Encoding trade-offs and design toolkits in quantum algorithms for discrete optimization: coloring, routing, scheduling, and other problems
Abstract
Challenging combinatorial optimization problems are ubiquitous in science and engineering. Several quantum methods for optimization have recently been developed, in different settings including both exact and approximate solvers. Addressing this field of research, this manuscript has three distinct purposes. First, we present an intuitive method for synthesizing and analyzing discrete (i.e., integer-based) optimization problems, wherein the problem and corresponding algorithmic primitives are expressed using a discrete quantum intermediate representation (DQIR) that is encoding-independent. This compact representation often allows for more efficient problem compilation, automated analyses of different encoding choices, easier interpretability, more complex runtime procedures, and richer programmability, as compared to previous approaches, which we demonstrate with a number of examples. Second, we perform numerical studies comparing several qubit encodings; the results exhibit a number of preliminary trends that help guide the choice of encoding for a particular set of hardware and a particular problem and algorithm. Our study includes problems related to graph coloring, the traveling salesperson problem, factory/machine scheduling, financial portfolio rebalancing, and integer linear programming. Third, we design low-depth graph-derived partial mixers (GDPMs) up to 16-level quantum variables, demonstrating that compact (binary) encodings are more amenable to QAOA than previously understood. We expect this toolkit of programming abstractions and low-level building blocks to aid in designing quantum algorithms for discrete combinatorial problems.
1 Introduction
Combinatorial optimization problems are ubiquitous across science, engineering, and operations research, encompassing diverse problem areas such as scheduling, routing, and network analysis, among others [1]. This has led to much interest in the potential for quantum advantage for hard optimization tasks, in different settings including exact, approximate, and heuristic solvers [2, 3, 4, 5, 6, 7, 8]. The past few years in particular have seen development of novel quantum approaches for tackling these problems, with much focus on constraint satisfaction problems over binary variables, such as the commonly studied MaxCut problem [4]. However, from the application perspective, a wide variety of important optimization problems are more naturally expressed over sets of discrete (typically integer) variables. This can add an additional layer of complexity when applying and implementing existing quantum algorithms, partly because there are many ways to encode a discrete variable into qubits, qudits, or other hardware, with different resource and performance tradeoffs.
Indeed, as a practitioner may have many algorithmic choices—regarding for instance the encoding, algorithm class, and parameters—it is vital to develop conceptual tools and software approaches that help prepare and implement algorithms for discrete optimization problems on quantum computers. Such tools can be useful for automating analyses of different approaches (such as different encodings), but they can also lead to superior programmability, which in turn may yield more efficient compilation and runtime implementations. In particular, seeking cleaner separations of programming layers is important towards enabling a broad community of practitioners who may not be experts in quantum mechanics or other low-level details [9, 10, 11].
Regarding encoding choice, we note that one may encode a variable into qubits in many different ways, each of which may have favorable properties for different hardware. For example, one encoding may be advantageous for a many-qubit device with lower available circuit depth, while another may be preferable for a device with more available depth but fewer qubits (see Figure 1). Therefore it is useful to have a framework that can be used to automate the mapping, compilation, and analysis of a given encoding choice.
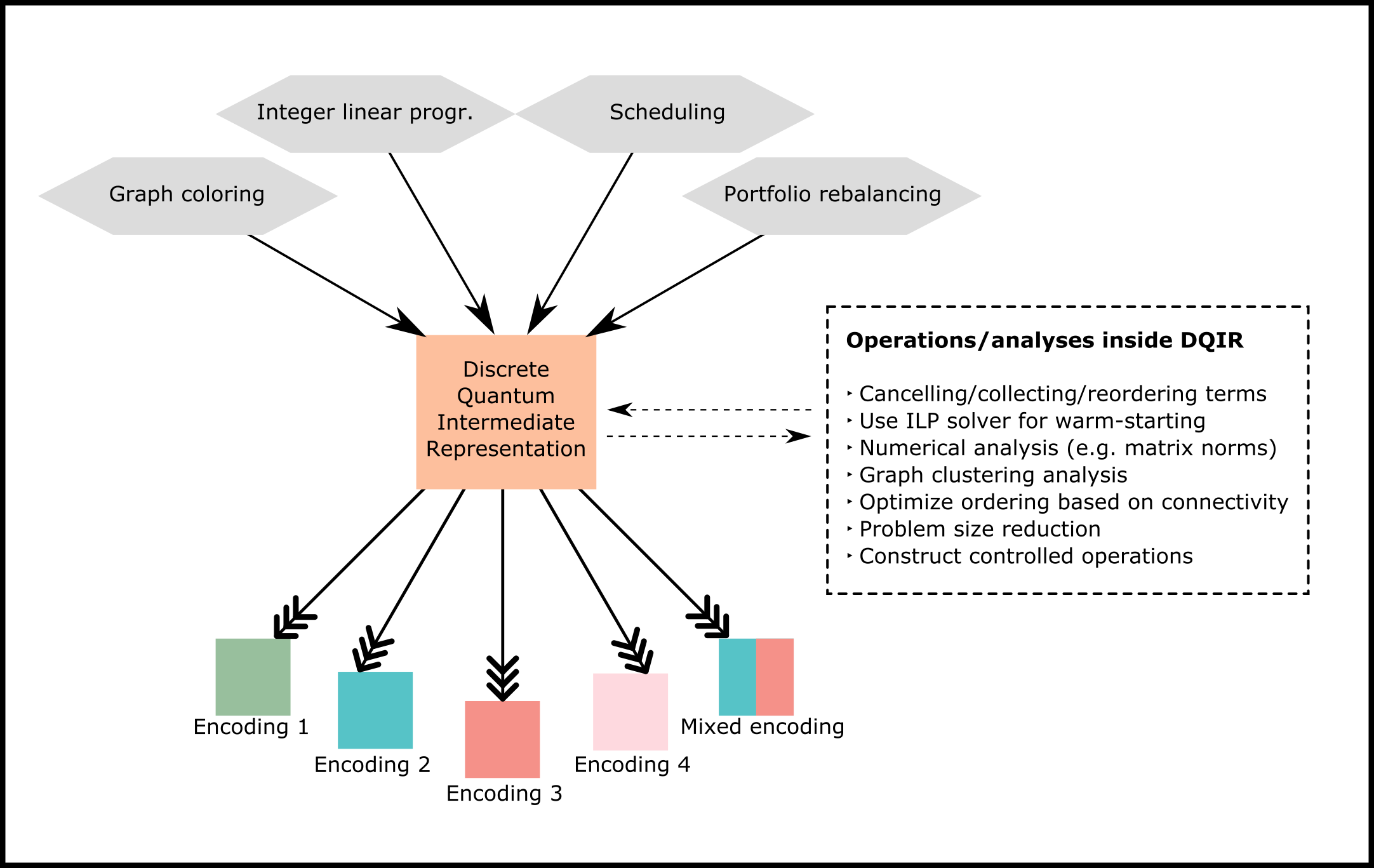
In the current work we (a) introduce an intuitive and efficient framework (an intermediate representation) for constructing and implementing quantum algorithms for discrete optimization problems, including generalizing a number of existing results from the Boolean cube to more general discrete domains; (b) provide a pedagogical resource including an informal dictionary of useful primitives and relations in this general setting; (c) numerically analyze which encodings are advantageous in which scenarios; and (d) present what are to our knowledge the first ultra-low-depth designs of QAOA mixers for standard binary and Gray encodings of integer variables. We will demonstrate how our framework provides a compact and practically useful representation of these problems. Figure 2 gives a schematic of the workflow of our discrete quantum intermediate representation (DQIR). DQIR is useful for preparing, manipulating, and analyzing problem instances independently of hardware implementations, while also automating the conversion to and analysis of encodings for the purpose of choosing the most advantageous one (e.g., given the resource constraints of a fixed real-world device).
Our work builds off of and extends a number of previous works. In particular, [12] which studied encoding procedures and pitfalls as well as compilation tradeoffs for -level systems in the context of quantum simulation, [13] which formally defined basic primitives and Hamiltonian mappings for the binary optimization case, [7] that studied the design of quantum approaches for discrete optimization, including the one-hot and standard binary mappings for a diverse set of standard problems. While intermediate representations have been introduced for many aspects of quantum compilation [14, 15, 16, 9, 17, 10], DQIR is intended for use specifically for problems defined over a domain of discrete variables. Here we attempt to unify and extend these viewpoints into a more general but more user-friendly framework. We then demonstrate how DQIR facilitates more efficient compilation and analysis over previous approaches. Some of the constructions and encodings presented are novel in the context of quantum optimization. A further contribution is the comparison of circuit depths for several encodings over a range of standard problems and subroutines for commonly occurring domains. To our knowledge such a systematic numerical analysis has not been published previously, and we anticipate the results to be directly useful to practitioners in the field.
It is useful to note some technical differences between physics simulation of -level particles [12, 18] (phonons [19, 20, 21, 22], photons [23], spin- particles [24], etc.) and discrete combinatorial problems. In physics simulations the Hamiltonian itself usually contains non-diagonal operators relative to the computational basis, for example bosonic creation and annihilation operators. These non-diagonal operators often make the largest contribution to resource requirements [12]. On the other hand, for classical combinatorial problems the cost function is typically mapped to a diagonal operator, and there is often significant flexibility in choosing non-diagonal operators suitable for realizing a given quantum algorithm. This flexibility makes it easier to reduce the resource requirements in the optimization setting. On a related one, the measurement problem [25, 26, 27, 28]—namely, that many measurements in many different bases are required to determine in physics simulation—is not nearly as much of a bottleneck in classical optimization problems for which the cost function is a diagonal operator
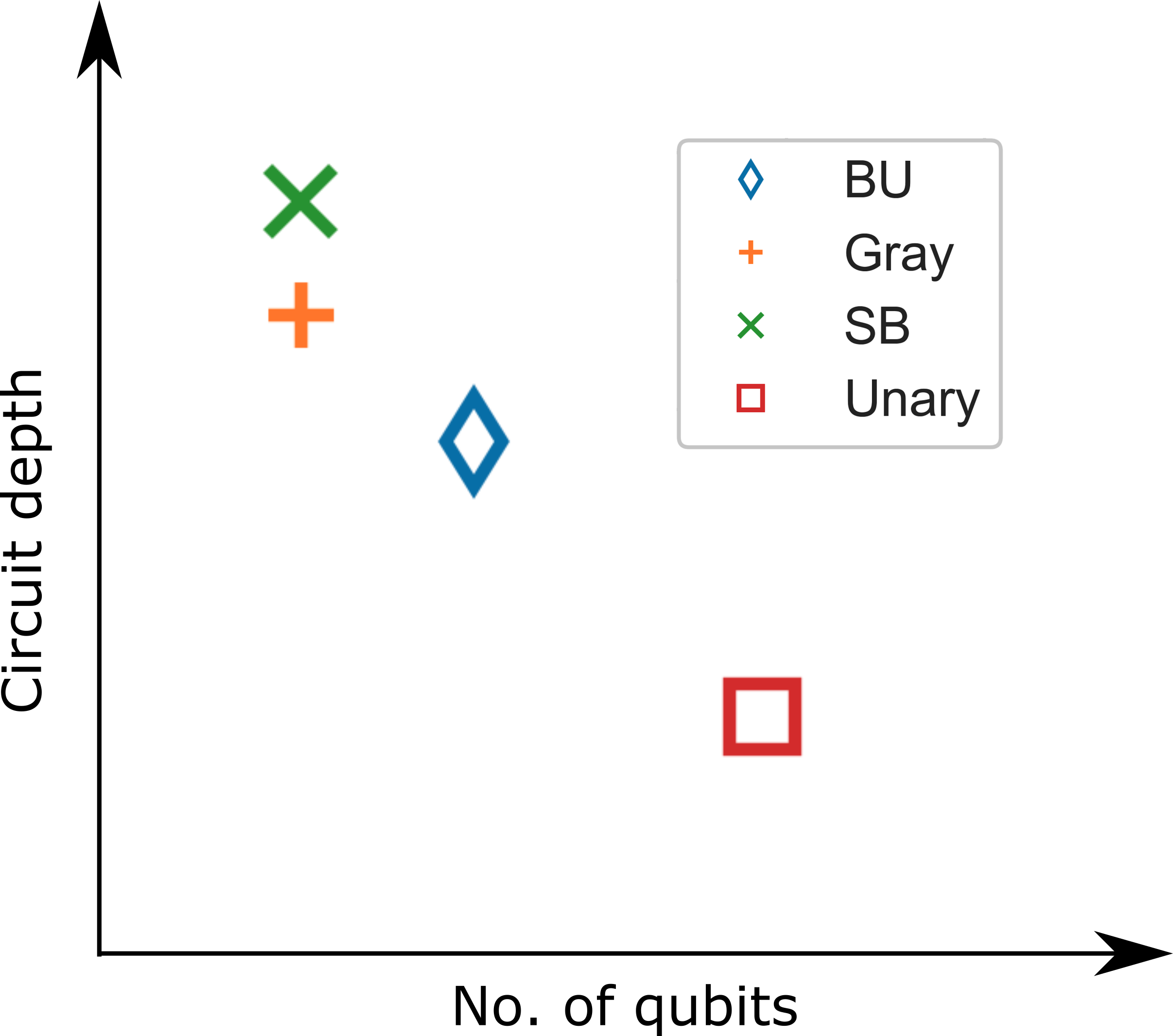
There have been numerous studies on quantum approaches for particular discrete optimization problems [29, 7], including for problems related to graph coloring [30, 31, 32, 33], planning [34, 35, 36], scheduling [37, 38, 39, 40, 41, 42, 43], routing [44, 45], integer programming [46], and option pricing [47, 48]. Though most of these works employ either a unary-style or more compact binary-style qubit encoding of the problem variables, some have considered multiple encodings in the same work [7, 32, 44, 49, 50]. Unlike most previous studies, our representation and methods are presented at a higher layer that is encoding-independent; therefore, one can in principle reuse mappings and primitives across different quantum hardware where different encodings or algorithms may be most suitable, as well as in some cases across different problems. Indeed, a further advantage is that the lower layers are not restricted to be physical-qubit-based, and DQIR can easily envelop qudits (i.e., -level quantum system, where may be not necessarily match the problem domain size), quantum fault-tolerance (i.e., encoded logical qubits), as well as continuous variable quantum computers or other more exotic proposals.
Critically, despite considerable effort it remains unclear exactly under which circumstances or for which problems or to what degree one may possibly achieve quantum advantage for combinatorial optimization, in the near-term and beyond [51, 52, 7, 53, 54, 55, 56, 57, 58, 59, 60]. We do not try to tackle the challenging questions related to performance in this work, and focus instead on mathematical tools that may be practically useful toward algorithm design and implementation, especially as more sophisticated and diverse quantum hardware platforms become available in the coming years.
This paper is organized as follows. In Section 2 we define the primitives of the discrete quantum intermediate representation, discuss encodings and important subroutines, and summarize procedures for mapping the problem to hardware-specific (especially qubit-based) representations. In Section 3 we overview several standard quantum approaches to optimization and consider their various required components, including mixers, penalties, and choice of initial state, while discussing best practices in each aspect. In Section 4 we introduce the novel concept of graph-derived partial mixers (GDPMs) in order to design specific resource-friendly mixers applicable to various problem classes. In Section 5 we express five general classes of discrete optimization problem in terms of DQIR, highlighting the compactness and intuitiveness of the resulting expressions. In Section 6 we then present numerical results for some of these problems for implementing several common operators derived in multiple encodings, and discuss the various resulting resource trade-offs. Finally, in section 7 we elaborate on the utility of our approach and discuss several future directions such as the incorporation of noise and hardware topology into our framework.
2 Discrete quantum intermediate representation
Here we formally introduce DQIR for quantum optimization algorithms, and beyond. There are several appealing reasons to use a DQIR in a compilation workflow. First, it provides a path to automated methods for encoding a range of problem types into any user-defined encoding. Instead of deriving conversions to qubit operators for each new encoding, as has been done in most previous work, one may implement any new encoding simply by defining a new integer-to-bit function. Second, a hardware-agnostic representation helps facilitate the interfacing with new devices, for example hardware with a novel topology or non-standard devices that use qutrits, ququads, or higher-order qudits [61, 62]. Third, it can be more efficient to perform algebraic manipulations inside DQIR, because often the resulting terms are simpler and fewer. Finally, several problem analyses and preparation steps are more conceptually natural and can be calculated with fewer operations in DQIR, as we demonstrate with the examples considered in Section 5.
2.1 Discrete functions and optimization problems
We consider real-valued functions
| (1) |
where we sometimes use to denote the special case of functions taking values in , over a domain of discrete variables, ,
| (2) |
Such domains are isomorphic as sets to subsets of integers
| (3) |
so for simplicity we will assume integer variable domains for most of this work. Note that the domain cardinalities are often (but not always) independent of the number of problem variables; the familiar setting of combinatorial optimization over binary variables corresponds to the case . Similarly, the important special case of Boolean functions corresponds to the case .
Problem cost functions and constrained optimization.
For a combinatorial optimization problem, we are typically given some representation of a function we seek to extremize as part of the problem input. For example, we may be given a set of clauses, functions each acting on a subset of the variables, from which is constructed using a suitable operation on the target space, such as in a constraint satisfaction problem, or for (Boolean) satisfiability. Generally we say a family of functions in a given representation is efficiently represented (as input) if it uses a number of variables that is polynomially scaling in the number of bits required to describe elements of the domain (in which case the usual notions of algorithmic efficiency apply).
Additionally, may be subject to a set of hard constraints, such as equality constraints
| (4) |
and/or inequality constraints
| (5) |
which must be satisfied by any potential solution. Hard constraints such as (4) and (5) hence induce a feasible subspace of the original domain (and corresponding Hilbert space),
| (6) |
which may depend on the particular problem instance. Generally, hard constraints may be given as part of the problem input, or may additionally arise as various problem encoding choices are made. Note that while in principle hard constraints may be absorbed into a (possibly complicated) redefinition of the underlying domain of , it is often advantageous to define simpler domains that do not depend on the particular instance and treat hard constraints via algorithmic primitives such as penalty terms or constraint-preserving mixers, as we discuss in Section 3.
For the optimization setting our goal is to minimize over the feasible subspace, i.e. subject to the hard constraints. (The maximization case is similar.) For a variety of important applications, in particular NP-hard optimization problems, it is believed that neither classical nor quantum computers can efficiently solve these problems optimally, for arbitrary problem instances. In such cases we may employ algorithms with super-polynomially scaling resources, or settle for efficiently obtained approximate solutions, where the goal is to find a configuration with function value as low as possible. For the latter, we may employ approximation algorithms, where a guarantee to achieved solution quality is known, or heuristics, where such a guarantee may not be; see for example [63] for a more detailed discussion of quantum heuristics for approximate optimization.
We highlight here one important example problem class. A variety of industrially important problems are expressible as what we call permutation problems, for which we seek to optimize a function over possible permutations , which we represent with strings of integers as
| (7) |
We define the space of permutations as
| (8) |
where is the permutation group on objects. In this example, infeasible strings are those in which any integer appears twice. (For our purposes it is not necessary to consider the many forms of constraint that might be used to induce this feasible subspace of permutations.) A subset of the problems considered in this work are permutation problems, namely scheduling and routing problems, which may come with additional feasibility constraints in practice.
Hamiltonians representing functions.
Following [13] we say a Hamiltonian represents a real function on if it acts diagonally
| (9) |
for every basis state , . Here we have assumed is defined over all of ; for cost functions it often suffices to consider (9) enforced over the feasible subspace.
We next give a number of basic primitives from which Hamiltonians may be constructed, as well as more general operators needed for quantum optimization algorithms.
2.2 Primitives and subroutines
Here we develop an intermediate representation that is particularly useful when mapping classical discrete optimization problems into quantum algorithms. The representation is based on a small number of fundamental primitives, to which any classical function on or transformation of discrete variables may be mapped. If the user desires, some analysis of the problem and algorithm may then be performed at this intermediate level, before a particular qubit-based (or other) encoding is implemented in an automated way. This means one does not need to consider the particular encoding or hardware details until after the “quantization” of the combinatorial problem, and constructions may in principle be easily transferred across different encodings and devices. We call this construction the Discrete Quantum Intermediate Representation (DQIR). DQIR then easily facilitates implementation of a wide variety of quantum algorithms such as the quantum approximate optimization algorithm and its generalization to the quantum alternating operator ansätze (QAOA) [4, 7], quantum annealing [6], variational approaches [64], and quantum imaginary time evolution (QITE) [65, 66], as well as the novel algorithms of tomorrow. For the reader’s benefit we briefly review some of these approaches in Sec. 3.1.
We begin by considering a single discrete variable. In our formalism, the values of a classical discrete variable are mapped one-to-one to the levels (labeled with integers of a quantum discrete variable (or quantum variable) that can be abstractly conceptualized as a qudit [7, 12]. Throughout this paper, we label discrete variables with a Greek letter and their values with Latin letters. As an example, in a graph coloring problem, each node is mapped to its own quantum variable while the discrete color value corresponds to a level in the quantum variable. Though this work focuses on discrete variables with , we emphasize that binary variables and problems are also subsumed by this framework.
Diagonal primitives.
For a single discrete variable , the simple projector onto the discrete value that corresponds to level is
| (10) |
which we call the indicator primitive because it represents the function that is if and only if variable is assigned .
For general single-variable functions we then define the value primitive
| (11) |
which diagonally applies an arbitrary scalar value to each level .
We emphasize that although is constructed using and the set of all is contained in the set of all , it is useful to think of both as primitives. This is because is used as a marker to ensure that a variable is in a particular state, whereas may be used as a drop-in replacement for a classical variable or function.
Often simply returns the integer label , an important case that we appropriately call the number operator and denote
| (12) |
which appears in the special case where the labels denote occupation number as in quantum physical systems [12]. Other functions are similarly defined through the coefficients .
The indicator and value primitives over different variables may be combined through linear combinations to represent any classical Boolean-valued, discrete-valued, or real-valued function. Properties of functions on binary variables are studied in [13], many of which immediately generalize to the case of integer domains; see for instance [67, Ch. 8] for additional details.
Multi-variate functions and examples.
