We use cookies essential for this site to function well. Please click to help us improve its usefulness with additional cookies. Learn about our use of cookies in our Privacy Policy & Cookies Policy.
Show details
Powered By

Cookies
This site uses cookies to ensure that you get the best experience possible. To learn more about how we use cookies, please refer to our Privacy Policy & Cookies Policy.
brahmaid
It is needed for personalizing the website.
Expiry: Session
Type: HTTP
csrftoken
This cookie is used to prevent Cross-site request forgery (often abbreviated as CSRF) attacks of the website
Expiry: Session
Type: HTTPS
Identityid
Preserves the login/logout state of users across the whole site.
Expiry: Session
Type: HTTPS
sessionid
Preserves users' states across page requests.
Expiry: Session
Type: HTTPS
g_state
Google One-Tap login adds this g_state cookie to set the user status on how they interact with the One-Tap modal.
Expiry: 365 days
Type: HTTP
MUID
Used by Microsoft Clarity, to store and track visits across websites.
Expiry: 1 Year
Type: HTTP
_clck
Used by Microsoft Clarity, Persists the Clarity User ID and preferences, unique to that site, on the browser. This ensures that behavior in subsequent visits to the same site will be attributed to the same user ID.
Expiry: 1 year
Type: HTTP
_clsk
Used by Microsoft Clarity, Connects multiple page views by a user into a single Clarity session recording.
Expiry: 1 Day
Type: HTTP
SRM_I
Collects user data is specifically adapted to the user or device. The user can also be followed outside of the loaded website, creating a picture of the visitor's behavior.
Expiry: 2 years
Type: HTTP
SM
Use to measure the use of the website for internal analytics
Expiry: 1 years
Type: HTTP
CLID
The cookie is set by embedded Microsoft Clarity scripts. The purpose of this cookie is for heatmap and session recording.
Expiry: 1 year
Type: HTTP
SRM_B
Collected user data is specifically adapted to the user or device. The user can also be followed outside of the loaded website, creating a picture of the visitor's behavior.
Expiry: 2 months
Type: HTTP
_gid
This cookie is installed by Google Analytics. The cookie is used to store information of how visitors use a website and helps in creating an analytics report of how the website is doing. The data collected includes the number of visitors, the source where they have come from, and the pages visited in an anonymous form.
Expiry: 399 days
Type: HTTP
_ga_#
Used by Google Analytics, to store and count pageviews.
Expiry: 399 Days
Type: HTTP
_gat_#
Used by Google Analytics to collect data on the number of times a user has visited the website as well as dates for the first and most recent visit.
Expiry: 1 day
Type: HTTP
collect
Used to send data to Google Analytics about the visitor's device and behavior. Tracks the visitor across devices and marketing channels.
Expiry: Session
Type: PIXEL
AEC
cookies ensure that requests within a browsing session are made by the user, and not by other sites.
Expiry: 6 months
Type: HTTP
G_ENABLED_IDPS
use the cookie when customers want to make a referral from their gmail contacts; it helps auth the gmail account.
Expiry: 2 years
Type: HTTP
test_cookie
This cookie is set by DoubleClick (which is owned by Google) to determine if the website visitor's browser supports cookies.
Expiry: 1 year
Type: HTTP
_we_us
this is used to send push notification using webengage.
Expiry: 1 year
Type: HTTP
WebKlipperAuth
used by webenage to track auth of webenagage.
Expiry: session
Type: HTTP
ln_or
Linkedin sets this cookie to registers statistical data on users' behavior on the website for internal analytics.
Expiry: 1 day
Type: HTTP
JSESSIONID
Use to maintain an anonymous user session by the server.
Expiry: 1 year
Type: HTTP
li_rm
Used as part of the LinkedIn Remember Me feature and is set when a user clicks Remember Me on the device to make it easier for him or her to sign in to that device.
Expiry: 1 year
Type: HTTP
AnalyticsSyncHistory
Used to store information about the time a sync with the lms_analytics cookie took place for users in the Designated Countries.
Expiry: 6 months
Type: HTTP
lms_analytics
Used to store information about the time a sync with the AnalyticsSyncHistory cookie took place for users in the Designated Countries.
