Novel Multi-Level Dynamic Traffic Load-Balancing Protocol for Data Center

 , , , ,
, , , ,
Abstract
:1. Introduction
2. Background
- Per packet: Can be used for the best load balance; however, due to the higher reordering, there are chances to attain insignificant reordering.
- Flowlets: Due to the variation of the candidate path latencies, the flowlet’s size changes enthusiastically. If the latency rates are higher, the flowlets become large. It is obvious that it applies per packet and per flow technique. Therefore, the load balancing is then fine as well as coarse-grained. As a result, the flowlets become promising in load balancing for asymmetric paths. Nevertheless, the flowlets causes a small flow reordering, which can interrupt the execution times.
- Per flow cell: It uses the fixed size with the consideration of tens of packets. The most positive effect of per flow cell is that it uses simplified load balancing to reduce the possible reordering of small flows. However, it rises the reordering for larger flows, which can be fragmented into several flow cells.
3. Motivation of the Study
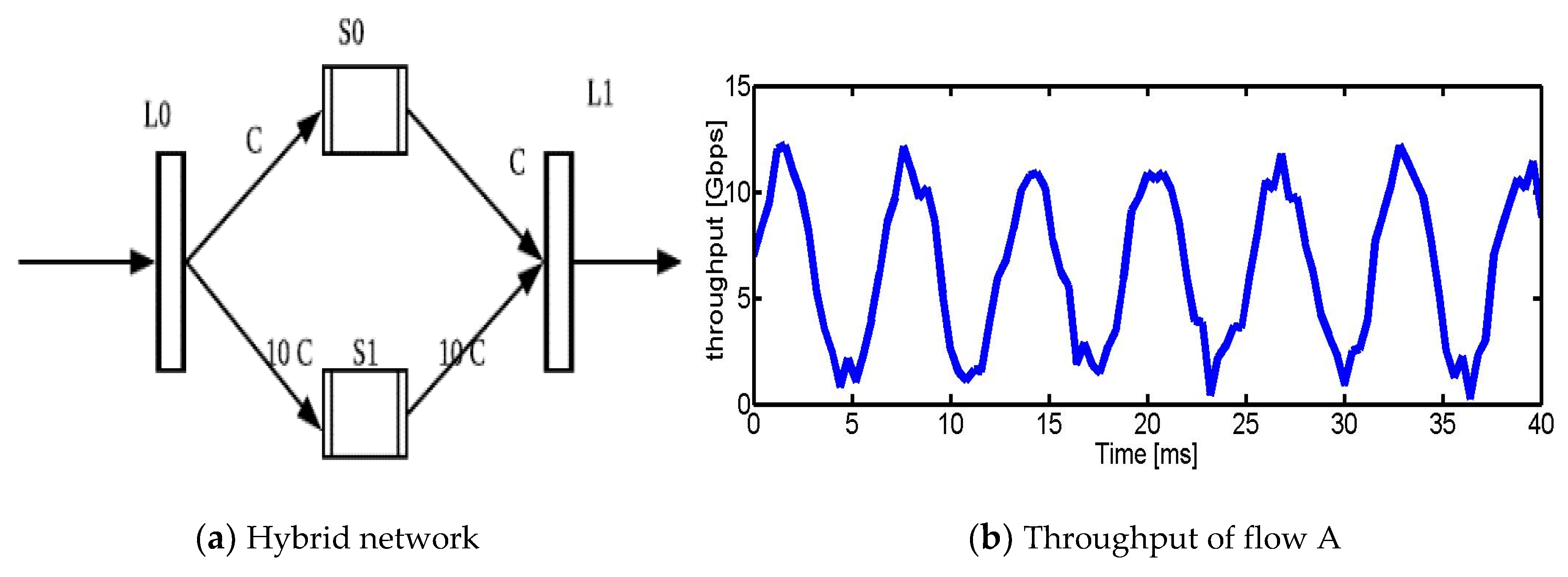
3.1. Congestion Mismatch Problem with an Example
3.2. Summary
4. Proposed Multi-Level Traffic Load Balancing MDTLB
4.1. Basic Concept
4.2. Design Considerations
4.2.1. Parameters
4.2.2. Adaptive Parameters Settings
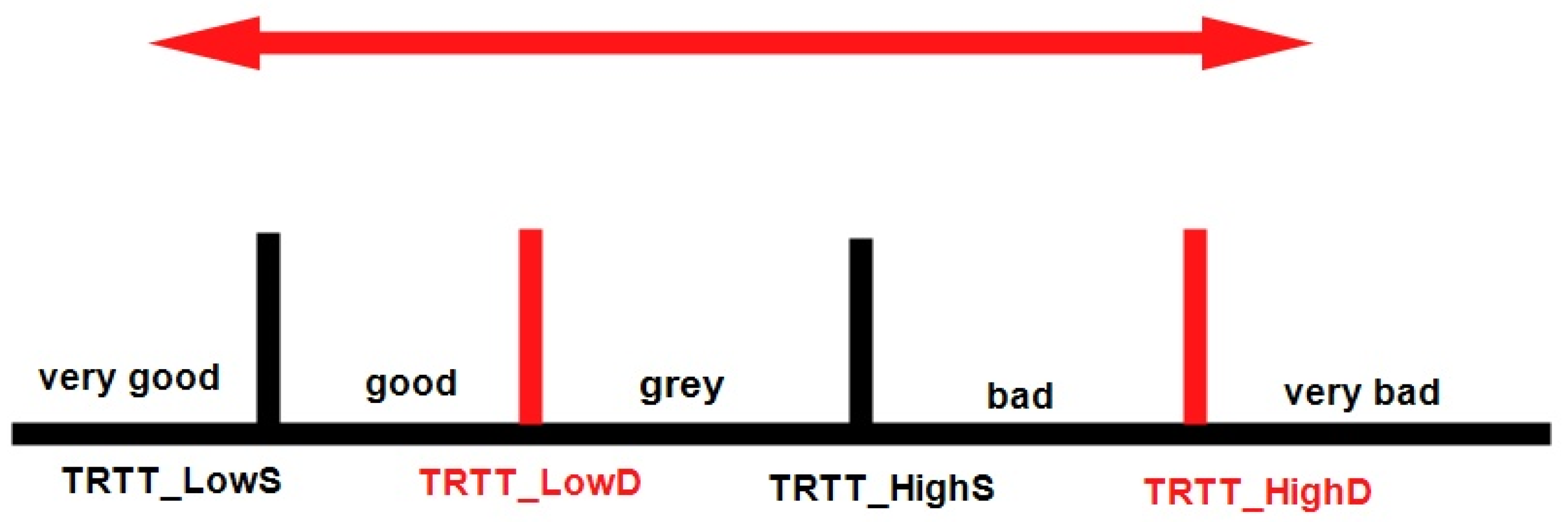
- The first is to increase the number of path levels to give the scheme more awareness of the path’s status. Hence, the path is divided into five types {very good, good, gray, bad, and very bad}, as shown in Figure 4.
