
Abstract
To reveal complex causes of aircraft events, this paper aims to mine association rules between the trigger probability and relative strength via a modified Apriori algorithm. Clustering is adopted for data preprocessing and TFâIDF value calculation. Causative item sets of aircraft events are obtained based on the accident causation 2â4 model and are coded to establish code indicators. By avoiding the use of statistical methodologies to resolve not-a-number (NaN) values for altering the interrelations among causes, an enhancement in the Apriori algorithm is proposed by considering frequent items. By extracting frequent patterns, in this paper, all the association rules that satisfy three perspectives (support, confidence and lift) are determined by constantly generating and pruning candidate item sets. A network graph is used to visualize the association rules between different unsafe events and all types of causes. Finally, 9835 representative pieces of data, including general unsafe events, general incidents and serious incidents from the Southwest Air Traffic Management Bureau, are selected for analysis. The results show that improper energy allocation, poor conflict resolution ability, inadequate onsite management duties, adoption of a luck mentality, and occurrence of controller oversight are highly correlated with general unsafe events, and failure to rectify incorrect recitation is notably correlated with general incidents, while inadequate manual promotion, lack of conflict judgement and insufficient safety management are strongly correlated with serious incidents. This study quantitatively reveals the potential patterns and characteristics of mutual interactions among various types of historical aircraft events and highlights directions for controllable prevention and prediction of aircraft events.
Similar content being viewed by others



Introduction
Association analysis of aircraft accident causation involves deriving probabilities of event types based on historical event causes after learning and training by considering past incidents. This method serves as a crucial means for preventing and predicting unsafe events or accidents1,2,3. With the rapid development of civil aviation in China, the number of flights has significantly increased, and air transport has become a major link in international communication and domestic economic development. However, airline networks are complex, organizational structures are vast, regional differences are notable, and unsafe events frequently occur. According to statistics of the Civil Aviation Administration of China Safety, the accident occurrence ratio reached 0.29%, the incident occurrence ratio reached 11.39%, and general unsafe events accounted for 88.32% of the total aircraft events from 2013 to 2022, as shown in Fig. 1.

Civil and general aviation aircraft accidents and incidents in China from 2013 to 2022.
Figure 1 indicates that the occurrence of accidents and incidents linearly increased from 2013 to 2019. Due to the COVID-19 pandemic, the number of flight accidents and incidents plummeted from 2020 to 2022. However, the number of general unsafe events has increased to approximately 10,000 per year. Aircraft event investigations revealed that the number of causes underlying unsafe events and incidents exceeded 20, and the proportions are shown in Fig. 2.

Causes of incidents and general unsafe events in China from 2019 to 2022.
According to the results of these investigations, many unsafe events are typically caused by multiple factors, including human factors, equipment usage, management systems, and internal/external environments. However, the characteristic indicators leading to aircraft incidents exhibit discreteness, constrained by dynamically extracted factors. This constraint prevents precise quantification, leaving the determined causes restricted to a qualitative level, thereby affecting the reliability of the analysis and prediction results. Hence, it is necessary to reveal meaningful connections hidden within investigation data of aircraft incidents by employing machine learning to establish association rules. Association analysis aims to assess the correlations among various incident factors and event types comprehensively and systematically. Subsequently, preventive measures to reduce the occurrence of similar events or accidents can be adopted.
This paper aimed to introduce a data-mining technique. A substantial amount of incident investigation data was analysed in depth. Comprehensive and accurate correlational information was derived, and inherent correlations leading to event causes were revealed. By establishing various association rules, greater insights were obtained. A pattern of potential correlations leading to unsafe aircraft incidents was revealed. Finally, the advantages of real-time high-speed data streaming were exploited, and unsupervised and supervised learning approaches were adopted. The latest information and insights were provided so that investigators can perceive and detect clues and anomalies related to incidents in a timely manner.
Literature review
Accident causation theory is an essential method for studying the occurrence and development of accidents4. Experts worldwide have studied factors influencing safety events across industries, such as coal mining5, road traffic6, and railway transportation7, by developing various event causation models and distinct theories of accident causation. As of December 2023, there are more than fifty distinct accident causation models, which can be categorized into linear, contagion and systemic accident causation models8. Systemic accident causation models are the most widely adopted and consider the entire accident as a whole rather than analysing individual causal factors9.
Lenné et al.10 analysed 169 general aviation accidents in Australia using the HFACS model and revealed a positive correlation between crew violations and deficiencies in crew resource management. Li et al.11 statistically analysed the causes of 41 civil aviation accidents in Taiwan from 1999 to 2006 using the HFACS model, and a relationship diagram of the considered causes was derived by using chi-square tests. Chang et al.12 examined human factor risk elements in runway incursion-related accidents utilizing an improved SHEL-SHELLO model. Kharoufah et al.13 conducted a random study of more than 200 commercial aviation transport accidents between 2000 and 2016 and used chi-square tests to detect the factors influencing these accidents. StojiljkoviÄ et al.14 utilized systematic human error reduction and prediction methods to identify 55 errors that occurred among 30 pilots over 10 years, and a hierarchical task analysis and classification method was established based on pilot tasks to analyse the probability and consequences of error occurrence. Chen et al.15 analysed human factors in 484 aviation accidents from 1999 to 2012 and identified causal relationships among human and other factors. Sun et al.16 comprehensively and systematically analysed the severity of the consequences of accidents in civil aviation enterprises from 2006 to 2015 using mathematical statistics, revealing the inherent characteristics and patterns of event or accident types and flight periods.