Expiry: 6 months
Type: HTTP
liap
Cookie used for Sign-in with Linkedin and/or to allow for the Linkedin follow feature.
Expiry: 6 months
Type: HTTP
visit
allow for the Linkedin follow feature.
Expiry: 1 year
Type: HTTP
li_at
often used to identify you, including your name, interests, and previous activity.
Expiry: 2 months
Type: HTTP
s_plt
Tracks the time that the previous page took to load
Expiry: Session
Type: HTTP
lang
Used to remember a user's language setting to ensure LinkedIn.com displays in the language selected by the user in their settings
Expiry: Session
Type: HTTP
s_tp
Tracks percent of page viewed
Expiry: Session
Type: HTTP
AMCV_14215E3D5995C57C0A495C55%40AdobeOrg
Indicates the start of a session for Adobe Experience Cloud
Expiry: Session
Type: HTTP
s_pltp
Provides page name value (URL) for use by Adobe Analytics
Expiry: Session
Type: HTTP
s_tslv
Used to retain and fetch time since last visit in Adobe Analytics
Expiry: 6 months
Type: HTTP
li_theme
Remembers a user's display preference/theme setting
Expiry: 6 months
Type: HTTP
li_theme_set
Remembers which users have updated their display / theme preferences
Expiry: 6 months
Type: HTTP
We do not use cookies of this type.
_gcl_au
Used by Google Adsense, to store and track conversions.
Expiry: 3 months
Type: HTTP
SID
Save certain preferences, for example the number of search results per page or activation of the SafeSearch Filter. Adjusts the ads that appear in Google Search.
Expiry: 2 years
Type: HTTP
SAPISID
Save certain preferences, for example the number of search results per page or activation of the SafeSearch Filter. Adjusts the ads that appear in Google Search.
Expiry: 2 years
Type: HTTP
__Secure-#
Save certain preferences, for example the number of search results per page or activation of the SafeSearch Filter. Adjusts the ads that appear in Google Search.
Expiry: 2 years
Type: HTTP
APISID
Save certain preferences, for example the number of search results per page or activation of the SafeSearch Filter. Adjusts the ads that appear in Google Search.
Expiry: 2 years
Type: HTTP
SSID
Save certain preferences, for example the number of search results per page or activation of the SafeSearch Filter. Adjusts the ads that appear in Google Search.
Expiry: 2 years
Type: HTTP
HSID
Save certain preferences, for example the number of search results per page or activation of the SafeSearch Filter. Adjusts the ads that appear in Google Search.
Expiry: 2 years
Type: HTTP
DV
These cookies are used for the purpose of targeted advertising.
Expiry: 6 hours
Type: HTTP
NID
These cookies are used for the purpose of targeted advertising.
Expiry: 1 month
Type: HTTP
1P_JAR
These cookies are used to gather website statistics, and track conversion rates.
Expiry: 1 month
Type: HTTP
OTZ
Aggregate analysis of website visitors
Expiry: 6 months
Type: HTTP
_fbp
This cookie is set by Facebook to deliver advertisements when they are on Facebook or a digital platform powered by Facebook advertising after visiting this website.
Expiry: 4 months
Type: HTTP
fr
Contains a unique browser and user ID, used for targeted advertising.
Expiry: 2 months
Type: HTTP
bscookie
Used by LinkedIn to track the use of embedded services.
Expiry: 1 year
Type: HTTP
lidc
Used by LinkedIn for tracking the use of embedded services.
Expiry: 1 day
Type: HTTP
bcookie
Used by LinkedIn to track the use of embedded services.
Expiry: 6 months
Type: HTTP
aam_uuid
Use these cookies to assign a unique ID when users visit a website.
Expiry: 6 months
Type: HTTP
UserMatchHistory
These cookies are set by LinkedIn for advertising purposes, including: tracking visitors so that more relevant ads can be presented, allowing users to use the 'Apply with LinkedIn' or the 'Sign-in with LinkedIn' functions, collecting information about how visitors use the site, etc.
