
Time Series Data Modeling Using Advanced Machine Learning and AutoML



Abstract
:1. Introduction
- Performing a comparative experimental study on different ML and DL models and AutoML frameworks.
- Defining the problem of data drift and investigating the ability of the automation in ML to tackle it.
- Representing a contribution to establishing the use of theory-based methods such as AutoML in experimental studies.
- Adding to the growing body of literature by elaborating the problem of data drift and elaborating the AutoML concept where this work can serve as an example for researchers to conduct empirical or review studies on ML and AutoML.
- This experimental work can be applied in extended time series domains and enables the widening of the same research domain with other data features.
- This work provided a comprehensive analysis of cryptocurrency data in an area where data significantly vary (from time to time and cryptocurrency to another).
2. Literature Review
2.1. TimeSeries Forecasting
2.2. Machine Learning
2.3. Data Drift Problem
2.4. Automated Machine Learning
- Model Selection: The objective of model selection, given a collection of ML models and a dataset, is to identify ML models with the greatest accuracy when trained on the dataset. AutoML aims to determine the model that best fits the data without human involvement, iterating over many models to be trained on the same input data and selecting the model with the best performance [27,59].
- Hyperparameter Optimization (HPO): Setting and adjusting hyperparameters appropriately will often result in a model with enhanced performance. Additionally, research has shown that an appropriate choice of hyper-parameters considerably improves the performance of models in comparison with the default model settings [60,61]. HPO is an important technique in machine learning that became essential owing to the upscaling of neural networks to improve accuracy. Due to the upscaling of neural networks for improved accuracy, a potential set of hyperparameter values becomes essential, necessitating that researchers have experience with neural networks when manually setting the hyperparameter [27]. Bayesian Optimization [62] and Random Search [63] are examples of strategies for automated HPO.
- Feature Engineering: This is another step that can be achieved by AutoML which is tedious and repetitive when performed manually [27].
3. Experimental Work
3.1. Data and Pre-Processing
3.1.1. Data Collection
- The datasets were collected from a reliable bulletin (Yahoo Finance).
- The first dataset contained the daily Ethereum cryptocurrency prices in U.S. Dollars (ETH-USD) from 8 July 2015 to 9 August 2022 with 2590 observations.
- The 2nd data set contained the daily Bitcoin cryptocurrency prices in U.S. Dollars (BTC-USD) from 17 September 2014 to 9 August 2022 with 2886 observations.
- Each dataset contained mainly the following features: date (date of observation taken), Close price, Open price, High price, Low price, Volume, and Adj Close price.
3.1.2. Data Visualization
3.1.3. Data Pre-Processing
3.2. Methodology
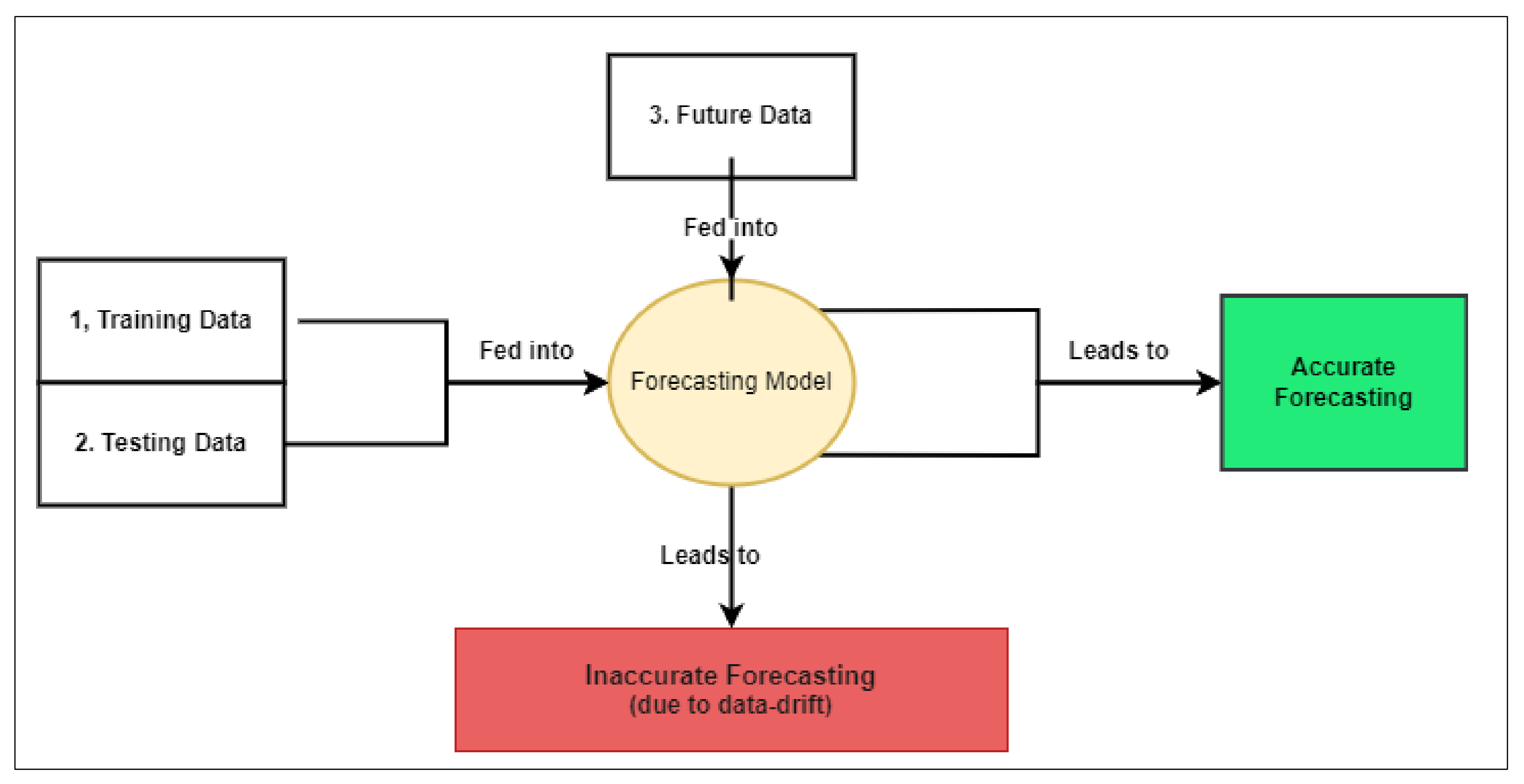
- This work used a combination of machine learning models and AutoML frameworks that auto-find and tune optimal ML models to solve the problems of forecasting time series and data drift. The machine learning models included: LR, AR, MA, ARMA, ARIMA, RNN, GRU, LSTM, and IndRNN. The AutoML frameworks included: EvalML and Auto-Keras.