These studies of aviation safety events involve extensive data processing operations, primarily relying on manual processing17 or simple visualization of report and chart data using computers18, leading to a low processing efficiency, error-prone outcomes, and challenging data quality assurance. With the rise of data-mining technology, it has become possible to extract valuable information and knowledge from large volumes of diverse and complex data19.
Data mining originated from various disciplines, with statistics, machine learning, and data warehousing as the most important fields. Friedman20 considered data mining as a business information processing technique, revealing hidden, unknown regularities by statistically analysing and predicting vast amounts of data to support decision-making. Therefore, the concept of data mining is often considered equivalent to knowledge discovery in databases (KDD)21,22,23. Currently, data mining, which focuses on accident data analysis using association analysis, cluster analysis, and decision tree analysis algorithms, is mostly applied in fields such as road traffic accidents and coal mine safety24,25,26,27,28,29.
The Apriori algorithm is the first and a classic association rule mining algorithm30 and is widely utilized for analysing potential cause-and-effect relationships in maritime shipping accidents, road traffic accidents, and railway incidents. Considerable research in this domain includes studies by Huang et al.31, who established a model for analysing association rules in maritime traffic accidents using the Apriori algorithm and proposed strategies to prevent maritime traffic accidents. Yang32 utilized the Apriori algorithm to analyse causality in road traffic accidents. Xu et al.7 investigated the causality of railway traffic accidents using the Apriori algorithm. ShuangLi et al.33 constructed a Bayesian network model through text mining techniques and strong association rules and conducted sensitivity analysis and critical path analysis, thereby elucidating the fundamental causes of mining accidents. Liu et al.34 performed a correlation rule analysis of railway operation accidents by improving the Apriori algorithm, extracting 90 causal factors of railway accidents, discovering 159 associated rules, and identifying key causes, interrelated key causes, and accident causation patterns. Li et al.35 employed text mining techniques to extract 37 unsafe behaviours and their causative feature words using the Apriori algorithm for association rule mining, ultimately obtaining six core causes and six sets of core associated factors. Li et al.36 explored the relationships and interdependence among different causes of building collapse accidents using spectral clustering and the Apriori algorithm, categorizing 43 accident causes into five groups, determining the most crucial cause combinations within each cluster, and proposing targeted measures. Jing et al.37 used the Apriori algorithm and Gephi visualization method for statistical analysis of reported data on coal mine accidents across China from 2018 to 2022 to reveal the complex relationships among individual causative factors.
The above literature review reveals that statistical analysis of aircraft accidents has focused mainly on the accident severity, type, month, geographical location and other factors. Text data mining is mainly employed in the railway, maritime accident and construction industries, but it is rarely adopted in the aviation field. To reveal the complex relationships among the causes of aircraft accidents, the Apriori algorithm was used to mine association rules and generate a visual network graph of the obtained association rules.
Methodology
Data preprocessing
Data preprocessing involves transforming the original data, correcting errors, deleting redundant data, and modifying inconsistent and incomplete data. Incident investigation reports are typically presented in document form, which is limited by the presentation and content completeness, as well as by the industry knowledge of the investigator. There is no standardized text format, as described in Table 1. Therefore, to ensure the accuracy of the subsequent excavation and analysis, data from accident investigation reports must be preprocessed.
The determination of the causes of aircraft incidents adheres to the principles of completeness, continuity, and consistency. These principles conform with industry regulations and operational manuals. By consulting numerous unsafe event investigation experts and comparing common data cleaning methods, clustering was used to identify outliers by dividing the data of general unsafe events, general incidents and serious incidents into three groups. The 56 retained items are assigned a value of 1, while the deleted items are assigned a value of 0. The specific cleaning process is shown in Fig. 3.
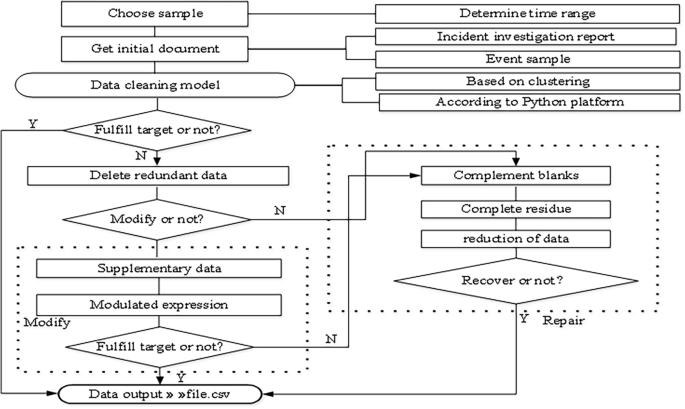
Data cleaning process.
A processed dataset is generated as output in accordance with the data format requirements of the code of the data analysis and processing modules (e.g., numpy, matplotlib, and pandas)
Feature extraction
The initial feature set obtained after data cleaning based on the expert system model typically consists of high-dimensional data, and not all features are equally important. Irrelevant information can reduce the algorithm performance, leading to dimensionality, ultimately affecting the outcome of data analysis. Introducing feature reduction facilitates the elimination of redundant dimensions (weakly correlated dimensions) or the extraction of more valuable features, thereby increasing the computation speed, enhancing the efficiency, and ensuring the accuracy of data analysis.
