
The race of self-assist technology has been amping up since the evolution of artificial general intelligence. Many efficient products powered with object recognition technology are being launched to auto-detect obstacles and replicate human vision.While some businesses avail object recognition to authenticate biometrics and verify employee credentials, others are racing along the lines to build intelligent automation products. These products are pre-programmed with image recognition software and possess the capability of scanning real-time surroundings and identifying external objects with optimum accuracy.
Rapid advancements can be seen across e-commerce, automotive, healthcare, banking, and logistics industries. as new object recognition systems enable consumers to virtually navigate crowded areas, get faster services, and put a lot of tasks on autopilot to reduce complications and worries. The advent of AI-powered vision products has made our day-to-day lives simpler.
What is object recognition?
Object recognition is a computer vision technique that localizes, identifies, and categorizes elements from static or dynamic images or videos. It is gaining momentum across industries that are launching humanoids, artificial pets, auto-assist appliances, home assistants, and Internet of Things (IoT) devices. Object recognition deploys deep learning to simulate naturally occurring brain intelligence and optical activity of humans.
Object recognition is a subset of artificial intelligence that extracts necessary information or critical insights from an image or video. It aims to help a computer see an existing image and break it down into a series of pixels to recognize a specific pattern or shape.
A successful object recognition algorithm depends on the quality of data required to train it. More data means that the model will more quickly classify objects based on known characteristics.
The probability of accurately identifying an object depends on an image's attributes. In artificial intelligence, the system calculates a confidence score to predict the label or class of an object. However, algorithmic computation in object recognition is a bit complex and requires complete understanding to achieve results.
Important types of object recognition
Object recognition combines four techniques: image recognition object localization, object detection, and image segmentation. Object recognition decodes the features and predicts the category or class of image through a classifier, for example, supervised machine learning models like Support Vector Machine (SVM), Adaboost, Boosting, or Decision Tree. Object recognition algorithms are coded in Darknet, an open-source neural network framework written in C, Cuda, or Python.
Here are some essential types of object recognition:
Image recognition
Image recognition is a predecessor of object recognition. It’s a critical stage in the entire process, used to predict the category of any given image. For example, if you have a picture of a dog in the park, the image recognition system analyzes the dog's core features: face size, limbs, tendons, etc, and then compares it to thousands of trained images to display the "dog" as an output.
Top 10 Image Recognition Platforms
- Cloud Vision API
- Rekognition
- Google Cloud AutoML Vision
- Microsoft Computer Vision API
- Azure Content Moderator
- Microsoft Video API
- Azure Face API
- Azure Custom Vision Service
- NVIDIA Deep Learning GPU Training System (DIGITS)
- Deepdream
*These are ten highly rated image recognition platforms with substantial market presence from the G2 Summer 2024 Grid® Report.
Object localization
This technique is used to locate the exact place of each type of object in an image. If you input an image with a dog and two cats, it creates a bounding box encapsulating three things: a dog and two cats to locate location coordinates, height, and width, along with a class prediction.
Single object localization identifies only one instance of every object and returns its location. In the above example, single object localization returns the value of one dog and one cat, thus eliminating the redundant component.
Object detection
The object detection system is similar to the object recognition system. The goal of an object detection system is only to identify and classify all the occurrences of a particular object or a set of objects in an image. In object detection, the system automatically detects the presence of an object and predicts its class.
Image segmentation
For image segmentation, a neural network or machine learning algorithm is trained to locate individual objects based on pixels in an image. Instead of creating a boundary, it analyzes the pixels of the object individually and highlights their location to ascertain the object’s presence. In the case of partly occluded or hidden objects, the system doesn't return any value as it cannot find shadowed counterparts of the image.
For example, if there is a car picture, the system colors the entire car red to point it out along with a class prediction "car" and a confidence score "of 85%." This output determines that the system is 85% sure that the object in the image is a car.
Want to learn more about Image Recognition Software? Explore Image Recognition products.
Object recognition vs object detection vs image segmentation
The differences between these similar-sounding computer vision techniques can be confusing, especially when all help accomplish a similar task.
