
Seeing through Events: Real-Time Moving Object Sonification for Visually Impaired People Using Event-Based Camera



Abstract
:1. Introduction
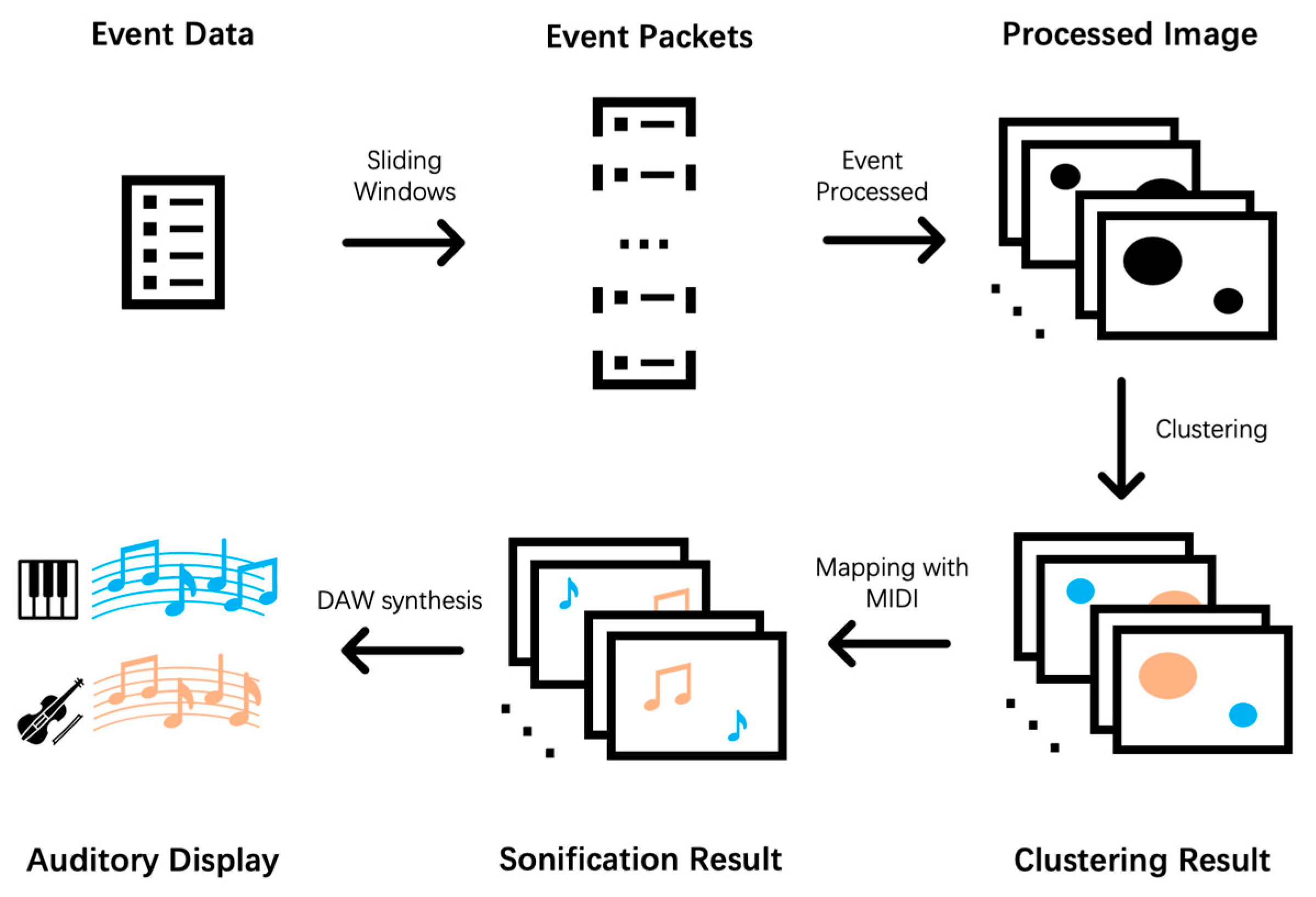
2. Framework
2.1. Tracking Method
2.1.1. Principle of Event-Based Camera
2.1.2. Problem Statement
2.1.3. Adaptive Gaussian Mixture Model
- (1)
- E step. Let denote the Gaussian mixture components of unlabeled data sample , which is an unknown value. According to Bayes’ theorem, the posterior probability of is:
- (2)
- M step. According to the posterior probability calculated in the previous step, we use maximum likelihood estimation to obtain the new GMM parameters. The maximum (logarithmic) likelihood of GMM is shown in the following equation:
2.1.4. Tracking Pipeline
2.2. Sonification Method
2.2.1. Musical Instrument Digital Interface (MIDI)
2.2.2. Mapping Method
- (1)
- Size. We mainly distinguish the relative size of objects based on the timbre. Larger objects use the pad timbre, which usually has a longer attack time and a longer release time [41]. The overall auditory sense is continuous and deep. Smaller objects use the lead timbre, which usually has a shorter attack time and a longer sustain time. Lead always makes auditory sense clear, sharp, and feels a strong sense of crispness.