The term frequencyâinverse document frequency (TFâIDF) method is a classic weighting calculation technique widely used in recent years for data analysis and information processing. The term frequency (TF) represents the frequency or occurrence of a particular keyword within an entire document. The inverse document frequency (IDF) denotes the inverse of the document frequency and is primarily employed to reduce the impact of common words across all documents that minimally influence the document. The TFâIDF model can be expressed as follows:
where \(tfidf_{i,j}\) denotes the product of the term frequency \(tf_{i,j}\) and the inverse document frequency \(idf_{i,j}\). In the TFâIDF method, the weight is directly proportional to the frequency of occurrence of a given feature in a document and inversely proportional to the number of documents containing this feature in the entire corpus. A higher value of \(tfidf_{i,j}\) indicates greater importance of the feature word within the text.
The causative factors obtained by feature extraction were sequentially numbered, constituting the current causative factor set \(t = \left\{ {t_{1} , t_{2} , \ldots , t_{i} } \right\}\). Simultaneously, the collected incident investigation reports were sequentially numbered, constituting the collection of incident investigation report texts \(D = \left\{ {D_{1} , D_{2} ,..., D_{j} } \right\}\).
The TF value can be calculated as:
where the numerator \(n_{i,j}\) denotes the occurrence of a given causative factor in incident investigation report \(D_{j}\), and the denominator \(\sum\nolimits_{k} {n_{k,j} }\) denotes the total count of all causative factors in report \(D_{j}\). The resultant \(tf_{i,j}\) provides the frequency of a specific feature word.
The IDF value can be obtained as:
where the numerator \(\left| D \right|\) denotes the total number of incident investigation reports and the denominator \(\left| {\left\{ {j:t_{i} \in d_{j} } \right\}} \right|\) denotes the number of reports containing word causative factor \(t_{i}\). If the considered word is absent in the corpus, zero denominator is obtained. Hence, in general, this can be avoided by adding 1 to the denominator, namely, \(1 + \left| {\left\{ {j:t_{i} \in d_{j} } \right\}} \right|\).
The TFâIDF model can be expressed as follows:
Determination of the aircraft incident causal factor set
After data preprocessing, text mining was conducted of the historical aircraft incident investigation reports (Fig. 3). Initially, according to regulations such as the Event Information Reporting and Processing Standard and Event Samples, causative factors were decomposed into relevant causative keywords. With the use of the TFâIDF method for feature word extraction from text, preliminary causative factors of aircraft incidents were identified by matching within specified classified texts. However, the causes of aircraft incidents are multifaceted, and many people are involved. In this paper, the accident causation 2-4 model was introduced. Factors contributing to aircraft incidents in the form of human factors, equipment factors, and management factors were attributed to internal organizational reasons, while the environment was considered an external factor. The specific model is shown in Fig. 4.

Accident causation 2â4 model.
The top 30 TFâIDF ranked feature words from each level were selected as causative factors. After deduplication, all the causal factors of each event were obtained. Similar or identical conditions were integrated, and a set of aircraft accident cause factors was finally extracted.
Aircraft incident causal rule mining
In this paper, the Apriori algorithm of association rules was used to discover relationships or patterns in datasets. Through the downward closure property of frequent item sets, candidate item sets were continuously generated and pruned, and all rules satisfying minimum support and minimum confidence levels were obtained. Association rules that meet the requirements also satisfy the filtering requirements. The greater the support and confidence are, the stronger the rule. In addition, in this paper, the lift index was employed to filter the obtained association rules. A lifting degree higher than 1 indicates that the former and latter terms are positively correlated. Conversely, they are negatively correlated.
Relevant definitions
The association rule problem based on events can be expressed as follows: let \(X = \left( {X_{1} ,X_{2} , \ldots ,X_{m} } \right)\) represent the set of causative factors obtained after data preprocessing, where \(m\) is the number of causative factors. \(S = \left\{ { S_{1} , S_{2} , \ldots , S_{n} } \right\}\) denotes the original set of association rules for events, with \(n\) denoting the total number of association rules, each \(S_{i} \left( {1 \le i \le n} \right)\) denoting a subset of item sets, and \(S_{i} \in X\).
Event association rules can be expressed as \(X_{a} = > X_{b}\), where \(X_{a}\) and \(X_{b}\) denote the antecedent and consequent, respectively, of the rules. For each rule, \(X_{a} \in X\), \(X_{b} \in X\) and \(X_{a} \cap X_{b} = \emptyset\) must meet the minimum support and confidence thresholds while yielding a lift value greater than 1.
Definition 1 Support: The probability of the simultaneous occurrence of event causative factor items \(X_{a}\) and \(X_{b}\) is referred to as the event causative rule support, represented by:
where the numerator \(\left| {X_{a} \cup X_{b} } \right|\) denotes the count of the simultaneous occurrence of event causative factor items \(X_{a}\) and \(X_{b}\), and \(\left| S \right|\) denotes the total count of all association rules.
