Dual Attention-Guided Multiscale Dynamic Aggregate Graph Convolutional Networks for Skeleton-Based Human Action Recognition



Abstract
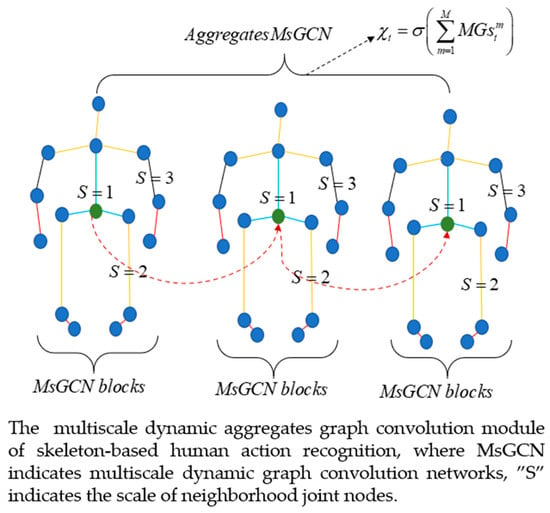
:
1. Introduction
- (1)
- We propose a dual attention-guided multiscale dynamic aggregate graph convolutional network for skeleton-based human action recognition. We aim to explore the importance of joint semantics and enhance the dependencies between the semantics of different modules.
- (2)
- The proposed DAG-GCN uses a node-level module and guided-level module to hierarchically mine the spatial-temporal correlation of frames and strengthen the semantic dependency between them.
- (3)
- The node-level module performs multilayer graph convolution, which captures the position and velocity information of bone joints through the graph nodes. This information passes through the multilayer transmission to constitute the deep-layer semantics of bone joints. The guided-level module is composed of positional attention and channel attention, and this module refines the joint semantics step-by-step and establishes and strengthens the dependencies between frames.
2. Related Work
3. Dual Attention-Guided Dynamic Aggregate Graph Convolution
3.1. Multi-Scale Dynamic Aggregates
3.2. Guided-Level Module
4. Experimental Results and Analysis
4.1. Datasets
4.2. Training and Implementation Details
4.3. Ablation Experiments
4.3.1. Ablation Study on the Proposed Node Module
4.3.2. Comparison to the State-of-the-Art
4.3.3. Performance of the Guided-Level Module
4.3.4. Visualization of the Recognition Results
5. Conclusions and Next Research Works
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| DAG-GCNs | dual attention-guided multi-scale dynamic aggregate graph convolutional networks |
| GL | guided-level module |
| BJL | bone joint-level module |
| NG | non-graph |
References
- Kerdvibulvech, C. A Review of Augmented Reality-Based Human-Computer Interaction Applications of Gesture-Based Interaction. In Proceedings of the International Conference on Human-Computer Interaction, Orlando, FL, USA, 26–31 July 2019; Springer: Cham, Switzerland, 2019; pp. 233–242. [Google Scholar]
- Zhang, K.; Sun, H.; Shi, W.; Feng, Y.; Jiang, Z.; Zhao, J. A Video Representation Method Based on Multi-view Structure Preserving Embedding for Action Retrieval. IEEE Access 2019, 7, 50400–50411. [Google Scholar] [CrossRef]
- Hassan, M.M.; Ullah, S.; Hossain, M.S.; Alelaiwi, A. An end-to-end deep learning model for human activity recognition from highly sparse body sensor data in Internet of Medical Things environment. J. Supercomput. 2008, 10, 142–149. [Google Scholar]
- Cao, Z.; Martinez, G.H.; Simon, T.; Wei, S.E.; Sheikh, Y.A. Open Pose: Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 99, 1. [Google Scholar]
- Song, S.; Lan, C.; Xing, J.; Zeng, W.; Liu, J. Skeleton-Indexed Deep Multi-Modal Feature Learning for High Performance Human Action Recognition. In Proceedings of the 2018 IEEE International Conference on Multimedia and Expo (ICME), San Diego, CA, USA, 23–27 July 2018; pp. 1–6. [Google Scholar]
