
Machine Learning Protocols And Methods
Machine Learning, a branch of Artificial Intelligence that gives computers the capability to learn without being explicitly programmed.
Recently cited
-
ArticleNature Methods
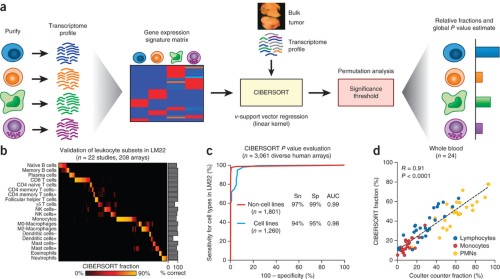
Robust enumeration of cell subsets from tissue expression profiles
, , , ...
-
PerspectiveNature Methods
The Perseus computational platform for comprehensive analysis of (prote)omics data
, , , ...
-
PerspectiveNature Methods
ilastik: interactive machine learning for (bio)image analysis
, , , ...
Recently published
-
ProtocolSpringer Protocols
Predicting Tumor Growth and Ligand Dependence from mRNA by Combining Machine Learning with Mechanistic Modeling
, Andreas Raue
-
OverviewSpringer Protocols
Machine Learning Techniques for Development of Drugs Against Coronavirus Disease 2019 (COVID-19): A Case Study Protocol
, , , Bikash Medhi
-
OverviewSpringer Protocols
Deep Learning-Based Drug Screening for COVID-19 and Case Studies
, , , , Yanjie Wei



Review papers
-
OverviewSpringer Protocols
A Non-technical Introduction to Machine Learning
Olivier Colliot
-
OverviewSpringer Protocols
Machine Learning and Brain Imaging for Psychiatric Disorders: New Perspectives
, , , Josselin Houenou
Psychiatric disorders include a broad panel of heterogeneous conditions. Among the most severe psychiatric diseases, in intensity and incidence, depression will affect 15–20% of the population in their lifetime, schizophrenia 0.7–1%, and bipolar
…more

Related Techniques
-
ProtocolSpringer Protocols
Artificial Intelligence in Drug Safety and Metabolism
Graham F. Smith
-
ProtocolSpringer Protocols
Developmental Toxicity Prediction
Raghuraman Venkatapathy
,
-
ProtocolSpringer Protocols
In Silico Prediction Method for Protein Asparagine Deamidation
Lei Jia
,
-
ProtocolSpringer Protocols
Application of Artificial Neural Network and Genetic Algorithm Modeling for In Vitro Regeneration of Seaweed Seedling Production
, , Vaibhav A. Mantri
-
ProtocolSpringer Protocols
Ensemble Classifiers for Multiclass MicroRNA Classification
, , Malik Yousef
-
ProtocolSpringer Protocols
Prediction of Peptide and TCR CDR3 Loops in Formation of Class I MHC-Peptide-TCR Complexes Using Molecular Models with Solvation
, , , ...
-
ProtocolSpringer Protocols
Systems Biology Approaches to Understanding COVID-19 Spread in the Population
, , Marko Djordjevic
-
ProtocolSpringer Protocols
Machine Learning to Predict Teratogenicity: Theory and Practice
-
ArticleNature Methods
Large-scale foundation model on single-cell transcriptomics
, , , ...
-
OverviewSpringer Protocols
Knowledge Graphs and Their Applications in Drug Discovery
Tim James
,
Advertisement
Broader concepts
- Machine Learning