- (2)
- Speed. The speed of an object is a relative concept. In different scenarios and applications, the definition of fast (slow) speed is different. This work focus on using the sonification method to distinguish between speed types, so the specific value of speed is not the focus of the study. We simply set a speed threshold . When the object’s speed is greater than , the corresponding note of the object appears every 75 ms; that is, the notes are denser. When the object’s speed is less than , a note appears every 150 ms; that is, the notes are sparser.
- (3)
- Abscissa. We linearly map the abscissa of the image plane to the pan value from 0 to 127, as shown in the following equation:where represents the width of the image plane, represents the pan value, and represents the abscissa of the object. The abscissa of the object is the average of all events that make up the object. The pan value calculated by the Equation (10) is the MIDI note pan value generated from the object.
- (4)
- Ordinate. We linearly map the ordinate of the image plane to two octaves from C4 (pitch = 60) to B5 (pitch = 83), as shown in the following equation:where represents the height of the image plane, represents the pitch, and represents the ordinate of the event. The ordinate of the object is the average of all events that make up the object.
2.2.3. New Attributes
2.3. Whole Framework
3. Experiment Settings
3.1. Dataset
- (1)
- Datasets contain scene events due to camera movement.
- (2)
- The scene is relatively complex, such as the number of objects is large, the shape of objects is complex, and objects move in three-dimensional space.
3.2. Participants
3.3. Pre-Experiment
3.4. Training
3.5. Experimental Process
4. Results and Discussion
4.1. Control Group Results
4.2. The Experimental Group 1 Results
4.3. The Experimental Group 2 Results
4.4. Discussion
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bhowmick, A.; Hazarika, S.M. An insight into assistive technology for the visually impaired and blind people: State-of-the-art and future trends. J. Multimodal User Interfaces 2017, 11, 1–24. [Google Scholar] [CrossRef]
- Dakopoulos, D.; Bourbakis, N.G.; Cybernetics, P.C. Wearable obstacle avoidance electronic travel aids for blind: A survey. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2009, 40, 25–35. [Google Scholar] [CrossRef]
- Hu, W.; Wang, K.; Yang, K.; Cheng, R.; Xu, Z.J.S. A Comparative Study in Real-Time Scene Sonification for Visually Impaired People. Sensors 2020, 20, 3222. [Google Scholar] [CrossRef] [PubMed]
- Welsh, R. Foundations of Orientation and Mobility; American Foundation for the Blind: New York, NY, USA, 1981. [Google Scholar]
- Allport, A. Visual attention. In Foundations of Cognitive Science; Posner, M.I., Ed.; MIT Press: Cambridge, MA, USA; London, UK, 1989; pp. 631–682. Available online: https://www.researchgate.net/profile/Gordon-Bower/publication/232500375_Experimental_methods_in_cognitive_science/links/0deec51980ae7df1a3000000/Experimental-methods-in-cognitive-science.pdf (accessed on 16 May 2020).
