
2024-01-17 機械学習勉強会
Mastering All YOLO Models from YOLOv1 to YOLO-NAS: Papers Explained (2024) Part1概要IntroductionObject DetectionとはYOLOの歴史簡単な年表YOLOv1YOLOv2YOLOv3YOLOv4YOLOv5 ~参考記事
Mastering All YOLO Models from YOLOv1 to YOLO-NAS: Papers Explained (2024) Part1
概要
- 2015年に登場したYOLOv1から最新のYOLO-NASまでの包括的なまとめ記事
- 細かいところは別記事などを参考にしつつまとめています
- 今回はYOLOv4まで。次回をお楽しみに。

Introduction
- YOLOとは
- 元々はCVPR 2016で公開されたsingle-stageの物体検出モデル
- 低レイテンシと高い精度を達成したと話題になった
- YOLOシリーズは今日までの物体検出モデルのコンセプトを形作っている
- ほとんどのYOLOモデルはsmall, medium, large全ての規模感に対応できるようになっている
- ONNX, TensorRT, OpenVINOなどで簡単にシリアライズできる
Object Detectionとは
- Object Detectionは物体の位置とその物体の分類として定義される
- 要するに物体のBBoxとそれが何かを分類する手法
- 長方形しか出力できないので、物体の形状までを特定したい場合はSegmentationを行う必要がある

- 古典的手法
- HOG (Histogram of Oriented Gradients) Feature + SVM: 正例と負例のHOG特徴をもとにSVMを訓練する
- Bag of features: 画像を画像特徴の順序のない集合として表す
- Viola-Jones アルゴリズム: リアルタイムの顔検出を可能にしたアルゴリズム。積分画像やHaar-like特徴、Adaboost、カスケード分類器などを利用して2001年ごろに2fpsほどの顔検出を可能にした
- 上記のような方法は特定のユースケースに特化しており、汎化性能が低かったため、その後Deep Learningベースの手法へと方向転換されるようになった
Overfeat (2013)という論文が先駆者。Sliding Window方式でさまざまなスケールで画像分類を実行し、更に同じCNNレイヤーでBBox回帰を行う

- 物体検出の課題
- オクルージョンと小さいオブジェクト
- 小さいオブジェクトは情報量が少ないため検出が難しい。
- オクルージョンなどによって部分的にしか見えない場合は更に難しくなる
- Global Context と Local Contexts
- グローバルな情報は例えば、信号機は主に道路の脇に見られるとか近くに車や歩行者が見られるといったもの
- ローカルな情報は例えば、信号機自体のテクスチャや幾何学的構造のようなもの
- これらの情報を適切にモデルが利用できなければならない。適切に訓練を行えば、車の後部に移った赤信号を誤検出することはなくなる。
YOLOの歴史
簡単な年表
- CVPR 2016で当時最先端のSingle-stage DetectorであるYOLOが発表された
- CVPR 2017では、YOLOv1を更に高速かつ正確にしたYOLOv2が発表。
- 2018年には、同じ著者がYOLOv2にネック構造を追加し、大きなbackboneを使うことでアーキテクチャを改善したYOLOv3をarXiVで公開した。
- 2020年には、他の著者が多くの重要な変更を加えたYOLOv4を発表し、その2ヶ月後にはUltralyticsがオープンソースでYOLOv5を公開した (YOLOv5の論文は発表されなかった)。同年に、YOLOv4の作者は更なる改良を加えたScaled-YOLOv4を発表した。
- 2021年にはYOLOR、YOLOXが発表された。
- 2022年にはYOLOv4の作成者はv6を飛ばしてYOLOv7 公開しました。これは速度と精度の点で当時の最先端だった。しかし同年、Meituan Visionの研究者によって、v7 よりも優れた YOLOv6が公開された。
- 2023年1月には、UltralyticsがSemantic Segmentation機能も備えたYOLOv8をオープンソース化した。2023年5月にはDeci AIが、これまでの YOLO をすべて超えるアルゴリズム生成アーキテクチャである YOLO-NAS を考案した。
YOLOv1
- 一般にDeep Learningの物体検出はSingle-stage detectorとTwo-stage detectorに分かれる
- Single-stage Detectorでは基本的にBackbone-Neck-Head アーキテクチャの設計に従っていたがYOLOv1にはNeckがない。
- GoogleNetからインスピレーションを受けていて24のCNN層と2つのLinear層という構造
- Darknetと呼ばれており、この後も長く使われる

- 最初の20層を224x224の画像サイズでImageNetで事前学習した上で、残りの4層は448x448の画像サイズでPASCAL VOC 2012で学習を行った。
- これによりモデルの情報が増加したため、小さな物体の検出精度が上がった
- その他でかめのDropoutや様々なAugmentationを行った
- 予測方法
- 画像を SxS グリッドに分割し、各グリッドはB個の座標とBBoxに関連するObjectness ScoreとC個のクラス確率を予測する。(論文ではB=2, S = 7)
- Objectness Scoreはそのグリッドに物体中心が含まれているかを示すスコア
- (具体的にはground truthとのIOU)
- YOLO はBBoxの座標として、BBoxの中心 (x, y) と幅 (w) と高さ (h) を予測。
- (x, y)はグリッドセルの境界を基準にしたBBoxの中心
- 要するに(次元のテンソルを出力。
- Objectness score x class確率を行うことで、どのBBoxが正解の物体を検出できているかが分かる。
- B個のBBoxを推論しているが、全て同じクラスを予測することになる
- 信頼度の高いBBoxをNMS(Non-Maximum Suppression)で、選別する。
- 同じ物体を検出しているBBox集合の中から最も確率の高いものを抽出し、それと周辺のBBoxとのIOUを計算する。
- IOUが閾値以上であれば同じ物体を予測しているとして、予測からBBoxを除去する
- 発展系でSoft-NMSやNon-Maximum Weighted、WBF (Weigted Boxes Fusion)といった手法もある

NMSとは


- 損失関数
- Lossは物体がある部分に対してのみ、座標のロスとobjective nessのロスをかけ、その他の部分にクラス部類のロスをかける。そのままだと物体がない部分が過剰になるので、バランスを取るハイパーパラメータがある。
- 物体がある部分 = 物体中心があるグリッド
- これは、分類誤差と回帰誤差を同等に扱ってしまうため、論文中では理想的ではないと語られている。
- 1行目:物体がある部分に対して座標の二乗誤差の合計をかけている
- 2行目:物体がある部分に対して幅と高さの平方根を取った上で、二乗誤差の合計をかけている。小さい物体の方が重要なため、平方根をかけている。
- 3行目:Objectness scoreのLoss。
- は物体の中心があるグリッドかつ正解のBBoxに対して最大のIOUを持つBBoxの場合に1になる
- 4行目:Objectness scoreのLoss。objがない部分がLossとして過剰にならないように0.5をかけている。
- は物体中心があるグリッドかつ最大のIOUでないBBoxの場合に1になる
- 5行目:objがある部分についてクラス確率のLoss
- この部分だけ、物体中心だけでなく物体がある全てのグリッドで計算

- 限界
- 各グリッドはB個のBBoxと一つのクラスしか予測できないため、複数の物体を検知することには向いていない
YOLOv2
- YOLOv1のアーキテクチャを僅かに変更し、訓練過程を改善
- BatchNormを追加
- 高解像度の画像を使用
- ImageNet訓練の段階から448x448の画像を使用
- 最終的には13x13の特徴マップが得られる
- Anchor Boxの作成
- 事前により確からしいBBoxのサイズを入力するために、学習セットにおいてk-meansを行い、代表的なBBoxのサイズを取得した
- 単純にユークリッド距離を用いると大きいBBoxが小さいBBoxよりも大きな誤差を生じるため、以下のような距離を用いた
- Location Prediction
- 予測する(x, y, w, h)を以下の図のように変換
- x, yをグリッド中心 (からの距離に変換
- w, hを事前に上で作成したBBoxのクラスターのサイズとして、そこから指数関数をかけた値に変換
- 学習時の安定性が増した

- 連結層 (path through layer)の追加
- 26x26の特徴マップから13x13の特徴マップへの連結層を追加
- 26x26x512 → 13x13x2048にreshapeして連結?
- 高解像度の情報をより考慮した上で予測をすることができる
- マルチスケールトレーニング
- 10バッチごとに入力画像を320 ~ 608の中の32の倍数からランダムに取得して訓練を行った
- 階層的分類
- Wordnetという手法を用いて、包括的な関係にあるラベルを階層的な分類になるように変更した
- ImageNetとCOCOの分類方法が異なる点を防ぎたい狙い
- 最終的には以下のようにWordTree型になるように工夫をした


- 最終的に全ての工夫を入れることでmAPを16pt上昇させている

YOLOv3
- YOLOv1, v2では各グリッドのクラス確率を予測していたが、YOLOv3では各BBoxごとにクラスを予測する
- グリッド毎に3つのBBox、Objectness score、クラス確率を予測する
- テンソルの形は(になる
- YOLOv3では一つのSoftmax層ではなく、複数のBinary Cross Entoropyで学習させる。
- BackboneとしてDarknet-53を使用
- ResNetからインスピレーションを受けてskip接続などを追加
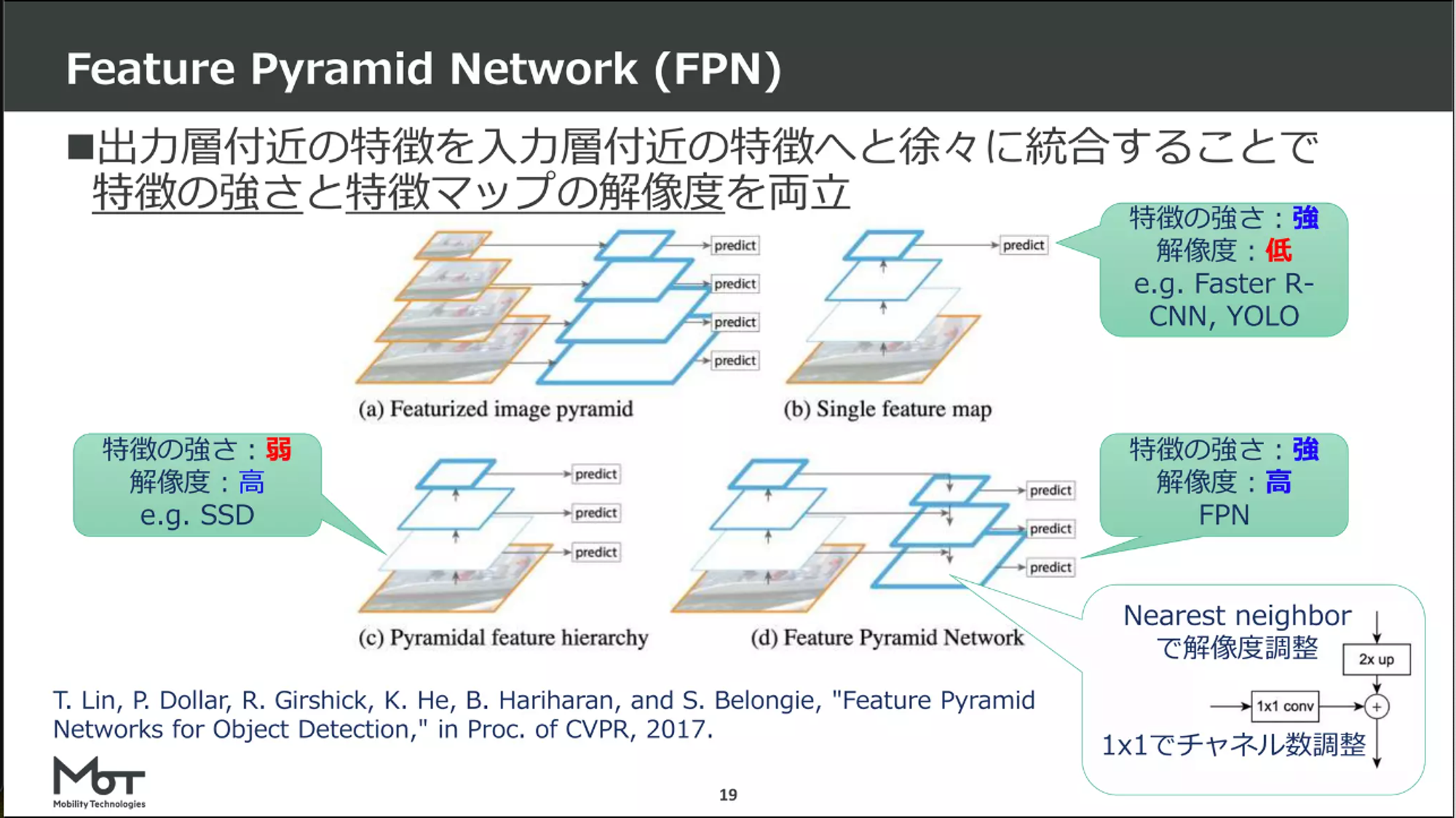
- 更にFeature Pyramid Network(FPN)のアーキテクチャも追加
- 以下のような構造で特徴の強さと解像度の良いとこどりを狙ったネットワーク
- ResNet101などより小さいが、より高速で、同等以上のパフォーマンスがある
参考
- BBoxのサイズはv2と同様にK-meansを使って探した
YOLOv4
ここから著者が変わる。v3から二年が経過。
元々の著者であるRedmonは軍事応用やプライバシーへの懸念などの倫理的な理由でComputer Visionの研究をstopした。
- 最先端のテクニックや手法を色々と実験を行った
- Bag of freebies: 学習上の工夫
