Erez Katz, Lucena Research CEO and Co-founder
In order to understand where transformer architecture with attention mechanism fits in, I want to take you through our journey of enhancing our ability to classify multivariate time series of financial and alternative data features.
We initially looked to conduct time series forecasting using fully connected networks by which we were passing to the input layer a one-dimensional sequence of values. We quickly realized that due to the noisy nature of the market, we needed a way to extract meaningful subsets of data, i.e extract substance from noise. Our inherit goal was to identify meaningful patterns within a noisy construct of time series data.
We were faced with two options:
- RNN with LSTM — Recurrent Neural Network with long/short term memory
- CNN with CapsNet – Convolutional Neural Networks with Hinton’s latest CapsNet technology.
We’ve tried both and landed on CNN and CapsNet, purely based on empirical evidence. We simply couldn’t make RNN/LSTM work.
Why Applying RNN with LSTM to Detect Time Series Patterns Didn’t Work
In retrospect, I attribute the lack of compatibility of RNN/LSTM to our specific use case to the following:
1. The problem we were trying to solve was to identify how multiple orthogonal time series sequences overlaid together can forecast an expected outcome (for example, a stock impending price action). Our hypothesis was that analyzing multiple time series together would be more informative than each one alone. RNN/LSTM is mainly designed to solve a single stream flow of information (such as text translation, NLP, and music sequence) and therefore wasn’t a good fit for our multiple time series input.
- 2. We found RNN to be very difficult to train even after we’ve added LSTM (long/short memory). I believe that the main reason for our challenge was the model’s inability to decide which information to save or discard when the input stream grew larger.
- 3. RNN was not parallelizable and so training took significantly longer compared to CNN, which is based on aggregating the scores of independent learning paths and thus can be easily parallelized.

Image 1: An illustration of RNN — a recursive loop unfolder to a sequence of identical models. Souce: http://colah.github.io/posts/2015-08-Understanding-LSTMs/
Using Image Classification with CNN
So we decided on applying computer vision to classify images composed of multiple time series graphs as shown below.

Image 2: Matching a price action (label Y values) with multiple time series sequences. Each time series graph represents a feature (such as social media sentiment, volatility, PE ratio, etc.) sequence over an identical timeframe.
The idea was to overlay multiple time series graphs on top of each other in order to create a composite image that is then fed as training data for a model to classify one of the following actions: buy, sell, do nothing.
Our initial results were actually encouraging and since we knew we were on the right track, we’ve expanded our image representation to include a richer depiction of time series data.
First we worked hard on feature engineering as we strived to evenly distribute our various feature data into a uniform format over 63 days. In addition, we’ve migrated our one dimensional 63 data points into a two dimensional richer depiction of 63 * 63 as described below.

Image 3: Converting one-dimensional time series to richer image representation based on RP (recurrent point) or GADF (Gramian Angular Difference Field).