- Mahowald, M. The silicon retina. In An Analog VLSI System for Stereoscopic Vision; Springer: Berlin/Heidelberg, Germany, 1994; pp. 4–65. [Google Scholar]
- Gallego, G.; Delbruck, T.; Orchard, G.; Bartolozzi, C.; Taba, B.; Censi, A.; Leutenegger, S.; Davison, A.; Conradt, J.; Daniilidis, K.; et al. Event-based vision: A survey. arXiv 2019, arXiv:1904.08405. [Google Scholar] [CrossRef] [PubMed]
- Khan, W.; Ansell, D.; Kuru, K.; Amina, M. Automated aircraft instrument reading using real time video analysis. In Proceedings of the 2016 IEEE 8th International Conference on Intelligent Systems (IS), Sofia, Bulgaria, 4–6 September 2016; pp. 416–420. [Google Scholar]
- Ni, Z.J.; Bolopion, A.; Agnus, J.; Benosman, R.; Régnier, S. Asynchronous Event-Based Visual Shape Tracking for Stable Haptic Feedback in Microrobotics. IEEE Trans. Robot. 2012, 28, 1081–1089. [Google Scholar] [CrossRef] [Green Version]
- Ni, Z.; Ieng, S.-H.; Posch, C.; Régnier, S.; Benosman, R. Visual tracking using neuromorphic asynchronous event-based cameras. Neural Comput. 2015, 27, 925–953. [Google Scholar] [CrossRef] [PubMed]
- Litzenberger, M.; Posch, C.; Bauer, D.; Belbachir, A.N.; Schon, P.; Kohn, B.; Garn, H. Embedded vision system for real-time object tracking using an asynchronous transient vision sensor. In Proceedings of the 2006 IEEE 12th Digital Signal Processing Workshop & 4th IEEE Signal Processing Education Workshop, Teton National Park, WY, USA, 24–27 September 2006; pp. 173–178. [Google Scholar]
- Lagorce, X.; Meyer, C.; Ieng, S.-H.; Filliat, D.; Benosman, R. Asynchronous event-based multikernel algorithm for high-speed visual features tracking. IEEE Trans. Neural Netw. Learn. Syst. 2014, 26, 1710–1720. [Google Scholar] [CrossRef] [PubMed]
- Piątkowska, E.; Belbachir, A.N.; Schraml, S.; Gelautz, M. Spatiotemporal multiple persons tracking using dynamic vision sensor. In Proceedings of the 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Providence, RI, USA, 16–21 June 2012; pp. 35–40. [Google Scholar]
- Glover, A.; Bartolozzi, C. Robust visual tracking with a freely-moving event camera. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 3769–3776. [Google Scholar]
- Stoffregen, T.; Gallego, G.; Drummond, T.; Kleeman, L.; Scaramuzza, D. Event-based motion segmentation by motion compensation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 7244–7253. [Google Scholar]
- Mitrokhin, A.; Fermüller, C.; Parameshwara, C.; Aloimonos, Y. Event-based moving object detection and tracking. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 1–9. [Google Scholar]
- Mitrokhin, A.; Ye, C.; Fermuller, C.; Aloimonos, Y.; Delbruck, T. EV-IMO: Motion segmentation dataset and learning pipeline for event cameras. arXiv 2019, arXiv:1903.07520. [Google Scholar]
- Meijer, P.B. An experimental system for auditory image representations. IEEE Trans. Biomed. Eng. 1992, 39, 112–121. [Google Scholar] [CrossRef] [PubMed]
- Nagarajan, R.; Yaacob, S.; Sainarayanan, G. Role of object identification in sonification system for visually impaired. In Proceedings of the TENCON 2003 Conference on Convergent Technologies for Asia-Pacific Region, Bangalore, India, 15–17 October 2003; pp. 735–739. [Google Scholar]
- Cavaco, S.; Henriques, J.T.; Mengucci, M.; Correia, N.; Medeiros, F.J.P.T. Color sonification for the visually impaired. Procedia Technol. 2013, 9, 1048–1057. [Google Scholar] [CrossRef] [Green Version]
- Yoshida, T.; Kitani, K.M.; Koike, H.; Belongie, S.; Schlei, K. EdgeSonic: Image feature sonification for the visually impaired. In Proceedings of the 2nd Augmented Human International Conference, Tokyo, Japan, 13 March 2011; pp. 1–4. [Google Scholar]
- Banf, M.; Blanz, V. A modular computer vision sonification model for the visually impaired. In Proceedings of the The 18th International Conference on Auditory Display (ICAD2012), Atlanta, Georgia, 18–22 June 2012. [Google Scholar]
