Comparison between k2 CTC loss and PyTorch CTC loss #575
Comments
|
That's interesting. |
|
Also it would be nice if someone could compute the sum of the derivative (.grad) of our CTC loss and make sure the sum on each frame of each sequence is close to 1.0. [if we can somehow access the .grad w.r.t. the nnet output]. |
|
Using random initialized transformer model, the first 10 iteration loss computed with K2CTCLoss and torch.nn.CTCLoss are:
Using transformer model trained with torch.nn.CTCLoss for 10 epoch, the first 10 iteration loss computed with K2CTCLoss and torch.nn.CTCLoss are:
It seems that we can get a similar loss value with random initialized model but not a pretrained model. |
|
Thanks a lot!! For the transformer model, can you clarify how you were training it? Was it with one of the two CTC losses? |
|
And in the 2nd table, can you clarify if you were training with the same loss functions you were evaluating? |
|
In the 2nd table, the pretrained transformer model is trained with torch.nn.CTCLoss only. And then the training and loss calculation used the same loss function. |
|
OK, but what I want is for you to train with the torch loss and evaluate with k2 CTC loss, with the same model. So same code will evaluate 2 objectives. With the random transformer model, what are the iterations? That is, what objective are you training with? |
|
Sorry for the misunderstanding. In the 1st table above (random transformer model results), the two column are trained with K2CTCLoss and torch.nn.CTCLoss as objective respectively. |
|
So if you train with the PyTorch loss and evaluate also with the k2 one, you'll get the same value? Because in iteration 1 of your 2nd table, they're very different... if you showed iteration 0, would the k2 one be the same? |
|
I checked the code and find a bug which accidently make the two loss function the same. The real results is : with a random initialized model, the two losses are similar. With a pretrained model, the two losses are very different. I will paste the results bellow. |
|
The training objective is torch.nn.CTCLoss and the evaluation is performed on both K2CTCLoss and torch.nn.CTCLoss
|
|
OK. WIthout seeing the code it will be hard to comment much further or help debug. |
|
Thanks a lot for your help! If anyone is interested, my K2CTCLoss implementation is in https://github.com/zhu-han/espnet-k2/blob/main/espnet/nets/pytorch_backend/ctc_graph.py. |
|
[re-posting directly, mail is unreliable.] Basically, your graphs are in the wrong order. |
|
You are not using 'indices' to sort the FSAs in the graphs.
I'm not sure if our Fsa object has an operator [] that can take a Tensor,
but it might.
Basically, your graphs are in the wrong order.
You could also possibly reorder `targets` and `target_lengths` before
compiling the graph.
…On Fri, Jan 8, 2021 at 10:19 PM Han Zhu ***@***.***> wrote:
Thanks a lot for your help! If anyone is intrested, my K2CTCLoss
implementation is in
https://github.com/zhu-han/espnet-k2/blob/main/espnet/nets/pytorch_backend/ctc_graph.py
.
—
You are receiving this because you commented.
Reply to this email directly, view it on GitHub
<#575 (comment)>, or
unsubscribe
<https://github.com/notifications/unsubscribe-auth/AAZFLO6YXZHFVCXH35WNLXLSY4H7JANCNFSM4V2H7NEQ>
.
