Beyond Words: The Future of Machine Learning with Transformer Models
Transformer models have emerged as a key architecture in machine learning and natural language processing (NLP). Transformers, which were first introduced in the research "Attention is All You Need" by Vaswani et al., have replaced earlier sequential models with remarkable success in a variety of tasks.
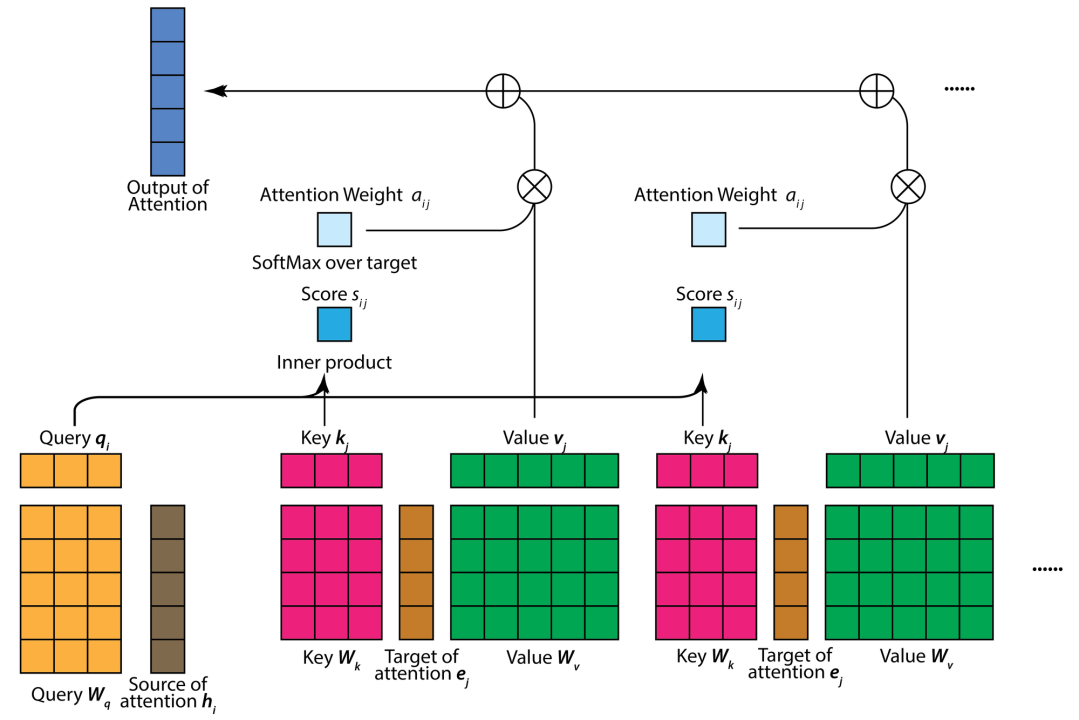
A Transformer model's attention mechanism is a crucial invention that allows the model to selectively focus on various input sequence segments while producing an output. This mechanism, which was first presented in the paper "Attention is All You Need" by Vaswani et al., enables the model to dynamically determine the relative importance of the various words in the input sequence.
Important Elements in the Attention Mechanism
Vectors of Query, Key, and Value: For every word in the input sequence, the attention mechanism uses three vectors: Query (Q), Key (K), and Value (V).The model can learn the relationships between words by using these vectors, which are linear transformations of the input embeddings.
Attention Points
By taking the dot product of one word's query vector and another word's key vector, the attention score is calculated. To regulate the magnitude and enhance training stability, the scores are scaled.
Activation of Soft max: Following the softmax activation function's processing of the attention scores, a probability distribution over the words in the input sequence is generated. This distribution shows how much weight the model gave each word.
Sum of Weighted Values: Taking a weighted sum of the Value vectors based on the attention scores that have been computed is the last step. The context vector for a specific word in the input sequence is represented by this weighted sum.
Multi-Head Attention: A Transformer's attention mechanism is frequently implemented with multiple heads to improve the model's capacity to capture various relationships. Independent of one another, each head offers a unique perspective on the connections between words. The final attention output is produced by concatenating and linearly transforming the outputs from several heads.
Positional Encoding: Positional encoding is added to the input embeddings to provide information about word positions, as transformers are not designed to understand the order of words in a sequence. This aids the attention mechanism in taking the input's sequential nature into account.
A key element of Large Language Models (LLMs), like the Transformer-based models, is the encoder-decoder architecture. The encoder-decoder structure is essential to LLMs' ability to comprehend and produce language akin to that of humans.
