 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Emotion Recognition
Multimodal emotion recognition is the process of recognizing emotions from multiple modalities, such as speech, text, and facial expressions.
Papers and Code
MultiMAE-DER: Multimodal Masked Autoencoder for Dynamic Emotion Recognition
Apr 28, 2024This paper presents a novel approach to processing multimodal data for dynamic emotion recognition, named as the Multimodal Masked Autoencoder for Dynamic Emotion Recognition (MultiMAE-DER). The MultiMAE-DER leverages the closely correlated representation information within spatiotemporal sequences across visual and audio modalities. By utilizing a pre-trained masked autoencoder model, the MultiMAEDER is accomplished through simple, straightforward finetuning. The performance of the MultiMAE-DER is enhanced by optimizing six fusion strategies for multimodal input sequences. These strategies address dynamic feature correlations within cross-domain data across spatial, temporal, and spatiotemporal sequences. In comparison to state-of-the-art multimodal supervised learning models for dynamic emotion recognition, MultiMAE-DER enhances the weighted average recall (WAR) by 4.41% on the RAVDESS dataset and by 2.06% on the CREMAD. Furthermore, when compared with the state-of-the-art model of multimodal self-supervised learning, MultiMAE-DER achieves a 1.86% higher WAR on the IEMOCAP dataset.
Dynamic Modality and View Selection for Multimodal Emotion Recognition with Missing Modalities
Apr 18, 2024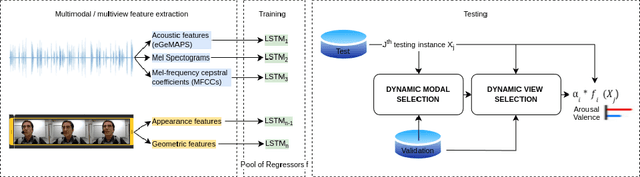
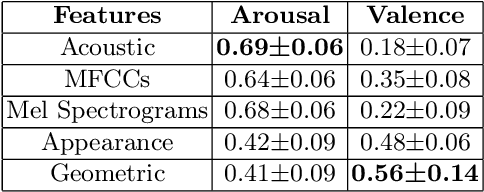
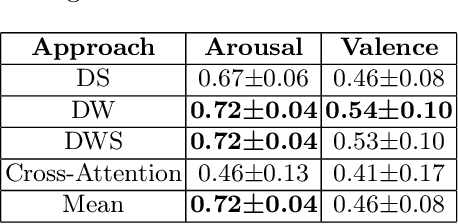
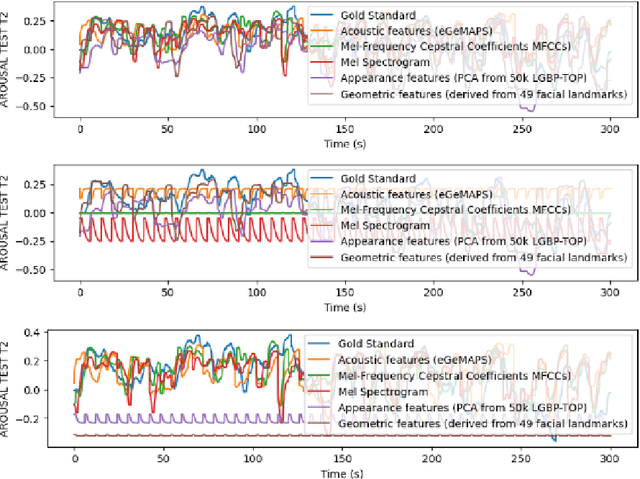
The study of human emotions, traditionally a cornerstone in fields like psychology and neuroscience, has been profoundly impacted by the advent of artificial intelligence (AI). Multiple channels, such as speech (voice) and facial expressions (image), are crucial in understanding human emotions. However, AI's journey in multimodal emotion recognition (MER) is marked by substantial technical challenges. One significant hurdle is how AI models manage the absence of a particular modality - a frequent occurrence in real-world situations. This study's central focus is assessing the performance and resilience of two strategies when confronted with the lack of one modality: a novel multimodal dynamic modality and view selection and a cross-attention mechanism. Results on the RECOLA dataset show that dynamic selection-based methods are a promising approach for MER. In the missing modalities scenarios, all dynamic selection-based methods outperformed the baseline. The study concludes by emphasizing the intricate interplay between audio and video modalities in emotion prediction, showcasing the adaptability of dynamic selection methods in handling missing modalities.
