

An Adaptive Sampling Algorithm with Dynamic Iterative Probability Adjustment Incorporating Positional Information

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Methods
3. Methodology
3.1. Dual Inverse Distance Weighting Method
- Step 1. Define the Distance Metric
- Step 2. Introduce Locally Varying Exponents
- Step 3. Calculate Weights
3.2. Dynamically Adjusting the Probability Density Function
- (1)
- : In this case, the currently selected sample points increase the average loss function value of the recent rounds, indicating a poorly performing sample set. Consequently, the value of will be 0.
- (2)
- : Here, the currently selected sample set decreases the average loss function value of the recent rounds but does not surpass the historical optimum. This indicates a relatively well-performing sample set. As per the formula, the value of should be in the range of (0, 1). The closer is to , the larger the value of is.
- (3)
- : In this scenario, the currently selected parameters outperform the historical optimum, indicating a very well-performing parameter set. According to the formula, the value of will be 1.
| Algorithm 1. DIDW-RAR algorithm |
 |
3.3. Sparsely Connected Neural Network
4. Results
4.1. Burgers’ Equation
4.2. Navier–Stokes Equation
4.2.1. Pipe Flow
4.2.2. Flow around a Circular Cylinder
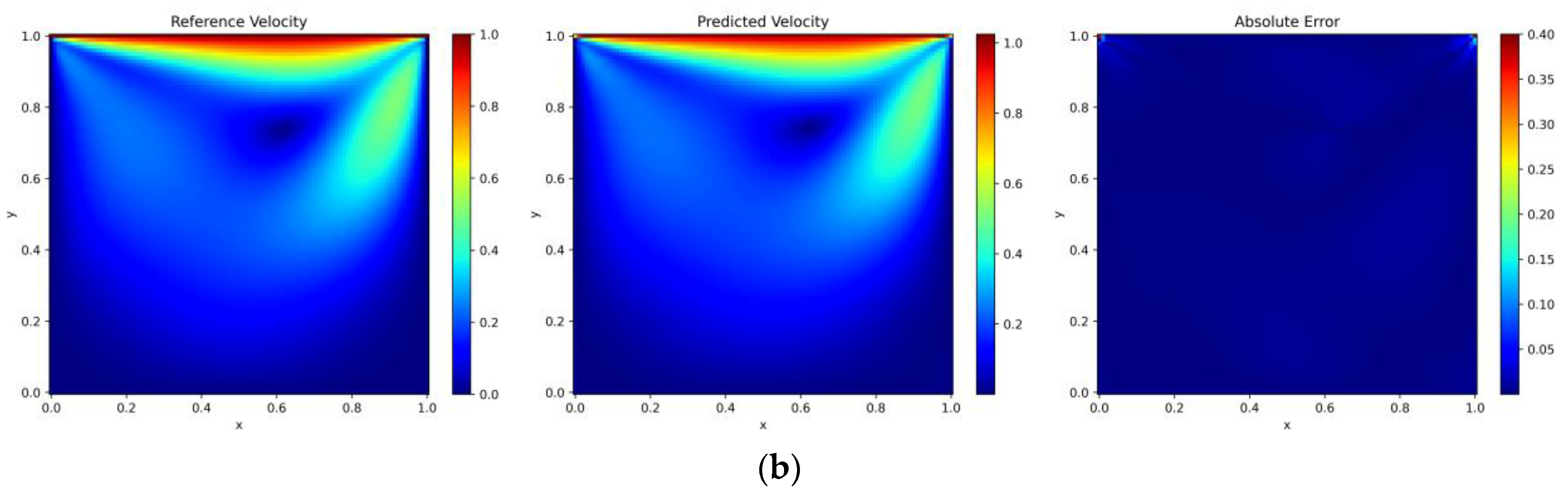
4.2.3. Lid-Driven Cavity Flow
4.2.4. Kovasznay Flow
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| PINN | Physics-Informed Neural Network |
| CFD | Computational Fluid Dynamics |
| PDE | Partial Differential Equation |
| DIDW | Dual Inverse Distance Weighting |
| D-D | Distance Between Data Points |
| D-P | Distance From Data Point to Potential Point |
| DIDW-RAR | Dual Inverse Distance Weighting—Residual-Based Adaptive Refinement |
| FCNN | Fully Connected Neural Networks |
| AD | Automatic Differentiation |
| Probability Density Function | |
| RAR-G | Residual-Based Adaptive Refinement with Greed |
| RAR-D | Residual-Based Adaptive Refinement with Distribution |
| LHS | Latin Hypercube Sampling |
References
- Chai, S.; Zou, Y.; Zhou, C.; Zhao, W. Weak Galerkin finite element methods for a fourth order parabolic equation. Numer. Methods Partial. Differ. Equ. 2019, 35, 1745–1755. [Google Scholar] [CrossRef]
- Yang, C.; Niu, R.; Zhang, P. Numerical analyses of liquid slosh by Finite volume and Lattice Boltzmann methods. Aerosp. Sci. Technol. 2021, 113, 106681. [Google Scholar] [CrossRef]
- Karniadakis, G.; Sherwin, S.J. Spectral/hp Element Methods for Computational Fluid Dynamics; Oxford University Press: New York, NY, USA, 2005. [Google Scholar]
- Cai, S.; Mao, Z.; Wang, Z.; Yin, M.; Karniadakis, G.E. Physics-informed neural networks (PINNs) for fluid mechanics: A review. Acta Mech. Sin. 2021, 37, 1727–1738. [Google Scholar] [CrossRef]
- Raissi, M.; Perdikaris, P.; Karniadakis, G.E. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. J. Comput. Phys. 2019, 378, 686–707. [Google Scholar] [CrossRef]
- Xiang, Z.; Peng, W.; Liu, X.; Yao, W. Self-adaptive loss balanced Physics-informed neural networks. Neurocomputing 2022, 496, 11–34. [Google Scholar] [CrossRef]
- Shukla, K.; Jagtap, A.D.; Karniadakis, G.E. Parallel physics-informed neural networks via domain decomposition. J. Comput. Phys. 2021, 447, 110683. [Google Scholar] [CrossRef]
- Rao, C.; Sun, H.; Liu, Y. Physics-informed deep learning for incompressible laminar flows. Theor. Appl. Mech. Lett. 2020, 10, 207–212. [Google Scholar] [CrossRef]
- Lu, L.; Meng, X.; Mao, Z.; Karniadakis, G.E. DeepXDE: A deep learning library for solving differential equations. SIAM Rev. 2021, 63, 208–228. [Google Scholar] [CrossRef]