-png.png)
-png.png)
Object recognition is a general term to describe a set of computer vision tasks that involve identifying components of a real-world using object modeling. In digital image processing, object recognition is used to classify tangible and intangible objects, the way the human brain does.
Object detection model is an intermediary between the system and the image. It assists with the multi-class categorization of objects between different data classes known to the model. Object detection helps determine the essence of an entity in any shape or form: straight, crooked, occluded, etc. It’s capable enough to point out multiple occurrences of a single entity and produce as many bounding boxes as required. It cannot extrapolate the area, volume, or perimeter of the object in the image.
Image segmentation is an extension of object recognition. This technique objects using pixelation of a particular area of the object or the complete image. It’s a more granular form of object recognition in which the entire image is scanned and outlined by pixels and interpreted by the computer to find the relevant category. There are two types of image segmentation methods:
- Instance segmentation: Identifying the boundaries of every instance of an object and representing it with different colors, signaling the correct class.
- Semantic segmentation: Labeling each pixel in the image (including background) and setting illumination contrasts to differentiate the objects from one another.
Object recognition vs Image recognition
Computer vision is a layered technology, with one or more tasks merging with one another. Object recognition and image recognition are a testament to this. Both techniques have marked praiseworthy milestones across many domains with the same benefits.
-png.png)
| Image Recognition | Object Recognition |
| Image recognition predicts the class of an image or video as a whole. | Object recognition identifies multiple objects in an image or video with defined labels. |
| It bundles image class and descriptive integers together to display key output. | It bundles together, class, location, frequency, and other factors of objects. |
| Users can scan a quick response (QR) code to anchor digital content on an image. | Users can slide a camera or smartphone to label real-world objects in real-time. |
| A list class is fed into the training model to identify images. | Powerful machine learning algorithms detect unknown features to identify objects. |
| The model is trained on the K-nearest neighbor algorithm | Each object is assigned a bounding box that predicts a confidence score. |
| In the supply chain, it is used to identify certain goods and classify them as defective or not defective. | It helps in performing facial recognition across domains to detect trespassers and alarm the concerned team. |
How does object recognition work?
A successful object recognition algorithm has two influential factors: the algorithm's efficiency and the number of objects or features in the image. The idea is to align the image with the machine learning algorithm and extract relevant features to identify and localize the objects present in it. Features can be either functional or geometrical in nature.
The result is always either a linear or a binary class prediction – Yes or No, whichever data model you deploy. Here is how it works:
Feature extraction
Feature extractors are the operators that break an image into different warped parts and extract unknown components for classification. It is mainly obtained by a supervised machine learning algorithm or a trained convolutional neural network (CNN) model like Alexnet or Inception. The algorithm creates a feature map of the image to make it easier to identify objects.
Bounding box
Each part of the image is enclosed within a bounding box or anchor box. The bounding box is static for an image but dynamic for identifying objects in a video. It is a rectangular boundary that restricts the movement of the object or its features for easier classification. Bounding boxes can help extract information like graphical coordinates, probability score, height, width, etc along with 25 more data elements.
Hypothesis formation
The number of image features extracted and the quality of the training data fed to the algorithm are critical elements of hypothesis formation. After feature extraction, the system generates a probability score and assigns it to objects present in the image. This is mainly done to lessen the workload of a machine learning classifier. The final output is calculated based on the probability score and class prediction for each object in the picture.
Hypothesis verification
At this point, the earlier hypothesis is verified, resulting in a mean classification score i.e. a metric used by the algorithm to compute the performance of class prediction of different objects in the picture. The deployed AI model checks relevant features of the object (shape, size, color, etc.), and class prediction by the bounding box enclosing the object. Once both parameters are checked, the system assigns a final composite score.
Recognition and mapping
Once the algorithm classifies the features, it maps the coordinates for the bounding box with the object. This information is fed into a support vector machine (SVM) that uses a frequent pattern (FP) growth tool to predict the object's class in real-time.
