holds that
| (2.2) |
for all . Here denotes the Dirac distribution supported at the point . If it holds that
| (2.3) |
in the weak sense for some for .
Proof.
Notice that, thanks to (1.1), it holds that for each . Taking variations in direction of any function for , where is the th basis element of , with arbitrary yields the equations
for , and where . The identities amount to the validity of the system (2.2). The equivalence of the latter with (2.1) follows from
and the fact that the (pseudo)differential operator is self-adjoint along with the validity of
where the latter duality pairing is between the space and its dual . In the case when , one takes variations in direction of test functions with to obtain that
in the sense of distributions. This means that
It is know that compactly supported distributions are of finite order and thus it must hold that is a finite linear combinations of , , and derivatives of them. Notice, however, that for and so no derivatives can be present in the linear combination. This yields the claim. ∎
Lemma 2.3.
Let be the minimizer of for the data set . Then , regardless of the regularization parameter .
Proof.
This regularity will readily follow from the reprentation of the solution discussed next. ∎
The minimization of or a variety of similar functionals has long been recognized to provide an answer to the so-called universal approximation property in the context of learning. It indeed can be shown that
if the values are those of a function belonging to a variety of (suitably chosen) functions spaces, such as (compactly supported continuous functions) or for . The convergence takes place in the space’s natural topology as becomes a finer and finer, not necessarily regular, discrete grid that fills the whole domain. The curse of dimensionality, however, limits the applicabilty of this approximation procedure as the size of any finite “filling” grid is exponential in the ambient dimension.
A reason the above approach or, more in general, kernel based approximation or interpolation has found widespread use, is its ability to bridge the gap between finite and infinite dimensional spaces. This property amounts in the case at hand in the possibility of computing the continuous variable solution by solving finite dimensional systems.
Theorem 2.4.
The minimizer , , is completely determined by its values , on the set of arguments . The latter can be determined by solving the well-posed linear system
| (2.4) |
where the matrix is given by
It then holds that
| (2.5) |
for any . For , it holds that
Proof.
The Fourier transform of the Laplace kernel is known. Indeed
| (2.6) |
where . For the purposes of this paper the parameter is set to be 1. The right-hand side of the above identity is the symbol of the pseudo-differential operator . Now, equation (2.1) is equivalent to
where the second equality sign follows from (2.6) and well-known properties of the Fourier transform. It only remains to evaluate this identity on the arguments to obtain the finite linear system. When , representation (2.3) entails that
and therefore that
as claimed. ∎
Proposition 2.5.
The matrix is invertible and it holds that
Proof.
The fact that is invertible is a consequence of the fact that is a positive kernel as follows from its Fourier transform and the well-known characterization of positivity. Continuity of the inversion function inv
then shows that
∎
Remark 2.6.
The proof of Lemma 2.3 is now obvious since the explicit representation of reveals that singularities are only found on the set .
Remark 2.7.
The convergence as implies convergence to in the topology of and hence, uniform convergence as well, thanks the embedding (1.1).
Remark 2.8.
Since the continuous minimization problem (1.5) has a unique solution, the linear system (2.4) is assured to be solvable and, in fact, well conditioned. It also follows that its solution , as well as its extension to , depend continuously on the data since the forcing term in (2.1) depends continuously on . The latter follows from the linear dependence on and the fact that Dirac distributions depend continuously on the location of their support in the topology of , again a known consequence of (1.1).
Remark 2.9.
Depending on the data set , the values will be close or not so close to the prescribed values . Thus, if is considered an interpolant of the data, it will not be exact, but only approximately capture the data. In many applications, some of which are considered in next section, this is a small price to be paid for the gain in robustness that the approach guarantees.
Remark 2.10.
Using directly that for some , it is possible to derive a system of equations for using that . Indeed it must hold
which yields the system
This shows that and, in particular, reiterates the point about the convergence as . In practice, it is more convenient to work with this system in order to compute .
While the parameter plays an important role, it will be dropped from the notation from now on. The understanding is that its value can be inferred from the context and that, whatever its value is, it is kept fixed. In this paper we are particularly focussed on the case and on the trivial value set , where for .
Definition 2.11.
If , we say that is the (continuous) signal generated by the data . We sometimes denote it by or .
The signal is the inexact interpolation of the characteristic function of the data set111We observe, in particular, that, if the data set discretizes a set of measure 0, then then its characteristic function is the trivial function and of not much use.. It can be strong, if , . This is the case, as was observed above, when is a fine and locally filling discretization of the ambient space, such as when approximating a set of positive measure by a set of discrete points. More often, however, the signal will be weak in the sense that is significantly less than 1 for . In this paper we contend that the usefulness of the signal does not only stem from its approximation or interpolation properties, but also (and perhaps mainly) from the fact that most of its level sets are very smooth due to Proposition 2.3 and, in fact, deliver smooth manifold approximations of that can effectively be employed as stable decision boundaries in supervised classification problems. Superlevel sets of the signal are reliable approximations with positive measure of any discrete data set that prove robust against noise. They, in a sense, connect the dots and capture the shape of the data. Thus the main philosophical difference between the traditional view point, that considers the data as the manifestation of a function that needs to be reconstructed, and the view point taken in this paper is that here the data set itself is approximated by the mostly smooth (super)level sets of a function that may not even fit the data well at all. We are indeed more interested in the level surfaces generated by the data’s signal than we are in its values. It will be shown that data signals, whether they are strong or weak, can be succesfully exploited in this sense. The practical experiments run in the next section will make use the following proposition.
Proposition 2.12.
Let (the notation means that the union is disjoint) be a given data set consisting of subsets (or classes). For
it holds that
Proof.
The signal and the signals relative to , are solutions of the linear equations
where and where
The claim therefore follows from the fact that
∎
Remark 2.13.
Notice that signals do not, however, behave additively, in the sense that
in general, even when
If one is given a labeled data set , where is the number of labels and , are the subsets consisting of the data corresponding to label , i.e. for , then one obtains a classification algorithm by computing the relative signals for and assigning any unlabeled datum to the class that exhibits the strongest relative signal, that is,
| (2.7) |
Remark 2.14.
An important aspect of the proposed approach (and of kernel based methods as well) is that the fundamental solution
| (2.8) |
of the (pseudo)differential operator used to obtain the finite linear system is essentially dimension independent. It depends on it only through the Euclidean distance function, which is a minimal ingredient that can hardly be avoided. It would of course be extremly difficult to work directly with the (pseudo)differential operator or the energy functional in high dimension. An application to the well-known MNIST classification problem will be discussed in the next section using an approach based on the signal generated by the training data. In that case one has that .
Remark 2.15.
Just as for exact interpolation and due to the fact there are no constraints like e.g. boundary conditions, the method is completely local. This means that an approximant can be computed based on a subset of the original data set that is confined or restricted to a subregion of interest. This feature will be exploited in the MNIST classification problem.
Remark 2.16.
It is well-known that the parameter has a regularizing effect that can be used to deal with noisy data when performing interpolation. It turns out that it also helps smooth out the level sets of . This is also illustrated in the next section.
Remark 2.17.
It is sometimes convenient to modify the decay rate of the exponential “basis” functions, especially if the data undergoes some initial normalization. This can be done without significant consequences other than a slight modification of the objective functional or, equivalently, of the corresponding differential operator. Indeed, for and using the well-known scaling and translation properties of the Fourier transform , it holds that
Here we use the notation for the Fourier transform of the function as well as and as place holders for the independent variables and in order to distinguish a function from its values. Furthermore denotes tanslation, that is, , and scaling, or . Replacing by and for any it is seen that
Thus the use of the modified exponentials merely corresponds to an inconsequential modification of the Euler-Lagrange equation (or its generating functional).
3. Numerical Experiments
In this section a series of experiments are performed to illustrate the effectiveness of the method described in the previous section. First we consider two dimensional problems to highlight important aspects and in order to motivate and justify the use of the method in a high dimensional context. The section then concludes with an application to the classification of the MNIST data set.
3.1. Stability of Signals’ Level Sets
Working in the context of approximating measurable functions, simple functions play an important role as they are the building block of any measurable function. While the approximation property is well-known we present a few examples to illustrate the efficacy of the use of the data signal’s level sets for classification purposes. First we will consider situations where the approximation is good, then examples when it is rather poor. It will be shown that, in all cases, i.e., regardless of how good the approximation is, the signal’s level sets still provide very useful information. This observation is crucial since it opens the door to applications to high dimensional data, where it is inconceivable that the data arguments provide a fine grid of even a small portion of the ambient space.
3.2. Characteristic Functions of Sets of Positive Measure
Take the three subsets of
| (3.1) | ||||
| (3.2) | ||||
| (3.3) |
and consider the associated characteristic function for . The first data set consists of the values of these functions on a regular grid, that is,
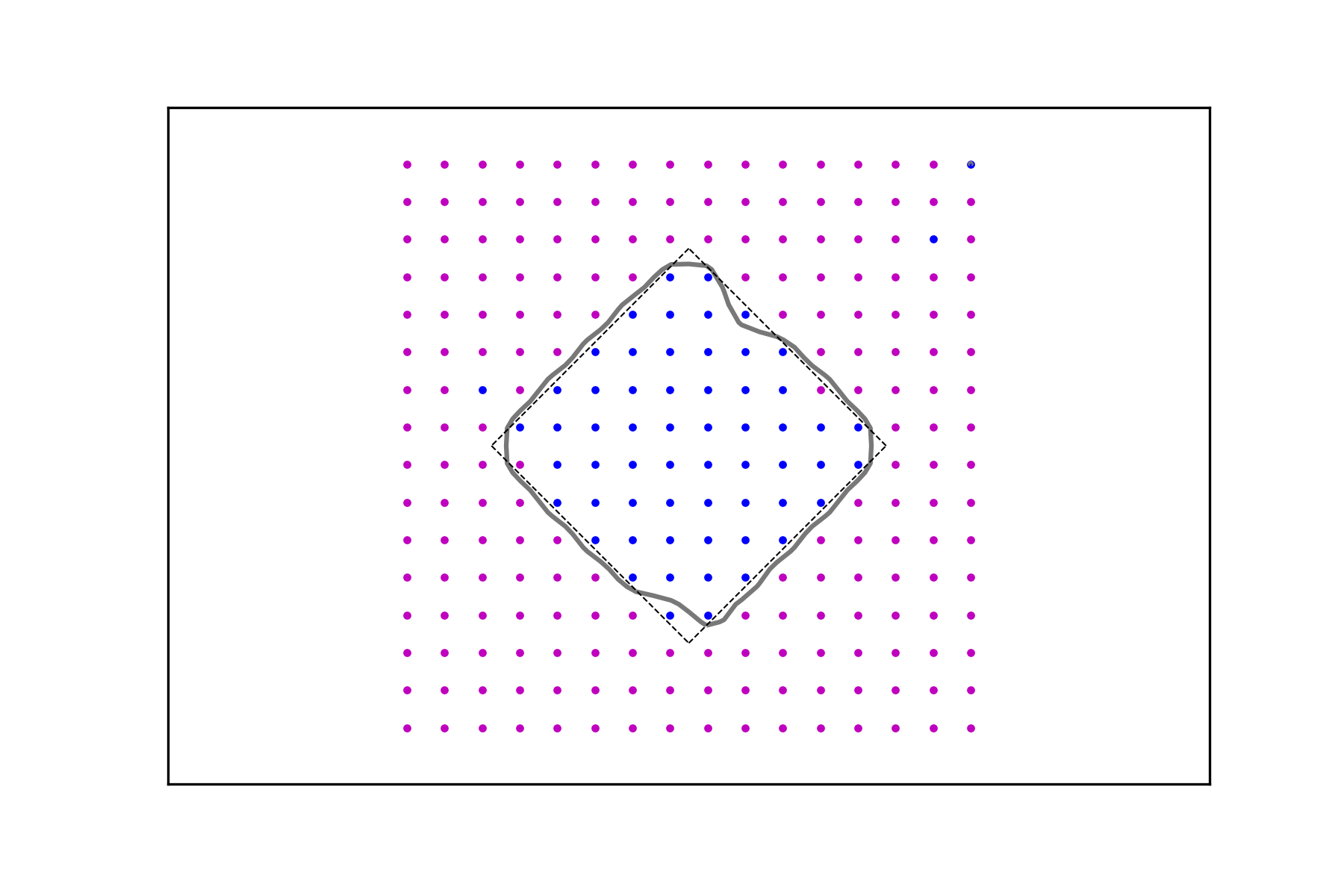
for and , which amounts to a uniform discretization of the box . In Figure 1 some level lines of the interpolant are shown for the three functions , , and for different values of the regularizing parameter and . While the size of the data set clearly correlates with the “accuracy” of the interpolation, the approximating function does an excellent job at generating meaningful and smooth level sets. Their smoothness is affected mainly by the parameter and the their proximity to the level sets corresponding to the highest values.