Definition 2 Confidence: If an event causative factor item \(X_{a}\) occurs, the probability of another event causative factor item \(X_{b}\) occurring is referred to as the event causative rule confidence, represented by:
where the numerator \(\left| {X_{a} } \right|\) denotes the count of association rules containing both causative factor items \(X_{a}\) and \(X_{b}\), and the denominator \(\left| {X_{a} \cup X_{b} } \right|\) denotes the count of association rules containing event causative factor items \(X_{a}\) and \(X_{b}\).
Definition 3 Lift: The measure of improvement in the probability of the occurrence of one event causative factor item \(X_{a}\) in the presence of another event causative factor item \(X_{b}\) can be expressed as:
Antecedents and consequents of the association rule
The core of association rules is to reveal the relationships between items in a dataset, helping to better understand the frequency at which one item set may occur given another. By identifying these relationships, potential patterns and regularities can be determined, providing support for decision-making and prediction. Association rules consist of two parts: the antecedent and the consequent. The antecedent is the condition, while the consequent is the result. The relationship between these parts indicates a trend where certain items may occur in the presence of other items. Association rules were mined based on the support and confidence. The support is a measure of the frequency of simultaneous occurrence of item sets, while the confidence is a measure of the probability of consequent occurrence given the antecedent.
In association rules, the order of the antecedent and consequent is a key concept but can also lead to confusion. Because association rules describe item sets based on their content rather than their order, the order of item sets does not affect the meaning of the rules. In other words, whether the antecedent or consequent, as long as their contents are the same, the meaning of the rules is the same, indicating some form of correlation or causality between two item sets. However, while conceptually, the order of the antecedent and consequent does not affect the meaning of the association rules, it can affect the calculation of metrics such as the support and confidence. This difference occurs because these metrics are calculated based on specific combinations of item sets, reflecting the degree and frequency of association between different item set combinations. Therefore, even if two rules express the same association relationship, their metrics, such as the support and confidence, may differ due to the actual occurrences in the dataset.
In conclusion, the meaning of the obtained association rules depends on the content of their antecedents and consequences, while the metrics reflect the performance and degree of association of these rules in the actual datasets.
Algorithmic improvements
In the application of the Apriori algorithm for data mining, despite the implementation of conditional checks to avoid division-by-zero errors, not-a-number (NaN) values can still occur. Such instances likely stem from either small data samples or inadequacies in meeting the threshold requirements for metrics such as the support and confidence within certain item sets, thereby resulting in NaN computations. Notably, the emergence of NaN values does not necessarily indicate code errors but may reflect the inherent data characteristics.
In practice, addressing NaN values typically involves employing statistical techniques such as mean or median imputation or adjusting thresholds to mitigate their occurrence. However, due to the distinct nature of aircraft incident data and their difference from conventional datasets, applying statistical methodologies to resolve NaN values, such as using alternative incident cause codes for filling or removing specific cause codes, could alter the interrelations among incident causes, thus compromising the accuracy of the final analysis.
To address this issue, in this paper, an enhancement to the Apriori algorithm was proposed. In contrast to conventional NaN resolution methods, the proposed approach focuses on preprocessing, specifically on filtering and tallying frequent items, aiming to enhance the efficiency and precision of the algorithm. Initially, by traversing each transaction in the dataset, the support of each item can be computed and stored in a header table. Subsequently, items with a support value below the minimum threshold can be removed from the header table, ensuring the retention of only frequent high-support items. Finally, these retained frequent items constitute the item sets. By exclusively considering frequent items, the refined algorithm aims to efficiently extract frequent patterns, thereby augmenting its performance and accuracy.
This preprocessing step reduces the processing time and resource overhead associated with infrequent item handling, consequently lowering the computational complexity and enhancing the algorithmic efficiency and precision. Such a strategy plays a pivotal role in data mining, enabling the algorithm to maintain effectiveness when managing large-scale datasets. Additionally, due to the substantial volume of aircraft incident data employed, an iterative approach was adopted during coding to generate candidate and frequent item sets, avoiding recursive calls and minimizing the recursion depth. This could ensure more effective processing of large datasets while mitigating potential stack overflow issues.
According to the association rule mining method, the steps for mining accident causation association rules are as follows:
Step 1: Input the dataset of accident causation factors.
Step 2: Set the minimum lift threshold, minimum confidence threshold, and minimum support threshold.
Step 3: Utilize the Apriori algorithm for generating strong association rules that meet the minimum support threshold.
Step 4: Filter the obtained frequent item sets based on the minimum support, minimum confidence, and lift thresholds; the rules that meet these criteria are considered association rules.
Step 5: Eliminate association rules where the antecedent or consequent is empty and store the association rules as aircraft incident causal rules.
Dataset used
Data collection and cleansing
The dataset utilized in this study was compiled from investigation reports of unsafe events from 2019 to 2022. There are 9835 pieces of data from the Southwest Air Traffic Management Bureau. Due to space limitations, the authors selected only 22 representative data points, which are distributed among different years, different flight stages, different causes and different levels of unsafe aircraft events. The resulting dataset (after data preprocessing) is detailed in Table 2.
Text mining was applied to the collected event investigation reports. Following existing regulations such as the Event Information Reporting and Processing Standard and Event Samples, causative factors were decomposed into relevant causative keywords. The TFâIDF method was employed for text feature extraction, and preliminary aircraft incident causative factors were obtained by matching within specified classified texts. The accident causation 2-4 model was applied for further screening of the aircraft incident causative factors, categorizing all factors during aircraft operation into human, equipment, management, and environmental layers. Finally, the top 30 TFâIDF-based ranked feature words from each layer were extracted as the causative factors for that layer.