Linear regression
After the class prediction, the image goes through linear regression to find the exact tensor (container of numeric data returned by the regressor of the object). Regression is performed using open-source platforms such as Darknet, TensorFlow, or PyTorch. The final output of the object recognition algorithm comprises the categorization of object class along with details of its bounding box to specify the exact location of the object in the image.
Did you know? The global image recognition market size will grow from $26.2 billion in 2020 to $53.0 billion by 2025, at a Compound Annual Growth Rate (CAGR) of 15.1 % from 2020 to 2025!
Source: MarketsandMarkets
Different object recognition techniques
The approach to object recognition is mainly twofold – machine learning algorithms or deep learning-based convolutional neural network (CNN) models. To perform an object recognition task using a machine learning approach, you need a feature extractor that identifies previously unknown object information to differentiate between general label categories.
On the flip side, using a CNN network for object recognition doesn’t require manual feature extraction or hypothesis testing. It can help detect objects and their location directly by predicting the properties of the bounding box enclosing it.
Keep reading to find out about some standard approaches that can be used to perform object recognition across industries.
Machine Learning
Machine learning is one of the most popular approaches for verifying the presence of an object. The machine learning algorithm is a predictive analytics data model that can be trained on numerous categories i.e cars, bikes, mountains, etc. Several supervised and unsupervised machine learning algorithms offer many combinations of feature extractors and model datasets that execute object recognition tasks efficiently and precisely.
Let's have a look at some of them:
Viola-Jones algorithm
Viola-Jones algorithm is one of the most popular object recognition frameworks. Its main objective is to enable the system to see human faces in a straight configuration using the process below:
- The image captured from a camera or a webcam is downsized to create a new image.
- Features like mouth or nose and their relationship to each other are manually programmed and added to the new image.
- The Viola-Jones algorithm runs on the new image to create a series of output elements that coincide with the existing features of the object.
- Outputs are fed into a support vector machine to identify the class of objects in the image, for example, the face.
Soon after launch, the Viola-Jones algorithm was implemented in OpenCV and became famous as one of the most successful techniques for performing object recognition. However, one challenge that popped up was that it failed to identify objects with partial occlusion or warped configurations.
Tip: An OpenCV classifier is a machine learning-based approach used to cross-check the trueness of object class through cascade function. OpenCV can be used with any machine learning object detection algorithm.
Histogram of Oriented Gradients
A more workable version of the erstwhile algorithm, namely the Histogram of Oriented Gradients (HOGG), came out in 2005. HOGG was an improvised machine learning algorithm widely used in pedestrian detection and image processing for object recognition. Here’s how it works:
- The system visualized a given image as a series of pixels.
- For each pixel, it calculated how dark its gradient was as compared to the surrounding pixel.
- An arrow was drawn, pointing toward the darker pixel. This process repeated until every single pixel was replaced.
- A matrix of arrows or gradients separated the image into small (16x16) squares. Each square pointed toward the place where the image was dark.
- Arrows that captured the exact essence of the object replace the squares.

The system compared the output with the original image using metrics like Euclidean or Minkowski distance. Based on a threshold value, it determined whether the given image was an object or not. HOGG became extremely popular as it was quick to compute and provided a much more stable model for the object classifier to work accurately.
Scale Invariant Feature Transform
Scale Invariant Feature Transform ( SIFT) is a popular computer vision algorithm that helps identify objects in digital images through corner edges. More like an edge detection technique, SIFT identifies the entire scanline of an image and graphically plots specific vital points using a logarithmic function. Once features are localized, it passes on this quantitative information or descriptors to a classifier to categorize the objects and find their specific location in the image.
Bag of Features algorithm
The “bag of features” algorithm randomly parses different features of an object in order to identify its category. Built on evolving Natural Language Processing (NLP ) technology, it is an unsupervised machine learning algorithm that stores a dictionary of the features it has detected to learn on its own and get better results.
Deep Learning
The era of deep learning officially began in 2012. With the rise in automobile technology, intelligent video surveillance, and new API standards, object recognition tasks have become relatively simple. However, there is a lot of work that comes with solving object recognition problems through deep learning as it requires sufficient graphical processing unit (GPU) power and a large training dataset.
