Object Detection and Tracking with OpenCV
Overview
In this article, we will build an object detection and tracking system using OpenCV, a popular computer vision library. We will use different techniques for object detection using opencv python, including dense and sparse optical flow, Kalman filtering, meanshift and camshift, and single object trackers. Additionally, we will explore how to perform multiple object tracking with re-identification.
Pre-requisites
Before we begin, you should have a basic understanding of the following:
- Python 3.x
- OpenCV-Python
- NumPy
- Pre-trained Models such as MobileNetSSD
- What is Object Tracking?
![]()
Object tracking is the process of identifying and tracking objects in a video stream. In this article, we will learn about different techniques for object detection using opencv python, including:
- Dense Optical flow
This technique involves calculating the optical flow (i.e., motion vectors) of every pixel in the image. We will use the Farneback algorithm to calculate the dense optical flow.
- Sparse optical flow
This technique involves identifying key points in the image and tracking their motion. We will use the Lucas-Kanade algorithm to calculate the sparse optical flow.

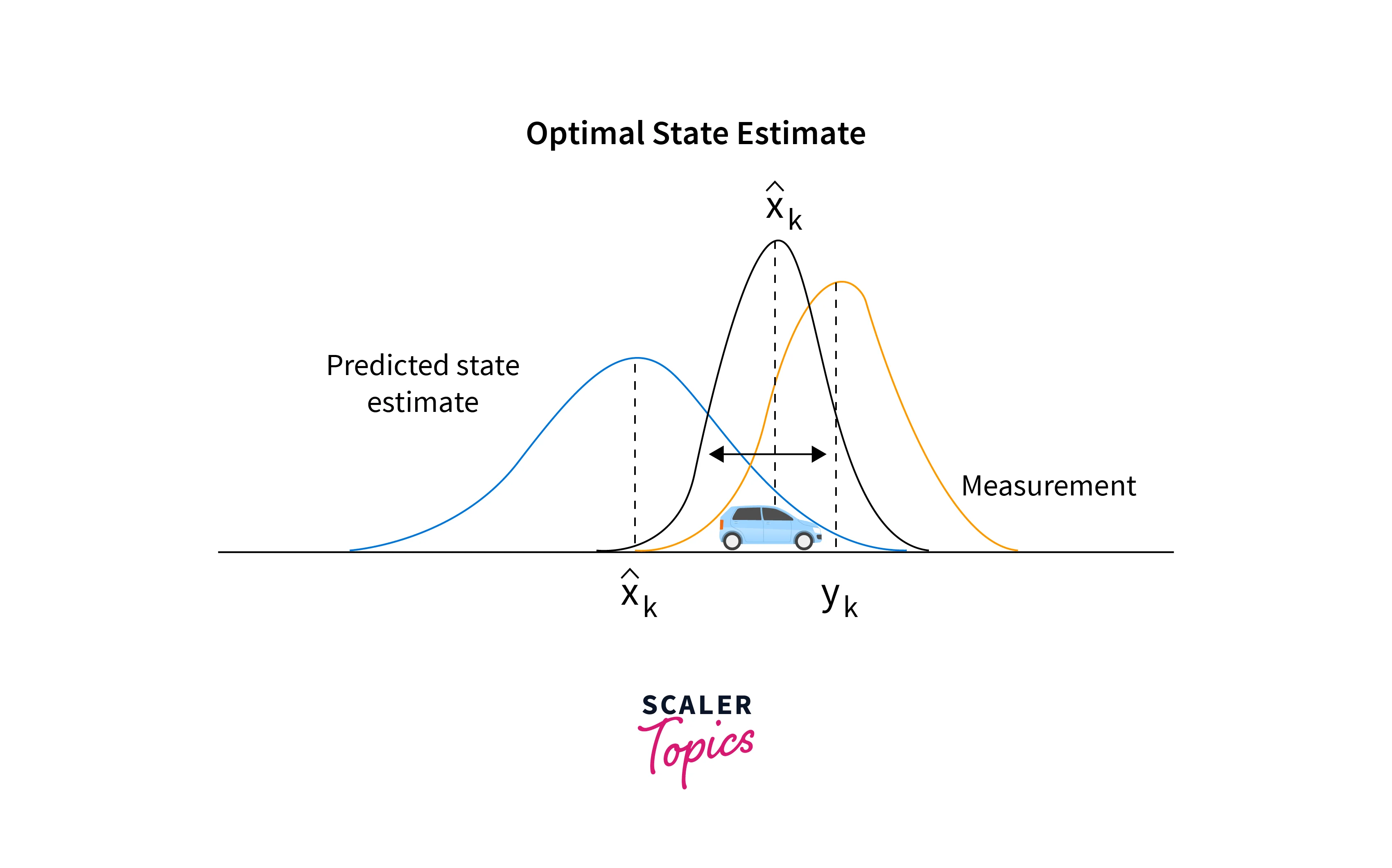
- Kalman Filtering
This is a statistical technique that uses a series of measurements to estimate the state of a system. We will use Kalman filtering to predict the position of the object in the next frame.