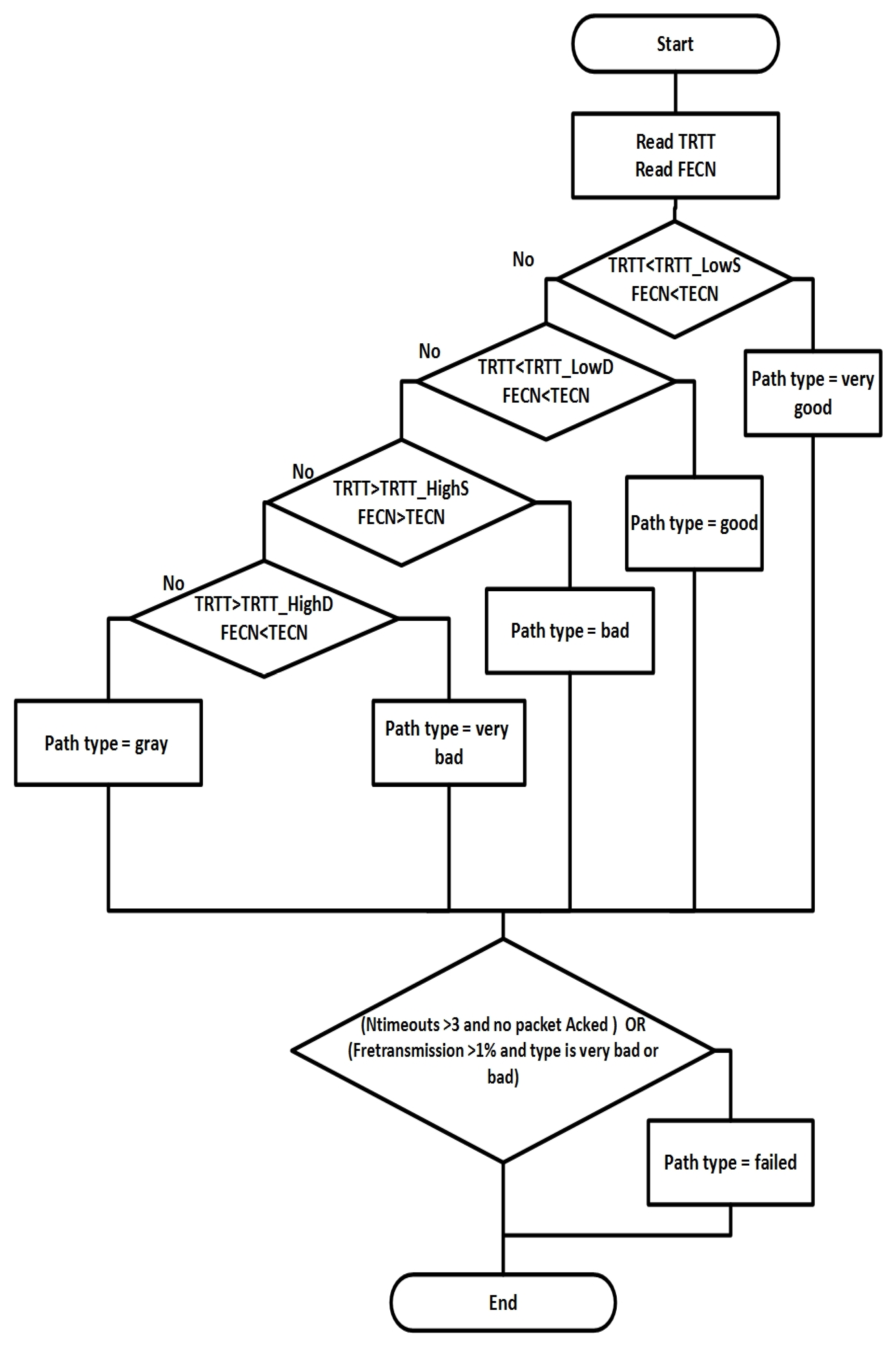
- The second step is to make the judging dynamic by introducing static and dynamic TRTT thresholds, as shown in Figure 5 and pseudocode one. The user sets the static thresholds, while the dynamic thresholds are set by the system using an adaptive way to determine the best threshold value based on the network load. It is important to note that TRTT can be used as the main judging thresholds. This is because the measurements of TRTT are more accurate and can give a wider range than TECN to distinguish between path levels.