DQIR builds all multivariate logic from single variable primitives. We introduce Greek subscripts to label each quantum variable. Any multivariate operator may then be expressed as a sum of tensor products of local operators,
| (13) |
where is a single-variable primitive, which includes both the diagonal case as well as operators built from the more general primitives we consider below. Note that the non-diagonal primitives and operators we consider do not in general satisfy .
For the diagonal case, any function may be expressed as a weighted sum of Boolean-valued functions, which is a common form of problem cost functions, and so it is especially useful to be able to build up Hamiltonians representing complicated functions from simpler Boolean projectors. It is further useful to be able to compose them through standard logical operators in order to represent more complication Boolean formulas or circuits. The following expressions relating Boolean logic on binary functions and variables [7] to their resulting Hamiltonian representations directly extend to our more general discrete variable setting:
| (14) | ||||
| (15) | ||||
| (16) | ||||
| (17) | ||||
where are arbitrary -valued functions on and . A particular useful property we employ below is that is identically zero when are on disjoint sets. Here functions acting on fewer than all variables are trivially extended to all of . The logical rules of (14) apply to the diagonal primitives above and easily generalize to higher-order multivariate expressions through composition. Cost functions are often expressed as sums of Boolean clauses, for example in constraint satisfaction problems, which can then be directly mapped to a cost Hamiltonian via the linearity property of (14). One may similarly consider the case of complex coefficients , , though the corresponding operator may no longer be Hermitian; for example, one may decompose a unitary operator this way.
Next we make use of (14) to write down Hamiltonians corresponding to some prototypical multivariate functions. A first important example is the equality operator
| (18) |
which vanishes when the values on variables and are unequal, else returns (i.e. acts as the identity) when they are the same. The case where variables take values in different domains is easily handled by considering only their pairwise intersections in (18). The not equal operator is then defined as . An example of a function with an arbitrary number of variables is the all equal function over variables,
| (19) |
The all different function (see, e.g. [68]) on integer variables can be expressed as
| (20) |
A simple example of an integer-valued function is the count non-zero function
| (21) |
Another example, given a graph with variables as nodes, is the pairwise different function
| (22) |
which for a node coloring counts the number of cut (differently colored) edges in .
Clearly a wide variety of cost functions or constraints can be represented as quantum operators in this way; we explore some concrete application examples in Sec. 5.
Non-diagonal primitives.
Naturally, in addition to classical functions, we also need to represent non-diagonal operators that facilitate shifting probability amplitude between different computational basis states. Thus we next introduce two additional classes of single-variable primitive.
We first define the one- and two-way
| (23) |
| (24) |
These operators are useful for instance in designing mixers for QAOA. We deliberately do not restrict (23) to be Hermitian, in order to allow DQIR to represent general non-Hermitian operators that appear for instance in the analysis or implementation of algorithms such as QITE. However, in the most common use cases transfer primitives will appear as .
The final single-variable primitive is the general local operator
| (25) |
which generalizes the three previous primitives. Formula (13) may then be used to express any multivariate operator in terms of the single-variable primitives.
The four single-variable primitives are the most essential concepts of the DQIR workflow and result in a convenient unified quantum representation for any classical function on discrete variables and any transformations between classical states. Additionally, we emphasize that DQIR objects may be constructed and manipulated independently of qubit encoding choice or other lower-level concerns, and one may perform symbolic algebraic manipulations and analyses within DQIR. In the remainder of this subsection we demonstrate explicit constructions of several important classes of functions and operators.
Single-variable reversible functions.
Logically reversible functions are the essential building blocks of both classical reversible and quantum computing. For a binary-valued variable the only non-identity bijective (i.e., one-to-one and onto) function is , which in qubit space can be implemented with the quantum gate , and can be undone reapplying the same transformation. Here we generalize the quantum implementation of such single-variable reversible discrete functions for with . A bijective function on integers is just a permutation of elements, . Any permutation on elements is representable as a unitary . We write
| (26) |
with Hermitian , as any unitary matrix may be expressed as the exponential of a Hermitian. may be represented in DQIR with the help of transfer primitives.
Note that it may often be useful (for example when is not known or its exponential is resource-intensive) to consider a decomposition into simpler permutations such that , where the exact implementation of each is known. For example, considering that any permutation may be constructed from pairwise exchanges, one may implement via individual transfer primitives:
| (27) |
where and I is the identity operator.
Controlled instructions.
DQIR may be used to facilitate controlled quantum instructions as well, where a unitary is applied conditioned on the variable being set to value ,
| (28) |
This includes the case where (and hence ) are parameterized unitaries. If the target unitary can be expressed as then the operation
| (29) |
produces the desired controlled operation, conditional on variable being in state .
Using the observation that any Hamiltonian representing a -valued Boolean function gives a projector [13], we generalize the control part of equation (29) from the indicator primitive to any multivariate Boolean-valued function on discrete variables,
| (30) |
where and act nontrivially on distinct sets of qubits, and acts as when the function is satisfied by the control register variables, else as the identity.
For multiqubit operators, the control function typically considered is the AND operation over a subset of variables (or their negations), as for example in multiqubit Toffoli gates [69]. The generalization to arbitrary functions on Boolean domains is considered in [13]. Our case of -ary domains is much more rich, with a much larger set of possible single- and multi-variable Boolean expressions, for example, controlling on multiple states for each variable. Applying the rules of (14) it is relatively straightforward to construct controlled operators for a wide variety of commonly encountered conditional expressions. Moreover, unitaries corresponding to different controlled functions can be applied in sequence to generate multi-case controlled operators.
Computing functions into registers.
Similarly, directly computing functions into registers is possible with operators constructed using DQIR representations, an important special case of multi-controlled instructions. For a Boolean-valued function , we may compute its value in an additional qubit register as
| (31) |
by applying the exponential
| (32) |
where is the Pauli operator and denotes addition modulo 2.
Here we show how to generalize this approach to computing powers of arbitrary bijective discrete functions . We wish to implement conditional on the result of an integer-valued function where . The operator of interest is
| (33) |
where signifies repetitions of the bijective function . If is a binary-valued function, then its output determines whether to perform the permutation or not. If is an integer-valued function then the permutation may be applied multiple times. Notably, the set of operations (33) contains the subclass
| (34) |
for arbitrary integer , which we highlight because of its potential use for integer arithmetic.
We emphasize that permutations are fundamental objects in reversible computation [70, 71] and hence (33) facilitates implementation of broad classes of functions. In particular arbitrary functions may be extended to reversible versions through the inclusion of ancillary variables [71].
| Base ten | SB | Gray | Unary | DW | BU |
|---|---|---|---|---|---|
| 0 | 0000 | 0000 | 000000001 | 00000000 | 00 00 00 01 |
| 1 | 0001 | 0001 | 000000010 | 00000001 | 00 00 00 11 |
| 2 | 0010 | 0011 | 000000100 | 00000011 | 00 00 00 10 |
| 3 | 0011 | 0010 | 000001000 | 00000111 | 00 00 01 00 |
| 4 | 0100 | 0110 | 000010000 | 00001111 | 00 00 11 00 |
| 5 | 0101 | 0111 | 000100000 | 00011111 | 00 00 10 00 |
| 6 | 0110 | 0101 | 001000000 | 00111111 | 00 01 00 00 |
| 7 | 0111 | 0100 | 010000000 | 01111111 | 00 11 00 00 |
| 8 | 1000 | 1100 | 100000000 | 11111111 | 00 10 00 00 |
2.3 Actions within DQIR
A primary advantage of DQIR is that it unifies the diverse landscapes of discrete problems and quantum algorithms under one operator representation, facilitating the design and deployment of automated tools that can be applied to suitably prepare arbitrary discrete problems for a quantum computer. Some such automated tools and actions are listed in Figure 2.
One purpose of an intermediate representation is to enable subroutines and analyses that are independent of the broader problem or algorithm type. At the simplest level, DQIR is useful as a way to cancel, collect, combine, and reorder terms in operators before one implements a qubit, or other, encoding. Because the terms are often fewer and simpler in DQIR than in subsequent lower-level representations, this will often reduce the complexity of the resulting algebra that needs to be performed (e.g. compared to Pauli expression manipulation). Working at the DQIR level can also avoid redundant work when analyzing across multiple encodings.
Higher-level analyses may be performed in DQIR as well. For instance, once a Hamiltonian is constructed in DQIR one may directly estimate its norm or other quantities of interest, as this may guide the choice of parameters such as time step size used in a quantum algorithm, or even guide the choice of algorithm itself. Analyzing the connectivity of the discrete variables, i.e. considering the underlying graph properties of the problem, may be very useful at this level as well. For a given hardware choice, one may reorder the quantum variables within DQIR, for example using a clustering algorithm, as to ensure that minimal non-native interactions are needed in the quantum device. In some cases one may choose to reduce the size of the problem by solving only highly connected variables on the quantum computer [72, 73].
2.4 Lowering DQIR into hardware-relevant representations
While for simplicity we focus here on qubit-based digital hardware with all-to-all connectivity, it is straightforward to incorporate alternative or additional encoding layers into DQIR, including mappings that account for hardware topology limitations, as well as noise via the broad field of quantum fault tolerance. Similarly, one may consider qudit-based hardware, including the general case where the dit and variable dimension don’t necessarily match.
Mapping to qudits.
Here the general goal is to convert DQIR to a multi-qudit representation where variables are encoded with one or more qudits via an embedding
| (35) |
In general the sizes of the variable domains may not be equal to the sizes of the encoded multi-qudit space; indeed the original domain is often strictly smaller than the embedded space. Such a dimension mismatch allows for one-to-many mappings, or requires that some states in the encoding domain be unused. We call an encoded computational basis state valid if it corresponds to a state in the original domain. For example when a variable with values is mapped to qubits using the standard binary encoding, is a valid state while is an invalid state. Valid states may or may not be feasible depending the particular problem at hand. For instance, consider the traveling salesperson problem encoded as a permutation problem (see equation (7)) on three cities using the standard binary encoding, such that the cities are labeled as . We refer to a six-qubit state such as () as valid but infeasible, because though it has a corresponding value in the original space (validity), it does not represent a permutation. Note that for unconstrained problems we may use the terms feasible or valid interchangeably.
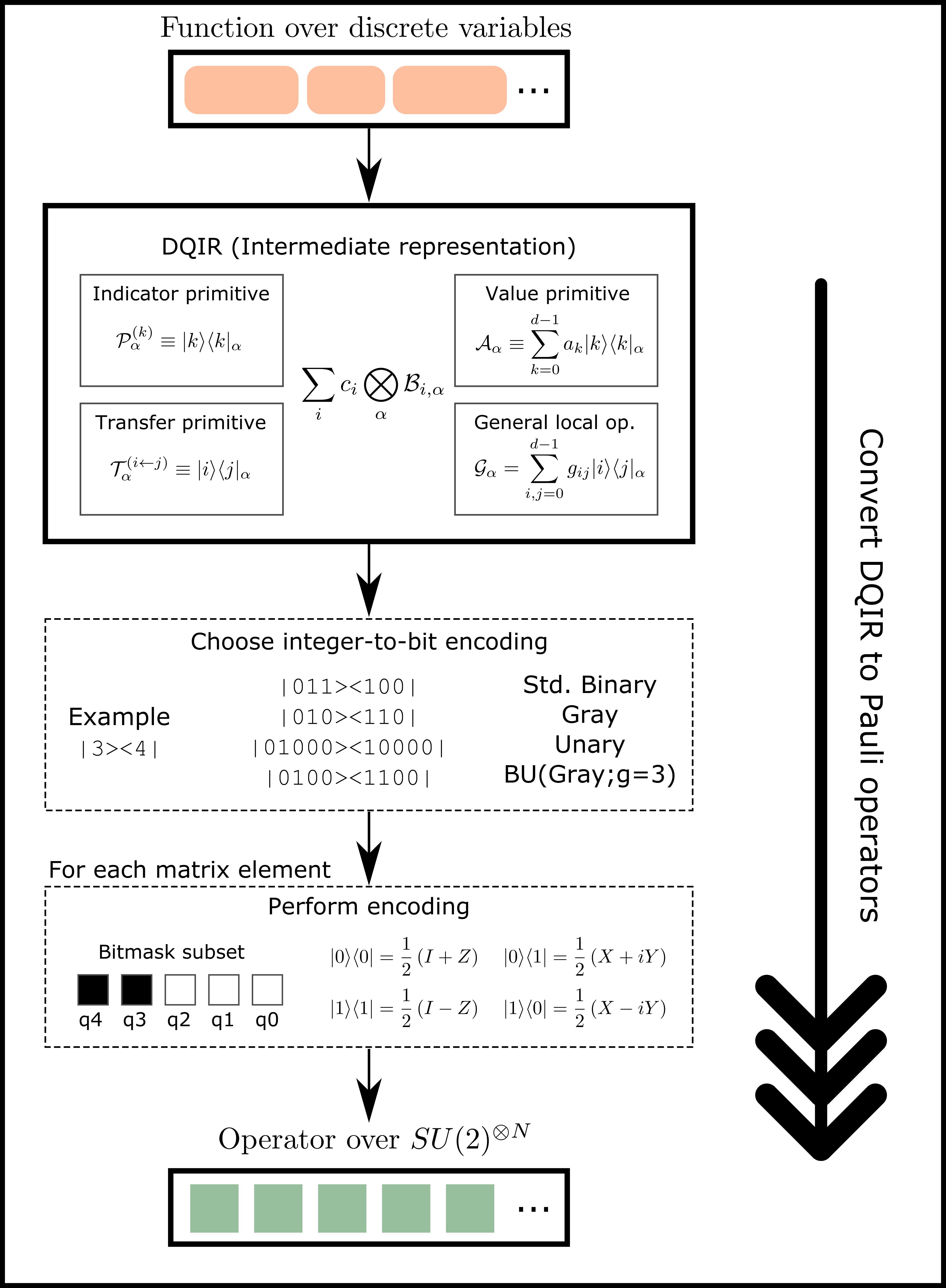
Mapping to qubits.
In the remainder of this work we focus on the important special case of independently mapping each single discrete variable to qubits
| (36) |
where for simplicity we will further assume that the mapping is injective (i.e., not one-to-many, which would be the case for example if each element were mapped to a larger subspace). We note however that a one-to-many mapping is possible as well and has been proposed in the context of QAOA for Max--Cut [33]. We will consider a number of explicit examples of such qubit mappings, see Table 1. The encoding (36) of states also induces a mapping of DQIR primitives and expressions to qubit operators. Operators on qubits are commonly expressed as sums of products of Pauli operators and critically depend on the particular encoding scheme selected. Much of the following procedure has been given in a pedagogical way in previous work [12] but here we give an overview, shown schematically in Figure 3. While here we focus on mapping to logical (encoded) qubits, DQIR may be easily incorporated into quantum error correction schemes [74] to derive operators at the physical qubit (or qudit) level.
We will consider several common qubit encodings drawn from the literature, summarized in Table 1. While some encodings require significantly more space (qubits) than others, on the other hand, within a given encoding and gate set a given operator may be much easier to implement than in another. For a given algorithm the choice of encoding presents immediate trade-offs between qubit count and circuit depth, as well as other measures or circuit complexity, though it is not clear generally how such resource trade-offs ultimately relate algorithm to performance, which is a rich but complicated topic beyond the scope of this work.
Furthermore, it may sometimes be desirable to employ different encodings for different variables, a general strategy we call mixed encoding. First, for heterogeneous problem domains with differing , different encodings may be optimal (in terms of circuit depth) for different variables, as will be demonstrated in Section 6. Second, even when variables have the same value of , hardware constraints such as irregular connectivity or differences in individual qubit quality might lead to performance advantages from mixed encodings.
Consider again the integer-to-bit encoding of Eq. (36) which maps from a discrete value to an encoding-dependent number of bits, . While there exist in principle exponentially many such encodings, common encodings may be broadly grouped in terms of their trade offs between space and depth overheads. In this work we consider the standard binary (SB), Gray, and unary (one-hot) encodings, as well as a class of encodings that interpolates between them called block unary [12], as shown in Table 1. These encodings have been previously studied in the context of resource advantages for physics and chemistry simulations [12]. For each variable the compact codes (SB and Gray) require qubits, unary requires qubits, and block unary interpolates between the two, requiring qubits where is an integer parameter (assuming a compact code is used for the local encoding of each block). An alternative unary approach called the domain wall (DW) encoding [75] uses one fewer qubit than one-hot; DW has been shown to yield significantly superior algorithm performance than one-hot in multiple contexts [76, 43].
Bitmask subsets.
| Primitive | Compact (SB,Gray,…) | Unary | Domain Wall | BUg=3 |
|---|---|---|---|---|
| **** | _____* | ____* | __ ** | |
| **** | ____*_ | ___** | __ ** | |
| **** | ___*__ | __**_ | __ ** | |
| **** | *_____ | *____ | ** __ | |
| **** | ___**_ | __*** | __ ** | |
| **** | *__*__ | *****_ | ** ** |
Consider a DQIR single-variable primitive . As described in previous work [12], in order to take advantage of the sparsity of non-compact encodings one can introduce the concept of a bitmask subset , the subset of bit (qubit) indices for which the resulting encoded qubit operator acts nontrivially. The bitmask subset is a useful concept because it facilitates automated implementation of encodings beyond just standard binary and Gray, in a way that does not operate on more qubits than are strictly required. Qubits not in the bitmask subset may safely be ignored. Hence the size of determines the qubit locality (number of qubits on which it operates nontrivially) of the encoded primitive. Examples of bitmask subsets for various elements and encodings are shown in Table 2.
When considering diagonal elements , for compact codes consists of all bits in the quantum variable, while for integer is simply the singleton set . Asymptotically, the size of the bitmask subset for block unary is in-between the sizes of those for compact and unary, i.e.
though for smaller this trend does not always hold. Performing the integer-to-bit encoding for each primitive in the computational basis yields
| (37) |
where and are the bit values for qubit resulting from the mapping, with implicit identity factors on the qubits outside of the bitmask . The following identities may then be used to convert the right-hand side primitives to the Pauli qubit operators :
| (38) |
We note that in the domain wall (DW) encoding, a particular integer often corresponds to many qubits being in the 1 state (see Table 1). Because of this, the bitmask subset for an off-diagonal element for is instead , where is included only if and is included only if . Thus DW yields a larger bitmask subset than in the one-hot case and often larger than in the compact codes. However, as long as all transition primitives operate only on nearest-integers—which is the case with discrete mixers typically considered for QAOA—DW will lead to at most 3-local operators regardless of . Notably, DW has been shown to provide advantages over one-hot in some cases, including fewer one-qubit operators in the Pauli basis [75]. Though we do not include resource analysis for the DW encoding in our numerics of Sec. 6, we speculate that circuit depths will be roughly similar to the unary (one-hot) case for the specific (and somewhat narrow) subroutine we analyze, i.e. for operator exponentiation. It is important to point out that one must analyze a full algorithm end-to-end in order to determine which encoding performs best for a given application. Notably, for some applications DW has been shown to out-perform one-hot in quantum annealing [76] and QAOA [77].
General remarks.
As mentioned, there is often significant trade-offs between encodings in the required space (number of qubits) and number of operations. Although a unary approach requires more qubits, it often leads to a shorter circuit depth. Consider a variable with . While unary codes require 16 qubits, compact codes require 4 qubits—but compact encodings usually yield an operator with more terms that additionally have a higher average Pauli weight. However, on the other hand there exist domains and problems for which a compact encoding is most efficient both in terms of space and operations counts, as discussed below.
Some conceptual results relevant for matching an application with an encoding have been studied previously [12, 18], where the number of entangling gates (not the circuit depth) was determined for various physics and chemistry applications. Here we summarize some of the previous findings. First, a lower Hamming distance between two bit strings leads to a Pauli operator with fewer terms. One direct implication of this is that the Gray code is often more efficient than SB, especially when implementing tridiagonal operators. Second, SB is often the optimal choice (outperforming even unary) for diagonal operators that we call diagonal binary-decomposable (DBD) operators, defined as operators than can be encoded in standard binary as where is a real scalar. Third, though it may seem that BU would yield operations counts in-between unary and compact, in physics applications it is often (though not always) inferior to both. This is because the bitmask subset is unfavorably large when two integers are present on different blocks.
After qubit operators have been obtained, the final compilation steps involve mapping the problem to a particular hardware. This implementation will be based on the native gate set, hardware topology, and possibly an error mitigation or correction procedure (Figure 4). If the goal is to determine a desired encoding for a given operator and set of hardware, then one may run through the compilation pipeline for many encodings before comparing resource counts such as gate counts, circuit depth, qubit counts, or approximate error bounds. In this manner, one may determine the most resource-efficient encoding for a given quantum device.
Notably, there may be circumstances under which one would convert between encodings in the middle of the quantum algorithm. This has shown to decrease required quantum resources in quantum simulation of some physics and chemistry Hamiltonians [12] and is worth exploring toward novel approaches for combinatorial problems as future work.