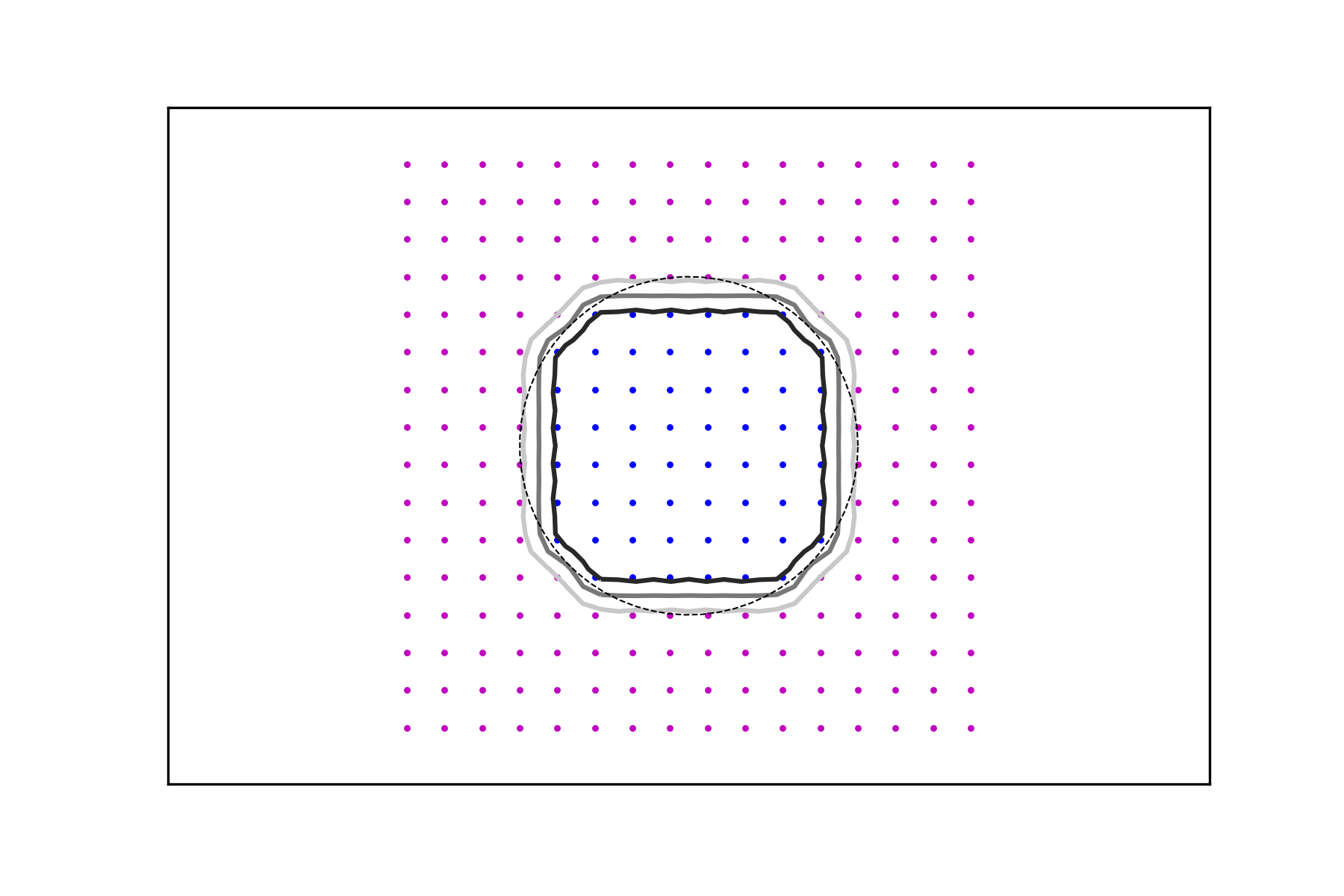






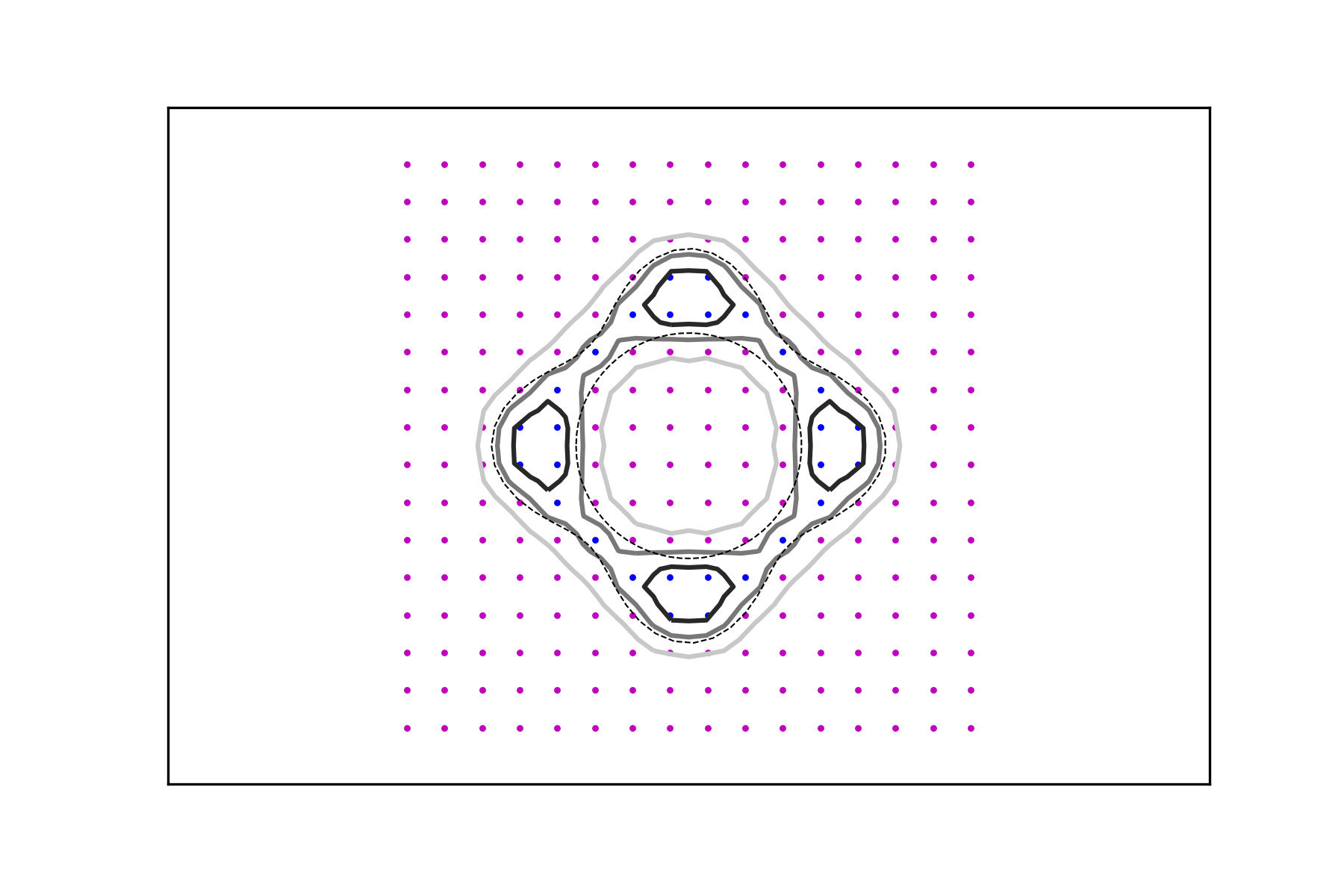

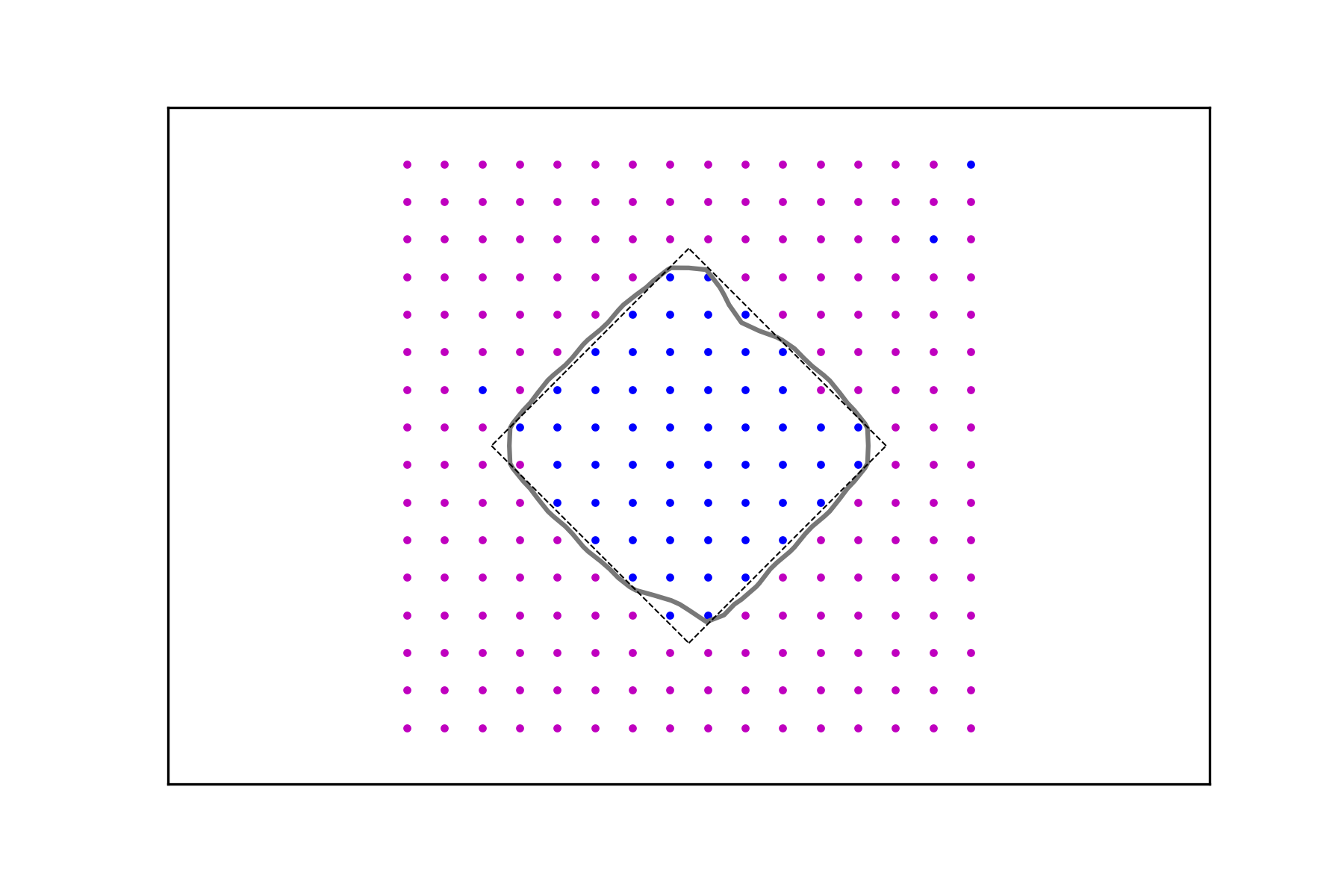
It follows that if a characteristic function has to be recovered or inferred from a data set, thresholding based on the interpolant is an effective strategy and the decision boundary is a solid choice across a range of values of the regularization parameter. Figure 2 depicts the same experiments using the denser data sets for .