Expiry: 6 months
Type: HTTP
li_sugr
Used to make a probabilistic match of a user's identity outside the Designated Countries
Expiry: 90 days
Type: HTTP
MR
Used to collect information for analytics purposes.
Expiry: 1 year
Type: HTTP
ANONCHK
Used to store session ID for a users session to ensure that clicks from adverts on the Bing search engine are verified for reporting purposes and for personalisation
Expiry: 1 day
Type: HTTP
We do not use cookies of this type.
Cookie declaration last updated on 24/03/2023 by Analytics Vidhya.
Cookies are small text files that can be used by websites to make a user's experience more efficient. The law states that we can store cookies on your device if they are strictly necessary for the operation of this site. For all other types of cookies, we need your permission. This site uses different types of cookies. Some cookies are placed by third-party services that appear on our pages. Learn more about who we are, how you can contact us, and how we process personal data in our Privacy Policy.
Reading list
Understanding Early stopping
Understanding Dropout
Vanishing and Exploding Gradients
Weights Initialization Techniques
Implementing Weight Initializing Techniques
Batch Normalization
Image Augmentation Techniques
Image Generator and Fit Generator
Model Checkpointing
Implementing Model Checkpointing
Dealing with Class Imbalance
Ensemble Deep Learning
Introduction
Artificial Intelligence is a forever emerging and advancing technology. AI models are used increasingly widely in today’s real-world applications. With the power of data and artificial intelligence, machines can demonstrate human intelligence, sometimes even better than humans!
The culmination of training data with machine learning has undoubtedly created huge longevity and thrilling material progress in technology, thus achieving inconceivable heights of intelligence.
One such recent yet dramatic progress in Machine Learning is a newly revoluted concept known as Federated Learning. This federated learning framework enables training AI models on decentralized data sources, such as mobile devices or edge sensors, without transferring the raw data to a central server. Instead, techniques like federated averaging are used to learn a shared model while localizing the training data collaboratively. This has significant implications for privacy-preserving AI and enabling real-world deployments in scenarios where data cannot leave the source devices.
Learning Objectives
- Understand the concept of federated learning and its motivation for privacy-preserving distributed machine learning.
- Learn the workflow and steps involved in a federated learning process, including local model training, secure aggregation, and global model updates.
- Gain insights into the secure aggregation principle and encryption techniques used to protect user data in federated learning.
- Explore the potential applications of federated learning in domains like healthcare, finance, IoT, and mobile devices.
- Get hands-on experience with coding examples using TensorFlow Federated to implement federated learning for a simple task like image classification.
This article was published as a part of the Data Science Blogathon.
Table of contents
What is Federated Learning in Machine Learning?
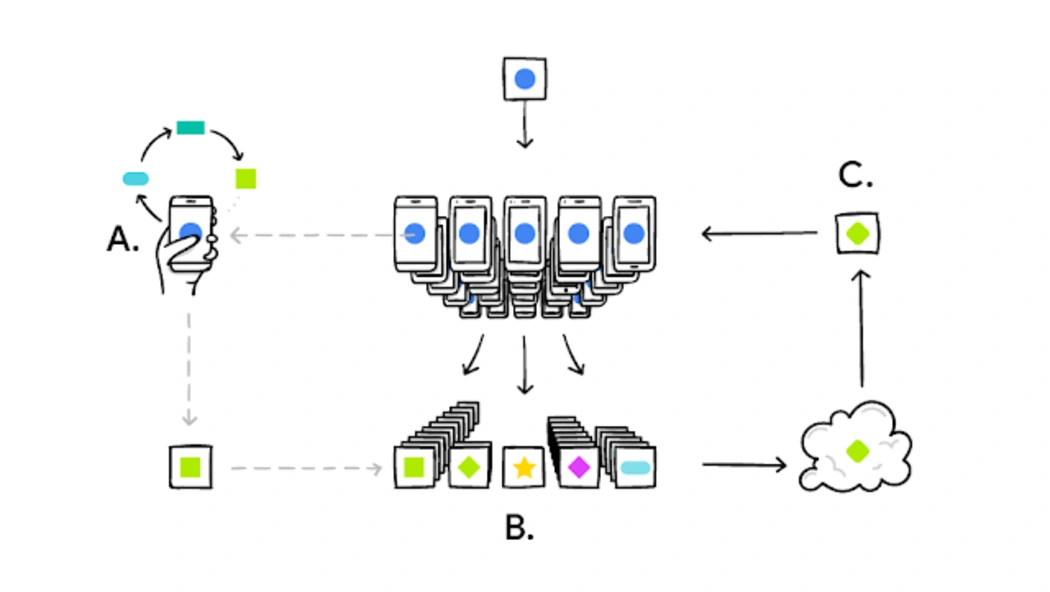
A user’s phone personalizes the model copy locally, based on their user choices:
- A subset of these user updates is then aggregated,
- Forming a consensus change,
- Which is applied to the shared model.