3 Algorithm components in DQIR
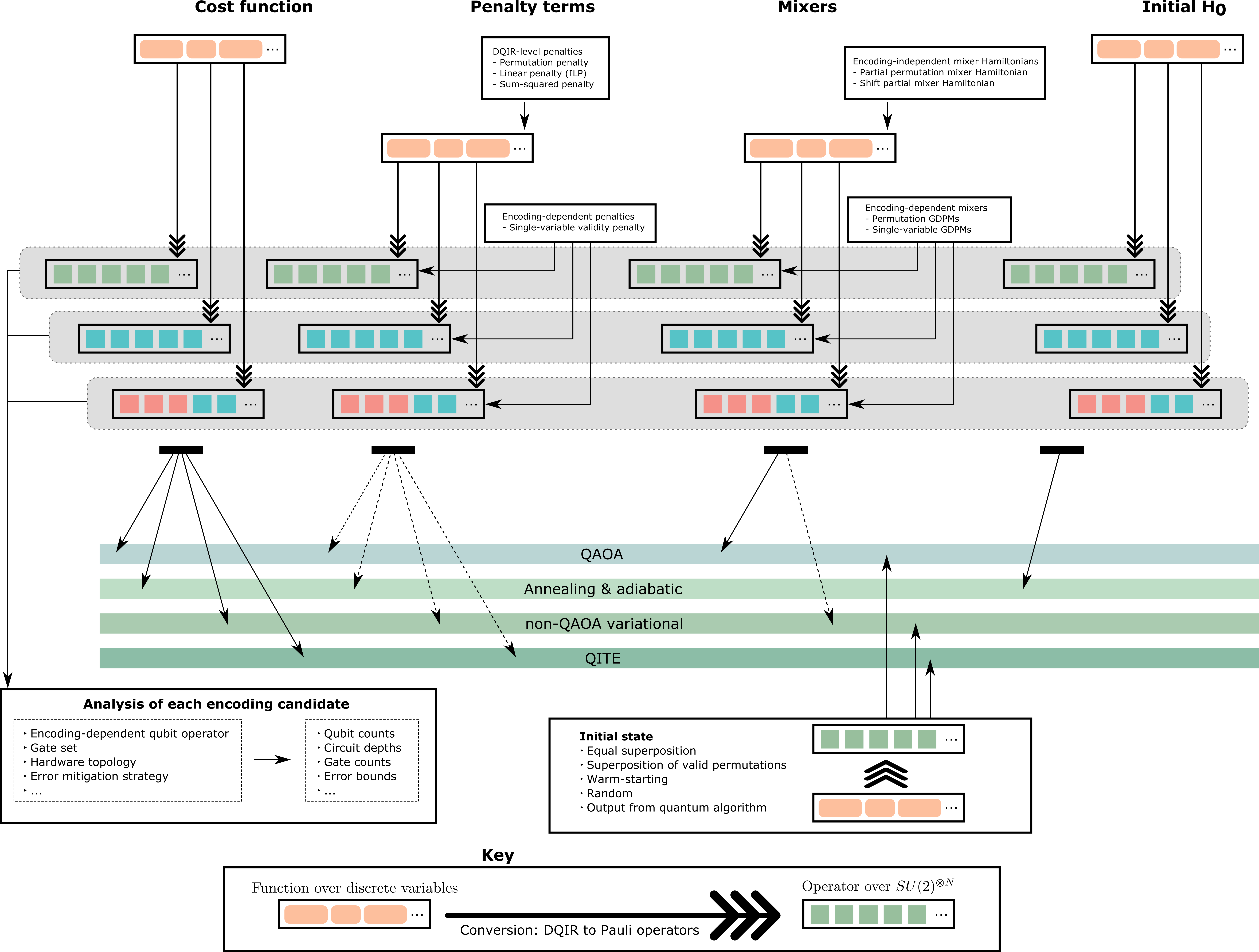
Here we provide a broad overview of various algorithmic components that are commonly required for tackling discrete optimization problems with existing quantum approaches, from the perspective of DQIR. We introduce several novel subroutines while striving to identify best practices and scenarios under which some algorithmic approaches are more advantageous than others. The flow chart in Figure 4 guides the discussion. We again emphasize that as the ultimate power of quantum computers for combinatorial optimization remains a deep and active open research area, we avoid making claims regarding algorithm performance as much as possible and instead focus on tangible metrics such as comparisons of required resources for specific approaches and subroutines.
3.1 Quantum approaches to combinatorial optimization
We first motivate our results by briefly summarizing four prototypical classes of algorithms applicable to estimating low-energy eigenvalues and eigenvectors of a problem cost Hamiltonian (i.e., obtaining approximate classical solutions). These are quantum annealing and adiabatic quantum optimization (AQO), QAOA (the quantum approximate optimization algorithm or, more generally, the quantum alternating operator ansatz), non-QAOA variational approaches, and finally approaches related to quantum imaginary time evolution (QITE). In each approach care must be taken to deal with any hard constraints, and we address several methods for doing so in detail. While a number of other approaches exist in the literature, and new approaches are frequently proposed in this rapidly developing field, the primitives required are typically similar to the ones we consider, so we uses these algorithms to illustrate the utility of our results for both current and future quantum methods. In particular, DQIR facilitates seamless extension in each approach to discrete variables of arbitrary .
Different quantum algorithms require different components and inputs to be produced from DQIR, as shown in Figure 4. Although each of the mentioned algorithms may be employed as exact solvers, we consider them more generally in the context of approximate optimization, as quantum computers are not believed able to efficiently solve NP-hard problems. Moreover, in most cases rigorous performance bounds appear quite difficult to obtain so these algorithms can be considered as heuristic approaches, especially in the setting of near-term quantum hardware; see e.g. [7] for additional discussion.
Again assume we are given a cost function on a discrete variable domain to minimize, suitably encoded as a cost Hamiltonian , and possibly subject to a set of hard constraints, as defined in Section 2.1. In each of the algorithms considered below we seek to prepare a quantum state with at least non-negligible support on low cost states such that repeated state preparation and computational basis measurement yields such a solution with high, or at least non-negligible, probability. Note that this definition subsumes both the special cases of exact optimization (requiring the true optimum solution), as well as exact algorithms (that succeed with probability very close to ).
Annealing & Adiabatic Quantum Optimization.
In AQO as well as (closely related) quantum annealing protocols [78, 6, 8] one begins in the ground state of a “driver” Hamiltonian for which said state is easy to prepare on a quantum computer, before gradually turning on the cost Hamiltonian :
| (39) |
where is a suitable annealing schedule starting at 0, varying continuously, and terminating at 1 for some sufficiently large . The two primary choices in the algorithm design are the annealing schedule and . There have been a number of exciting recent innovations to the quantum annealing protocol in terms of both hardware and theory, in particular more advanced annealing schedules accommodating so-called pause [79] and reverse [80] features, among others, as well as novel hardware topology [81] and encodings [82, 77]. Also notable are non-adiabatic annealing methods that may for example make use of environmental noise [83, 84, 85, 86, 87]. Though this is a natural procedure for analog quantum devices (i.e. quantum annealers), one may use Hamiltonian simulation algorithms such as Trotterized product formulas to approximately perform AQO on gate-based quantum computers, in terms of alternating “bang-bang” evolutions under and . If we further relax the requirement that the sequence of discretized evolution must closely match the adiabatic one we naturally arrive at the QAOA family of parameterized quantum circuits, as we discuss next. We note that compilation of problems to actual quantum annealing hardware is a rich topic with quite distinct concerns from the gate model setting [88, 89].
Quantum alternating operator ansatz.
In QAOA [3, 4, 7] one constructs a quantum circuit that alternates between applications of the so-called phase and mixing operators, applied to a suitable, efficiently preparable initial state:
| (40) |
Each layer uses parameters and , . The phase operator corresponds to time evolution under for a time . The mixing subroutine may be similarly implemented as the exponential of a mixing Hamiltonian , or more generally as some suitable parameterized unitary operator that meets certain design criteria discussed below. The algorithm parameters may be predetermined by analytic, empirical, or other means [51, 90, 57, 91, 92, 93, 94, 95, 96, 97, 98], or determined variationally using a hybrid quantum-classical search procedure [27]. QAOA is inspired by but distinct from adiabatic algorithms, in that while in certain limits the QAOA state (40) can closely approximate the adiabatic evolution of (39) [4], for different parameters the resulting evolution can be significantly different, especially at a small or moderate number of layers . Moreover, in general QAOA is not restricted to start in the ground state of the mixer. Even more so than the case of quantum annealing, a number of variants to QAOA have recently been proposed, see for instance [99, 54, 100, 101, 102].
Variational quantum circuits beyond QAOA.
Here we consider, broadly, more general classes of parameterized quantum circuits than those of QAOA. We use the term “non-QAOA ansatz” to refer to any such circuits that don’t strictly fit the definition of QAOA given above. Parameters may again be determined in general through variational optimization, or set through analysis or other means in specific cases. Here the quantum state ansatz may not depend on the cost function, or may but in a different way than in (40). Relaxing the ansatz design gives greater flexibility and may help in fitting a quantum algorithm into the limited achievable circuit depths of early generation hardware, which may include hardware-tailored ansatz [64]. In principle one may use a short depth circuit with many more parameters than QAOA, at the expense of a much more challenging parameter setting task [103, 27], or include more complex circuit features [104, 102]. Similarly to the QAOA case, where one has freedom in the design of the mixing operator, one may typically trade-off between quantum resources, and classical pre- and post-processing requirements in designing an effective variational ansatz for a given class of problems.
Imaginary time evolution.
Quantum imaginary time evolution (QITE) algorithms [66, 65] determine and implement an approximation of the real operator to create the state
| (41) |
up to normalization, on a quantum computer. If such a state could be prepared for sufficiently large and with sufficient fidelity then we would be guaranteed to find a ground state of (assuming the initial state has support on such states). However, as the QITE operator is far from unitary for non-negligible , it cannot be simultaneously implemented efficiently, exactly, and deterministically in general on quantum hardware. (Otherwise, for instance, quantum computers could efficiently solve NP-hard problems which is widely believe to not be the case; this is easy seen considering the initial state corresponding to a uniform superposition of bit (dit) strings.) Hence, after decomposing into Trotter steps each of small duration as indicated in (41), QITE algorithms iteratively employ a hybrid quantum-classical procedure to determine a suitable local unitary approximation for each subsequent step. The procedure is expensive partly because as originally proposed [66] each time step requires many iterations of quantum state tomography on a subset of the qubits that grows with each step. Understanding both the performance and limitations of QITE and related approaches remains an open and active research direction, in particular for the specific setting of combinatorial optimization, and especially what is achievable with near-term devices or polynomially-scaling resources more generally.
We next turn to methods for adapting these approaches to problems with hard constraints, which we extend to our discrete variable setting. Two primary strategies in the literature for dealing with hard constraints are penalty terms and constraint-preserving mixers, which we consider in turn. We further propose a hybrid approach that combines these two methods in Section 3.3.4.
3.2 Penalties
Here we consider penalties, which are additional terms (diagonal operators) directly added to an existing cost Hamiltonian to produce an effective cost function that penalizes with added cost any violations of the hard constraints,
| (42) |
such that the low-energy states of correspond to the low-energy feasible states of . Each penalty term represents a suitable (usually non-negative) classical function, and comes with a sufficiently large penalty weight note that choosing optimal penalty weights is nontrivial and depends on the context and particular problem [79]. Because finite-weight penalties do not strictly preserve the feasible subspace (i.e., transitions between feasible and infeasible or invalid states are possible, as opposed to the mixer-based approach of Sec. 3.3), it is generally necessary to introduce a simple post-processing step of discarding invalid or infeasible bit strings returned, or else attempting to ‘correct’ them with a suitable classical procedure—for example a simple approach would be to correct an infeasible or invalid output state by finding the closest feasible string. In general there may be different possible ways to construct suitable penalty terms, and different choices come with different resource tradeoffs.
In terms of the algorithms of Section 3.1, penalty terms are the standard approach in AQO for dealing with hard constraints. For QAOA, penalty terms may in principle be employed similarly, however, they may be much less effective [7, 31] because, as mentioned, in various parameter regimes QAOA may not resemble an adiabatic evolution such that penalty terms may not have the desired effect on the quantum state evolution. This observation hints at the alternative constraint-preserving mixer approach we consider in Section 3.3. Penalty terms may be similarly utilized in more general variational algorithms beyond QAOA, where similar consideration apply. Finally, for QITE, penalties (or another suitable approach) are necessary as without them the algorithm may converge to a wrong (i.e., infeasible or even invalid) state. For each approach, we note the distinction between including penalty terms within the quantum circuit or protocol directly, versus including it indirectly via the objective function to be optimized (typically the expectation of a cost Hamiltonian) in determining the algorithm parameters; the former can be seen as modifying the algorithm, where the latter is effectively a post-processing step.
We distinguish the two most important types of penalty terms into two categories: discrete-space (DQIR-level) penalties and encoding-dependent (qubit-level) penalties.
3.2.1 DQIR-level penalties
DQIR-level penalties are used to penalize violations of any of the unencoded classical problem’s constraints of equations (4) and (5), i.e. they are used to enforce feasibility as specified by the problem input of the algorithm dynamics and output. Here we provide several penalty constructions for a number of commonly occurring examples of hard constraints. For simplicity of presentation we will assume uniform variable domains of equal cardinality for each variable throughout; in most cases the generalization to arbitrary variable domains is straightforward. Similarly, each primitive is easily restricted, as desired, to the case of acting on only a particular subset of the problem variables.
First, recalling equations (7) and (8) we define the pair permutation penalty as
| (43) |
which is non-zero on states for which a discrete value occurs more than once, and so penalizes integer strings that don’t encode permutations. Here we have employed the indicator primitives .
Next, a commonly encountered linear constraint is that all variables in a given set must sum to some constant (i.e. when some such quantity must be preserved), for which one may use the squared-sum penalty
| (44) |
Here squaring is used to ensure that any states violating the constraint are assigned higher energy by the penalty than those that do and is a common technique in penalty term design. We employ in Sec. 5 below for the portfolio rebalancing problem.
General linear constraints are a further important constraint class that come in the form of inequalities such as , where the left-hand side is a weighted sum of a discrete variables and is a constant. In general these constraints yield a rectangular matrix such that . These linear constraints lead us to define penalty operators
| (45) |
where the number of indicator primitives in the product is equal to the sparsity of row . We further define
| (46) |
where the are constants. We stress that a variable is included in the product of equation (45) only if is non-zero. The number of terms in the final encoded operator for penalty (45) is heavily dependent on the sparsity of row of ; for many encodings the number of terms in the qubit-encoded operator scales exponentially with the number of nonzero elements in row . Hence if even one row of is not sparse, using will usually not be an efficient approach. In such cases, the introduction of a slack variable may be a preferable route [7, 105]. See Section 5 for more discussion of in the context of integer linear programming (ILP) problems.
A wide variety of other useful constraints and penalties are possible and may be implemented at the DQIR level, in particular by directly applying the techniques of Section 2.2; we do not attempt an exhaustive enumeration here. We next turn to constraints and penalties that arise only after a lower-level encoding choice has been made.
3.2.2 Encoding-dependent penalties
Unlike DQIR-level penalties, encoding-dependent constraints and penalties are those used when the target encoded space of the mapping (35) also includes invalid variable assignments, i.e. some encoded states that do not correspond to a state in the original domain . Given such a fixed encoding, in some cases we can define suitable penalty terms at the DQIR level, then further compile these terms by applying the encoding to them; in other cases contextual lower-level knowledge can be utilized to derive suitable penalty terms.
As this work primarily considers encodings for which each variable is mapped to its own set of qubits, here we define only single-variable validity penalties which for a given variable takes the form
| (47) |
where are the encoded assignments of such that the sum is taken over any invalid states [44]. This penalty is intended for use primarily with compact codes, because for non-compact codes (e.g. unary) equation (47) requires a very large number of terms. For example, if one is using SB to encode a variable into two qubits, then one may impose a penalty cost on the qubit state , which is not a valid configuration as it is not contained in .
The approach presented here may be extended to more general multi-variable encodings and error correcting codes, which is often relatively straightforward on a case-by-case basis. Hence working at the DQIR level provides greater flexibility if the underlying hardware or encoding is later changed.
3.2.3 Leakage
Here we propose a simple measure that quantifies deviation from the desired feasible subspace, and as applicable both DQIR-level and encoded quantum states. Given such a quantum state , we define its feasible outcome component as the probability of a measurement in the computational basis returning a feasible solution
| (48) |
where
Hence, at the end of a quantum algorithm (for example, one that employs penalty terms such as AQO) the final quantum state produces a feasible outcome with probability .
Similarly, given a unitary operator and a feasible state (i.e., , we define leakage due to with respect to as the probability of a transition to a state that is either infeasible (valid but violates some constraints ) or even invalid (does not correspond to a state in the domain ),
| (49) |
Leakage is a critical consideration when one desires to construct operators that shift probability amplitude between feasible states only, such as driver operators in AQO and similarly, mixers in QAOA. We note here two contrasting examples. First, problems on an unconstrained domain without any input hard constraints correspond to , i.e., the only possible leakage is to invalid states that may arise from encoding choice; if no such invalid states exist then gives the identity operator. Second, under our conventions permutations problem correspond to , where in general leakage to both infeasible or invalid states may occur.
Finally, we emphasize that we may apply (49) in either case of evaluating individual operators, or an overall quantum algorithm. For the latter case, increased leakage typically relates to increased classical resources in terms of additional circuit repetitions required to compensate for diminished success probability. Moreover, while for simplicity we do not distinguish here between leakage to invalid versus valid but infeasible subspaces, this distinction may be useful in application.
3.3 Mixers
When mapping a problem to quantum hardware, the inclusion of penalty terms can dramatically increase the resources required to implement a given algorithm, in terms of both the weights and density relative to the cost function of the penalty operator terms.
Additionally, in practice penalty-based methods do not prevent a finite or possibly significant probability of invalid and/or infeasible states, which as mentioned may dramatically increase the number of algorithm repetitions and hence overall time required to obtain a satisfactory problem solution.
An alternative approach is to design quantum operations and initial states so as to automatically restrict algorithm dynamics to the subspace of feasible states, such that the need for penalty terms is avoided altogether. Such an approach has been developed for generalizations of AQO [106, 107] and QAOA [63, 7, 108, 99, 31, 33, 105]. In the context of QAOA, whether such an approach leads to fewer quantum resources than a penalty-based approach, for comparable levels of algorithm performance, should be analyzed on a case-by-case basis [7, 31], and so we leave this question for future work. In this section we address the design of mixers that strictly preserve hard constraints, as well as novel approximate mixer variants that tolerate some manageable degree of leakage. The approximate mixers we construct require fewer quantum resources than their exact counterparts in some cases and appear particularly suitable for applications where we are willing to trade reduced circuit depth for increased classical repetitions, for example small-scale near-term experiments, though this behaviour is not generic.
For QAOA and related quantum gate model approaches it is often desirable to define mixers in terms of simpler, reusable components. Following [7], a full mixer may be constructed as an ordered product of a set of partial mixers such that
| (50) |
where ideally each is a local operator and can be implemented easily or at least efficiently. Importantly, the partial mixers do not mutually commute in general such that different orderings of the product (50) can produce different full mixers. Here by local we mean that each acts nontrivially on a bounded set of qudits, such that in particular partial mixers acting on disjoint sets of qudits can be implemented in parallel. Clearly, if each partial mixer preserves feasibility, then so does . Hence if such a mixer is utilized in QAOA along with a feasible initial state, the algorithm is guaranteed to output feasible approximate solutions only.
Partial mixers may be expressed as quantum circuits, as exponentials of Hermitian generators built using DQIR primitive, or as DQIR local primitives themselves (e.g., ). In some cases it is useful to further decompose into lower levels of partial mixers or other basic operators and so on, as desired. To this end it is useful to have a template of partial mixer designs applicable to different problem classes (i.e., domains) and types of hard constraints, with different suitability for different hardware architectures. We consider the construction of basic partial mixing designs below and in Section 4.
We categorize full or partial mixers based on two primary characteristics. First, as mentioned, mixers may be either strict or approximate, depending on whether they allow any leakage or not; we elaborate on the approximate case below. designed with respect to the feasible subspace, or hardware-logical-level mixers that may be designed to preserve validity; the first type can be defined independently of the encoding choice, while the latter cannot.
Given a set of hard constraints, a strict mixer should always take feasible quantum states to other feasible quantum states, as well as explore (in some sense) a sufficiently large portion of the feasible subspace. As previously identified in [7, Sec. 3.1], this motivates the following general design criteria for construction suitable mixing operators, in particular as products of partial mixers.
Design criteria 1.
Desired criteria for full mixers .
-
a.
(Feasibility) For all values of the mixer should preserve the feasible subspace, i.e., not result in any leakage when acting on a feasible quantum state. (This criteria may be relaxed if penalties or post-selection are introduced.)
-
b.
(Reachability) For all pairs of basis states in the feasible subspace there must be non-zero transition amplitude overlap for some and positive integer .
Criteria 1(a) ensures that when such a mixer is used in QAOA, only feasible (approximate) solutions will be returned. Given a set of partial mixers satisfying 1(a), any mixer formed from taking products will also preserve feasibility. Criteria 1(b) allows flexibility in terms of trading off the circuit depth per mixing layer (and hence overall number of QAOA layers given fixed resources) with the degree of mixing. In Section 4 we introduce techniques for the automated design of mixers satisfying Design Criteria 1 using graph-theoretic approaches. The design criteria is easily extended to accommodate more general cases such as multi-parameter mixers .
3.3.1 Approximate mixers
Here we consider generalized mixing operators which may allow some degree of leakage.
We call a mixer strict if it preserves the feasible subspace as in design criteria 1(a), i.e. if for all and all ; otherwise we use the term approximate mixer. If they can be implemented with low or moderate cost, strict mixers are preferred because they search only the valid and feasible problem space. However, there may be cases where a strict mixer is relatively expensive, or even when an efficient strict mixer construction is not known. In such cases an approximate mixer may be used, for which there may be a finite leakage per mixing stage, as well as leakage at the end of the algorithm. We elaborate on some additional motivating example applications for approximate mixers in Section 3.3.4, in particular that in some cases they may be further combined with penalty terms to reduce or eliminate leakage.
A naive implementation of an approximate mixer is to first define a Hermitian generator whose exact exponential would satisfy Design Criteria 1 and produce zero leakage, but which cannot be easily implemented on a given quantum computer. If is decomposed as
| (51) |
such that each may be exponentiated exactly, then a full approximate mixer may for example be constructed as a product formula. When using qubits, an appropriate choice is for each to be a Pauli string, as quantum circuits for their exact exponentials are easily implemented with basic quantum gates [109]. For some parameter values, or on some initial states, the leakage may be relatively small or manageable. For example, a first-order Trotter step corresponds to
| (52) |
which implies that Trotter error and hence leakage can be bounded as a function of . Within the same or between different mixing layers feasibility-violating transitions can cancel to some degree to have a less detrimental effect than worst-case bounds would indicate. If one wishes to reduce or control the leakage they can replace with for roughly times the circuit cost. Similar considerations apply to products of partial mixers derived from higher-order Suzuki-Trotter approximations [110]. More general quantum Hamiltonian simulation algorithms may also be applied to implement , however these approaches often appear to be beyond near-term capabilities and don’t typically result in a products of partial mixers in the same way. A general takeaway is that one can often trade-off increased circuit depth with tighter leakage guarantees, when desired. Importantly, we show in Section 6 that when constructing single-variable mixers, the naive Trotter approach (52) for approximate mixers can nevertheless lead to larger circuit depths than the strict mixers designed in Section 4.1 of this work.