- The datasets included: Ethereum cryptocurrency prices in U.S. Dollars (ETH-USD) from 2015 to 2022 and Bitcoin cryptocurrency prices in U.S. Dollars (BTC-USD) from 2014 to 2022.
- The MSE and MAE scores were used as evaluation metrics to compare the models’ efficiency, which is the mean of the squared errors. The larger this metric is the larger the error indicating that the model is less accurate. The units of MSE and MAE are the same as the unit of measurement for the quantity, which is being estimated, U.S. Dollars in our case.
- The programming language used for implementation was Python.
- After data pre-processing and feature selection, this work experimented with 9 machine learning models to model the timeseries data and then experimented with two AutoML frameworks to model the same.
3.2.1. Machine Learning
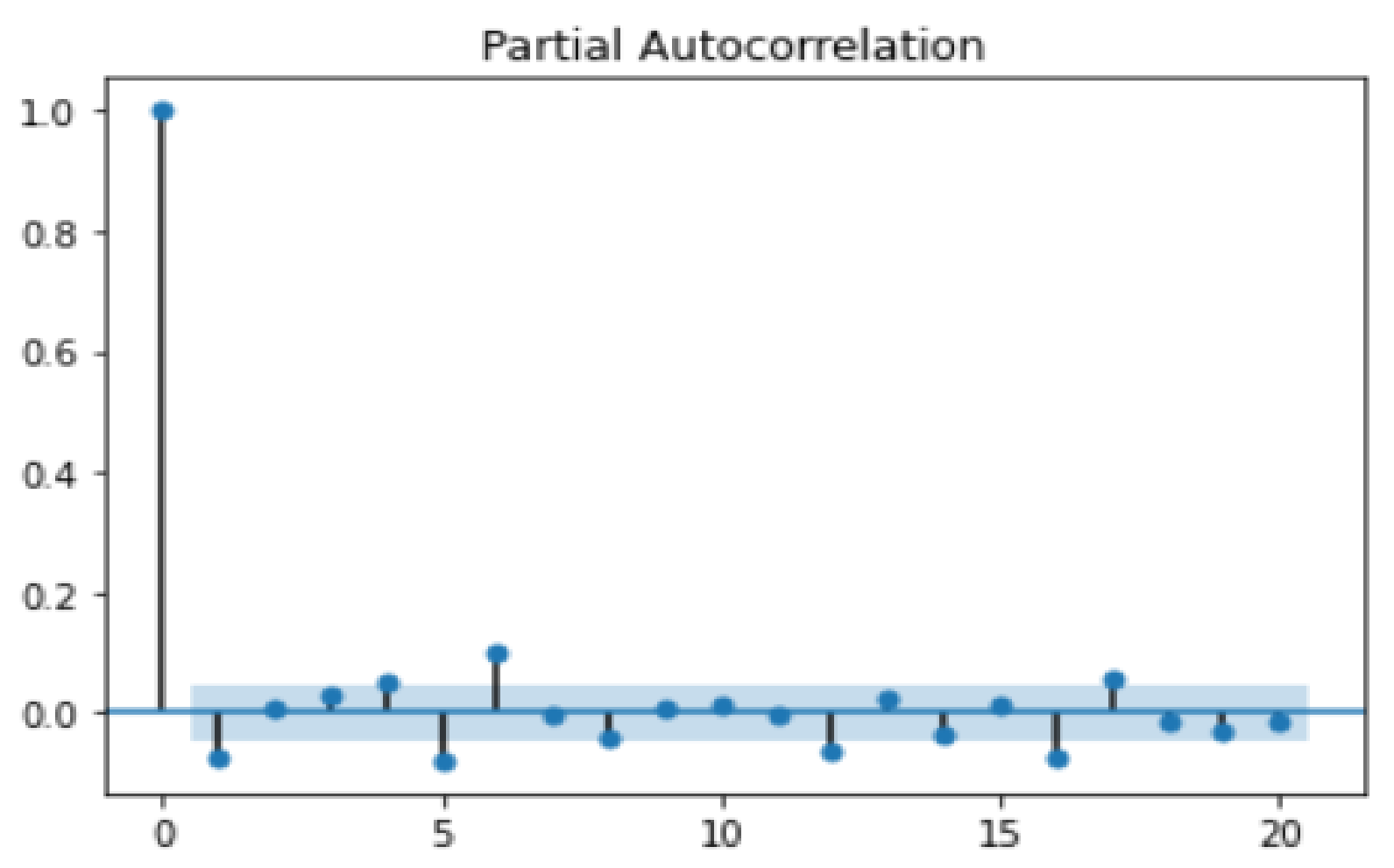
- Auto-Regressive (AR) [27,69] with the parameters: p = 12 on the 1st dataset and p = 12 on the 2nd dataset. These parameters were set using PACF plots [68] that can determine the partial autocorrelation between a value and its proceedings in a time series. The higher the partial autocorrelation, the higher the impact on prediction.