Encoding of the causal factor set
The obtained 56 items are all data sources from the unsafe incident investigation reports listed in Table 1. After data cleaning with the expert system and factor screening by the accident cause 2-4 model, the 4th, 5th, 6th, 8th, 11th, 14th, 18th, 19th, 20th, 24th, 31st, 32th, 34th, 45th, 46th, 48th, 49th, 50th, 52nd and 55th items were selected. These items include the unsafe event type and all types of causes, including relevant personnel, aircraft, equipment conditions, management and environment. The set of causative factors of aircraft incidents was extracted and encoded, as summarized in Table 3.
Unsupervised learning of causal analysis
The set of causal factors used to train the machine model lacks labels, requiring it to autonomously explore, obtain, and summarize knowledge to annotate the training data. This facilitates the discovery of inherent patterns and features among these elements. In this study, an initial correlation network for aircraft accident causation was established, as shown in Fig. 5.

Initial association network of the causal relationships from unsupervised learning.
Figure 5 clearly shows that node A02 occupies a central position and exhibits connections with numerous factors. However, due to the considerable number of nodes and edges, deriving precise connections between causal factors remains challenging, thereby hindering quantitative analysis of their relationships. To reveal valuable yet hidden associations, the subsequent step involved employing the Apriori algorithm for data mining. This approach aimed to reveal the latent value within the dataset, resulting in the determination of association rules meeting specific conditions. The network graph of these rules is shown in Fig. 6.

Network graph of the discovered association rules.
In Fig. 6, node A02 remains at the network centre, demonstrating connections with multiple nodes such as M05, E02, and H67, among others. Nevertheless, it remains challenging to quantitatively analyse these association rules. Therefore, the introduction of quantitative evaluation through the support, confidence, and lift was necessary, as shown in Fig. 7.

Scatter plot of the support, confidence and lift from unsupervised learning.
An analysis of the support depicted in Fig. 7 reveals frequently occurring risk factors in accidents, indicating their propensity to cause the risk state of an aircraft incident. Moreover, the analysis of high-confidence association rules reflects reliable causeâeffect relationships. Association rules with high lift indicate positive or negative combinations of factors. However, in the scatter plot, numerous association rules exhibit a confidence level of 1, suggesting a high-confidence association between factors. Some feature value pairs are detailed in Table 4.
Table 4, which is based on the definition of confidence, indicates that inadequate mastery of specific content during flight training H37, inadequate personnel qualification management M25, and poor conflict resolution ability H10 are likely to cause the occurrence of a general incident A02. To more comprehensively visualize the association rules causing the occurrence of a general incident A02, a high-confidence network graph was generated, as shown in Fig. 8.

High-confidence network graph from unsupervised learning.
Figure 8 shows that A02 remained at the network centre and was interconnected with multiple nodes, indicating that many factors potentially cause A02. However, the association rules are overly idealized, relying too heavily on individual factors while disregarding other factors that might contribute to its occurrence, thereby potentially impacting the accuracy of the final analysis.
Causal analysis using supervised learning
Initial association
To enhance the analysis accuracy, supervised learning was applied to prelabel the original training set, thereby adjusting or removing association rules with a confidence value of 1. A new set of associations was then established after this step, leading to changes in confidence values. The resulting causal correlation network of aircraft incident causes after data intervention is shown in Fig. 9. In the causality network graph, each node represents the causal factors extracted from the selected practice survey reports, including 90 causal factors and 3 incident types, and the node size is determined by the degree of the node. The correlation between the causal factors is regarded as an undirected edge between the nodes; if 2 causal factors occur in one event at the same time, there is an edge between the two points, and the weight of the edge is the number of accidents in which both factors concurrently appear.

Incident cause correlation network from supervised learning.
Figure 9 shows that A01 and H02 are central nodes in the network graph. In contrast to the unsupervised algorithm results shown in Fig. 5, where only A02 emerged as the central node, this revised network graph more explicitly highlights the significance of controllers in safeguarding against aircraft incidents. Through supervised learning intervention, extreme situations in the association rules of the original training set could be addressed, allowing the analysis of association rules between factors to expand beyond the connections of a single node with others.
The Apriori algorithm was utilized to mine association rules while adjusting the minimum support, confidence, and lift thresholds. Different minimum support thresholds yielded varying quantities of association rules, as detailed in Table 5.
To ensure the analysis accuracy, thresholds were set to filter out low-reliability association rules while obtaining a sufficient quantity for analysis. Thus, by setting the minimum support, confidence, and lift thresholds to 0.05, 0.1, and 1, respectively, rule mining was performed. After data mining, 128 association rules were obtained. A scatter plot of their support, confidence, and lift is shown in Fig. 10.

Scatter plot of the support, confidence, and lift of the association rules from supervised learning.
Figure 11 shows that certain nodes occur at the centre of the network graph, exhibiting more complex connections with other nodes. These nodes include general incident A02, serious incident A03, inadequate safety pressure transmission M18, insufficient regulation M21, inadequate onsite management duties H30, inadequate regulation M21, inadequate coping ability H45, and inadequate rigorous risk control measures M01. These nodes exhibit higher degrees than other nodes, indicating more frequent association rules with other nodes. This emphasizes the need for specific attention and strict control of these nodes in civil aviation safety management.