| 1. for each path p do: 2. if fECN < T ECN and TRTT < then type = very good 3. else if fECN < T ECN and TRTT < then type = good 4. else if fECN > T ECN and TRTT > then type = bad 5. else if fECN >T ECN and TRTT > then type = very bad 6. else type = gray 7. if ( > 3 and no packet is ACKed) or ( > 1% and type ≠ bad or very bad), then type = failed end for |
| If (good portion is small) or (good portion is medium and bad portion is big) or (good portion is big and bad portion is big) then changeRatio = ChangeRatio + 10 Else if ( good portion is big and bad portion is not big ) then changeRatio = ChangeRatio − 10 End |
4.2.3. Rerouting Logic
| 1. for every packet do 2. Assume its corresponding flow is f and path is p 3. if f is a new flow or f.iftimeout ==true or ptype == failed then 4. {p’} = all very good paths 5. if {p’} ≠ ɸ then 6. P* = ArgminpЄ{p’}(p.rp) /* Select a very good path with the smallest local sending rate/* 7. else 8. {p"} = all good paths 9. if {p"} ≠ ɸ then 10. P* = ArgminpЄ{p"}(p.rp) /* Select a good path with the smallest local sending rate */ else 11. {p"’} = all gray paths 12. if {p"’} ≠ ɸ then 13. p* = ArgminpЄ{p"’}(p.rp) 14. else 15. p* = a randomly selected path with no failure 16. else if p:type == very bad then 17. if f.ssent < S and f.rf < R then 18. {P’} = all very good paths notably better than p 19. / ∀p’Є {P’}, we have p.tRTT – p’.tRTT > and p.fECN – p’.fECN > */ 20. if {p’} ≠ ɸ then 21. P* = ArgminpЄ{p’}(p.rp) 22. else 23. {p"} = all good paths notably better than p 24. if {p"} ≠ ɸ then 25. P* = ArgminpЄ{p"}(p.rp) 26. /* Select a good path with the smallest local sending rate */ 27. else 28. {p"’} = all gray paths notably better than p 29. if {p"’} ≠ ɸ then 30. p* = Argmin pЄ{p"’}(p.rp) 31. else 32. p = p /* Do not reroute */ 33. return p* /* The new routing path */ |
4.2.4. Example of Proposed Scheme
- Flow A started; the status of paths is unknown, so they are grey; the portion of good paths equals the portion of bad paths (0), so no need to change the dynamic thresholds, and our routing logic will choose any of the paths, let us say P1.
- Flow B started; the judging of paths will be bad for P1 due to traffic and grey for P2; the routing logic will choose P2; the portion of bad paths is greater than the portion of good paths, so the dynamic threshold should be increased by 10%.
- Flow C started and due to the change of the dynamic threshold from the previous step, the judging logic will be good for P1 and bad for P2; as a result, the routing logic will choose P1, and the portion of good paths equals the portion of bad paths, so no need to change the dynamic thresholds.
- Flow D started, the judging logic will be bad for P1 and P2; the routing logic will choose either P1 or P2, let us say P1; the portion of bad paths is greater than the portion of good paths, so the dynamic thresholds should be increased by 10%.
- Flow E started, and due to the change of dynamic thresholds from the previous step, the judging logic will be very bad for P1 and good for P2; the routing logic will choose P2, and the portion of good paths equals the portion of bad paths, so no need to change the dynamic thresholds.
- Flow F started, the judging logic will be very bad for P1 and bad for P2; the routing logic will choose P2, the portion of bad paths is greater than the portion of good paths, so the dynamic thresholds should be increased by 10%.
- Flow G started, and due to the change of dynamic threshold from the previous step, the judging logic will be very good for P1 and good for P2; the routing logic will choose P1, and the portion of bad paths is smaller than the portion of good paths, so the dynamic thresholds should decrease by 10%.
- Flow H started, and due to the change of dynamic threshold from the previous step, the judging logic will be good for P1 and good for P2; the routing logic will chose either P1 or P2, let us say P2; the portion of bad paths is smaller than the portion of good paths, so the dynamic thresholds should decrease by 10%.
- Flow I started, and the judging logic will be good for P1 and bad for P2; thus, the routing logic will choose P1, and the portion of good paths equals to the portion of bad paths, so no need to change the dynamic thresholds.
