Photoswap:
Personalized Subject Swapping in Images
Abstract
In an era where images and visual content dominate our digital landscape, the ability to manipulate and personalize these images has become a necessity. Envision seamlessly substituting a tabby cat lounging on a sunlit window sill in a photograph with your own playful puppy, all while preserving the original charm and composition of the image. We present Photoswap, a novel approach that enables this immersive image editing experience through personalized subject swapping in existing images. Photoswap first learns the visual concept of the subject from reference images and then swaps it into the target image using pre-trained diffusion models in a training-free manner. We establish that a well-conceptualized visual subject can be seamlessly transferred to any image with appropriate self-attention and cross-attention manipulation, maintaining the pose of the swapped subject and the overall coherence of the image. Comprehensive experiments underscore the efficacy and controllability of Photoswap in personalized subject swapping. Furthermore, Photoswap significantly outperforms baseline methods in human ratings across subject swapping, background preservation, and overall quality, revealing its vast application potential, from entertainment to professional editing.

1 Introduction
Imagine a digital world where the boundaries of reality and creativity blur, where a photograph of a tabby cat lounging in a sunlit window sill can effortlessly be transformed to feature your playful puppy in the same pose. Or envision yourself as a part of a famous movie scene, replaced seamlessly with the original character while preserving the very essence and composition of the scene. Can we achieve this level of personalized image editing, not just with expert-level photo manipulation skills, but in an automated, user-friendly manner? This question lies at the heart of personalized subject swapping, the challenging task of replacing the subject in an image with a user-specified subject, while maintaining the integrity of the original pose and composition. It opens up a plethora of applications in areas such as entertainment, advertising, and professional editing.
Personalized subject swapping is a complex undertaking that comes with its own set of challenges. The task requires a profound comprehension of the visual concept inherent to both the original subject and the replacement subject. Simultaneously, it demands the seamless integration of the new subject into the existing image. One of the critical objectives in subject swapping is to preserve the similar pose of the replacement subject. It is crucial that the swapped subject seamlessly fits into the original pose and scene, creating a natural and harmonious visual composition. This necessitates careful consideration of factors such as lighting conditions, perspective, and overall aesthetic coherence. By effectively blending the replacement subject with these elements, the final image maintains a sense of continuity and authenticity.
Existing image editing methods fall short in addressing these challenges. Many of these techniques are restricted to global editing and lack the finesse needed to seamlessly integrate new subjects into existing images. For example, for most text-to-image (T2I) models, a slightly prompt change could lead to a totally different image. Recent works [27, 25, 6, 3, 46] allow user to control the generation with an additional input such as user brush, semantic layout, or sketches. However, it is still challenging to guide the generation process to follow users’ intent on the generation of object shape, texture, and identity. Other approaches [16, 41, 26] have explored the potential of using text prompts to edit image content in the context of synthetic image generation. Despite showing promise, these methods are not yet fully equipped to handle the intricate task of swapping subjects in existing images with user-specified subjects.
Therefore, we present Photoswap, a novel framework that leverages pre-trained diffusion models for personalized subject swapping in images. In our approach, the diffusion model learns to represent the concept of the subject (). Then the representative attention map and attention output saved in the source image generation process will be transferred into the generation process of the target image to generate the new subject while keeping non-subject pixels unchanged. Our extensive experiments and evaluations demonstrate the effectiveness of Photoswap. Not only does our method enable the seamless swapping of subjects in images, but it also maintains the pose of the swapped subject and the overall coherence of the image. Remarkably, Photoswap outperforms baseline methods by a large margin in human evaluations of subject identity preservation, background preservation, and overall quality of the swapping (e.g., 50.8% vs. 28.0% in terms of overall quality). The contributions of this work are as follows: 1) We present a new framework for personalized subject swapping in images. 2) We propose a training-free attention swapping method that governs the editing process. 3) The efficacy of our proposed framework is demonstrated through extensive experiments including human evaluation.
2 Related Work
2.1 Text-to-Image Generation
In the early stages of text-based image generation, Generative Adversarial Networks (GANs) [14, 2, 19] were widely used due to their exceptional ability to produce high-quality images. These models aimed to align textual descriptions with synthesized images through multi-modal vision-language learning, achieving impressive results on specific domains (e.g., bird, chair and human face). When combined with CLIP [32], a large pre-trained model that learns visual-textual representations from millions of caption-image pairs, GAN models [7] have demonstrated promising outcomes in cross-domain text-to-image (T2I) generation. Recently, T2I generation has seen remarkable progress with auto-regressive [29, 9, 9] and diffusion models [27, 15, 30, 36], offering diverse outcomes and can synthesize high-quality images closely aligned with textual descriptions in arbitrary domains.