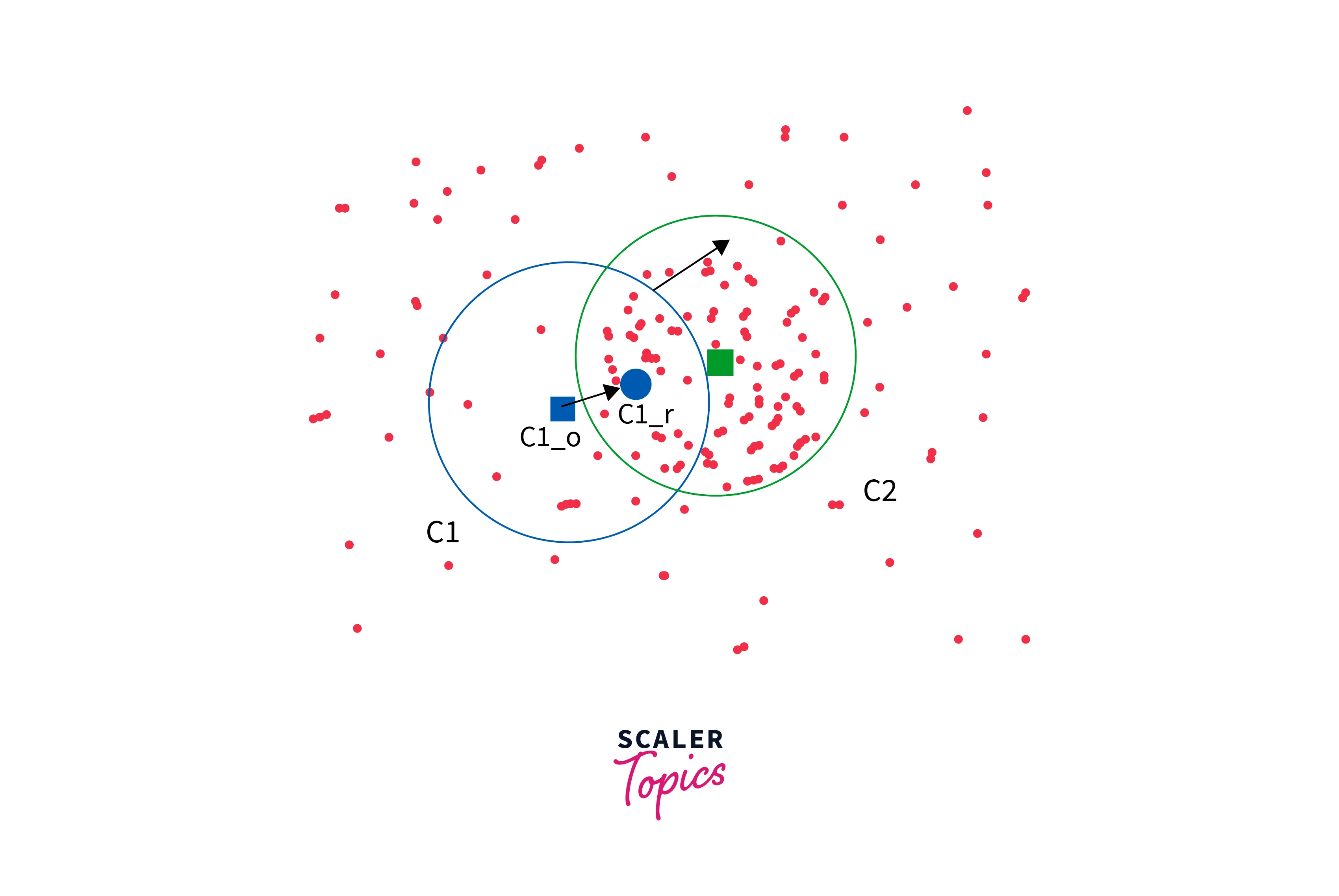
- Meanshift and Camshift
These are iterative techniques that involve shifting a window over the image to locate the object. We will use meanshift and camshift to track the object's position.
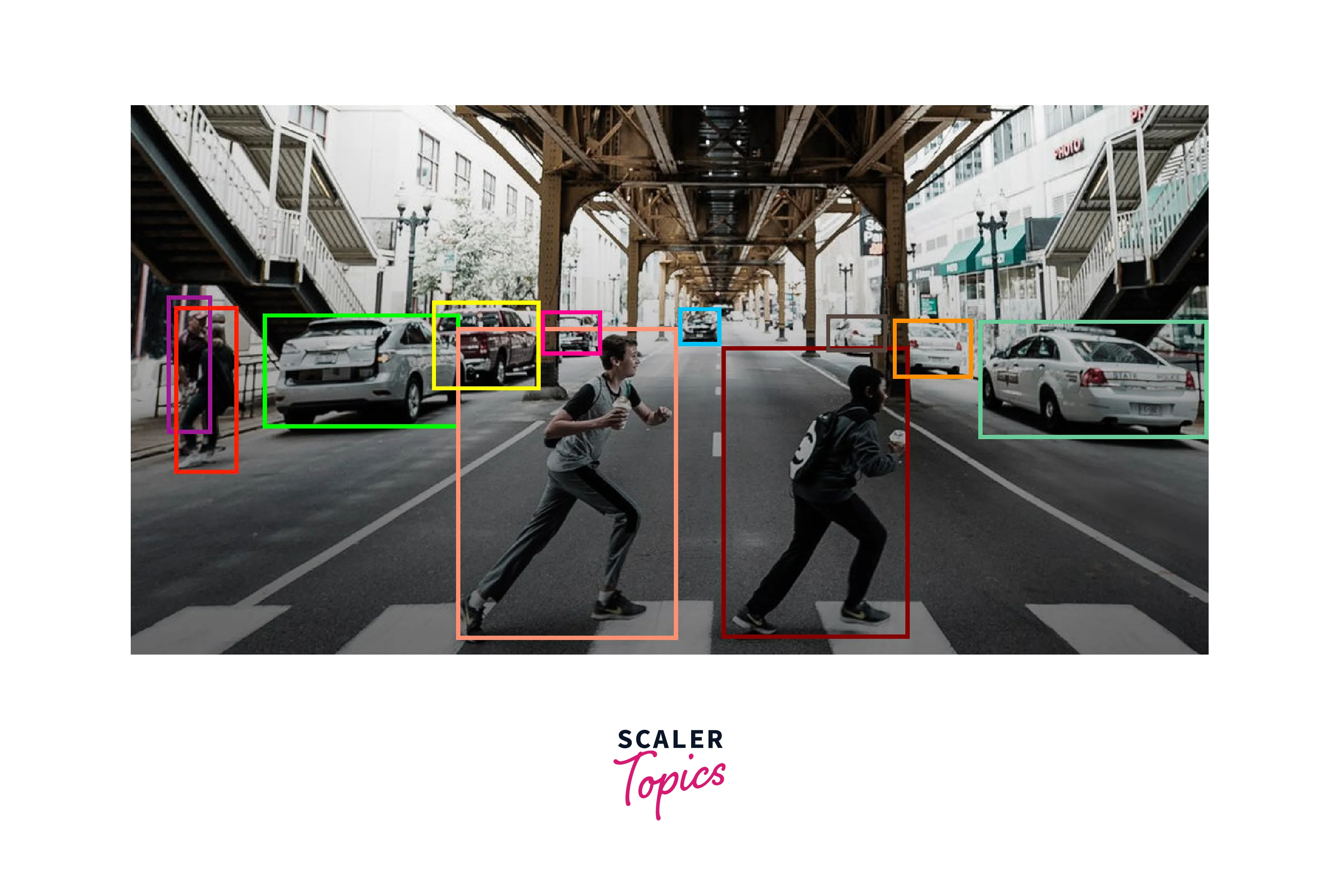
- Single object trackers
These are tracking algorithms that use a combination of different techniques to track a single object.This is one of the most used methods in the object detection using opencv python.
![]()
- Multiple object tracking with Re-Identification
In this article, we will also explore how to track multiple objects in a video stream using re-identification. Re-identification involves identifying objects that have been previously detected but may have disappeared from the frame and then reappeared.
![]()
How are we going to build this?
We will build the object tracking and object detecting using OpenCV Python. Here's a low-level overview of the steps involved:
- Read the video file.
- Use object detection to identify the object(s) in the frame. Here, we are going to use the MobileSSD pre-trained Model to perform this task.
- Display the output video with the object(s) highlighted.