LLMs' Encoder-Decoder Architecture
Encoder: Processing the input sequence, which may consist of a sentence or a paragraph, is the encoder's responsibility. The input sequence's tokens are all converted into high-dimensional embeddings. To extract contextual information and hierarchical features from the input, multiple encoding layers are used.
Decoder: The information encoded by the encoder is used by the decoder to create the output sequence.One step at a time, it uses the encoded data to create a series of tokens.Similar to the encoder, the decoder is made up of several layers, each of which produces a portion of the output sequential.

Feedforward neural networks (FNNs) are widely used as parts of the model architecture in the context of Large Language Models (LLMs), helping with tasks like representation learning, language understanding, and various downstream natural language processing applications. Although LLMs, like transformers, have a primary architecture based on self-attention mechanisms, each transformer block's feedforward layers often use feedforward neural networks.
Feedforward Neural Networks Function in LLMs Inside Transformer Blocks
Generally, each transformer block in an LLM is made up of two primary parts: the feedforward neural network and the self-attention mechanism. Every position in the sequence is handled independently by the feedforward neural network.
Layer for Position-wise Feedforward: The output of the self-attention mechanism is received by the position-wise feedforward layer, which independently processes it at each position. It is composed of activation functions, usually a ReLU (Rectified Linear Unit), and fully connected layers. The model can recognize intricate patterns in the data because of the non-linearities introduced by the feedforward neural network.
Part in the Transforming of Features:The features that are learned through self-attention are transformed in a significant way by the feedforward neural network. It assists the model in identifying connections and trends that the attention mechanism might not have explicitly recognized.
LLMs that use feedforward neural networks in their transformer architectures include BERT (Bidirectional Encoder Representations from Transformers) and GPT (Generative Pre-trained Transformer).
FFN(x) = ReLU (xW1+b1) w2+ b2 ............................(1)
Mathematically, the operation of the position-wise feedforward layer can be represented as follows: where x is the input representation, w1,b1 are the weights and biases of the first layer, and w2,b2 are the weights and biases of the second layer.
The position-wise feedforward operation is represented by this equation, which involves linear transformations on the input representation x, non-linear activation, and then another linear transformation. This process adds to the model's overall expressive power since it is carried out independently at every point in the input sequence.
Frequently Used Transformer Models
In 2018, researchers at Google Research unveiled BERT (Bidirectional Encoder Representations from Transformers), a potent pre-trained natural language processing (NLP) model. BERT is a member of the transformer-based model family and has had a big impact on NLP. This is a synopsis of BERT:
Important BERT features include Understanding context in both directions:
BERT is made to be able to comprehend word context in both directions. BERT takes both directions into account at once, in contrast to earlier models that only processed text in one direction (left-to-right or right-to-left).
Architecture of Transformers: BERT is based on the transformer architecture, which recognizes relationships between words in a sentence or sequence by using self-attention mechanisms.
Prior to Large Corpus Training: BERT has been pre-trained on a vast quantity of textual data, acquiring rich contextualized word representations. Predicting missing words in sentences is part of this unsupervised pre-training.
The goal of the Masked Language Model (MLM) is In order to train the model to predict masked words based on surrounding context, BERT employs a masked language model objective during pre-training. This involves masking random words in a sentence. Switch Blocks: BERT is made up of several transformer blocks layered on top of one another. Neural networks with position-wise feedforward and self-attention layers are included in every block.

A family of natural language processing (NLP) models called Generative Pre-trained Transformer (GPT) was created by OpenAI. GPT is a member of the transformer-based architecture and is renowned for producing text that is logical and appropriate for the context.
This is a quick synopsis of GPT: Important GPT Features The foundation of GPT is the transformer architecture, which captures the contextual relationships between words in a sequence by means of self-attention mechanisms. The Generative Approach Being a generative model, GPT can produce text that resembles that of a human depending on a prompt or context.
Prior to Diverse Data Training: Because GPT has been pre-trained on a wide variety of online text, it is able to pick up on contextual cues and general language patterns.
Training that is autoregressive:The autoregressive method used to train the GPT makes the model predict the following word in a sequence by looking at the words that came before it.
Training by Layer:The GPT model's independent training of each layer makes effective parallelization possible.
Two-way Context:GPT leverages bidirectional context understanding, capturing dependencies from both left and right directions, in contrast to previous models that processed text in a unidirectional manner.
Observe the Context:GPT can concentrate on pertinent context when producing text because it uses self-attention mechanisms to assess the relative importance of various words in a sequence.