|
|
possibly would work (not sure though) |
|
Thanks for your help! I will change my code accordingly and do the experiments. |
|
@zhu-han, thanks for sharing your interesting report. |
|
After fixing the graph order issue, K2CTCLoss could work with Transformer now. With bpe 500 as CTC modeling unit, the loss curve is like: And previous results make sense now. Before making batch, the training samples is sorted according to input length. So with a smaller batch size, all samples in the same batch is more likely to have the same length. With the same length, the sorted text could match the order of unsorted graph. In my experiments, BLSTM has smaller batch size than Transformers (20 vs 256), so BLSTM suffers less than Transformer because of this bug. That's why BLSTM could work and Transformer could not work in previous results. Thanks a lot! |
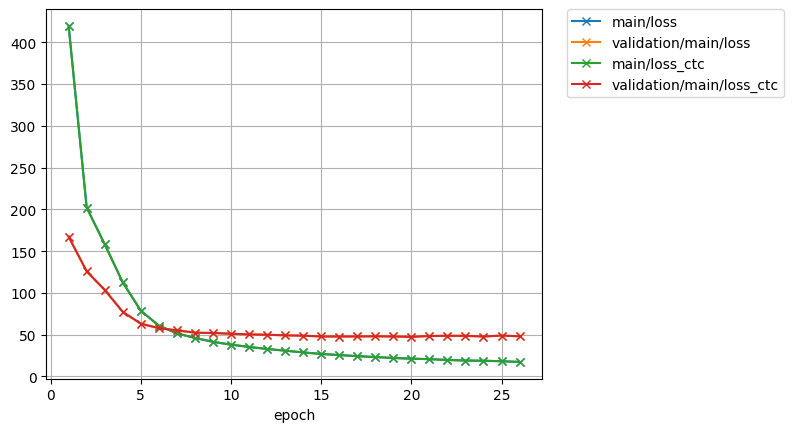
|
@sw005320 My revised K2CTCLoss is in https://github.com/zhu-han/espnet-k2/blob/main/espnet/nets/pytorch_backend/ctc_graph.py. I will be glad to help on this. |
|
I just added gradients test for k2 CTC loss. Please see #577 It shows that k2 CTC loss is identical to PyTorch CTC loss and warp-ctc when they are given the same input. The gradients of k2 and PyTorch are also the same. |
|
Thanks! But since I find models trained with k2 CTC loss and PyTorch CTC loss did have some differences, I added additional test cases baed on
It seems with longer samples, the difference is larger. |
|
And these are the results I got on librispeech 100h using PyTorch CTC loss and k2 CTC loss:
Detailed setup:
|
|
Cool! |
|
Given the same input, the PyTorch CTC gradient sum per frame is: |
|
That must be prior to the softmax. Can you get it after the softmax?
…On Sun, Jan 10, 2021 at 12:26 PM Han Zhu ***@***.***> wrote:
Given the same input, the PyTorch CTC gradient sum per frame is:
[ 0.0000e+00, 2.3842e-07, -3.5763e-07, -2.3842e-07, -3.5763e-07,...]
and the k2 CTC gradient sum per frame is:
[-1.1921e-06, -2.3842e-07, 1.0729e-06, 8.3447e-07, 4.7684e-07,...]
—
You are receiving this because you commented.
Reply to this email directly, view it on GitHub
<#575 (comment)>, or
unsubscribe
<https://github.com/notifications/unsubscribe-auth/AAZFLO6GAEBOJEFYOVVG5V3SZET7FANCNFSM4V2H7NEQ>
.
|
|
Those was already after softmax results. It's sum is 5.2452e-06. k2 gradient of this same frame is: And it's sum is -8.5831e-06 These two gradients only have one different value: -9.4860 vs -9.4859 in the first dimension. |
|
doesnt look right. .gradient after.softmax should sum to one, is.equal to
posterior.
…On Sunday, January 10, 2021, Han Zhu ***@***.***> wrote:
It was after softmax result.
for example, the torch gradient for one frame is:
[ -9.4860, 2.4738, 5.9179, 4.7736, 5.5900, 2.8961, 6.4206,
4.4688, 2.8942, 4.0882, -74.9657, 4.3691, 5.7488, 6.3485,
6.4876, 2.9647, 3.2492, 4.7775, 3.5132, 2.7532, 4.7165]
It's sum is 5.2452e-06.
k2 gradient of this same frame is:
[ -9.4859, 2.4738, 5.9179, 4.7736, 5.5900, 2.8961, 6.4206,
4.4688, 2.8942, 4.0882, -74.9657, 4.3691, 5.7488, 6.3485,
6.4876, 2.9647, 3.2492, 4.7775, 3.5132, 2.7532, 4.7165]
And it's sum is -8.5831e-06
These two gradients only have one different value: -9.4860 vs -9.4859 in
the first dimension
—
You are receiving this because you commented.