Finally, we remark that approximate mixers may be especially appropriate in the near-term setting, where circuit depths are limited and problem sizes not too large such that one may potentially tolerate a more significant decrease to the probability of success due to leakage than in the asymptotically large setting.
3.3.2 Single-variable mixers
Single-variable mixers (i.e., single-qudit mixers [7]) operate on one variable, mixing only the valid values of the space. We define a DQIR-level generator for such a mixer called a shift partial mixer Hamiltonian (also called a fully-connected mixer [7]),
| (53) |
leading to a full mixer generator over all variables . If the term is added to equation (53), the operator is called the single-qudit ring mixer Hamiltonian [7]. As discussed in the previous section, a single-variable approximate mixer may be implemented for encoded variables after further decomposing into Pauli strings which can be exponentiated exactly.
We now turn to special cases of strict mixers for specific qubit encodings. The more general design of mixers for arbitrary and arbitrary encodings are considered in Section 4. For the unary (one-hot) encoding, we require that for pairs of qubits the two encoded states and be mixed, while (which corresponds to the other encoded values) is invariant, and no leakage to or can occur, meaning that the two-qubit unary partial mixer may have pattern
| (54) |
A possible full mixer in the unary encoding may thus be defined as . Notably, these gates can be applied in parallel on qubits , followed by , meaning that the depth of this single-variable unary mixer is independent of both the number of discrete variables and the problem size.
When using compact codes (Gray and SB), in the special case for which is a power of 2, all available encoded quantum states are valid. Therefore a minimal depth choice is the simple binary mixer [7] (sometimes called the transverse-field mixer before an encoding is specified),
| (55) |
where is the Pauli rotation gate on qubit and are mixing parameters. This circuit, with a depth of only 1, is significantly shorter than in the unary (one-hot) case, where it is not possible to construct a circuit of single-qubit rotations that always preserves feasibility. We emphasize that the simple binary mixer is strict (produces no leakage) only in the special case of being a power of 2; other cases are considered in Section 4.2.
Recalling (13), multi--variate mixers may be constructed by combining single-variable DQIR primitives in a similar manner as the single variable mixer case described here.
3.3.3 Permutation mixers
We next consider partial permutation mixers (PPMs), used for permutation problems like scheduling and routing. A DQIR basis state is valid if each object (for example, each city) appears exactly once; hence for permutations we use variable to refer to the integer values as in Eq. (7). For exploring the space of all permutations it suffices to consider PPMs that operate on two variables, from which full mixers satisfying Design Criteria 1 may be built, and so we focus on this case.
We introduce the following design criteria specific to problems over permutations. Criteria 2(a) and 2(b) are directly related to Criteria 1(a) while 2(c) is directly related to 1(b).
Design criteria 2.
Criteria for designing a DQIR two-variable partial permutation mixer .
-
a.
For any pair of variables in an -object permutation, the possible two-variable configurations are those for which and . No elements in between such states and necessarily infeasible states (those for which , , or ) are allowed. (This criterion may be relaxed if some leakage is allowed.)
-
b.
The only allowable non-zero off-diagonal elements involving feasible states are those for DQIR-level operators , i.e. terms such as and are not allowed for all-unequal. (This criterion may be relaxed if some leakage is allowed.)
-
c.
The set of non-zero off-diagonal DQIR-level primitives that obey Criteria 2(a) and (b) must include all DQIR single-variable values at least once. (Note that this criterion is used toward ensuring Criterion 1(a) is satisfied in the case where we construct a full mixer using the same PPM across different variable pairs; more generally, this condition may be relaxed.)
Full mixers may be constructed by combining two-variable PPMs in simple patterns, with the PPMs designed in accordance with Criteria 2 in order to ensure that Criteria 1 is satisfied. For example, one may again use a to operate on DQIR variable pairs followed by , and repeating. Criteria for designing PPMs are further discussed from a graph-theoretic perspective in Section 4.3.
We first consider a two-variable mixer Hamiltonian whose exact exponential meets Criteria 2. We define the two-variable standard partial permutation mixer (SPPM) Hamiltonian as
| (56) |
The exact exponential of this operator would ensure that two of the same integers would never appear more than once, which in turn ensures that the state remains in the feasible space for permutation problems. As discussed, an approximate SPPM mixer can be derived from a Suzuki-Trotter product formula, which will (depending on the encoding) lead to some degree of leakage.
In the unary encoding, it is straight-forward to define a strict partial permutation mixer to mix state on variable with state on variable . One may use a gate of the form of equation (54), where the two target qubits correspond to states and . (These have been called ordering swap partial mixers [7].) Implementing these gates for sufficiently many different pairs states will lead to a PPM that meets criterion 2(b).
Strict partial permutation mixers for standard binary, Gray, and block unary encodings are much less straight-forward to design, even when is a power of 2. Unlike the single-variable mixer case, there is no two-variable PPM equivalent of the simple binary mixer of equation (55), because such a mixer would lead to infeasible states such as . Novel graph-theoretic strategies for designing PPMs are discussed in Section 4.3.
3.3.4 Combining mixers with penalties
Here we explain how in some cases it may be advantageous for algorithms such as QAOA to combine the mixers and penalty term approaches, which we refer to generally as penalty exchanging. In this approach, we select a mixer that preserves some superset of the feasible subspace, and as needed add penalty terms to the cost function (cost Hamiltonian) to suppress transitions to strings . If is not too much larger than it may be possible to avoid penalty terms altogether. Here, a strict mixer on may be approximate with respect to the target subspace . In particular this approach may be applied at the level of individual variables and domains . Furthermore, in some cases it may be possible to select an exact mixer with respect to such that all or some measurement outcomes can be classically ‘corrected’ to a feasible string , e.g. the approach of [111].
We describe some scenarios where this approach may be useful. For some problems it may be possible to reduce required mixer resources such as circuit depth by relaxing the individual variable domains (i.e., increasing ), at the expense of tolerating some degree of leakage.
For example, imagine a single-variable mixer for a variable that requires much deeper circuits than that for in a given compact encoding. It may be the case that depth can be lowered by extending the cost function to while adding a variable domain penalty for . We consider such an example in Sec. 6.2. Another example is that for some hard constraints it may by hard or inefficient to construct a mixer that exactly preserves the feasible subspace. In this case we may relax the domain to one for which a suitable mixer can be efficiently implemented, and augment the cost Hamiltonian with appropriate penalties. A third example is that, generically, a mixer which is exact at the DQIR level may, after encoding, be compiled in an approximate way (i.e., may allow some leakage to invalid states).
For a given problem and domain, different combinations of mixers and penalty terms may be possible. In order obtain decreased circuit depth, these must be selected such that the gains for the mixing stage are not outweighed by the added cost of implementing the penalty terms. Moreover, any gains should lead to manageable degree of leakage with respect to the reduction of probability of success. A further critical consideration beyond the scope of this article is the effect on overall performance.
For specific realizations, penalty exchange ought to be analyzed or numerically tested within a full quantum algorithm. Exploring suitable circuits using penalty exchanging (based for example on memoized template circuits of fixed depths) is a task appropriate for DQIR.
3.4 Initial states
There are many options for the input quantum state. In practice, it is difficult to know a priori which combination of initial state and algorithm is most favorable for a given problem instance and quantum device. There is a complex interplay between choice of initial state, encoding, penalties, mixers, and algorithm. For instance, if one allows for use of penalties then one is less restricted in the choice of initial state, but one may pay a substantial price in obtaining feasible outcomes [31].
Here we categorize the selection of initial state in terms of several characteristics. Algorithms such as QAOA or other variational approaches in principle can accomodate arbitrary initial states when the link to adiabatic evolution is relaxed. However, in general a given target solution may be more difficult or even impossible to access from one initial state than from another [112], and further research is needed to better understand the performance and resource tradeoffs.
One may begin with either a well-defined state for which a quantum circuit is known or a quantum state that was outputted from a previous quantum algorithm (for instance, output from QAOA may be used as input for an ITE algorithm). Here we focus on the former case, where the initial state should be easy-to-prepare relative to the cost of the circuit to follow [7].
An important general class of states consists of tensor products of single-variable states, which may be expressed as for arbitrary single-variable states . The primary advantage of tensor product states is that they can be prepared in short depth. If there are no feasibility constraints, one may choose to prepare an equal superposition of all valid states
| (57) |
by operating on each (encoded) variable in parallel. This encapsulates the trivial-to-prepare qubit initial state as originally proposed for QAOA. In addition to being easy to prepare, equal superposition states are also the ground state of a mixer Hamiltonian that is a sum of single-variable terms.
For permutation problems such as scheduling and routing, whose solution is in , it may be advantageous to begin in a superposition of valid permutations
| (58) |
where is the set of all valid permutations and are complex coefficients. Previous work has shown how to prepare an equal superposition of permutations in the unary (one-hot) encoding [99], with a cost scaling as in the gate count and in the depth. This highlights that although more clever initial states may lead to more robust numerical behavior, one may pay a higher cost in the initial state preparation. We observe that, using known conversions [12] from unary to standard binary, Gray, and block unary encodings, this unary superposition state may be converted to any of the latter encodings.
Importantly, single-variable tensor product states subsume the special case of initializing a quantum algorithm with a classical string, that may selected randomly, or be obtained with some amount of instance-dependent classical preprocessing, for example using the output of a classical algorithm or heuristic. Such initial state subroutines may range from simple greedy algorithms to much more sophisticated approaches. One may integrate such classical solvers at the DQIR layer in the software pipeline. Given such a classical state , we may always transform to a quantum superposition, if desired, by applying a single mixing stage [7], or other suitable operator.
Other useful variations on the above initial states are possible. One may introduce classical or quantum randomness into an ensemble of initial states as a way to explore more of the solution landscape, and mitigate the possibility of a poor choice. For example one may implement a “warm-starting” procedure [100], where output from a classical relaxation (whereby discrete variables are replaced with continuous ones) of a combinatorial problem is used to derive an input quantum state and appropriate mixer in a different way than described above. Numerous other initial state variations are possible including adaptive approaches. Generally, an initial state design should be evaluated and selected in tandem with the intended algorithm (e.g., mixer) toward achieving the best possible performance.
4 Graph-derived mixers
In this section we show a novel approach to designing suitable mixing operators using a search algorithm based on graph-theoretic design criteria. We provide numerics supporting the resource advantages of our approach in Section 6.
The purpose of this section is to introduce a general method for creating mixers that strictly preserve the valid and feasible subspace. There have been several works that introduced their own class of such constraint-preserving mixers [99, 31, 33]. Grover mixers [99] use a construction based on Grover’s algorithm that yields constraint-preserving circuits that include multi-Toffoli gates; our approach provides additional flexibility and may lead to shorter gate depths, and one may choose to construct mixers from at most 2-qubit gates, which do not need to be decomposed. Another notable work [33] constructs constraint mixers on compact (e.g. binary) encodings; our current work produces considerably shallower mixer circuits. Finally, constructs such as XY mixers [31, 113] are efficient mixers that apply only to one-hot encodings; in contrast, our general graph based approach may in principle be applied to any encoding and any constraint. Despite our graph approach offering more flexibility in gate choice as well as shorter circuit depths, there are some potential drawbacks. First, the search algorithm in our graph-derived mixers may lead to longer compile times than previous approaches. Second, there is no guarantee that an appropriate mixer is found, if the choice of gate library is not sufficiently powerful (however, were were able to design mixers for all use cases considered in this work). Hence, determining which constraint-preserving approach to take must be studied on a case-by-case basis.
4.1 Graph representations for strict mixers
Here we introduce a novel approach in which we represent partial mixers as graphs derived from their action on computational basis states. We will show how such a construct facilitates the automated design of strict partial and full mixers that meet Design Criteria 1. These partial mixers are encoding-dependent and must be designed separately for each encoding. In general the size of the mixer graph grows exponentially with the number of problem variables , in the worst-case. However, there are many problems (including permutation problems and coloring problems considered later in this work) for which a full mixer across all variables may be generated from applying the same one- or two-variable partial mixers across different variables, for which the size of the corresponding graph grows with (which is often a constant) rather than .
Consider a partial mixer unitary operating on quantum discrete variables (i.e., is designed in terms of its action on a Hilbert space of size where is the cardinality of variable ). We define the partial mixer graph (PMG) as
| (59) |
where the set of vertices corresponds to the quantum basis states and corresponds to the coefficient of , i.e. . The graph is undirected, as for simplicity in this work we restrict ourselves to the class of unitaries for which if and only if . Our approach similarly extends to the more general directed case.
Consider for example a controlled- operator with the first and second qubit as target and off-control, respectively, in the context of its action on some (encoded) 3-qubit state (i.e., the middle green box in the bottom left of Figure 5). This gate has the following sparsity pattern and the resulting partial mixer graph contains two edges:
| (60) |
where here we have used . This construct is useful because we may now redefine mixer design as a graph-theoretic problem, which will often be both conceptually and computationally simpler than using the usual operator matrix representations.
For a fixed set of problem hard constraints, we define and , respectively, as the induced sets (subspaces) of locally good (feasible) and bad (infeasible or invalid) states, defined with respect to the variables under consideration. This approach facilitates easy reuse of the resulting local partial mixers independently of the global problem structure. It is vital to emphasize that a locally good state in may or may not correspond to a feasible global state. Consider for example a problem over permutations where we wish to design mixers with . For any two variables, contains all states for which the two variables are assigned different integers. However, if in the global variable space a different variable is assigned the same integer as one of these two local states, then the global basis is not a feasible state (even though the two-variable local state is feasible).
Using and we restate our mixer design criteria in graph-theoretic terms below. In particular, the following condition must be met for any mixer design: Edges between nodes in and nodes in are not allowed. Additional design criteria are often necessary in considering specific domains or problem classes.
This graph-based perspective can be particularly useful, via the following approach, for constructing low-depth mixers satisfying the relevant design criteria. Observe that in order to design local partial mixers (i.e. local unitaries) that preserve the valid subspace, one may first construct a library of short quantum circuits, for which it suffices to store only the graph for each circuit. Then, given a set of hard constraints (on variables), an automated search over this library of (local) graphs, along with a set of graph theoretic design criteria implementable in a compiler, allows one to design circuits for, in principle, arbitrary sets of constraints (see Figure 5). This search may be done during compilation, or before. We call these graph-derived partial mixers (GDPM). As mentioned, in a number of settings, such as when partial mixers acting on bounded sets of qubits suffice, this process is guaranteed to be efficient. Moreover, these partial mixers can be easily reused across different problems or instances.
We remark that a future possibility for dealing with more sophisticated hard constraints is to use ancilla-based mixer designs, which have been proposed previously [7]. For example, one may compute arithmetic information to store in ancilla qubits, before using this register as control qubits to perform a subsequent mixing operation only if it is guaranteed to preserve the feasible space. Such procedures are relatively straightforward to design and implement in DQIR, in an encoding-independent way. For example, this may be a workable approach for dealing with hard constraints in integer linear programming, though we do not explore this direction in detail here. Generally, there exist a variety of open questions related to the design of more effective mixers [7]; we remark on several important directions here in Section 7.
4.2 Single-variable GDPMs
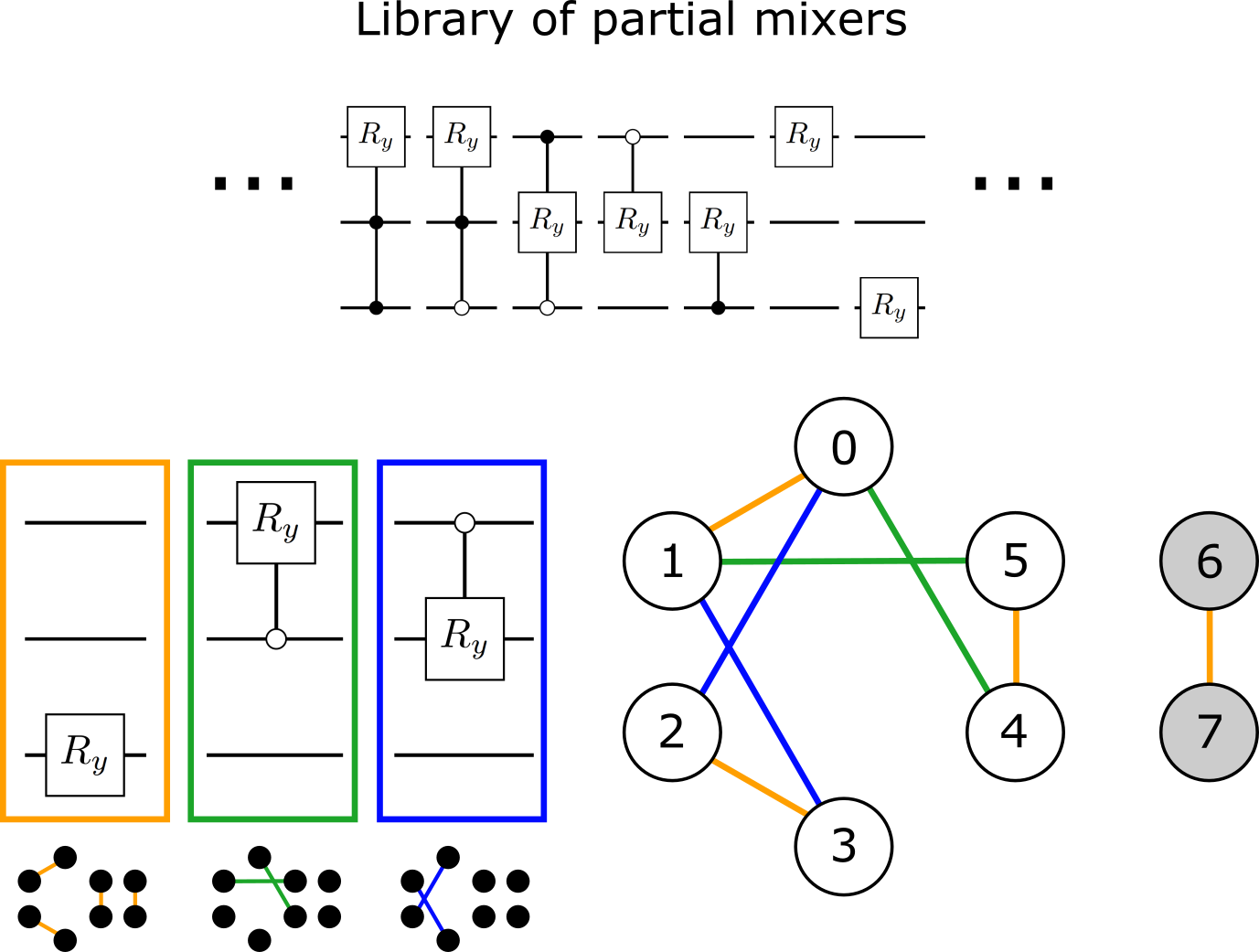
The simple mixer of equation (55) is a single-variable mixer for compact codes that may be used especially when is an integer. But designing strict mixers for compact codes is more difficult when is not a power of 2, and it is with this case in mind that we develop novel classes of mixers. Here we introduce a general approach for designing strict mixers satisfying our criteria, based on the graph-theoretic approach introduced in the previous section. We first define two specialized criteria 3 for designing a compact single-variable mixer. Criteria 3(a) and (b) are related to Criteria 1(a) and (b), respectively.
Design criteria 3.
Criteria for designing a single-variable GDPM from simpler partial mixers for a given and encoding choice.
-
a.
Edges between sets and are not allowed.
-
b.
The union of the PMG subgraphs restricted to must yield a connected graph (e.g. there must be some path between any two arbitrary feasible states).
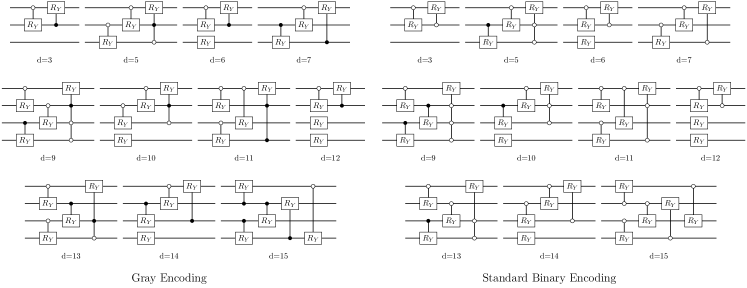
These criteria lead to the following algorithm for designing strict single-variable mixers for arbitrary and encoding choice. A library of basic (parameterized) unitaries must be input, from which the algorithm finds an ordered product of library elements that meet Criteria 3. The library must be expressive enough to meet the design criteria, and may consist, for instance, of previously determined partial mixer designs or particular favorable operations on a given hardware device. The design of a single-variable GDPM is shown schematically in Figure 5, where three primitive circuit elements are combined to produce a mixer for in the SB encoding. The following algorithm sketch shows how a GDPM may be found via converting a library of parametric circuit unitaries into graph representations. While here we consider the problem of merely finding a suitable mixer, it is straightforward to extend this approach to one where some designs are favored over others, for example, if each library element came with an associated implementation cost.
Algorithm Sketch 1.
Algorithm for the design of single-variable GDPMs.
-
1.
Input or construct a suitable library of parameterized unitaries , for which each member is efficient to implement. The library may be expanded to include additional operators if the algorithm fails to produce a mixer that meets the design constraints.
-
2.
For each parameterized unitary determine , the partial mixer graph (PMG). Call this library of graphs . For the remainder of the algorithm we use a subset of this library of graphs, as opposed to the original library of circuit unitaries.
-
3.
For each graph in , discard any that contains edges between and . The remaining members of cannot cause leakage.
-
4.
Replace each remaining member of with its induced subgraph (i.e. the graph for which nodes are removed). This step improves algorithm efficiency because the bad states in need not be stored or processed.
-
5.
Initialize set and add all members of to . (In the subsequent steps, the goal is to find a union of graphs that forms a connected graph. This is equivalent to finding a union of graphs that yields a single graph component. For example, the union of the three graphs in Figure 5 yields a single graph component over .)
-
6.
For each graph in find the number of graph components. Remove all members of that do not have exactly the minimum number of graph components. (This step just “pares down” the number of candidate graph sets, in order to reduce the cost later on. The step is not overly stringent, as the members of are used again in the next step, i.e. the unitaries of the original library are continuously being recycled.)