Diagram of the 128 association rules.
Based on the diagram, it can be preliminarily determined that A01, A02 and A03 hold central positions in the network graph and possess significant weights. In contrast to the unsupervised algorithm results in Fig. 6, despite containing fewer nodes, the variations among different association rule indicators increased. This approach is more advantageous for subsequent analyses of the relationships between association rules, enhancing the credibility of the analysis results.
Analysis of the high-support association rules
Fifty association rules with high support were extracted from all association rules. These high-support association rules are detailed in Table 6.
The 50 high-support association rules exhibited support values varying between 0.057142 and 0.142858, confidence values varying between 0.2 and 0.833334, and lift values varying between 1 and 4.375. High-support association rules indicate frequent relationships between factors, with higher support indicating stronger rules. A diagram of the high-support association rules is shown in Fig. 12.

Diagram of the high-support association rules.
The analysis revealed important nodes, such as A01, A02, A03, H30, M21, and H10. The frequent relationships between the identified factors include correlations between air traffic controllers H02 and general unsafe events A01, between inadequate manual promotion M14 and serious incidents A03, between improper energy allocation H04 and general unsafe events A01, and between poor conflict resolution ability H10, inadequate onsite management duties H30, and occurrence of luck mentality H12 and general unsafe events A01. These frequent influences between factors contribute to the aircraft operational system occurring in a high-risk state, leading to aircraft incidents. Hence, focused attention and preventive measures are needed for the corresponding personnel, equipment, management, and environmental factors related to these causal factors to minimize their impact.
Analysis of the high-confidence association rules
Fifty association rules with high confidence were selected from the 128 association rules. These high-confidence association rules are detailed in Table 7.
These 50 high-confidence association rules exhibited confidence values varying between 0.5 and 0.833334, support values varying between 0.057142 and 0.142858, and lift values varying between 1.25 and 11.666667. Analysis of the high-confidence association rules, represented in the network diagram shown in Fig. 13, provides more intuitive judgement of the relationships between factors.

Diagram of the high-confidence association rules.
An analysis of the diagram reveals that the occurrence of aircraft general unsafe events A01 is highly likely due to controller oversight H02. There is a 75% chance of personnel-related factors such as the occurrence of luck mentality H12 causing the occurrence of aircraft general unsafe events A01 during work. Similarly, serious incidents A03 are 75% likely to occur due to inadequate manual promotion M14. When a general incident A02 occurs, there is a 66.7% likelihood of it being caused by a failure to rectify incorrect recitation H06. Such high-confidence association rules highlight significant causal relationships, indicating that certain antecedent factors are highly likely to cause subsequent factors, thereby increasing the risk of aircraft incidents.
Analysis of the high-lift association rules
Fifty association rules with high lift were selected from the 128 association rules. Some of these high-lift association rules are detailed in Table 8.
These 50 high-lift association rules exhibited lift values varying between 2.625 and 11.666667, support values varying between 0.057142 and 0.085715, and confidence values varying between 0.2 and 0.75. The network diagram shown in Fig. 14, which was created based on these high-lift association rules, illustrates the relationships between factors more explicitly.

Diagram of the high-lift association rules.
The analysis indicates that the highest lift is observed between factors such as lack of conflict judgement H09, insufficient safety management M04, and serious incidents A03, suggesting a strong positive correlation among these three factors. This suggests that the occurrence of a lack of conflict judgement H09 and insufficient safety management M04 might increase the risk of serious incidents A03, ultimately leading to their occurrence.
Conclusion and prospects
The current practice of aviation event prediction often fails to capitalize on valuable insights from historical data, primarily focusing on immediate operational parameters. This study focused on addressing this gap by leveraging historical aviation event data and data mining techniques, in accordance with relevant regulations, to extract insights, analyse causal relationships, and enhance operational safety.
We utilized the TFâIDF technique for feature extraction and identified ninety causal factors based on the event causality 2-4 model. These factors were categorized into four layers: human (49 factors), equipment (8 factors), management (26 factors), and environment (7 factors) layers.
The Apriori algorithm was modified to mine association rules from frequent patterns in an unsupervised learning framework, compensating for the absence of date labels. Network graph analysis was employed to initially identify associations between the data, aiding feature extraction. However, early results indicated a prevalence of association rules with a confidence level of 1, suggesting overly idealized associations with low causal analysis accuracy. To resolve this issue, supervised learning techniques were applied to adjust and refine these rules, with continual calibration of the support and confidence thresholds initially set to 0.05 and 0.1, respectively. This process yielded 128 meaningful association rules, which were analysed for their support, confidence, and lift to quantify the underlying associations.
In this study, aviation event influencing factors were comprehensively analysed from multiple perspectives and levels, uncovering potential patterns and characteristics of mutual interactions among various types of historical event data. By quantitatively analysing the relationships among aviation event factors, the reliability of aviation event analysis can be enhanced.