Cooperative Sentiment Agents for Multimodal Sentiment Analysis
Apr 19, 2024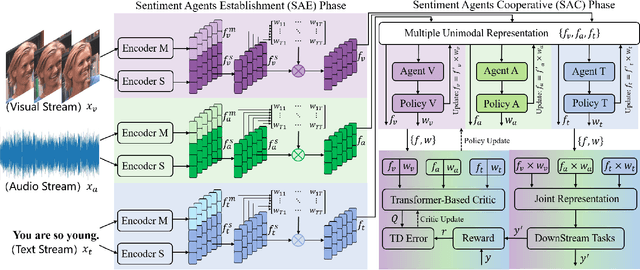
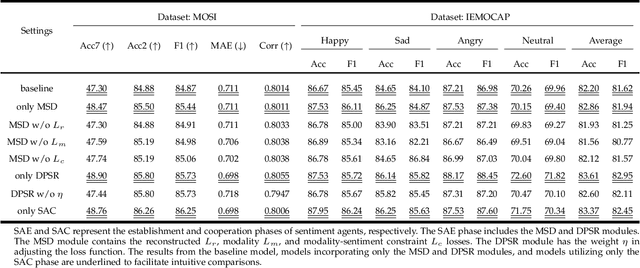
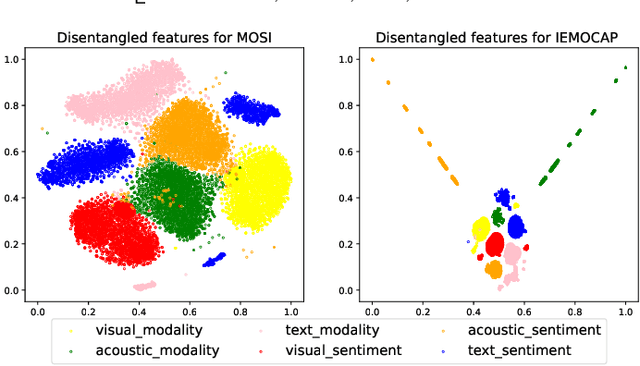
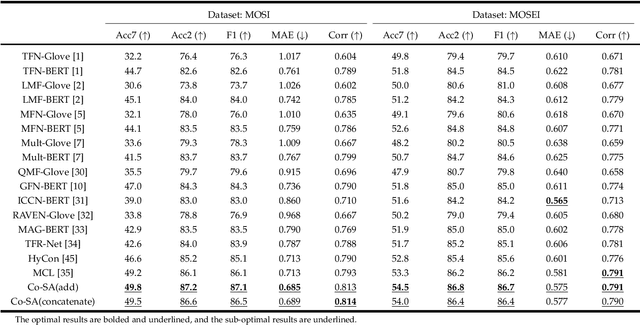
In this paper, we propose a new Multimodal Representation Learning (MRL) method for Multimodal Sentiment Analysis (MSA), which facilitates the adaptive interaction between modalities through Cooperative Sentiment Agents, named Co-SA. Co-SA comprises two critical components: the Sentiment Agents Establishment (SAE) phase and the Sentiment Agents Cooperation (SAC) phase. During the SAE phase, each sentiment agent deals with an unimodal signal and highlights explicit dynamic sentiment variations within the modality via the Modality-Sentiment Disentanglement (MSD) and Deep Phase Space Reconstruction (DPSR) modules. Subsequently, in the SAC phase, Co-SA meticulously designs task-specific interaction mechanisms for sentiment agents so that coordinating multimodal signals to learn the joint representation. Specifically, Co-SA equips an independent policy model for each sentiment agent that captures significant properties within the modality. These policies are optimized mutually through the unified reward adaptive to downstream tasks. Benefitting from the rewarding mechanism, Co-SA transcends the limitation of pre-defined fusion modes and adaptively captures unimodal properties for MRL in the multimodal interaction setting. To demonstrate the effectiveness of Co-SA, we apply it to address Multimodal Sentiment Analysis (MSA) and Multimodal Emotion Recognition (MER) tasks. Our comprehensive experimental results demonstrate that Co-SA excels at discovering diverse cross-modal features, encompassing both common and complementary aspects. The code can be available at https://github.com/smwanghhh/Co-SA.