-
7.
For every pair of graphs with and , add the graph union to the set . (Stated differently, this step combines each graph in with each graph in the original library .)
-
8.
Repeat steps 6 and 7 until some graph in yields a single graph component. A single graph component signifies that there is some path connecting all nodes in . Hence the unitaries that were implicitly used to compose the single-component graph may be combined in product to form a proper single-particle GDPM, as in Figure 5. (These unitaries may be implemented in any order; for instance the shortest-depth ordering may be chosen.)
Additional steps may be taken to improve algorithm efficiency, for example by removing from the PMGs that correspond to circuits with larger depths. In this work, for the design of single-variable GDPMs, we chose to use multi-controlled Pauli rotations where the rotation qubit may be on any qubit and control qubits may be on or off. This is just a small subset of the possible unitaries one could consider using in a library.
The results of our computationally designed GDPMs are shown in Figure 6, for Gray and SB encodings up to . Similar constructions follow for arbitrary , as desired. These mixer circuits are a primary contribution of this paper, as practitioners may directly use them in QAOA, particularly in cases of limited quantum resources. Decompositions of the circuit library into one- and two-qubit gates is discussed further in Section 4.4. In Section 6 we will demonstrate that the decomposed circuit depths of these strict mixers are substantially shorter even than the approximate mixers that result from standard approximations to the exponential of equation (53).
GDPMs for the block unary (BU) encodings may be designed by using a compact GDPM within each -qubit block, and then connecting blocks with separate unitaries. We observe briefly that for the BU encoding, two blocks of two qubits each may be connected using a four-qubit gate, the doubly controlled gate. Decomposed depths of BU GDPM circuits are also given in Section 6 as well.
4.3 Permutation GDPMs
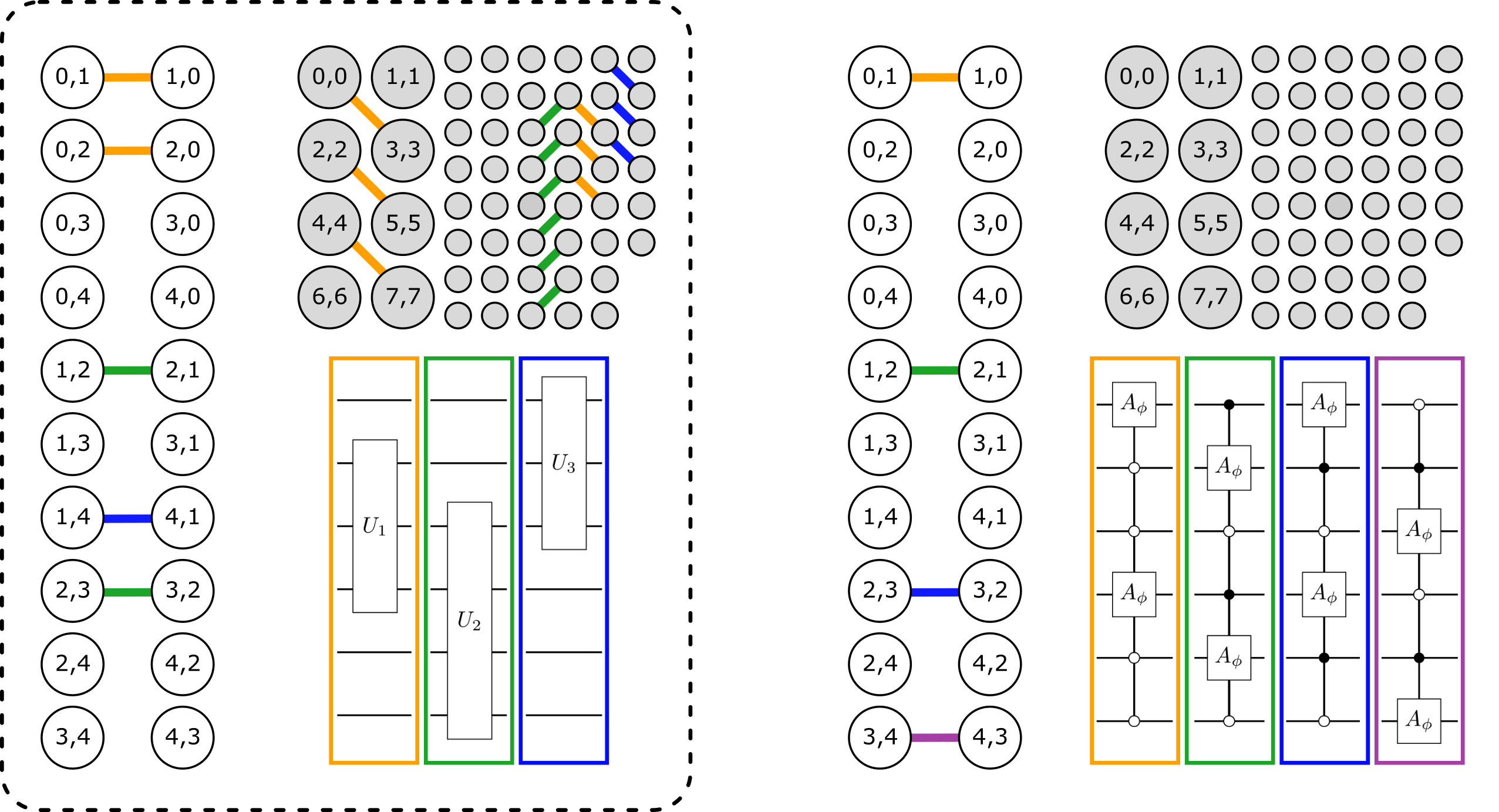
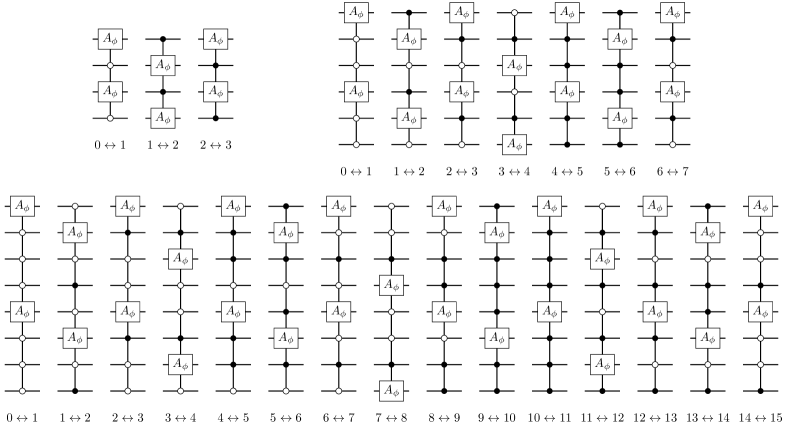
We next introduce two-variable GDPMs for permutation problems like scheduling and routing. Considering again two permutation variables as in (7), we define the set of good states as all pairs for which and ; all other states belong in . The graph-theoretic conditions for designing partial permutation mixers are then quite distinct from the previous case:
Design criteria 4.
Criteria for the design of two-variable GDPMs for permutation problems. (These are equivalent to Criteria 2, reformulated for the graph perspective.)
-
a.
Edges between sets and are not allowed.
-
b.
Within , edges may exist only between DQIR-space two-variable pairs and .
-
c.
Define a graph with nodes labeled , where an edge between nodes and exists iff there is an edge between and . must be a connected graph.
These criteria are shown schematically on the left of Figure 7. The left-hand figure is for illustrative purposes and does not correspond to an actual mixer we construct; the right-hand figure corresponds to a strict mixer for the Gray code that is discussed below.
Observe that the edge placement rules are more stringent for permutation GDPMs than for single-variable GDPMs. This is because for permutations it is possible to preserve the “local feasibibility” condition (Criteria 4(b)) of the two-variable space while violating the feasibility of the full quantum state. Explicitly, as alluded to in Section 3.3.3, while a transformation such as —which does not violate Criteria 4(a) but does violate Criteria 4(b)—leads to a two-variable state on the first two variables that is in , it still leads to an infeasible global state, for instance .
One may define an algorithm for finding the PPMs that is structurally similar to Algorithm Sketch 1, where the number of covered local states is maximized in lieu of minimizing the graph components. In preliminary numerical experiments, our elementary library of multi-controlled- gates was not able to meet Criteria 4, as anticipated, meaning that a different library of unitaries would be needed in practice. However, we were able to rationally design a set of PPMs that meet the correct graph-theoretic criteria, as we describe presently.
The right side of Figure 7 shows an example of our novel mixers for the Gray code with . The gate is a rotation gate in the class of equation (54). The key insight behind our use of these multi-controlled is that, in the Gray code, the Hamming distance between encoded states and is always exactly 2. Hence we ensure that the two-qubit gate mixes only the two differing bits, controlling on the bits of constant value.
The resulting GDPM circuits shown in Figure 8 may be combined for use with the Gray code, for any value of (equivalently, ) up to 16. For instance, for the first 9 gates of the bottom row of Figure 8 will together form a valid PPM.
For compact codes generally, Gray code mixers may be easily converted to mixers for SB, and vice versa. One approach simply uses a circuit to convert SB to Gray [114, 12], implements the Gray code mixer shown on the right side of Figure 7, and then converts back to SB. This adds a depth of just CNOT gates to the overall partial mixer.
4.4 Comments on decomposing multi-qubit gates
Because the GDPMs presented here operate in the qubit space, it is worthwhile to elaborate on a few known qubit-based quantum gate decompositions that lead to shorter-depth implementations than the most commonly used decomposition might naively yield. Here we consider decompositions of the two-qubit controlled- gate, the multi-controlled- gate, the class of gates, and alternatives to the multi-controlled- gates like Toffoli gates. In this section, we assume a gate set consisting of CNOTs and arbitrary one-qubit rotations.
Though a general two-qubit controlled-unitary requires two CNOTs and a depth of 5, a more constrained controlled- gate may be implemented with one CNOT and two single-qubit gates for a depth of 3 [69]. Such a depth-3 circuit appears to be the optimal choice for the two-qubit gates in the above-mentioned unitary library (Figure 5). Regarding gates on more than two qubits, decompositions for multi-controlled- circuits have been shown to be implementable in a depth of , which is often shorter depth than general multi-controlled- unitaries [115].
As previously mentioned, a gate with the sparsity pattern of equation (54) can be implemented in a depth of just 5 [116], a reduction from the depth-9 gate resulting from a more naive approach of exponentiation of with the standard staircase circuit construction [109].
Some comments are merited regarding decompositions of higher-order gates as well. Depending on the methods used, the iterative process of decomposing a multi-controlled unitary often leads to intermediate multi-controlled- gates. If ancilla qubits are available, such a multi-controlled- gate can be decomposed into Toffoli gates [69]. This linear scaling in the number of qubits corresponds to a logarithmic scaling in the size of a variable’s domain. Despite this seemingly favorable scaling, decomposing one Toffoli gate yields a circuit depth of 12 [70], leading to a considerable overall cost.
However, here we briefly introduce an alternative strategy to effectively reduce the depth. If one relaxes the condition that all phases in the Toffoli be , then one may implement unitaries that are “congruent modulo phase shift” to the Toffoli gate, such as
| (61) |
where we note the phase on state . This unitary can be implemented in a depth of just 7 [69], a notable reduction. Still, such a “pseudo-Toffoli” must be used with caution [69, 117]. Though a mixer unitary built from such pseudo-Toffolis may yield the same sparsity pattern, the phases of some computational basis states would be flipped for every mixing step of QAOA. This would make the connection between QAOA and AQO quite tenuous, as phases would be significantly modified outside the subroutine that exponentiates the cost function. Further analytical and numerical investigations would be required to understand the effect of replacing Toffoli gates by or similar unitaries.
5 Combinatorial problems
Here we consider five prototypical classes of discrete combinatorial problems as concrete examples of applying DQIR: graph coloring, the traveling salesperson problem, factory/machine scheduling, financial portfolio rebalancing, and integer linear programming. For each problem we show how its domain, feasible subspace, and cost Hamiltonian may be naturally represented with DQIR, directly enabling the application of various quantum algorithms including but not limited to those listed in Sec. 3.1. Numerical results concerning the resource requirements for each problem are presented in Section 6. There are of course numerous further important classes of discrete optimization problem that we do not address explicitly here, but may be straightforwardly implemented in DQIR, including, for example, other problems related to graphs such as graph partitioning or edge coloring [7], and lattice problems such as the closest or shortest vector problems [118]. We refer the interested reader to [7, App. A] for a compendium of relevant problems and example mappings.
The purpose of this section is to two-fold. First, these examples are pedagogically useful when designing quantum approaches to broader real-world industrial problems. For instance, the concepts used for our simple factory scheduling problem are applicable to much more complex scheduling problems. Our second aim is to demonstrate through examples that DQIR provides a representation for discrete problems that is more compact, interpretable, and portable than previous direct-to-qubit approaches. We remark that while qudit generalizations of the Pauli matrices exist for arbitrary (see e.g. [7, App. C]), mixers derived from them may be significantly more expensive in given encoding than the approach of Sec. 3.3.
5.1 Graph coloring problems
A variety of computationally challenging optimization problems can be related to colorings of graphs. Here we consider the problem of assigning colors to vertices such that the number of edges with differently colored ends is maximized.
When considering colors, and reformulating the problem as a minimization, count the number of adjacent vertices with equal values. In DQIR this gives the cost Hamiltonian
| (62) |
where denotes the color on node , is defined in equation (18), and the sum is taken over the graph edges.
When some of the state space is invalid (for example if there are 3 colors and an SB encoding is used), one may use either single-variable mixers and/or add a variable domain penalty . Alternatively, when one-hot encoding is employed, we note that the condition that each node is singly colored translates to constraints on the allowed Hamming weights such that many of the single-qubit Pauli-Z terms can be excluded from the cost Hamiltonian as they simply yield an overall constant [7].
Cost Hamiltonians for a variety of related problems may be similarly constructed [7]. This includes both other problems over vertex colorings of a graphs but with different cost functions and hard constraints, for example problems related to proper colorings such as approximating the graph’s chromatic number or size of the largest properly colorable induced subgraphs, as well as problems over different domains such as edge colorings. In general graph coloring problems have a close connection to scheduling, routing, and planning problems as we elaborate on below.
5.2 Traveling salesperson problem
The well-known traveling salesman/salesperson problem (TSP) is to minimize the total distance travelled on a round trip visiting each of cities exactly once. In the formulation we adopt here, a valid state is a permutation of the cities. The distances between cities is given by a distance matrix of size . The problem may be expressed as minimization over permutations of the cost function
| (63) |
which for each permutation gives the corresponding total distance traveled, and where in order to include the final distance . At the DQIR level, the problem is encoded as a list of integers. The cost Hamiltonian in DQIR is
| (64) |
5.3 Machine scheduling
Machine scheduling (or job sequencing) [119, 38] is another problem class with a domain that can be defined as a permutation of integers, though its cost function is substantially different from TSP.
Here we consider a simple single machine scheduling (SMS) problem. We are given a set of jobs with three properties: processing times , deadlines , and weights . For job , the start time is . Our goal is to determine start times that minimize total weighted lateness , where the lateness of each job is . Note that one may also express the scheduling configurations as a list of start times (instead of a permutation of job IDs) [7], or otherwise, though we do not consider such representations here. Importantly, a number of more sophisticated but closely related scheduling problem variants are studied in the literature, including ones with additional hard problem constraints and multiple machines [119].
We choose to use lateness [120, 119, 121, 122] in our problem definition here in order to consider as simple a cost function as possible. However, many other cost functions may be of interest in real-world scheduling problems, for instance tardiness or earliness, defined respectively as and [119]. Note that because lateness is simply tardiness minus earliness, it may be viewed a special case of the latter quantities. Though we do not explicitly consider tardiness and earliness in this work, we note here that the quantum phase operator may be extended to the operation using ancilla qubits. First one would compute into the ancilla register using subroutines of Section 2.2, which may include standard arithmetic operations, before performing operators controlled on the ancilla register value being positive to implement phase kickback, and finally uncomputing the first step to disentangle the ancilla register. Alternatively, one may consider distinct representations of the problem domain [7].
For SMS problem it is useful to introduce value primitives for the processing times
| (65) |
and the deadlines
| (66) |
In DQIR, a precursor for the start time operator can be written as an expression of value primitives and an indicator primitive,
| (67) |
where this operator’s support on a classical state is non-zero only when the th job is in the th position. This is a prototypical example of a value primitive being useful in mapping classical problems to the quantum representation of DQIR.
A full start time operator for job may be expressed as
| (68) |
Combining the above formulas, one way to compactly describe the cost function of total weighted tardiness is
| (69) |
We highlight again the compactness of this expression, that it is encoding-independent, and that it written entirely in terms of the primitives of DQIR. Because SMS is a permutation problem, mixers, penalties, and/or initial states need to be introduced as appropriate, analogously to the case of TSP.
Note that when Gray or SB is used, in equation (69) is equal to the identity in qubit space if . Hence when a compact code is is a power of 2, this will lead to very favorable cancellations only in these compact encodings, as we will see in the numerical results.
5.4 Financial portfolio rebalancing
In computational finance, the task of portfolio rebalancing is an optimization problem. Here we use a simple model previously proposed in the context of QAOA [47]. For a set of financial stocks separated into “lots” of discrete quantities, and given the previous portfolio position and a set of parameters, the goal is to determine whether to have a long, short, or no-hold position for each lot. The relevant parameters are the solution vector , the normalized risk-return function , the normalized trading cost function , the number of lots , the number of lots one may invest in , a risk parameter , the normalized asset returns covariance matrix , the normalized average asset returns vector , the previous portfolio position , and the normalized cost of trading.
The optimization function is
| (70) |
where
| (71) |
and
| (72) |
where is the Dirac delta function. We now write down DQIR expressions for the classical and . An arbitrary choice for labeling the three possible states is to use {long, no-hold, short} , which can be expressed via the value primitive
| (73) |
In DQIR the neat expressions are
| (74) |
and
| (75) |
where we note that any delta function between a constant and a variable may be replaced by . Finally, we have the constraint
| (76) |
which may be treated as a hard constraint by choosing appropriate initial state and mixers, or as a soft constraint by introducing a penalty (equation (44)).
5.5 Integer programming
Because many industrially relevant problems tend to be cast as integer programming and related problems [123, 124], here we outline the canonical form of ILP and briefly summarize its implementation in DQIR. Given a rectangular matrix and constant vectors and , the problem is to maximize under the two constraints
| (77) |
and . The cost function for canonical ILP is simply represented as
| (78) |
where the value primitive is the previously defined number operator . Considering that this cost function is “one-local” in DQIR space, most of the algorithmic complexity appears via the problem’s constraints, e.g. via introduction of constructs such as in equation (45).
We note that it may be computationally hard in general to even produce an initial state that contains the full feasibly subspace while excluding the infeasible subspace. Therefore, it appears likely that penalties (Section 3.2) will be necessary in NISQ implementations of ILP that use the approach of this subsection, else other approaches may be applicable only in limited cases. While we do not expect quantum computers to efficiently solve NP-hard problems such as ILP it may prove worthwhile to explore problem variants or restricted settings where quantum approaches may become viable.
6 Numerical Study of Encoding Choice
The purpose of this section is to perform a preliminary but extensive numerical investigation of the differences in behavior between the different encodings in terms of quantum resources (specifically circuit depths), with a focus on the subroutines in Sections 3 and 4, and applied instances of problems considered in Section 5. The observations and results of this section may help guide practitioners in deciding which encoding to use when designing suitable algorithm implementations for particular quantum devices. We emphasize that, as illustrated in Figure 1, different encodings require significantly different quantities of qubits—hence the shortest-depth encoding may not always be the encoding of choice for a given set of hardware. Note that we assume all-to-all connectivity in the results presented here.
With the exception of the strict GDPM mixers, this preliminary resource analysis involves compiling the matrix exponential for a Hermitian operator and real constant . The general connection to quantum algorithms is that the standard formulations of AQO and QAOA are directly implemented in terms of such operator exponentials; hence these numerical results may aid in making preliminary encodings choices when implementing AQO or QAOA. For QAOA, as discussed a variety of different mixers are possible with different resource tradeoffs beyond those we consider here. The connections to QITE and non-QAOA ansatzes are less obvious and thus our results are less applicable to those two classes of algorithm.
The operators for which we calculate circuit depths should be placed into three distinct categories: (a) exact exponentials of diagonal functions, (b) approximate mixers as implemented in equation 52, and (c) strict mixers. The former two operator categories use the same compilation procedure, which is described in Section 6.1: after a Hermitian operator is converted to the Pauli representation generated by a given encoding, each Pauli term is exponentiated as the simple first-order product formula of equation 52 with an ordering choice described below. This product formula leads to exact exponentials only in category (a) because all the terms are diagonal and thus commute. On the other hand, the calculated depths for the strict mixers of category (c) are determined as described in Section 4.4. Results in Sections 6.2 and 6.3 belong to category (a), while those in Section 6.4 belong to categories (b) and (c). We consider DQIR variable sizes , from which some preliminary trends emerge. We plot the resulting circuit depths for the different encodings and discuss the observed relative advantages.
We note that there are many Hamiltonian simulation algorithms for implementing the exponential of a Hermitian operator, each with various resource and accuracy trade-offs [125, 126, 127, 128, 129, 130, 131, 132, 133]. In this work, in an attempt to provide some preliminary guidance specifically for nearer-term quantum optimization, we chose a recently proposed Hamiltonian simulation technique [134] that is designed to produce short-depth circuits for early generations of quantum hardware. The trends observed in our numerical results may differ when using other Hamiltonian simulation algorithms, including methods that require advanced fault-tolerant quantum hardware.