5. Results and Discussion
6. Related Work
7. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Greenberg, A.; Hamilton, J.; Maltz, D.A.; Patel, P. The cost of a cloud: Research problems in data center networks. ACM SIGCOMM Comput. Commun. Rev. 2008, 39, 68–73. [Google Scholar] [CrossRef]
- Singh, A.; Korupolu, M.; Mohapatra, D. Server-storage virtualization: Integration and load balancing in data centers. In Proceedings of the 2008 ACM/IEEE Conference on Supercomputing, Austin, TX, USA, 21 November 2008; p. 53. [Google Scholar]
- Dillon, T.; Wu, C.; Chang, E. Cloud computing: Issues and challenges. In Proceedings of the Advanced Information Networking and Applications (AINA), Perth, Australia, 20–13 April 2010; pp. 27–33. [Google Scholar]
- Grossman, R.L. The case for cloud computing. IT Prof. 2009, 11, 23–27. [Google Scholar] [CrossRef]
- Chappell, D. Introducing the Windows Azure Platform. Available online: https://www.google.com.tw/url?sa=t&rct=j&q=&esrc=s&source=web&cd=2&ved=2ahUKEwjEk-fjjpDgAhWaa94KHTC-CUEQFjABegQICRAC&url=http%3A%2F%2Fwww.davidchappell.com%2Fwriting%2Fwhite_papers%2FIntroducing_the_Windows_Azure_Platform%2C_v1.4--Chappell.pdf&usg=AOvVaw3BMon_jPUkscNOo26bp5nL (accessed on 16 December 2018).
- Kannan, L.N.; Zeto, R.W.; Chen, L.; Xu, F.; Jalan, R. System and method to balance servers based on server load status. United States Patent U.S. 9,215,275, 15 December 2015. [Google Scholar]
- Cao, J.; Xia, R.; Yang, P.; Guo, C.; Lu, G.; Yuan, L.; Zheng, Y.; Wu, H.; Xiong, Y.; Maltz, D. Per-packet load-balanced, low-latency routing for clos-based data center networks. In Proceedings of the Ninth ACM Conference on Emerging Networking Experiments and Technologies, Santa Barbara, CA, USA, 9–12 December 2013; pp. 49–60. [Google Scholar]
- Shafiee, M.; Ghaderi, J. A simple congestion-aware algorithm for load balancing in datacenter networks. IEEE/ACM Trans. Netw. 2017, 25, 3670–3682. [Google Scholar] [CrossRef]
- Shi, Q.; Wang, F.; Feng, D.; Xie, W. ALB: Adaptive Load Balancing Based on Accurate Congestion Feedback for Asymmetric Topologies; IEEE/ACM: Banff, AB, Canada, 2018. [Google Scholar]
- Noormohammadpour, M.; Raghavendra, C.S. Datacenter Traffic Control: Understanding Techniques and Tradeoffs. IEEE Commun. Surv. Tutor. 2017, 20, 1492–1525. [Google Scholar] [CrossRef]
- He, K.; Rozner, E.; Agarwal, K.; Felter, W.; Carter, J.; Akella, A. Presto: Edge-based load balancing for fast datacenter networks. In Proceedings of the 2015 ACM Conference on Special Interest Group on Data Communication, New York, NY, USA, 17–21 2015 August; Volume 45, pp. 465–478. [Google Scholar]
- Alizadeh, M.; Edsall, T.; Dharmapurikar, S.; Vaidyanathan, R.; Chu, K.; Fingerhut, A.; Matus, F.; Pan, R.; Yadav, N.; Varghese, G. CONGA: Distributed congestion-aware load balancing for datacenters. In Proceedings of the 2014 ACM conference on SIGCOMM, New York, NY, USA, 17–22 August 2014; Volume 44, pp. 503–514. [Google Scholar]
- Katta, N.; Hira, M.; Kim, C.; Sivaraman, A.; Rexford, J. Hula: Scalable load balancing using programmable data planes. In Proceedings of the Symposium on SDN Research ACM, Santa Clara, CA, USA, 14 March 2016; p. 10. [Google Scholar]