Reply to this email directly, view it on GitHub
<#575 (comment)>, or
unsubscribe
<https://github.com/notifications/unsubscribe-auth/AAZFLOY2WDPP5WBQWAX7H7LSZEWPPANCNFSM4V2H7NEQ>
.
|
|
Oh, I misunderstand that ,I thought you mean the loss was computed prior to the softmax. I will update results. |
|
When I set learning rate as 1 and use k2 CTC loss, the gradient sum per frame of the tensor after logsoftmax is -1. I'm not sure it is what you want to check. |
|
Yes that sounds right. See if the same is true of PyTorch's one; the error could be there. |
|
For PyTorch, these values is near to 0, i.e.,[-4.7088e-6, -4.6492e-6, ...] |
|
Ah, I guess it does the normalization internally. |
|
For the simplest case, And if the target label is
|
|
PyTorch is obviously doing the log-softmax normalization as part of the CTC computation; in k2 those things are separate. |
|
Do we know of any difference in speed? |
@sw005320 Could you share the progress with us? Does the comparison include speed differences? |
|
I tested these different CTC modes in espnet with these results on voxforge italian eval:
Previously I was able to compare the speeds of pytorch vs warp vs gtn, but for k2 I used a different device. I'll provide an update with speed comparisons shortly. |
|
When training on librispeech 100h for one epoch, the results are:
|
|
OK thanks.
Was that in debug or release mode? (It can be quite different).
In debug mode, there is a speed boost from doing
export K2_DISABLE_CHECKS=1
prior to running it.
We have a lot of checking code active by default right not.
…On Thu, Jan 14, 2021 at 2:17 PM Han Zhu ***@***.***> wrote:
When training on librispeech 100h for one epoch, the results are:
Method Time
PyTorch 15.69 min
k2 17.78 min
—
You are receiving this because you commented.
Reply to this email directly, view it on GitHub
<#575 (comment)>, or
unsubscribe
<https://github.com/notifications/unsubscribe-auth/AAZFLO6WQSNO2HU5B2YPRKDSZ2D6VANCNFSM4V2H7NEQ>
.
|
|
I followed https://k2.readthedocs.io/en/latest/installation.html#install-k2-from-source to install k2. Is this in release mode by default? |
If you followed it step by step, then it is a |
|
Yes, it is in release mode then. |
should tell you whether |
|
It shows |
|
OK. When was the code pulled? there may have been speed improvements.
…On Thu, Jan 14, 2021 at 3:54 PM Han Zhu ***@***.***> wrote:
It shows Build type: Release.
—
You are receiving this because you commented.
Reply to this email directly, view it on GitHub
<#575 (comment)>, or
unsubscribe
<https://github.com/notifications/unsubscribe-auth/AAZFLO6536EOWLFSN7BVCC3SZ2PLFANCNFSM4V2H7NEQ>
.
|
|
Pulled on 2021/01/06. |
|
OK, probably no speed optimizations since then.
…On Thu, Jan 14, 2021 at 4:10 PM Han Zhu ***@***.***> wrote:
Pulled on 2021/01/06.
—
You are receiving this because you commented.
Reply to this email directly, view it on GitHub
<#575 (comment)>, or
unsubscribe
<https://github.com/notifications/unsubscribe-auth/AAZFLO22D7SFPE63U2BYDH3SZ2RG3ANCNFSM4V2H7NEQ>
.
|
|
This pull-request #571 (comment), merged on Jan 8, made |
|
Tried with the latest k2, training time is similar. Previous training time is 17.78 min and the latest one is 17.68 min. |
|
Which version of CUDA Toolkit are you using? The change is enabled only for NVCC version > 10.1.105. |
|
I'm using CUDA 10.1, NVCC version 10.1.243 |
|
That function wasn't the bottleneck anyway.
We can optimize more later. Anyway our code is more general than torch's
one (e.g. supports lexicons) so there are fewer
opportunities for optimization.
…On Thu, Jan 14, 2021 at 10:08 PM Han Zhu ***@***.***> wrote:
I'm using CUDA 10.1, NVCC version 10.1.243
—
You are receiving this because you commented.