According to the exploration of historical aircraft event causality in this paper, it is evident that A01 is the most common event type, and H02 holds significance in ensuring aircraft safety.These nodes include A02, A03, M18, M21, H30, M21, H45, and M01, exhibit higher degrees than other nodes, indicating more frequent association rules with other nodes. This emphasizes the need for specific attention and strict control of these nodes in civil aviation safety management. Additinally, the results show that improper energy allocation, poor conflict resolution ability, inadequate onsite management duties, adoption of a luck mentality, and occurrence of controller oversight are highly correlated with general unsafe events, and failure to rectify incorrect recitation is notably correlated with general incidents, while inadequate manual promotion, lack of conflict judgement and insufficient safety management are strongly correlated with serious incidents. Therefore, in actual aircraft operations, it is essential to prioritize the aforementioned nodes. Prompt action should be taken upon detecting tendencies towards the occurrence of these nodes to prevent the occurrence of unsafe incidents.
Given the importance of ensuring aviation operational safety and preventing events, learning from past events is crucial. However, due to limitations in data sampling and the finite cognitive understanding of manually labelled experiences, it is possible that the results of machine learning might possess directional bias. Therefore, during the next phase of research, efforts will focus on expanding the dataset and employing human experiences more systematically, possibly along the direction of deep learning methodologies.
Data availability
Data sets generated during the current study are available from the corresponding author on reasonable request, but restrictions apply to the availability of these data, which were used under license for the current study, and so are not publicly available.
Abbreviations
- NaN:
-
Not a number
- TFâIDF:
-
Term frequencyâinverse document frequency
- HFACS:
-
Human factor analysis and classification system
References
Chen, B. & Wu, M. Etiologies of accident and safety concepts. J. Saf. Sci. Technol. 1, 42â46. https://doi.org/10.3969/j.issn.1673-193X.2008.01.009 (2008).
Fu, G., Yin, W., Dong, J., Di, F. & Zhu, C. Behavior-based accident causation: The â2â4âmodel and its safety implications in coal mines. J. China Coal Soc. 38(7), 1123â1129. https://doi.org/10.13225/j.cnki.jccs.2013.07.032 (2013).
Chen, Q. Analysis on accident causation factors and hazard theory. China Saf. Sci. J. 19(10), 67â71. https://doi.org/10.16265/j.cnki.issn1003-3033.2009.10.010 (2009).
Fu, G. & Guo, Q. A brief review on the study and application of accident causation theory. Saf. Secur. 40(09), 1â5. https://doi.org/10.19737/j.cnki.issn1002-3631.2019.09.001 (2019).
Zhang, N. & Sheng, W. Causes analysis of coal mine gas explosion accidents based on Bayesian network. Ind. Mine Autom. 5(07), 53â58. https://doi.org/10.13272/j.issn.1671-251x.2019010049 (2019).
Zheng, S., Fan, Y. & Li, Z. Causal factors of truck traffic accidents based on HFACS model. Saf. Environ. Eng. 27(06), 133â139. https://doi.org/10.13578/j.cnki.issn.1671-1556.2020.06.019 (2020).
Xu, W. et al. Construction and analysis of railway accident causation network based on association rules. Railw. Transp. Econ. 42(11), 72â79. https://doi.org/10.16668/j.cnki.issn.1003-1421.2020.11.13 (2020).
Zhang, Y., Dong, C., Guo, W., Dai, J. & Zhao, Z. Systems theoretic accident model and process (STAMP): A literature review. Saf. Sci. 152(8), 105596. https://doi.org/10.1016/j.ssci.2021.105596 (2022).
Ji, Z., Yin, J. & Ge, S. Application of grounded theory in causation analysis of shipnavigational accidents. Navig. China 46(02), 9â16. https://doi.org/10.3969/j.issn.1000-4653.2023.02.002 (2023).
Lenné, M., Ashby, K. & Fitzharris, M. Analysis of general aviation crashes in Australia using the human factors analysis and classification system. Int. J. Aviat. Psychol. 18(4), 340â352. https://doi.org/10.1080/10508410802346939 (2008).
Li, W., Don, H. & Yu, C. Routes to failure: Analysis of 41 civil aviation accidents from the Republic of China using the human factors analysis and classification system. Accid. Anal. Prev. 40(2), 426â434. https://doi.org/10.1016/j.aap.2007.07.011 (2008).
Chang, Y., Yang, H. & Hsiao, Y. Human risk factors associated with pilots in runway excursions. Accid. Anal. Prev. 94, 227â237. https://doi.org/10.1016/j.aap.2016.06.007 (2016).
Kharoufah, H., Murray, J., Baxter, J. & Wild, G. A review of human factors causations in commercial air transport accidents and incidents: From to 2000â2016. Prog. Aerosp. Sci. 99(5), 1â13. https://doi.org/10.1016/j.paerosci.2018.03.002 (2018).
Stojiljkovic, E., Bijelic, B., Grozdanovic, M. & Djokic, M. Pilot error in process of helicopter starting. Aircr. Eng. Aerosp. Technol. 90(1), 158â165. https://doi.org/10.1108/AEAT-08-2015-0190 (2017).
Chen, W. & Huang, S. Evaluating flight crew performance by a Bayesian network model. Entropy 20(178), 1â14. https://doi.org/10.3390/e20030178 (2018).
Sun, R., Yuan, Z., Sun, L. & Ma, Y. Analysis of safety trend in civil aviation of China. 4th International Conference on Transportation Information and Safety (ICTIS). Banff, AB, Canada. 2017, 852â857. https://doi.org/10.1109/ICTIS.2017.8047867.