Image 4: Richer image representation based on RP (recurrent point) to create a more enhanced multi-channel input into a CNN model.
We then proceeded to feed a set of features as depicted in image 4 above and our classification accuracy improved!
Enhancing Our Multi-Channel Image Classification with Hinton’s Capsule Network
We were truly encouraged by the results of our enhanced CNN model until we came across an article published by Geoff Hinton which points out several drawbacks in traditional CNNs.
The biggest challenge of traditional CNN stems from the use of Max Pooling. Max Pooling is an integral part of the CNN multi-layer format in which spatial features are simplified by only passing to the next layer, the most dominant neuron in a cluster. This method works great by approximating features and downsizing a large image but the loss of information and the inability of the network to reconstruct the original image have seriously degraded the network’s ability to detect objects and contextualize them within an image.
Max Pooling works great through approximation and downsizing of an image feature maps. However, important information on the image gets lost through the convolution and max pooling process.
It turns out that such image downsizing was somewhat detrimental to the type of pattern detection we are seeking to achieve in our time series analysis.
Example: Take for example the images below:
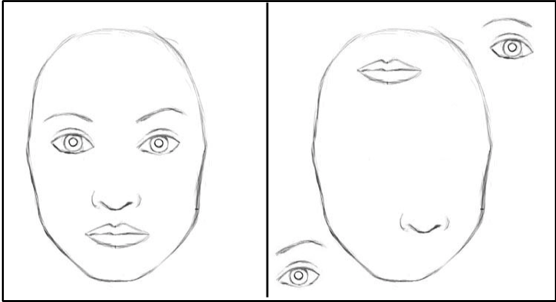
Image 5: Due to feature extraction with Max Pooling. A CNN fails to recognize the interrelationships between the sub-images detected in the master image.
A traditional CNN network will likely classify the two side by side images as a “face”. The reason is that the convolutional hidden layers and the max pooling identify the shape of the detectable objects by approximation and without any regards to the placement, the pose, the texture, or any other attributes that define the image.
Come to think of it, the network makes a pretty wild assumption that if there is an object within the image that looks like an eye, another that looks like a mouth, and one more that looks like a nose — it’s pretty safe to assume that it’s an image of a face. More seriously, the network is unable to reconstruct the original image due to the loss of information and can be easily fooled and exploited by adversarial neurons. Adversarial Neurons are neurons that were inserted into an image representation with the intent to hinder the machine’s ability to classify it while these images look just fine to the naked eye.
Hinton advocated a new breed of deep learning models for image detection — including sub-image and object detection — called capsule networks (CapNets). CapsNets address all of the above drawbacks by describing objects within an image through a set of vectors that preserve the location, pose, and some other attributes of the spatial field being convolved (a Capsule). In addition, capsule networks introduced the concept of routing by agreement, marginal cost, and image reconstruction lost as methods to train a network to detect images with much greater accuracy and speed.
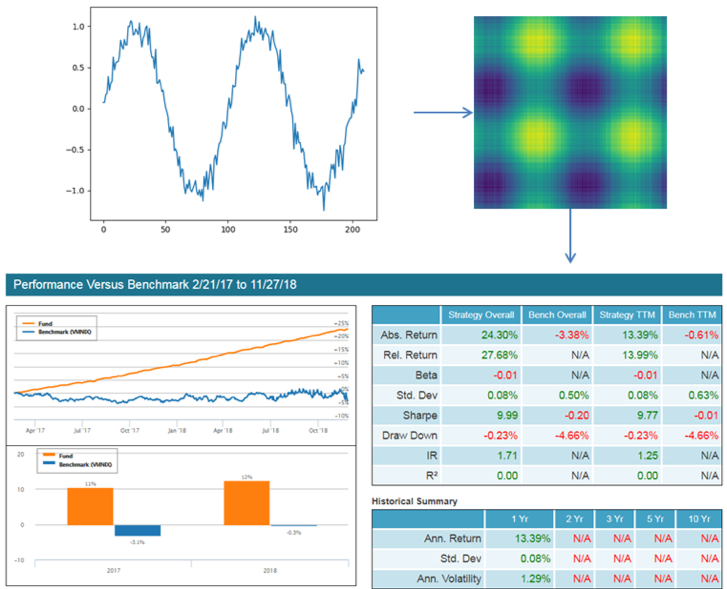
Image 6: Capsule network used to detect a stock price which behaves similarly to a sine wave formation. Lucena has tested capsule network’s ability to forecast the next sequence in the time series with various noise levels. Our goal is to empirically test the network’s sensitivity to real life market noise.
The Icing on the Cake: Transformer Architecture with Attention Mechanism
So now that we are able to detect objects (or patterns) within an overarching image, we are still short one important piece of information.
What has led to the current state or what has transpired before the detected pattern?
We needed to consider the time series “behavior” that have led to the current state being inspected. Take for example the image below. All marked patterns (1, 2, and 3) are forms of mean reversion. It is apparent, however, that the sequences that lead to the corresponding mean-reversion patterns are vastly different. Naturally, this “before” pattern would be helpful to the machine in its attempt to classify what comes next.
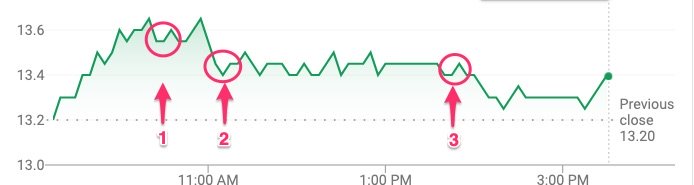
Image 7: Mean reversion patterns in a time series graph that in isolation look similar, but once they are introduced in the context of their preceding sequences, look vastly different.
Moreover, the proximity to which the preceding sequence appears in relationship to the current patterns is not always informative. Hence, the network should learn to ignore meaningless sequences and pay “attention” only to what’s important.
Transformer Architecture with Attention Mechanism
In the past few months, transformer architecture with attention mechanism has been gaining popularity. The concept was originated by OpenAI in their language translation models, and also by DeepMind for a machine learning AlphaStar player set to defeat top professional human Starcraft players. In order to understand how they can help us with time series analysis, I want to illustrate how it’s used first in the context of text to speech or language translation.
Transformer architecture is set to solve sequence transduction problems. In other words, the model is tasked with transforming any input sequence to an output sequence through three steps: encoding, machine translation, and decoding.