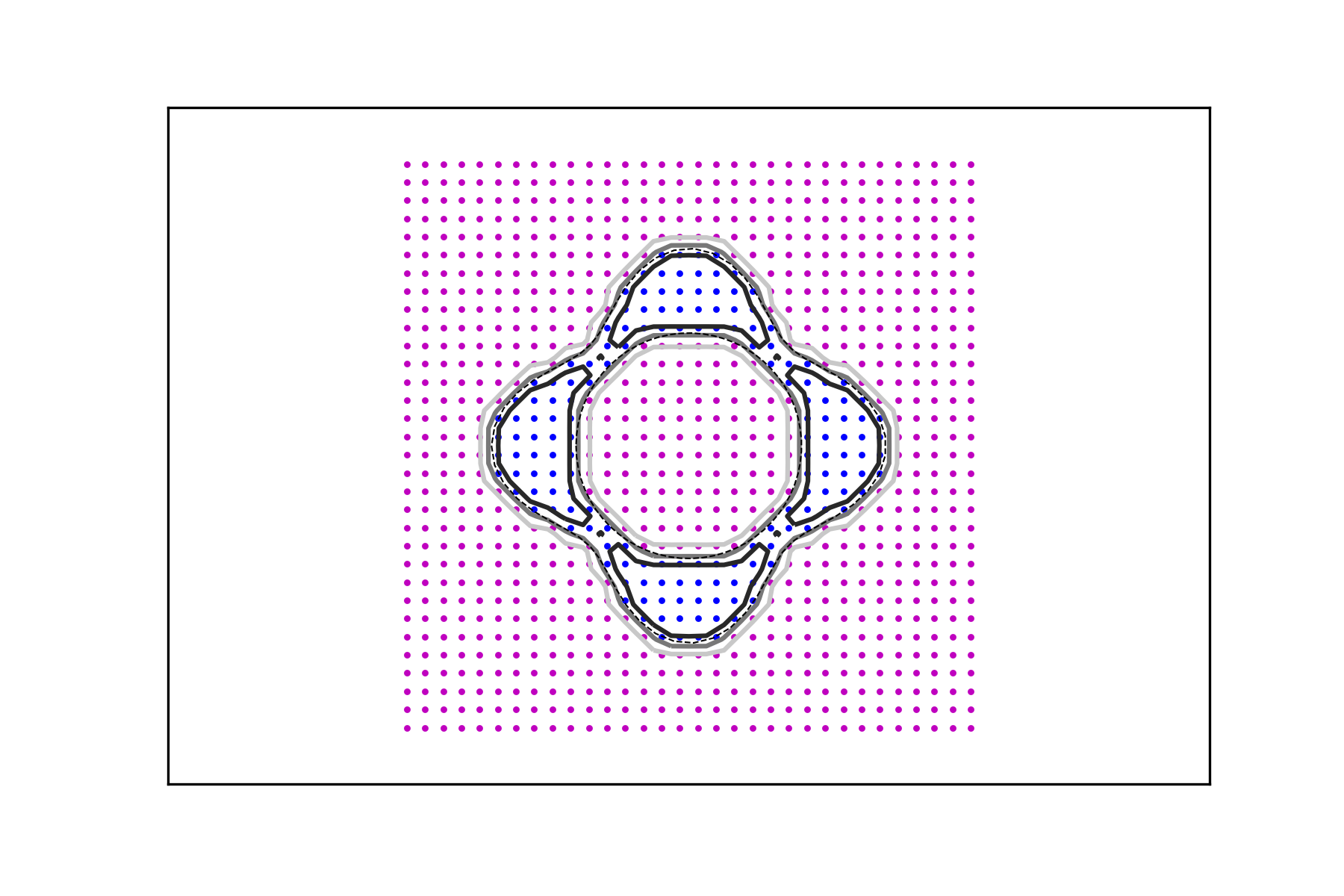


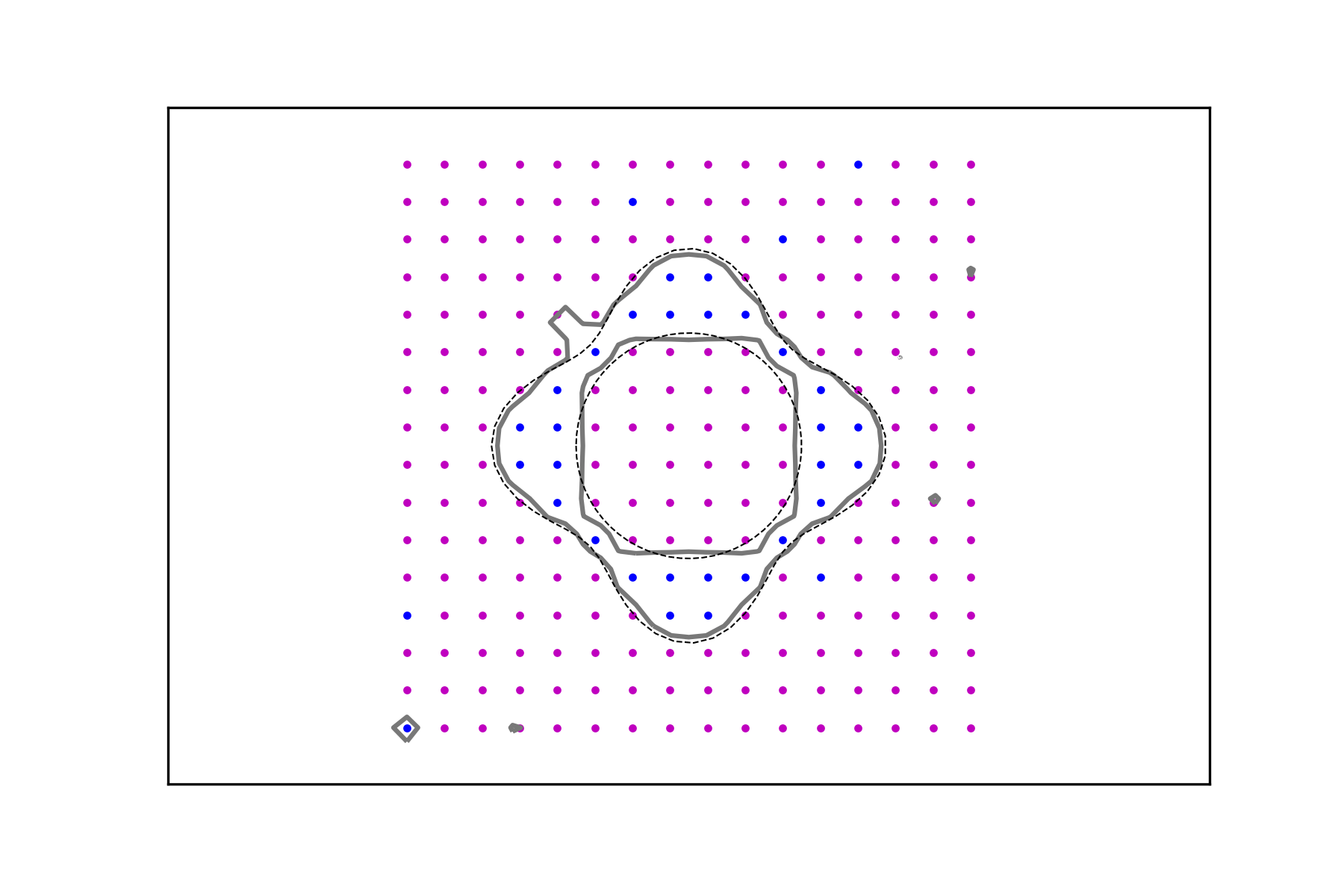
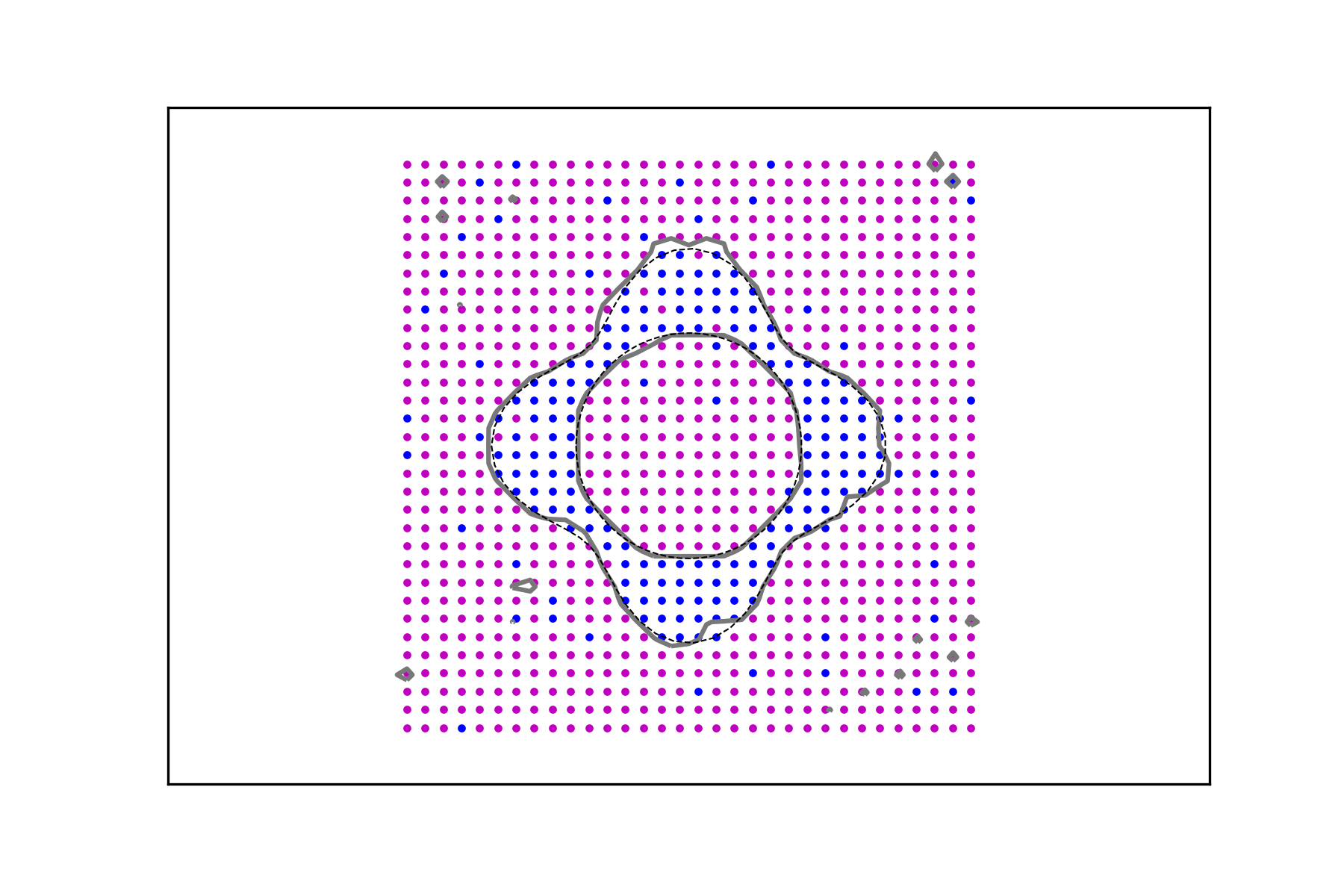
In Figures 3 and 4, it is shown how the method performs in the presence of data corruption. In Figure 3 2% of the data is misclassified, whereas the misclassification rate in Figure 4 is 5%. By this we mean that a mistake is made, with the given probability, when a value is assigned to an argument by evaluating the corresponding characteristic function. These examples clearly demonstrate the usefulness of the regularizing parameter which leads to data signals whose decision level sets are more stable in the presence of classification errors.