Rather than focusing on T2I generation tasks without any constraints, subject-driven T2I generation [28, 4, 35] requires the model to identify the specific object from a set of visual examples and synthesize novel scenes incorporating them based on the input text prompts. Building upon modern diffusion techniques, recent approaches such as DreamBooth [35] and Textual Inversion [12, 13, 21, 26] learn to invert special tokens from a given set of images. By combining these tokens with text prompts, they generate personalized unseen images. To improve data efficiency, retrieval augmentation techniques [39, 1, 5] leverages external knowledge bases to overcome limitations posed by rare entities, resulting in visually relevant appearances and enhanced personalization. In our work, we aim to tackle personalized subject swapping, not only preserving the identity of subjects in reference images, but also maintaining the context of the source image.
2.2 Text-guided Image Editing
Text-guided image editing manipulates an existing image based on the input textual instructions, while preserving certain aspects or characteristics of the original image. Early works based on GAN models [19] only limits to a certain object domain. Diffusion-based methods [46, 27, 10] break this barrier and support text-guided image editing. Though these methods generate stunning results, many of them suffer from conducting local editing, and additional manual masks [25, 45, 25] are required to constrain the editing regions, which is often tedious to draw. By employing cross-attention [16] or spatial characteristics [41], the local editing can be achieved but struggles with non-rigid transformations (e.g., changing pose) and retaining the original image layout structure. While Imagic [20] addresses the need for non-rigid transformations by fine-tuning a pre-trained diffusion model to capture image-specific appearances, it requires test-time finetuning, which is not time-efficient for deployment. Moreover, relying solely on text as input lacks precise control. In contrast, we propose a novel training-free attention swapping scheme that enables precise personalization based on reference images, without the need for time-consuming finetuning.
2.3 Exemplar-guided Image Editing
Exemplar-guided image editing covers a broad range of applications, and most of the works [42, 17, 49] can be categorized as exemplar-based image translation tasks, conditioning on various information, such as stylized images [24, 8, 48], layouts [44, 22, 18], skeletons [22], sketches/edges [38]. With the convenience of stylized images, image style transfer [23, 47] receives extensive attentions, replying on methods to build a dense correspondence between input and reference images, but it cannot deal with local editing. To achieve local editing with non-rigid transformation, conditions like bounding boxes and skeletons are introduced, but require drawing efforts from users, which sometimes are hard to obtain. A recent work [43] poses exemplar-guided image editing task as an inpainting task with the mask and transfers the semantic content from the reference image to the source one, with the context intact. Different from these works, we propose a more user-friendly scenario by conducting personalized subject swapping with only reference images and obtain high-quality editing results.
3 Preliminary
Diffusion models are a type of generative model that operates probabilistically. In this process, an image is created by gradually eliminating noise from the target that is characterized by Gaussian noise. In the context of text-to-image generation, a diffusion model typically involves a process where an initial random image is gradually refined step by step, with each step guided by a learned model, until it becomes a realistic image. The changes to the image spread out and affect many pixels over time. Given an initial random noise , the diffusion model gradually denoise , which gives .
Diffusion models are probabilistic generative models that learn to generate images by simulating a random process called a diffusion process. In the image generation process, the diffusion model gradually predicts the noise at the current diffusion step and denoises to get the final image. In this study, we utilize a pre-trained text-to-image diffusion model, Stable Diffusion [33], which encodes the image into latent space and gradually denoises the latent variable to generate a new image. Stable Diffusion is based on a U-Net architecture [34], which generates latent variable conditioned on a given text prompt and the latent variable from the previous step :
| (1) |
The U-Net consists of layers that include repetition of self-attention and cross-attention blocks. This study focuses on manipulating self-attention and cross-attention to achieve the task of personalized subject swapping.