- Han, F.; Reily, B.; Hoff, W.; Zhang, H. Space-time representation of people based on 3D skeletal data. Comput. Vis. Image Underst. 2017, 158, 85–105. [Google Scholar] [CrossRef] [Green Version]
- Si, C.; Jing, Y.; Wang, W.; Wang, L.; Tan, T. Skeleton-Based Action Recognition with Spatial Reasoning and Temporal Stack Learning. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 103–118. [Google Scholar]
- Zhang, P.; Lan, C.; Xing, J.; Zeng, W.; Xue, J.; Zheng, N. View adaptive recurrent neural networks for high performance human action recognition from skeleton data. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2117–2126. [Google Scholar]
- Huynh-The, T.; Hua, C.H.; Kim, D.S. Learning Action Images Using Deep Convolutional Neural Networks For 3D Action Recognition. In Proceedings of the IEEE Sensors Applications Symposium (SAS), Sophia Antipolis, France, 11–13 March 2019; pp. 1–6. [Google Scholar]
- Fan, H.; Luo, C.; Zeng, C.; Ferianc, M.; Que, Z.; Liu, S.; Niu, X.; Luk, W. F-E3D: FPGA-based Acceleration of an Efficient 3D Convolutional Neural Network for Human Action Recognition. In Proceedings of the IEEE 30th International Conference on Application-Specific Systems, Architectures and Processors (ASAP), New York, NY, USA, 15–17 July 2019; pp. 1–8. [Google Scholar]
- Wu, H.; Ma, X.; Li, Y. Hierarchical dynamic depth projected difference images–based action recognition in videos with convolutional neural networks. Int. J. Adv. Robot. Syst. 2019, 16. [Google Scholar] [CrossRef] [Green Version]
- Zhang, P.; Lan, C.; Xing, J.; Zeng, W.; Xue, J.; Zheng, N. View Adaptive Neural Networks for High Performance Skeleton-based Human Action Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 1963–1978. [Google Scholar] [CrossRef] [Green Version]
- Cho, S.; Maqbool, M.; Liu, F.; Foroosh, H. Self-Attention Network for Skeleton-based Human Action Recognition. arXiv 2019, arXiv:1912.08435. [Google Scholar]
- Liu, S.; Ma, X.; Wu, H.; Li, Y. An End to End Framework with Adaptive Spatio-Temporal Attention Module for Human Action Recognition. IEEE Access 2020, 8, 47220–47231. [Google Scholar] [CrossRef]
- Yan, S.; Xiong, Y.; Lin, D. Spatial temporal graph convolutional networks for skeleton-based action recognition. arXiv 2018, arXiv:1801.07455. [Google Scholar]
- Kong, Y.; Li, L.; Zhang, K.; Ni, Q.; Han, J. Attention module-based spatial-temporal graph convolutional networks for skeleton-based action recognition. J. Electron. Imaging 2019, 28, 043032. [Google Scholar] [CrossRef] [Green Version]
- Shi, L.; Zhang, Y.; Cheng, J.; Lu, H. Two-Stream Adaptive Graph Convolutional Networks for Skeleton-Based Action Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 June 2019; pp. 12026–12035. [Google Scholar]
- Liu, R.; Xu, C.; Zhang, T.; Zhao, W.; Cui, Z.; Yang, J. Si-GCN: Structure-induced Graph Convolution Network for Skeleton-based Action Recognition. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–8. [Google Scholar]