- Barrass, S.; Kramer, G. Using sonification. Multimed. Syst. 1999, 7, 23–31. [Google Scholar] [CrossRef]
- Dubus, G.; Bresin, R. A systematic review of mapping strategies for the sonification of physical quantities. PLoS ONE 2013, 8, e82491. [Google Scholar] [CrossRef] [PubMed]
- Khan, W.; Hussain, A.; Khan, B.; Nawaz, R.; Baker, T. Novel framework for outdoor mobility assistance and auditory display for visually impaired people. In Proceedings of the 2019 12th International Conference on Developments in eSystems Engineering (DeSE), Kazan, Russia, 7–10 October 2019; pp. 984–989. [Google Scholar]
- Constantinescu, A.; Müller, K.; Haurilet, M.; Petrausch, V.; Stiefelhagen, R. Bring the Environment to Life: A Sonification Module for People with Visual Impairments to Improve Situation Awareness. In Proceedings of the 2020 International Conference on Multimodal Interaction, Utrecht, The Netherlands, 25–29 October 2020; pp. 50–59. [Google Scholar]
- Wang, J.; Yang, K.; Hu, W.; Wang, K. An environmental perception and navigational assistance system for visually impaired persons based on semantic stixels and sound interaction. In Proceedings of the 2018 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Miyazaki, Japan, 7–10 October 2018; pp. 1921–1926. [Google Scholar]
- Presti, G.; Ahmetovic, D.; Ducci, M.; Bernareggi, C.; Ludovico, L.; Baratè, A.; Avanzini, F.; Mascetti, S. WatchOut: Obstacle sonification for people with visual impairment or blindness. In Proceedings of the 21st International ACM SIGACCESS Conference on Computers and Accessibility, Pittsburgh, PA, USA, 28–30 October 2019; pp. 402–413. [Google Scholar]
- Yang, K.; Wang, K.; Bergasa, L.M.; Romera, E.; Hu, W.; Sun, D.; Sun, J.; Cheng, R.; Chen, T.; López, E. Unifying terrain awareness for the visually impaired through real-time semantic segmentation. Sensors 2018, 18, 1506. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kaul, O.B.; Behrens, K.; Rohs, M. Mobile Recognition and Tracking of Objects in the Environment through Augmented Reality and 3D Audio Cues for People with Visual Impairments. In Proceedings of the Extended Abstracts of the 2021 CHI Conference on Human Factors in Computing Systems (CHI EA ’21), New York, NY, USA, 8–13 May 2021; Article 394. pp. 1–7. [Google Scholar] [CrossRef]
- Ahmetovic, D.; Avanzini, F.; Baratè, A.; Bernareggi, C.; Galimberti, G.; Ludovico, L.A.; Mascetti, S.; Presti, G. Sonification of pathways for people with visual impairments. In Proceedings of the 20th International ACM SIGACCESS Conference on Computers and Accessibility, Galway, Ireland, 22–24 October 2018; pp. 379–381. [Google Scholar]
- Skulimowski, P.; Owczarek, M.; Radecki, A.; Bujacz, M.; Rzeszotarski, D.; Strumillo, P. Interactive sonification of U-depth images in a navigation aid for the visually impaired. J. Multimodal User Interfaces 2019, 13, 219–230. [Google Scholar] [CrossRef] [Green Version]
- Jeon, M.; Winton, R.J.; Yim, J.-B.; Bruce, C.M.; Walker, B.N. Aquarium fugue: Interactive sonification for children and visually impaired audience in informal learning environments. In Proceedings of the 18th International Conference on Auditory Display, Atlanta, GA, USA, 18–21 June 2012. [Google Scholar]
- Walker, B.N.; Godfrey, M.T.; Orlosky, J.E.; Bruce, C.; Sanford, J. Aquarium sonification: Soundscapes for accessible dynamic informal learning environments. In Proceedings of the 12th International Conference on Auditory Display, London, UK, 20–23 June 2006. [Google Scholar]
- Walker, B.N.; Kim, J.; Pendse, A. Musical soundscapes for an accessible aquarium: Bringing dynamic exhibits to the visually impaired. In Proceedings of the ICMC, Copenhagen, Denmark, 27–31 August 2007. [Google Scholar]
- Reynolds, D.A. Gaussian Mixture Models. Encycl. Biom. 2009, 741, 659–663. [Google Scholar]