Multimodal Emotion Recognition by Fusing Video Semantic in MOOC Learning Scenarios
Apr 11, 2024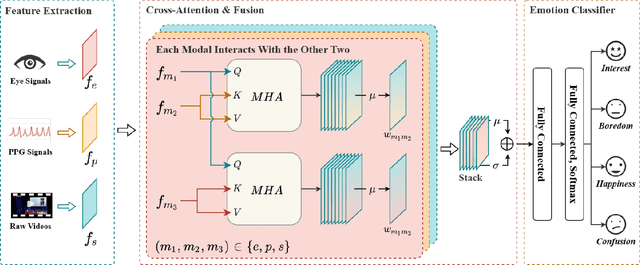

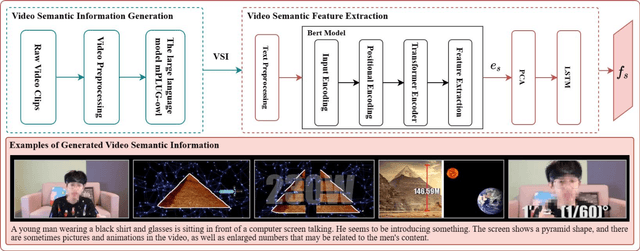
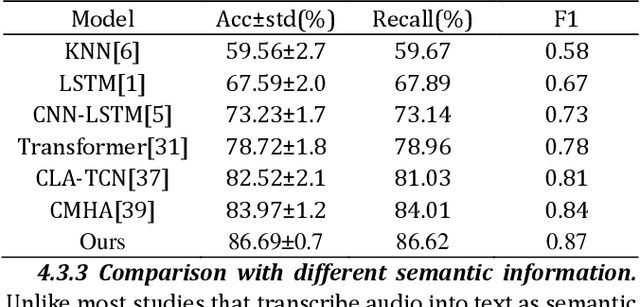
In the Massive Open Online Courses (MOOC) learning scenario, the semantic information of instructional videos has a crucial impact on learners' emotional state. Learners mainly acquire knowledge by watching instructional videos, and the semantic information in the videos directly affects learners' emotional states. However, few studies have paid attention to the potential influence of the semantic information of instructional videos on learners' emotional states. To deeply explore the impact of video semantic information on learners' emotions, this paper innovatively proposes a multimodal emotion recognition method by fusing video semantic information and physiological signals. We generate video descriptions through a pre-trained large language model (LLM) to obtain high-level semantic information about instructional videos. Using the cross-attention mechanism for modal interaction, the semantic information is fused with the eye movement and PhotoPlethysmoGraphy (PPG) signals to obtain the features containing the critical information of the three modes. The accurate recognition of learners' emotional states is realized through the emotion classifier. The experimental results show that our method has significantly improved emotion recognition performance, providing a new perspective and efficient method for emotion recognition research in MOOC learning scenarios. The method proposed in this paper not only contributes to a deeper understanding of the impact of instructional videos on learners' emotional states but also provides a beneficial reference for future research on emotion recognition in MOOC learning scenarios.