Tu, X., Liu, B. & Lin, W. Survey of big data. Appl. Res. Comput. 31(6), 1612â1616. https://doi.org/10.3969/j.issn.1001-3695.2014.06.003 (2014).
Chen, H. & Kai, J. Application of big data analysis technology in visualization of historical navigation route. Ship Sci. Technol. 41(24), 58â60 (2019).
Haung, W. Exploration of big data mining and data processing methods. Comput. Knowl. Technol. 17(08), 23â24. https://doi.org/10.14004/j.cnki.ckt.2021.0616 (2021).
Friedman, J. H. Data Mining and Statistics: What''s The Connection? Stanford University. 1997; pp. 06â12.
Liu, T. Data Mining Techniques and Its Applications 251â253 (National Defense Industry Press, 2001).
Fayyad, U. & Stolorz, P. Data mining and KDD: Promise and challenges. Futur. Gener. Comput. Syst. 13(2), 99â115. https://doi.org/10.1016/S0167-739X(97)00015-0 (1997).
Guo, M. & Wang, J. Data mining and knowledge discovery in databases: A survey. Pattern Recognit. Artif. Intell. 11(3), 292â299 (1998).
Xu, R., Bao, Y., Jiang, H., Chen, X. & Ji, J. Research on mining technology for road traffic accident data analysis. J. Peopleâs Public Secur. Univ. China Sci. Technol. 14(4), 69â73. https://doi.org/10.3969/j.issn.1007-1784.2008.04.021 (2008).
Wang, H. The application of the mining of association rules in analysis of traffic accidents. Anhui Anhui Univ. China 2012, pp. 126â135.
Cheng, T. Research on road traffic accident data mining and application. Harbin: Harbin Institute of Technology, China 2009; pp. 167â172.
Hu, J. & Cao, X. Analysis of characteristic of driver involved in road traffic accident. China J. Highw. Transp. 22(06), 106â110. https://doi.org/10.19721/j.cnki.1001-7372.2009.06.016 (2009).
Dong, L., Liu, G., Wan, S., Li, Y. & Wu, Z. Applicaition of data mining to traffic accidents analysis. J. Jilin Univ. (Sci. Edn.) 6, 951â955. https://doi.org/10.13413/j.cnki.jdxblxb.2006.06.024 (2006).
Shang, W. et al. The analysis of multidimensional association rule in traffic accidents. Comput. Appl. Softw. 2(40â42), 65. https://doi.org/10.3969/j.issn.1000-386X.2006.02.018 (2006).
Zhao, H., Cai, L. & Li, X. Overview of association rules Apriori mining algorithm. J. Sichuan Univ. Sci. Eng. Natl. Sci. Edn. 24(1), 66â70. https://doi.org/10.3969/j.issn.1673-1549.2011.01.019 (2011).
Huang, C., Gao, D., Hu, S., Geng, H. & Peng, Y. Association rule analysis of vessel traffic accidents based on Apriori algorithm. J. Shanghai Marit. Univ. 35(03), 18â22. https://doi.org/10.13340/j.jsmu.2014.03.004 (2014).
Yang, J. Correlation Analysis of Data Mining and its Application in Road Traffic Accidents. Guangzhou: Guangzhou University, 2014, pp. 36â45.
Li, S., You, M., Li, D. & Liu, J. Identifying coal mine safety production risk factors by employing text mining and Bayesian network techniques. Process Saf. Environ. Prot. 162, 1067â1081. https://doi.org/10.1016/j.psep.2022.04.054 (2022).
Liu, Z. & He, S. Association rule mining for causes of railway traffic accidents based on improved Apriori algorithm. Railw. Transp. Econ. 45(4), 120â126. https://doi.org/10.16668/j.cnki.issn.1003-1421.2023.04.17 (2023).
Li, Y., Zhang, Y., Chen, X., Hou, T. & Li, S. Associative network analysis of inducements for unsafe behaviors based on text-mining method. Saf. Coal Mines 54(04), 251â256. https://doi.org/10.13347/j.cnki.mkaq.2023.04.035 (2023).
Li, J. & Jiang, M. Application of spectral clustering and Apriori algorithm in combination analysis of construction collapse accident causes. J. Saf. Environ. https://doi.org/10.13637/j.issn.1009-6094.2022.2612 (2023).
Jing, G., Qin, H. & Jiang, F. Coal mine safety accident analysis based on Apriori algorithm. J. Saf. Environ. https://doi.org/10.13637/j.issn.1009-6094.2023.1305 (2023).
Funding
This work was supported by the Key Research and Development Project of Sichuan Province (No. 2023YFG0163) and the General Program of Civil Aviation Flight University of China (J2022-061). The funder had no role in the study design, data collection and analysis, decision to publish, or preparation of the manuscript.
Author information
Authors and Affiliations
Contributions
Conceptualization, M.Y.; methodology, H.C.; software, M.Y.; validation, H.C., M.Y.; investigation, H.C., M.Y.; data curation, X.T.; writingâoriginal draft preparation, H.C., M. Y; writingâreview and editing, X.T.; visualization, M.Y.; project administration, H.C.; funding acquisition, X.T. All authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Chen, H., Yang, M. & Tang, X. Association rule mining of aircraft event causes based on the Apriori algorithm. Sci Rep 14, 13440 (2024). https://doi.org/10.1038/s41598-024-64360-6
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-64360-6
Keywords
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