- Christensen, T. The Cambridge History of Western Music Theory; Cambridge University Press: Cambridge, UK, 2006. [Google Scholar]
- Hermann, T.; Hunt, A.; Neuhoff, J.G. The Sonification Handbook; Logos: Berlin, Germany, 2011. [Google Scholar]
- Kramer, G. Auditory Display: Sonification, Audification and Auditory Interfaces; Addison-Wesley Longman Publishing Co., Inc.: Boston, MA, USA, 2000. [Google Scholar]
- Moog, R.A. Midi: Musical instrument digital interface. J. Audio Eng. Soc. 1986, 34, 394–404. [Google Scholar]
- Sethares, W.A. Tuning, Timbre, Spectrum, Scale; Springer Science & Business Media: New York, NY, USA, 2005. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Note Pitch | Note Density | Pan | Pedal | Instrument | Poly-Phony | ||
|---|---|---|---|---|---|---|---|
| Appearance attributes | Size | √ | |||||
| New attribute | √ | √ | |||||
| Motion attributes | Speed | √ | |||||
| Abscissa | √ | ||||||
| Ordinate | √ |
| Attributes No. | 1 (CC #1) | 2 (CC #64) | 3 (CC #91) | 4 (CC #93) | 5 |
|---|---|---|---|---|---|
| Attributes Name | Vibrato | Pedal | Reverb | Chorus | Polyphony |
| Experimental Group 1 No. | Description: Lead with New Attributes | Experimental Group 2 No. | Description: Pad with New Attributes | Control Group |
|---|---|---|---|---|
| 1-1 | Lead with vibrato | 2-1 | Pad with vibrato | monophonic with no new attributes |
| 1-2 | Lead with pedal | 2-2 | Pad with pedal | |
| 1-3 | Lead with reverb | 2-3 | Pad with reverb | |
| 1-4 | Lead with chorus | 2-4 | Pad with chorus | |
| 1-5 | Lead with polyphony | 2-5 | Pad with polyphony |
| 1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|
| Experimental Group 1 | 30.0% | 10.0% | 0 | 0 | 60.0% |
| Experimental Group 2 | 22.5% | 72.5% | 0 | 0 | 5.0% |
| Sonification Method | Appearance Attributes Contained | |
|---|---|---|
| Control Group | Ours | Object Size |
| Experimental Group 1 | Ours | Object Size and Object Width |
| Experimental Group 2 | Hu [3] | Object Size |
| Objective Questions | Single_Q1 | Multiple_Q1 | Single_Q2 | Multiple_Q2 |
|---|---|---|---|---|
| SP | 99.0% | 98.6% | 94.8% | 80.6% |
| VIP | 100.0% | 100.0% | 96.4% | 78.6% |
| Objective Questions | Single_Q1 | Multiple_Q1 | Single_Q2 | Multiple_Q2 | Single_Q3 | Multiple_Q3 |
|---|---|---|---|---|---|---|
| Control Group | 99.5% | 99.3% | 95.6% | 79.6% | / | / |
| Experimental Group 1 | 100.0% | 72.2% | 88.9% | 55.6% | 72.2% | 38.9% |
| Experimental Group 2 | 66.7% | 77.8% | 61.1% | 44.4% | / | / |
| Subjective Questions | Q1 | Q2 | Q4 | Q5 | Q6 | |
|---|---|---|---|---|---|---|
| Control Group | Single | 6.509 | 5.72 | 5.684 | 5.938 | 6.142 |
| Multiple | 6.175 | 5.314 | 5.371 | 5.54 | 5.671 | |
| Experimental Group 1 | Single | 6.111 | 5.611 | 5.556 | 6.278 | 5.722 |
| Multiple | 5.667 | 4.944 | 5.056 | 6.111 | 5.333 | |
| Experimental Group 2 | Single | 5.667 | 4.556 | 4.833 | 5.833 | 5.111 |
| Multiple | 4.833 | 3.611 | 3.722 | 5.111 | 3.833 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ji, Z.; Hu, W.; Wang, Z.; Yang, K.; Wang, K. Seeing through Events: Real-Time Moving Object Sonification for Visually Impaired People Using Event-Based Camera. Sensors 2021, 21, 3558. https://doi.org/10.3390/s21103558
Ji Z, Hu W, Wang Z, Yang K, Wang K. Seeing through Events: Real-Time Moving Object Sonification for Visually Impaired People Using Event-Based Camera. Sensors. 2021; 21(10):3558. https://doi.org/10.3390/s21103558
Chicago/Turabian StyleJi, Zihao, Weijian Hu, Ze Wang, Kailun Yang, and Kaiwei Wang. 2021. "Seeing through Events: Real-Time Moving Object Sonification for Visually Impaired People Using Event-Based Camera" Sensors 21, no. 10: 3558. https://doi.org/10.3390/s21103558
APA StyleJi, Z., Hu, W., Wang, Z., Yang, K., & Wang, K. (2021). Seeing through Events: Real-Time Moving Object Sonification for Visually Impaired People Using Event-Based Camera. Sensors, 21(10), 3558. https://doi.org/10.3390/s21103558