This process is repeated, continuously refining the model. Federated Learning is a training technique for central models, utilizing decentralized data sources while ensuring hyper-personalization, minimal latencies, and, most importantly, privacy preservation. This article serves as an introductory guide to understanding the basics of Federated Learning.
What is Federated Learning?
Federated Learning is simply the decentralized form of Machine Learning. In traditional machine learning approaches, we usually train models on data that is aggregated from several edge devices like smartphones, laptops, etc., and brought together to a centralized server. The learning process happens on this centralized data store, where machine learning algorithms like neural networks train themselves on the aggregated data and finally make predictions on new data.
However, in a federated learning system, the learning methods are distributed across the edge devices themselves. Instead of centralizing the training data, only the model parameters are sent to individual devices like smartphones, where the learning process takes place locally on each device’s data. This decentralized machine learning approach has several advantages, including improved data privacy, reduced bandwidth requirements compared to sending raw data, and the ability to leverage insights from diverse data sources without directly accessing the raw data. Open-source frameworks are emerging to facilitate the development and deployment of such federated learning architectures for training predictive models on decentralized data.
Great!
But, can you smell a “privacy nightmare”?
Addressing Privacy Concerns
The AI market is dominated by tech giants such as Google, Amazon, and Microsoft, offering cloud-based AI solutions and APIs. In the traditional AI methods, sensitive private data are sent to centralized data centers where models are trained.
That isn’t very good! With the increased awareness of data protection and user privacy across different devices and platforms, AI developers should not ignore the fact that their model is accessing and using data that is user-sensitive!
Techniques like federated learning and differential privacy aim to address these concerns by keeping the private data localized and adding noise to protect individual privacy, while still enabling collaborative model training. This avoids the need to directly share raw user data with central servers or data centers, aligning better with modern data protection regulations and user expectations around privacy.
Well, here comes our Savior! The Federated Learning approach.
Types of Federated Learning
There are mainly three types of federated learning:
- Horizontal Federated Learning: Data samples are distributed across devices or servers, and the model is trained collaboratively.
- Vertical Federated Learning: Features are divided between devices, and the model is trained on complementary features.
- Federated Transfer Learning: Pre-trained models are fine-tuned on decentralized data for specific tasks, reducing the need for extensive local data.
Understanding Federated Learning with an Example
Federated Learning is born at the intersection of on-device AI, blockchain, and edge computing/IoT.
Here we train a centralized Machine Learning model on decentralized data! Let us take a hypothetical problem statement, and understand how federated learning works, step by step.
So, grab your coffee mug and dive in!
Suppose, you got selected as a machine learning intern in a company, and your task is to create a robust machine learning application, that needs to train itself on user-sensitive data.
You’re allowed to extract user data, aggregate it from many users, and stack them up on a centralized cloud server, for your model to crunch it. You are a smart guy, and you are doing your job!
But wait. Isn’t your work invading someone’s privacy?
Yes, it is. And that is not an ethical practice in technology.
You discussed it in a meeting, and your boss is now worried about the next steps. In the meantime, you and your teammates started discussing the matter.
One of them yelled, “What if we don’t take user-sensitive data, but train our model locally, on each device?”
That was a good idea. But how can we do this?
We will train our model on the devices themselves, and not on the centralized server, that exposes sensitive data! The local data generated by the user history, on a particular device, will now be used as on-device data to train our model and make it smarter, much quicker.
Yay! No more privacy nightmares.