- Moving Average (MA) [70] with the parameters: q = 14 on the 1st dataset and q = 14 on the 2nd dataset. These parameters were set using ACF plots [68] that can determine the autocorrelation between a value and its proceedings in a time series. The higher the autocorrelation, the higher the impact on prediction.
- ARMA [71] with the parameters: p = 12, q = 14 on both the 1st dataset and 2nd dataset. These parameters were set using both ACF and PACF plots that can determine, combined, the optimal order for the ARMA model parameters.
- Linear Regression (LR) [73] where all training data points (closing prices) for each dataset were used to draw a fitting line of the data using the ordinary least squares method.
- Forecast horizon: 5;
- Max delay (lookback): 20;
- Gap: 0;
- Batch size: 20 for each deep learning model;
- Number of hidden layers: 3, for each deep learning model;
- Learning rate: 0.001, for each deep learning model;
- Time index: Date.
- Forecast horizon: The number of future periods we are attempting to forecast. In this example, we want to forecast prices for the next 5 days, hence the value is 5. According to [74], predicting a long horizon is not an easy task and choosing a shorter horizon such as 5 is more useful.
- Max delay: The maximum number of past values to investigate from the present value in order to construct forecasting input features. Increasing the max delay (look-back period) might result in lesser error rates, but would imply a higher dimensional input and hence increased complexity [75]. In our example, a sliding window method was used, where the previous 20 values were used to predict the next 5 values.
- Gap: The number of periods that pass between the end of the training set and the beginning of the test set. Throughout our example, the gap is zero since we are trying to forecast the prices for the following five days using the data as it is “today”. However, if we were to forecast prices for the next Monday through Sunday using data from the prior Friday, the difference would be 2 (Saturday and Sunday separate Monday from Friday).
- Time index: The column of the training set, having the date of the corresponding observation.
3.2.2. AutoML




4. Result Analysis
4.1. Machine Learning
4.2. EvalML
- Random Forest;
- Extra Trees;
- Light Gradient Boosting Machine (LightGBM);
- eXtreme Gradient Boosting (XGBoost);
- Decision Tree Regressor.
- Decision Tree Regressor;
- Elastic Net Regressor;
- eXtreme Gradient Boosting (XGBoost);
- Random Forest Regressor;
- Extra Trees Regressor.
4.3. AutoKeras
- Input layer;
- GRU layer;
- GRU layer;
- GRU layer;
- Dropout layer;
- Dense layer;
- Input layer;
- Bidirectional LSTM layer;
- Bidirectional LSTM layer;
- Dropout layer;
- Dense layer.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- De Gooijer, J.G.; Hyndman, R.J. 25 Years of IIF Time Series Forecasting: A Selective Review; Tinbergen Institute Discussion Paper, No. 05-068/4; Tinbergen Institute: Amsterdam, The Netherlands, 2005; pp. 5–68. [Google Scholar]
- Clements, M.P.; Franses, P.H.; Swanson, N.R. Forecasting economic and financial time-series with non-linear models. Int. J. Forecast. 2004, 20, 169–183. [Google Scholar] [CrossRef] [Green Version]
- Cowpertwait, P.S.P.; Metcalfe, A. V Introductory Time Series with R; Springer: Berlin/Heidelberg, Germany, 2009; ISBN 0387886982. [Google Scholar]
- Parray, I.R.; Khurana, S.S.; Kumar, M.; Altalbe, A.A. Time series data analysis of stock price movement using machine learning techniques. Soft Comput. 2020, 24, 16509–16517. [Google Scholar] [CrossRef]
- Frick, T.; Glüge, S.; Rahimi, A.; Benini, L.; Brunschwiler, T. Explainable Deep Learning for Medical Time Series Data. In Proceedings of the International Conference on Wireless Mobile Communication and Healthcare, Virtual Event, 18–19 December 2020; pp. 244–256. [Google Scholar]
- Shen, Z.; Zhang, Y.; Lu, J.; Xu, J.; Xiao, G. A novel time series forecasting model with deep learning. Neurocomputing 2020, 396, 302–313. [Google Scholar] [CrossRef]
- Livieris, I.E.; Pintelas, E.; Pintelas, P. A CNN–LSTM model for gold price time-series forecasting. Neural Comput. Appl. 2020, 32, 17351–17360. [Google Scholar] [CrossRef]
- Du, S.; Li, T.; Yang, Y.; Horng, S.-J. Multivariate time series forecasting via attention-based encoder–decoder framework. Neurocomputing 2020, 388, 269–279. [Google Scholar] [CrossRef]
- Alsharef, A.; Bhuyan, P.; Ray, A. Predicting Stock Market Prices Using Fine-Tuned IndRNN. Int. J. Innov. Technol. Explor. Eng. 2020, 9, 309–315. [Google Scholar] [CrossRef]
- Marc Claesen, B.D.M. Hyperparameter Search in Machine Learning. In Proceedings of the MIC 2015: The XI Metaheuristics International Conference, Agadir, Morocco, 7–10 June 2015. [Google Scholar]
- Ackerman, S.; Raz, O.; Zalmanovici, M.; Zlotnick, A. Automatically detecting data drift in machine learning classifiers. arXiv 2021, arXiv:2111.05672. [Google Scholar]
- Ackerman, S.; Farchi, E.; Raz, O.; Zalmanovici, M.; Dube, P. Detection of data drift and outliers affecting machine learning model performance over time. arXiv 2020, arXiv:2012.09258. [Google Scholar]
- Rahmani, K.; Thapa, R.; Tsou, P.; Chetty, S.C.; Barnes, G.; Lam, C.; Tso, C.F. Assessing the effects of data drift on the performance of machine learning models used in clinical sepsis prediction. medRxiv 2022. [Google Scholar] [CrossRef]
- Fields, T.; Hsieh, G.; Chenou, J. Mitigating drift in time series data with noise augmentation. In Proceedings of the 2019 International Conference on Computational Science and Computational Intelligence (CSCI), Las Vegas, NV, USA, 5–7 December 2019; pp. 227–230. [Google Scholar]
- Tornede, T.; Tornede, A.; Wever, M.; Hüllermeier, E. Coevolution of remaining useful lifetime estimation pipelines for automated predictive maintenance. In Proceedings of the Genetic and Evolutionary Computation Conference, Lille, France, 10–14 July 2021; pp. 368–376. [Google Scholar]
- Alteryx EvalML 0.36.0 Documentation. Available online: https://evalml.alteryx.com/en/stable/ (accessed on 1 August 2022).