To build an OpenCV object detection and tracking system using the COCO dataset and the MobileNet SSD model, we can load the model into memory, capture frames from a video source, preprocess the images, feed them into the model, obtain object detection predictions, filter out detections below a certain confidence threshold, perform non-maximum suppression, draw bounding boxes on the image.
Final Output
The final output will be a video with the object(s) tracked and highlighted.

Requirements
To build the system of object tracking object detection using opencv python, we will need to install the following libraries:
- OpenCV-Python
- NumPy
Additionally, we will need a image to test the system. Once we have the necessary libraries and data, we can begin building the system.
Building the Object Detection and Tracking with OpenCV
Object detection and tracking are critical tasks in computer vision, and OpenCV is a powerful library for implementing these tasks. In this tutorial, we will learn how to build an object detection using opencv python. We will start by discussing the dataset and data preprocessing.
Dataset
The first step in building an object detection using opencv python is to obtain a dataset. A dataset is a collection of images or videos that we will use to train our system. There are many datasets available for object detection and tracking, such as the COCO dataset, KITTI dataset, and Pascal VOC dataset. For the purpose of this tutorial, we will use the COCO dataset.
The COCO dataset contains over 330,000 images with more than 2.5 million object instances labeled across 80 categories. The dataset can be downloaded from the official COCO website (http://cocodataset.org/#download).
The MobileNet SSD model is pre-trained on the COCO dataset, which contains over 330,000 images of 80 different object categories. The pre-trained model is available for download and can be used for object detection in real-time applications, as seen in the code implementation provided earlier. We are going to make use of this pre-trained model to perform object detection using opencv python.
Build the Object Detection and Tracking with OpenCV
Here is a basic code implementation and explanation of the process:
Step 1: Install OpenCV library
First, you need to install the OpenCV library on your system. You can do this by running the following command:
Step 2: Import necessary libraries
Now, import the necessary libraries that will be used in the program. We need the OpenCV library and NumPy library for matrix calculations. We also need the imutils library for resizing the frames.
Step 3: Load the object detection model
Next, load the object detection model. You can use pre-trained models like YOLO, SSD, or Faster R-CNN for object detection. In this example, we will use the MobileNet SSD model to perform object detection using opencv python, which is lightweight and fast.