4 The Photoswap Method
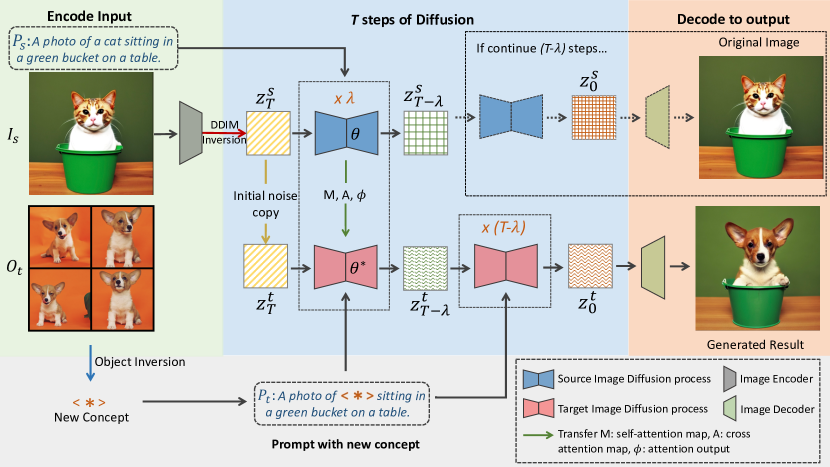
Providing a few reference images of a personalized target subject , Photoswap can seamlessly swap it with another subject in a given source image . The Photoswap pipeline is illustrated in Figure 2. To learn the visual concept of the target subject , we fine-tune a diffusion model with reference images and do object inversion to represent using special token *. Then, to substitute the subject in the source image, we first obtain the noise 111For a synthetic image, is the initial noise used to generate it. For a real image, we utilize an improved version of DDIM inversion [40] to get the initial noise and re-generate the source image. See Sec. 5.1 for details. that can be used to re-construct the source image . Next, through the U-Net, we obtain the needed feature map and attention output in the self-attention and cross-attention layers, including , , and (which we will introduce in Sec. 4.2). Finally, during the target image generation process that is conditioned on the noise and the target text prompt , in the first steps, those intermediate variables (, , and ) would be replaced with corresponding ones obtained during the the source image generation process. In the last () steps, no attention swapping is needed and we can continue the denoising process as usual to obtain the final resulting image. Sec. 4.1 discusses the visual concept learning technique we used, and Sec. 4.2 details the training-free attention swapping method for controllable subject swapping.
4.1 Visual Concept Learning
Subject swapping requires a thorough understanding of the subject’s identity and specific characteristics. This knowledge enables the creation of accurate representations that align with the source subject. The subject’s identity influences the composition and perspective of the image, including its shape, proportions, and textures, which affect the overall arrangement of elements. However, existing diffusion models lack information about the target subject () in their weights because the training data for text-to-image generation models does not include personalized subjects. To overcome this limitation and generate visually consistent variations of subjects from a given reference set, we need to personalize text-to-image diffusion models accurately. Recent advancements have introduced various methods, such as fine-tuning the diffusion model with distinct tokens associated with specific subjects, to achieve this “personalization”[11, 35, 21]. In our experiments, we primarily utilize DreamBooth[35] as a visual concept learning method. It’s worth noting that alternative concept learning methods can also be effectively employed with our framework.

4.2 Controllable Subject Swapping via Training-free Attention Swapping
Subject swapping poses intriguing challenges, requiring the maintenance of the source image’s spatial layout and geometry while integrating a new subject concept within the same pose. This necessitates preserving the critical features in the source latent variable, which encapsulates the source image information, and leveraging the influence of the target image text prompt , which carries the concept token, to inject the new subject into the image.
The central role of the attention layer in orchestrating the generated image’s layout has been well-established in prior works [16, 3, 41]. To keep non-subject pixels intact, we orchestrate the generation of the target image by transferring vital variables to the target image generation process. Here, we explore how distinct intermediate variables within the attention layer can contribute to a controllable generation in the context of subject swapping.
Within the source image generation process, we denote the cross-attention map as , the self-attention map as , the cross-attention output as , and the self-attention output as . The corresponding variables in the target image generation process are denoted as , , , , where represents the current diffusion step.
In the self-attention block, the latent feature is projected into queries , keys , and values . We obtain the self-attention block’s output using the following equation:
| (2) |
where is the self-attention map, and is the feature output from the self-attention layer. The cross-attention block’s output is:
| (3) |
where is the cross-attention map. In both self-attention and cross-attention, the attention map and are correlated to the similarity between and , acting as weights that dictate the combination of information in . In this work, the manipulation of the diffusion model focus on self-attention and cross-attention within U-Net, specifically, swapping , , and , while keeping unchanged.