6.1 Compiling product formulas from DQIR
We implemented a prototype of DQIR in Python, which we used to produce our numerical results. The code is built on three object classes: one to represent a discrete variable, one for defining the multivariate space, and one for describing and manipulating an arbitrary operator as a sum of products of local primitives. The latter class is based on the use of a Python dictionary, where keys are operator strings and values are coefficients which may be numeric or symbolic. High-level functions return a DQIR object for each combinatorial problem type and auxiliary operators such as mixer generators. Algebra routines are built into the classes, allowing for multiplication and addition of any operators as well as replacing symbolic coefficients with numerical values. We use subroutines from mat2qubit [135], Scipy [136], OpenFermion [137], and SymPy [138]. The examples included in the mat2qubit package give explicit code for producing these Hamiltonians, and we also include the qubit-encoded Hamiltonians and raw quantum circuits in the Supplemental Materials. Terms are cancelled and combined inside DQIR, which reduces the amount of computational algebra that need be performed in the final Pauli representation; this is especially important when one’s goal is to compare many encodings. We implemented functionality for returning a complex operator’s full matrix representation, allowing for the study of matrix properties.
For qubits, converting to the Pauli representation is automated with the help of the Intel Quantum SDK [139]. After each discrete variable is assigned an encoding, the DQIR-to-qubit encoding procedure of Section 2.4 is used. This yields a weighted sum of terms as in equation (51), where each is a Pauli string with a real coefficient. Our task is to compile a circuit that performs either an exact (for cost functions) or approximate (for mixers) simulation of the exponential . The circuit depths that we report are for the simple product formula for arbitrary real , where the ordering of terms is determined using an algorithm that attempts to minimize circuit depth (discussed below). For all diagonal operators (cost functions, penalties, and diagonal primitives), this procedure provides exact exponentials, because all commute with each other. For non-diagonal mixer Hamiltonians this procedure leads to an approximate mixer that may produce leakage as described in Section 3.3.1. We do not necessarily recommend the use of these instances of approximate mixer, but perform this analysis in order to have a point of comparison against our novel GDPMs). The circuit depths we present are independent of the scalar in the exponential. Note that circuit depths for the strict mixers are based on Section 4.4, not based on the compilation procedure of this section.
From the Pauli representation we produce first-order product formulas using an algorithm [134]based on Pauli Frame Graphs (PFG). In this approach, one does not “uncompute” the change of basis for each Pauli term, but instead moves directly to another Pauli frame in order to exponentiate the next term. Optimizing the circuit depth can then be recast in terms of a graph search problem. This PFG-based approach has been shown to produce significantly shorter circuits for a variety of physics and chemistry Hamiltonian classes, as compared to more standard circuit construction methods.
It is worth noting that the use of a gate set that natively performs the continuous two-gate operation [140] may lead to shorter depths as well as circuit times that are more directly dependent on the magnitude of the coefficients. However, in our view such a gate set is unlikely to be the one that is used in most commercialized quantum hardware [141, 142]. While some platforms are capable of arbitrary-angle multi-qubit entangling gates, and such operations can vary in time of operation, “continuous” control is antagonistic to arbitrary operation time due to the difficulties of system-wide clock synchronization. Thus, in practice, operations ought to be fixed to integer multiples of the system clock, where idle time is typically inserted to make up the difference. Thus at best, small angles will still likely be limited to the time of a single clock cycle.
When reporting results below, our calculated circuit depths result from the PFG decompositions, where our code uses a gate set of arbitrary one-qubit rotations and the 9 entangling gates defined in reference [134], which includes the CNOT gate. (Converting these entangling gates to CNOT can be done using only one-qubit gates; because such one-qubit gates may be fused with existing adjacent one-qubit gates, the reported circuit depths are similar to using the gate set of CNOT and arbitrary one-qubit rotations.) Single-variable strict mixers were designed by Algorithm 1, and the resulting unitaries were decomposed based either on the PFG algorithm or on the circuit decompositions summarized in Section 4.4, whichever yielded shorter depth.
6.2 Primitives and penalties
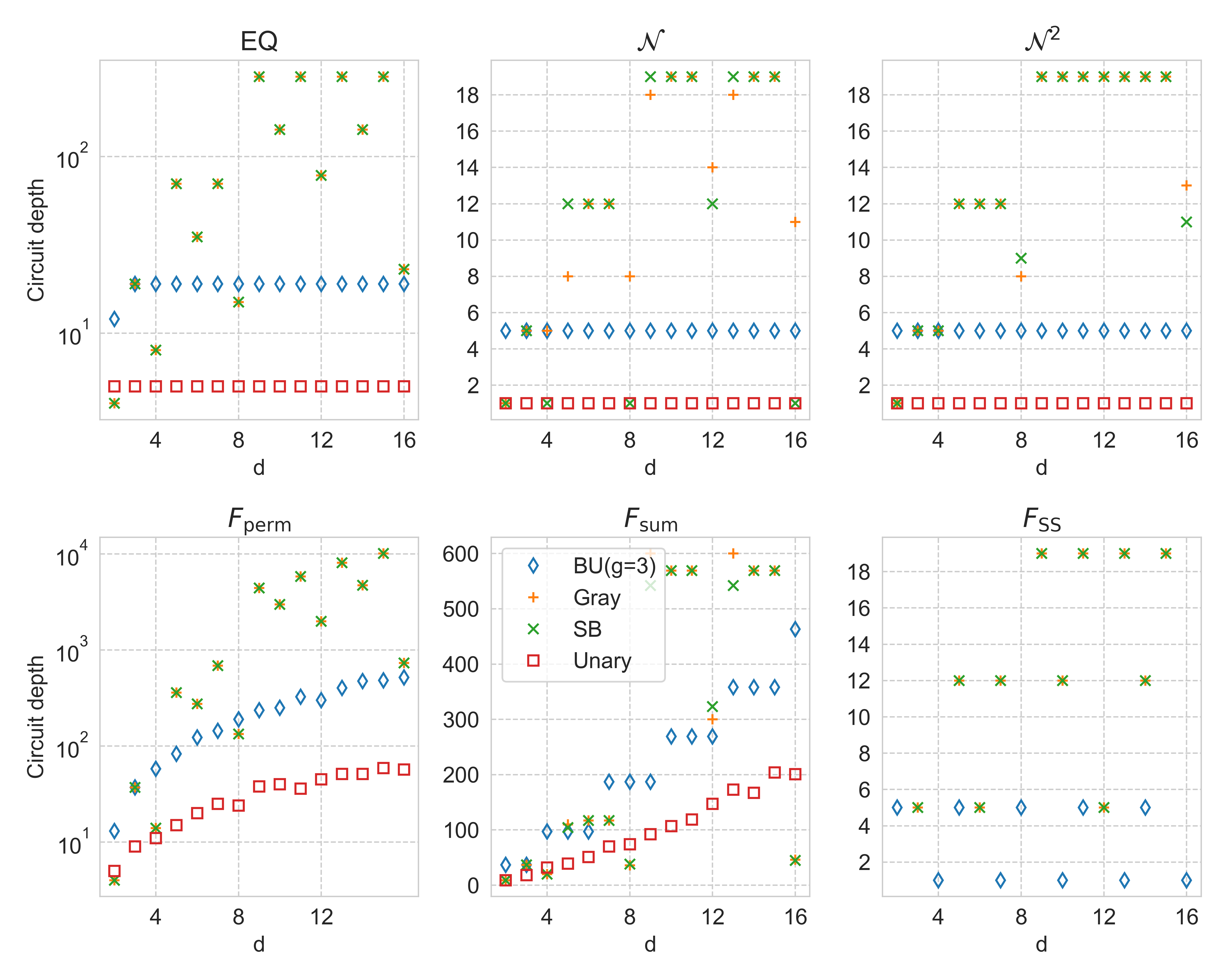
Here we present numerical results for diagonal operators that are used as building blocks in the construction of cost functions, i.e. we study primitives from Section 2.2 and penalties from Section 3.2. Figure 9 shows circuit depth plotted against variable size, for diagonal operator building blocks , , , , , and of Section 2. We remind the reader that unary requires qubits, compact codes require qubits, and block unary interpolates between them (see Figure 1). Thus the shortest-depth circuit is not necessarily the most appropriate choice if a given quantum device is space-limited. Results here assume all-to-all connectivity; circuit depths will be different when considering a different hardware topology [18], an important aspect beyond the scope of this work.
For most diagonal operators considered here, unary provides the shortest-depth circuits. However, there are many important exceptions apparent for and These exceptions are notable for the following reason. When the circuit depths for the compact codes are equal to or less than the depths for unary, this means a compact code is likely to be superior on most hardware, as it would require both shorter depth and fewer qubits. However, the circuit depth of the full quantum algorithm (not just one of its subroutines) must be analyzed to determine whether this is the case—we do not perform such an analysis of full quantum algorithms in this work, but we note that in the context of Hamiltonian simulation there are some problem instances for which compact codes out-performed unary in terms of both depth and space [12].
Because of favorable term cancellation in qubit space, compact codes tend to be most useful when is a power of 2, as discussed in previous work [12]. This trend is exhibited in the examples of Figure 9, where compact codes are more likely to be competitive with other encodings when is an integer.
Though the Gray and SB encodings often yield the same circuit depth, in some cases they have different depths, for example in and . This highlights the fact that in some instances it may be worth considering multiple compact encodings. A practitioner may choose to explore more of the (exponentially many) compact encodings before choosing the shortest-depth one.
The reason for BU’s intermediate depth is that the locality of the diagonal operators is smaller than the compact code but larger than unary. For a given quantum device, block unary is an optimal choice only when two necessary conditions are met. First, the depth for BU must be less than that of the compact codes. This is true for most values in the simple diagonal functions considered here. Second, the hypothetical device must be qubit-limited, such that there are not enough qubits available to use a unary code. Because our results show that (often) BU is intermediate in both depth and in qubit count as compared with the other encodings, there is a strong chance that BU will be the optimal choice for some near-term hardware parameters (those with moderate depth and moderate qubit counts).
The three types of penalties considered show similar behavior; namely, unary is usually shortest-depth and it is common for BU to have shorter depth than compact codes. Note that the single-variable validity penalty is the null operator in the following cases: in compact codes when is a power of 2, in block unary when is divisible by , and always for the unary encoding because we are assuming that validity-preserving operators are used for unary algorithms. Both the permutation and summation penalties involve a quadratic number of two-variable terms, which is the reason for their larger circuit depths. Note that the depth of the permutation penalty is strongly dependent on the number of discrete variables (e.g. number of cities). This suggests that problems for which is not a power of 2 ought to be reformulated—this could be accomplished in the TSP by adding cities with very small distance to an existing city, and in scheduling this could be accomplished by adding extra tasks with very small .
Finally, we highlight one clear example where penalty exchanging (Section 3.3.4) would reduce overall circuit depth. When with compact codes, the operator yields a depth of 70 while single-variable validity penalty yields depth 12. Hence one can reduce depth by implementing the version of (depth 15) while introducing a validity penalty for , which results in a net overall depth reduction. As mentioned, shorter depth does not always lead to improved algorithms—any modification of a subroutine ought to be tested for performance in a real algorithm.
6.3 Full cost functions
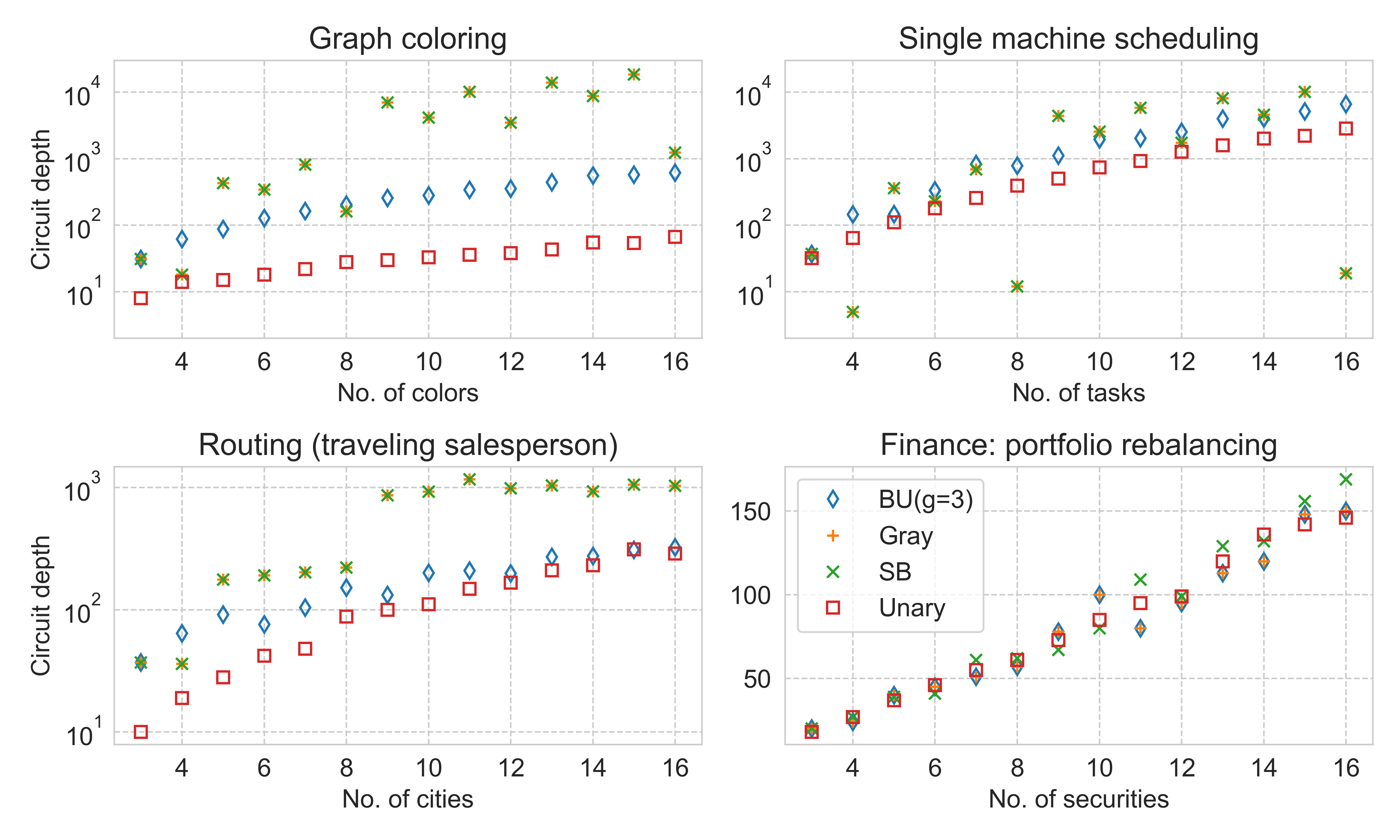
Here we consider circuit depths for implementing the exponential of a cost function, a subroutine that is necessary for executing AQO and QAOA (summarized in Section 3.1). Figure 10 shows circuit depths for exponentiating four classes of cost functions defined in Section 5: graph coloring, scheduling, routing, and portfolio rebalancing. The problem parameters used are defined in the text below. Though these problem instances should be considered as toy models, the numerical results are useful for understanding trends in and in encoding choice that may also be applicable to more realistic real-world problems.
Our graph coloring problem instances use complete (i.e. fully connected) graphs for which the number of nodes equals the number of colors , i.e. scales linearly with the number of variables . We use this class of graphs as a worst-case example of scaling behavior. Resource requirements will be substantially different for example when is constant and independent of . In real-world problems, the circuit depth would be heavily dependent on both the class of graph (e.g. complete, regular, multipartite, etc.) and how the number of colors scales with . Graph coloring is “two-local” in the sense that all terms are products of at most two DQIR variables, and in the case of complete graphs the number of terms scales quadratically. The results, which follow the trends of the operator, show that while unary and BU encodings follow clean monotoic trends, in compact codes the depth shows a much less consistent trend. For example, for SB and Gray there is a large drop in depth from to . Expanding the domain and using penalty exchanging may be appropriate in such cases.
Machine scheduling (or factory scheduling) is one of two problems we present where the solution must be a permutation of integers. The substantial depths observed here result from the quadratic number of two-variable terms in the cost Hamiltonian. At , the depths for compact (SB and Gray) encodings are over an order of magnitude lower than the unary depths. This is because, when is a power of 2 and a compact encoding is used, the term of equation (69) in qubit space is equal to the identity, which leads to massive simplifications and term cancellations in the Hamiltonian. We hasten to note that this does not necessarily imply that the compact codes are superior to unary for machine scheduling. An algorithm implementation requires not just the cost function but also either a penalty or PPMs, the versions of which have presented are much higher depth for compact than for unary (see Figures 8 and 9).
However, we have not extensively explored the design of PPMs in this work. We are hopeful that a future design of PPMs that operate on fewer qubits (see the hypothetical case on the left of Figure 7) may lead to PPMs that are much shorter-depth when decomposed. Though their existence is only speculated, if such shorter-depth PPMs are possible, it may result in the compact code being both the lowest-space and lowest-depth choice in QAOA for machine scheduling.
TSP (routing) is also a permutation problem composed of two-variable terms and all-to-all connectivity. As in the case of machine scheduling, higher-depth penalties and/or mixers are unavoidable when solving the problem, because one must stay in the permutation space. The numerical trend matches what was expected, with circuit depths highest for compact and lowest for unary. This is another case where the results appear to suggest that BU has a strong chance of being viable, in cases where there are not enough qubits available for the unary encoding.
In the financial portfolio rebalancing problem, regardless of the number of variables. Therefore BU gives identical results to the Gray code, as they both use 2 qubits per variable. The circuit depths for all encodings are very similar, which leads us to conclude that the more space-efficient compact codes are preferred for this Hamiltonian class, especially considering the short-depth compact mixers that we present. Note that the Gray code is similar to the encoding used in the original study of QAOA for portfolio rebalancing [47].
Notably, as observed in the last section, these full cost functions (excluding portfolio rebalancing) show that that there is a potential role for block unary—certainly more so than previous studies of physics Hamiltonians would have suggested [12]. This is because when the depth of BU lies in between compact and unary, there exists some set of hardware parameters for which block unary is the optimal choice. As previously stated, BU is the optimal choice when there are not enough qubits to use unary, but there are enough qubits to implement BU or compact codes.
6.4 Mixers
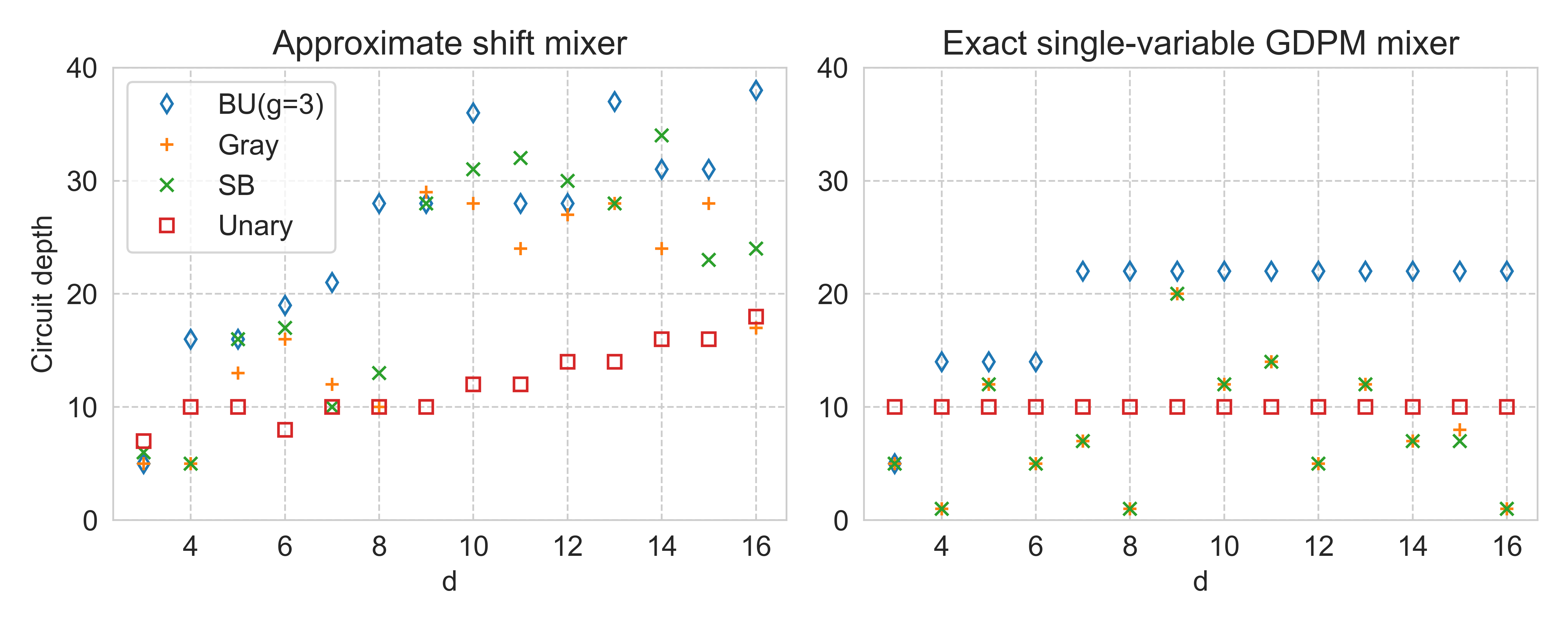
Figure 11 shows circuit depths for implementing approximate (i.e. leaky) shift mixers (left) and strict (leakage-free) single-variable GDPMs (right) designed by Algorithm 1. The approximate shift mixers are simply the first-order product formula that implements decomposition of the exponential of equation (53), with the term ordering and depths determined using the previously mentioned PFG approach [134]. In the exact mixers, depths are determined by whichever decompositions outlined in Section 4.4 produce the lowest depths.
In nearly all cases, the naive approach of approximating the exponential of a mixer Hamiltonian yields larger depths than our designed exact mixers. This means that the single-variable GDPM designs are superior both in terms of depth and in terms of not producing leakage. This suggests that our algorithmically designed single-variable mixers will find utility in real algorithms, though we leave numerical analysis of these mixers’ performance in a QAOA simulation to future work.
BU mixers were designed by using two-qubit mixers within each block, and connecting each two-qubit block with doubly-controlled gates. The latter four-qubit gates connect two blocks by mixing adjacent cross-block integers. For example, states and are mixed using such a four-qubit gate. The depths for this four-qubit gate were calculated using the PFG method. The resulting depths are largest for BU in all cases , but the discrepancy is not large enough to overwhelm the differences in cost function depths shown in the previous two sections. These are not necessarily the optimal mixer designs for BU.