Let us sum up the plan now!
- So, our centralized machine learning application will have a local copy on all devices, where users can use them according to our need.
- The model will now gradually learn and train itself on the information inputted by the user and become smarter, time to time.
- The devices are then allowed to transfer the training results, from the local copy of the machine learning app, back to the central server.
Remember, only results, not data!
- This same process happens across several devices, that have a local copy of the application. The results will be aggregated together in the centralized server, this time without user data.
- The centralized cloud server now updates its central machine learning model from the aggregated training results, which is now far better than the previously deployed version.
- The development team now updates the model to a newer version, and users update the application with the smarter model, created from their own data!
WOW! That’s pretty awesome!
All is going pretty good, while one of your teammates seems to be very worried about the device battery power issue!
She points, “Such long and costly training would always drain our phone battery, guys!”
So, do we have a solution to this? Yes, of course, we do!
Don’t worry. Devices will only participate in the training process when users are not using it. This can occur while your phone is on the charge, in do not disturb mode, or idle.
Cool. That’s a lot of awesomeness.
So, what did we learn about Federated Learning?

In a nutshell, Federated Learning with the above 6 steps discussed, will now create a system that encrypts the user-sensitive data with an encryption key that is not in the hands of your centralized cloud server.
Such an approach is referred to as the Secure Aggregation Principle, where our server is allowed to secure and combine the encrypted results and decrypt only the aggregated results.
This kind of functional encryption is simply said to be a zero-sum masking protocol. Zero-sum masks sum to 1 in one direction, and 0 in another. One of them combines and secures the encrypted or secure user data, while the next decrypts the training results to the server.
This process continues until completed, and then the masks cancel out each other.
That is all about Federated Learning!
How does Federated Learning Works?
Federated learning works by training a central model across decentralized devices or servers through an iterative optimization process. Instead of moving all data to a central location, the model is trained locally on each device, and only the model parameter updates or gradients are shared with a central server. This allows the central model to be optimized over a large number of iterations by aggregating updates from many devices while maintaining data privacy. However, this decentralized training scenario also introduces challenges like dealing with heterogeneity in the data distributions across devices, ensuring convergence despite limited communication rounds, and developing efficient techniques for aggregating model updates from a massive number of sources. Advanced optimization algorithms tailored for the federated setting are an active area of research with Federated Learning with Keras and TensorFlow
Before we start, please make sure that your environment is correctly set up and import all the dependencies.
Hands-on with Federated Learning!
Setting Up the Environment and Dependencies
Before diving into the Federated Learning implementation, ensure that your environment is correctly configured. Run the following commands to uninstall unnecessary packages and install the required dependencies:
!pip uninstall --yes tensorboard tb-nightly
!pip install --quiet --upgrade tensorflow-federated-nightly
!pip install --quiet --upgrade nest-asyncio
!pip install --quiet --upgrade tb-nightly # or tensorboard, but not both
import nest_asyncio
nest_asyncio.apply()Importing Necessary Libraries
Next, import the required libraries for data preprocessing, model creation, and training:
import collections
import numpy as np
import tensorflow as tf
import tensorflow_federated as tff
np.random.seed(0)Loading and Preprocessing Data
For this example, we will use the federated version of the MNIST dataset. The preprocess function is defined to format the data, and the make_federated_data function prepares the federated training data:
def preprocess(dataset):
def batch_format_fn(element):
return collections.OrderedDict(
x=tf.reshape(element['pixels'], [-1, 784]),
y=tf.reshape(element['label'], [-1, 1])
)
return dataset.repeat(NUM_EPOCHS) \
.shuffle(SHUFFLE_BUFFER) \
.batch(BATCH_SIZE) \
.map(batch_format_fn) \
.prefetch(PREFETCH_BUFFER)
def make_federated_data(client_data, client_ids):
return [preprocess(client_data.create_tf_dataset_for_client(x)) for x in client_ids]
sample_clients = emnist_train.client_ids[:NUM_CLIENTS]
federated_train_data = make_federated_data(emnist_train, sample_clients)
print('Number of client datasets:', len(federated_train_data))