Generative Pre-trained transformer models
GPT Models: GPT-1: With 117 million parameters, the first version of the GPT model was published.
GPT-2: With 1.5 billion parameters, GPT-2 was a larger model that showed enhanced language generation abilities.
GPT-3: With 175 billion parameters, the GPT-3 model is the most recent and largest in the GPT series. It has been used in many domains and has demonstrated remarkable performance on a variety of language tasks.
Text Production: GPT is well known for its ability to generate text that is coherent and appropriate for the given context in paragraph form.
Comprehension of Language: For tasks like named entity recognition, sentiment analysis, and text classification, GPT can be optimized.
Talking Agents: Conversational agents that can carry on natural language conversations have been created using GPT.
Help with Creative Writing: GPT can help with creative writing assignments by offering ideas and finishing sentences.
Google AI researchers have developed a natural language processing (NLP) model called Text-to-Text Transfer Transformer (T5). T5, which is based on the transformer architecture, is made to be able to tackle a variety of natural language processing tasks by presenting them as text-to-text problems. This is a quick synopsis of T5.
Text-to-Text Organization: T5 presents a single, unified framework that converts all NLP tasks into a text-to-text format. This implies that text sequences are used to handle both input and output for different tasks.
Architecture of Transformers: T5 is based on the transformer architecture, just like BERT and GPT models, and uses self-attention mechanisms to capture contextual relationships in text.
XLNet is a natural language processing (NLP) model that expands on the transformer architecture with the goal of integrating concepts from autoencoding (AE) and autoregressive (AR) techniques to address shortcomings in previous models. Researchers from Carnegie Mellon University and Google Research introduced it. This is a quick synopsis of XLNet.
Modeling Permutation Languages
XLNet presents Permutation Language Modeling (PLM), a novel training objective that combines aspects of auto encoding and autoregressive techniques.
XLNet analyzes all potential permutations of a sequence and predicts the likelihood of each permutation, as opposed to autoregressive models like GPT which predict the next word in a sequence.
Architecture of Transformers:XLNet is based on the transformer architecture, just like BERT and GPT models, and uses self-attention mechanisms to capture contextual relationships in text
Goals for Training: By including both autoregressive and auto encoding tasks during training, XLNet combines the advantages of AR and AE objectives. It computes the probability of the original sequence under the PLM objective using the permuted sequences as training data.
XLNet has improved context capturing and achieved competitive performance on a variety of natural language processing (NLP) tasks, contributing to the development of large-scale language models.
Its integration of permutation language modelling and bidirectional context sets it apart from previous transformer-based models.
from transformers import GPT2LMHeadModel, GPT2Tokenizer # Load pre-trained model and tokenizer model_name = "gpt2"
model = GPT2LM Head Model.from_pretrained(model_name)
tokenizer = GPT2 Tokenizer. from_pretrained(model_name)
# Example input text input_text = "Once upon a time, in a land far, far away, "
# Tokenize input text input_ids = tokenizer.encode(input_text, return_tensors="pt")
# Generate output
output = model.generate(input_ids, max_length=100, num_return_sequences=1, no_repeat_ngram_size=2, top_k=50, top_p=0.95)
# Decode and print generated text
generated_text = tokenizer.decode(output[0], skip_special_tokens=True)
print("Generated Text:\n", generated_text)
Modern pre trained models can be downloaded and trained with ease thanks to Transformers' APIs and tools. By using pre trained models, you can cut down on the time and resources needed to train a model from scratch, as well as your compute costs and carbon footprint
Computer Vision: image classification, object detection, and segmentation; Audio: automatic speech recognition and audio classification.
Natural Language Processing: text classification, named entity recognition, question answering, language modelling, summarization, translation, multiple choice, and text generation.
Multimodal: answering questions at tables, optical character recognition, extracting data from scanned documents, classifying videos, and responding to visual queries.
Transformers facilitate framework interoperability with TensorFlow, PyTorch, and JAX. This gives you the freedom to train a model in three lines of code in one framework, then load it for inference in another, all while using a different framework at different stages of the model's life. For use in production settings, models can also be exported to formats like TorchScript and ONNX.
🚀 Toward the Future: As we give thanks, let's also look forward with hope and excitement. Together, we'll continue to shape the future of AI. where the possibilities are endless.Beyond the numbers, our commitment to data science is unwavering. Making decisions with authority, illuminating trends, and creating stories from the unprocessed data canvas are the main goals. Every dataset has a story waiting to be told, and we have taken on the role of the storytellers.