- Yu, J.; Lu, L.; Meng, X.; Karniadakis, G.E. Gradient-enhanced physics-informed neural networks for forward and inverse PDE problems. Comput. Methods Appl. Mech. Eng. 2022, 393, 114823. [Google Scholar] [CrossRef]
- Gao, W.; Wang, C. Active learning based sampling for high-dimensional nonlinear partial differential equations. J. Comput. Phys. 2023, 475, 111848. [Google Scholar] [CrossRef]
- Tang, K.; Wan, X.; Yang, C. DAS: A deep adaptive sampling method for solving partial differential equations. arXiv 2021, arXiv:2112.14038. [Google Scholar]
- Hanna, J.M.; Aguado, J.V.; Comas-Cardona, S.; Askri, R.; Borzacchiello, D. Residual-based adaptivity for two-phase flow simulation in porous media using physics-informed neural networks. Comput. Methods Appl. Mech. Eng. 2022, 396, 115100. [Google Scholar] [CrossRef]
- Wu, C.; Zhu, M.; Tan, Q.; Kartha, Y.; Lu, L. A comprehensive study of non-adaptive and residual-based adaptive sampling for physics-informed neural networks. Comput. Methods Appl. Mech. Eng. 2023, 403, 115671. [Google Scholar] [CrossRef]
- Zeng, S.; Zhang, Z.; Zou, Q. Adaptive deep neural networks methods for high-dimensional partial differential equations. J. Comput. Phys. 2022, 463, 111232. [Google Scholar] [CrossRef]
- Mao, Z.; Meng, X. Physics-informed neural networks with residual/gradient-based adaptive sampling methods for solving partial differential equations with sharp solutions. Appl. Math. Mech. 2023, 44, 1069–1084. [Google Scholar] [CrossRef]
- Peng, W.; Zhou, W.; Zhang, X.; Yao, W.; Liu, Z. Rang: A residual-based adaptive node generation method for physics-informed neural networks. arXiv 2022, arXiv:2205.01051. [Google Scholar]
- Fornberg, B.; Flyer, N. Fast generation of 2-D node distributions for mesh-free PDE discretizations. Comput. Math. Appl. 2015, 69, 531–544. [Google Scholar] [CrossRef]
- Gu, Y.; Yang, H.; Zhou, C. Selectnet: Self-paced learning for high-dimensional partial differential equations. J. Comput. Phys. 2021, 441, 110444. [Google Scholar] [CrossRef]
- Li, Z. An enhanced dual IDW method for high-quality geospatial interpolation. Sci. Rep. 2021, 11, 9903. [Google Scholar] [CrossRef]
- Baydin, A.G.; Pearlmutter, B.A.; Radul, A.A.; Siskind, J.M. Automatic differentiation in machine learning: A survey. J. Marchine Learn. Res. 2018, 18, 1–43. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Newton, D.; Yousefian, F.; Pasupathy, R. Stochastic gradient descent: Recent trends. Recent Adv. Optim. Model. Contemp. Probl. 2018, 193–220. [Google Scholar]
- Chang, D.; Sun, S.; Zhang, C. An accelerated linearly convergent stochastic L-BFGS algorithm. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3338–3346. [Google Scholar] [CrossRef]
- Jain, A.K.; Murty, M.N.; Flynn, P.J. Data clustering: A review. ACM Comput. Surv. (CSUR) 1999, 31, 264–323. [Google Scholar] [CrossRef]
- Yang, X.; Ge, Y.; Zhang, L. A class of high-order compact difference schemes for solving the Burgers’ equations. Appl. Math. Comput. 2019, 358, 394–417. [Google Scholar] [CrossRef]














Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Y.; Chen, L.; Chen, Y.; Ding, J. An Adaptive Sampling Algorithm with Dynamic Iterative Probability Adjustment Incorporating Positional Information. Entropy 2024, 26, 451. https://doi.org/10.3390/e26060451
Liu Y, Chen L, Chen Y, Ding J. An Adaptive Sampling Algorithm with Dynamic Iterative Probability Adjustment Incorporating Positional Information. Entropy. 2024; 26(6):451. https://doi.org/10.3390/e26060451
Chicago/Turabian StyleLiu, Yanbing, Liping Chen, Yu Chen, and Jianwan Ding. 2024. "An Adaptive Sampling Algorithm with Dynamic Iterative Probability Adjustment Incorporating Positional Information" Entropy 26, no. 6: 451. https://doi.org/10.3390/e26060451