- Jin, H.; Song, Q.; Hu, X. Auto-keras: An efficient neural architecture search system. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 1946–1956. [Google Scholar]
- LeDell, E.; Poirier, S. H2O automl: Scalable automatic machine learning. In Proceedings of the AutoML Workshop at ICML, Vienna, Austria, 17–18 July 2020. [Google Scholar]
- Olson, R.S.; Bartley, N.; Urbanowicz, R.J.; Moore, J.H. Evaluation of a tree-based pipeline optimization tool for automating data science. In Proceedings of the Genetic and Evolutionary Computation Conference 2016, Denver, CO, USA, 20–24 July 2016; pp. 485–492. [Google Scholar]
- Hamayel, M.J.; Owda, A.Y. A Novel Cryptocurrency Price Prediction Model Using GRU, LSTM and bi-LSTM Machine Learning Algorithms. AI 2021, 2, 477–496. [Google Scholar] [CrossRef]
- Awoke, T.; Rout, M.; Mohanty, L.; Satapathy, S.C. Bitcoin price prediction and analysis using deep learning models. In Communication Software and Networks; Springer: Singapore, 2021; pp. 631–640. [Google Scholar]
- Balaji, A.; Allen, A. Benchmarking automatic machine learning frameworks. arXiv 2018, arXiv:1808.06492. [Google Scholar]
- Gijsbers, P.; LeDell, E.; Thomas, J.; Poirier, S.; Bischl, B.; Vanschoren, J. An open source AutoML benchmark. arXiv 2019, arXiv:1907.00909. [Google Scholar]
- Hanussek, M.; Blohm, M.; Kintz, M. Can AutoML outperform humans? An evaluation on popular OpenML datasets using AutoML benchmark. arXiv 2020, arXiv:2009.01564. [Google Scholar]
- Zoller, M.-A.; Huber, M.F. Benchmark and Survey of Automated Machine Learning Frameworks. arXiv 2019, arXiv:1904.12054. [Google Scholar] [CrossRef]
- Paldino, G.M.; De Stefani, J.; De Caro, F.; Bontempi, G. Does AutoML Outperform Naive Forecasting? Eng. Proc. 2021, 5, 36. [Google Scholar]
- Alsharef, A.; Aggarwal, K.; Kumar, M.; Mishra, A. Review of ML and AutoML Solutions to Forecast Time-Series Data. Arch. Comput. Methods Eng. 2022, 29, 5297–5311. [Google Scholar] [CrossRef]
- Alsharef, A.; Sonia; Aggarawal, K. Predicting Time-Series Data Using Linear and Deep Learning Models—An Experimental Study. In Data, Engineering and Applications; Springer: Singapore, 2022; pp. 505–516. ISBN 978-981-19-4686-8. [Google Scholar]
- Ekambaram, V.; Manglik, K.; Mukherjee, S.; Sajja, S.S.K.; Dwivedi, S.; Raykar, V. Attention based multi-modal new product sales time-series forecasting. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual Event, 6–10 July 2020; pp. 3110–3118. [Google Scholar]
- Karevan, Z.; Suykens, J.A.K. Transductive LSTM for time-series prediction: An application to weather forecasting. Neural Netw. 2020, 125, 1–9. [Google Scholar] [CrossRef]
- Durand, D.; Aguilar, J.; R-Moreno, M.D. An Analysis of the Energy Consumption Forecasting Problem in Smart Buildings Using LSTM. Sustainability 2022, 14, 13358. [Google Scholar] [CrossRef]
- Kilinc, H.C.; Yurtsever, A. Short-Term Streamflow Forecasting Using Hybrid Deep Learning Model Based on Grey Wolf Algorithm for Hydrological Time Series. Sustainability 2022, 14, 3352. [Google Scholar] [CrossRef]
- © 2022 Yahoo Ethereum USD (ETH-USD) Price History & Historical Data-Yahoo Finance. Available online: https://finance.yahoo.com/quote/ETH-USD/history/?guccounter=1 (accessed on 10 August 2022).
- © 2022 Yahoo Bitcoin USD (BTC-USD) Price History & Historical Data-Yahoo Finance. Available online: https://finance.yahoo.com/quote/BTC-USD/history/?guccounter=1 (accessed on 10 August 2022).