- Ding, X.; Yang, K.; Chen, W. A Semantics-Guided Graph Convolutional Network for Skeleton-Based Action Recognition. In Proceedings of the 2020 the 4th International Conference on Innovation in Artificial Intelligence, Xiamen, China, 6–9 May 2020; pp. 130–136. [Google Scholar]
- Ke, Q.; Bennamoun, M.; An, S.; Sohel, F.; Boussaid, F. A new representation of skeleton sequences for 3d action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3288–3297. [Google Scholar]
- Du, Y.; Fu, Y.; Wang, L. Skeleton based action recognition with convolutional neural network. In Proceedings of the 2015 3rd IAPR Asian Conference on Pattern Recognition (ACPR), Kuala Lumpur, Malaysia, 3–6 November 2015; pp. 579–583. [Google Scholar]
- Shahroudy, A.; Liu, J.; Ng, T.T.; Wang, G. Ntu rgb+ d: A large scale dataset for 3d human activity analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1010–1019. [Google Scholar]
- Liu, J.; Shahroudy, A.; Xu, D.; Wang, G. Spatio-Temporal LSTM with Trust Gates for 3D Human Action Recognition. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 816–833. [Google Scholar]
- Majd, M.; Safabakhsh, R. Correlational Convolutional LSTM for Human Action Recognition. Neurocomputing 2019, 396, 224–229. [Google Scholar] [CrossRef]
- Gammulle, H.; Denman, S.; Sridharan, S.; Fookes, C. Two Stream LSTM: A Deep Fusion Framework for Human Action Recognition. In Proceedings of the 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 24–31 March 2017; pp. 177–186. [Google Scholar]
- Zhang, Z.; Lv, Z.; Gan, C.; Zhu, Q. Human action recognition using convolutional LSTM and fully-connected LSTM with different attentions. Neurocomputing 2020, 410, 304–316. [Google Scholar]
- Xiong, W.; Wu, L.; Alleva, F.; Droppo, J.; Huang, X.; Stolcke, A. The Microsoft 2017 Conversational Speech Recognition System. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 5934–5938. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local Neural Networks. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- Liu, C.; Ying, J.; Yang, H.; Hu, X.; Liu, J. Improved human action recognition approach based on two-stream convolutional neural network model. Vis. Comput. 2020, 6, 28. [Google Scholar]
- Torpey, D.; Celik, T. Human Action Recognition using Local Two-Stream Convolution Neural Network Features and Support Vector Machines. arXiv 2020, arXiv:2002.09423. [Google Scholar]
- Tang, Y.; Tian, Y.; Lu, J.; Li, P.; Zhou, J. Deep Progressive Reinforcement Learning for Skeleton-Based Action Recognition. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 5323–5332. [Google Scholar]
- Li, F.; Zhu, A.; Xu, Y.; Cui, R.; Hua, G. Multi-stream and Enhanced Spatial-temporal Graph Convolution Network for Skeleton-based Action Recognition. IEEE Access 2020, 8, 97757–97770. [Google Scholar] [CrossRef]
- Shiraki, K.; Hirakawa, T.; Yamashita, T.; Fujiyoshi, H. Acquisition of Optimal Connection Patterns for Skeleton-based Action Recognition with Graph Convolutional Networks. Proceedings of the 15th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications–Volume 5: VISAPP arXiv:1811.12013v2.