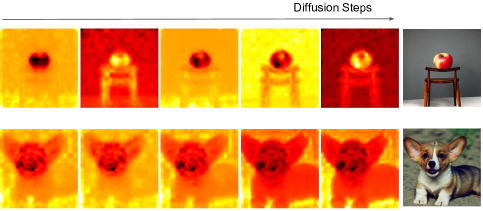
Self-attention map , as it calculates the similarity within spatial features after linear projection, plays a pivotal role in governing spatial content during the generation process. As visualized in Figure 3, we capture during the image generation and highlight the leading components via Singular Value Decomposition (SVD). This visualization reveals a high correlation between and the geometry and content of the generated image. Further, when visualizing the full steps of the diffusion process (Figure 4), we discern that the layout information is mirrored in the self-attention from the initial steps. This insight underscores the necessity of initiating the swap early on to prevent the emergence of a new, inherent layout.
Cross-attention map is determined by both latent variable and text prompt, as in Equation 3, and can be viewed as a weighted sum of the information from a text prompt. Copying to during the target image generation process improves the layout alignment between the source image and the target image.
Self-attention output , derived from the self-attention layer, encapsulates rich content information from the source image, independent of direct computation with textual features. Hence, replacing with enhances the preservation of context and composition from the original image. Our observations indicate that exerts a more profound impact on the image layout than the cross-attention map .
Cross-attention output , emanating from the cross-attention layer, embodies the visual concept of the target subject. It is vital to note that substituting cross-attention output with would obliterate all information from the target text prompt , as illustrated in Equation 3. Given that and are projections of target prompt embeddings, we retain unchanged to safeguard the target subject’s identity.
Algorithm 1 provides the pseudo code of our full Photoswap algorithm.

5 Experiments
5.1 Imlementation Details
For the implementation of subject swapping on real images, we require an additional process that utilizes an image inversion method, specifically the DDIM inversion [40], to transform the image into initial noise. This inversion method relies on a reversed sequence of sampling to achieve the desired inversion. However, there exist inherent challenges when this inversion process is applied in text-guided synthesis within a classifier-free guidance setting. Notably, the inversion can potentially amplify the accumulated error, which could ultimately lead to subpar reconstruction outcomes. To fortify the robustness of the DDIM inversion and to mitigate this issue, we further optimize the null text embedding, as detailed in Mokady et al. [26]. The incorporation of this optimization technique bolsters the effectiveness and reliability of the inversion process, consequently allowing for a more precise reconstruction. Without further notice, the DDIM inversion in this paper is enhanced by null text embedding optimization.
During inference, we utilize the DDIM sampling method with 50 denoising steps and classifier-free guidance of 7.5. The default step for cross-attention map replacement is 20. The default step for self-attention map replacement is 25, while the default step for self-attention feature replacement is 10. Note that the replacement steps may change to some specific checkpoint. As mentioned in Section 4, the target prompt is just source prompt with the object token being replaced with the new concept token. For concept learning, we mainly utilize DreamBooth [35] to finetune a stable diffusion 2.1 to learn the new concept from 3 5 images. The learning rate is set to 1e-6. We use Adawm optimizer with 800 hundred training step. We finetune both the U-net and text encoder. The DreamBooth training takes around 10 minutes on a machine with 8 A100 GPU cards.
5.2 Personalized Subject Swapping Results
Figure 5 showcases the effectiveness of our Photoswap technique for subject swapping. Our approach excels at preserving crucial aspects such as spatial layout, geometry, and the pose of the original subject while seamlessly introducing a reference subject into the target image. Remarkably, even in cartoon images, our method ensures that the background remains intact during the subject change process. A notable example is the "cat" image, where our technique successfully retains all the intricate details from the source image, including the distinctive "Whiskers." This demonstrates our framework’s ability to accurately capture and preserve fine-grained information during subject swapping.


We further demonstrate the versatility of Photoswap by showcasing its effectiveness in multiple subject swap and occluded object swap scenarios. As depicted in Figure LABEL:fig:real_three_faces (a), we present a source image featuring two sunglasses, which are successfully replaced with reference glass while preserving the original layout of the sunglasses. Similarly, in Figure LABEL:fig:real_three_faces (b), we observe a source image with a dog partially occluded by a suit. The resulting swapped dog wears a suit that closely matches the occluded region. These examples serve to highlight the robustness of our proposed Photoswap method in handling various real-world cases, thereby enabling users to explore a broader range of editing possibilities.