MIPS at SemEval-2024 Task 3: Multimodal Emotion-Cause Pair Extraction in Conversations with Multimodal Language Models
Apr 11, 2024

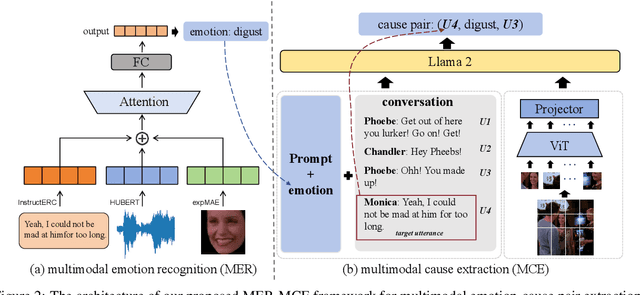
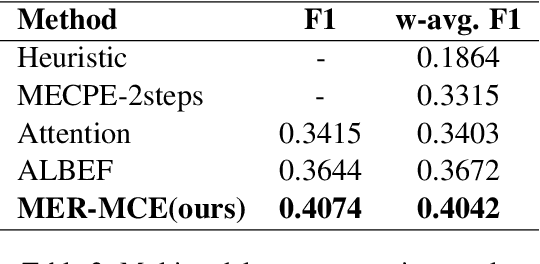
This paper presents our winning submission to Subtask 2 of SemEval 2024 Task 3 on multimodal emotion cause analysis in conversations. We propose a novel Multimodal Emotion Recognition and Multimodal Emotion Cause Extraction (MER-MCE) framework that integrates text, audio, and visual modalities using specialized emotion encoders. Our approach sets itself apart from top-performing teams by leveraging modality-specific features for enhanced emotion understanding and causality inference. Experimental evaluation demonstrates the advantages of our multimodal approach, with our submission achieving a competitive weighted F1 score of 0.3435, ranking third with a margin of only 0.0339 behind the 1st team and 0.0025 behind the 2nd team. Project: https://github.com/MIPS-COLT/MER-MCE.git
MMA-DFER: MultiModal Adaptation of unimodal models for Dynamic Facial Expression Recognition in-the-wild
Apr 13, 2024Dynamic Facial Expression Recognition (DFER) has received significant interest in the recent years dictated by its pivotal role in enabling empathic and human-compatible technologies. Achieving robustness towards in-the-wild data in DFER is particularly important for real-world applications. One of the directions aimed at improving such models is multimodal emotion recognition based on audio and video data. Multimodal learning in DFER increases the model capabilities by leveraging richer, complementary data representations. Within the field of multimodal DFER, recent methods have focused on exploiting advances of self-supervised learning (SSL) for pre-training of strong multimodal encoders. Another line of research has focused on adapting pre-trained static models for DFER. In this work, we propose a different perspective on the problem and investigate the advancement of multimodal DFER performance by adapting SSL-pre-trained disjoint unimodal encoders. We identify main challenges associated with this task, namely, intra-modality adaptation, cross-modal alignment, and temporal adaptation, and propose solutions to each of them. As a result, we demonstrate improvement over current state-of-the-art on two popular DFER benchmarks, namely DFEW and MFAW.
GMP-ATL: Gender-augmented Multi-scale Pseudo-label Enhanced Adaptive Transfer Learning for Speech Emotion Recognition via HuBERT
May 03, 2024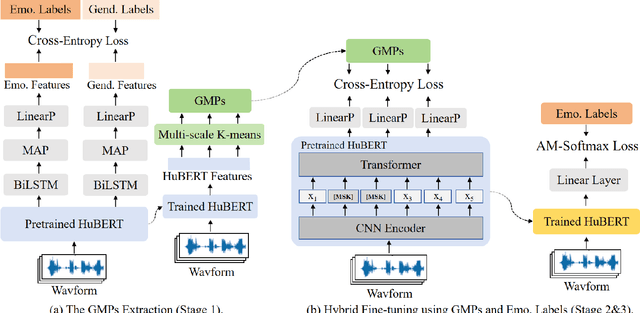
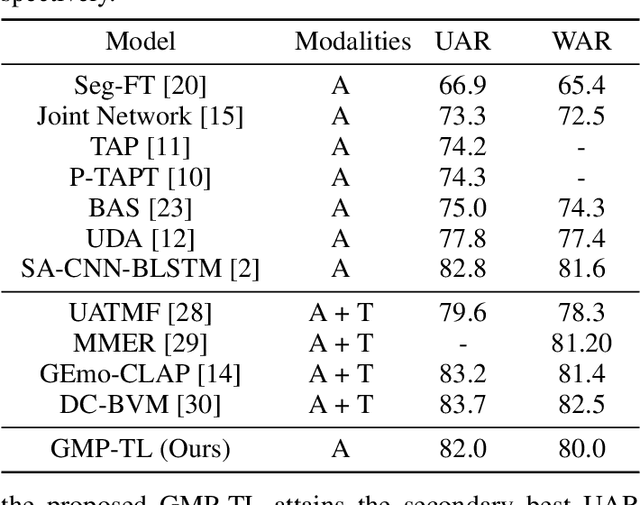
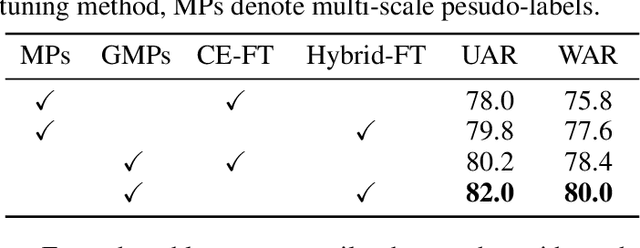
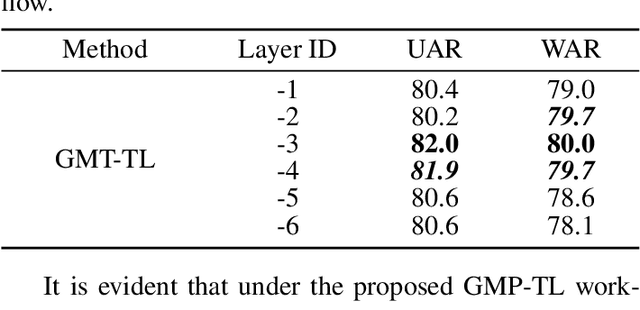