print('First dataset:', federated_train_data[0])Creating the Model
Now, we define the model architecture using Keras. The create_keras_model function sets up a simple neural network, and the model_fn function converts it into a TFF model:
def create_keras_model():
return tf.keras.models.Sequential([
tf.keras.layers.InputLayer(input_shape=(784,)),
tf.keras.layers.Dense(10, kernel_initializer='zeros'),
tf.keras.layers.Softmax(),
])
def model_fn():
keras_model = create_keras_model()
return tff.learning.from_keras_model(
keras_model,
input_spec=preprocessed_example_dataset.element_spec,
loss=tf.keras.losses.SparseCategoricalCrossentropy(),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()]
)Training the Model on Decentralized Data
The following code snippet demonstrates the training process on decentralized or user data. The iterative_process is used to iteratively train the model on the federated training data:
state, metrics = iterative_process.next(state, federated_train_data)
print('round 1, metrics:', metrics)
NUM_ROUNDS = 11
for round_num in range(2, NUM_ROUNDS):
state, metrics = iterative_process.next(state, federated_train_data)
print('round {:2d}, metrics:{}'.format(round_num, metrics))Evaluating and Testing the Model
Finally, we evaluate and test the trained model using the tff.learning.build_federated_evaluation function:
evaluation = tff.learning.build_federated_evaluation(MnistModel)
train_metrics = evaluation(state.model, federated_train_data)
federated_test_data = make_federated_data(emnist_test, sample_clients)
test_metrics = evaluation(state.model, federated_test_data)Conclusion
Federated Learning seems to have a lot of potential. Not only does it secure user-sensitive personal data, but it also aggregates results and identifies common patterns from a lot of users, which makes the global model robust, day by day.
It trains itself as per its user data on mobile phones or edge devices, keeps the personal data secure, and then comes back as a smarter model, which is again ready to test itself from its user’s local data! Training and testing became smarter and more privacy-preserving.
Be it training, testing, or information privacy, Federated Learning created a new era of secured AI that can leverage large decentralized datasets without directly accessing the raw data.
Federated Learning is still in its early stages and faces numerous challenges with its design and deployment, especially for complex deep learning and generative AI models. A good way to tackle this challenge is by defining the Federated Learning problem and designing a data pipeline such that it can be properly productized.
You can run a TensorFlow tutorial of Federated Learning here to get your hands on it!
Master all the important concepts of data science and machine learning with our AI/ML Blackbelt Plus Program.
Key Takeaways
- Federated learning enables training machine learning models on decentralized data across devices without sharing raw data, preserving privacy.
- Instead of centralized data aggregation, the model is trained locally on each device, and only model updates are sent to a central server.
- It leverages secure aggregation techniques like encryption to protect user data during the aggregation process.
- Federated learning is advantageous for scenarios where data cannot leave the source due to privacy regulations or constraints.
- Frameworks like TensorFlow Federated facilitate the development and deployment of federated learning systems.
Frequently Asked Questions
Q1. Which framework is primarily used for Federated Learning?
A. TensorFlow is the go-to framework for Federated Learning tasks, providing a robust and flexible environment for this decentralized approach to Machine Learning.
Q2. What is Federated Learning in the context of TensorFlow?
A. Federated Learning in TensorFlow allows for a central model to be trained on data distributed across multiple devices, a collaborative process that enhances privacy and data security.
Q3. What are the key applications of Federated Learning?
A. Federated Learning finds utility in sectors like healthcare, finance, IoT, and smart devices, where secure and privacy-preserving model training on sensitive, distributed data is essential.
Q4. What are the main challenges and limitations of Federated Learning?
A. Federated Learning, despite its potential, currently faces several challenges and limitations. These include dealing with heterogeneous data distributions across devices, ensuring model convergence with limited communication, and scaling aggregation techniques for massive numbers of devices. Additionally, complex deep learning models may require advanced optimization algorithms tailored for the federated setting. These challenges present opportunities for further research and development in the field.
References:
- Federated Learning: Strategies for Improving Communication Efficiency — Google Research
- Federated Learning: A Survey on Enabling Technologies, Protocols, and Applications -ResearchGate
- TensorFlow Federated Tutorials!