Image 7: Sequence transduction. Source: https://jalammar.github.io/visualizing-neural-machine-translation-mechanics-of-seq2seq-models-with-attention/
When looking at a sentence such as: “The King lived in France. The spoken language around the King’s dinner table was…”
It’s obvious to us as readers that the next word in the above sentence is most probably “French.” That’s because we remember from the previous sentence the context of locale as France. Transformer architecture with attention in a way act similarly as it learns to determine which previous words is important to remember. It does it better than RNN / LSTM for the following reasons:
- – Transformers with attention mechanism can be parallelized while RNN/STM sequential computation inhibits parallelization.
- – RNN/LSTM has no explicit modeling of long and short range dependencies.
- – In RNN/LSTM the “distance” between positions is linear.
To state simply, when translating a sequence of words, the system inspects one word at a time and there is no notion of dependencies between close words or distant words that may have relevance to the current word being inspected. Not to mention that process is linear and can’t be parallelized for speed.
How Transformer Architecture with Attention Mechanism Help Our Time Series Forecasting
In order to effectively settle on a predictive pattern, the model attempts to infer a sequence of ebbs and flows that have historically been proven predictive. This goes toward any time series patterns of any value that fluctuates over time. (For example, measuring alternative data in the form of social media sentiment towards a stock over time.)
The use of transformer architecture with attention mechanism enables the network to detect similar sequences, even though the specific image representations may be somewhat different.
This in turn helps the models learn faster and generalize features better.
Example: Take a look for example at the following image:
Imagine this is a time series representation of some factor over time and that the five higher-highs denoted by the red circles are indicative of an impending plateau to be followed by a subsequent drop.

Image 8: Time series example of a predictive sequence flow.
In practice, the attention network will create a hidden state to each marked peak in which it remembers the peaks and discards as less important the “noise” between them. In other words, the network is able to extract what’s important from the sequence. Just like a sentence with five words to which the network measures the importance of each word in combination with the others, our network evaluates each peak in combination with other peaks.
To put all of this together, we use CNN and CapsNet to detect certain snippets of pattern formations such as a sudden spike or drop in a feature value. We then sequence the identified patterns through a transformer to measure how the sequence of these patterns can be used to reliably forecast an outcome.
Conclusion:
It’s important to note that the notion of time series image classification is not meant to be used solely for asset price predictions. There are quite a few interesting machine learning problems that extend far beyond predicting stock prices, such as measuring risk, volatility, KPI’s etc.
In this article I wanted to focus on the ways transformers, encoders, and decoders with attention networks can be useful for time series classification. The specific deep learning mechanics necessitates a separate article, but for reference please find an excellent introduction here.
I will keep you posted as our team integrates this concept into our existing CapsNet framework and will report on our findings in the near term.
Questions? Drop them below or contact us.