5.3 Comparison with Baseline Methods
Personalized object swap is a new task and there is no existing benchmark. However, we could modify the existing attention manipulation based methods. More specifically, we used the same concept learning method DreamBooth to finetune the same stable diffusion checkpoint to inject the new concept. To fairly compare with our results, we modified existing prompt-based editing method P2P [16] , an editing method based diffusion models. Note that origin P2P only works on a pair of synthetic images, in our setting we use same concept learning dreambooth an fix the seed to allow concept swapping. On the other hand, PnP [41] could also be implmented in similar setting, however we found PnP usually can not lead to satisfactory object swapping and may lead to a huge difference between the source image and the generated image. We suspect that it is because PnP is designed for image translation so it does not initiate the attention manipulation step from the beginning step. The qualitative comparision between Photoswap and P2P+dreambooth is shown in Figure 7. We observe that P2P with DreamBooth could achieve achieve basic object swap, but it still suffers from background mismatching issue.

| Photoswap | P2P+DreamBooth | Tie | |
|---|---|---|---|
| Subject Swapping | 46.8% | 25.6% | 27.6% |
| Background Preservation | 40.7% | 32.7% | 26.6% |
| Overall Quality | 50.8% | 28.0% | 21.2% |
Human Evaluation.
We conduct a human evaluation to study the editing quality by (1) Which result better swaps the subject as the reference and keeps its identity; (2) Which result better preserves the background; (3) Which result has better overall subject-driven swapping. We randomly sample 99 examples and adopt Amazon MTurk222Amazon Mechanical Turk (MTurk): https://www.mturk.com. to compare between two results. To avoid potential bias, we hire 3 Turkers for each sample. Table 1 demonstrates the comparison between our Photoswap and P2P. Firstly, more turkers (over 46%) denote that our Photoswap better swaps the subject yet keeps its identity at the same time. Moreover, we can also preserve the background in the source image (41% vs. 33%), which is another crucial goal of this editing. In summary, Photoswap precisely performs subject swapping and preserves the remaining part from the input, leading to an overall superiority (50%) to P2P.
5.4 Controlling Subject Identity
The effectiveness of the proposed mutual self-attention is demonstrated through both synthetic image synthesis and real image editing. Additionally, we perform an analysis of the control strategy with varying values of during the denoising process. Figure 8 provides insights into this analysis. It is observed that when applying self-attention control with a large swapping step for , the synthesized image closely resembles the source image in terms of both style and identity. In this scenario, all contents from the source image are preserved, while the subject style learned from the reference subject is disregarded. As the value of decreases, the synthesized image maintains the subject from the reference image while retaining the layout and pose of the contents from the source image. This gradual transition in the control strategy allows for a balance between subject style transfer and preservation of the original image’s contents.

5.5 Attention Swapping Step Analysis
In this section, we visualize the effect of the influence of swapping steps of different components. As discussed in the main paper, self-attention output , and self-attention map , derived from the self-attention layer, encompasses comprehensive content information from the source image, without relying on direct computation with textual features. Previous works such as Hertz et al. [16] did not explore the usage of and in the object-level image editing process.

Figure 9 provides a visual representation of the effect of incrementally increasing the swapping step for one hyperparameter while maintaining the other two at zero. Although all of them can be utilized for subject swapping, they demonstrate varying levels of layout control. At the same swapping step, the self-attention output offers more robust layout control, facilitating better alignment of gestures and preservation of background context. In contrast, the self-attention map and cross-attention map demonstrate similar capabilities in controlling the layout.
However, extensive swapping can affect the subject’s identity, as the novel concept introduced via the text prompt might be eclipsed by the swapping of the attention output or attention map. This effect becomes particularly evident when swapping the self-attention output. This analysis further informs the determination of the default , , and values. While the cross-attention map facilitates more fine-grained generation control, given its incorporation of information from textual tokens, we discovered that offers stronger holistic generation control, bolstering the overall output’s quality and integrity.
5.6 Results of Other Concept Learning Methods
Our mainly use DreamBooth as the concept learning method in the experiments, primarily due to its superior capabilities in learning subject identities [35]. However, our method is not strictly dependent on any specific concept learning method. In fact, other concept learning methods could be effectively employed to introduce the concept of the target subject.