The CNN is a deep learning model that solves complex computer vision tasks through artificial intelligence. The model itself has specific input and output layers that mimic the brain's structure. The layers of this model represent naturally occurring axons, dendrites, pons, and optical fibers of the brain that fuel the human vision system. Here are a couple of deep learning algorithms that improved the scope of computer vision:
R-CNN
Region-based convolutional neural network (R-CNN) is a high-performing self-trained model that works on the VOC-2012 dataset and ILSVRC 2021 dataset.
ImageNet Large Scale Visual Recognition Challenge (ILSVRC) is an annual academic competition that has a separate challenge for image classification, object localization, and object detection problems. It is conducted with the intent of fostering independent and separate solutions for each task that can be implemented on a broader scale.
Given below is a detailed process of image recognition through R-CNN.
- First, the user needs to generate a set of uncategorized bounding boxes for an image or "candidate regions" using a selective search algorithm.
- At a high level, the selective search process looks at the image through a series of windows of different sizes.
- Each candidate region groups the image's features like shape, color, pixels, intensity, etc.
- These feature maps of an image are passed through a pre-trained CNN (Alexnet CNN) model to extract core features and compute the output elements.
- Once the output elements are displayed, they are fed into an SVM classifier to classify the labels.
Source: machinelearningmastery.com
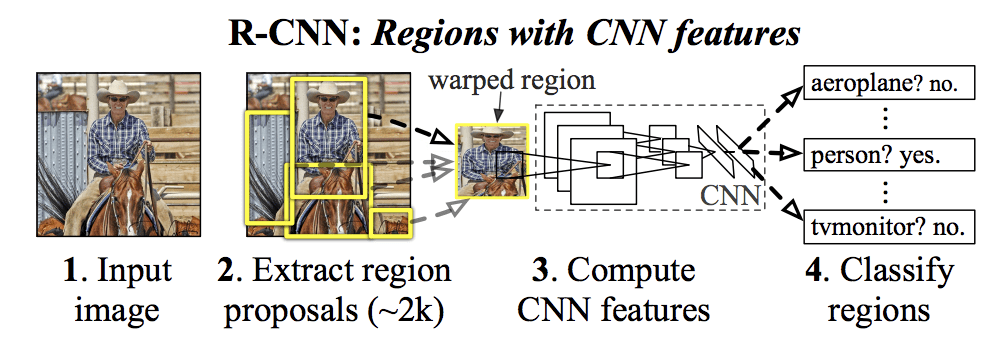
Limitations of the R-CNN algorithm
Although R-CNN proved to be a significantly faster model to train an object recognition model and make predictions, there were still some limitations to its workability. Here is a set of constraints for R-CNN that thwarted it from producing accurate results:- Selective search, Alexnet CNN, and SVM classifier all have to be trained on a model database and operated using large amounts of graphical processing power.
- Training a neural network simultaneously on more than 2000 region proposals was tedious and time-consuming.
- The model compiled each candidate region one by one sequentially while testing. As it did not scan the entire image in one go, the actual predictions were partially occluded and misty.
Did you know? More efficient object recognition models have been recently proposed, namely Fast R-CNN, Faster R-CNN, and Mask R-CNN. These algorithms have been pre-trained on large datasets like VGG-16 and PASCAL VOC and produce state-of-the-art class predictions.
You Only Look Once (YOLO)
Just like the analogy of "you only live once," YOLO is a convolutional neural network that analyzes data once and for all. It has been launched in recent years. Out of all the approaches to performing object recognition tasks, YOLO is the most accurate. It looks at an image only once but in a clever way. The feature extraction of an image or video through YOLO is residue-free and entirely seamless. It cuts down on the probability assigned by the system of an object belonging to a specific class by some amount, thus resulting in a more stable model and accurate classification of objects.
Here is a standardized overview of how YOLO works:
- The image is divided into a grid of 13*13 = 169 cells of equal dimensions.