Reply to this email directly, view it on GitHub
<#575 (comment)>, or
unsubscribe
<https://github.com/notifications/unsubscribe-auth/AAZFLOYZCNBI5I3OPOJNLF3SZ33FFANCNFSM4V2H7NEQ>
.
|
In test_case3, when I change the input to |
|
How different are they? |
|
Repeats symbols are already handled by the current CTC topology as standard CTC loss does, and I don't think there's a difference between them. |
|
It is definitely expected to affect the gradient. In our implementation we don't do that as part of the FSA stuff, it is a separate component, so our CTC loss needs the log-softmax. |
Has anyone compaired the performance between k2 CTC loss implementation and the CTCLoss in PyTorch?
I tried to write a K2CTCLoss with k2 to replace torch.nn.CTCLoss and did some experiments using ESPnet. It shows there is a gap between K2CTCLoss and torch.nn.CTCLoss.
The experiments are conducted on Librispeech 100h and the training criterion is CTC only. Acoustic model is BLSTM or Transformer based encoder. For CTC modeling unit, I tried char and bpe 5000. Here are some conclusions of my experiments:
K2CTCLoss could work with BLSTM based acoustic model, though torch.nn.CTCLoss could reduce the loss faster;
K2CTCLoss did't work with Transformer. When using bpe 5000 as CTC modeling unit, the loss curve of K2CTCLoss would be like :
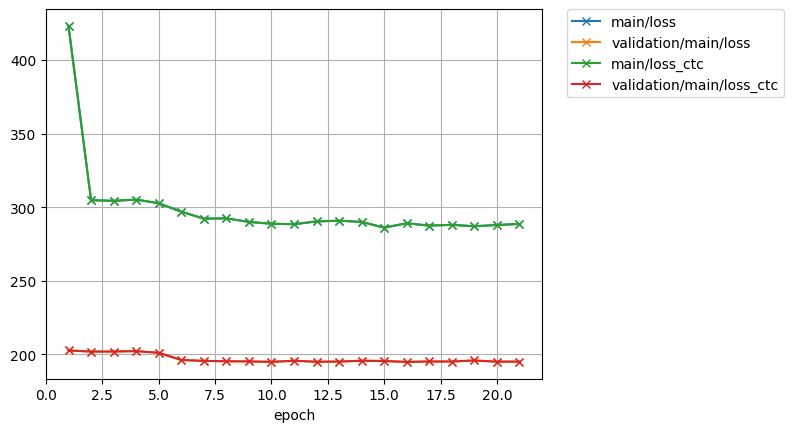
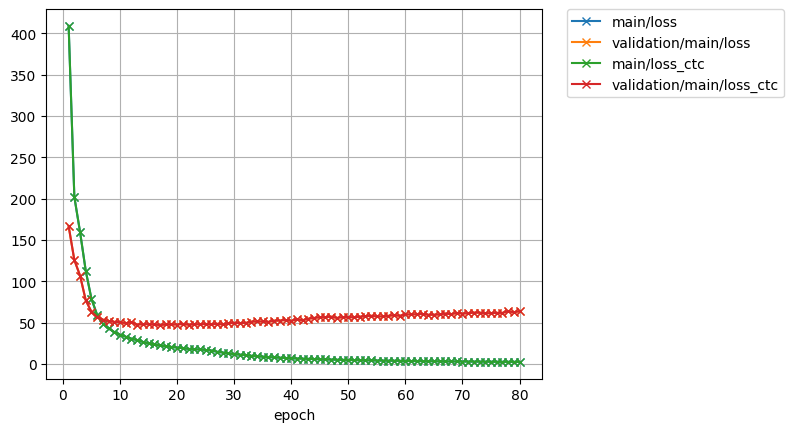
In comparison, torch.nn.CTCLoss with Transformer is like:
The above conclusions are the same when CTC modeling unit is char or bpe 5000.
In snowfall, the CTC implementation is (1) acoustic feature->phone->word. I did a experiment using the K2CTCLoss with (2) acoustic feature->char structure. And the WERs are (1) 12.84% and (2) 15.99% respectively. So I think the K2CTCLoss implementation should be fine.
Could anyone give me some advice on how to make it work better? And does anyone know why it can't work well with transformer? Thanks!
The text was updated successfully, but these errors were encountered: