SMR: State Memory Replay for Long Sequence Modeling
2405.17534
0
0

Abstract
Despite the promising performance of state space models (SSMs) in long sequence modeling, limitations still exist. Advanced SSMs like S5 and S6 (Mamba) in addressing non-uniform sampling, their recursive structures impede efficient SSM computation via convolution. To overcome compatibility limitations in parallel convolutional computation, this paper proposes a novel non-recursive non-uniform sample processing strategy. Theoretical analysis of SSMs through the lens of Event-Triggered Control (ETC) theory reveals the Non-Stable State (NSS) problem, where deviations from sampling point requirements lead to error transmission and accumulation, causing the divergence of the SSM's hidden state. Our analysis further reveals that adjustments of input sequences with early memories can mitigate the NSS problem, achieving Sampling Step Adaptation (SSA). Building on this insight, we introduce a simple yet effective plug-and-play mechanism, State Memory Replay (SMR), which utilizes learnable memories to adjust the current state with multi-step information for generalization at sampling points different from those in the training data. This enables SSMs to stably model varying sampling points. Experiments on long-range modeling tasks in autoregressive language modeling and Long Range Arena demonstrate the general effectiveness of the SMR mechanism for a series of SSM models.
Create account to get full access
Overview
- This paper introduces a new model called SMR (State Memory Replay) for long sequence modeling tasks.
- SMR aims to alleviate the "curse of memory" in state-space models by storing and replaying past hidden states.
- The model is designed to improve performance on tasks that require modeling long-term dependencies, such as language modeling and time series forecasting.
Plain English Explanation
The paper proposes a new machine learning model called SMR (State Memory Replay) that is designed to work better with long sequences of data, such as text or time series. One of the challenges with many existing models is that they struggle to remember and make use of information from the distant past, a problem known as the "curse of memory."
The key idea behind SMR is to store the model's internal hidden states (the information it uses to make predictions) from previous time steps, and then replay those stored states when processing new data. This allows the model to better retain and leverage knowledge from the past, which can be crucial for tasks that require understanding long-term dependencies, like language modeling or forecasting.
By incorporating this "memory" of past states, the SMR model aims to overcome the limitations of traditional state-space models and perform better on a range of long-sequence tasks. The paper evaluates the SMR model on several benchmark datasets and demonstrates its effectiveness compared to other state-of-the-art approaches.
Technical Explanation
State-space models are a common framework for modeling sequential data, where the current output depends on both the current input and the hidden state of the model, which carries information from the past. However, these models can struggle with long-range dependencies due to the "curse of memory" - the tendency for information from the distant past to be lost or overwhelmed by more recent inputs.
To address this issue, the authors propose the SMR (State Memory Replay) model, which stores and replays past hidden states to better retain long-term information. Specifically, SMR maintains a memory buffer that stores the hidden states from previous time steps. When processing a new input, SMR retrieves and replays relevant past states from the memory buffer, allowing it to better leverage historical information.
The authors evaluate SMR on several long sequence modeling tasks, including language modeling and time series forecasting. They show that SMR outperforms various state-of-the-art baselines, including Stable SSM, Mamba 360, and Illusion of State, as well as standard state-space models. The authors also provide analysis and insights into the inner workings of SMR, demonstrating how the memory replay mechanism helps the model overcome the curse of memory.
Critical Analysis
The SMR model presented in this paper offers a promising approach to addressing the limitations of state-space models for long sequence modeling tasks. By incorporating a memory replay mechanism, the model is able to better retain and leverage information from the distant past, which is a significant challenge for many existing models.
However, the paper does not explore the computational and memory requirements of the SMR model, which could be a potential drawback, especially for large-scale or real-time applications. Additionally, the authors do not delve into the interpretability of the model or provide insights into the types of long-term dependencies that the SMR model is able to capture.
Further research could also investigate the applicability of the SMR approach to other domains, such as event-based sensors or reinforcement learning, where long-term dependencies are also a critical challenge.
Conclusion
The SMR model proposed in this paper represents an important step forward in addressing the "curse of memory" in state-space models for long sequence modeling tasks. By incorporating a memory replay mechanism, the model is able to better retain and leverage long-term information, leading to improved performance on a range of benchmarks.
While the paper leaves some open questions, the core idea of SMR is a promising direction for advancing the state-of-the-art in sequential modeling and could have significant implications for applications that require understanding and predicting long-term patterns in data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
StableSSM: Alleviating the Curse of Memory in State-space Models through Stable Reparameterization
Shida Wang, Qianxiao Li
0
0
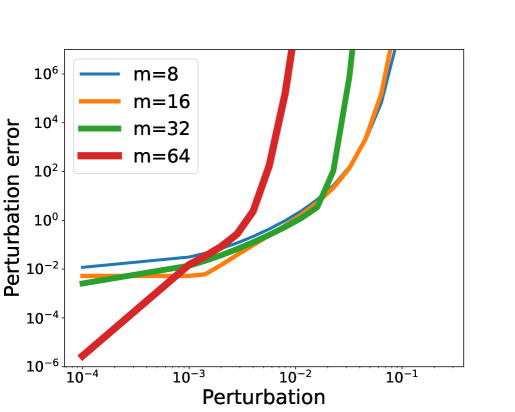
In this paper, we investigate the long-term memory learning capabilities of state-space models (SSMs) from the perspective of parameterization. We prove that state-space models without any reparameterization exhibit a memory limitation similar to that of traditional RNNs: the target relationships that can be stably approximated by state-space models must have an exponential decaying memory. Our analysis identifies this curse of memory as a result of the recurrent weights converging to a stability boundary, suggesting that a reparameterization technique can be effective. To this end, we introduce a class of reparameterization techniques for SSMs that effectively lift its memory limitations. Besides improving approximation capabilities, we further illustrate that a principled choice of reparameterization scheme can also enhance optimization stability. We validate our findings using synthetic datasets, language models and image classifications.
6/6/2024
🤿
Mamba-360: Survey of State Space Models as Transformer Alternative for Long Sequence Modelling: Methods, Applications, and Challenges
Badri Narayana Patro, Vijay Srinivas Agneeswaran
0
0
Sequence modeling is a crucial area across various domains, including Natural Language Processing (NLP), speech recognition, time series forecasting, music generation, and bioinformatics. Recurrent Neural Networks (RNNs) and Long Short Term Memory Networks (LSTMs) have historically dominated sequence modeling tasks like Machine Translation, Named Entity Recognition (NER), etc. However, the advancement of transformers has led to a shift in this paradigm, given their superior performance. Yet, transformers suffer from $O(N^2)$ attention complexity and challenges in handling inductive bias. Several variations have been proposed to address these issues which use spectral networks or convolutions and have performed well on a range of tasks. However, they still have difficulty in dealing with long sequences. State Space Models(SSMs) have emerged as promising alternatives for sequence modeling paradigms in this context, especially with the advent of S4 and its variants, such as S4nd, Hippo, Hyena, Diagnol State Spaces (DSS), Gated State Spaces (GSS), Linear Recurrent Unit (LRU), Liquid-S4, Mamba, etc. In this survey, we categorize the foundational SSMs based on three paradigms namely, Gating architectures, Structural architectures, and Recurrent architectures. This survey also highlights diverse applications of SSMs across domains such as vision, video, audio, speech, language (especially long sequence modeling), medical (including genomics), chemical (like drug design), recommendation systems, and time series analysis, including tabular data. Moreover, we consolidate the performance of SSMs on benchmark datasets like Long Range Arena (LRA), WikiText, Glue, Pile, ImageNet, Kinetics-400, sstv2, as well as video datasets such as Breakfast, COIN, LVU, and various time series datasets. The project page for Mamba-360 work is available on this webpage.url{https://github.com/badripatro/mamba360}.
4/26/2024
The Illusion of State in State-Space Models
William Merrill, Jackson Petty, Ashish Sabharwal
0
0
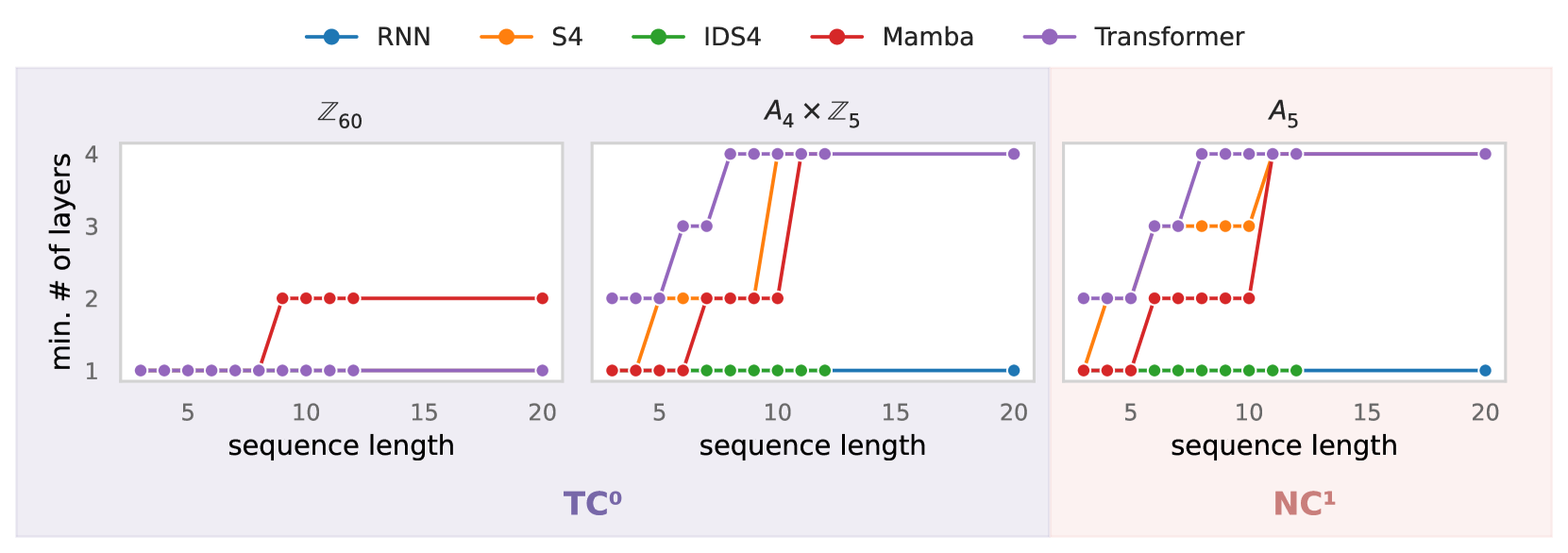
State-space models (SSMs) have emerged as a potential alternative architecture for building large language models (LLMs) compared to the previously ubiquitous transformer architecture. One theoretical weakness of transformers is that they cannot express certain kinds of sequential computation and state tracking (Merrill & Sabharwal, 2023), which SSMs are explicitly designed to address via their close architectural similarity to recurrent neural networks (RNNs). But do SSMs truly have an advantage (over transformers) in expressive power for state tracking? Surprisingly, the answer is no. Our analysis reveals that the expressive power of SSMs is limited very similarly to transformers: SSMs cannot express computation outside the complexity class $mathsf{TC}^0$. In particular, this means they cannot solve simple state-tracking problems like permutation composition. It follows that SSMs are provably unable to accurately track chess moves with certain notation, evaluate code, or track entities in a long narrative. To supplement our formal analysis, we report experiments showing that Mamba-style SSMs indeed struggle with state tracking. Thus, despite its recurrent formulation, the state in an SSM is an illusion: SSMs have similar expressiveness limitations to non-recurrent models like transformers, which may fundamentally limit their ability to solve real-world state-tracking problems.
6/6/2024
State Space Models for Event Cameras
Nikola Zubi'c, Mathias Gehrig, Davide Scaramuzza
0
0
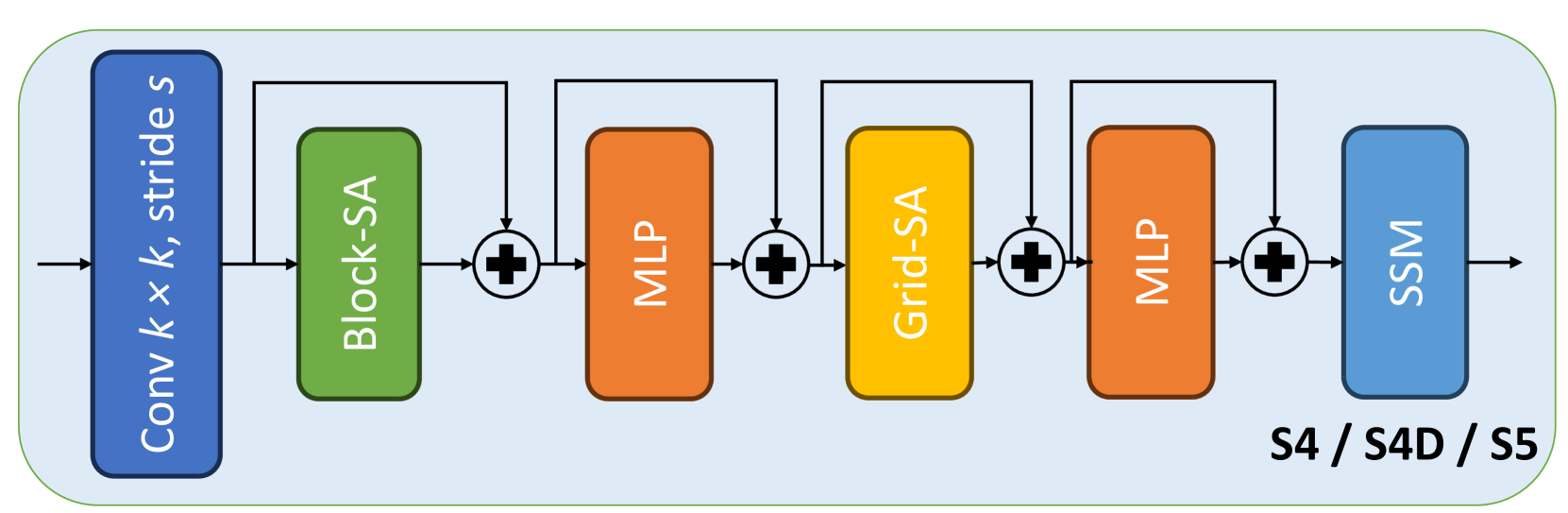
Today, state-of-the-art deep neural networks that process event-camera data first convert a temporal window of events into dense, grid-like input representations. As such, they exhibit poor generalizability when deployed at higher inference frequencies (i.e., smaller temporal windows) than the ones they were trained on. We address this challenge by introducing state-space models (SSMs) with learnable timescale parameters to event-based vision. This design adapts to varying frequencies without the need to retrain the network at different frequencies. Additionally, we investigate two strategies to counteract aliasing effects when deploying the model at higher frequencies. We comprehensively evaluate our approach against existing methods based on RNN and Transformer architectures across various benchmarks, including Gen1 and 1 Mpx event camera datasets. Our results demonstrate that SSM-based models train 33% faster and also exhibit minimal performance degradation when tested at higher frequencies than the training input. Traditional RNN and Transformer models exhibit performance drops of more than 20 mAP, with SSMs having a drop of 3.76 mAP, highlighting the effectiveness of SSMs in event-based vision tasks.
4/19/2024