The media shown in this article on Top Machine Learning Libraries in Julia are not owned by Analytics Vidhya and is used at the Author’s discretion.
blogathonFederated Learningfederated learning examplemachine learningtensorflowtypes of federated learningwhat is federated learning
Sukanya
18 Sep, 2024
An ace multi-skilled programmer whose major area of work and interest lies in Software Development, Data Science, and Machine Learning. A proactive and detail-oriented individual who loves data storytelling, and is curious and passionate to solve complex value-oriented business problems with Data Science and Machine Learning to deliver robust machine learning pipelines that ensure maximum impact. In my free time, I focus on creating Data Science and AI/ML content, providing 1:1 mentorships, career guidance and interview preparation tips, with a sole focus on teaching complex topics the easier way, to help people make a successful career transition to Data Science with the right skillset!
Free Courses





Recommended Articles
-
Federated Learning for Beginners
-
Privacy-Preserving in Machine Learning (PPML)
-
TensorFlow for Beginners With Examples and Pyth...
-
Top 10 Questions to Test your Data Science Skil...
-
A Basic Introduction to Tensorflow in Deep Lear...
-
Unleashing the Power of Few Shot Learning
-
Safetensors: A Secure Approach to Storing and D...
-
Non-Generalization Principles and Transfer Lear...
-
Build Your Neural Network Using Tensorflow
-
What are Neural Networks and How Do They Work? ...
Frequently Asked Questions
Lorem ipsum dolor sit amet, consectetur adipiscing elit,
Write for us
Write, captivate, and earn accolades and rewards for your work
- Reach a Global Audience
- Get Expert Feedback
- Build Your Brand & Audience
- Cash In on Your Knowledge
- Join a Thriving Community
- Level Up Your Data Science Game






Free Courses
Generative AI| Large Language Models| Building LLM Applications using Prompt Engineering| Building Your first RAG System using LlamaIndex Stability.AI| MidJourney| Building Production Ready RAG systems using LlamaIndex| Building LLMs for Code| Deep Learning| Python| Microsoft Excel Machine Learning| Decision Trees| Pandas for Data Analysis| Ensemble Learning| NLP| NLP using Deep Learning| Neural Networks| Loan Prediction Practice Problem| Time Series Forecasting| Tableau| Business AnalyticsPopular Categories
Generative AI| Prompt Engineering| Generative AI Application| News| Technical Guides| AI Tools| Interview Preparation| Research Papers| Success Stories| Quiz| Use Cases| ListiclesGenerative AI Tools and Techniques
GANs| VAEs| Transformers| StyleGAN| Pix2Pix| Autoencoders| GPT| BERT| Word2Vec| LSTM| Attention Mechanisms Diffusion Models| LLMs| SLMs| StyleGAN| Encoder Decoder Models| Prompt Engineering| LangChain| LlamaIndex| RAG| Fine-tuning| LangChain AI Agent Multimodal Models| RNNs| DCGAN| ProGAN| Text-to-Image Models| DDPM| Document Question Answering| Imagen| T5 (Text-to-Text Transfer Transformer)| Seq2seq Models WaveNet| Attention Is All You Need (Transformer Architecture)Popular GenAI Models
Llama 3.1| Llama 3| Llama 2| GPT 4o Mini| GPT 4o| GPT 3| Claude 3 Haiku| Claude 3.5 Sonnet| Phi 3.5| Phi 3| Mistral Large 2| Mistral NeMo| Mistral-7b| Gemini 1.5 Pro| Gemini Flash 1.5| Bedrock| Vertex AI| DALL.E| Midjourney| Stable DiffusionData Science Tools and Techniques
Python| R| SQL| Jupyter Notebooks| TensorFlow| Scikit-learn| PyTorch| Tableau| Apache Spark| Matplotlib| Seaborn| Pandas| Hadoop| Docker| Git| Keras| Apache Kafka| AWS| NLP| Random Forest| Computer Vision| Data Visualization| Data Exploration| Big Data| Common Machine Learning Algorithms| Machine LearningEnter email address to continue
Enter OTP sent to
Edit
Resend OTP
Resend OTP in 45s