To illustrate this, we present the results of Photoswap when applying Text Inversion [12]. We train the model using 8 A100 GPUs with a batch size of 4, a learning rate of 5e-4, and set the training steps to 1000. Results in Figure 10 indicate that Text Inversion also proves to be an effective concept learning method, as it successfully captures key features of the target object. Nevertheless, we observe that Text Inversion performance is notably underwhelming when applied to human faces. We postulate that this is because Text Inversion focuses on learning a new embedding for the novel concept, rather than finetuning the entire model. Consequently, the capacity to express the new concept becomes inherently limited, resulting in its less than optimal performance in certain areas.
5.7 Ethics Exploration

Like many AI technologies, text-to-image diffusion models can potentially exhibit biases reflective of those inherent in the training data [37, 31]. Given that these models are trained on vast text and image datasets, they might inadvertently learn and perpetuate biases, such as stereotypes and prejudices, found within this data. For instance, should the training data contain skewed representations or descriptions of specific demographic groups, the model may produce biased images in response to related prompts.
However, Photoswap has been designed to mitigate bias within the generation process of a text-to-image diffusion model. It achieves this by directly substituting the depicted subject with the intended target. In Figure 11, we present our evaluation of face swapping across various skin tones. It is crucial to observe that when there is a significant disparity between the source and reference images, the swapping results tend to homogenize the skin color. As a result, we advocate for the use of Photoswap on subjects of similar racial backgrounds to achieve more satisfactory and authentic outcomes. Despite these potential disparities, the model ensures the preservation of most of the target subject’s specific facial features, reinforcing the credibility and accuracy of the final image.
5.8 Failure Cases

Here we highlight two common failure cases. First, the model struggles to accurately reproduce hands. When the subject includes hands and fingers, the swapping results often fail to precisely mirror the original hand gestures or the number of fingers. This issue could be an inherited challenge from Stable Diffusion. Moreover, Photoswap can encounter difficulties when the image comprises complex information. As illustrated in the lower row of Figure 12, Photoswap fails to reconstruct the complicated formula on a whiteboard. Therefore, while Photoswap exhibits strong performance across various scenarios, it’s crucial to acknowledge these limitations when considering its application in real-world scenarios involving intricate hand gestures or complex abstract information.
6 Conclusion
This paper introduces Photoswap, a novel framework designed for personalized subject swapping in images. To facilitate seamless subject photo swapping, we propose leveraging self-attention control by exchanging intermediate variables within the attention layer between the source image and reference images. Despite its simplicity, our extensive experimentation and evaluations provide compelling evidence for the effectiveness of Photoswap. Our framework offers a robust and intuitive solution for subject swapping, enabling users to effortlessly manipulate images according to their preferences. In the future, we plan to further advance the method to address those common failure issues to enhance the overall performance and versatility of personalized subject swapping.
References
- Blattmann et al. [2022] Blattmann, A., Rombach, R., Oktay, K., Müller, J., and Ommer, B. (2022). Retrieval-Augmented Diffusion Models. In NeurIPS.
- Brock et al. [2018] Brock, A., Donahue, J., and Simonyan, K. (2018). Large scale gan training for high fidelity natural image synthesis. arXiv.
- Cao et al. [2023] Cao, M., Wang, X., Qi, Z., Shan, Y., Qie, X., and Zheng, Y. (2023). Masactrl: Tuning-free mutual self-attention control for consistent image synthesis and editing. arXiv.
- Casanova et al. [2021] Casanova, A., Careil, M., Verbeek, J., Drozdzal, M., and Romero-Soriano, A. (2021). Instance-Conditioned GAN. In NeurIPS.
- Chen et al. [2023] Chen, W., Hu, H., Saharia, C., and Cohen, W. W. (2023). Re-Imagen: Retrieval-Augmented Text-to-Image Generator. In ICLR.
- Couairon et al. [2022] Couairon, G., Verbeek, J., Schwenk, H., and Cord, M. (2022). Diffedit: Diffusion-based semantic image editing with mask guidance. arXiv.
- Crowson et al. [2022] Crowson, K., Biderman, S., Kornis, D., Stander, D., Hallahan, E., Castricato, L., and Raff, E. (2022). Vqgan-clip: Open domain image generation and editing with natural language guidance. In ECCV.
- Deng et al. [2022] Deng, Y., Tang, F., Dong, W., Ma, C., Pan, X., Wang, L., and Xu, C. (2022). Stytr2: Image style transfer with transformers. In CVPR.
- Ding et al. [2021] Ding, M., Yang, Z., Hong, W., Zheng, W., Zhou, C., Yin, D., Lin, J., Zou, X., Shao, Z., Yang, H., et al. (2021). Cogview: Mastering text-to-image generation via transformers. NeurIPS.