The continuous evolution of pre-trained speech models has greatly advanced Speech Emotion Recognition (SER). However, there is still potential for enhancement in the performance of these methods. In this paper, we present GMP-ATL (Gender-augmented Multi-scale Pseudo-label Adaptive Transfer Learning), a novel HuBERT-based adaptive transfer learning framework for SER. Specifically, GMP-ATL initially employs the pre-trained HuBERT, implementing multi-task learning and multi-scale k-means clustering to acquire frame-level gender-augmented multi-scale pseudo-labels. Then, to fully leverage both obtained frame-level and utterance-level emotion labels, we incorporate model retraining and fine-tuning methods to further optimize GMP-ATL. Experiments on IEMOCAP show that our GMP-ATL achieves superior recognition performance, with a WAR of 80.0\% and a UAR of 82.0\%, surpassing state-of-the-art unimodal SER methods, while also yielding comparable results with multimodal SER approaches.
UniMEEC: Towards Unified Multimodal Emotion Recognition and Emotion Cause
Mar 30, 2024Multimodal emotion recognition in conversation (MERC) and multimodal emotion-cause pair extraction (MECPE) has recently garnered significant attention. Emotions are the expression of affect or feelings; responses to specific events, thoughts, or situations are known as emotion causes. Both are like two sides of a coin, collectively describing human behaviors and intents. However, most existing works treat MERC and MECPE as separate tasks, which may result in potential challenges in integrating emotion and cause in real-world applications. In this paper, we propose a Unified Multimodal Emotion recognition and Emotion-Cause analysis framework (UniMEEC) to explore the causality and complementarity between emotion and emotion cause. Concretely, UniMEEC reformulates the MERC and MECPE tasks as two mask prediction problems, enhancing the interaction between emotion and cause. Meanwhile, UniMEEC shares the prompt learning among modalities for probing modality-specific knowledge from the Pre-trained model. Furthermore, we propose a task-specific hierarchical context aggregation to control the information flow to the task. Experiment results on four public benchmark datasets verify the model performance on MERC and MECPE tasks and achieve consistent improvements compared with state-of-the-art methods.
Recursive Joint Cross-Modal Attention for Multimodal Fusion in Dimensional Emotion Recognition
Mar 30, 2024
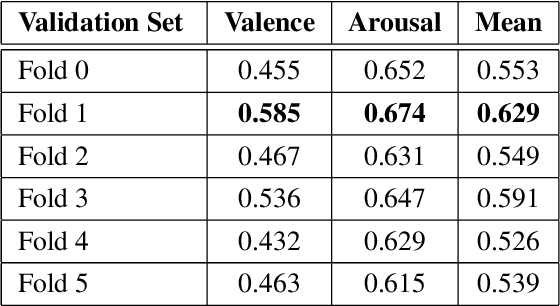
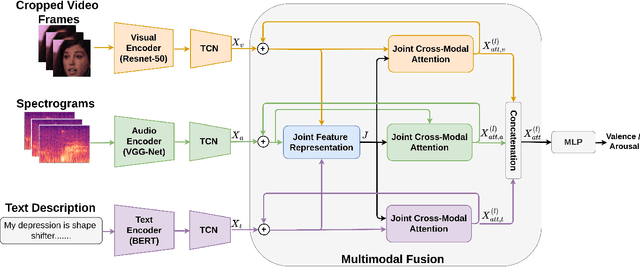
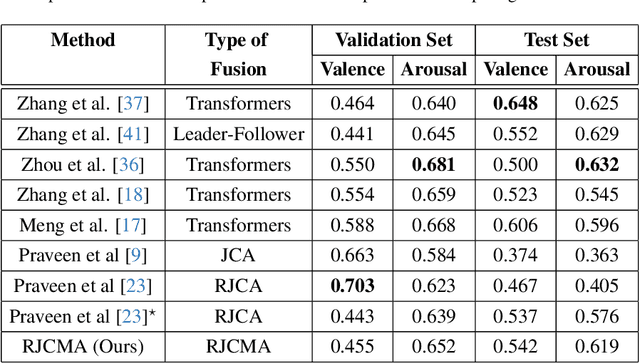