- Bhuriya, D.; Kaushal, G.; Sharma, A.; Singh, U. Stock market predication using a linear regression. In Proceedings of the 2017 International Conference of Electronics, Communication and Aerospace Technology (ICECA), Coimbatore, India, 20–22 April 2017; Volume 2, pp. 510–513. [Google Scholar]
- Laine, M. Introduction to dynamic linear models for time series analysis. In Geodetic Time Series Analysis in Earth Sciences; Springer: Cham, Switzerland, 2020; pp. 139–156. [Google Scholar]
- Tseng, F.-M.; Tzeng, G.-H.; Yu, H.-C.; Yuan, B.J.C. Fuzzy ARIMA model for forecasting the foreign exchange market. Fuzzy Sets Syst. 2001, 118, 9–19. [Google Scholar] [CrossRef]
- Uras, N.; Marchesi, L.; Marchesi, M.; Tonelli, R. Forecasting Bitcoin closing price series using linear regression and neural networks models. PeerJ Comput. Sci. 2020, 6, e279. [Google Scholar] [CrossRef] [PubMed]
- Quemy, A. Two-stage optimization for machine learning workflow. Inf. Syst. 2020, 92, 101483. [Google Scholar] [CrossRef] [Green Version]
- Dahl, S.M.J. TSPO: An Automl Approach to Time Series Forecasting. Master’s Thesis, Universidade Nova de Lisboa, Lisbon, Portugal, 2020. [Google Scholar]
- Manikantha, K.; Jain, S. Automated Machine Learning. Int. J. Adv. Res. Innov. Ideas Educ. 2021, 6, 245–281. [Google Scholar]
- Xu, Z.; Tu, W.-W.; Guyon, I. AutoML Meets Time Series Regression Design and Analysis of the AutoSeries Challenge. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Bilbao, Spain, 13–17 September 2021; pp. 36–51. [Google Scholar]
- Wu, Q.; Wang, C. Fair AutoML. arXiv 2021, arXiv:2111.06495. [Google Scholar]
- Wang, C.; Wu, Q.; Weimer, M.; Zhu, E. FLAML: A fast and lightweight automl library. Proc. Mach. Learn. Syst. 2021, 3, 434–447. [Google Scholar]
- Dobre-Baron, O.; Nițescu, A.; Niță, D.; Mitran, C. Romania’s Perspectives on the Transition to the Circular Economy in an EU Context. Sustainability 2022, 14, 5324. [Google Scholar] [CrossRef]
- Eurostat. Available online: https://ec.europa.eu/eurostat/cache/metadata/en/cei_pc033_esmsip2.htm (accessed on 5 October 2021).
- Khan, M.A.; Abbas, K.; Su’ud, M.M.; Salameh, A.A.; Alam, M.M.; Aman, N.; Mehreen, M.; Jan, A.; Hashim, N.A.A.B.N.; Aziz, R.C. Application of Machine Learning Algorithms for Sustainable Business Management Based on Macro-Economic Data: Supervised Learning Techniques Approach. Sustainability 2022, 14, 9964. [Google Scholar] [CrossRef]
- Wang, J.; You, S.; Agyekum, E.B.; Matasane, C.; Uhunamure, S.E. Exploring the Impacts of Renewable Energy, Environmental Regulations, and Democracy on Ecological Footprints in the Next Eleven Nations. Sustainability 2022, 14, 11909. [Google Scholar] [CrossRef]
- Wackernagel, M.; Lin, D.; Evans, M.; Hanscom, L.; Raven, P. Defying the Footprint Oracle: Implications of Country Resource Trends. Sustainability 2019, 11, 2164. [Google Scholar] [CrossRef]
- Silva, A.S.A.d.; Barreto, I.D.D.C.; Cunha-Filho, M.; Menezes, R.S.C.; Stosic, B.; Stosic, T. Spatial and Temporal Variability of Precipitation Complexity in Northeast Brazil. Sustainability 2022, 14, 13467. [Google Scholar] [CrossRef]
- Abushandi, E.; Al Ajmi, M. Assessment of Hydrological Extremes for Arid Catchments: A Case Study in Wadi Al Jizzi, North-West Oman. Sustainability 2022, 14, 14028. [Google Scholar] [CrossRef]
- Abu Bakar, N.; Rosbi, S.; Bakar, N.A.; Rosbi, S. Autoregressive integrated moving average (ARIMA) model for forecasting cryptocurrency exchange rate in high volatility environment: A new insight of bitcoin transaction. Int. J. Adv. Eng. Res. Sci. 2017, 4, 237311. [Google Scholar]
- Li, Y.; Ma, W. Applications of artificial neural networks in financial economics: A survey. In Proceedings of the 2010 International Symposium on Computational Intelligence and Design, Hangzhou, China, 29–31 October 2010; Volume 1, pp. 211–214. [Google Scholar]
- Alto, V. Neural Networks: Parameters, Hyperparameters and Optimization Strategies. Available online: https://towardsdatascience.com/neural-networks-parameters-hyperparameters-and-optimization-strategies-3f0842fac0a5 (accessed on 1 August 2022).
- Bhatia, R. Data Drift: An In-Depth Understanding. Available online: https://www.linkedin.com/pulse/data-drift-in-depth-understanding-rishabh-bhatia (accessed on 1 September 2022).