- Feng et al. [2023] Feng, W., He, X., Fu, T.-J., Jampani, V., Akula, A., Narayana, P., Basu, S., Wang, X. E., and Wang, W. Y. (2023). Training-Free Structured Diffusion Guidance for Compositional Text-to-Image Synthesis. In ICLR.
- Gal et al. [2022] Gal, R., Alaluf, Y., Atzmon, Y., Patashnik, O., Bermano, A. H., Chechik, G., and Cohen-Or, D. (2022). An image is worth one word: Personalizing text-to-image generation using textual inversion. arXiv.
- Gal et al. [2023a] Gal, R., Alaluf, Y., Atzmon, Y., Patashnik, O., Bermano, A. H., Chechik, G., and Cohen-Or, D. (2023a). An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion. In ICLR.
- Gal et al. [2023b] Gal, R., Arar, M., Atzmon, Y., Bermano, A. H., Chechik, G., and Cohen-Or, D. (2023b). Encoder-based Domain Tuning for Fast Personalization of Text-to-Image Models. In arXiv.
- Goodfellow et al. [2020] Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., and Bengio, Y. (2020). Generative adversarial networks. Communications of the ACM.
- Gu et al. [2022] Gu, S., Chen, D., Bao, J., Wen, F., Zhang, B., Chen, D., Yuan, L., and Guo, B. (2022). Vector quantized diffusion model for text-to-image synthesis. In CVPR.
- Hertz et al. [2022] Hertz, A., Mokady, R., Tenenbaum, J., Aberman, K., Pritch, Y., and Cohen-Or, D. (2022). Prompt-to-prompt image editing with cross attention control. arXiv.
- Huang et al. [2018] Huang, X., Liu, M.-Y., Belongie, S., and Kautz, J. (2018). Multimodal unsupervised image-to-image translation. In ECCV.
- Jahn et al. [2021] Jahn, M., Rombach, R., and Ommer, B. (2021). High-resolution complex scene synthesis with transformers. arXiv.
- Karras et al. [2019] Karras, T., Laine, S., and Aila, T. (2019). A style-based generator architecture for generative adversarial networks. In CVPR.
- Kawar et al. [2022] Kawar, B., Zada, S., Lang, O., Tov, O., Chang, H., Dekel, T., Mosseri, I., and Irani, M. (2022). Imagic: Text-based real image editing with diffusion models. arXiv.
- Kumari et al. [2023] Kumari, N., Zhang, B., Zhang, R., Shechtman, E., and Zhu, J.-Y. (2023). Multi-Concept Customization of Text-to-Image Diffusion. In CVPR.
- Li et al. [2023] Li, Y., Liu, H., Wu, Q., Mu, F., Yang, J., Gao, J., Li, C., and Lee, Y. J. (2023). Gligen: Open-set grounded text-to-image generation. arXiv.
- Liao et al. [2017] Liao, J., Yao, Y., Yuan, L., Hua, G., and Kang, S. B. (2017). Visual atribute transfer through deep image analogy. ACM Transactions on Graphics.
- Liu et al. [2021] Liu, S., Lin, T., He, D., Li, F., Wang, M., Li, X., Sun, Z., Li, Q., and Ding, E. (2021). Adaattn: Revisit attention mechanism in arbitrary neural style transfer. In ICCV.
- Meng et al. [2021] Meng, C., Song, Y., Song, J., Wu, J., Zhu, J.-Y., and Ermon, S. (2021). Sdedit: Image synthesis and editing with stochastic differential equations. arXiv.
- Mokady et al. [2022] Mokady, R., Hertz, A., Aberman, K., Pritch, Y., and Cohen-Or, D. (2022). Null-text Inversion for Editing Real Images using Guided Diffusion Models. In arXiv.
- Nichol et al. [2021] Nichol, A., Dhariwal, P., Ramesh, A., Shyam, P., Mishkin, P., McGrew, B., Sutskever, I., and Chen, M. (2021). Glide: Towards photorealistic image generation and editing with text-guided diffusion models. arXiv.
- Nitzan et al. [2022] Nitzan, Y., Aberman, K., He, Q., Liba, O., Yarom, M., Gandelsman, Y., Mosseri, I., Pritch, Y., and Cohen-or, D. (2022). MyStyle: A Personalized Generative Prior. In Special Interest Group on Computer Graphics and Interactive Techniques in Asia (SIGGRAPH Asia).