- Zhang, H.; Zhang, J.; Bai, W.; Chen, K.; Chowdhury, M. Resilient datacenter load balancing in the wild. In Proceedings of the Conference of the ACM Special Interest Group on Data Communication, Los Angeles, CA, USA, 21–25 August 2017; pp. 253–266. [Google Scholar]
- Huang, J.; Huang, Y.; Wang, J.; He, T. Adjusting Packet Size to Mitigate TCP Incast in Data Center Networks with COTS Switches. IEEE Trans. Cloud Comput. 2018. [Google Scholar] [CrossRef]
- Ruan, C.; Wang, J.; Jiang, W.; Huang, J.; Min, G.; Pan, Y. FSQCN: Fast and Simple Quantized Congestion Notification in Data Center Ethernet. J. Netw. Comput. Appl. 2017, 83, 53–62. [Google Scholar] [CrossRef]
- Zhang, T.; Wang, J.; Huang, J.; Chen, J.; Pan, Y.; Min, G. Tuning the aggressive TCP behavior for highly concurrent HTTP connections in intra-datacenter. IEEE/ACM Trans. Netw. 2017, 25, 3808–3822. [Google Scholar] [CrossRef]
- Wang, P.; Xu, H.; Niu, Z.; Han, D.; Xiong, Y.; Wang, P.; Xu, H.; Niu, Z.; Han, D.; Xiong, Y. Expeditus: Congestion-Aware Load Balancing in Clos Data Center Networks. IEEE/ACM Trans. Netw. (TON) 2017, 25, 3175–3188. [Google Scholar] [CrossRef]
- Vanini, E.; Pan, R.; Alizadeh, M.; Taheri, P.; Edsall, T. Let It Flow: Resilient Asymmetric Load Balancing with Flowlet Switching. In Proceedings of the NSDI, Boston, MA, USA, 27–29 March 2017; pp. 407–420. [Google Scholar]
- Dong, P.; Yang, W.; Tang, W.; Huang, J.; Wang, H.; Pan, Y.; Wang, J. Reducing transport latency for short flows with multipath TCP. J. Netw. Comput. Appl. 2018, 108, 20–36. [Google Scholar] [CrossRef]
- Bonaventure, O.; Paasch, C.; Detal, G. Use Cases and Operational Experience with Multipath TCP. Available online: https://inl.info.ucl.ac.be/publications/use-cases-and-operational-experience-multipath-tcp.html (accessed on 16 December 2018).
- Iwasaki, Y.; Ono, S.; Saruwatari, S.; Watanabe, T. Design and Implementation of OpenFlow Networks for Medical Information Systems. In Proceedings of the IEEE Global Communications Conference, Singapore, 4–8 December 2017; pp. 1–7. [Google Scholar]
- Frömmgen, A.; Rizk, A.; Erbshäußer, T.; Weller, M.; Koldehofe, B.; Buchmann, A.; Steinmetz, R. A programming model for application-defined multipath TCP scheduling. In Proceedings of the 18th ACM/IFIP/USENIX Middleware Conference, Las Vegas, NV, USA, 11–15 December 2017; pp. 134–146. [Google Scholar]
- Vo, P.L.; Le, T.A.; Tran, N.H. mFAST: A Multipath Congestion Control Protocol for High Bandwidth-Delay Connection. Mob. Netw. Appl. 2018, 1–9. [Google Scholar] [CrossRef]
- Ghorbani, S.; Yang, Z.; Godfrey, P.; Ganjali, Y.; Firoozshahian, A. DRILL: Micro load balancing for low-latency data center networks. In Proceedings of the Conference of the ACM Special Interest Group on Data Communication, Los Angeles, CA, USA, 21–25 August 2017; pp. 225–238. [Google Scholar]
- Kabbani, A.; Vamanan, B.; Hasan, J.; Duchene, F. Flowbender: Flow-level adaptive routing for improved latency and throughput in datacenter networks. In Proceedings of the 10th ACM International on Conference on emerging Networking Experiments and Technologies, Sydney, Australia, 2–5 December 2014; pp. 149–160. [Google Scholar]