Step 4: Initialize the video capture object
Now, initialize the video capture object to read frames from the camera or a video file.
Step 5: Loop through the frames Next, loop through the frames captured by the video capture object. In each iteration of the loop, read the frame, resize it, and pass it to the object detection model for detecting objects.
Step 6: Release resources
Finally, release the video capture object and close all windows.
Using Pretrained Models - MobileNet SSD
MobileNet SSD is a single-shot object detection architecture that uses a variant of the MobileNet architecture as its base network. MobileNet is a lightweight neural network architecture designed for mobile and embedded vision applications, which is achieved by using depthwise separable convolutions instead of traditional convolutions.
The MobileNet SSD architecture is based on this idea of depthwise separable convolutions and is optimized for running on mobile devices and embedded systems with limited computational resources.
The MobileNet SSD architecture consists of two main parts: the base network and the detection network.
-
The base network is a modified version of the MobileNet architecture that consists of a series of depthwise separable convolutions followed by a fully connected layer. This base network extracts features from the input image that are then used by the detection network to detect objects.
-
The detection network is composed of a series of convolutional layers that predict the class probabilities and bounding boxes for the objects in the input image. The detection network uses a technique called multi-scale feature maps to detect objects at different scales and sizes in the input image.
The above mechanism is implemented for the system which does object detection using opencv python.

How to perform inference with the model on a single data point?
Here are the steps of performing inference with the MobileNet SSD model on a single data point using OpenCV. This is an extended version of the system which performs object detection using opencv python we built earlier. Here is a basic code implementation and explanation of the process:
Step 1: Install OpenCV library
First, you need to install the OpenCV library on your system. You can do this by running the following command:
Step 2: Load the object detection model
Next, load the MobileNet SSD object detection model. The MobileNet SSD model consists of two files: a .prototxt file that contains the model architecture, and a .caffemodel file that contains the model weights. You can download these files from the internet or use the files that come with the OpenCV library.
Step 3: Load the input image
Load the input image on which you want to perform object detection. You can use the cv2.imread() function to read an image from a file.
Step 4: Preprocess the input image
Preprocess the input image before passing it through the object detection model. You need to resize the image to a fixed size, convert it to a blob, and subtract the mean values of the dataset from it.
Step 5: Pass the image through the model
Pass the preprocessed image through the MobileNet SSD model to perform object detection.
Step 6: Visualize the output
Visualize the output of the object detection model on the input image. Loop through the detected objects, draw the bounding boxes and labels around them, and display the resulting image.
This will display the input image with the detected objects and their labels.
Note: In the code implementation above, the classes list is not defined. You need to define this list before running the code. The classes list contains the names of the object classes that the MobileNet SSD model was trained to detect. These class names correspond to the 80 object categories in the COCO dataset, which the MobileNet SSD model was pre-trained on.
When you download the MobileNetSSD_deploy.prototxt file from the OpenCV repository, it contains the list of the 80 object classes along with their corresponding IDs. Here is an example of what the classes list might look like:
Tracking vs Detection
Tracking is Faster than Detection
Object tracking is generally faster than object detection since it involves tracking the object in subsequent frames rather than analyzing each frame separately. Object detection using opencv python involves processing every frame, which can be computationally expensive.
Tracking can help when Detection Fails
Object tracking can help in cases where object detection fails, such as occlusion or when the object is partially visible. Tracking algorithms can use previous information to estimate the position of the object even when it's not fully visible.
![]()
Tracking preserves identity
Object tracking can preserve the identity of the object being tracked, allowing us to track an object across multiple frames and maintain its identity. Object detection, on the other hand, only tells us that an object is present, but not necessarily which object it is.
Conclusion
- Object detection using opencv python and tracking are important computer vision techniques that can help us identify and track objects in videos or images.
- By combining these techniques, we can build robust and accurate systems that can be used in a variety of real-world applications.