- Each cell of the image is responsible for the prediction of up to 5 bounding boxes.
- At some point, bounding boxes overlap fragments of objects inside the little cell.
- Once it overlaps an object, it assigns a confidence score predicting whether the bounding box has captured an object or not.
- In addition to predicting the presence of the bounding box, the YOLO model also assigns a specific class (e.g traffic lights, person, car, etc.) to each bounding box.
- A total of 169*5 or 845 bounding boxes are assigned different confidence intervals across the image.
- The confidence interval is combined with the class prediction of the object.
- Based on a threshold number, all the unnecessary bounding boxes are eliminated, and the image is only left with 2 to 3 boxes that fit the object perfectly.
YOLO implementation for object recognition
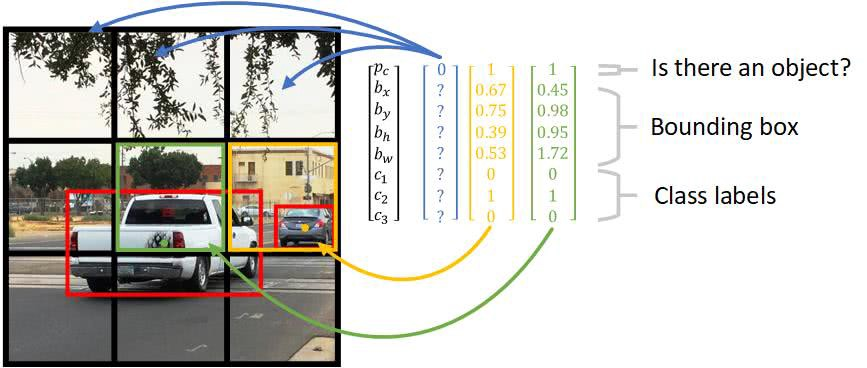
YOLO is not a traditional classifier. The neural network runs once on the image. Each cell in the image grid has a specific tensor value. In this case, five bounding boxes are predicted by each cell. Each bounding box is responsible for orchestrating 25 data elements for the underlying object. These elements can include height, width, box coordinates (bx, by), probability score, or confidence interval. Hence, the tensor value, in this case, will be 25*5 = 125.
YOLO neural network assigns a likelihood value to each part of the picture, making it easier for the recognizer to identify and locate the presence of objects in the image.
Tip: YOLO's latest version, YOLOv2 or YOLO9000, is a single run, real-time object detection CNN that has been trained on 9000 object classes and can be embedded in a .mp3 or .mov file to predict bounding boxes using pre-declared weights, softmax classifier, and anchors.
Why is the YOLO algorithm important?
Out of all the existing approaches to computer vision, YOLO best gives a computer the ability to detect objects in real surroundings and interact with them, almost as well as human beings do. As YOLO is a convolutional neural network, it requires a lot of GPU and training data to work efficiently. Here are some reasons why YOLO is the most preferred object recognition approach in various business application domains:
- It predicts objects in images in real-time and runs at a lightning-fast speed of 45 FPS.
- It provides accurate results with minimal errors.
- Over time, it learns to understand shapes and patterns in unknown images on its own to classify their category.
Other techniques of object recognition
Implementing a simple method for object recognition rather than webbed artificial intelligence approaches is best. Having a direct path to problems lessens the cognitive complexity of a problem. It prevents the system model from collecting multiple images.
Here are some simple techniques of object recognition that you can use to identify objects within a picture:
- Template matching: Template matching is a technique where the user compares the image with a pre-existing template, maps the similarity of the features, and assigns a label to the picture. Pattern–recognition-based object recognition systems work entirely on template matching techniques and do not require any hypothesis formation to determine objects.
- Visual transformer: The visual transformer employs a Transformer-like architecture over patches of an image. The image is divided into smaller patches, each projected onto an encoder using a linear classifier. The output is a standard set of vectors that meets with a classification node to predict the presence of objects.
Is object recognition the same as facial recognition?