In compact codes, the figure shows the mixer depth is equal to one when is a power of 2 (). This is because the simple mixer of equation (55) is used. This short depth, along with the fact that circuits for cost function exponentials also tend to be shorter depth at these same values (Figure 10), shows that SB and Gray may sometimes be more competitive with unary than expected, while requiring far fewer qubits. Finally, we highlight that the GDPM compact (Gray and SB) mixers are even shorter depth than unary mixers for the majority of values.
7 Conclusions
In this work we have constructed and analyzed a large set of quantum subroutines relevant to solving optimization problems defined on domains of discrete (e.g. integer) variables. We introduced an intermediate representation (DQIR) which facilitates the synthesis of a variety of algorithm components into qubit-based hardware, though these procedures may be used for qudit-based hardware as well. Previous work had analytically derived operators for each encoding, whereas our method automates the implementation of any arbitrary integer-to-bit mapping by building on previous techniques [7, 12].
The first advantage of our approach is that it provides a compact, flexible and readily interpretable representation of discrete optimization problems; one may fully define discrete problems and algorithmic components before considering any hardware implementation. Second, one may automate the process of “screening” any number of potential hardware mappings, comparing circuit depths or other measures of resource efficiency for different encodings. In addition, we have provided numerical and conceptual guidance for which operator components are most useful for which algorithmic approaches to a given problem class. We suggested several best practices regarding the interplay between initial states, preservation of feasibility and validity, and encoding choice.
Our numerical results yielded several rules of thumb regarding encoding choice. First, though the unary (one-hot) encoding is often the lowest-depth and highest-space choice, there are some subroutines for which the compact codes (e.g. Gray and standard binary) are advantageous both in terms of qubit counts and circuit depth. Second, the block unary code, because its depth usually lies between the depths of compact and unary encodings, indeed often sits on the space-depth Pareto front (Figure 1). This means that BU would in fact be the optimal choice for combinatorial problems for some hypothetical hardware parameters; this was somewhat surprising, as BU appears less likely to be useful in physics simulation [12]. Third, the choice of bitstring for labeling each discrete value in compact codes can affect circuit depths—this is shown by the differences in depth sometimes observed between Gray and standard binary. Fourth, compact codes are much shorter depth when the variable domain is a power of 2. Finally, our numeric results highlighted that penalty exchanging, in which the the variable domain size is modified in exchange for introducing a penalty, may be an important strategy in algorithm design.
Separately, we have introduced criteria and approaches for designing a new class of QAOA mixers, which we call graph-derived partial mixers (GDPMs). Our computationally designed single-variable GDPM mixers provide systematic low-depth construction of exact mixers that preserve a desired feasible subspace. The very short depths of GDPMs for compact codes, even when is not a power of 2, lead us to be optimistic about the use of compact codes for quantum optimization.
There are several important open directions for future study. While we have implicitly assumed all-to-all connectivity throughout, the constructions of this work may be further tailored to a given hardware topology. Similarly, the generalization to quantum error correcting codes may be straightforward in some cases. In either case, the specific details may affect which encoding is preferable. In particular, the type of basic quantum gate which is considered "expensive" may be quite different between the near-term and fault-tolerant settings. Using DQIR, automated compilation of many encodings, and the low-level quantum subroutines introduced in this work, some of these questions can begin to be addressed systematically.
In terms of algorithms, performance is ultimately the most tantalizing question, which has so far proven challenging to analyze. As improved quantum hardware becomes available better, empirical evidence should help further guide algorithm design and choice. For QAOA, many questions remain as to how to select the best mixer for a given problem with fixed quantum resources. For example, while alternative mixers requiring deeper circuits than the ones considered in Sec. 4 may in some sense provide more efficient mixing, their cost may limit the number of implementable QAOA layers; for comparable circuit depths it is not clear which approach will ultimately result in better performance.
Acknowledgements
This research used the resources of the National Energy Research Scientific Computing Center (NERSC), a U.S. Department of Energy Office of Science User Facility located at Lawrence Berkeley National Laboratory, operated under Contract No. DE-AC02-05CH11231 using NERSC award DDR-ERCAP0018781. SH is grateful for support from the NASA Ames Research Center, under NASA Academic Mission Services (NAMS) Contract no. NNA16BD14C, from the DARPA ONISQ program under interagency agreement IAA 8839 Annex 114, and from the DARPA RQMLS program under interagency agreement IAA 8839 Annex 128.
References
- [1] Christos H Papadimitriou and Kenneth Steiglitz. Combinatorial optimization: algorithms and complexity. Courier Corporation, 1998.
- [2] Lov K Grover. A fast quantum mechanical algorithm for database search. In Proceedings of the twenty-eighth annual ACM symposium on Theory of computing, pages 212–219, 1996. https://doi.org/10.1145/237814.237866.
- [3] Tad Hogg and Dmitriy Portnov. Quantum optimization. Information Sciences, 128(3-4):181–197, 2000. https://doi.org/10.1016/s0020-0255(00)00052-9.
- [4] Edward Farhi, Jeffrey Goldstone, and Sam Gutmann. A quantum approximate optimization algorithm. arXiv preprint arXiv:1411.4028, 2014. https://doi.org/10.48550/arXiv.1411.4028.
- [5] Matthew B Hastings. A short path quantum algorithm for exact optimization. Quantum, 2:78, 2018. https://doi.org/10.22331/q-2018-07-26-78.
- [6] Tameem Albash and Daniel A Lidar. Adiabatic quantum computation. Reviews of Modern Physics, 90(1):015002, 2018. https://doi.org/10.1103/revmodphys.90.015002.
- [7] Stuart Hadfield, Zhihui Wang, Bryan O’Gorman, Eleanor Rieffel, Davide Venturelli, and Rupak Biswas. From the quantum approximate optimization algorithm to a quantum alternating operator ansatz. Algorithms, 12(2):34, 2019. https://doi.org/10.3390/a12020034.
- [8] Philipp Hauke, Helmut G Katzgraber, Wolfgang Lechner, Hidetoshi Nishimori, and William D Oliver. Perspectives of quantum annealing: Methods and implementations. Reports on Progress in Physics, 83(5):054401, 2020. https://doi.org/10.1088/1361-6633/ab85b8.
- [9] K.M. Svore, A.V. Aho, A.W. Cross, I. Chuang, and I.L. Markov. A layered software architecture for quantum computing design tools. Computer, 39(1):74–83, jan 2006. https://doi.org/10.1109/MC.2006.4.
- [10] David Ittah, Thomas Häner, Vadym Kliuchnikov, and Torsten Hoefler. Enabling dataflow optimization for quantum programs. arXiv preprint arXiv:2101.11030, 2021. https://doi.org/10.48550/arXiv.2101.11030.
- [11] Ruslan Shaydulin, Kunal Marwaha, Jonathan Wurtz, and Phillip C Lotshaw. Qaoakit: A toolkit for reproducible study, application, and verification of the qaoa. In 2021 IEEE/ACM Second International Workshop on Quantum Computing Software (QCS), pages 64–71. IEEE, 2021. https://doi.org/10.1109/qcs54837.2021.00011.
- [12] Nicolas P. D. Sawaya, Tim Menke, Thi Ha Kyaw, Sonika Johri, Alán Aspuru-Guzik, and Gian Giacomo Guerreschi. Resource-efficient digital quantum simulation of d-level systems for photonic, vibrational, and spin-s hamiltonians. npj Quantum Information, 6(1), jun 2020. https://doi.org/10.1038/s41534-020-0278-0.
- [13] Stuart Hadfield. On the representation of Boolean and real functions as Hamiltonians for quantum computing. ACM Transactions on Quantum Computing, 2(4):1–21, 2021. https://doi.org/10.1145/3478519.
- [14] Kesha Hietala, Robert Rand, Shih-Han Hung, Xiaodi Wu, and Michael Hicks. Verified optimization in a quantum intermediate representation. CoRR, abs/1904.06319, 2019. https://doi.org/10.48550/arXiv.1904.06319.
- [15] Thien Nguyen and Alexander McCaskey. Retargetable optimizing compilers for quantum accelerators via a multilevel intermediate representation. IEEE Micro, 42(5):17–33, 2022. https://doi.org/10.1109/mm.2022.3179654.
- [16] Alexander McCaskey and Thien Nguyen. A MLIR dialect for quantum assembly languages. In 2021 IEEE International Conference on Quantum Computing and Engineering (QCE), pages 255–264. IEEE, 2021. https://doi.org/10.1109/qce52317.2021.00043.
- [17] Andrew W Cross, Lev S Bishop, John A Smolin, and Jay M Gambetta. Open quantum assembly language. arXiv preprint arXiv:1707.03429, 2017. https://doi.org/10.48550/arXiv.1707.03429.
- [18] Nicolas P. D. Sawaya, Gian Giacomo Guerreschi, and Adam Holmes. On connectivity-dependent resource requirements for digital quantum simulation of d-level particles. In 2020 IEEE International Conference on Quantum Computing and Engineering (QCE). IEEE, 2020. https://doi.org/10.1109/qce49297.2020.00031.
- [19] Alexandru Macridin, Panagiotis Spentzouris, James Amundson, and Roni Harnik. Electron-phonon systems on a universal quantum computer. Phys. Rev. Lett., 121:110504, 2018. https://doi.org/10.1103/PhysRevLett.121.110504.
- [20] Sam McArdle, Alexander Mayorov, Xiao Shan, Simon Benjamin, and Xiao Yuan. Digital quantum simulation of molecular vibrations. Chem. Sci., 10(22):5725–5735, 2019. https://doi.org/10.1039/c9sc01313j.
- [21] Pauline J. Ollitrault, Alberto Baiardi, Markus Reiher, and Ivano Tavernelli. Hardware efficient quantum algorithms for vibrational structure calculations. Chem. Sci., 11(26):6842–6855, 2020. https://doi.org/10.1039/d0sc01908a.
- [22] Nicolas PD Sawaya, Francesco Paesani, and Daniel P Tabor. Near-and long-term quantum algorithmic approaches for vibrational spectroscopy. Physical Review A, 104(6):062419, 2021. https://doi.org/10.1103/physreva.104.062419.
- [23] Jakob S Kottmann, Mario Krenn, Thi Ha Kyaw, Sumner Alperin-Lea, and Alán Aspuru-Guzik. Quantum computer-aided design of quantum optics hardware. Quantum Science and Technology, 6(3):035010, 2021. https://doi.org/10.1088/2058-9565/abfc94.
- [24] R Lora-Serrano, Daniel Julio Garcia, D Betancourth, RP Amaral, NS Camilo, E Estévez-Rams, LA Ortellado GZ, and PG Pagliuso. Dilution effects in spin 7/2 systems. the case of the antiferromagnet GdRhIn5. Journal of Magnetism and Magnetic Materials, 405:304–310, 2016. https://doi.org/10.1016/j.jmmm.2015.12.093.
- [25] Jarrod R McClean, Jonathan Romero, Ryan Babbush, and Alán Aspuru-Guzik. The theory of variational hybrid quantum-classical algorithms. New Journal of Physics, 18(2):023023, 2016. https://doi.org/10.1088/1367-2630/18/2/023023.
- [26] Vladyslav Verteletskyi, Tzu-Ching Yen, and Artur F Izmaylov. Measurement optimization in the variational quantum eigensolver using a minimum clique cover. The Journal of chemical physics, 152(12):124114, 2020. https://doi.org/10.1063/1.5141458.
- [27] Marco Cerezo, Andrew Arrasmith, Ryan Babbush, Simon C Benjamin, Suguru Endo, Keisuke Fujii, Jarrod R McClean, Kosuke Mitarai, Xiao Yuan, Lukasz Cincio, et al. Variational quantum algorithms. Nature Reviews Physics, 3(9):625–644, 2021. https://doi.org/10.1038/s42254-021-00348-9.
- [28] Dmitry A Fedorov, Bo Peng, Niranjan Govind, and Yuri Alexeev. VQE method: A short survey and recent developments. Materials Theory, 6(1):1–21, 2022. https://doi.org/10.1186/s41313-021-00032-6.
- [29] Andrew Lucas. Ising formulations of many NP problems. Frontiers in physics, 2:5, 2014. https://doi.org/10.3389/fphy.2014.00005.
- [30] Young-Hyun Oh, Hamed Mohammadbagherpoor, Patrick Dreher, Anand Singh, Xianqing Yu, and Andy J. Rindos. Solving multi-coloring combinatorial optimization problems using hybrid quantum algorithms. arXiv preprint arXiv:1911.00595, 2019. https://doi.org/10.48550/arXiv.1911.00595.
- [31] Zhihui Wang, Nicholas C. Rubin, Jason M. Dominy, and Eleanor G. Rieffel. XY mixers: Analytical and numerical results for the quantum alternating operator ansatz. Phys. Rev. A, 101:012320, Jan 2020. https://doi.org/10.1103/PhysRevA.101.012320.
- [32] Zsolt Tabi, Kareem H. El-Safty, Zsofia Kallus, Peter Haga, Tamas Kozsik, Adam Glos, and Zoltan Zimboras. Quantum optimization for the graph coloring problem with space-efficient embedding. In 2020 IEEE International Conference on Quantum Computing and Engineering (QCE). IEEE, oct 2020. https://doi.org/10.1109/qce49297.2020.00018.
- [33] Franz G Fuchs, Herman Oie Kolden, Niels Henrik Aase, and Giorgio Sartor. Efficient encoding of the weighted MAX k-CUT on a quantum computer using qaoa. SN Computer Science, 2(2):89, 2021. https://doi.org/10.1007/s42979-020-00437-z.
- [34] Bryan O’Gorman, Eleanor Gilbert Rieffel, Minh Do, Davide Venturelli, and Jeremy Frank. Comparing planning problem compilation approaches for quantum annealing. The Knowledge Engineering Review, 31(5):465–474, 2016. https://doi.org/10.1017/S0269888916000278.
- [35] Tobias Stollenwerk, Stuart Hadfield, and Zhihui Wang. Toward quantum gate-model heuristics for real-world planning problems. IEEE Transactions on Quantum Engineering, 1:1–16, 2020. https://doi.org/10.1109/TQE.2020.3030609.
- [36] Tobias Stollenwerk, Bryan OGorman, Davide Venturelli, Salvatore Mandra, Olga Rodionova, Hokkwan Ng, Banavar Sridhar, Eleanor Gilbert Rieffel, and Rupak Biswas. Quantum annealing applied to de-conflicting optimal trajectories for air traffic management. IEEE Transactions on Intelligent Transportation Systems, 21(1):285–297, jan 2020. https://doi.org/10.1109/tits.2019.2891235.
- [37] Alan Crispin and Alex Syrichas. Quantum annealing algorithm for vehicle scheduling. In 2013 IEEE International Conference on Systems, Man, and Cybernetics. IEEE, 2013. https://doi.org/10.1109/smc.2013.601.
- [38] Davide Venturelli, Dominic J. J. Marchand, and Galo Rojo. Quantum annealing implementation of job-shop scheduling. arXiv preprint arXiv:1506.08479, 2015. https://doi.org/10.48550/arXiv.1506.08479.
- [39] Tony T. Tran, Minh Do, Eleanor G. Rieffel, Jeremy Frank, Zhihui Wang, Bryan O’Gorman, Davide Venturelli, and J. Christopher Beck. A hybrid quantum-classical approach to solving scheduling problems. In Ninth Annual Symposium on Combinatorial Search. AAAI, 2016. https://doi.org/10.1609/socs.v7i1.18390.
- [40] Krzysztof Domino, Mátyás Koniorczyk, Krzysztof Krawiec, Konrad Jałowiecki, and Bartłomiej Gardas. Quantum computing approach to railway dispatching and conflict management optimization on single-track railway lines. arXiv preprint arXiv:2010.08227, 2020. https://doi.org/10.48550/arXiv.2010.08227.
- [41] Constantin Dalyac, Loïc Henriet, Emmanuel Jeandel, Wolfgang Lechner, Simon Perdrix, Marc Porcheron, and Margarita Veshchezerova. Qualifying quantum approaches for hard industrial optimization problems. A case study in the field of smart-charging of electric vehicles. EPJ Quantum Technology, 8(1), 2021. https://doi.org/10.1140/epjqt/s40507-021-00100-3.
- [42] David Amaro, Matthias Rosenkranz, Nathan Fitzpatrick, Koji Hirano, and Mattia Fiorentini. A case study of variational quantum algorithms for a job shop scheduling problem. EPJ Quantum Technology, 9(1):5, 2022. https://doi.org/10.1140/epjqt/s40507-022-00123-4.
- [43] Julia Plewa, Joanna Sieńko, and Katarzyna Rycerz. Variational algorithms for workflow scheduling problem in gate-based quantum devices. Computing & Informatics, 40(4), 2021. https://doi.org/10.31577/cai_2021_4_897.
- [44] Adam Glos, Aleksandra Krawiec, and Zoltán Zimborás. Space-efficient binary optimization for variational quantum computing. npj Quantum Information, 8(1):39, 2022. https://doi.org/10.1038/s41534-022-00546-y.
- [45] Özlem Salehi, Adam Glos, and Jarosław Adam Miszczak. Unconstrained binary models of the travelling salesman problem variants for quantum optimization. Quantum Information Processing, 21(2):67, 2022. https://doi.org/10.1007/s11128-021-03405-5.
- [46] David E. Bernal, Sridhar Tayur, and Davide Venturelli. Quantum integer programming (QuIP) 47-779: Lecture notes. arXiv preprint arXiv:2012.11382, 2020. https://doi.org/10.48550/arXiv.2012.11382.
- [47] Mark Hodson, Brendan Ruck, Hugh Ong, David Garvin, and Stefan Dulman. Portfolio rebalancing experiments using the quantum alternating operator ansatz. arXiv preprint arXiv:1911.05296, 2019. https://doi.org/10.48550/arXiv.1911.05296.
- [48] Sergi Ramos-Calderer, Adrián Pérez-Salinas, Diego García-Martín, Carlos Bravo-Prieto, Jorge Cortada, Jordi Planagumà, and José I. Latorre. Quantum unary approach to option pricing. Phys. Rev. A, 103:032414, 2021. https://doi.org/10.1103/PhysRevA.103.032414.
- [49] Kensuke Tamura, Tatsuhiko Shirai, Hosho Katsura, Shu Tanaka, and Nozomu Togawa. Performance comparison of typical binary-integer encodings in an ising machine. IEEE Access, 9:81032–81039, 2021. https://doi.org/10.1109/ACCESS.2021.3081685.
- [50] Ludmila Botelho, Adam Glos, Akash Kundu, Jarosław Adam Miszczak, Özlem Salehi, and Zoltán Zimborás. Error mitigation for variational quantum algorithms through mid-circuit measurements. Physical Review A, 105(2):022441, 2022. https://doi.org/10.1103/physreva.105.022441.
- [51] Zhihui Wang, Stuart Hadfield, Zhang Jiang, and Eleanor G Rieffel. Quantum approximate optimization algorithm for maxcut: A fermionic view. Physical Review A, 97(2):022304, 2018. https://doi.org/10.1103/physreva.97.022304.
- [52] Stuart Andrew Hadfield. Quantum algorithms for scientific computing and approximate optimization. Columbia University, 2018. https://doi.org/10.48550/arXiv.1805.03265.
- [53] Matthew B. Hastings. Classical and quantum bounded depth approximation algorithms. quantum Information and Computation, 19(13&14):1116–1140, 2019. https://doi.org/10.26421/QIC19.13-14-3.
- [54] Sergey Bravyi, Alexander Kliesch, Robert Koenig, and Eugene Tang. Obstacles to variational quantum optimization from symmetry protection. Physical Review Letters, 125(26):260505, 2020. https://doi.org/10.1103/physrevlett.125.260505.
- [55] Alexander M Dalzell, Aram W Harrow, Dax Enshan Koh, and Rolando L La Placa. How many qubits are needed for quantum computational supremacy? Quantum, 4:264, 2020. https://doi.org/10.22331/q-2020-05-11-264.
- [56] Daniel Stilck França and Raul Garcia-Patron. Limitations of optimization algorithms on noisy quantum devices. Nature Physics, 17(11):1221–1227, 2021. https://doi.org/10.1038/s41567-021-01356-3.
- [57] Leo Zhou, Sheng-Tao Wang, Soonwon Choi, Hannes Pichler, and Mikhail D Lukin. Quantum approximate optimization algorithm: Performance, mechanism, and implementation on near-term devices. Physical Review X, 10(2):021067, 2020. https://doi.org/10.1103/physrevx.10.021067.
- [58] Boaz Barak and Kunal Marwaha. Classical Algorithms and Quantum Limitations for Maximum Cut on High-Girth Graphs. In Mark Braverman, editor, 13th Innovations in Theoretical Computer Science Conference (ITCS 2022), volume 215 of Leibniz International Proceedings in Informatics (LIPIcs), pages 14:1–14:21, Dagstuhl, Germany, 2022. Schloss Dagstuhl – Leibniz-Zentrum für Informatik. https://doi.org/10.4230/LIPIcs.ITCS.2022.14.
- [59] Lennart Bittel and Martin Kliesch. Training variational quantum algorithms is NP-hard. Physical Review Letters, 127(12):120502, 2021. https://doi.org/10.1103/PhysRevLett.127.120502.
- [60] Kunal Marwaha and Stuart Hadfield. Bounds on approximating Max XOR with quantum and classical local algorithms. Quantum, 6:757, 2022. https://doi.org/10.22331/q-2022-07-07-757.
- [61] A Barış Özgüler and Davide Venturelli. Numerical gate synthesis for quantum heuristics on bosonic quantum processors. Frontiers in Physics, page 724, 2022. https://doi.org/10.3389/fphy.2022.900612.
- [62] Yannick Deller, Sebastian Schmitt, Maciej Lewenstein, Steve Lenk, Marika Federer, Fred Jendrzejewski, Philipp Hauke, and Valentin Kasper. Quantum approximate optimization algorithm for qudit systems with long-range interactions. arXiv preprint arXiv:2204.00340, 2022. https://doi.org/10.1103/physreva.107.062410.
- [63] Stuart Hadfield, Zhihui Wang, Eleanor G Rieffel, Bryan O’Gorman, Davide Venturelli, and Rupak Biswas. Quantum approximate optimization with hard and soft constraints. In Proceedings of the Second International Workshop on Post Moores Era Supercomputing, pages 15–21, 2017. https://doi.org/10.1145/3149526.3149530.