- Hu, Y.-J.; Huang, S.-W. Challenges of automated machine learning on causal impact analytics for policy evaluation. In Proceedings of the 2017 2nd International Conference on Telecommunication and Networks (TEL-NET), Noida, India, 10–11 August 2017; pp. 1–6. [Google Scholar]
- Feurer, M.; Eggensperger, K.; Falkner, S.; Lindauer, M.; Hutter, F. Practical automated machine learning for the automl challenge 2018. In Proceedings of the International Workshop on Automatic Machine Learning at ICML, Stockholm, Sweden, 10–15 July 2018; pp. 1189–1232. [Google Scholar]
- Mohr, F.; Wever, M.; Hüllermeier, E. ML-Plan: Automated machine learning via hierarchical planning. Mach. Learn. 2018, 107, 1495–1515. [Google Scholar] [CrossRef] [Green Version]
- Waring, J.; Lindvall, C.; Umeton, R. Automated machine learning: Review of the state-of-the-art and opportunities for healthcare. Artif. Intell. Med. 2020, 104, 101822. [Google Scholar] [CrossRef] [PubMed]
- Mantovani, R.G.; Horváth, T.; Cerri, R.; Vanschoren, J.; de Carvalho, A.C. Hyper-parameter tuning of a decision tree induction algorithm. In Proceedings of the 2016 5th Brazilian Conference on Intelligent Systems (BRACIS), Recife, Brazil, 9–12 October 2016; pp. 37–42. [Google Scholar]
- Melis, G.; Dyer, C.; Blunsom, P. On the state of the art of evaluation in neural language models. arXiv 2017, arXiv:1707.05589. [Google Scholar]
- Snoek, J.; Larochelle, H.; Adams, R.P. Practical bayesian optimization of machine learning algorithms. Adv. Neural Inf. Process. Syst. 2012, 25, 2951–2959. [Google Scholar] [CrossRef]
- Bergstra, J.; Bengio, Y. Random search for hyper-parameter optimization. J. Mach. Learn. Res. 2012, 13, 281–305. [Google Scholar]
- Erickson, N.; Mueller, J.; Shirkov, A.; Zhang, H.; Larroy, P.; Li, M.; Smola, A. Autogluon-tabular: Robust and accurate automl for structured data. arXiv 2020, arXiv:2003.06505. [Google Scholar]
- Kotthoff, L.; Thornton, C.; Hoos, H.H.; Hutter, F.; Leyton-Brown, K. Auto-WEKA: Automatic model selection and hyperparameter optimization in WEKA. In Automated Machine Learning; Springer: Cham, Switzerland, 2019; pp. 81–95. [Google Scholar]
- Zimmer, L.; Lindauer, M.; Hutter, F. Auto-Pytorch: Multi-Fidelity MetaLearning for Efficient and Robust AutoDL. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 3079–3090. [Google Scholar] [CrossRef] [PubMed]
- He, Y.; Fataliyev, K.; Wang, L. Feature selection for stock market analysis. In Proceedings of the International Conference on Neural Information Processing, Daegu, Korea, 3–7 November 2013; pp. 737–744. [Google Scholar]
- Momani, P.; Naill, P.E. Time series analysis model for rainfall data in Jordan: Case study for using time series analysis. Am. J. Environ. Sci. 2009, 5, 599. [Google Scholar] [CrossRef]
- Adhikari, R.; Agrawal, R.K. An introductory study on time series modeling and forecasting. arXiv 2013, arXiv:1302.6613. [Google Scholar]
- Idrees, S.M.; Alam, M.A.; Agarwal, P. A prediction approach for stock market volatility based on time series data. IEEE Access 2019, 7, 17287–17298. [Google Scholar] [CrossRef]
- Oancea, B. Linear regression with r and hadoop. Challenges Knowl. Soc. 2015, 1007–1012. Available online: https://scholar.archive.org/work/46m3utxrpfhnlc4ssehtrpoyue/access/wayback/http://cks.univnt.ro/uploads/cks_2015_articles/index.php?dir=12_IT_in_social_sciences%2F&download=CKS+2015_IT_in_social_sciences_art.144.pdf (accessed on 4 November 2022).
- Zhang, M. Time Series: Autoregressive Models AR, MA, ARMA, ARIMA; University of Pittsburgh: Pittsburgh, PA, USA, 2018. [Google Scholar]
- Kedem, B.; Fokianos, K. Regression Models for Time Series Analysis; John Wiley & Sons: Hoboken, NJ, USA, 2005; ISBN 0471461687. [Google Scholar]
- Shah, S. Comparison of Stochastic Forecasting Models. 2021. Available online: https://doi.org/10.31219/osf.io/7fepu (accessed on 4 November 2022).
- Chakraborty, D.; Ghosh, S.; Ghosh, A. Autoencoder based Hybrid Multi-Task Predictor Network for Daily Open-High-Low-Close Prices Prediction of Indian Stocks. arXiv 2022, arXiv:2204.13422. [Google Scholar]
- EvalML Data Checks. Available online: https://evalml.alteryx.com/en/stable/user_guide/data_checks.html (accessed on 10 August 2022).