- Bag of specials: 少ないコスト (推論時間や計算リソース)で大きな精度向上ができる
- 性能が良かったものを組み合わせてBackboneとしてCSPDarkNet53という構造を提案
- Object Detectionの構造を以下のように分割して定義
- Backbone: 画像の特徴抽出
- Neck: 特徴マップをよしなに操作して、より良い特徴量を生み出す
- Head: クラス分類やBBoxの位置を予測
- YOLOv4の場合は
- Backbone: CSPDarkNet53
- Neck: Spatial Pyramid Pooling(SPP), Path Aggregation Network(PAN)
- Head: YOLOv3

最終的に採用されたBag of freebies
- BBoxの損失関数
- CIoU-loss
- BBox間の重なり、BBoxの中心間の距離、アスペクト比の差異などを考慮したLoss
- 参考:【論文5分まとめ】Distance-IoU Loss
- Data Augmentation
- CutMix
- Mosaic data augmentation: 4つの画像を混ぜる
- 正則化
- DropBlock: Dropoutのblockバージョン
- CBN (Cross-Iteration Batch Normalization)を改良したCmBN (Cross mini-batch normalization)
- BatchNormはbatch sizeが小さい時に効果が小さいので、CBNでは複数のiterationのサンプルを結合させる
- CmBNではmini-batchの中だけで結合させる


- その他
- Cosine annealing scheduler
- Class label smoothing
最終的に採用されたBag of specials
- Backbone
- Mish Activation
- Cross-stage partial connections

- Neck


- Head
- YOLOv3と同じアンカー構造
- DIoU-NMS
- DIoUをスコアに用いたNMS
YOLOv5 ~
- TO BE CONTINUED …