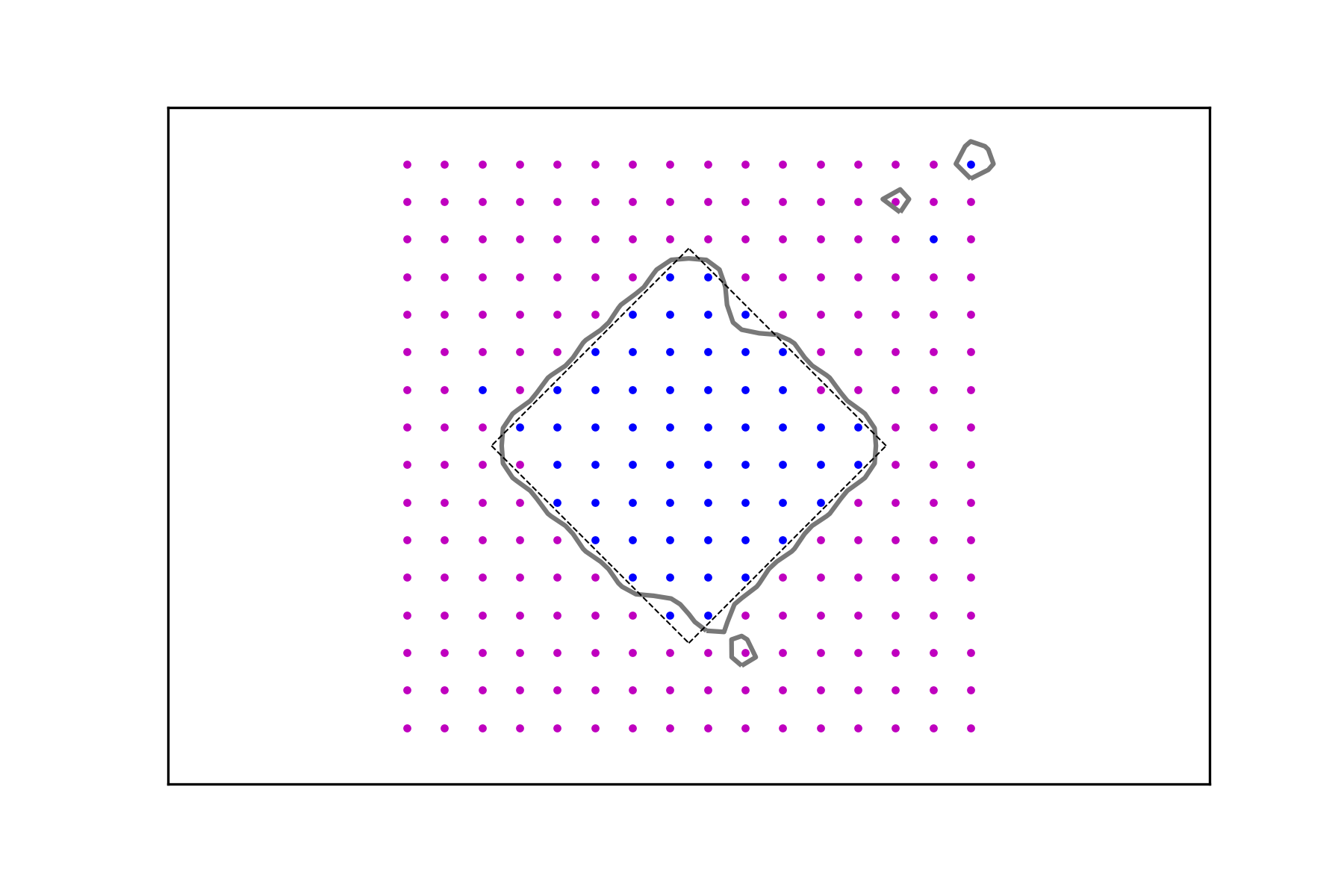







3.3. Sample Data
Finally we demonstrate that the method offers a degree robustness when the data arguments are randomly sampled from a uniform distribution supported on the box . The resulting decision boundaries of half maximal value are depicted in Figure 5 along with the sampled argument data sets . The sampling rate clearly affects the smoothness of the level sets, a deterioration that is to some extent counteracted by the regularization.





3.4. Classification
Continuity of the interpolant and its level sets (almost all of them actually smooth) are obtained at the cost of approximate interpolation. Such an approximation can still be accurate when the argument data set covers the function’s domain of definition uniformly and the value set is accurate, but the real advantage of this method is its applicability to incomplete data and/or noisy data sets. This point is further reinforced with the next series of experiments, where the data build a lower dimensional manifold of the ambient space and its signal is weak, that is, information about the underlying function is limited to sets of zero measure, or the data is not deterministic (in its argument set) but only has a probability distribution for its location.
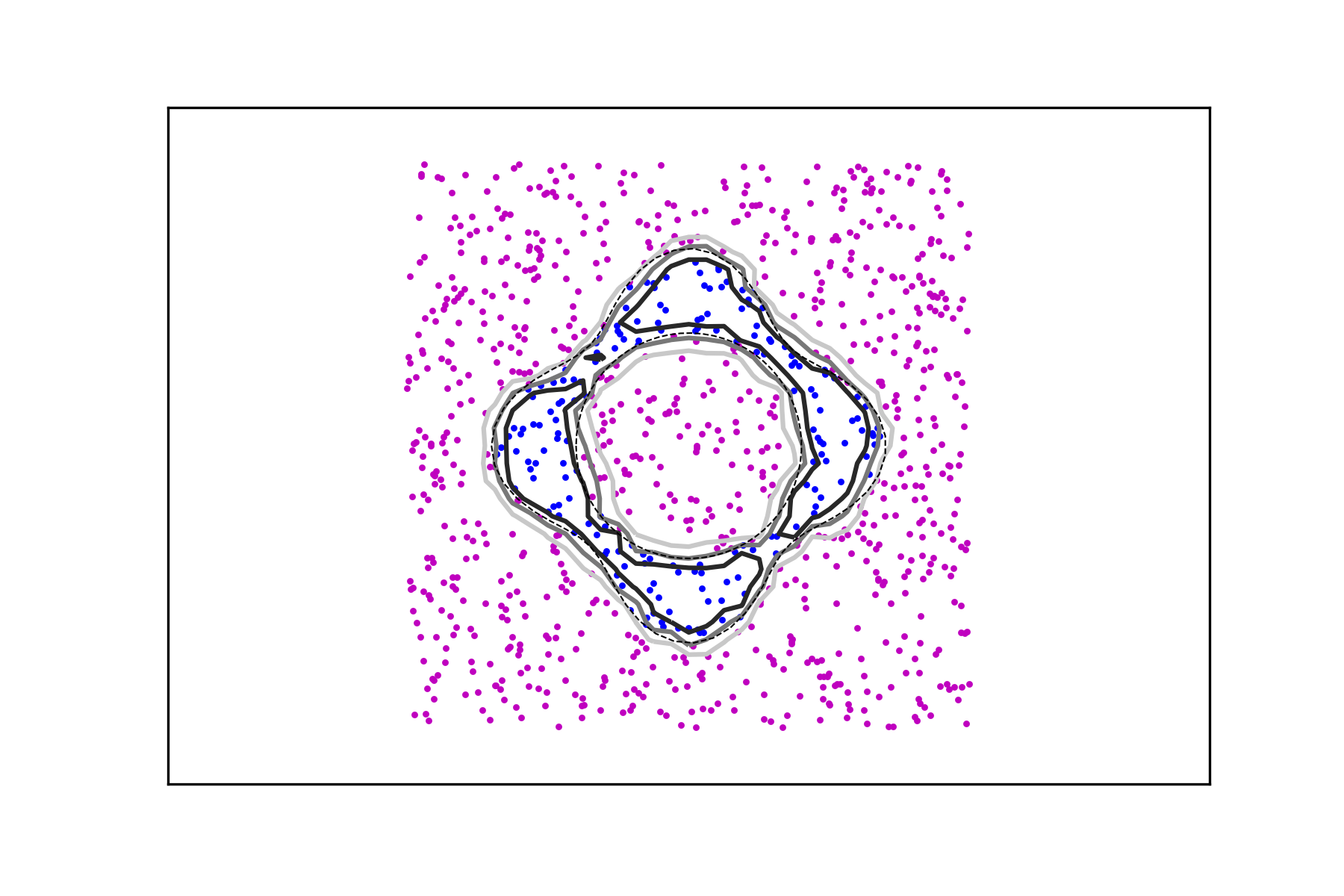
Consider the data sets , , consisting of points belonging to two distinct classes: points along a circle and points on the union of two segments with two different densities as depicted in Figure 6. For , denote the circular data sets by
and the union of segments data sets by


In the spirit of the previous examples, we create two pairs of data sets
and compute the associated signals and , . Figure 7 shows the level sets
for different values of the regularization parameter.
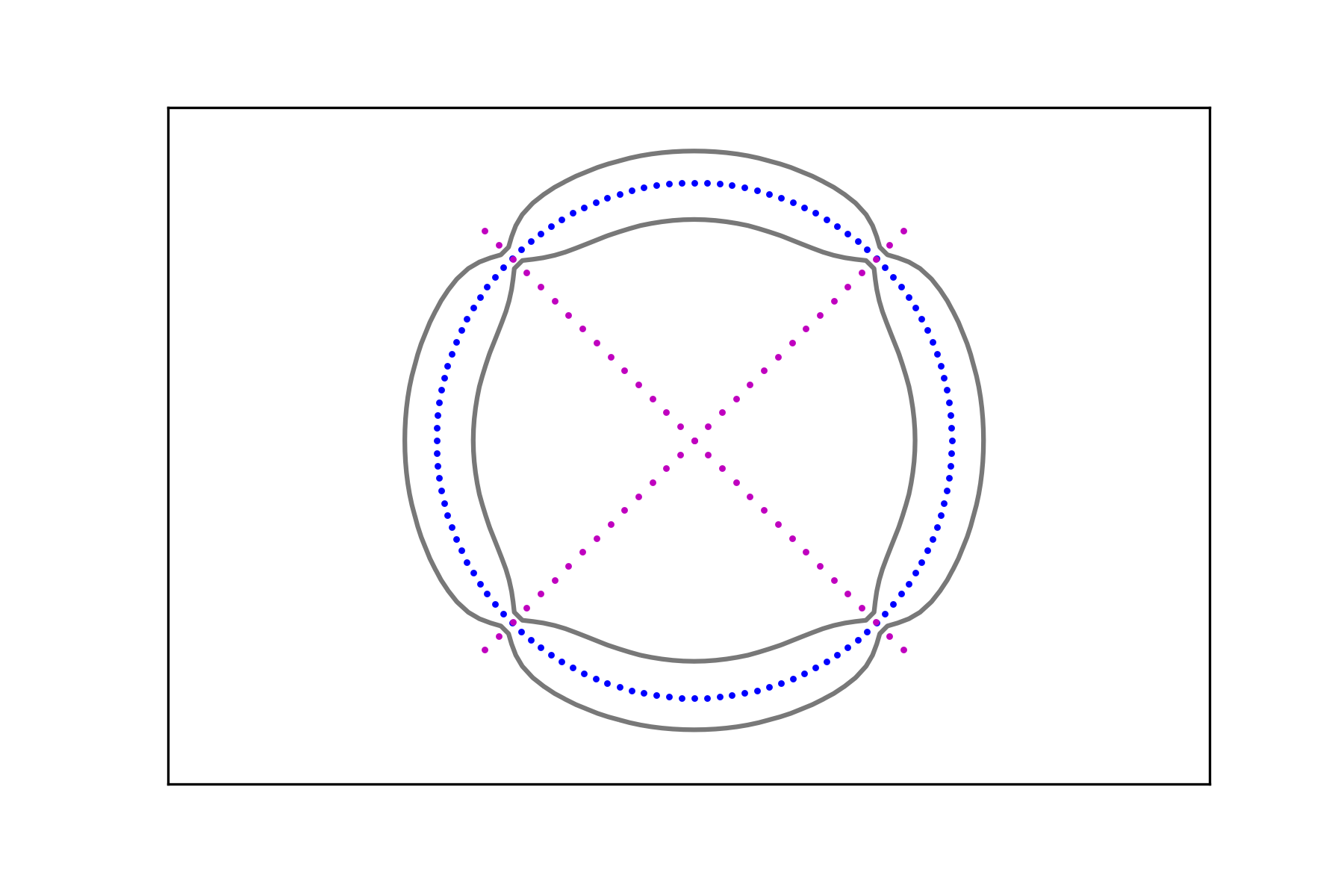
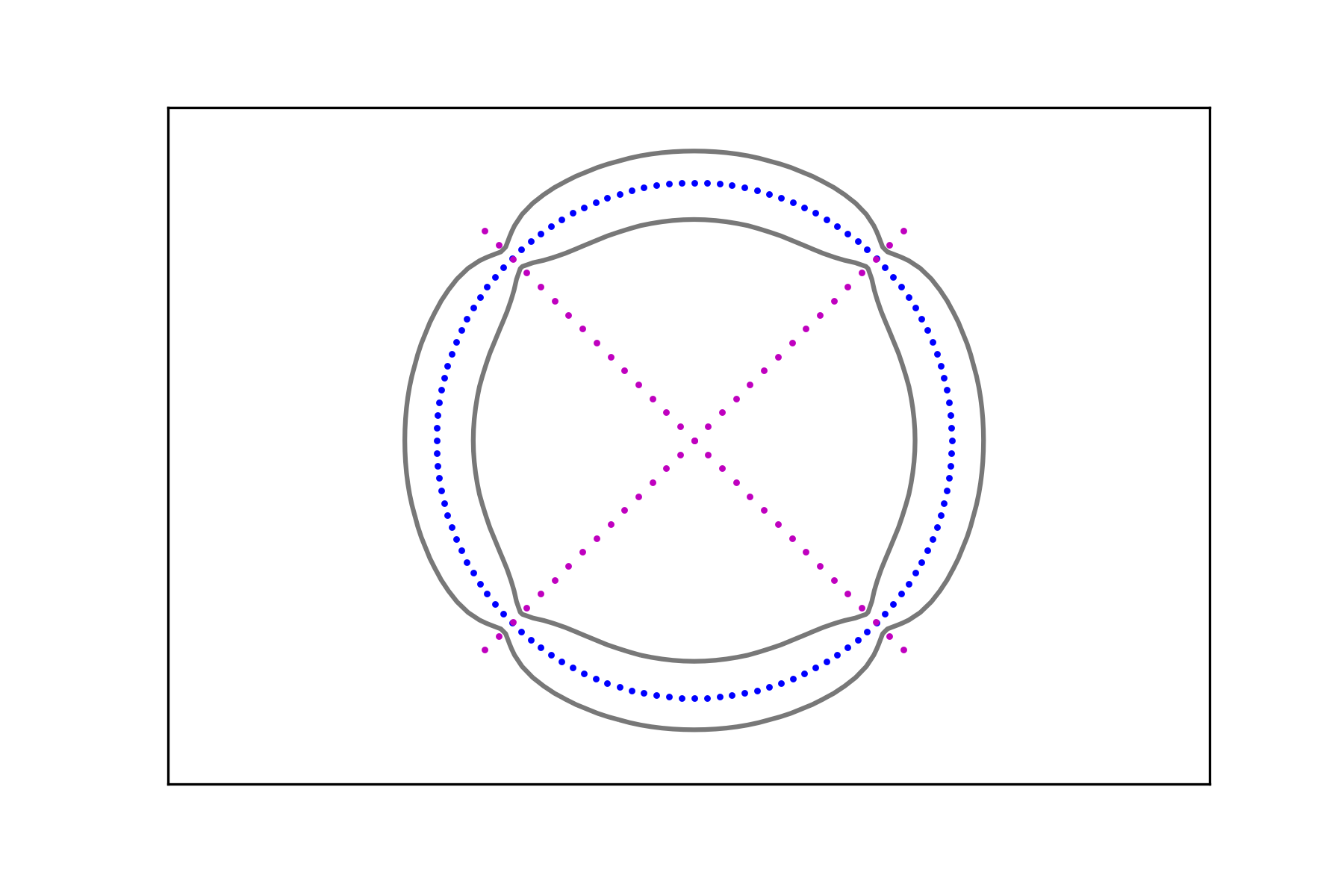
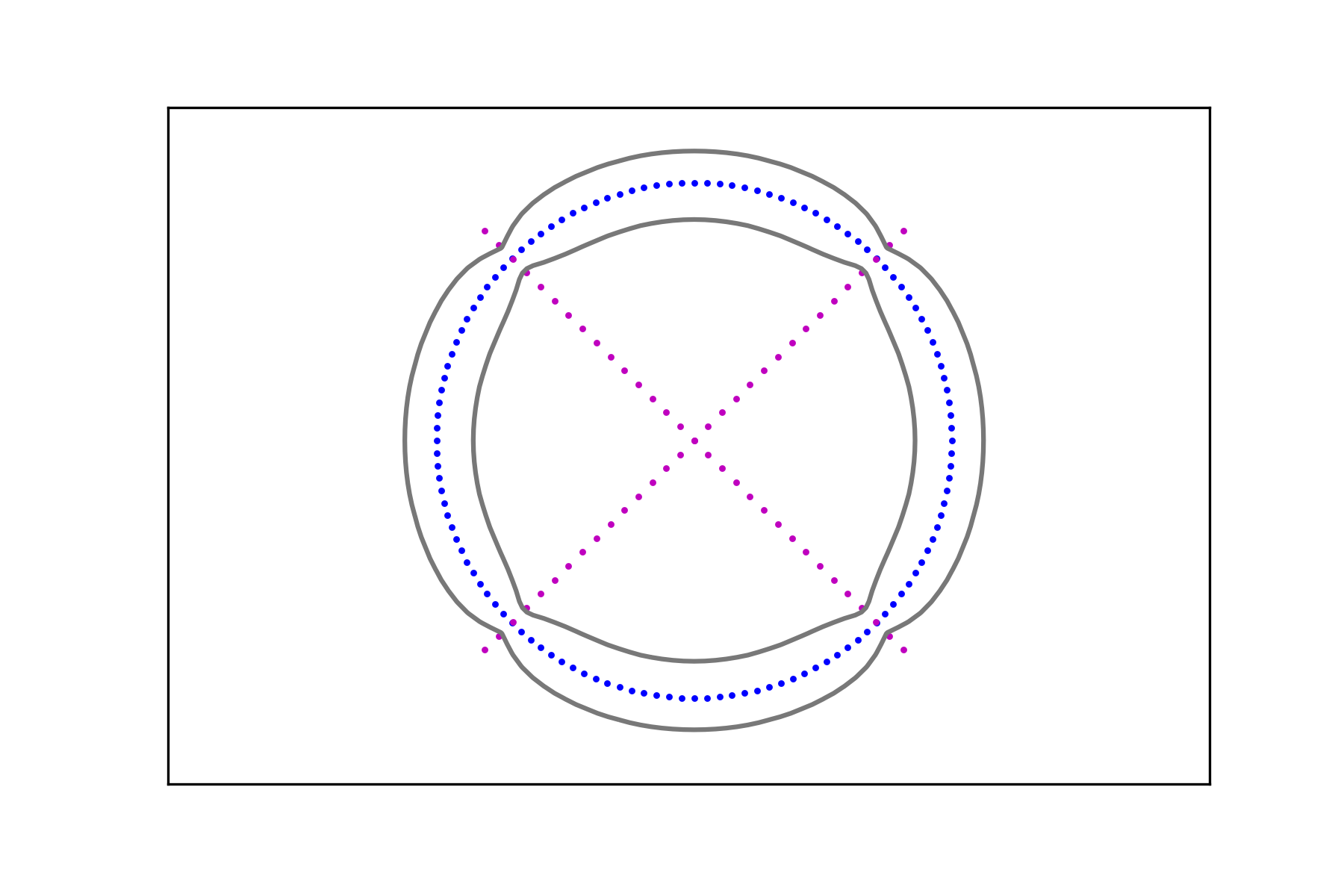
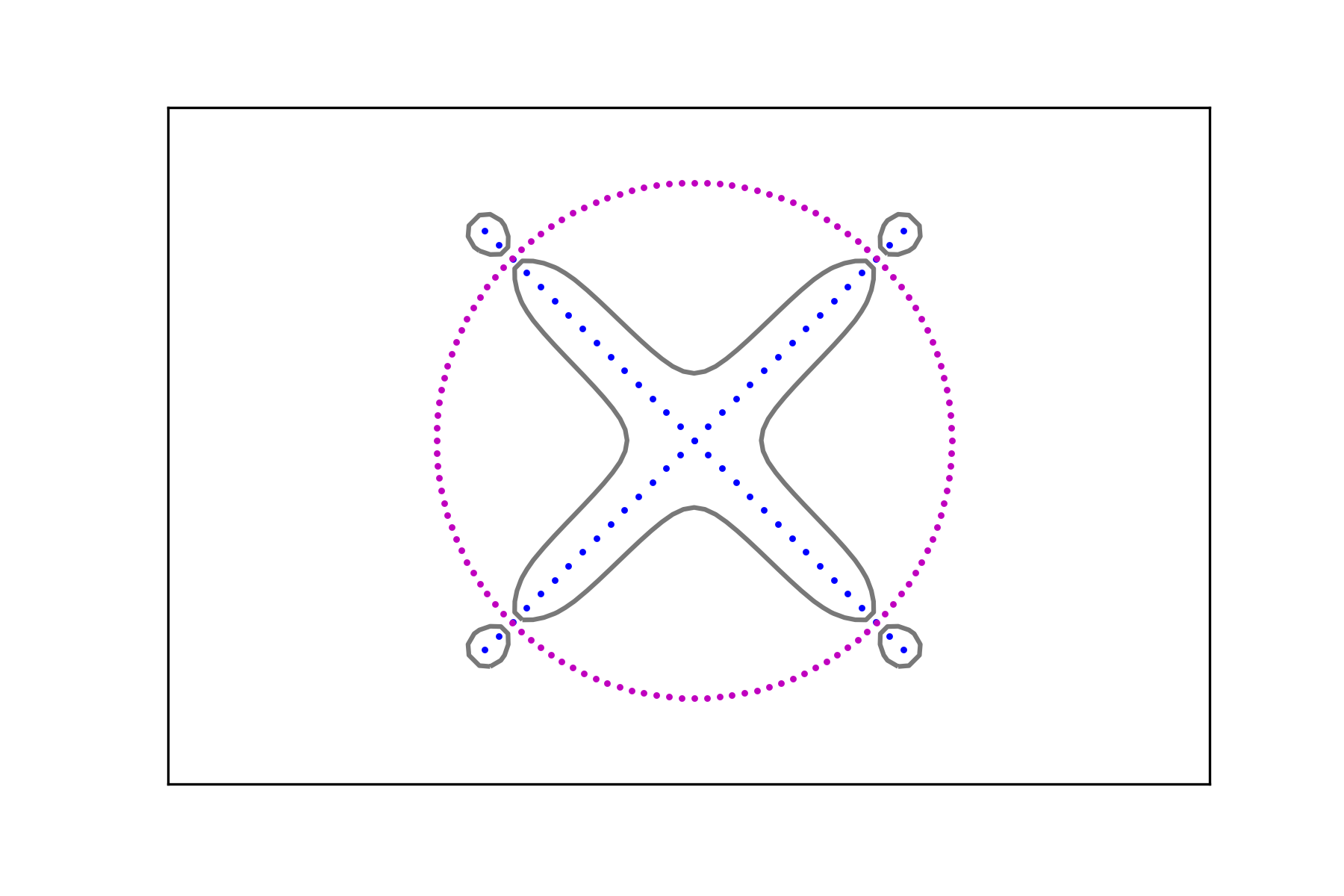
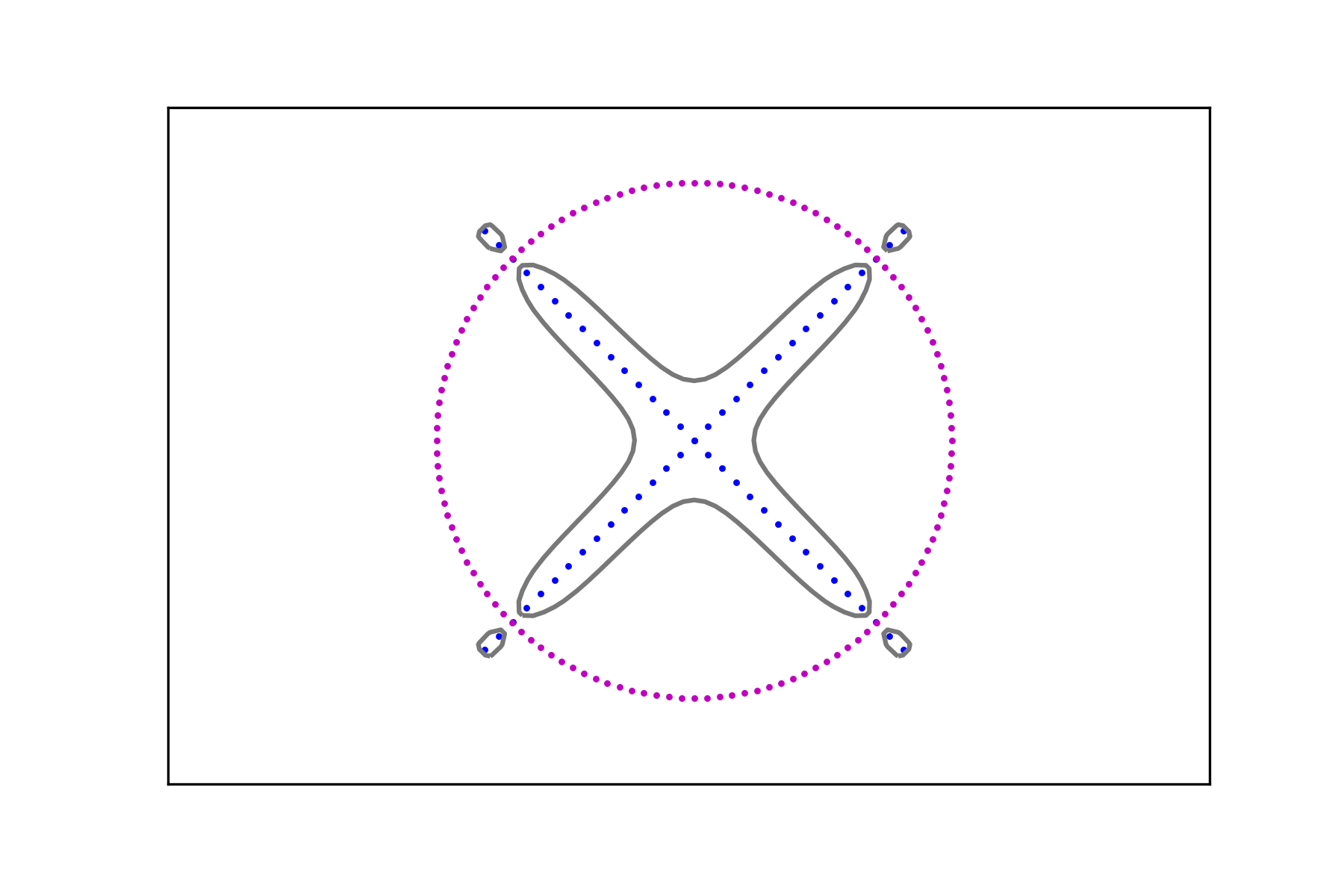



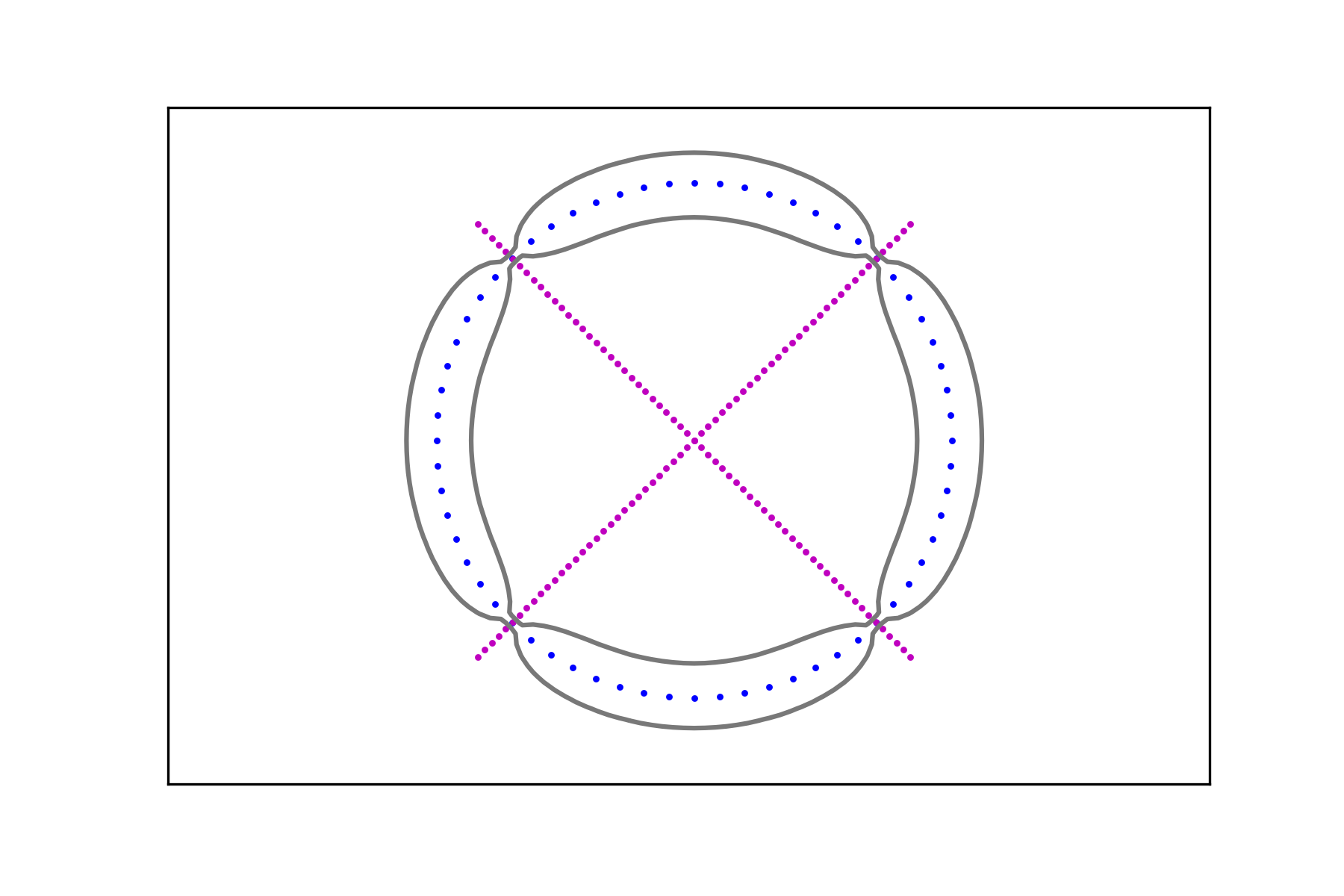
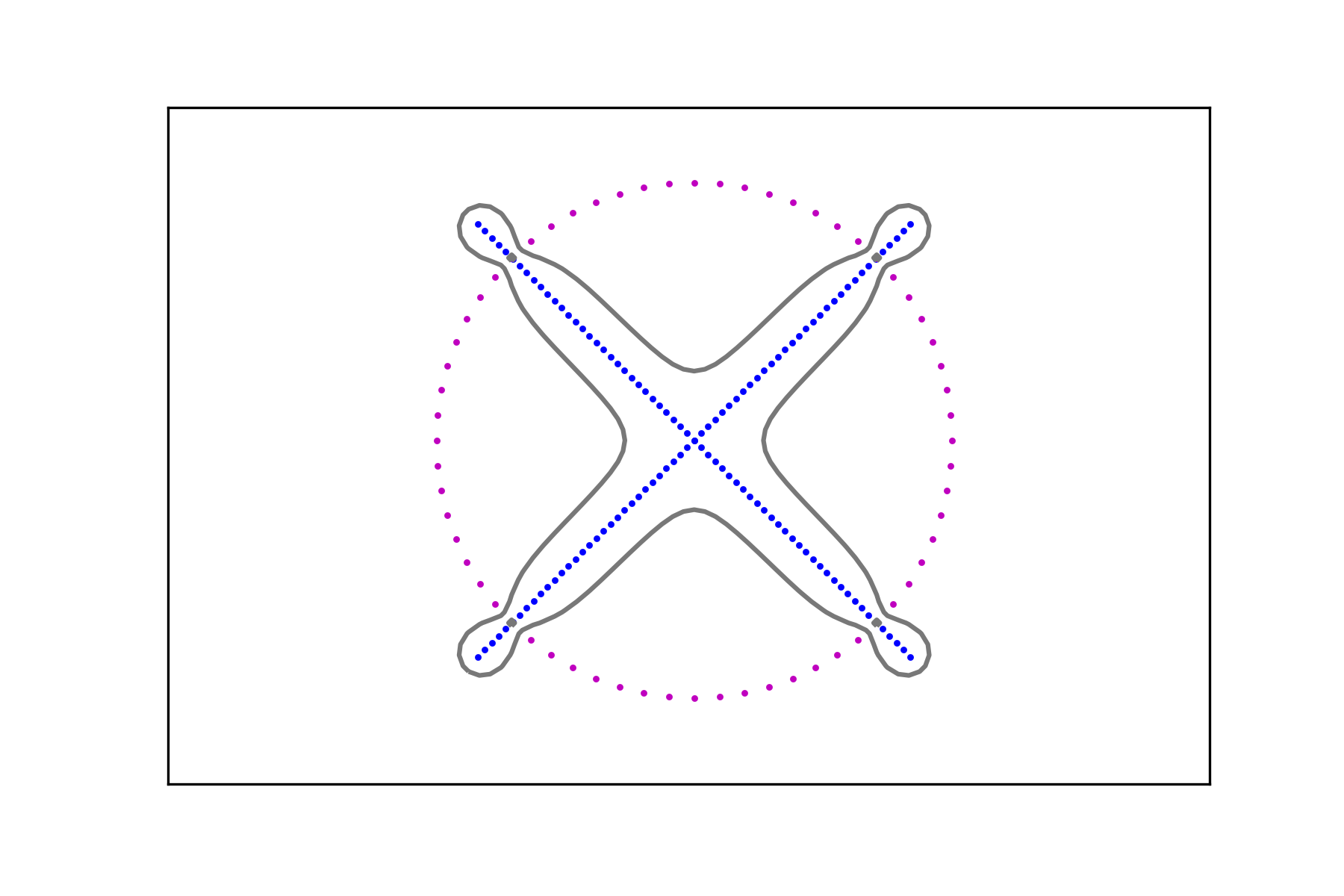
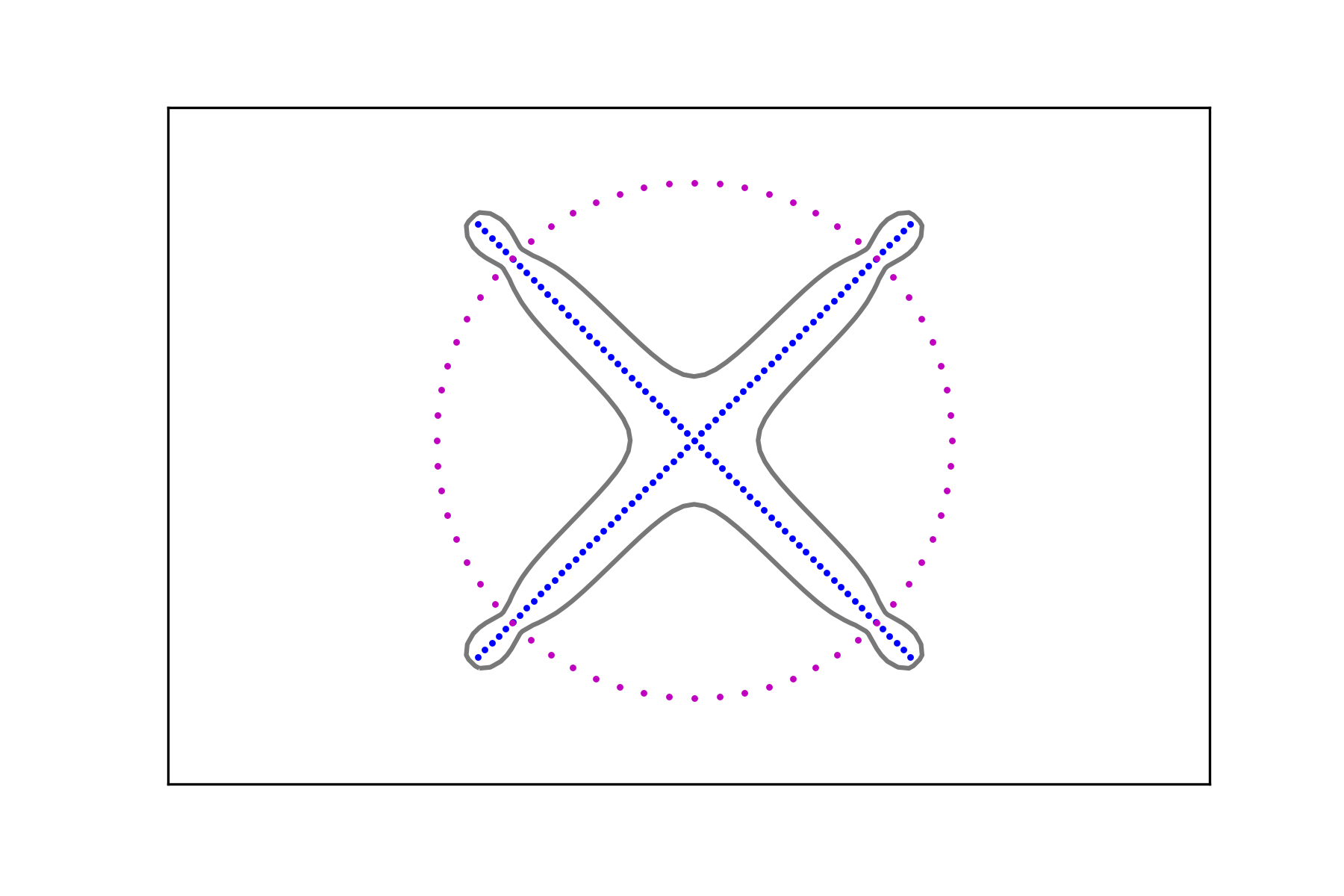

The region in their interior (i.e. the one containing the corresponding data set) can be considered as a smooth fattening of the data set to a set of positive measure. It can be obtained for any data set regardless of the intensity of its signal.
Next we turn our interest to the question of classification: given a point that needs to be classified, we use the decision algorithm defined by (2.7). This gives
which, in this case, yields the level lines (hypersurfaces in higher dimension)
| (3.4) |
as the decision boundary. This is illustrated in Figure 8 for the classification problem of the two class pairs for introduced above.

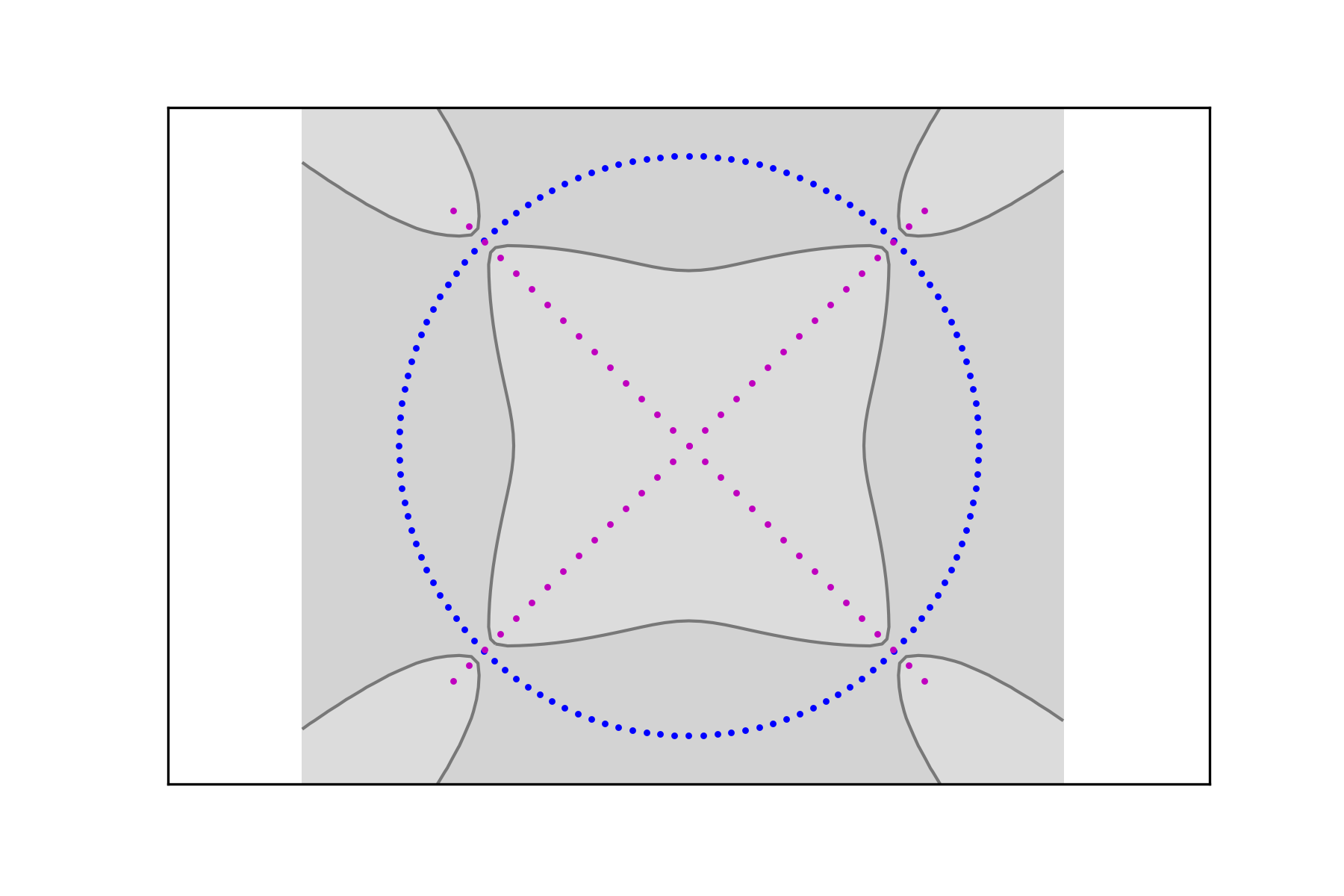




If the data pairs , , are considered the ground truth, then the above decision boundary is arguably optimal. If, on the other hand, it is known that the actual sets are the continuous circle and the union of two segments, then the data are only a sampling of these sets. In this case, the decision boundary may be biased by the relative oversampling of the one set compared to the other. This is evident when one compares the decision boundaries of Figure 8. In concrete situations, if information about the dimensionality of the ground truth is known, this effect can be mitigated by using comparable sampling rates for the different classes (see next section for an example of this procedure).
We conclude this section with a classification problem for data split into three classes , , each consisting of a set of points which are normally distributed with mean and different covariance matrices. The data set and the corresponding decision regions computed based on (2.7) are depicted in Figure 9. In these experiments .


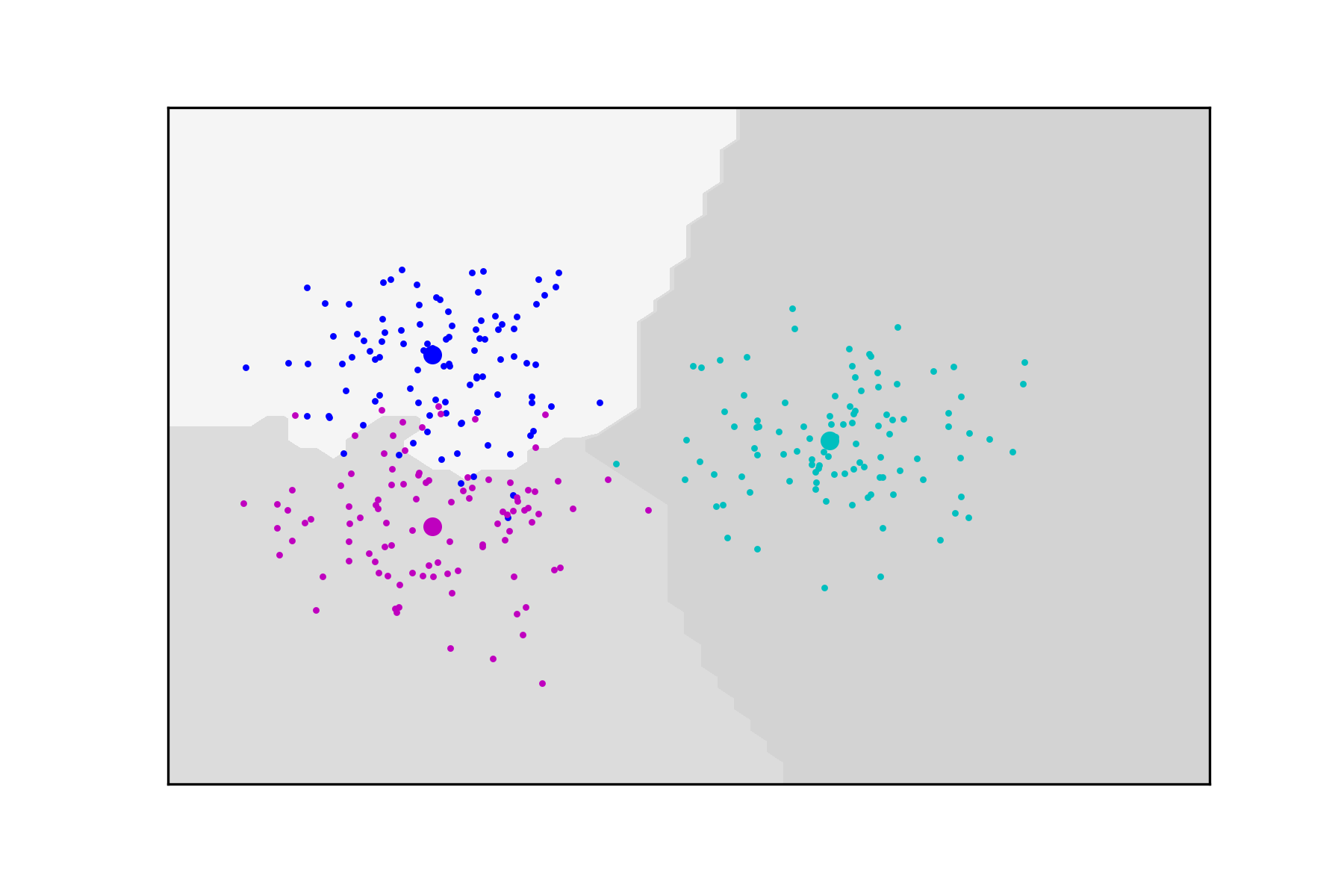
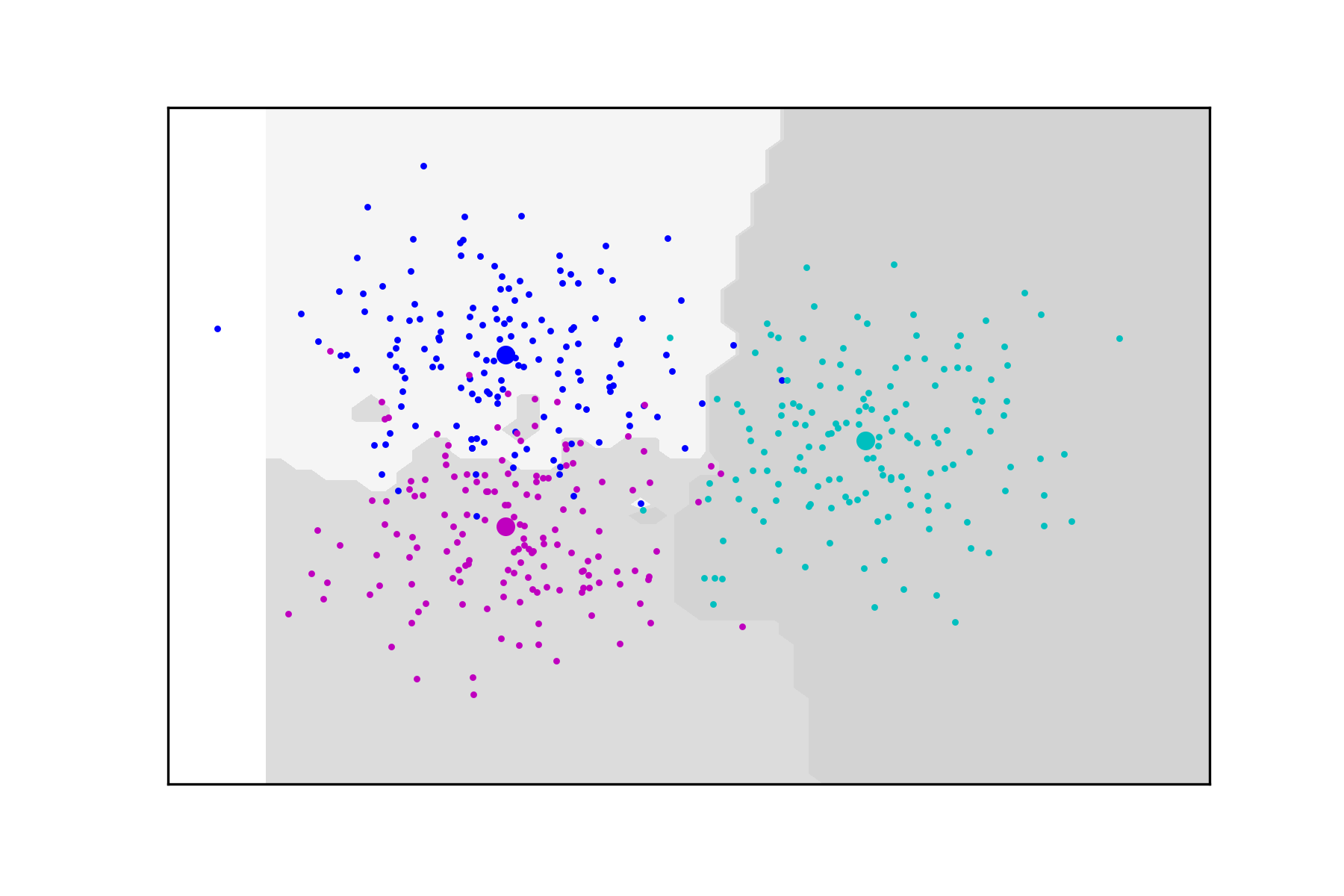


3.5. The MNIST data set
The final application is to the standard machine learning example and toy problem of digit classification for the MNIST data set. The data set consists of grayscale images of hand-written digits stored as vectors in . Here it is considered that the ambient space is simply . The argument data is normalized to have unit Euclidean norm, that is, each original vector is replaced by . In this way the maximal Euclidean distance between any two data points is . The data set is split into a training set containing 60,000 data points and their corresponding label indicating which digit is represented, and a testing data set of size 10,000. The labels of the testing data are known but need to be inferred from any knowledge that can be gleaned from the training set. This an example of when, due to the so-called curse of dimensionality, the data does not have any hope to fill the ambient space uniformly and thus, even if one assumed the existence of an underlying function , the data would never be sufficient to accurately approximate it. It has to be said of course, that the testing data mostly does not stray away significantly from the training data and the different digits in the latter build thin subsets of the ambient space. This fact is typically captured by saying that the data lives in some lower dimensional manifold(s). We know from the previous section and from the two dimensional experiments, however, that the (training) data still generates a significant, if not strong, signal. The classification method described in the sequel exploits this signal and does not require any kind of training based on the minimization of non-convex functionals, as is often the case for machine learning algorithms based on neural nets. It is, in fact, based on the solution of low dimensional, well-posed linear systems as is about to be explained. First, in order to strengthen the signal somewhat, the training set is expanded to include rotations by and horizontal/vertical translations by pixels of each image. Then, given a test image , the closest training images of each digit class are determined
where . The idea is now to use system (2.4) in order to produce approximate interpolants of the characteristic functions of each digit class given by the data set
where , and
Finally the approximative characteristic functions will compete to determine the digit to be associated with the test image via (2.7), in this case
This approach yields an accuracy of 222For comparison, a classification based on a direct nearest neighbor approach using the extended training set has an accuracy of on the test set. In Table 1 we record the detailed outcome of the classification, performed with .
Recall that this method is stable and depends continuously on the data set and hence delivers a robustness that methods with higher classification rates typically do not. Unlike neural networks it, moreover, does not require any training but uses the training set directly in a fully transparent way.
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 973 | 0 | 1 | 0 | 0 | 2 | 3 | 1 | 0 | 0 |
| 1 | 0 | 1131 | 2 | 1 | 0 | 0 | 0 | 1 | 0 | 0 |
| 2 | 4 | 1 | 1015 | 0 | 1 | 0 | 0 | 10 | 0 | 1 |
| 3 | 0 | 0 | 1 | 995 | 0 | 8 | 0 | 3 | 3 | 0 |
| 4 | 0 | 0 | 0 | 0 | 971 | 0 | 4 | 1 | 0 | 6 |
| 5 | 1 | 0 | 0 | 8 | 0 | 877 | 4 | 1 | 0 | 1 |
| 6 | 0 | 2 | 0 | 0 | 0 | 1 | 955 | 0 | 0 | 0 |
| 7 | 0 | 4 | 4 | 0 | 0 | 0 | 0 | 1020 | 0 | 0 |
| 8 | 2 | 0 | 3 | 9 | 3 | 2 | 3 | 4 | 946 | 2 |
| 9 | 1 | 2 | 1 | 4 | 9 | 7 | 0 | 10 | 2 | 973 |
Remark 3.1.
It should be pointed out that the proposed classification method performs well when the data classes effectively lie on submanifolds the shape of which their relative signals are able to capture. If the class similarity is not geometric in this sense, this method will likely not produce satisfactory results if applied to the original data. It is indeed possible for general data sets to exhbit classes that share some common feature but are far apart as points in space. In this case, the dots cannot be easily connected.
References
- [1] Mark A. Aizerman, Emmanuel M. Braverman, and Lev I. Rozonoer. Theoretical foundations of the potential function method in pattern recognition learning. Automation and Remote Control, 25:821–837, 1964.
- [2] Bernhard E. Boser, Isabelle M. Guyon, and Vladimir N. Vapnik. A training algorithm for optimal margin classifiers. In Proceedings of the fifth annual Acm workshop on Computational learning theory, pages 144–. Assn for Computing Machinery, 1992.
- [3] T. Poggio and F. Girosi. Regularization Algorithms for Learning that are Equivalent to Multilayer Networks. Science, 247(4945):978–982, 1990.
- [4] V.N. Vapnik and A.Y. Chervonenkis. On a class of algorithms of learning pattern recognition. Avtomatika i Telemekhanika, 25(6):In Russian, 1964.
- [5] H. Wendland. Scattered Data Approximations. Cambridge Monographs on Applied and Computational Mathematics. Cambridge University Press, Cambridge, 2004.