- Diebold, F.X.; Mariano, R.S. Comparing predictive accuracy. J. Bus. Econ. Stat. 2002, 20, 134–144. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Property | Description | 1st Dataset (ETH-USD) | 2nd Dataset (BTC-USD) | Notes |
|---|---|---|---|---|
| Event data loss | There are gaps in the event data/time series. | 70 out of 2590 observations were missing from the 1st dataset. | 60 out of 2886 observations were missing from the 2nd dataset. | Missed values were replaced with their corresponding previous values (Forward Fill) and we assumed that the value did not change on that day where the most recent value is closest to the current. |
| Values out of range | The values are out of range for the domain under observation. | False | False | 1st dataset’s values ranged between 0 and 5000. 2nd dataset values ranged between 0 and 70,000. |
| Value spikes | Spikes or sudden changes are implausible for the domain. | True | True | Datasets contained spikes (price spikes). |
| Wrong timestamps | Timestamps are wrong. | False | False | Datasets did not have wrong timestamps. |
| Rounded measurement value | The value is not to the optimal level of detail or has slight variations. | False | False | As a part of pre-processing, the float values of price were normalized to the nearest integer to facilitate calculations and readability of data. |
| Signal noise | Small changes which are not in the process but result from inaccurate measurements. | No | No | Datasets did not have signal noise. |
| Data Not Updated | Data arenot up-to-date. | No | No | The data are up-to-date and were updated on 31 December 2021. |
| Unreliable data source | The data source is not considered fully reliable. | False | False | Data were collected from a reliable source, Yahoo Finance, which provides financial news, data, financial reports, and original content. |
| Units of measurements | The units of measurement are the same for all data sources. | True | True | Unified for all datasets (U.S. Dollars) where all the values are in U.S. Dollars. |
| Data formats | Different data formats, e.g., float vs. string, etc. | True | True | The prices were given as float numbers or string values (e.g., 21 k). This was taken into consideration in the pre-processing where all data formats were unified as natural integer numbers. |
| Short data history | The history of recorded data is short for good analysis. | True | True | BTC and ETH are among the oldest cryptocurrencies in exchange and the historical data available are large when compared with other cryptocurrencies; however, data volume is still not perfectly sufficient. |
| Calculated/forced values | Compensated values are used instead of real measurements. | False | False | All data values are real measurements not calculated. |
| Prediction Model | LR | AR | MA | ARMA | ARIMA | RNN | GRU | LSTM | IndRNN |
|---|---|---|---|---|---|---|---|---|---|
| Time Series Featurizer | {’time_index’: ‘Date’, ‘max_delay’: 20, ‘delay_target’: True, ‘delay_features’: False, ‘forecast_horizon’: 5, ‘gap’: 0} | ||||||||
| MSE ETH-USD | 11,835 | 17,500 | 16,410 | 6124 | 675 | 478 | 389 | 311 | 298 |
| MSE BTC-USD | 9952 | 11,422 | 10,214 | 3177 | 554 | 495 | 386 | 302 | 287 |
| MAE ETH-USD | 45.09 | 65.94 | 47.24 | 41.56 | 14.51 | 13.18 | 12.41 | 11.57 | 11.73 |
| MAE BTC-USD | 46.70 | 61.88 | 47.35 | 31.25 | 13.13 | 12.35 | 12.80 | 11.75 | 10.77 |
| Index | Pipeline Name | MSE Score | Model Parameters and Hyperparameters |
|---|---|---|---|
| 0 | Random Forest Regressor w/Imputer + Time Series Featurizer + DateTimeFeaturizer | 334 | {‘Time Series Featurizer’: {’time_index’: ‘Date’, ‘max_delay’: 20, ‘delay_target’: True, ‘delay_features’: True, ‘forecast_horizon’: 5, ‘conf_level’: 0.05, ‘gap’: 0, ‘rolling_window_size’: 0.25}, ‘Random Forest Regressor’: {’n_estimators’: 100, ‘max_depth’: 6, ‘n_jobs’: -1}, ‘pipeline’: {’gap’: 0, ‘max_delay’: 20, ‘forecast_horizon’: 5, ‘time_index’: ‘Date’}} |
| 1 | Extra Trees Regressor w/Imputer + Time Series Featurizer + DateTimeFeaturizer | 363 | {‘Time Series Featurizer’: {’time_index’: ‘Date’, ‘max_delay’: 20, ‘delay_target’: True, ‘delay_features’: True, ‘forecast_horizon’: 5, ‘conf_level’: 0.05, ‘gap’: 0, ‘rolling_window_size’: 0.25}, ‘Extra Trees Regressor’: {’n_estimators’: 100, ‘max_features’: ‘auto’, ‘max_depth’: 6, ‘min_samples_split’: 2, ‘min_weight_fraction_leaf’: 0.0, ‘n_jobs’: -1}, ‘pipeline’: {’gap’: 0, ‘max_delay’: 20, ‘forecast_horizon’: 5, ‘time_index’: ‘Date’}} |
| 2 | LightGBM Regressor w/Imputer + Time Series Featurizer + DateTimeFeaturizer | 396 | {‘Time Series Featurizer’: {’time_index’: ‘Date’, ‘max_delay’: 20, ‘delay_target’: True, ‘delay_features’: True, ‘forecast_horizon’: 5, ‘conf_level’: 0.05, ‘gap’: 0, ‘rolling_window_size’: 0.25}, ‘LightGBM Regressor’: (boosting_type: gbdt, learning_rate: 0.1, n_estimators: 20, max_depth’: 0, ‘num_leaves’: 31, Win_child_samples’: 20, ‘n-jobs’. -1, ‘bagging_freq’: 0, ‘bagging_fraction’: 0.9), ‘pipeline’: {’gap’: 0, ‘max_delay’: 20, ‘forecast_horizon’: 5, ‘time_index’: ‘Date’}} |