Though multimodal emotion recognition has achieved significant progress over recent years, the potential of rich synergic relationships across the modalities is not fully exploited. In this paper, we introduce Recursive Joint Cross-Modal Attention (RJCMA) to effectively capture both intra-and inter-modal relationships across audio, visual and text modalities for dimensional emotion recognition. In particular, we compute the attention weights based on cross-correlation between the joint audio-visual-text feature representations and the feature representations of individual modalities to simultaneously capture intra- and inter-modal relationships across the modalities. The attended features of the individual modalities are again fed as input to the fusion model in a recursive mechanism to obtain more refined feature representations. We have also explored Temporal Convolutional Networks (TCNs) to improve the temporal modeling of the feature representations of individual modalities. Extensive experiments are conducted to evaluate the performance of the proposed fusion model on the challenging Affwild2 dataset. By effectively capturing the synergic intra- and inter-modal relationships across audio, visual and text modalities, the proposed fusion model achieves a Concordance Correlation Coefficient (CCC) of 0.585 (0.542) and 0.659 (0.619) for valence and arousal respectively on the validation set (test set). This shows a significant improvement over the baseline of 0.24 (0.211) and 0.20 (0.191) for valence and arousal respectively on the validation set (test set) of the valence-arousal challenge of 6th Affective Behavior Analysis in-the-Wild (ABAW) competition.
Samsung Research China-Beijing at SemEval-2024 Task 3: A multi-stage framework for Emotion-Cause Pair Extraction in Conversations
Apr 25, 2024
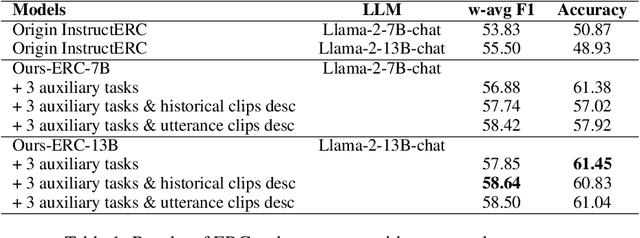
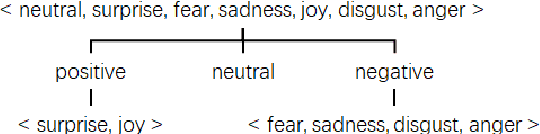
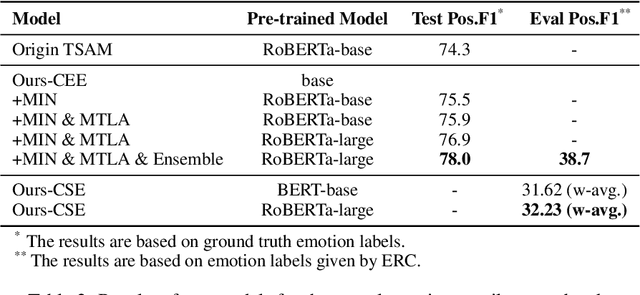
In human-computer interaction, it is crucial for agents to respond to human by understanding their emotions. Unraveling the causes of emotions is more challenging. A new task named Multimodal Emotion-Cause Pair Extraction in Conversations is responsible for recognizing emotion and identifying causal expressions. In this study, we propose a multi-stage framework to generate emotion and extract the emotion causal pairs given the target emotion. In the first stage, Llama-2-based InstructERC is utilized to extract the emotion category of each utterance in a conversation. After emotion recognition, a two-stream attention model is employed to extract the emotion causal pairs given the target emotion for subtask 2 while MuTEC is employed to extract causal span for subtask 1. Our approach achieved first place for both of the two subtasks in the competition.