Face recognition and object recognition are two sides of the same coin. Facial recognition is new-age technology that automatically recognizes face-like structures within an image to determine its identity. In real-time, facial recognition helps detect the unidentified presence of human beings or suspicious objects in a confined space with the help of cameras or embedded devices. The usability of facial recognition spans many different industrial domains, like robotic process automation (RPA), biometrics detection, and defense operations.
Applications of object recognition
Object recognition is inextricably linked to many real-life applications across business domains. Several iterations have been made to create and fine-tune object recognition for commercial and non-commercial sectors. So far, businesses have been reasonably successful in performing object recognition using narrow AI.
Here are some real-life application object recognition systems across different domains of industry research:
- Security and surveillance: Offices and residential complexes have been using traditional CCTV cameras based on visual object recognition principles. People now even use security systems for their household activities. While an outdoor camera helps watch visitors, indoor cameras help monitor a baby's actions.
- Satellite and earth-imaging: Object recognition helps detect objects in aerial imagery and atmospheric pressure. It can also let us predict the position of tectonic plates rattling inside our core due to constant metamorphosis. The assistance from radio frequency distribution (RFID) allows pilots and air traffic control (ATC) towers to maintain continuous communication with each other.
- Self-driven automobiles: Object recognition is a crucial part of self-driven automobiles. The vehicles powered with object recognition have the ability to move around freely without anyone in control of the steering wheel. To ensure safe driving, they must be fully equipped with computational visibility. Active sensors such as lidar weigh the depth, position, and relative distance of objects surrounding the vehicles and identify roadblocks and collisions.
- Animal monitoring for poultry: Recognition and identification of livestock such as pigs or any other cattle across multiple farms are now possible using AI vision algorithms and inexpensive surveillance cameras. Compared to other methods, AI vision helps keep a check on the health and welfare of animals. This leads to improved product quality and profitability of animal products.
- Advanced human-computer interaction: Object recognition establishes a channel of interaction between humans and computers in different application domains. It helps improve two-way communication between two dependent or independent intelligent genes and allows accurate sending and receiving of signals.
- Robot vacuums: Object recognition is the standpoint of robotic process automation. Robot vacuums like cyborgs and Roomba are powered by AI technology for cleaning floors without bumping into anything. With the help of a built-in camera and 3D sensor, the robot recognizes objects from a distance, classifies them as distractions, and cuts in a different direction.
Object recognition and augmented reality
Object recognition is one of the crucial performance vectors in the process of augmented reality. Augmented reality enhances users' perception of the natural world through CG overlays such as graphics, text, or sounds. With the help of object recognition, it becomes pretty simple to detect and manipulate real-life elements to relay relevant visual information and create highly engaging experiences.
Object recognition is a marker-based technique that helps register a connection with a real-world object and track its position in real-time to overlay 3D animations on top of it. In other words, object recognition locates high-contrast spots, curves, or edges of objects from different angles to create a virtual slideshow before our eyes.
Passing the gift of vision to computers
Years ago, who would have thought that artificial intelligence would no longer be known as the "fifth generation of computers," but as a current game-changer for humanity?
Object recognition passes the baton of vision from humans to computers. It holds the potential to transform the modern business sphere by designing state-of-the-art, secure customer experiences.
The future of object recognition also depends on the evolution of artificial intelligence technology. Much like the original industrial revolution, it will reduce man labor in the future and empower humans to do what they are better equipped for - being creative and empathetic.
Tackle data labeling like a pro with active learning tools and cut organizational AI infrastructure costs while maintaining highest accuracy.

Shreya Mattoo
Shreya Mattoo is a Content Marketing Specialist at G2. She completed her Bachelor's in Computer Applications and is now pursuing Master's in Strategy and Leadership from Deakin University. She also holds an Advance Diploma in Business Analytics from NSDC. Her expertise lies in developing content around Augmented Reality, Virtual Reality, Artificial intelligence, Machine Learning, Peer Review Code, and Development Software. She wants to spread awareness for self-assist technologies in the tech community. When not working, she is either jamming out to rock music, reading crime fiction, or channeling her inner chef in the kitchen.