- Wang, J.; Hu, J.; Qian, S.; Fang, Q.; Xu, C. Multimodal Graph Convolutional Networks for High Quality Content Recognition. Neurocomputing 2020, 412, 42–51. [Google Scholar] [CrossRef]
- Qin, Y.; Mo, L.; Li, C.; Luo, J. Skeleton-based action recognition by part-aware graph convolutional networks. Vis. Comput. 2019, 36, 621–631. [Google Scholar]
- Yang, D.; Li, M.M.; Fu, H.; Fan, J.; Leung, H. Centrality Graph Convolutional Networks for Skeleton-based Action Recognition. Sensors 2020, 20, 3499. [Google Scholar]
- Yang, K.; Ding, X.; Chen, W. A Graph-Enhanced Convolution Network with Attention Gate for Skeleton Based Action Recognition. In Proceedings of the ICCPR ’19: 2019 8th International Conference on Computing and Pattern Recognition, Beijing, China, 23–25 October 2018; Association for Computing Machinery: New York, NY, USA, 2019; pp. 342–347. [Google Scholar]
- Rashid, M.; Kjellstrm, H.; Lee, Y.J. Action Graphs: Weakly-supervised Action Localization with Graph Convolution Networks. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Snowmass Village, CO, USA, 1–5 March 2020; pp. 615–624. [Google Scholar]
- Lee, J.; Jung, Y.; Kim, H. Dual Attention in Time and Frequency Domain for Voice Activity Detection. arXiv 2020, arXiv:2003.12266. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual Attention Network for Scene Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 June 2019; pp. 3146–3154. [Google Scholar]
- Zhang, P.; Xue, J.; Lan, C.; Zeng, W.; Gao, Z.; Zheng, N. Adding attentiveness to the neurons in recurrent neural networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 135–151. [Google Scholar]
- Li, M.; Chen, S.; Chen, X.; Zhang, Y.; Wang, Y.; Tian, Q. Actional-structural graph convolutional networks for skeleton-based action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3595–3603. [Google Scholar]
- Gao, X.; Hu, W.; Tang, J.; Liu, J.; Guo, Z. Optimized skeleton-based action recognition via sparsified graph regression. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 601–610. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | X-View (NTU60) | X-Sub (NTU60) | X-View (NTU120) | X-Sub (NTU120) |
|---|---|---|---|---|
| 85.19 | 69.57 | 56.57 | 39.76 | |
| 87.43 | 76.72 | 70.63 | 50.46 | |
| 89.08 | 78.91 | 71.16 | 63.74 | |
| 87.12 | 84.99 | 74.09 | 71.46 | |
| 92.88 | 86.51 | 74.09 | 71.46 | |
| 95.76 | 90.01 | 82.44 | 79.03 | |
| 90.53 | 84.81 | 74.23 | 71.39 | |
| 91.80 | 83.46 | 72.44 | 69.88 |
| Models | X-View (NTU60) | X-Sub (NTU60) | X-View (NTU120) | X-Sub (NTU120) |
|---|---|---|---|---|
| [22] | 70.3 | 62.9 | 26.3 | 25.5 |
| [5] | 81.2 | 73.4 | 57.9 | 55.7 |
| [20] | 84.8 | 79.6 | 57.9 | 58.4 |
| [41] | 87.6 | 79.4 | – | – |
| [8] | 88.4 | 80.7 | – | – |
| [12] | 94.3 | 88.7 | – | – |
| [15] | 88.3 | 81.5 | – | – |
| [42] | 94.2 | 86.8 | – | – |
| [43] | 94.3 | 87.5 | – | – |
| [17] | 95.1 | 88.5 | 84.9 | 82.9 |
| [19] | 94.5 | 89.0 | 81.5 | 79.2 |
| 95.76 | 90.01 | 82.44 | 79.03 |
| Models | X-View (NTU60) | X-Sub (NTU60) | X-View (NTU120) | X-Sub (NTU120) |
|---|---|---|---|---|
| 90.69 | 78.88 | 65.49 | 62.57 | |
| 92.08 | 82.44 | 79.66 | 71.80 | |
| 93.75 | 85.94 | 81.58 | 76.66 | |
| 95.76 | 90.01 | 82.44 | 79.03 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, Z.; Lee, E.-J. Dual Attention-Guided Multiscale Dynamic Aggregate Graph Convolutional Networks for Skeleton-Based Human Action Recognition. Symmetry 2020, 12, 1589. https://doi.org/10.3390/sym12101589
Hu Z, Lee E-J. Dual Attention-Guided Multiscale Dynamic Aggregate Graph Convolutional Networks for Skeleton-Based Human Action Recognition. Symmetry. 2020; 12(10):1589. https://doi.org/10.3390/sym12101589
Chicago/Turabian StyleHu, Zeyuan, and Eung-Joo Lee. 2020. "Dual Attention-Guided Multiscale Dynamic Aggregate Graph Convolutional Networks for Skeleton-Based Human Action Recognition" Symmetry 12, no. 10: 1589. https://doi.org/10.3390/sym12101589