| 3 | XGBoost Regressor w/Imputer + Time Series Featurizer + DateTimeFeaturizer | 422 | {‘Time Series Featurizer’: {’time_index’: ‘Date’, ‘max_delay’: 20, ‘delay_target’: True, ‘delay_features’: True, ‘forecast_horizon’: 5, ‘conf_level’: 0.05, ‘gap’: 0, ‘rolling_window_size’: 0.25}, ‘XGBoost Regressor’: {’eta’: 0.1, ‘max_depth’: 6, ‘min_child_weight’: 1, ‘n_estimators’: 100, ‘n_jobs’: -1}, ‘pipeline’: {’gap’: 0, ‘max_delay’: 20, ‘forecast_horizon’: 5, ‘time_index’: ‘Date’}} |
| 4 | Decision Tree Regressor w/Imputer + Time Series Featurizer + DateTimeFeaturizer | 533 | {’Time Series Featurizer’: {’time_index’: ‘Date’, ‘max_delay’: 20, ‘delay_target’: True, ‘delay_features’: False, ‘forecast_horizon’: 5, ‘conf_level’: 0.05, ‘gap’: 0, ‘rolling_window_size’: 0.25}, ‘Decision Tree Regressor’: {’gap’: 0, ‘forecast_horizon’: 5}, ‘pipeline’: {’time_index’: ‘Date’, ‘gap’: 0, ‘max_delay’: 20, ‘forecast_horizon’: 10}} |
| ETH-USD EvalML | |
|---|---|
| Model | MSE |
| Random Forest | 762 |
| Extra Trees | 768 |
| LightGBM | 1062 |
| XGBoost | 1059 |
| Decision Tree Regressor | 1079 |
| Index | Pipeline Name | MSE Score | Model Parameters and Hyperparameters |
|---|---|---|---|
| 0 | Decision Tree Regressor w/Imputer + Time Series Featurizer + DateTime Featurization component | 368 | {’Time Series Featurizer’: {’time_index’: ‘Date’, ‘max_delay’: 20, ‘delay_target’: True, ‘delay_features’: False, ‘forecast_horizon’: 5, ‘conf_level’: 0.05, ‘gap’: 0, ‘rolling_window_size’: 0.25}, ‘Decision Tree Regressor’: {’gap’: 0, ‘forecast_horizon’: 5}, ‘pipeline’: {’time_index’: ‘Date’, ‘gap’: 0, ‘max_delay’: 20, ‘forecast_horizon’: 10}} |
| 1 | Elastic Net Regressor w/Imputer + Time Series Featurizer + DateTimeFeaturizer + Standard Scaler | 394 | {‘Time Series Featurizer’: {’time_index’: ‘Date’, ‘max_delay’: 20, ‘delay_target’: True, ‘delay_features’: True, ‘forecast_horizon’: 5, ‘conf_level’: 0.05, ‘gap’: 0, ‘rolling_window_size’: 0.25}, ‘Elastic Net Regressor’: {’alpha’: 0.0001, ‘l1_ratio’: 0.15, ‘max_iter’: 1000, ‘normalize’: False}, ‘pipeline’: {’gap’: 0, ‘max_delay’: 20, ‘forecast_horizon’: 5, ‘time_index’: ‘Date’}} |
| 2 | XGBoost Regressor w/Imputer + Time Series Featurizer + DateTimeFeaturizer | 470 | {‘Time Series Featurizer’: {’time_index’: ‘Date’, ‘max_delay’: 20, ‘delay_target’: True, ‘delay_features’: True, ‘forecast_horizon’: 5, ‘conf_level’: 0.05, ‘gap’: 0, ‘rolling_window_size’: 0.25}, ‘XGBoost Regressor’: {’eta’: 0.1, ‘max_depth’: 6, ‘min_child_weight’: 1, ‘n_estimators’: 100, ‘n_jobs’: -1}, ‘pipeline’: {’gap’: 0, ‘max_delay’: 20, ‘forecast_horizon’: 5, ‘time_index’: ‘Date’}} |
| 3 | Random Forest Regressor w/Imputer + Time Series Featurizer + DateTimeFeaturizer | 542 | {‘Time Series Featurizer’: {’time_index’: ‘Date’, ‘max_delay’: 20, ‘delay_target’: True, ‘delay_features’: True, ‘forecast_horizon’: 5, ‘conf_level’: 0.05, ‘gap’: 0, ‘rolling_window_size’: 0.25}, ‘Random Forest Regressor’: {’n_estimators’: 100, ‘max_depth’: 6, ‘n_jobs’: -1}, ‘pipeline’: {’gap’: 0, ‘max_delay’: 20, ‘forecast_horizon’: 5, ‘time_index’: ‘Date’}} |
| 4 | Extra Trees Regressor w/Imputer + Time Series Featurizer + DateTimeFeaturizer | 638 | {‘Time Series Featurizer’: {’time_index’: ‘Date’, ‘max_delay’: 20, ‘delay_target’: True, ‘delay_features’: True, ‘forecast_horizon’: 5, ‘conf_level’: 0.05, ‘gap’: 0, ‘rolling_window_size’: 0.25}, ‘Extra Trees Regressor’: {’n_estimators’: 100, ‘max_features’: ‘auto’, ‘max_depth’: 6, ‘min_samples_split’: 2, ‘min_weight_fraction_leaf’: 0.0, ‘n_jobs’: -1}, ‘pipeline’: {’gap’: 0, ‘max_delay’: 20, ‘forecast_horizon’: 5, ‘time_index’: ‘Date’}} |
| BTC-USD EvalML | |
|---|---|
| Model | MSE |
| Decision Tree Regressor | 693 |
| Elastic Net | 838 |
| XGBoost | 1142 |
| Random Forest | 1322 |
| Extra Trees | 1457 |
| Hyperparameter | Best Value |
|---|---|
| Bidirectional | False |
| Layer Type | GRU |
| Number of Hidden Layers | 3 |
| Dropout | 0.25 |
| Optimizer | Adam |
| Learning Rate | 0.001 |
| Hyperparameter | Best Value |
|---|---|
| Bidirectional | True |
| Layer Type | LSTM |
| Number of Hidden Layers | 2 |
| Dropout | 0.2 |
| Optimizer | SGD |
| Learning Rate | 0.001 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alsharef, A.; Sonia; Kumar, K.; Iwendi, C. Time Series Data Modeling Using Advanced Machine Learning and AutoML. Sustainability 2022, 14, 15292. https://doi.org/10.3390/su142215292
Alsharef A, Sonia, Kumar K, Iwendi C. Time Series Data Modeling Using Advanced Machine Learning and AutoML. Sustainability. 2022; 14(22):15292. https://doi.org/10.3390/su142215292
Chicago/Turabian StyleAlsharef, Ahmad, Sonia, Karan Kumar, and Celestine Iwendi. 2022. "Time Series Data Modeling Using Advanced Machine Learning and AutoML" Sustainability 14, no. 22: 15292. https://doi.org/10.3390/su142215292