- Dixit, A.; Prakash, P.; Hu, Y.C.; Kompella, R.R. On the impact of packet spraying in data center networks. In Proceedings of the INFOCOM, Turin, Italy, 14–19 April 2013; pp. 2130–2138. [Google Scholar]
- Katta, N.; Hira, M.; Ghag, A.; Kim, C.; Keslassy, I.; Rexford, J. CLOVE: How I learned to stop worrying about the core and love the edge. In Proceedings of the 15th ACM Workshop on Hot Topics in Networks, Atlanta, GA, USA, 9–10 November 2016; pp. 155–161. [Google Scholar]
- Carpio, F.; Engelmann, A.; Jukan, A. DiffFlow: Differentiating short and long flows for load balancing in data center networks. arXiv, 2016; preprint. arXiv:1604.05107. [Google Scholar]
- Wang, S.; Zhang, J.; Huang, T.; Pan, T.; Liu, J.; Liu, Y. Flow distribution-aware load balancing for the datacenter. Comput. Commun. 2017, 106, 136–146. [Google Scholar] [CrossRef]
- Cheung, C.M.; Leung, K.C. DFFR: A flow-based approach for distributed load balancing in Data Center Networks. Comput. Commun. 2018, 116, 1–8. [Google Scholar] [CrossRef]
- Olteanu, V.; Agache, A.; Voinescu, A.; Raiciu, C. Stateless datacenter load-balancing with beamer. In Proceedings of the 15th USENIX Symposium on Networked Systems Design and Implementation (NSDI), Renton, WA, USA, 9–11 April 2018; Volume 18, pp. 125–139. [Google Scholar]
- Wang, P.; Trimponias, G.; Xu, H.; Geng, Y. Luopan: Sampling-Based Load Balancing in Data Center Networks. IEEE Trans. Parallel Distrib. Syst. 2019, 30, 133–145. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Flow Level Variable | Meaning |
|---|---|
| Set if the flow experiences a timeout | |
| Size sent from the flow | |
| Number of times out that the flow experiences | |
| Sending rate of the flow |
| Path level variable | Meaning |
|---|---|
| Number of timeout events of path | |
| Fraction of retransmission events of path | |
| Type | Path condition |
| Threshold for Fraction of ECN | |
|---|---|
| Static Threshold for low RTT, | |
| Static Threshold for high RTT | |
| Dynamic Threshold for low RTT | |
| Dynamic Threshold for high RTT | |
| Threshold for notably better RTT | |
| Threshold for notably better ECN fraction |
| Events | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|
| Flow | A | B | C | D | E | F | G | H | I |
| P1 type | Grey | Bad | Good | Bad | Very Bad | Very Bad | Very Good | Good | Good |
| P2 type | Grey | Gray | Bad | Bad | Good | Bad | Good | Good | Bad |
| chosen path | P1 | P2 | P1 | P1 | P2 | P2 | P1 | P2 | P1 |
| Dynamic thresholds | No change | +10% | No change | +10% | No change | +10% | −10% | −10% | No change |
| Values | Parameters |
|---|---|
| runMode | MDTLB, TLB (Hermes), Conga, Presto, DRB, ECMP, Clove, DRILL, LetFlow |
| transportProt | Tcp |
| enableLargeDupAck | False |
| enableLargeSynRetries | False |
| enableFastReConnection | False |
| enableLargeDataRetries | False |
| For each leaf serverCount | 8 |
| spineCount | 4 |
| leafCount | 4 |
| linkCount | 1 |