- OpenAI [2021] OpenAI (2021). DALL·E: Creating images from text. https://openai.com/research/dall-e.
- OpenAI [2022] OpenAI (2022). DALL·E2. https://openai.com/product/dall-e-2.
- Perera and Patel [2023] Perera, M. V. and Patel, V. M. (2023). Analyzing bias in diffusion-based face generation models. arXiv preprint arXiv:2305.06402.
- Radford et al. [2021] Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al. (2021). Learning transferable visual models from natural language supervision. In ICML.
- Rombach et al. [2022] Rombach, R., Blattmann, A., Lorenz, D., Esser, P., and Ommer, B. (2022). High-resolution image synthesis with latent diffusion models. In CVPR.
- Ronneberger et al. [2015] Ronneberger, O., Fischer, P., and Brox, T. (2015). U-net: Convolutional networks for biomedical image segmentation. In MICCAI. Springer.
- Ruiz et al. [2023] Ruiz, N., Li, Y., Jampani, V., Pritch, Y., Rubinstein, M., and Aberman, K. (2023). DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation. In CVPR.
- Saharia et al. [2022] Saharia, C., Chan, W., Saxena, S., Li, L., Whang, J., Denton, E. L., Ghasemipour, K., Gontijo Lopes, R., Karagol Ayan, B., Salimans, T., et al. (2022). Photorealistic text-to-image diffusion models with deep language understanding. In NeurIPS.
- Sasha Luccioni et al. [2023] Sasha Luccioni, A., Akiki, C., Mitchell, M., and Jernite, Y. (2023). Stable bias: Analyzing societal representations in diffusion models. arXiv e-prints, pages arXiv–2303.
- Seo et al. [2022] Seo, J., Lee, G., Cho, S., Lee, J., and Kim, S. (2022). Midms: Matching interleaved diffusion models for exemplar-based image translation. arXiv.
- Sheynin et al. [2023] Sheynin, S., Ashual, O., Polyak, A., Singer, U., Gafni, O., Nachmani, E., and Taigman, Y. (2023). KNN-Diffusion: Image Generation via Large-Scale Retrieval. In ICLR.
- Song et al. [2020] Song, J., Meng, C., and Ermon, S. (2020). Denoising diffusion implicit models. In International Conference on Learning Representations.
- Tumanyan et al. [2022] Tumanyan, N., Geyer, M., Bagon, S., and Dekel, T. (2022). Plug-and-play diffusion features for text-driven image-to-image translation. arXiv.
- Wang et al. [2019] Wang, M., Yang, G.-Y., Li, R., Liang, R.-Z., Zhang, S.-H., Hall, P. M., and Hu, S.-M. (2019). Example-guided style-consistent image synthesis from semantic labeling. In CVPR.
- Yang et al. [2022a] Yang, B., Gu, S., Zhang, B., Zhang, T., Chen, X., Sun, X., Chen, D., and Wen, F. (2022a). Paint by example: Exemplar-based image editing with diffusion models. arXiv.
- Yang et al. [2022b] Yang, Z., Wang, J., Gan, Z., Li, L., Lin, K., Wu, C., Duan, N., Liu, Z., Liu, C., Zeng, M., et al. (2022b). Reco: Region-controlled text-to-image generation. arXiv.
- Zeng et al. [2022] Zeng, Y., Lin, Z., Zhang, J., Liu, Q., Collomosse, J., Kuen, J., and Patel, V. M. (2022). Scenecomposer: Any-level semantic image synthesis. arXiv.
- Zhang and Agrawala [2023] Zhang, L. and Agrawala, M. (2023). Adding conditional control to text-to-image diffusion models. arXiv.
- Zhang et al. [2020] Zhang, P., Zhang, B., Chen, D., Yuan, L., and Wen, F. (2020). Cross-domain correspondence learning for exemplar-based image translation. In CVPR, pages 5143–5153.
- Zhang et al. [2022] Zhang, Y., Huang, N., Tang, F., Huang, H., Ma, C., Dong, W., and Xu, C. (2022). Inversion-based creativity transfer with diffusion models. arXiv.
- Zhou et al. [2021] Zhou, X., Zhang, B., Zhang, T., Zhang, P., Bao, J., Chen, D., Zhang, Z., and Wen, F. (2021). Cocosnet v2: Full-resolution correspondence learning for image translation. In CVPR.