- [64] Nikolaj Moll, Panagiotis Barkoutsos, Lev S Bishop, Jerry M Chow, Andrew Cross, Daniel J Egger, Stefan Filipp, Andreas Fuhrer, Jay M Gambetta, Marc Ganzhorn, et al. Quantum optimization using variational algorithms on near-term quantum devices. Quantum Science and Technology, 3(3):030503, 2018. https://doi.org/10.1088/2058-9565/aab822.
- [65] Sam McArdle, Tyson Jones, Suguru Endo, Ying Li, Simon C Benjamin, and Xiao Yuan. Variational ansatz-based quantum simulation of imaginary time evolution. npj Quantum Information, 5(1):1–6, 2019. https://doi.org/10.1038/s41534-019-0187-2.
- [66] Mario Motta, Chong Sun, Adrian T. K. Tan, Matthew J. O’Rourke, Erika Ye, Austin J. Minnich, Fernando G. S. L. Brandão, and Garnet Kin-Lic Chan. Determining eigenstates and thermal states on a quantum computer using quantum imaginary time evolution. Nature Physics, 16(2):205–210, 2019. https://doi.org/10.1038/s41567-019-0704-4.
- [67] Ryan O’Donnell. Analysis of Boolean functions. Cambridge University Press, 2014.
- [68] Kyle E. C. Booth, Bryan O’Gorman, Jeffrey Marshall, Stuart Hadfield, and Eleanor Rieffel. Quantum-accelerated constraint programming. Quantum, 5:550, September 2021. https://doi.org/10.22331/q-2021-09-28-550.
- [69] Adriano Barenco, Charles H Bennett, Richard Cleve, David P DiVincenzo, Norman Margolus, Peter Shor, Tycho Sleator, John A Smolin, and Harald Weinfurter. Elementary gates for quantum computation. Physical review A, 52(5):3457, 1995. https://doi.org/10.1103/PhysRevA.52.3457.
- [70] V.V. Shende and I.L. Markov. On the CNOT cost of TOFFOLI gates. Quantum Information and Computation, 9(5&6):461–486, 2009. https://doi.org/10.26421/qic8.5-6-8.
- [71] Mehdi Saeedi and Igor L Markov. Synthesis and optimization of reversible circuits—a survey. ACM Computing Surveys (CSUR), 45(2):1–34, 2013. https://doi.org/10.1145/2431211.2431220.
- [72] Gian Giacomo Guerreschi. Solving quadratic unconstrained binary optimization with divide-and-conquer and quantum algorithms. arXiv preprint arXiv:2101.07813, 2021. https://doi.org/10.48550/arXiv.2101.07813.
- [73] Zain H. Saleem, Teague Tomesh, Michael A. Perlin, Pranav Gokhale, and Martin Suchara. Quantum divide and conquer for combinatorial optimization and distributed computing. arXiv preprint arXiv:2107.07532, 2021. https://doi.org/10.48550/arXiv.2107.07532.
- [74] Daniel A Lidar and Todd A Brun. Quantum error correction. Cambridge university press, 2013.
- [75] Nicholas Chancellor. Domain wall encoding of discrete variables for quantum annealing and qaoa. Quantum Science and Technology, 4(4):045004, 2019. https://doi.org/10.1088/2058-9565/ab33c2.
- [76] Jesse Berwald, Nicholas Chancellor, and Raouf Dridi. Understanding domain-wall encoding theoretically and experimentally. Philosophical Transactions of the Royal Society A, 381(2241):20210410, 2023. https://doi.org/10.1098/rsta.2021.0410.
- [77] Jie Chen, Tobias Stollenwerk, and Nicholas Chancellor. Performance of domain-wall encoding for quantum annealing. IEEE Transactions on Quantum Engineering, 2:1–14, 2021. https://doi.org/10.1109/tqe.2021.3094280.
- [78] Mark W Johnson, Mohammad HS Amin, Suzanne Gildert, Trevor Lanting, Firas Hamze, Neil Dickson, Richard Harris, Andrew J Berkley, Jan Johansson, Paul Bunyk, et al. Quantum annealing with manufactured spins. Nature, 473(7346):194–198, 2011. https://doi.org/10.1038/nature10012.
- [79] Zoe Gonzalez Izquierdo, Shon Grabbe, Stuart Hadfield, Jeffrey Marshall, Zhihui Wang, and Eleanor Rieffel. Ferromagnetically shifting the power of pausing. Physical Review Applied, 15(4):044013, 2021. https://doi.org/10.1103/physrevapplied.15.044013.
- [80] Davide Venturelli and Alexei Kondratyev. Reverse quantum annealing approach to portfolio optimization problems. Quantum Machine Intelligence, 1(1):17–30, 2019. https://doi.org/10.1007/s42484-019-00001-w.
- [81] Nike Dattani, Szilard Szalay, and Nick Chancellor. Pegasus: The second connectivity graph for large-scale quantum annealing hardware. arXiv preprint arXiv:1901.07636, 2019. https://doi.org/10.48550/arXiv.1901.07636.
- [82] Wolfgang Lechner, Philipp Hauke, and Peter Zoller. A quantum annealing architecture with all-to-all connectivity from local interactions. Science advances, 1(9):e1500838, 2015. https://doi.org/10.1126/sciadv.1500838.
- [83] MS Sarandy and DA Lidar. Adiabatic quantum computation in open systems. Physical review letters, 95(25):250503, 2005. https://doi.org/10.1103/physrevlett.95.250503.
- [84] MHS Amin, Peter J Love, and CJS Truncik. Thermally assisted adiabatic quantum computation. Physical review letters, 100(6):060503, 2008. https://doi.org/10.1103/physrevlett.100.060503.
- [85] Sergio Boixo, Tameem Albash, Federico M Spedalieri, Nicholas Chancellor, and Daniel A Lidar. Experimental signature of programmable quantum annealing. Nature communications, 4(1):2067, 2013. https://doi.org/10.1038/ncomms3067.
- [86] Kostyantyn Kechedzhi and Vadim N Smelyanskiy. Open-system quantum annealing in mean-field models with exponential degeneracy. Physical Review X, 6(2):021028, 2016. https://doi.org/10.1103/physrevx.6.021028.
- [87] Gianluca Passarelli, Ka-Wa Yip, Daniel A Lidar, and Procolo Lucignano. Standard quantum annealing outperforms adiabatic reverse annealing with decoherence. Physical Review A, 105(3):032431, 2022. https://doi.org/10.1103/physreva.105.032431.
- [88] Stefanie Zbinden, Andreas Bärtschi, Hristo Djidjev, and Stephan Eidenbenz. Embedding algorithms for quantum annealers with chimera and pegasus connection topologies. In International Conference on High Performance Computing, pages 187–206. Springer, 2020. https://doi.org/10.1007/978-3-030-50743-5_10.
- [89] Mario S Könz, Wolfgang Lechner, Helmut G Katzgraber, and Matthias Troyer. Embedding overhead scaling of optimization problems in quantum annealing. PRX Quantum, 2(4):040322, 2021. https://doi.org/10.1103/prxquantum.2.040322.
- [90] Aniruddha Bapat and Stephen Jordan. Bang-bang control as a design principle for classical and quantum optimization algorithms. arXiv preprint arXiv:1812.02746, 2018. https://doi.org/10.26421/qic19.5-6-4.
- [91] Ruslan Shaydulin, Stuart Hadfield, Tad Hogg, and Ilya Safro. Classical symmetries and the quantum approximate optimization algorithm. Quantum Information Processing, 20(11):1–28, 2021. https://doi.org/10.48550/arXiv.2012.04713.
- [92] Vishwanathan Akshay, Daniil Rabinovich, Ernesto Campos, and Jacob Biamonte. Parameter concentrations in quantum approximate optimization. Physical Review A, 104(1):L010401, 2021. https://doi.org/10.1103/physreva.104.l010401.
- [93] Michael Streif and Martin Leib. Training the quantum approximate optimization algorithm without access to a quantum processing unit. Quantum Science and Technology, 5(3):034008, 2020. https://doi.org/10.1088/2058-9565/ab8c2b.
- [94] Guillaume Verdon, Michael Broughton, Jarrod R McClean, Kevin J Sung, Ryan Babbush, Zhang Jiang, Hartmut Neven, and Masoud Mohseni. Learning to learn with quantum neural networks via classical neural networks. arXiv preprint arXiv:1907.05415, 2019. https://doi.org/10.48550/arXiv.1907.05415.
- [95] Max Wilson, Rachel Stromswold, Filip Wudarski, Stuart Hadfield, Norm M Tubman, and Eleanor G Rieffel. Optimizing quantum heuristics with meta-learning. Quantum Machine Intelligence, 3(1):1–14, 2021. https://doi.org/10.1007/s42484-020-00022-w.
- [96] Alicia B Magann, Kenneth M Rudinger, Matthew D Grace, and Mohan Sarovar. Feedback-based quantum optimization. Physical Review Letters, 129(25):250502, 2022. https://doi.org/10.1103/physrevlett.129.250502.
- [97] Lucas T Brady, Christopher L Baldwin, Aniruddha Bapat, Yaroslav Kharkov, and Alexey V Gorshkov. Optimal protocols in quantum annealing and quantum approximate optimization algorithm problems. Physical Review Letters, 126(7):070505, 2021. https://doi.org/10.1103/physrevlett.126.070505.
- [98] Jonathan Wurtz and Peter J Love. Counterdiabaticity and the quantum approximate optimization algorithm. Quantum, 6:635, 2022. https://doi.org/10.22331/q-2022-01-27-635.
- [99] Andreas Bärtschi and Stephan Eidenbenz. Grover mixers for QAOA: Shifting complexity from mixer design to state preparation. In 2020 IEEE International Conference on Quantum Computing and Engineering (QCE), pages 72–82. IEEE, 2020. https://doi.org/10.1109/qce49297.2020.00020.
- [100] Daniel J Egger, Jakub Mareček, and Stefan Woerner. Warm-starting quantum optimization. Quantum, 5:479, 2021. https://doi.org/10.22331/q-2021-06-17-479.
- [101] Jonathan Wurtz and Peter J Love. Classically optimal variational quantum algorithms. IEEE Transactions on Quantum Engineering, 2:1–7, 2021. https://doi.org/10.1109/tqe.2021.3122568.
- [102] Xiaoyuan Liu, Anthony Angone, Ruslan Shaydulin, Ilya Safro, Yuri Alexeev, and Lukasz Cincio. Layer VQE: A variational approach for combinatorial optimization on noisy quantum computers. IEEE Transactions on Quantum Engineering, 3:1–20, 2022. https://doi.org/10.1109/tqe.2021.3140190.
- [103] Jarrod R McClean, Sergio Boixo, Vadim N Smelyanskiy, Ryan Babbush, and Hartmut Neven. Barren plateaus in quantum neural network training landscapes. Nature communications, 9(1):1–6, 2018. https://doi.org/10.1038/s41467-018-07090-4.
- [104] Linghua Zhu, Ho Lun Tang, George S Barron, FA Calderon-Vargas, Nicholas J Mayhall, Edwin Barnes, and Sophia E Economou. Adaptive quantum approximate optimization algorithm for solving combinatorial problems on a quantum computer. Physical Review Research, 4(3):033029, 2022. https://doi.org/10.1103/physrevresearch.4.033029.
- [105] Bence Bakó, Adam Glos, Özlem Salehi, and Zoltán Zimborás. Near-optimal circuit design for variational quantum optimization. arXiv preprint arXiv:2209.03386, 2022. https://doi.org/10.48550/arXiv.2209.03386.
- [106] Itay Hen and Marcelo S Sarandy. Driver hamiltonians for constrained optimization in quantum annealing. Physical Review A, 93(6):062312, 2016. https://doi.org/10.1103/physreva.93.062312.
- [107] Itay Hen and Federico M Spedalieri. Quantum annealing for constrained optimization. Physical Review Applied, 5(3):034007, 2016. https://doi.org/10.1103/PhysRevApplied.5.034007.
- [108] Yue Ruan, Samuel Marsh, Xilin Xue, Xi Li, Zhihao Liu, and Jingbo Wang. Quantum approximate algorithm for NP optimization problems with constraints. arXiv preprint arXiv:2002.00943, 2020. https://doi.org/10.48550/arXiv.2002.00943.
- [109] Michael A. Nielsen and Isaac L. Chuang. Quantum Computation and Quantum Information: 10th Anniversary Edition. Cambridge University Press, New York, NY, USA, 10th edition, 2011.
- [110] Masuo Suzuki. Decomposition formulas of exponential operators and Lie exponentials with some applications to quantum mechanics and statistical physics. Journal of mathematical physics, 26(4):601–612, 1985. https://doi.org/10.1063/1.526596.
- [111] Michael Streif, Martin Leib, Filip Wudarski, Eleanor Rieffel, and Zhihui Wang. Quantum algorithms with local particle-number conservation: Noise effects and error correction. Physical Review A, 103(4):042412, 2021. https://doi.org/10.1103/physreva.103.042412.
- [112] Vishwanathan Akshay, Hariphan Philathong, Mauro ES Morales, and Jacob D Biamonte. Reachability deficits in quantum approximate optimization. Physical review letters, 124(9):090504, 2020. https://doi.org/10.22331/q-2021-08-30-532.
- [113] Franz Georg Fuchs, Kjetil Olsen Lye, Halvor Møll Nilsen, Alexander Johannes Stasik, and Giorgio Sartor. Constraint preserving mixers for the quantum approximate optimization algorithm. Algorithms, 15(6):202, 2022. https://doi.org/10.3390/a15060202.
- [114] Vandana Shukla, O. P. Singh, G. R. Mishra, and R. K. Tiwari. Application of CSMT gate for efficient reversible realization of binary to gray code converter circuit. In 2015 IEEE UP Section Conference on Electrical Computer and Electronics (UPCON). IEEE, dec 2015. https://doi.org/10.1109/UPCON.2015.7456731.
- [115] Alexander Slepoy. Quantum gate decomposition algorithms. Technical report, Sandia National Laboratories, 2006. https://doi.org/10.2172/889415.
- [116] Bryan T. Gard, Linghua Zhu, George S. Barron, Nicholas J. Mayhall, Sophia E. Economou, and Edwin Barnes. Efficient symmetry-preserving state preparation circuits for the variational quantum eigensolver algorithm. npj Quantum Information, 6(1), 2020. https://doi.org/10.1038/s41534-019-0240-1.
- [117] D.P. DiVincenzo and J. Smolin. Results on two-bit gate design for quantum computers. In Proceedings Workshop on Physics and Computation. PhysComp 94. IEEE Comput. Soc. Press, 1994. https://doi.org/10.48550/arXiv.cond-mat/9409111.
- [118] David Joseph, Adam Callison, Cong Ling, and Florian Mintert. Two quantum ising algorithms for the shortest-vector problem. Physical Review A, 103(3):032433, 2021. https://doi.org/10.1103/PhysRevA.103.032433.
- [119] Peter Brucker. Scheduling Algorithms. Springer-Verlag Berlin Heidelberg, 2004.
- [120] AMA Hariri and Chris N Potts. Single machine scheduling with batch set-up times to minimize maximum lateness. Annals of Operations Research, 70:75–92, 1997. https://doi.org/10.1023/A:1018903027868.
- [121] Xiaoqiang Cai, Liming Wang, and Xian Zhou. Single-machine scheduling to stochastically minimize maximum lateness. Journal of Scheduling, 10(4):293–301, 2007. https://doi.org/10.1007/s10951-007-0026-8.
- [122] Derya Eren Akyol and G Mirac Bayhan. Multi-machine earliness and tardiness scheduling problem: an interconnected neural network approach. The International Journal of Advanced Manufacturing Technology, 37(5):576–588, 2008. https://doi.org/10.1007/s00170-007-0993-0.
- [123] Michele Conforti, Gérard Cornuéjols, Giacomo Zambelli, et al. Integer programming, volume 271. Springer, 2014.
- [124] Hannes Leipold and Federico M Spedalieri. Constructing driver hamiltonians for optimization problems with linear constraints. Quantum Science and Technology, 7(1):015013, 2021. https://doi.org/10.1088/2058-9565/ac16b8.
- [125] Masuo Suzuki. Generalized Trotter’s formula and systematic approximants of exponential operators and inner derivations with applications to many-body problems. Communications in Mathematical Physics, 51(2):183–190, 1976. https://doi.org/10.1007/BF01609348.
- [126] Dominic W. Berry and Andrew M. Childs. Black-box hamiltonian simulation and unitary implementation. Quantum Info. Comput., 12(1–2):29–62, 2012. https://doi.org/10.26421/qic12.1-2-4.
- [127] D. W. Berry, A. M. Childs, and R. Kothari. Hamiltonian simulation with nearly optimal dependence on all parameters. In 2015 IEEE 56th Annual Symposium on Foundations of Computer Science, pages 792–809, 2015. https://doi.org/10.1109/FOCS.2015.54.
- [128] Dominic W. Berry, Andrew M. Childs, Richard Cleve, Robin Kothari, and Rolando D. Somma. Simulating Hamiltonian dynamics with a truncated Taylor series. Physical Review Letters, 114(9):090502, 2015. https://doi.org/10.1103/PhysRevLett.114.090502.
- [129] Guang Hao Low and Isaac L. Chuang. Optimal hamiltonian simulation by quantum signal processing. Phys. Rev. Lett., 118:010501, 2017. https://doi.org/10.1103/PhysRevLett.118.010501.
- [130] Guang Hao Low and Isaac L. Chuang. Hamiltonian simulation by qubitization. Quantum, 3:163, 2019. https://doi.org/10.22331/q-2019-07-12-163.
- [131] Andrew M. Childs, Aaron Ostrander, and Yuan Su. Faster quantum simulation by randomization. Quantum, 3:182, 2019. https://doi.org/10.22331/q-2019-09-02-182.
- [132] Earl Campbell. Random Compiler for Fast Hamiltonian Simulation. Physical Review Letters, 123(7):070503, 2019. https://doi.org/10.1103/PhysRevLett.123.070503.
- [133] Andrew M. Childs, Yuan Su, Minh C. Tran, Nathan Wiebe, and Shuchen Zhu. Theory of trotter error with commutator scaling. Phys. Rev. X, 11:011020, 2021. https://doi.org/10.1103/PhysRevX.11.011020.
- [134] Albert T Schmitz, Nicolas PD Sawaya, Sonika Johri, and AY Matsuura. Graph optimization perspective for low-depth trotter-suzuki decomposition. arXiv preprint arXiv:2103.08602, 2021. https://doi.org/10.48550/arXiv.2103.08602.
- [135] Nicolas PD Sawaya. mat2qubit: A lightweight pythonic package for qubit encodings of vibrational, bosonic, graph coloring, routing, scheduling, and general matrix problems. arXiv preprint arXiv:2205.09776, 2022. https://doi.org/10.48550/arXiv.2205.09776.
- [136] Pauli Virtanen, Ralf Gommers, Travis E. Oliphant, Matt Haberland, Tyler Reddy, David Cournapeau, Evgeni Burovski, Pearu Peterson, Warren Weckesser, Jonathan Bright, Stéfan J. van der Walt, Matthew Brett, Joshua Wilson, K. Jarrod Millman, Nikolay Mayorov, Andrew R. J. Nelson, Eric Jones, Robert Kern, Eric Larson, C J Carey, İlhan Polat, Yu Feng, Eric W. Moore, Jake VanderPlas, Denis Laxalde, Josef Perktold, Robert Cimrman, Ian Henriksen, E. A. Quintero, Charles R. Harris, Anne M. Archibald, Antônio H. Ribeiro, Fabian Pedregosa, Paul van Mulbregt, and SciPy 1.0 Contributors. SciPy 1.0: Fundamental Algorithms for Scientific Computing in Python. Nature Methods, 17:261–272, 2020. https://doi.org/10.1038/s41592-019-0686-2.
- [137] Jarrod R McClean, Nicholas C Rubin, Kevin J Sung, Ian D Kivlichan, Xavier Bonet-Monroig, Yudong Cao, Chengyu Dai, E Schuyler Fried, Craig Gidney, Brendan Gimby, et al. Openfermion: the electronic structure package for quantum computers. Quantum Science and Technology, 5(3):034014, 2020. https://doi.org/10.1088/2058-9565/ab8ebc.
- [138] Aaron Meurer, Christopher P Smith, Mateusz Paprocki, Ondřej Čertík, Sergey B Kirpichev, Matthew Rocklin, AMiT Kumar, Sergiu Ivanov, Jason K Moore, Sartaj Singh, et al. Sympy: symbolic computing in Python. PeerJ Computer Science, 3:e103, 2017. https://doi.org/10.7717/peerj-cs.103.
- [139] Pradnya Khalate, Xin-Chuan Wu, Shavindra Premaratne, Justin Hogaboam, Adam Holmes, Albert Schmitz, Gian Giacomo Guerreschi, Xiang Zou, and AY Matsuura. An LLVM-based C++ compiler toolchain for variational hybrid quantum-classical algorithms and quantum accelerators. arXiv preprint arXiv:2202.11142, 2022. https://doi.org/10.48550/arXiv.2202.11142.
- [140] C. A. Ryan, C. Negrevergne, M. Laforest, E. Knill, and R. Laflamme. Liquid-state nuclear magnetic resonance as a testbed for developing quantum control methods. Phys. Rev. A, 78:012328, Jul 2008. https://doi.org/10.1103/PhysRevA.78.012328.
- [141] Richard Versluis, Stefano Poletto, Nader Khammassi, Brian Tarasinski, Nadia Haider, David J Michalak, Alessandro Bruno, Koen Bertels, and Leonardo DiCarlo. Scalable quantum circuit and control for a superconducting surface code. Physical Review Applied, 8(3):034021, 2017. https://doi.org/10.1103/physrevapplied.8.034021.
- [142] Bjoern Lekitsch, Sebastian Weidt, Austin G Fowler, Klaus Mølmer, Simon J Devitt, Christof Wunderlich, and Winfried K Hensinger. Blueprint for a microwave trapped ion quantum computer. Science Advances, 3(2):e1601540, 2017. https://doi.org/10.1126/sciadv.1601540.