| spineLeafCapacity | 10 |
| leafServerCapacity | 10 Gbps |
| linkLatency | 10 us |
| cdfFileName | data mining: VL2_CDF, web search: DCTCP_CDF, general flows: (VL2_DF + DCTCP_CDF)/2 |
| load | [0.3, 0.5, 0.7, 0.9] |
| MDTLBMinRTTS | 40 us |
| MDTLBHighRTTS | 180 us |
| Initial MDTLBMinRTTD | 40 us |
| Initial MDTLBHighRTTD | 180 us |
| MDTLBBetterPathRTT | 1 us |
| MDTLBT1 | 100 us |
| MDTLBECNPortionLow | 0.1 |
| MDTLBProbingEnable | True |
| MDTLBProbingInterval | 50 us |
| MDTLBSmooth | True |
| MDTLBRerouting | True |
| MDTLBS | 64,000 byte |
| MDTLBReverseACK | True |
| quantifyRTTBase | 10 |
| MDTLBFlowletTimeout | 5 ms |
| Chemes | Sensing Uncertainties | Reacting to Uncertainties | Advanced Hardware | Sensitivity to Parameter Settings | Evaluation Method | ||
|---|---|---|---|---|---|---|---|
| Congestion | Switch Failure | Minimum Switchable Unit | Switching Method and Frequency | ||||
| Presto [11] | Oblivious | Oblivious | Flow cell (Fixed-sized unit) | Per-flow cell round robin | No | No | Real physical network |
| DRB [7] | Oblivious | Oblivious | Packet | Per-packet round robin | No | No | NS-3 with testbed real physical network |
| LetFLow [19] | Oblivious | Oblivious | Flowlet | Per-flowlet random hashing | Yes | No | NS-3 |
| DRILL [25] | Local awareness (Switch) | Oblivious | Packet | Per-packet rerouting (according to local congestion) | Yes | No | OMNET++ Simulator |
| CONGA [12] | Global awareness (Switch) | Oblivious | Flowlet | Per-flowlet rerouting (according to global congestion) | Yes | No | Based on OMNET++ Simulator and real hardware testbed |
| HULA [13] | Global awareness (Switch) | Oblivious | Flowlet | Per-flowlet rerouting (according to global congestion) | Yes | No | NS-2 Simulator |
| FlowBender [26] | Global awareness (End host) | Oblivious | packet | Reactive and random rerouting (when congested) | No | No | NS-3 and real physical testbed |
| CLOVE-ECN [28] | Global awareness (End host) | Oblivious | Flowlet | Flowlet Per-flowlet weighted round robin (according to global congestion) | No | No | NS-2 |
| Hermes [14] | Global awareness (End host) | Aware | Packet | Timely yet cautious rerouting (based on global congestion and failure) | No | No | NS-3 |
| MDTLB | Global awareness (End host) | Aware | Packet | Rerouting logic (based on global congestion and failure) and path judging | No | Yes | NS-3 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Memon, S.; Huang, J.; Saajid, H.; Khuda Bux, N.; Saleem, A.; Aljeroudi, Y. Novel Multi-Level Dynamic Traffic Load-Balancing Protocol for Data Center. Symmetry 2019, 11, 145. https://doi.org/10.3390/sym11020145
Memon S, Huang J, Saajid H, Khuda Bux N, Saleem A, Aljeroudi Y. Novel Multi-Level Dynamic Traffic Load-Balancing Protocol for Data Center. Symmetry. 2019; 11(2):145. https://doi.org/10.3390/sym11020145
Chicago/Turabian StyleMemon, Sheeba, Jiawei Huang, Hussain Saajid, Naadiya Khuda Bux, Arshad Saleem, and Yazan Aljeroudi. 2019. "Novel Multi-Level Dynamic Traffic Load-Balancing Protocol for Data Center" Symmetry 11, no. 2: 145. https://doi.org/10.3390/sym11020145